
基于小样本学习的个性化Hashtag推荐
2021-10-19 08:46曾兰君彭敏龙刘雅琦许辽萨魏忠钰黄萱菁
中文信息学报 2021年9期
曾兰君,彭敏龙,刘雅琦,许辽萨,魏忠钰,黄萱菁
(1. 复旦大学 计算机科学技术学院,上海 200433;2. 蚂蚁集团,浙江 杭州 310007;3. 复旦大学 大数据学院,上海 200433)
0 引言
近年来,信息传播平台,如微博、推特等,已经成为最受欢迎的信息生成和传播社交媒体之一。Hashtag是微博当中以井号(#)开头的字或者短语,用来标记微博的关键字或者主题信息。Hashtag已被证明在许多下游任务中发挥着重要的作用,例如,微博的分类管理和检索[1]、拓展查询[2]、情感分析[3]。此外,Hashtag也经常用于突发事件监测、流行电视节目评论监测和公众对政府态度监测等方面。对于有经验的用户来说,使用合适的Hashtag可以让自己的微博被更多的人看到,与未关联用户进行话题讨论。虽然已经有很多研究表明了Hashtag在信息组织方面的优势,但在实际应用中,由于需要一定的经验以及时间,只有少量用户会主动标记Hashtag[4]。因此,Hashtag推荐任务有着重要的研究价值和实际意义。
最近,由于在提取特征方面的有效性和优越性,深度学习方法在Hashtag推荐任务中获得了巨大的成功[4-10]。这些方法通常将推荐任务看作是多标签分类问题,将所有可用的Hashtag(通常是训练数据集中出现频率最高的前K个Hashtag)作为输出空间,推荐过程即为对微博的分类过程。但是这些方法有两个问题:一是无法处理模型在训练期间没有见到的Hashtag,因为分类器一旦被训练好,模型及其输出空间就固定了。然而在实际应用中,新的Hashtag不断被用户引入,Hashtag的分布也随着时间不断变化,这导致了训练和推理之间的差距随着时间的推移不断扩大。二是实际中Hashtag数量巨大,选取所有Hashtag作为输出类别会导致较高的计算成本,并增加推荐难度。
本文从推特上随机爬取了275 546名用户的微博(详细信息见3.1节)。图1展示了在该大型真实数据集上的分析结果。从图1(a)中,我们可以看到,大多数用户只使用了全部103 584个Hashtag中很小的一部分,其中超过80%的用户只使用了不到100个不同的Hashtag。通过图1(b)可以看出,用户倾向于使用最近用过的Hashtag。具体地,对于查询微博中的一个Hashtag,平均来说,在用户发布这条微博之前的100条微博中可以找到它的概率约为70%。
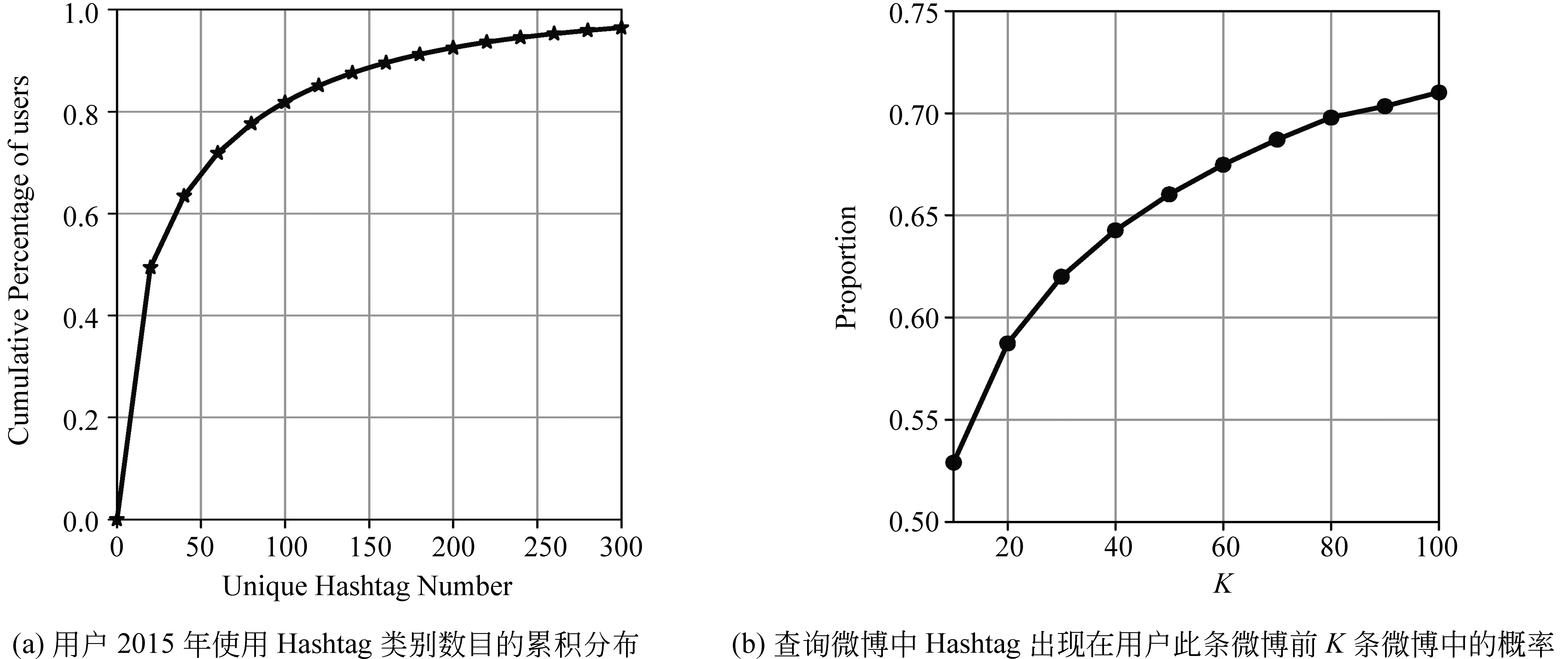
图1 在随机抽取的275 546名推特用户上的数据分析
针对目前方法的局限性,本文提出将Hashtag推荐任务看作是一个小样本学习问题,并提出了一个基于注意力的关系网络模型,可以快速应用于分类新的Hashtag。此外,受到用户数据分析的启发,我们提出为每一个查询微博定制一个个性化输出空间。本文的主要贡献有:
(1) 将标签推荐任务建模为小样本学习任务,并提出了一种基于注意力的关系网络(AREN),该模型采用新颖的episodic策略进行训练。这使得我们的方法能够在推理时处理训练不可见的Hashtag标签和不同的输出空间。
