
基于语言模型的预训练技术研究综述
2021-10-19 09:22岳增营刘睿珩
中文信息学报 2021年9期
岳增营,叶 霞,刘睿珩
(火箭军工程大学 作战保障学院,陕西 西安 710025)
0 引言
自然语言处理(Natural Language Processing,NLP)先后经历了语法规则语言模型、统计语言模型和神经网络语言模型。发展至今,语言表示学习成为驱动NLP发展的一个重要因素。基于知识库规则的语言表示是人工归纳出的自然语言的语法规则,它来源于人类掌握的语言学知识和领域知识,在计算机初始阶段,随着编程语言的发展而出现。然而,由于自然语言本身的多样性,基于知识库规则的语言表示学习不可持续。
N元模型(N-gram)的出现利用了较大的语料库,标志着统计语言模型(Statistical Language Model,SLM)的建立,其基本原理是利用前N个词预测下一个词,对于不可见的N-grams,采用平滑操作处理。然而,N-gram模型有三个缺陷,一是只能建模邻近的前N个词,忽略了长距离词语之间的依赖关系;二是无法建模词之间的相似性;三是维度灾难,大大制约了通用语言模型在大规模语料库上的建模能力,尤其对离散空间中的联合分布建模时,这个问题尤为突出。
基于独立同分布假设的词袋模型(Bag of Words,BOW),基于局部与整体假设的词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)表示以及基于奇异值分解的潜在语义分析 (Latent Semantic Analysis,LSA)模型,都推动了统计语言模型的发展,但是这些方法无法解决维度灾难[1]和数据稀疏带来的零概率问题。
NNLM(Neural Net Language Model)[2]的提出标志着使用神经网络进行语言建模的开始,Word2Vec[3]、GloVe[4]对其进行了简化,实现了符号空间到向量空间的映射,标志着静态词嵌入(Word Embedding)的诞生,使得在NLP领域大规模使用神经网络方法成为可能。
然而,静态词嵌入是词与向量的静态对应关系,无法满足下游任务对上下文信息和长距离依赖的需求。与静态词嵌入不同,上下文嵌入超越了词级语义,每个标注都与表示形式相关联,该表示形式是整个输入序列的函数,这些依赖于上下文表示的形式可以捕获多种语言上下文词的语法和语义属性。
神经网络方法一般先对模型参数进行随机初始化,然后利用反向传播、梯度下降等优化算法对模型参数进行训练。预训练技术出现之前,基于神经网络的深度学习在NLP领域的应用面临以下问题:首先,此时的深度学习模型不够复杂,简单地堆叠神经网络层并不能带来更多性能提升;其次,数据驱动的深度学习模型缺少大规模的标注数据,人工标注代价太高,难以驱动复杂模型。因此,基于知识增强、迁移学习和多任务学习的预训练技术逐步被更多学者重视。
预训练的核心思想是:放弃模型的随机初始化,先用大语料库对模型进行预训练,得到蕴含上下文信息的通用语言表示,然后对相应的下游任务进行微调。预训练技术可以获得更加通用的信息,并且用这些蕴含更加通用信息的语言表示初始化下游任务,不仅可以获得更好的性能,还可以加速下游任务训练。此外,可以将预训练视为一种正则化,以避免对小样本数据过拟合。
上下文嵌入的预训练技术从预训练任务的角度可以分为监督学习、无监督学习和自监督学习。监督学习主要利用带标签数据进行可迁移的语言表示学习,其中机器翻译具有丰富的平行语料对,是最主要的监督学习预训练任务;无监督学习主要是通过语言模型任务对语言进行密度估计,语言模型不需要标注数据,理论上可以获得无限大的数据规模;自监督学习可以利用标注数据,但是不依赖标注数据,通过人为构造训练任务,以无监督的方式进行监督学习,获得数据中的可泛化知识,掩码语言模型(Masked Language Model,MLM)是应用最广泛的自监督学习预训练任务。
计算机性能不断提升,GPT、BERT、XLNet等一系列基于大语料库预训练技术的语言模型的提出,奠定了预训练和微调两段式模型的主流地位,预训练技术出现了飞跃发展。
1 基于静态词嵌入预训练技术
独热编码(One-hot)存在数据稀疏和维度灾难问题,词语之间两两正交,缺乏相关性,余弦相似度为零。为了解决这些问题,研究者将词均匀嵌入稠密的向量空间,提出了词嵌入的概念。
1.1 基于本地上下文窗口的词嵌入预训练技术
2003年Bengio等[2]结合了基于马尔可夫假设的语言模型和神经网络结构,提出了NNLM模型。该模型采用线性投影层(One-hot编码乘权重矩阵W)和非线性隐藏层的前馈神经网络共同学习词嵌入和统计语言模型。
NNLM包含一个输入层、一个嵌入层、一个全连接层(隐藏层)、一个输出层,可分为特征映射和计算条件概率分布两部分。模型的训练输入数据是词序列(wt-1wt-2…wt-n+1)⊆V,词wt是标签,V是语料库,Vi是语料库中第i个词,通过前n-1个词来预测第n个词的出现概率。
输入序列中每个词用One-hot编码表示成一个V×(n-1)维的稀疏矩阵,然后与词嵌入矩阵C∈RV×m(C的每一行对应一个词嵌入)相乘,通过输入的每个词的One-hot编码在C中查找对应的词嵌入,C(wi)∈Rm是语料库中第i个词对应的特征向量,m是特征向量的维度。然后将C(wt-n+1),…,C(wt-1)首尾相连成一个(n-1)m维的向量:(C(wt-n+1),…,C(wt-1)),并映射到隐藏层W(h×(n-1)m)。

(1)
其中,T是一段文本,对每个位置t的预测计算似然估计, 反向传播最小化C(θ),R(θ)是正则化项,θ是模型参数。
Word2Vec[3]包含两种训练模式,CBOW和Skip-gram,其本质是对NNLM模型的优化。CBOW是用目标词的上下文来预测目标词,输入是目标词固定窗口的上下文对应的One-hot编码,然后与权重矩阵WV×N相乘(V是语料库中词的数量,N是中间层的节点数),在矩阵WV×N中只有该词对应的One-hot编码中为1的位置的权重被激活,这个权重向量就是当前词对应的词嵌入。Skip-gram原理相同,只是输入与输出相反,利用目标词预测固定窗口的上下文。
