
中文知识库问答中的路径选择
2021-10-19 08:46:58周夏冰李正华梁兴伟陈文亮
中文信息学报 2021年9期
吴 锟,周夏冰,李正华,梁兴伟,陈文亮
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.康佳集团股份有限公司,广东 深圳 518000)
0 引言
知识库问答(Knowledge Base Question Answering,KBQA)是一项具有挑战性的自然语言处理任务,需要根据给定的自然语言问句,通过检索结构化的知识库,返回事实性答案。国内外已经构建起多个成熟的开放域知识库,其中,面向英文的包括Freebase[1],DBpedia[2]等,面向中文的包括Zhishi.me[3],CNDBpedia[4]。知识库作为KBQA的知识来源,是由大量结构化的事实三元组(S,R,O)构成,例如,在三元组(<莫妮卡·贝鲁奇>,<代表作品>,<西西里的美丽传说>)中,<莫妮卡·贝鲁奇>被称为主语(Subject,S),<代表作品>被称为关系(Relation,R),<西西里的美丽传说>被称为宾语(Object,O)。
自然语言问句的结构多种多样,在知识库问答中,简单问句指根据单个三元组能被准确回答的问句[5],如图1左图问句“莫妮卡·贝鲁奇的代表作?”,只需包含单个形如(<莫妮卡·贝鲁奇>,<代表作品>,?)的三元组就能被回答;而复杂问句则需要多个三元组,如图1右图问句“林徽因的丈夫的父亲是?”,需要两个三元组(<林徽因_(中国建筑师、诗人、作家)>,<丈夫>,<梁思成>),(<梁思成>,<父亲>,<梁启超_(中国近代思想家、政治家、教育家)>)才能得到准确的答案。相比简单问句,复杂问句的形式复杂多变,如何对其进行区分和解答则十分具有挑战性。

图1 简单问句(左)和复杂问句(右)
Bordes等[6]将知识库问答的解决方法分为两种,一种是基于语义解析的方法[7-9],另一种是基于信息检索的方法[6,10-12]。基于语义解析的方法把问句解析成由实体和关系构成的语法树,根据语法树生成查询语句获得最终答案。该方法需要大规模的形式语句的标注数据,并且经常存在句子语法结构和知识库中三元组结构不匹配的问题[13]。基于信息检索的方法则会先检索知识库获得答案对应的候选路径(图),再计算其与问句间的语义相似度,最后输出最优路径(图)及最终答案。该方法在构造训练数据上相对容易,也更方便查询答案[14],因而获得了更多的关注,且在多个数据集上取得了更优异的性能。本文的方法属于基于信息检索的方法。
对于知识库问答任务,验证集和测试集中存在大量训练集中未见的实体、关系,对于它们的处理和建模成为模型性能提升的一个瓶颈。同时,大部分中文知识库问答系统仅考虑简单问句,不同问句候选路径数量差距较小。然而对于复杂问题,候选路径数量的组合爆炸是一个严重影响问答系统效率和性能的问题。在包含复杂问题的数据集上,存在如下的挑战:
(1) 在大规模知识库中,当问句的主题实体与答案间相连路径的跳数(Hop)变多时,候选路径(图)的数量会呈指数式增长[15],如何控制搜索空间使得系统高效、高性能?
(2) 如何充分利用知识库中关系的多样性,使训练集中覆盖更多验证集、测试集中存在的三元组关系,提高语义相似度模型的性能?