(2) 通过对数据的分析,我们发现用户只使用很小一部分的Hashtag,并且倾向于使用之前用过的Hashtag。基于此,本文提出对每个查询微博使用个性化的输出空间,这在很大程度上降低了计算成本。此外,我们还引入了回退机制,在必要时扩展个性化的输出空间。
(3) 我们收集了大量的真实微博数据。在该数据上的实验研究表明,相比于当前最先进的方法,本文提出的模型能够获得更好的推荐性能,并且有更强的鲁棒性。
1 相关工作
1.1 Hashtag推荐
随着对Hashtag推荐的需求不断增长,研究者从不同视角提出了大量的工作,如概率模型[11-13]、协同过滤[14]和深度学习[4-10]等。
Mazzia和Juett[12]使用朴素贝叶斯模型来估计给定微博对每个Hashtag的先验概率。Krestel等[15]提出了基于隐含狄利克雷分布的方法,从用户标记的数据中学习潜在的主题结构。Ding等[13]提出基于主题的翻译模型来解决这个问题,推荐的过程即为将文本翻译为Hashtag的过程。此外,基于相似性的方法[14,16-17]提取相似微博或相似用户微博中的Hashtag,然后对这些Hashtag进行排序。其中,Wang等[14]根据用户发表的微博使用协同过滤算法查找相似用户。Tran等[17]在建模用户特征时,不仅使用了用户微博文本,还考虑了用户使用过的Hashtag和社交互动。Kowald等[16]结合Hashtag使用频率和时间权重对Hashtag进行排序。颛悦等[18]提出一种融合个性化与多样性的人物标签推荐方法。Belhadi等[19]首次将Top-k高效用模式挖掘的方法用于Hashtag推荐任务。为了探究社会因素对Hashtag推荐性能的影响,Alsini等[20]对比了在多种社区检测算法发现的社区上使用文本相似度推荐Hashtag的性能。
近年来,深度神经网络方法在Hashtag推荐上取得了很大的成功,这些方法大多将该问题转换为分类任务。Gong和Zhang[6]首次利用基于注意力的卷积神经网络提取文本信息,并结合触发词实现Hashtag推荐。Li等[21]则使用注意力机制融合微博的主题内容和文本内容。Zhang等[4]注意到多模态微博中图片对Hashtag的影响,利用卷积网络提取图片信息、利用长短时记忆网络(LSTM)提取文本信息,并结合联合注意力机制实现多模态微博的推荐。为了解决未登录词问题,Dhingra等[7]提出使用双向门控循环单元(GRU)对微博的字符序列进行编码。Wei等[10]首次提出使用图卷积神经网络来建模微视频中用户和标签之间的复杂交互,从而实现个性化Hashtag推荐。针对Hashtag推荐的长尾问题,Li等[22]提出构造带有外部知识的Hashtag图网络,并利用Hashtag相关性进行信息传播。Peng等[23]提出基于匹配的方法,通过编码字符序列表示Hashtag,然后计算Hashtag和微博文本之间的相关性。Kaviani等[24]使用目前最新的预训练语言模型BERT来提取编码微博的文本信息。为了解决短微博中特征和数据稀疏问题,Kumar等[25]提出在微博的编码中引入外部知识。Javari等[26]构造了基于图的用户画像,并提出一种弱监督注意力机制,根据邻居节点高效编码用户特征。与以上这些方法不同,我们将Hashtag推荐任务看作小样本学习问题,让模型在保证深度学习提取特征优势的同时,可以快速吸收新的Hashtag类别。