为了简化计算,Word2Vec在嵌入层对输入的所有词嵌入相加求和取平均,而不是首尾相接,放弃了前馈神经网络中非线性的隐藏层,直接将中间的嵌入层与Softmax层相连。
语料库中的V个词计算相似度并归一化是极其耗时的,Word2Vec采用层次Softmax,利用霍夫曼树代替从中间层到Softmax层的映射,将V分类的问题转化成了log2V次的二分类问题,并且高频词会靠近根节点,符合贪心优化思想;引入负采样算法,在Softmax层中,输出是N维的向量C,每个分量Ci表示预测为第i个词的概率,选择概率最大的词作为当前的输出值,按照一定的概率分布抽取K个负样本,将一个V分类问题变成了K+1个二分类问题。
Facebook于2017年提出了FastText模型[5],该模型融合了词的形态,结合以字符为粒度的N-gram,可以快速在大型语料库上训练词嵌入。
FastText最大的创新点在于将词拆成子词(Subword),在词的开头和结尾添加边界符号“<”和“>”,从而可以将前缀和后缀与其他字符序列区分开,加上词本身,组成N-gram字符袋。以“where”为例,N取3,字符袋表示为:
基于本地上下文窗口方法产生的词向量,缺乏整体的词与词之间的关系,并且直接训练Skip-gram类型的方法,容易导致高曝光的词得到更大的权值。
1.2 融合全局上下文信息的词嵌入预训练技术
GloVe[4]模型通过融合全局矩阵分解和局部上下文窗口的优点,生成具有语义结构的词向量空间,是一种全局对数双线性回归模型。
该模型首先基于语料库中词频统计信息构建词的共现矩阵X,其元素为Xi,j(在语料库中词i和j共同出现在同一窗口中的次数)。Peningto等[4]通过统计信息发现词嵌入矩阵与共现矩阵具有良好的一致性,然后利用两个词嵌入的内积去逼近共现频次的对数,构造了代价函数,如式(2)所示。
(2)

GloVe综合了LSA、CBOW的优点,训练更快,能够捕捉词之间的语义特征,对于大规模语料具有良好的扩展性,并应用到了命名实体识别、情感分类、错误稽查[6]等任务,获得了不错的表现。但是该模型不具有良好的鲁棒性,每新增一份语料,稳定性就会变化。
WordRank[7]把词嵌入定义成一个排序问题,其核心思想是:输入目标词,输出该词的上下文列表,要求在列表中与输入词共现频率越高的上下文词排名越靠前。WordRank原理与GloVe相似,目标词和上下文的相关性越大,其内积就越大,差别在于GloVe利用共现矩阵表示目标词和上下文的相关性,而WordRank利用有序上下文词列表来表示。WordRank更适合语义类比的任务,但是无法解决OOV问题,而且在低频词和高频词上准确率较低。
1.3 基于静态词嵌入预训练技术的缺点
以Word2Vec为代表的静态词嵌入预训练技术尽管可以捕获词的语义特征,但其与上下文无关,无法有效表示更高级的特征,如词义排歧、语义角色等。当静态词嵌入用于下游任务时,仍然需要从零学习上下文信息,无法解决多义词等问题。
词嵌入预训练技术的出现开启了NLP领域中迁移学习[8]的时代,结合知识增强、多任务学习,催生出以BERT为代表的更深层次的上下文嵌入预训练技术。
2 上下文嵌入预训练技术
在Transformer[9]问世之前,NLP领域的学者在其他语言表示学习方法研究上做了大量工作,包括卷积神经网络(CNN)、递归神经网络(Recursive Neural Network)、循环神经网络(Recurrent Neural Network)[10]、强化学习以及将深度学习模型与记忆增强策略相结合,Young等[11]对此期间的大量工作做了详细的总结。
Transformer利用一种前馈全连接神经网络架构,使用多头自注意力机制,结合位置编码、层归一化、残差连接和非线性变换,构建了编码器-解码器结构。给定输入序列,首先进行融合位置编码的词嵌入映射,然后将词嵌入输入多层 Transformer 网络,通过自注意力(self-attention)机制来学习上下文间的依赖,再通过前馈神经网络经过非线性变化,输出综合了上下文特征的上下文嵌入。每一层Transformer网络主要由多头自注意力机制(Multi-head self-attention)层和前馈网络层构成。多头自注意力机制并行执行多个不同参数的自注意力机制,并将其结果拼接输入到前馈网络层以计算非线性层次的特征。各层中使用残差连接(Residual Connection)把自注意力机制前或者前馈神经网络前的向量引入,以增强输出结果,并且还通过层归一化把同层的各个节点的多维向量映射到一个区间。这两个操作有利于更加平滑地训练深层次网络,其中编码器模块能够对未标记的文本进行双向表示,而解码器模块在整个输入序列的顶部使用了掩码机制,可进行单向语言建模。
Transformer具有易于并行、能够获取长距离依赖、综合特征提取能力强的特点,性能全面超过CNN和RNN特征提取器,并且实验证明,Transformer具有一定的多语言特征提取能力[12]。
2.1 基于自回归语言模型的预训练技术
自回归(Autoregressive,AR)语言模型[13]是一种前馈模型,其结构如图1所示,可以根据上文或下文内容预测当前词。因此,自回归语言模型只能利用单向语义而不能同时利用上下文信息。自回归语言模型能够天然拟合生成类NLP任务,如文本摘要、机器翻译等。当前主流的AR语言模型多采用Transformer解码器作为特征提取器,如GPT系列。

图1 AR语言模型结构图
2.1.1 基于双向自回归语言模型的预训练技术
ELMo[14]提出一种解决一词多义问题的方法,先学习静态词嵌入,然后在上下文中动态地调整。
ELMo基于大语料库,以长短时记忆网络(Long Short-Term Memory,LSTM)为基础架构,受启发于计算机视觉(CV)领域的层次表示,构造了双层双向LSTM结构,如图2所示。其训练过程为(以正向网络为例):第一步,利用 CNN与LSTM相结合的词嵌入模型[15]将输入词tk映射到词嵌入vk,;第二步,将上一时刻的输出hk-1及词嵌入vk传入LSTM网络,得到这一时刻的输出hk;第三步,将hk与矩阵W相乘后输入Softmax层进行归一化,最终得到概率分布。该模型的训练目标就是最大化这两个方向LSTM语言模型的对数似然函数,如式(3)所示。