近年来,一些中文知识库问答数据集也被建立起来,包括简单问答数据集NLPCC KBQA。针对复杂问题集,本文在包含简单问题和复杂问题的CCKS 2019-CKBQA评测数据集上进行了深入研究,做出了如下贡献:
(1) 探索了预训练语言模型BERT(Bidirectional Encoder Representations from Transformers)在复杂问句知识库问答上的应用;
(2) 采取了负例动态采样的模型训练方式,提高了训练集中关系的多样性,显著提升了语义相似度模型的性能;
(3) 比较了两种应对路径爆炸的路径剪枝方法,即基于分类的方法和基于集束搜索的方法。
1 相关工作
1.1 开放域知识库问答
开放域知识库问答任务的解决方法可以归为两类:基于语义解析的方法和基于信息检索的方法。基于语义解析的方法旨在将问句转换成规范语义表示。Berant等[7]利用语义解析技术构造问句对应的语法树,并把语法树转化为逻辑形式表达,再将逻辑形式转化为查询语句查询答案。基于信息检索的方法是另一种典型且应用更广泛的方法,实体对齐、路径(图)选择是其中两个主要步骤。实体对齐指的是找到知识库中问句涉及的实体。Bordes等[6]提取出问句的N-grams词,用于匹配知识库中实体的别名,得到候选的实体集合。Mohammed等[10]利用双向长短时记忆网络(Bi-directional Long Short-Term Memory,LSTM)[16]先对问句进行序列标注,提取问句中与答案相关的实体别名(实体提及),而后利用实体提及的N-grams词来链接知识库中的实体,得到实体的候选集合。路径(查询图)选择依据和问句的相似度筛选最优路径(查询图)。在英文简单问答中,Yu等[11]将问句模式(实体提及被替换的问句)和关系谓词分别编码,计算二者间的语义相似度。Wang等[12]将路径选择看作是序列到序列(Seq2Seq)的任务,提出使用基于Seq2Seq的Encoder-Decoder模型。对于英文复杂问句,Luo等[17]定义了包括时间、序数等模板限制去优化候选查询图生成,再对问句和图分别进行编码,计算两者的语义相似度。在训练集的负例选择中,Yin等[9]和Luo等[17]对每个问句抽取固定数量(k个)的负例加入训练集,Bordes等[6]采用了多任务训练,在每轮迭代依据概率选择主任务或者辅助任务的负例数据进行训练。由于数据集中候选路径数量有限,上述方法重点探索了问题与路径(图)的匹配问题。然而在一些包含复杂问题的数据集上,路径爆炸是一个关键问题。
1.2 预训练语言模型
从ELMo[18]到GPT[19],预训练语言模型在多项自然语言处理任务上展现了它的优势。2018年,Devlin等[20]基于Transformer[21]模型提出BERT模型,利用了大规模文本,通过上下句判断等任务进行预训练,随后根据不同的任务进行微调,在包括命名实体识别、阅读理解问答和自然语言推理等多项自然语言处理任务上取得了当时最优结果。预训练、微调的两阶段模式逐渐成为众多自然语言处理任务的主流方法。例如,在与路径选择相关的答案句选择任务中,Garg等[22]使用BERT序列对分类结构多次微调模型来挑选答案句,序列对分类也是使用BERT计算序列相关度的标准结构。