1.2 小样本学习
虽然深度学习在诸多领域取得了引人瞩目的成就,但这些模型严重依赖于大量人工标注的高质量数据。当标注数据稀少时,这些模型的学习能力有限。为了解决这个问题,小样本学习被提了出来。这项技术试图让机器在学习大量的数据后,能在有限样本下实现对新类别或新概念的快速认知。目前,小样本学习的研究热点可分为基于度量的方法、基于优化的方法和基于生成式模型的方法等[27-28]。基于度量的方法[29-30]旨在学习一个强大的可迁移到新样本上的网络映射,并使用合适的度量函数计算样本之间的相似度。基于优化的方法[31-32]旨在学习一个好的初始化参数,在新任务测试时,仅通过很少的参数迭代次数,模型即可自适应到该新任务上。生成式模型[33]则期望生成大量新类别数据样本,进而将小样本学习转化为传统的监督学习。在这项工作中,我们主要采用基于度量的方法。
在小样本分类任务中,Vinyals等[29]引入了N-wayK-shot的问题设定。在这个设定中,我们在训练时可以得到大量标注数据,数据类别的集合为Ctrain,但在测试时,查询样例的真实标签来自于训练不可见的类别集合Ctest。除此之外,对于每一个查询样例,该设定会提供一个相应的支持集,支持集中的数据来自于N∈Ctest个新类别,每个类别有K个带有标注的支持样本。这项任务旨在根据支持集快速识别查询样例的正确类别。但是由于K很小(如K=5),如果直接使用支持集进行训练,分类器会出现严重的过拟合问题。现有的方法使用元学习来解决这个问题。
episodic训练策略是对元学习的一种实践[29]。它在训练阶段通过对原始数据的采样,模拟测试过程构建子任务。具体地,在一个episodic中,模型首先从Ctrain中随机抽取N个类别,然后从每个选定的类别中采样K个带有标记的示例作为支持样例,并从剩余样本中抽取查询样本。通过这种方式,可以在训练数据上构造大量用于训练的支持查询对。在这些子任务上训练的模型,可以学习到不同支持查询对之间的共性,因此,可以很好地推广到新的支持查询对上。
2 模型
本文将Hashtag推荐任务看作是小样本学习任务。首先,我们介绍这个任务定义和文中用到的符号。然后,我们介绍本文提出的个性化Hashtag推荐模型AREN。最后,我们介绍AREN的一种回退机制。AREN的整体结构如图2所示。
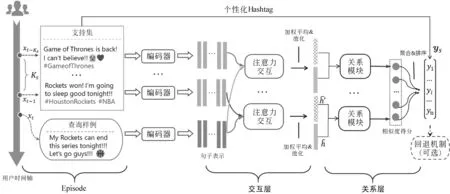
图2 AREN模型的结构图
2.1 任务定义和符号描述
按照小样本分类任务的定义,对于给定的查询微博x,在推理时指定一个支持集S(带有Hashtag微博的集合),模型的目标是确定查询微博x的Hashtag类别,该类别可能是训练时不可见的。而在训练时,我们可以得到一组训练用户U={u1,…,uN}。每个用户u的微博按照发布时间排序为列表Tu=[(x1,Yx1),…,(xnu,Yxnu)],其中,Yx表示微博x中所有用户标记的真实Hashtag(一条微博可能包含多个Hashtag)。D={Tu}u∈U构成了整个训练数据集。对于一个列表L,L[i]表示其第i项,L[i:j]=[L[i],…,L[j]]。
2.2 个性化Hashtag推荐模型