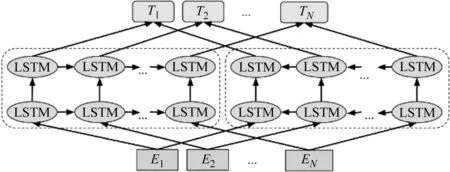
图2 ELMo结构图
(3)

ELMo利用大量语料库进行预训练后的网络具有层次表示的特性,最底层是静态词嵌入,第一层双向LSTM主要提取句法信息,第二层双向LSTM主要提取语义信息。ELMo的预训练不仅得到上下文嵌入矩阵,还获得一个双层双向的LSTM网络结构,能够同时提取词的语义和句法信息,解决了同义词问题。从目标函数中可以看出,ELMo的双向特征提取器是两个单向LSTM的简单拼接。
2.1.2 基于单向自回归语言模型的预训练技术
Howard等[16]论证了迁移学习在NLP领域的可行性,并证明,无论是在CV领域还是在NLP领域,预训练模型的底层特征具有可复用性,高层特征具有和任务的高相关性,并依据这一原理提出了通用语言模型微调方法(ULMFiT),旨在解决传统的微调方法存在易过拟合、训练时间长、灾难性遗忘等问题。
OpenAI 团队在ULMFiT的基础上,采用了Transformer[9]特征提取器,提出了GPT-1[17],该模型具有更强的语言生成能力,能够学习文本的长距离依赖问题。GPT-1通过无标签语料库预训练,经过简单的微调就能应用在各种下游任务中,并且不需要下游任务和预训练的语料库在同一领域。对于无标签语料库U=(u1,…,un),训练目标是最大化似然函数,如式(4)所示。
(4)
其中,k是输入窗口的大小,Θ是超参数。
GPT-1由12层Transformer解码器组成,其内置的掩码多头自注意力机制能够同时提取文本多方面的信息,并且能够自动掩盖当前词后面的序列,保证模型从左至右提取信息。训练时,输入前k-1个词的词嵌入和绝对位置向量,经过Transformer解码器,再通过全连接输入到Softmax层,输出词的概率分布,预测第k个词。
得益于自回归语言模型天然拟合生成类NLP任务的特点,Transformer的优异表征能力,以及更加通用的迁移学习微调方法,GPT-1在11项NLP任务中有9项获得了SOTA的成绩,甚至通过预训练,可以实现一些零样本[18]任务,但是训练速度较慢。
OpenAI团队认为语言模型的规模对于零样本任务的迁移学习至关重要,增加语言模型的规模能够提高模型跨任务学习的能力,提出了GPT-2[19]。该模型旨在通过海量网络文本数据和大模型训练出一个通用的语言模型,无须标注数据也能解决具体问题。
GPT-2与GPT-1一脉相承,仍然由Transformer解码器组成,只做了局部修改:归一化层移到了Transformer解码器模块的输入位置;在最后一个多头自注意力机制模块之后增加归一化层。GPT-2采用数量更大、质量更高、范围更广的网络文本,通过数据清洗进一步提升数据质量,训练出参数规模更大、更通用的预训练模型,然后无监督地做下游任务。
GPT-2针对零样本任务,实现了部分训练集到测试集的映射,从而实现从已知领域到未知领域的迁移学习。GPT-2在零样本以及长文本任务中都表现优异,能够生成连贯的文本段落,在许多语言建模基准上取得了SOTA的成绩。GPT-2堆叠了48层Transformer解码器模块,15亿参数,利用40 GB高质量的网络文本进行预训练,模型仍未完全拟合,如果提供更多质量更好的数据,该模型仍有提升的潜力。
为了解决当前主流预训练语言模型过分依赖领域内有标签数据,以及对于领域数据分布的过拟合问题,OpenAI 团队提出了GPT-3[19],该模型的主要目的是用更少的领域数据,无须进行任何额外的梯度更新或微调,完全只通过模型与文本的交互,即可直接应用于特定任务与少样本任务。
与GPT-2的区别在于GPT-3受稀疏Transformer[20]的启发,在Transformer的各层上都使用了交替密集和局部带状稀疏的注意力模式,实现了加速训练的目的,并且把模型参数规模增加到1 750亿,预训练数据集增加到45 TB。
OpenAI 团队重点研究了在零样本、单样本 和少样本三种不同的设定下GPT-3的表现,并特别强调了在少样本设定下,在部分自然语言理解任务上表现优异。实验中,人类评估人员对GPT-3生成的新闻检测准确率仅为12%,GPT-3还可以做语法纠错、语言建模、补全、问答、翻译、常识推理、SuperGLUE等任务,甚至可以做二位数加减法任务。
2.2 基于自编码语言模型的预训练技术
基于自编码(Autoencoder ,AE)语言模型的预训练技术不会进行显式的概率估计,而是从加入噪声的输入序列重建原始数据[13]。AE语言模型能够很好地编码上下文信息,其结构如图3所示,在自然语言理解相关的下游任务上表现突出,但是自编码语言模型没有很好地利用时序和位置信息,在生成类NLP任务中表现一般。

图3 AE语言模型结构图
BERT[21]是谷歌2018年提出的基于Transformer编码器的降噪自编码(DAE)[22]语言模型,Transformer的编码器负责接收文本作为输入,不负责预测,其创新点主要在预训练方法上。BERT借鉴了Word2Vec、ELMo、GPT-1、Transformer等的思想,是现有技术的综合体。
文献[21]中使用了两种BERT模型,BERTbase堆叠了12层Transformer编码器模块,参数规模为1.1亿,BERTlarge堆叠了24层Transformer编码器模块,参数规模为3.4亿。层之间采用残差连接,并使用批次归一化操作。
输入层,BERT采用词嵌入、段嵌入和位置嵌入相加的方式。具体地,使用WordPiece[23]算法处理词表,再对处理后的词表进行768维的词嵌入,位置嵌入最大支持512位输入序列,[CLS]作为每句话的第一个标签,可以用于下游的分类任务,当输入句子对时,用标签[SEP]将两个句子隔开,对于单个句子,仅使用一个段嵌入。
预训练任务包括掩码语言模型(MLM)和下一句预测(NSP)。MLM类似于完形填空,在将词序列输入BERT之前,随机选择15%的词被标签[MASK]替换。然后模型尝试基于序列中其他未被掩盖的词来预测被掩盖的词。替换策略为:10%的时间被选中的词会被随机词替换,10%的时间不变,80%的时间被替换为标签[MASK],以避免模型将[MASK]记为被替换的词。
