
大数据技术对校园突发事件中学生行为监测的应用
2021-10-19 07:41姜攀
苏州市职业大学学报 2021年3期
姜 攀
(苏州工业园区服务外包职业学院 信息中心,江苏 苏州 215123)
行为分析是一个新兴的研究领域,目前,我国对于校园学生行为的管理手段大都停留在事后定性分这析上,无法将校园悲剧消灭在萌芽状态,这已经无法满足智慧校园的需要,更不符合大数据时代的发展方向。据相关研究发现,我国高等学校中有心理问题的大学生约占20%,按照病情轻重划分,其中15%的大学生属于一般心理问题,3.5%的大学生属于有心理障碍,1.5%的大学生属于有精神病,失去自我控制能力,分不清现实与幻觉[1]。这些都是不容忽视的数据。随着校园突发事件等学生异常行为的发生趋向年轻化和多发性,通过大数据技术对校园突发事件中学生行为的监测和预测显着极其重要。
本研究从用户需求和系统功能需求出发,搭建学生行为分析的大数据平台总体框架,设计成绩预警、贫困生预测、生活习惯分析等,从学校的教务管理系统、学工系统、一卡通系统、上网行为审计系统、视频监控系统中抽取学生行为数据,对数据进行清洗和储存,实现对校园学生不良行为的监测,以提升相关教育管理部门的早期监测能力。
1 大数据来源
在校园环境中,监测和分析学生的行为数据来源主要有以下四方面:
1)传统数据库。是指现有的关系数据库、数据仓库、数据集市或任何其他产生结构化数据的信息系统。在这个类别中,有关于学生、课程、考试等信息,还有大学的食堂、超市、宿舍等都可能有数据库在运行。现有的数据库可能会在缺失的数据库基础上增加一些额外的信息,如课程表、教室和实验室的分配,建筑物的开放时间,教师的办公时间等。
2)个人数据。通常是数字或非数字形式的,是非结构化或半结构化的,不可以在未经个人许可之前获取这些数据。数字数据包括电子邮件、手机通话、短信、数字照片、音频资料、视频资料、网上购物和信用卡使用情况。非数字数据可以是纸质文件、手写笔记、纸质照片、剪报等形式。
3)网络数字痕迹。人们每天基于网络的许多行为都会留下数字痕迹。网络数字痕迹通常使用的来源是网络挖掘和文本挖掘(来自服务器的日志),从社交网络中挖掘舆论以及从公共门户网站收集的数据。很多数据都是在微信、QQ和微博等社交网站公开的,数据是非结构化的。
4)户外活动数据。这些数据的一部分来源是由校方控制的,视频监控、车辆识别系统、门禁授权系统等通常遍布全校。这些系统的数据以隔离方式进行监测和存储,通常可供本地分析,以发现安全漏洞和任何其他违反规则的行为。
2 大数据平台总体架构
基于大数据技术对校园突发事件中学生行为监测,其大数据平台总体架构如图1所示。
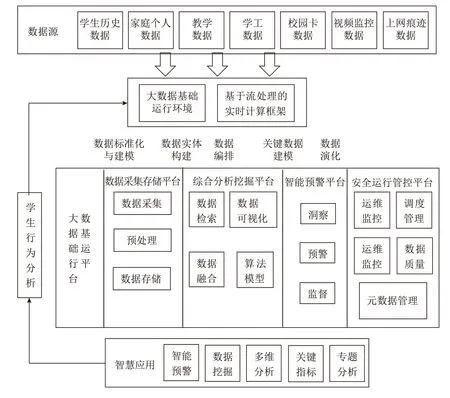
图1 学生行为监测大数据平台总体架构
该平台主要由校园基础数据源、大数据基础运行平台以及各种智慧应用平台组成。其中,大数据基础运行平台主要包括数据采集存储平台、综合分析挖掘平台、智能预警平台,安全运行管控平台。具有智能预警、数据挖掘、多维分析、关键指标、专题分析等多种应用。
1)数据采集和存储平台:将各平台的基础信息和与学生行为相关大数据收集后的结果进行结构化存储和清洗。
2)综合分析挖掘平台:通过对收集到的大数据分析和建模,对其进行更深层次的数据挖掘和分析。
3)智能预警平台:根据平台分析结果对监测到的异常行为进行智能预警以及自动生成对应的监督措施。
4)安全运行管控平台:该平台是对整个系统进行数据管控,以保障数据安全以及系统运行的稳定。
3 数据抓取及存储关键技术
行为分析是一项复杂的工作,学生的行为受多个因素的影响,需要我们具有能够收集、存储和处理大量数据的技术,同时具有足够的灵活性,以适应功能的逐步增加。
通过收集一卡通系统中各类终端设备的海量数据,针对具体的分析场景建模。分析数据库中的有关上课考勤、宿舍出入等刷卡记录表,建立学生日常行为预警系统,记录学生上课迟到、早退和旷课次数,加入教务管理系统中的学生成绩信息后,该记录也可以作为预测学生成绩的关键指标。通过在系统中预设阀值来实现自动预警功能,学生管理者可以根据这些预警信息及时响应。