2 问答系统构建
本文构建了完整的知识库问答系统,路径生成和路径选择是其最主要的两个模块。第一步,问答系统先对问句进行命名实体识别得到实体提及,通过实体提及在知识库中检索得到主题实体,继续搜索知识库得到问句答案的候选路径。下一步,利用语义相似度模型对候选路径进行排序,得到最优的候选路径。最后,依据最优候选路径生成查询语句进行检索得到问句的答案。
2.1 路径生成:实体对齐和问句类型定义
如图2所示,实体对齐包括对问句进行实体识别和实体链接,得到问题的主题实体。本文采用了BERT-BiLSTM的序列标注模型进行实体识别,并融入了知识库术语信息来提高实体识别的召回率。
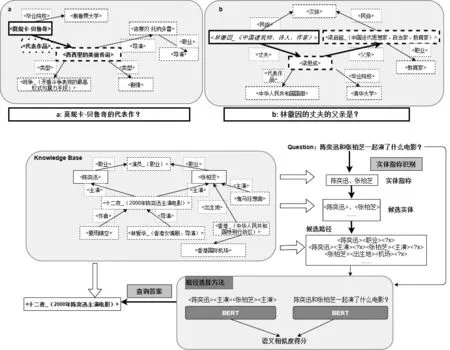
图2 KBQA系统框架图
在实体对齐模块得到问句的主题实体后,本文通过检索知识库得到主题实体相关联的候选路径。受Bao等[5]启发,本文根据标注的查询语句定义了表1中的单跳问句、两跳问句和多限制问句类型,并增加了难以分类的其他类型问句。在训练集中,主题实体两跳范围内能找到答案的问句占比超过89%。因此,考虑到候选路径的规模,本文仅检索主题实体两跳范围内的路径。
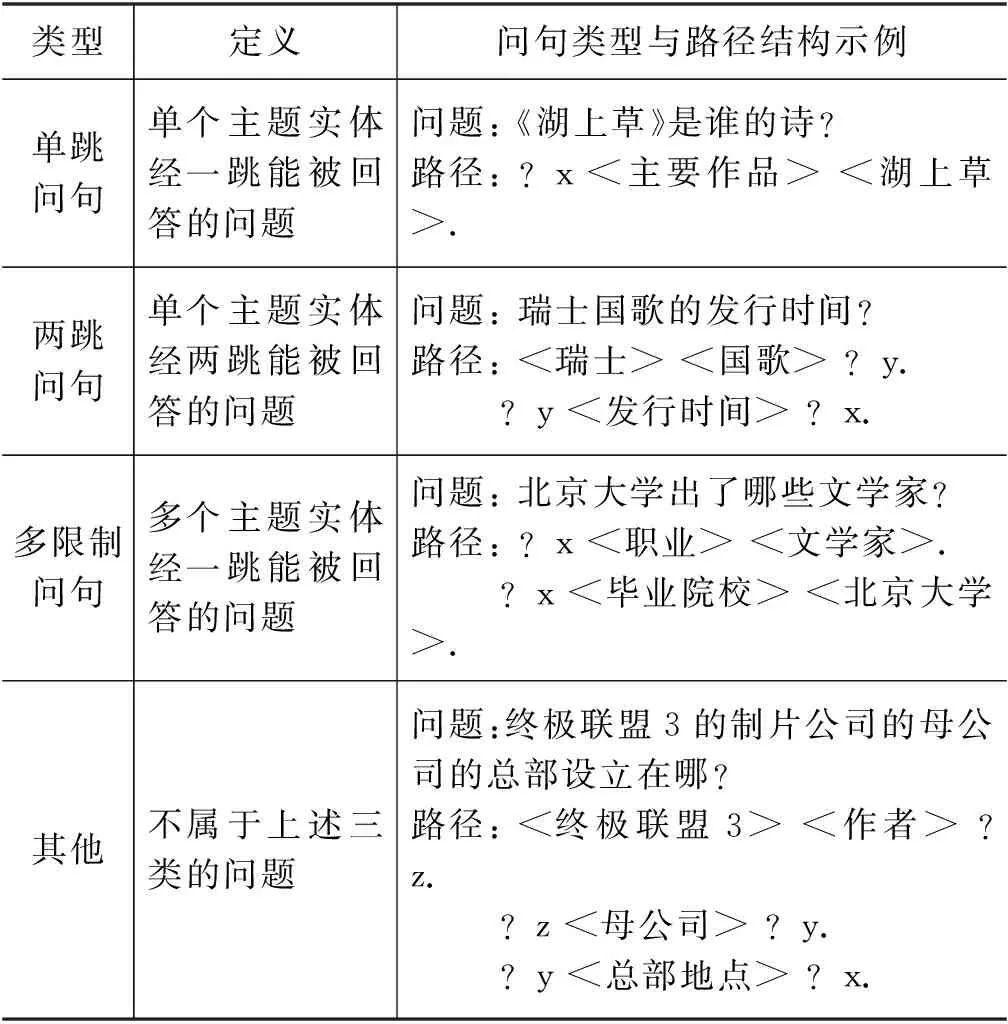
表1 问句类型定义
生成路径时,本文使用特殊符号“
2.2 路径选择:路径剪枝与语义相似度模型
由于候选路径规模庞大,路径选择模块需要先对候选路径进行剪枝后,再使用语义相似度计算模型计算路径与问句的相似度,最后查询知识库得到问题的最终答案。本文建立了基于预训练模型BERT的语义相似度模型进行相似度计算,采用负例动态采样的训练方式扩充了训练集中关系谓词的多样性;在路径剪枝部分,讨论了不同的路径剪枝方案,即基于分类的方案和基于集束搜索的方案,并对两种方法进行了比较。
3 路径剪枝
在大规模知识库中,问句候选路径的数量会随着考虑的路径跳数变化而呈指数式增长。一旦候选路径池的规模过大,计算所有可能路径显得低效且不实际。例如,对于CCKS 2019-CKBQA数据集内的简单问题“中国实行什么政治制度?”,主题实体<中华人民共和国>一跳范围内路径数量为7 077 879,而两跳范围内路径数量更是达到了千万数量级。因此,对候选路径进行剪枝是在预测阶段进行语义相似度计算前的必要步骤。在CCKS 2019-CKBQA数据集上,本文比较了预测阶段基于分类和基于集束搜索进行剪枝的路径选择方法。
3.1 基于分类的路径选择方法
预测阶段基于分类的路径选择方法如图3上图所示,本文建立了基于BERT的分类模型,依据上文定义的问句类型进行问句分类,并根据分类结果搜索对应类型的候选路径。