NSP任务的主要目的是更好地理解两个句子的关系,以适应问答、自然语言推理等任务。在预训练期间,50% 的输入句子对在原始文档中是前后关系,另50%在语料库中随机选择。将句子对输入模型前,在第一个句子的开头插入标签[CLS],在每个句子的末尾插入标签[SEP]。整个序列输入BERT模型后,用一个简单的分类层将 [CLS] 标记的输出映射到2×1维的向量,用Softmax计算句子对是前后关系的概率。采用多任务学习思想,MLM和NSP任务一同训练,最小化两种任务的组合损失函数。
BERT在11种NLP任务上获得了SOTA的结果,尤其在自然语言理解类任务上表现得更为优异,是一项里程碑式的工作。
2.3 基于序列到序列语言模型的预训练技术
基于序列到序列(Seq2Seq)语言模型的预训练技术使用原始的Transformer特征提取器,是典型的编码器-解码器结构,用于翻译任务或将其他任务转换为Seq2Seq问题。编码侧采用Transformer编码器模块组成AE语言模型结构,任意两个单词两两可见,以更充分地编码输入序列;解码器端,使用Transformer解码器模块组成AR语言模型结构,从左到右逐个生成单词。其模型结构如图4所示。

图4 Seq2Seq语言模型结构图
MASS[24]是微软提出的屏蔽Seq2Seq预训练模型,是BERT和GPT的综合, MASS本质上是将BERT整合到Seq2Seq框架上,其预训练阶段使用了编码器-注意力-解码器的Seq2Seq框架,旨在解决自然语言生成任务。
MASS的预训练阶段,在编码器的输入中屏蔽连续的k个词,迫使编码器从未屏蔽的词中尽量多地提取信息,并在解码器端利用这些信息预测被屏蔽的k个词,以提高解码器的语言建模能力;解码器端只输入前k-1个被屏蔽词,保留所有词的绝对位置信息,以迫使解码器从编码器端提取信息来预测连续片段,促进编码器-注意力-解码器结构的联合训练。
MASS通过调整超参数k(屏蔽的连续词的长度)的大小,可以将自己的预训练方法调整为MLM或者语言模型(LM)。当k=1时,编码器端屏蔽一个词,解码器端预测一个词,解码器端没有任何输入,此时,MASS的预训练方法为MLM;当k=m(m为输入序列的长度)时,编码器被屏蔽,所有词输入解码器并预测所有词,此时,MASS的预训练方法为LM。
MASS在自然语言生成任务上取得了显著提升,并且引入了跨语言模型,特别是在英语-法语和英语-德语的神经机器翻译数据集上取得了SOTA的成绩,但是其性能并没有显著增长,可能是因为模型和训练数据规模较小。
2.4 基于前缀语言模型的预训练技术
前缀语言模型(Prefix LM)本质上是Seq2Seq模型的变体,标准的Seq2Seq模型,编码器和解码器各自使用一个独立的Transformer;而Prefix LM,编码器和解码器通过分割的方式共享一个Transformer结构,这种分割占用是通过在Transformer内部的注意力掩码机制来实现的。Prefix LM编码器侧采用AE语言模型结构,解码器侧采用AR语言模型结构。以UniLM为例,模型结构如图5所示。

图5 UniLM的前缀语言模型结构图
UniLM[25]是微软在BERT的基础上提出的统一预训练语言模型,并在文章中首次应用了Prefix LM,它集合了AR语言模型和AE语言模型的优点,能够同时完成单向、双向和Seq2Seq语言模型三种预训练任务,在自然语言理解和自然语言生成任务上都表现出色。
数据处理电路由单片机U1(PIC18F25K80)、电阻 R28、电阻 R1、电阻 R5、电容 C1~C3、电容 C10、晶振Y1、LED灯L2、接线端子J1等构成.将外部+24 V直流电源通过稳压电路单元接入接线端子J2的一端,接线端子J2另一端与电源芯片MC7805和MC7815相连,MC7805将24V电源转化为+5 V,MC7815将24 V电源转化为+15 V;+5 V直流电源用于为单片机和电流霍尔传感器供电,+15 V直流电源用于为电压霍尔传感器供电,而电源部分为通用电路.
模型直接复用BERT的网络结构,每一层通过掩码矩阵M来控制每个词的注意力范围,0表示关注,负无穷表示被掩盖,直接采用BERTlarge的参数初始化。采取混合训练方式,同一个批次内,1/3的时间采用双向语言模型训练任务,1/3的时间采用Seq2Seq语言模型训练任务,1/3的时间平均分配给前向和后向语言模型训练任务。掩码方式与BERT基本相同,只做了很小改进,80%的时间只掩盖一个词,20%的时间掩盖二元文法(Bigram)或者三元文法(Trigram)。
UniLM巧妙地利用三个掩码矩阵实现了三种预训练任务的统一:单向语言模型训练任务,被掩盖词的上文或者下文是其单侧的词序列,利用掩码矩阵M,将不可见的词在M中对应位置的值置为负无穷;双向语言模型训练任务,被掩盖词的上下文是左右两侧的词序列,将M的值都置为0;Seq2Seq语言模型训练任务,预测的是目标序列,其上下文是所有的源序列和其左侧已预测的子目标序列。训练时,源序列和目标序列的词都会被随机替换为[MASK],在预测[MASK]的同时,输入的语句对被打包在一起,因此模型可以提取语句之间存在的依赖关系。
UniLM可以同时处理自然语言理解和自然语言生成任务,在GLUE上首次不加外部数据超越了BERT,后续的改进可以考虑加入跨语言任务的预训练。
谷歌在2019年提出了一种探索迁移学习边界的模型T5[26],其核心思想是对NLP任务建模,将所有预训练任务构造成异步的Seq2Seq模型,对每个任务使用相同模型、目标函数、训练流程和解码步骤,可以比较不同迁移学习目标、未标记数据集和其他因素的有效性,同时可以通过扩展模型和数据集探索迁移学习的边界。
为了实现在多个任务上的输入输出格式的统一,T5在原始输入序列上增加任务专用前缀,例如将“That is good.”翻译成德语,输入序列为:“Translate English to German: That is good.”