为了适当地利用和建模用户选择Hashtag的偏好,本节提出了一个针对用户的小样本学习模型,即基于注意力的关系网络(AREN),并采用了新颖的episodic策略来进行训练。我们主要分为四个部分来介绍该模型,即episodic策略、微博编码层、交互层和关系层。
2.2.1 episodic策略
在AREN的episodic策略中,我们受到图1数据分析的启发,提出使用用户历史来构建支持集。为了训练一个可以快速吸收新类别并且处理不同输出空间的统一模型,我们使用训练用户数据构造支持查询对,模拟推理过程。具体地,在每个episodic中,首先随机采样一个用户u∈U和一个时间点t∈(Ks,|Tu|],其中,Ks是控制支持微博数量的超参数。然后,将用户的第t个微博Tu[t]看作查询微博x,Tu[t-Ks:t-1]看作支持集合S,S中出现的所有Hashtag类别即为输出空间YS。这个个性化的输出空间比实际的输出空间要小很多,可以有效降低推荐复杂度。与一般的N-wayK-shot设置不同,在这个设定中,不同支持集的类别数目可能不同,且单个支持集中每个类别的支持样例数也可能不同。
根据查询微博x和支持集S,AREN为每个Hashtagy∈YS计算一个得分,如式(1)所示。
s(y|x,S)=∑(x′,Yx′)∈Ssim(x,x′)I(y∈Yx′)
(1)
其中,I是指示函数,sim(x,x′)是一个计算x和x′语义相似度的非负函数。值得注意的是,分数s(y|x,S)与y在S中出现的频率正相关。这个设计是基于假设:在S中使用越频繁的标签将来用户使用它的概率越大。最后我们根据s(y|x,S)的降序排列给出推荐。
在这个模型中,相似度sim计算过程如式(2)所示。
sim(x,x′)=d(Att(f(x),f(x′)))
(2)
其中,f是一个基于LSTM(Long Short-Term Memory)的编码器,用于提取微博的特征向量,Att是一个注意力网络,用于提取特征向量f(x)和f(x′)的交互信息,d是一个关系网络,计算两个特征的相似度。
2.2.2 微博编码层
编码层的目标是生成每个微博文本的特征表示。具体地,给定一个包含lx个单词的微博x,我们首先使用一个词嵌入矩阵At∈dw×|V|将每一个单词映射到维度为dw的向量,其中,|V|是词汇表大小。通过这一步我们可以得到微博x在词级别上的表示x={w1,w2,…,wlx}。然后,我们使用双向长短时记忆网络(BiLSTM)对词序列进行上下文语义编码。在每个时间步骤t,BiLSTM以词向量wt为输入,输出对应的隐含状态ht,具体过程如式(3)、式(4)所示。

2.2.3 交互层
为了过滤噪声,更准确地计算两个微博x和x′之间的相似度,我们使用注意力机制让它们的表示进行交互,学习它们的对齐表示。该层的输入为通过编码器得到的微博x和x′的隐含表示H和H′。式(5)~式(9)精确地表示了两个句子的交互过程。

2.2.4 关系层

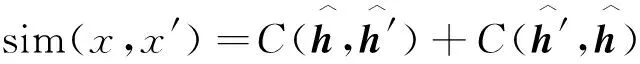
(10)
(11)
其中,MLP包含两个具有ReLU激活函数的隐藏层和一个具有Softplus激活函数的输出层,θc表示其中的可训练参数。
2.2.5 模型训练
在每一个episodic中, 支持查询对的损失函数定义如式(12)所示。
(12)