通过分析学工系统中的学生、家庭基本信息以及一卡通系统中的图书借阅情况、食堂和餐厅消费情况、宿舍购水电记录情况、医务室就诊情况,加上上网审计系统中学生上网审计记录等,通过这些数据的抓取,建立学生综合行为分析系统,该系统可以预测成绩预警、贫困生预警、健康状况预警、节能预警等。
处理大数据时,在云计算服务的帮助下使用Hadoop平台。Hadoop是由许多不同的模块(超过150个)组成,是一个处理大数据的强大平台[2]。
1)HDFS是一个分布式、可扩展、可移植的文件系统,用来存储大文件(可以是千兆字节和兆字节)。因此,Hadoop可以有几百甚至几百万个独立的文件,这些文件分布在许多计算机上(可以是几千台),并且都通过软件相互连接。
2)Map Reduce是Hadoop的另一个关键部分,负责执行分布式处理。这个过程由Map和Reduce组成。Map是将一个任务及其相关的数据分割成许多片段,以便可以被发送到几个不同的服务器上进行并行处理。Reduce过程是从不同的计算机取出结果并将它们结合起来,得出一个单一的结果。
3)Pig是Hadoop中的一个平台,用来编写Map Reduce程序,使用Pig拉丁语编程语言。
4)Hive是Hadoop中的一个数据仓库,它可以用于数据查询、汇总和分析。它使用HiveQL(一种类似SQL的语言)进行查询。
此外,还可以使用其他组件。其中比较常用的有HBase(NoSQL数据库)、Storm(允许处理流数据)、Spark(允许快速内存处理)和Giraph(用于分析社交网络数据)。
4 学生行为大数据分析过程
学生行为大数据分析过程如图2所示。

图2 学生行为大数据分析过程
4.1 源数据库
1)学生学习异常行为大数据:学生缺勤、挂课、偏科、抄袭等异常行为大数据分析。
2)学生日常生活异常行为大数据:根据学生进出校园打卡记录、食堂就餐、晨练打卡、活动轨迹等异常生活行为大数据分析。
3)学生上网习惯异常行为大数据:根据学生上网习惯,对登录非常规如暴力、色情、赌博、诈骗等网站的学生,计算机进行上网异常行为大数据分析。
4)校园视频监控学习异常行为大数据:通过对校园视频图像分析,查找学生异常行为大数据。
5)学生家庭等社会环境异常大数据:非普通家庭和非普通社会环境。
6)其他异常行为大数据:通过班主任、同学、教师等反映的其他异常行为进行大数据分析。
4.2 数据抽取与整合
通过遍历数据源,对所需数据源的数据进行抽取,即将学生行为数据从源数据库抽取出来,在此过程中加入ODS(操作性数据),用作数据抽取。ODS可以整合来自不同来源、不同系统、甚至不同地点的数据,由于ODS数据是非常不稳定的,其数值的变化接近于实时,一个ODS的内容可能从一个时刻到另一个时刻发生巨大的变化,这取决于目标来源的性质。但其好处是抽取过程中极大降低了数据转化的复杂性,而主要关注数据抽取的接口、数据量大小、抽取方式等方面的问题。抽取后的数据最终在数据仓库(DW)中完成整合。数据抽取过程如图3所示。

图3 数据抽取过程
数据抽取工作是对源数据进行全量抽取,通过各类接口提取原始数据,并将数据源中的表或者视图中的数据完整地抽取出来并转换为自己的ETL工具可以识别的格式。数据采集则根据业务数据的不同种类定制合适的数据抽取策略[3-4]。
4.3 数据清洗与分析
数据清洗是修复或删除数据集中不正确的、损坏的、格式不正确的、重复的或不完整的数据的过程。当结合多个数据源时,可能会出现数据重复或错误标记的情况。如果数据不正确,结果和算法都是不可靠的,即使它们可能看起来是正确的。没有一个绝对的方法来规定数据清理过程中的确切步骤,因为不同的数据集的过程会有所不同。但是,为数据清洗过程建立一个模板是至关重要的。这些数据包含了学校各个业务系统中的数据:①基础数据,包括教务和学工系统中学生的基本信息和家庭信息等;②管理系统数据,主要来自学工、教学、一卡通、上网审计等系统中的各类数据,如学生上课情况、请假、消费、上网时长等;③学生行为数据,主要来自各业务系统中的包含与学生个人行为有关的信息,如校园卡消费时间、上课考勤情况、上网时间段等。