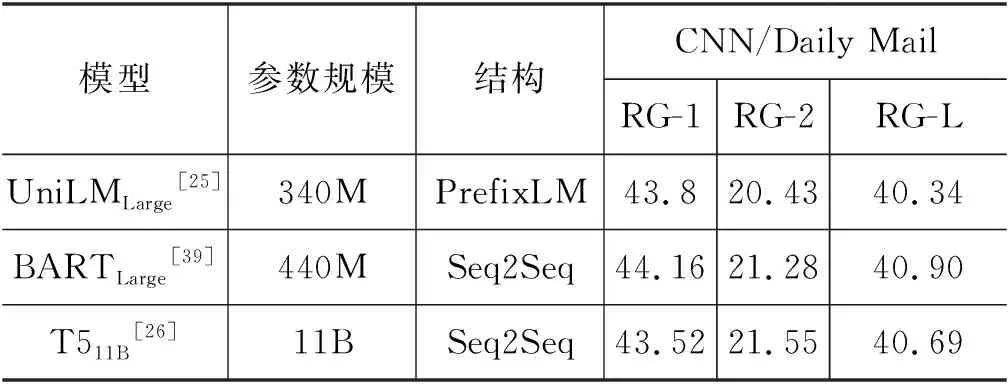
T5主体框架采用原始的Transformer模型[9],对比了三种网络架构(Seq2Seq结构、LM结构、Prefix LM结构),这三种网络架构对应三种注意力掩码机制(全视野掩码、因果掩码、前缀因果掩码),全视野掩码机制是Transformer编码器的掩码机制,因果掩码机制是Transformer解码器的掩码机制,前缀因果掩码机制是前两者的结合,前半段是全视野掩码机制,后半段是因果掩码机制。在自监督的预训练方法方面,重点比较了LM、DAE、顺序还原三种。参考了SpanBERT[27],对比不同加入噪声的方式:MLM[21];小段替换法[24],类似于MASS的序列屏蔽;丢弃法,随机丢弃一些字符。通过实验发现,Seq2Seq结构配合DAE预训练方法,采用段长为3的小段替换掩码方法,达到了最好效果。微调阶段参考了MT-DNN[28],利用GLUE和super-GLUE任务,进行多任务微调,充分利用有监督数据,缓解了过拟合。1 100亿参数规模的T5,在GLUE上取得了SOTA的成绩。
2.5 基于排列语言模型的预训练技术
BERT主要存在两个问题:预训练阶段引入了[MASK]标签,导致预训练和微调两个阶段训练信息不一致;BERT在预训练阶段的MLM任务是建立在被掩盖的词之间是相互独立的假设之上,与现实有差距[13]。
XLNet[13]的主要创新点在于采用了PLM、双流自注意力机制和Transformer-XL[29]特征提取器。
受Uria等[30]的启发,Yang等[13]设计了PLM,目的是在保留AR语言模型的优点的同时捕获双向上下文信息。假设输入序列(xaxbxcxd), 根据AR语言模型,若要预测xc,只能利用xaxb的信息,而在PLM中,对输入序列做全排列,则有4!种排列可能,再选择一部分作为预训练的输入,表面上仍是从左到右的AR语言模型,但是通过排列组合,把一部分下文排到被预测词的上文位置,就可以同时利用上下文信息。对于长度为T的输入序列ZT,PLM的目标是最大化似然函数,如式(5)所示。
(5)
其中,z是该序列排列组合的一种排列方法,zt表示z的第t个词,z 实际上,PLM并不会改变原始序列的物理位置,而是使用与原始序列相对应的位置编码,依靠注意力掩码机制实现不同的排列组合方法,具体的实现方法必须依靠双流自注意力机制。 为了解决位置不确定性(在不同位置的同一个词有相同的模型预测结果)问题,Yang等设计了双流自注意力机制。双流是内容信息流(Centent Stream)和位置信息流(Query Stream)。排列组合后的输入序列位置信息非常重要,对每个位置,为了预测内容信息,必须输入其位置信息,但是不能包含内容本身的信息,否则模型只需要直接从输入复制到输出即可,无法学习有用特征,但是为了预测下文内容,又必须包含内容信息。因此Yang等在类似于BERT的位置信息加内容信息输入的内容信息流之外,增加了只有位置信息的位置信息流。利用位置信息流就能对需要预测的位置进行预测,而不会泄露当前位置的内容信息。 Transformer-XL[29]特征提取器是Transformer的改进模型,主要进行了两个方面的改进:段循环状态重用和相对位置编码。在训练期间,前一段的隐状态将被固定并缓存,在模型处理新段时将其复用。这种缓存预定长度为M的跨越多个段的旧隐藏状态,并和相对位置编码一起应用机制,增强了模型对长距离依赖的提取能力。Transformer-XL仅在隐状态下对相对位置信息进行编码,以相对方式定义时间偏差,通过将相对距离动态地注入到注意力分数中,查询(Query)[9]向量可以将不同段同一位置的词表征有效区分,从而使状态重用机制可行。 XLNet凭借对上下文信息更加精细的建模和更大的数据规模,在自然语言理解类任务中性能大幅超过BERT,尤其擅长长文本的阅读理解,并且在NLP领域打开了新的思路。 预训练技术几乎在所有的NLP任务中都获得了成功,成为了NLP领域的研究热点,很多学者做了大量的改进工作[31-32]。本节主要在精细调参、引入知识、改进训练方法、引入多任务学习四个方面介绍预训练技术的改进工作。 BERT在调参和消融研究方面并没有做太多工作, Open AI团队在BERT的基础上进行了更加精细的调参,提出了RoBERTa[33]模型。具体的:去除NSP训练任务,获得了更好的效果;动态改变掩码策略,把数据复制10份,然后统一进行随机掩码;对学习率的峰值和预热更新步数作出调整;不对输入序列进行截断,使用全长度序列;延长预训练时间,增加预训练步数;放大预训练的批次大小;采用字节对编码(Byte Pair Encoding,BPE),可以编码任何输入文本而不会引入[UNKOWN]标记。在消融研究中发现,更加充分的训练过程对模型性能提升效果最大,其次是数据规模的增加,可以说,RoBERTa是加强版本的BERT,为后续以BERT为基础的研究工作提供了更强的基准。 引入知识方面,预训练技术通常从通用大型文本语料库中自监督地学习通用语言表示,缺少特定领域的知识。设计辅助的预训练任务,将外部领域知识整合到预训练模型中被证明是有效的[31]。ERNIE 1.0[34]将实体向量与文本表示融合;ERNIE-THU[35]引入知识图谱中的多信息实体作为外部知识改善语言表征;LIBERT[36]通过附加的语言约束任务整合了语言知识;SenseBERT[37]使用英语词汇数据库WordNet作为标注参照系统,预测单词在语境中的实际含义,显著提升词汇消歧能力。 