其中,为了方便表示,我们使用s(y)来表示s(y|x,S),l表示Softplus函数,即l(x)=ln(1+ex)。 值得注意地是,l为损失函数时的一阶导数为l′(x)=ex/(1+ex)。因此,当s(y-)≪s(y+)时,l′(s(y-)-s(y+))→0,模型几乎不会进行更新。相反,当s(y-)≫s(y+)时,l′(s(y-)-s(y+))→1,即模型会在明显错误的例子上线性更新以减少损失。
综上所述,模型在所有训练任务上的代价函数可以形式化如式(13)所示。
Ls=u∈U[(S,x,Yx)~Tuls(S,x,Yx)]
(13)
训练目标为:
(14)
其中,θs是AREN中的可训练参数。我们使用梯度下降法训练模型,训练过程如算法1所示。

算法 1 个性化模型AREN优化过程

续表
2.3 回退机制
事实上,当用户在谈论突发事件、新闻或者谣言时,他们很可能会使用一些之前没有用过的Hashtag。上文的个性化推荐模型不能很好地处理这些情况,为了解决这一问题,我们提出了一个回退机制来扩展AREN的个性化输出空间,该机制由一个控制器和一个用户无关的推荐算法组成。
2.3.1 控制器
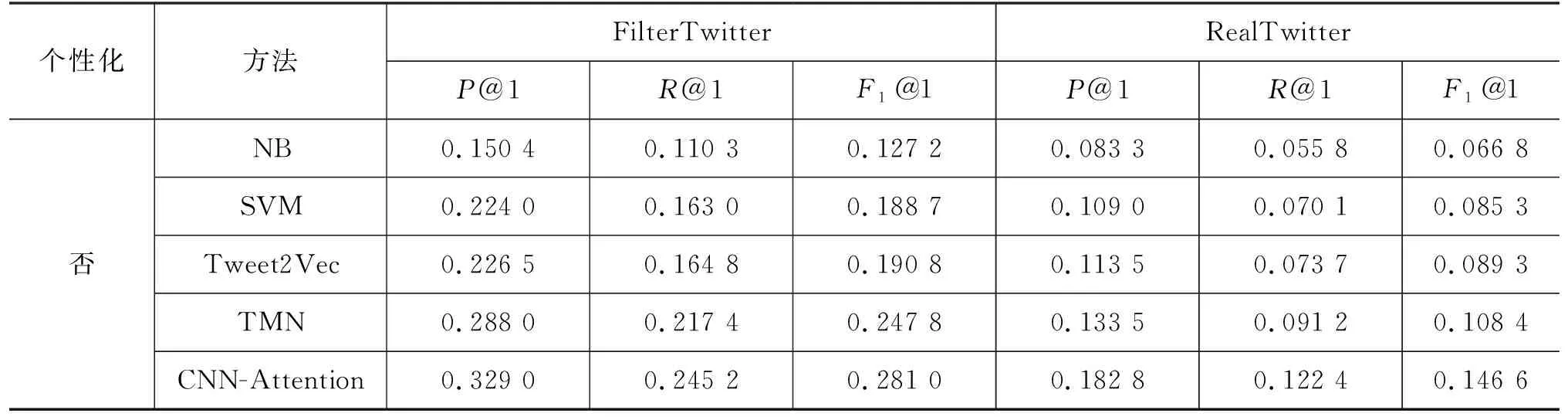
控制器是为了自动判断扩展AREN输出空间的必要性。为此,本文为AREN中Hashtag的得分设置阈值,如果一个Hashtag y的得分小于阈值,则不应该使用AREN推荐y。为了计算阈值,我们首先对s(y|x,S)进行降序排序,得到的排序列表记为sort(Ys)。控制器将这个列表的前Kz个值sort(Ys)[1:Kz]作为输入,其中,Kz是一个超参数,在本文实验中设置为10。如候选Hashtag个数|Ys| η=MLP(s(Ys)[1:Kz]) (15) 控制器在支持查询对(x,Yx,Su)上的训练损失定义如式(16)所示。 (16) 式(16)的基本思想是,正确的Hashtag分数应该尽可能大于阈值,而错误Hashtag的分数应该小于阈值。我们使用联合损失来同时训练个性化模型AREN和控制器,如式(17)所示。 lsz(S,x,Yx)=ls(S,x,Yx)+λlz(S,x,Yx) (17) 在测试中,让n表示为每一个微博推荐的Hashtag数量(测试时是固定的), 假设在AREN中有m个标签的得分超过了阈值η,则如果m≥n,我们将推荐得分最高的前n个Hashtag并结束推荐过程;否则,我们扩展AREN的输出空间S,并使用其他非个性化模型推荐另外n-m个Hashtag。 2.3.2 用户无关Hashtag推荐模型 在这个模型中,我们在AREN个性化的支持集S中额外加入最近流行的Hashtag和相应的微博,得到扩展的支持集Se。由于|Se|可能会很大,如果使用关系网络建模查询微博x与每个支持样例x′∈|Se|之间的相似性,会使得计算非常复杂。因此,我们使用了另外一个小样本学习模型来执行用户无关的Hashtag推荐。 该模型依然采用episodic进行训练。但与AREN不同的是,该模型通过式(18)计算y∈YSe的推荐概率。 g(y|x,Se) (18) 其中,Sy⊂Se表示扩展支持集Se内包含Hashtag为y的微博集合。这里相似函数sim不再使用交互层和关系网络实现,而是直接对编码层得到的特征使用余弦相似度。 