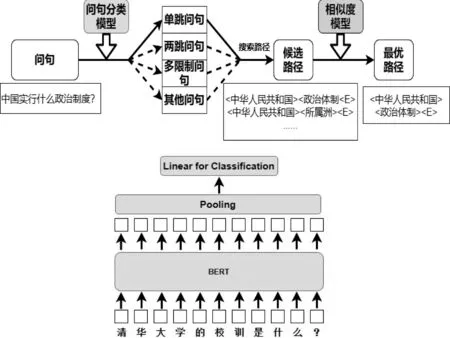
图3 基于分类的路径选择方法(上)和问句分类模型(下)
本文问句分类采用常用的BERT Max-Pooling模型。如图3所示,BERT模型用以提取问句的字级特征,经过Max pooling池化层得到整个句子的表示,最后经过线性层输出每个类别的得分。损失函数采用了对数似然函数,如式(1)、式(2)所示。
其中,k为问句类别的数量,si代表问句属于第i个类别的得分,qi为问句属于第i个类别的概率。
3.2 基于集束搜索的路径选择方法
集束搜索(Beam Search)是神经机器翻译(Nerual Machine Translation,NMT)中常用的解码方法,当字典过大时能有效提高解码的效率。如图4所示,在集束搜索过程中,每一步会搜索序列中该位置的所有可能值,最后保留已搜索序列得分最高的前k个结果(k也被称为束宽)。

图4 束宽为2的集束搜索过程
本文将集束搜索的方法应用于预测阶段多跳路径剪枝中,其路径选择方法如图5所示。先搜索主题实体相关的第一跳(单跳)路径,利用问句和单跳路径的语义相似度得分,保留得分最高的前k的一跳路径G1和一跳相关实体;生成第二跳(两跳)路径时,仅搜索与一跳相关实体相连的第二跳路径作为两跳路径G2,如此往下。为了便于与基于分类搜索的方法相比较,这里仅考虑两跳内的路径,生成两跳范围内的候选路径G=G1∪G2∪G3(单跳路径G1、两跳路径G2和多限制问句路径G3)。最后对候选路径G中的路径得分进行排序后选择最优路径。该方案依赖束宽k能过滤掉大量无关路径,显著降低候选路径的数量。

图5 基于集束搜索的路径选择方法
相比于基于分类的方法,基于集束搜索的方法中候选路径的数量依赖束宽进行动态调整,当搜索的路径跳数达到三跳甚至四跳时,集束搜索能更稳定地控制候选路径数量;同时,产生的候选路径中同时存在多种结构的路径,考虑了单个问句属于不同类型的可能性。不过束宽作为一个重要的参数,影响着系统的性能,需要根据数据集设置。
4 语义相似度模型
语义相似度模型用以计算问句与路径语义上的关联程度。给定一个问句Q和若干候选路径的集合P,使用模型计算路径的得分并寻找满足下式的路径,如式(3)所示。

(3)

本文采用了Luo等[17]使用的Encoding Comparing结构,使用预训练语言模型BERT作为编码器,将定量的负例采样作为基线。如图6所示,BERT模块对问句端和路径端分别编码,将句首位置(特殊符号“[CLS]”)输出的向量hQ和hp,分别作为问句端和路径端的表示,并使用向量间的余弦相似度作为问句与路径的相似度得分,记作S(Q,p)=cos(hQ,hp)。训练阶段,采用Margin Loss来扩大正确路径p+与错误路径p-之间的得分差距,如式(4)所示。

图6 基于BERT的语义相似度模型
losssim=max(0,γ+S(Q,p-)-S(Q,p+))