在改进训练方法方面,BERT wwm采用全词掩码机制;SpanBERT采用随机段掩码机制,去掉NSP任务;RoBERTa[33]采用动态掩码机制,去掉NSP任务,改进优化函数,提高了模型性能。 在引入多任务学习方面,多任务学习是指同时进行多个训练任务,且在训练中共享知识,利用多个任务之间的相关性来改进模型的性能和泛化能力。MT-DNN[28]在下游任务中引入多任务学习机制,用多个任务微调共享的文本编码层和任务特定层的参数;ERNIE 2.0[38]在预训练阶段引入多任务学习,与先验知识库进行交互,增量地引入词汇、语法、语义预训练任务。 从模型结构来看,目前的主流预训练技术大都采用Transformer作为特征提取器,从现阶段看,Transformer的潜力仍然没有被充分挖掘。预训练模型的知识,是通过Transformer在训练迭代中不断学习,并以模型参数的形式进行编码。怎么用Transformer搭建模型结构学习效率更高?这是一个主要问题。关于模型结构的分类以及代表模型,第2节中做了详细的分析介绍。 从模型效果来看,基于Seq2Seq的语言模型结构无论在语言理解类任务还是语言生成类任务中,都是效果最好的,并且能够将理解类任务和生成类任务统一在一个框架下,其缺点是计算量大。对于语言理解类任务,基于AE语言模型的结构相对而言效果较好,主要因为AR语言模型结构损失了下文信息;对于语言生成类任务,基于AR语言模型和Prefix LM的结构效果较好,主要因为其单向语言模型结构更符合自然语言的生成方式。具体实验数据如表1所示,其中SQuAD 1.1、MNLI为自然语言理解类任务, ELI 5、XSum、CNN/DM为自然语言生成类任务。 表1 AE、AR、PLM三种结构性能PPL对比 在对比实验中[26],在其他条件相同的情况下,Prefix LM结构效果弱于Seq2Seq语言模型结构,具体实验数据如表2所示,一方面因为两者参数规模差异巨大;另一方面与Prefix LM的结构有关。Seq2Seq模型的注意力机制是建立在编码器的最后输出上,这样可以获得更全面完整的全局整合信息;而Prefix LM的注意力机制是建立在编码器的对应层上,因为其编码器和解码器分割了同一个Transformer结构,注意力机制只能在对应层内的词之间进行,难以跨层。 表2 Seq2Seq与前缀语言模型结构ROUGE评分对比 预训练技术的成功,解决了高资源领域知识向低资源领域迁移的问题。理论上,预训练技术可以实现多语言之间的迁移学习。 Jawahar等[40]通过一系列实验探索了BERT的每一层捕捉了什么信息表征。实验证明:BERT 的低层网络学习到了短语级别的信息表征,中层网络学习到了句法信息特征,而高层网络则学习到了丰富的语义信息特征。 在此基础上,Pires等[12]深入探索了多语言的BERT(Multilingual BERT,mBERT)学到了哪些特征以及mBERT在零样本迁移学习上的表现。mBERT由12层的Transformer构成,语料库是包含了104种语言的维基百科文本数据,建立了一个包含所有目标语言的词汇表,并且在所有语言之间共享模型参数,预训练的任务仍然是MLM。其中每个样本都是一个单语段落,所有语言以多任务的方式交替训练。实验证明,mBERT拥有超过浅层词汇级别的深层次表征能力,并不过度依赖词汇重叠,在类型相似的不同语言文本上具有良好的泛化能力,但是在具有不同顺序特征的语言文本和音译文本上表现较差。mBERT没有经过明确的跨语言预训练就具有强大的多语言泛化能力,可以实现不同脚本语言之间的迁移学习和代码转换,但是为了有效迁移到不同类型语言文本和音译文本上,需要模型引进更多、更明确的多语言预训练任务。 在世界现存的语言中,某些语言之间存在平行语料。理论上,利用平行语料可以有监督地训练多语言预训练模型,提高模型的泛化能力。在mBERT的基础上,XLM(Cross-lingual Language Model)[41]增加翻译语言模型(Translation Language Model,TLM)预训练任务,将平行语料纳入多语言预训练任务中。在多语词表构建中,XLM不是简单地把各语言的BPE词表进行拼接,而是先对多语语料按照多项式分布采样,以保证语料平衡,然后拼接,最后进行BPE统计。Yang等[13]提出了三种预训练任务:因果语言模型(Causal Language Model,CLM)、MLM和TLM。CLM是无监督单语单向语言模型训练任务,MLM是无监督单语双向语言模型训练任务,TLM是有监督翻译语言模型训练任务,先拼接平行双语语料,然后再执行MLM,旨在学到平行语料的对齐信息。采用CLM、MLM相结合或者TLM、MLM相结合的预训练方式,当CLM与MLM结合使用时,使用64批次最大长度为256的连续句子流训练模型,每次迭代中,输入序列由来自相同语言的通过多项式分布采样的句子组成;当TLM与MLM结合使用时,TLM利用平行语料,将机器翻译语料中的双语句对拼接成新句子,然后进行MLM训练。XLM在跨语言自然语言推理(XNLI)、跨语言分类、无监督和有监督机器翻译方面达到了SOTA水准。 XLM只引进了一个多语言预训练任务,多语言表示学习性能仍显不足。Unicoder[42]在XLM 的基础上,进一步提出了跨语言词语恢复(Cross-lingual Word Recovery),跨语言同义句分类(Cross-lingual Paraphrase Classification)和跨语言MLM(Cross-lingual Masked Language Model)三个新的预训练任务,使模型更好地学习语言之间的对应关系。