数据清洗将学工、教务、一卡通、上网审计等与学生行为相关的全量业务数据,通过各类数据清洗方法(一般包括删除多列、更改数据类型、变量转换、缺失数据检查、删转换时间等)清洗后形成标准化数据。按照近源模型层、整合模型层、共性加工层和集市应用层进行构建。数据清洗过程模型如图4所示。
在图4中,①近源层是在保证业务系统数据接口不变的情况下,对业务系统的原始明细数据进行存储。②整合模型层通过各类主题(如学工主题、教务主题、一卡通主题、上网审计等)模型来存储管理各个业务系统之间相同类型的数据,且保留数据的历史明细。③汇总层以分析的主题对象作为建模驱动,基于各类汇总数据(如学生汇总、教务汇总、一卡通汇总、网络审计汇总等)指标需求构建公共粒度的汇总表。汇总数据层的一个表通常会对应一个统计粒度(维度或维度组合)及该粒度下若干派生指标。④集市应用层(如大数据应用、学生行为应用、系统对接应用等)主要为特定内容建立维度摘要信息并建立摘要数据区域[5-7]。

图4 数据清洗过程模型
4.4 数据可视化
应用服务器首选以Apache Tomcat为基础开发大数据可视化分析系统,此系统共包含了主题数据集、数据可视化图表、主题面板、用户管理、预警管理和决策分析管理这六大模块。
5 大数据分析主要算法
1)分类分析:根据一定的分类准则将具有不同特征的数据划分到不同类别的过程。如,按时上课、遵守纪律这类学生的学习行为为正常;而缺勤、不做作业、沉迷于游戏,挂课、补考课程数量较多,这类学生常常出现学习异常行为。
2)回归分析:通过对自变量和因变量做一定的相关性分析,建立回归方程。根据学生的食堂和日常生活消费异常情况可以推测学生是否出现校园贷,如学生经常旷课有可能沉迷于游戏等异常行为。
3)聚类分析:是一种处理数据的统计方法。是根据项目之间的密切联系将其组织成组,或称聚类。就像缩小空间分析(因子分析)一样,关注的是那些事先没有将变量划分为标准与预测子集的数据矩阵。聚类分析的目的是找到相似的受试者群体,其中每对受试者之间的“相似性”是指对整个特征集的某种全局衡量。聚类分析通常用于对数据中可能存在的关系不做任何假设的情况下。它提供了关于数据中存在的关联和模式的信息,但不是这些关联和模式可能是什么或它们意味着什么。在本研究中是根据学生各种异常行为数据进行聚类分析,得出某些高发的异常行为。
4)关联分析:在海量数据中挖掘出数据间潜在的关联关系。通过分析学生在校园中的打卡轨迹,就可以初步判断出他是在学习,还是在做其他事情。上网经常浏览自杀等不正常网页和独处异常行为就要关联他是否有自闭症和自杀倾向。学生未归或晚归就要关联他是否到校外喝酒或其他异常行为。
5)图像视频分析:采用视频识别分析算法,对各监控采集的视频进行行为异常分析。
6)大数据分析学生异常行为预警。对于出现的学生异常行为,平台要及时通过短信等信息方式通知班主任或辅导员,甚至家长。
7)大数据分析学生异常行为可视化。通过标签云、文本语义结构树、动态文本时序信息可视化、图和树可视化、流式地图、时空立体图、多维可视化等直观表示。采用可视化技术,将海量大数据分析结果以各种图表、GIS、动态图等形式进行展现,支持数据的查询和报表的下载,预警查询、学生行为等级分级、预警信息定向推送等功能。
6 结论
通过数据挖掘整理分析与预警及可视化等技术,对校园突发事件中学生行为进行监测,预判学生是否有出现意识形态的偏差而导致暴力等异常行为倾向,及时有效地遏制暴力等异常行为所带来的其他负面影响,确保校园这片净土,为学生营造一个良好的学习氛围。利用大数据技术,分析和预判大学生异常行为,为学校和社会相关职能部门早期监测提供对策支持。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
师道·教研(2022年1期)2022-03-12
北京测绘(2021年7期)2021-07-28
今日农业(2019年12期)2019-08-13
琴童(2017年3期)2017-04-05
小天使·二年级语数英综合(2017年3期)2017-04-01
火控雷达技术(2016年3期)2016-02-06
小说月刊(2014年11期)2014-04-18