根据Twitter的隐私政策和开发者协议(1)https://developer.twitter.com/en/developerterms/agreement-and-policy,目前大多数Twitter上的数据集不再公开。因此,为了评估我们的模型,本文通过Twitter提供的API构建了两个包含用户和时间信息的数据集,分别命名为RealTwitter和FilterTwitter(2)按照隐私协议要求,为了方便后续研究,我们仅公开数据集中的用户ID。。 首先,随机抽样275 546名Twitter用户,爬取他们在2015年发布的微博。然后,删除其中不含Hashtag的微博、非英语微博和所有转发微博。接下来,我们随机抽取其中10 000名用户作为研究用户,并提取这些用户在2015年1月1日至2015年4月30日期间发布的微博作为训练数据。对于验证集和测试集,我们爬取这10 000个用户在2015年5月1日至2015年5月20日期间发布的微博,然后将这些用户随机分成两组,其中,50%用于验证集,50%用于测试集。我们把这个真实数据集命名为RealTwitter。 考虑到基于分类的方法不能被直接应用于新出现的Hashtag类别,为了更公平地比较,我们构建了另外一个数据集——FilterTwitter。在Real-Twitter基础上,筛选出训练集中出现频率低于20的Hashtag,分别删除其在训练集、验证集和测试集中对应的微博。这样,我们的验证和测试数据就只包含在训练集中出现次数大于20的Hashtag。这两个数据集的详细信息如表1所示。 表1 数据集分析 3.2.1 评价指标 在实验中,使用用户标记的Hashtag作为真实标签,一条微博可能对应多个Hashtag。与之前的工作[4]相同,我们使用精确度(P)、召回率(R)和F1-score(F1)作为评价指标。测试时,将每个查询微博推荐的Hashtag数目记作n,其中n={1,2,3,4,5},对应的P、R和F1分别记作P@n、R@n和F1@n。 3.2.2 对比模型 我们选取了目前领先的算法作为本文的对比模型。非个性模型包括:基于朴素贝叶斯的方法(NB)[12]、基于支持向量机的方法(SVM)[11]、基于字符编码的深度学习方法(Tweet2Vec)[7]、结合主题模型和记忆网络的方法(TMN)[34]和基于注意力卷积神经网络的方法(CNN-Attention)[6]。个性化模型包括:端到端的记忆网络(HMemN2N)[5]、基于相似度的方法(CB-UC)[17]和基于时间影响的认知启发方法(BLL)[16]。 3.2.3 参数设置 在我们的模型中,词向量使用预训练过的GloVe[35]进行初始化,并在训练数据上进行微调,词向量维度设置为100。微博编码器中LSTM的隐含状态向量设置为100维。支持集大小在训练时固定为30。在推断过程中,当用户的历史微博不足30条时,所有的历史微博被用于构成支持集。超参数λ设置为1。模型使用Rmsprop优化方法进行训练,初始学习率设置为1e-4。 表2展示了本文提出的方法AREN和各基线模型在两个数据集上的实验结果。此外,我们还加入了AREN的一个变体AREN&Rollback,它使用可控的回退机制,并在回退中使用非个性化的小样本学习模型。表中列出的指标是当为每个微博推荐的标签个数n=1时的结果,n取其他值时与n=1趋势相似,详细信息可查看图3。