(4)
其中,γ是模型的一个超参。
在训练阶段,需要从知识库中选择错误路径作为负例。负例路径选择时会存在两个问题:一是负例样本均衡性问题,对于不同的问句,当负例路径数量差距很大时(如10 000∶1),训练样本负例数量分布极其不均衡;二是负例样本多样性问题,当训练用的负例路径固定时,其他负例会被直接丢弃。Luo等[17]对每个问句抽取k个固定负例作为训练集,舍弃了部分已有的负例路径。当训练集中负例固定时,实体、关系数量固定,验证集和测试集中仍可能存在大量未见的实体和关系。为了缓解训练集中关系的单一性问题,本文引入负例动态采样的训练方式,训练方法如下:
(1) 对训练集中的问句{Qi},从知识库中搜索所有的相关路径{Gi},在除去正确路径p+后得到负例路径池{G′i|G′i=Gi-p+}。需要注意的是,这里的负例路径池大小因问句中主题实体的不同而不同,负例路径池将主题实体相关的所有一跳、两跳、多限制路径包括进来。
(2) 当路径池中路径数量|G′i|未达到负例路径最低数量k时,随机生成k-|G′i|个负例路径进行扩充,得到负例路径池G′i′;否则G′i′=G′i。
(3) 训练数据采样阶段,在任意第j轮中,从扩充的训练路径池中随机进行等量k的负例采样,得到第j轮的训练路径池{G″ij|G″ij⊆G″i,|G″ij|=k}, 作为当轮的训练样本。
负例动态采样训练保持了每个问句的训练数据的均衡性,同时扩充了训练集中关系谓词的多样性。相比于定量采样的方法,动态采样使得训练集中的不同实体/关系的数量扩充了数倍(与训练迭代的轮次和负例池大小相关),缓解了验证集和测试集中大量未见的实体/关系的问题。
5 实验结果与分析
5.1 数据集介绍
本文实验数据来自于CCKS 2019-CKBQA评测任务。该数据集包括3 000条左右来自开放领域和1 000条左右来自金融领域的问答数据,既包含简单问题,也包含复杂问题,它们的数量比例大致为1∶1。每条问答数据包含问句、答案和查询答案的SPARQL语句。表2给出了单条完整问答数据的示例,表3给出了数据集的具体统计数据。
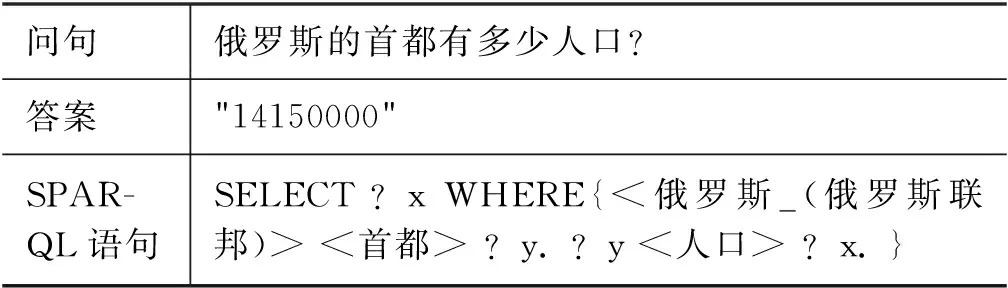
表2 一条问答数据示例

表3 数据集相关数据统计
问答系统须从给定知识库PKUBASE中选择若干实体或属性值作为该问题的答案。PKUBASE知识库包含三个文件:pkubase-triples包含知识库主要三元组,pkubase-types包含各实体的类别三元组,pkubase-mention2ent可以用来辅助进行实体链接,包含每个实体指向某个别名的优先级。
5.2 评价指标
问答系统整体性能以官方规定的平均F1值为最终评价指标。设Q为问题集合,Ai为系统对第i个问题给出的答案集合,Gi为第i个问题的标准答案,相关计算如式(5)~式(7)所示。
5.3 实验参数设置