三个任务分别定义在词语、句子和段落级别,和TLM、MLM一起预训练,使模型从不同的层次学习多语言对应关系。 跨语言词语恢复任务与TLM相似,输入模型的是双语句对,模型首先对该句对中每个源语言-目标语言单词对计算注意力得分,然后将每个源语言单词表示为全部目标语言单词表示的加权和,最后基于新生成的源语言表示序列,恢复原始的源语言序列。跨语言同义句分类任务的输入是双语句对,训练目标是判定这两个句子是否互译,从而得到不同语言在句子层面的对应关系。跨语言MLM任务对多语言文档进行MLM训练,该文档相邻句子的语言不同,但仍保持通顺的承接关系,以此模糊语言之间的边界。 在微调方面,Unicoder提出了新的微调方案,将源语言训练数据通过机器翻译成伪目标语言训练数据,然后进行微调。Huang等[42]在XNLI和跨语言问答(XQA)两个任务上利用15种语言数据进行了预训练,性能超过了XLM和mBERT,并且发现,在微调中使用的语言越多,性能越好,即使是高资源语言也可以得到改进。 Open AI团队在XLM基础上提出了XLM-R[43]模型,对之前的模型进行了三方面的改进:第一,使用100种语言、2.5 TB文本数据以自监督的方式训练跨语言表示,为低资源语言生成新的未标记语料库;第二,在微调期间,利用多语言标记数据训练模型的多语言能力,以改进下游任务的性能;第三,调整了模型的参数,将整体模型容量增加到5.5亿。在训练和词汇构建过程中对低资源语言进行上采样,生成更大的共享词汇表,以抵消“多语言诅咒”(使用跨语言迁移将模型扩展到更多的语言时限制了模型理解每种语言的能力)。XLM-R在跨语言分类,序列标签和问答方面获得SOTA的结果,同时超过了BERT在单语言上的性能。 预训练技术庞大的参数规模降低了其易用性,在工业应用尤其是边缘计算中,模型压缩和加速训练技术显得尤为重要。 ALBERT[44]用SOP替换了NSP训练任务,并且从结构优化角度,提出了矩阵分解和权值共享两种压缩方法。矩阵分解是指将词嵌入矩阵分解为V×E和E×H两个矩阵,其中V是词汇表大小,E是词嵌入维度,H是隐藏层维度,即先将词投影到一个低维的词嵌入空间,再将其投影到高维的隐藏空间,大幅度减少了参数量;权值共享是指多个层使用相同的参数。ALBERT使用跨层权值共享方法,不同层的自注意力机制和前馈网络共享一套参数,压缩率为 1/N,N为总层数。除了在结构上的调整,ALBERT在训练深层网络时,先训练浅层网络,再进行微调,以此加快深层模型的收敛。ALBERT在各个自然语言理解任务上几乎都达到了SOTA的表现。但是,矩阵分解和参数共享都带来了模型性能的下降,所以ALBERT实际上并没有找到BERT真正的参数冗余,还需进一步研究。 知识蒸馏(Knowledge Distillation)旨在通过一些优化任务从大型、知识丰富的教师模型学习一个小型的学生模型,是常用的模型压缩方法。微软研究院为解决模型压缩的通用性问题,提出了一种深度自注意力知识蒸馏方法:MiniLM[45]。MiniLM的主要贡献体现在三方面:第一,对教师模型最后一层Transformer深度蒸馏,降低了教师模型和学生模型之间层映射的困难,使学生模型的层数更加灵活;第二,MiniLM在自注意力模块中,除了常规的Q和K点积之外,在V之间加入缩放点积操作,以作为一种新的深度自注意知识,也可以将不同维数的表征转换为相同维数的关系矩阵,而无须引入额外的参数来转换学生模型的表征,使学生模型可以使用任何维数的隐层;第三,引入助教助力蒸馏大型预训练模型,进一步提升深度自注意蒸馏的性能。在各种参数尺寸的学生模型中,MiniLM的单语模型优于各种最先进的基线。在 SQuAD 2.0和GLUE的多个任务上以一半的参数和计算量保持住99%的准确率。此外,将深度自注意力蒸馏方法应用到多语种预训练模型上也取得不错的结果。表3列举了部分主流的通用知识蒸馏方案。 表3 主流知识蒸馏方法及代表模型 结构化剪枝[49-50]方法通过在训练时随机丢弃神经元,预测时剪掉影响较小的层,完成模型的压缩。模型压缩方法还有量化[51]、模块替换等。 4.1.1 预训练技术的边界 一方面,目前预训练模型参数规模不断增加,从BERT的3.4亿参数,到图灵NLG[52]的170亿参数,尤其是GPT-3凭借1 750亿参数成为目前为止最大的NLP预训练模型,数据量超过45 TB,训练成本高达1 200万美元。海量的训练数据,庞大的参数规模,昂贵的算力,使预训练模型优化逐渐变成了资本战争,普通学者和小型科技公司在该方向已经很难超越。而且这种超大模型难以复现,使预训练技术失去了竞争性。当前预训练技术的发展受到了计算机算力的限制,这似乎预示着预训练技术已达到上界。 从另一方面看,大多数改进模型比不过在提升数据质量和数量的同时扩充模型容量带来的收益[33, 53],正如Richard S Sutton教授所说:“通用方法非常强大,这类方法会随着算力的增加而继续扩展,搜索和学习似乎正是两种以这种方式随意扩展的方法。”产业界有大规模的数据、算力、工程系统、架构等有一系列的优势,继续发挥这些优势探索预训练技术的边界是促进NLP领域发展最简单直接的方式,例如GPT-3的出现为NLP技术在产业中标准化落地提供了可能性,降低了NLP技术的使用门槛,有利于推进产业的智能化变革,并且BERT等模型的开源,也造福了整个NLP社区。从更深层次看,当前面临的算力不足问题也促进了学术界对深度学习的可解释性研究,同时催生出混合精度训练、三维并行训练、稀疏注意力加速等应用价值很高的大规模预训练优化技术。