整体来看,本文提出的方法AREN和AREN&Rollback取得了最好的结果。此外,个性化方法的性能都优于非个性化方法,这验证了在模型设计中加入用户信息的必要性。 表2 在两个数据集上的实验结果 续表 在数据集FilterTwitter上的实验表明,与目前最好的方法BBL对比,AREN在精确率、召回率和F1值上分别取得了7.0%、4.9%和5.8%的提升。这证明了本文提出小样本学习模型的有效性。此外,在结合了回退机制之后,我们的模型在精确率、召回率和F1值上又进一步提高了0.8%、0.7%和0.8%。 为了证明本文方法在处理新出现的Hashtag上的有效性,我们在真实的数据集RealTwitter上进行了实验。如上所述,该数据集里有大量带有新Hashtag的测试微博,这为推荐任务带来了额外的挑战。从表2可以看出,所有方法在RealTwitter上的性能相比FilterTwitter均有下降。然而,我们观察到本文方法相比基线下降幅度更小,例如, AREN & Rollback在F1值上下降12.5%,而基线方法CB-UC和BLL则分别下降17.8%和18.3%。 图3展示了当推荐Hashtag数目取n={1,2,3,4,5}时,各代表模型在FilterTwitter数据集上的精确率、召回率和F1值。很明显,在不同推荐个数时,随着推荐Hashtag数量的增加,模型精度率降低,召回率提高。从图中我们可以看出,在Hashtag数目取不同值时,本文的方法都是所有曲线中性能最高的。 图3 推荐不同Hashtag数目时模型对应的结果 本节进一步探讨了所提出方法的鲁棒性。首先,考虑到一些用户可能没有足够的历史微博,我们探究了在测试时支持集大小Ks对AREN性能的影响。其次,我们分析了随着时间增加,测试和训练之间的分布差距越来越大的情况下,AREN在测试时的性能。最后,我们把训练好的模型用于训练集中没有包括的用户。 为了探究支持集大小的影响,我们将模型AREN在RealTwitter上进行训练,并在测试时不断改变支持集的大小Ks(训练时Ks固定为30)。图4展示了Ks取不同值时的测试性能。从图4可以看出,当Ks∈[20,50]范围内时,模型性能很稳定,但当Ks<20时,模型性能会随着Ks减小而快速下降。因此,为了保证推荐质量,最好给本文模型提供20个以上的用户历史微博。 图4 支持集大小Ks对AREN性能的影响 为了验证本文模型在时间上的可靠性,我们将模型在RealTwitter训练集上进行了训练,该数据集中的微博发布于2015年前4个月。然后,我们提取训练用户在2015年5月到2015年12月发布的微博,并按月份进行划分。将训练好的模型分别用于这些微博进行推荐。图5显示了本文模型和HMemN2N的比较,后者是目前基于分类的最优方法。从图中可以看出,模型AREN性能稳定,而HMemN2N性能随着测试和训练时间间隔增加而下降。此外,我们注意到AREN的性能随时间轻微上升,这可以解释为用户的历史微博随时间不断增加,因此在测试时,Ks<30的情况会不断减少,结果也随之变好。 图5 测试时间和训练不可见用户对AREN性能影响new代表训练不可见用户数上的实验结果。 为了证明本文的方法能够用于训练不可见用户,我们从爬取的全部275 546名用户中随机抽取了另外10 000名用户,这些用户与之前抽取的训练用户不相交。