问句分类模型线性层输出维度为4,语义相似度模型训练正负样本比例为1∶5,损失函数参数γ为0.1,初始化学习率均为0.000 1,优化器均使用Adam[23]优化器,连续10次迭代性能不提升训练阶段将提前停止。
5.4 路径选择方法结果与分析
本节对比了基于分类和基于集束搜索进行剪枝的路径选择方法对应的系统整体性能,并分析了负例动态采样训练方法和BERT模型结构的影响。
为了对比基于集束搜索的方法和基于分类的方法,本文对前者方案中束宽不同取值进行了实验。系统整体效率与数据集问句平均候选路径数正相关,系统单句的处理速度与数据集单句候选路径数正相关。表4中的结果表明,束宽k会影响系统性能。当选择合适的束宽(如15)时,基于集束搜索方案能达到与基于分类方案相当的性能,同时系统的整体效率也相当;当束宽较小(如2、5)时,基于集束搜索的方法性能下降1%~2%,不过系统的整体效率有显著的提高;从最坏情况系统单句处理效率来看,基于集束搜索方案对单句的处理效率总是远优于基于问句分类方案,束宽越小,单句处理效率越高。

表4 路径剪枝方法结果对比
表5展示了问句端和路径端BERT结构的影响。从表中可以看出,在两类系统中,共享BERT编码在相似度模型上的性能均优于独立BERT编码。当使用独立的BERT编码后,两类路径选择方法分别有0.53%和0.86%的性能下降。本文认为:尽管路径的组成形式不同于问句,与三元组更相似,但与问句相关度更大的路径,共享编码器能得到更相近的表示。
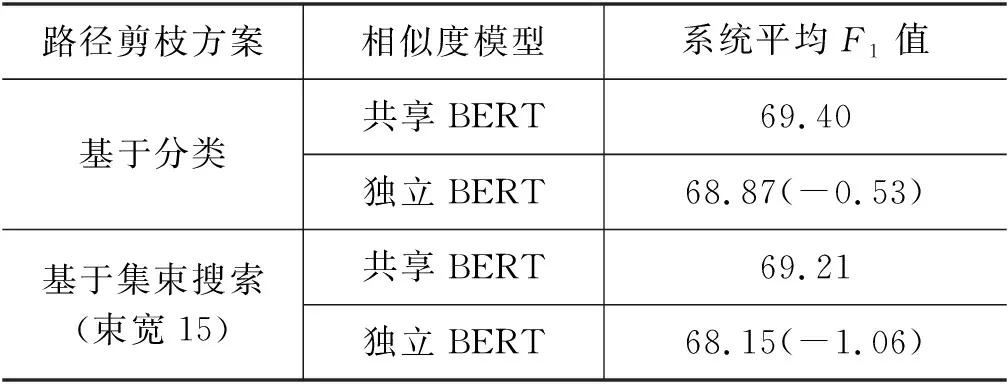
表5 负例动态采样下的独立和共享BERT编码
表6展示了负例动态采样的效果。不使用负例动态采样方法后,整个问答系统的性能明显下降。负例动态采样方法在不影响训练速度的情况下,丰富了训练集中关系的多样性,缓解了测试集中存在大量未见的关系的问题,提高了语义相似度模型的性能,在基于分类和基于集束搜索的路径选择方法中分别提升了2.03%和2.73%。在基于集束搜索的方法上提升更多,是因为该方法多次使用语义相似度模型来搜索路径。

表6 独立BERT下的负例动态采样
5.5 系统融合性能
本节将本文系统性能与CCKS2019-CKBQA评测最终成绩进行了比较,结果如表7所示。
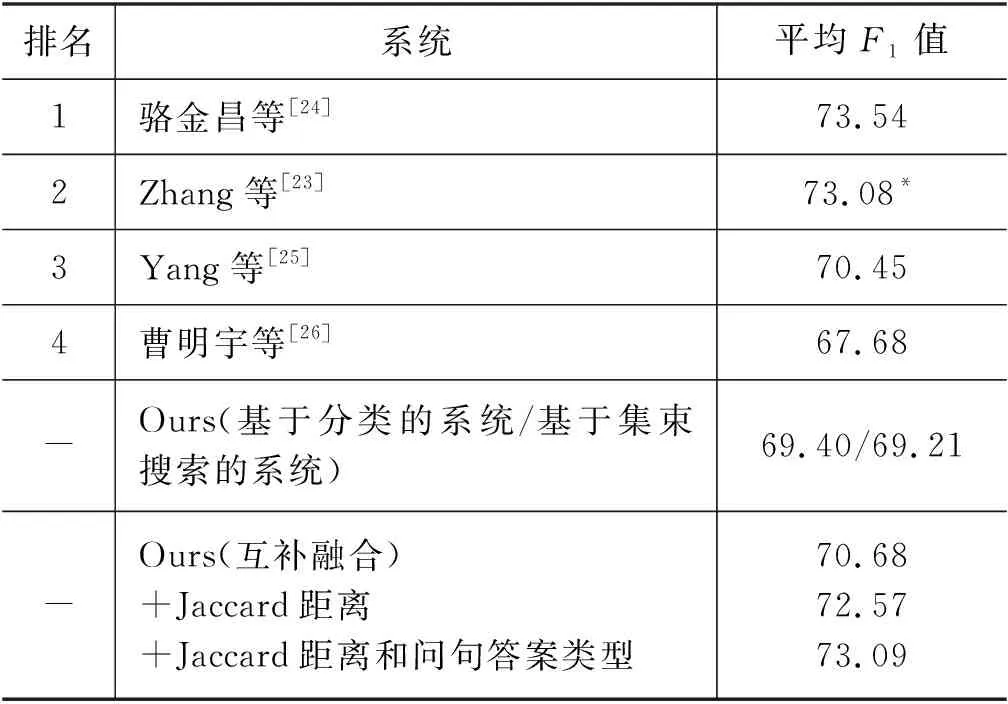
表7 不同系统性能对比
骆金昌等[24]在路径选择时融合了多个模型,定义了多达39个特征,主要包括路径与问题的字面匹配、路径与问题的语义匹配(包括BERT语义匹配)、答案类型、实体链接的概率和候选路径自身的特征,采用传统的learn-to-rank模型对路径进行排序。大量的人工特征和多模型融合对整个系统性能有了巨大的提升,但也降低了系统的效率。
Zhang等[23]利用NLPCC数据,采用规则和模型融合等方式实现了三个子系统,最后对每个子系统输出的路径和答案进行融合得到最后的答案。经模型融合和数据增强的单系统最佳性能F1达到69.41,系统融合将三个系统优势互补,最终性能得到显著提升。不过,大量的人工规则与三个子系统使得整个系统十分繁冗。