产业界可以解决工程性问题和应用问题,而学术界可以解决算法以及模型的可解释性这类更基础的问题,预训练技术的发展还远没有达到边界。 4.1.2 预训练语言模型的评估方法较为理想化 传统评估模型的方法大都在领域内的测试集上观察准确度,造成模型可以仅利用测试集中浅显的特征就能得到高分,而不是做到真正的理解语义和语法特征。Jia等[54]对SQuAD进行了对抗性评估,十六种模型的F1值从75%降至36%,如果允许添加单词的非语法顺序,F1值降至7%。Niven等[55]通过实验证明了BERT在论证推理理解(Argument Reasoning Comprehension)任务中取得的成绩是由于利用了数据集中的虚假统计线索,并且证明了各种模型都可以利用这些线索。虽然后续NLP领域的学者针对这个现象做了很多关注模型鲁棒性的工作,但是由于这些工作往往针对某个特定的数据集或者任务,甚至于针对某种特定的模型失败的方式,针对性较强,很难迁移到更通用的场景。Linzen等[56]建议未来应该标准化大小适中的预训练语料库,使用专家创建的数据集,通用排行榜应该更加关注支持小样本学习的模型。 4.2.1 更加通用的预训练技术 预训练技术发展到现在一直备受关注,但是有几个问题一直存在:直接用BERT等预训练模型对目标任务进行微调是否还有提升空间?直接微调效果不理想如何处理?持续预训练是否能提高效果?Gururangan等[53]在四个领域的八个不同任务上做了交叉实验,证明了即使是具有数亿个参数的语言模型也难以编码单个文本域的复杂性,无论领域内数据多还是少,领域自适应预训练(DAPT)都能提高性能,而且使用给定任务的未标注数据进行任务自适应预训练(TAPT)也能提高性能。那么如何采取一个更有效的数据选择方法,来构建更多的、任务相关的无标注数据,有效地将大型预训练语言模型重构到更远的领域,并且获得一个更加通用的语言模型成为了未来的趋势。 4.2.2 更加有效的模型评估方法 Ribeiro等[57]对这一问题做出了探索,他们通过语义保留扰动找到模型的对抗性实例,并将其概括为语义等效对抗规则(SEAEs),具有一定的通用性。除此之外,通过改变测试集的标签,可以使很多模型效果大降,并且具有很强的通用性,但是这种方法需要人工构造测试集。Ribeiro等[58]提出了一种全新的颠覆性的评测方式CHECKLIST,全方位地对模型多项能力(是否熟练掌握任务相关的词汇、是否理解同义词和反义词、是否正确理解了命名实体等)进行最小功能测试、不变性测试、定向期望测试。他们抛弃传统的评测方式,用CHECKLIST的方法在三个任务上进行了测试,发现当前的SOTA模型存在各种各样的问题。更加多元化和通用化的评估方法必将激励NLP领域向更深层次探索,而不仅仅是利用浅层特征不断刷榜。ACL2020的最佳论文等都与评估相关,这说明数据集上的SOTA并不是那么重要,而要思考模型真正的泛化性、鲁棒性,以及模型的可解释性。 4.2.3 多语言预训练技术 多语言预训练模型利用迁移学习缓解了多种语言的资源短缺问题,并且在多语言搜索、QA、广告、新闻、文本摘要、低资源神经机器翻译等方面取得新的提升。但是当前最有效的多语言预训练任务依然是MLM,需要继续拓展新的多语言预训练任务;而且当前多语言预训练模型大多采用BPE词表,远比单语言的词表大,导致训练开销更大。多语言预训练技术方兴未艾,也会是预训练技术未来的一个发展趋势。 4.2.4 多模态预训练技术 人类通过多模态感知外部世界,尽管任何单个模态信息可能都不完整或充满噪声,但是人类可以自然地对齐并融合多模态信息,以提取了解世界所需的关键概念。如果把百亿级的图片、视频中的所有的物体和关系进行识别,把整个物理世界通过多模态方式进行预训练,甚至有可能解决GPT-3无法解决的常识问题。当前,多模态预训练技术在图像-语言[59-61]、文档-语言[62]、视频-语言[61]等方面取得了一定成绩,但它尚处于初期阶段,仍然面临很多挑战,例如多模态数据集缺乏,目前没有较好的算法将CV和NLP模型共同训练,CV领域模式识别的类别和精度不够导致多模态预训练的输入信号误差较大。 本文针对NLP领域中的预训练技术的发展做了综述,对预训练技术进行了分类和对比分析,并分析了预训练技术面临的问题和未来的发展趋势。以ELMO、GPT-2、BERT为代表的大规模预训练上下文嵌入模型不断冲击测评榜的SOTA位置,尤其GPT-3的出现,更让学界注意到刷榜的局限性,将会从更高层次的角度思考未来的方向。从当前形势看,探索更加轻量级的预训练技术和多语言、多模态预训练技术在未来一段时间会成为研究热点。另一方面,强大的自然语言生成能力也可能被人利用生成假新闻,产生道德伦理问题。2.6 预训练技术的改进方法
3 预训练技术的对比分析及扩展
3.1 主流预训练技术的对比分析

3.2 多语言预训练技术
3.3 模型压缩

4 面临的问题及未来发展趋势
4.1 面临的问题
4.2 未来发展趋势
5 结语
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
当代体育科技(2020年9期)2020-05-12
家庭影院技术(2019年8期)2019-12-04
通信学报(2019年5期)2019-06-11
当代体育科技(2019年33期)2019-01-14
通信技术(2018年3期)2018-03-21
兵器知识(2017年8期)2017-10-16
环球时报(2017-07-04)2017-07-04