然后按月份划分他们的微博,并将在Real- Twitter训练的模型直接用于这些微博进行推荐。结果如图5所示,AREN在新用户和训练用户上的测试结果基本一致,而HMemN2N在新用户上性能下降了一半。同时,本文模型在新用户上的性能随着时间变化也是稳定的,这再次验证了模型的鲁棒性。 为了分析模型中各部分的贡献,本文设计了以下四个模型变种并在两个数据集上进行了实验。 ●AREN(Random):对于给定的查询微博,从用户所有的历史微博中随机抽取支持集,而不使用时间轴信息; ●AREN(w/oA):将交互层从AREN移除,并使用BiLSTM最后一个时间序列的隐状态来表示微博文本; ●AREN(w/oR):使用预定义的余弦相似度代替关系网络计算句子的相似性。 ●AREN(w/oS):使用Sigmoid激活函数代替模型中的Softplus函数。 表3列出了当推荐的Hashtag数量n=1时的推荐结果。通过表3可以看出,当更换或移除任一模块时,AREN的性能都会明显降低,这验证了我们设计的各个模块的有效性。 表3 消融实验对比结果 本节用表4中的一个例子具体分析本文方法处理新出现Hashtag的过程。对于表格中的查询微博,我们使用在RealTwitter训练集上训练的模型进行推荐。因为唐纳德·特朗普(Donald Trump)在2015年6月宣布参选美国总统,因此构建在2015年前四个月微博数据上的RealTwitter训练集中没有包含相关的Hashtag。当使用分类模型进行推荐时,无法推荐相关Hashtag,例如,模型HMemN2N推荐了相似但不正确的“#GE2015”和“#leadersdebate”等。但在使用AREN时,根据本文的episodic策略,将用户最近的微博作为支持集,最终给出正确的推荐“#DonaldTrump”和“#Trump2016”。在联合了最近热点Hashtag后,回退机制另外推荐了相关的“#HillaryClinton”。 表4 案例分析 本文将Hashtag推荐任务看作一个小样本学习问题,并设计了一种基于注意力的关系网络,解决了目前分类方法不能处理新出现类别的问题。基于用户使用Hashtag的偏好,本文提出个性化用户微博的输出空间,并基于此设计了模型的episodic训练策略。此外,为了给用户的个性化空间加入更多的Hashtag,本文的模型可以在合适的时候引入一种回退机制。在真实数据集上的大量实验表明,与基线方法相比,本文提出的方法能够显著提高推荐性能,并且表现更加稳定。 未来工作中,我们考虑将用户之间的互动关系加入到本文模型当中,例如,使用查询用户及其好友的历史微博来构建扩展的支持集。另一个方向是在支持集中对时间影响进行建模,例如,将此工作与文献[17]相结合。3 实验
3.1 实验数据

3.2 实验设置
3.3 实验结果


3.4 鲁棒性分析


3.5 消融实验

3.6 案例分析

4 总结
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
汽车与新动力(2016年6期)2017-01-04
中国老区建设(2016年1期)2016-02-28
新校长(2016年8期)2016-01-10
中国卫生(2015年1期)2015-01-22
商事法论集(2014年1期)2014-06-27