Yang等[25]直接使用了百度云和Paddle-Paddle平台开放的模型进行实体识别,并就金融类问题专门搜集了该领域词典提升实体识别效果,定义了包括BERT语义相似度模型等多个特征完成关系识别,最后根据设定的多个规则优化答案选择。直接引入外部模型进行实体识别的方法巧妙利用了外部数据,却也带来了很多噪声,人工搜集的特定领域词典针对性强,但泛化程度低。
曹明宇等[26]训练了实体识别模型识别实体提及,定义了多个特征完成实体链接后,在路径搜索时使用了桥接操作,并训练了基于序列对分类结构的路径排序模型进行路径选择。
本文仅考虑了两跳范围的路径,路径选择模型未考虑任何额外数据及人工规则。两个无人工特征、单模型的系统均达到了Zhang等[23]最优的单系统性能,均可位列第四。为了进一步提高系统的性能,本文继续采用了系统融合的策略,将两种路径选择方法得到的结果进行系统融合。
互补融合两个系统各自存在无法回答的问题,简单的互补融合使最终系统性能F1达到70.68。
Jaccard距离使用问句与路径之间的Jaccard距离作为特征,系统融合性能F1提升到72.57。
答案类型搜索知识库中实体的类型,继续加上答案类型特征后,系统性能F1达到了73.09。
最终,系统融合后的最终结果性能可以位列第二。
6 总结与展望
本文探究了中文知识库问答路径选择中的负例采样和路径爆炸的问题,提出使用负例动态采样的方法训练语义相似度模型,并比较了基于分类和基于集束搜索的路径选择方法。实验结果表明,负例动态采样的训练方式能显著提升语义相似度模型的性能;基于分类的路径选择方法类性能稍优,基于集束搜索的方法拥有更高的效率,但需要根据不同数据集调整集束束宽。与评测结果相比,无人工特征、单模型的系统的性能位列第四,使用了两个关键特征进行系统融合后,最终系统性能可以位列第二。
本文的问答系统仍存在一些局限性,一些需要常识进行推理的问题仍然存在挑战,例如,通过<姚明><女儿><姚沁蕾>推理得到<姚沁蕾><父亲><姚明>需要额外的亲属关系的常识等外部知识。未来的工作中,我们将探究上述更加复杂的问题的解决方法。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
中国外汇(2019年18期)2019-11-25 01:41:54
制造技术与机床(2019年6期)2019-06-25 10:17:46
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国交通信息化(2016年9期)2016-06-06 07:42:23
现代语文(2016年21期)2016-05-25 13:13:44
图书馆研究(2015年5期)2015-12-07 04:05:48
大连民族大学学报(2015年2期)2015-02-27 08:28:11
