
基于卷积神经网络的高空作业安全带识别与检测
2021-10-18 08:15吴烈凡
现代计算机 2021年24期
吴烈凡
(广东工业大学信息工程学院,广州510006)
0 引言
尽管其他行业通过自动化和人工智能在生产率上发生了深刻的变化,但建筑还没有。建筑仍然是世界范围内除尘工厂中数字化程度最低的建筑之一,并且对工人的需求巨大。然而,建筑是最危险的工作部门之一。根据美国劳工统计局(BLS)致命伤建筑业的比率高于全国平均水平,在中国,超过2850座建筑2012-2016年期间,工人死于建筑施工活动每天平均有1.57人[1]。工程死亡总是由不同因素共同造成的。其中,脑外伤约占全部的24%美国的建筑死亡人数[2-3]。因此,有一个加强现场安全政策和程序的迫切需求施工现场安全。个人防护装备的使用(例如安全带)可提供有效的风险管理。但是,工人并未完全遵守施工现场的安全规定出于各种原因的各种规定,即使以前已经对其进行过教育和培训[4]。因此,现行的检查实践安全性主要取决于检查员的手册监控和报告。通常,在施工中使用监控摄像头为框架站点,基于视觉的技术执行安全带佩戴检测通过多个阶段,主要包括行人检测[5-6],安全带本地化和安全带识别。虽然进行了广泛的研究,基于视觉的安全带磨损检测仍然具有挑战性。首先,背景和行人状态是由各种现场条件引起的,因此在特定场景下进行研究很难将其扩展到其他建筑工地。同时,存在距离相机较远的小型个体很难将它们与背景杂波和其他重叠的实例。此外,在同一图像区域,彼此部分遮挡,这也使得安全带佩戴检测困难。最后,直到现在还没有公开可用的开放数据集,用于开发和评估安全带各种情况下的磨损检测算法。
在本文中,我们专门解决了戴安全带的任务在施工现场检测。目的是确定建筑工地上的所有人是否都戴安全带。已有的安全带穿戴检测研究将其整个检测流程分为工人检测和安全带穿戴识别两个步骤。FANG Weili等[7]的研究提出使用基于ZFNet[8]特征提取网络的Faster R-CNN模型检测工地人员,然后在检测出工地人员区域的基础上将其输入到深层的卷积神经网络用于分类,以识别该工人是否穿戴安全带。这种检测流程一方面需要依赖较高的召回率和准确率以确保输入到分类网络的图像为工人区域图像,否则出现误检时会造成计算资源的浪费,而另一方面当检测出多个工人区域时,需要多次输入至分类网络,将极大降低运行效率,同时两个深层的卷积神经网络部署于边缘客户端时在实时性方面也有待商榷。
1 国内外研究现状
目前,在国内韩豫等主要使用滑动窗口模板的方式来检测安全带,其采用的匹配方式是归一化相关系数法[9]。整体功能运行流程及实现方式分为3个步骤,首先,是身份识别,将待检查人员站在深度摄像头前进行图像采集,从而定位到头部人脸区域后调用compareHist()对比直方图函数,将获取的人脸信息与工人信息库中信息进行相似度比对,以此确认待检查工人身份。若相似度低于阈值,即判断为非法闯入,并发出警告。若高于相似度阈值,则进一步确认准入权限。其次,进行的是安全装备检查,将安全带的图像作为模板图像,调用matchTemplate()模板匹配函数进行模板匹配,对在待检查工人的色彩图像中搜索最相似区域。最后,是作业行为能力检查,待检查工人在深度相机镜头前做一套指定的运动动作,系统记录该工人的骨骼关键节点间的角度变化,若在此过程中变化的行为与数据库中记录的行为信息不匹配,即认定该工人不符合要求,不适合施工作业,进而发出警告。卢煌等同样运用的是基于滑动窗口的机制,主要运用HOG特征和SVM分类器来检测建筑工地中高空作业人员,然后在每个检测结果窗口进行色彩空间以识别安全带[10]。以上的两种安全带检测方法都是运用基于滑动窗口的方法,此类方法在时间成本上花费较大,整体检测速度不是很理想,进而达不到很好的实时性,不利于实时运行。在图像整体感受野上会达到不好的效果,导致在整体算法的鲁棒性上有待提高。郑翼等提出基于SSD深度神经网络模型判别安全带的检测方法[11]。首先,采用背景建模方法,提取待检测视频图像中的运动区域,作为待检测区域;然后,采用人体检测算法,识别出待检测区域中的人体图像,得到人体检测结果,再运用深度神经网络模型对待检测区域中的人体的头部和躯干部位分别进行检测,进而得到安全带的检测结果;最后将上一步得到的结果进行综合位置空间判定,若计算结果大于阈值,则判定该人体佩戴安全带,否则没有佩戴。李学钧等则是先检测出人体关键点然后在人体躯干关键点处截取躯干区域;其次对样本图像进行采集,将采集的样本图像进行预处理;然后采用迁移学习方法在所述预训练模型上加载图像样本,每隔设定步输出准确率,直到达到最优结果,保存安全带佩戴分类模型,最后采用CNN模型识别是否佩戴安全带[12]。杨奎军提出一种在线式高空作业智能安全带检测监督装置[13]。该装置由控制单元、全景摄像机、传感器及后台4个部分组成。此检测首先在挂钩金属传感器接收到固定指令,然后运用全景摄像机拍照生成360度无死角的照片和视频,并将拍得的照片和视频上传到云端,接着后台人员进行二次核验,最后当发现高空从业人员没有挂系好安全带的通过远程激活控制单元的警报进行声光报警。此方法能很好检测到高空从业人员是否佩戴安全带并且能发出警报,但由于天气和光照等因素有时会对拍照造成一定影响,以及需要后台人员监测,这样整个检测将达不到很好的实时性。卫潮冰等提出了一种基于CNN的智能监测识别检测方法[14]。该方法首先通过相关样本图像训练出所需的安全带识别模型,然后利用所得到的模型对电力施工现场所拍摄的实时图像进行检测识别,从而实现智能化检测。该种方法会因为人员遮挡的原因使得性能较差,同时,此方法只训练同一工地场景图像,从而普适性较差,不能很好进行普遍推广。
在国外,FANG Weili等提出了基于CNN方法来检测高空作业中从业人员是否佩戴安全带[7]。主要是提出了两个CNN检测模型,首先是运用Faster RCNN模型检测出是否为工人,其次在检测出工人的时候,再运用CNN模型识别已检测工人是否佩戴安全带。此检测模型的准确率达到99%,召回率为95%,分类模型分别为80%和98%。此方法虽然在准确率上取得不错的效果,但由于采用了两个神经网络,整个检测网络不是端到端的,故在实时性方面有待商榷。Fernandez-Madrigal等的研究是基于传感器的检测方法[15]。该方法主要是部署了蓝牙低功耗(BLE)信标,以划定必须使用线束的区域,并检测线束是否连接到相应的线束上工人进入这些区域时的生命线。进行基于本地估计,通过对RSSI测量值(扩展卡尔曼滤波器)进行统计过滤,对界定不同区域的信标与生命线中的信标之间的接近程度进行了评估,然后再使用有限状态机风险状态检测器。
2 安全带检测框架图
2.1 网络框架
安全带检测网络框架如图1所示。
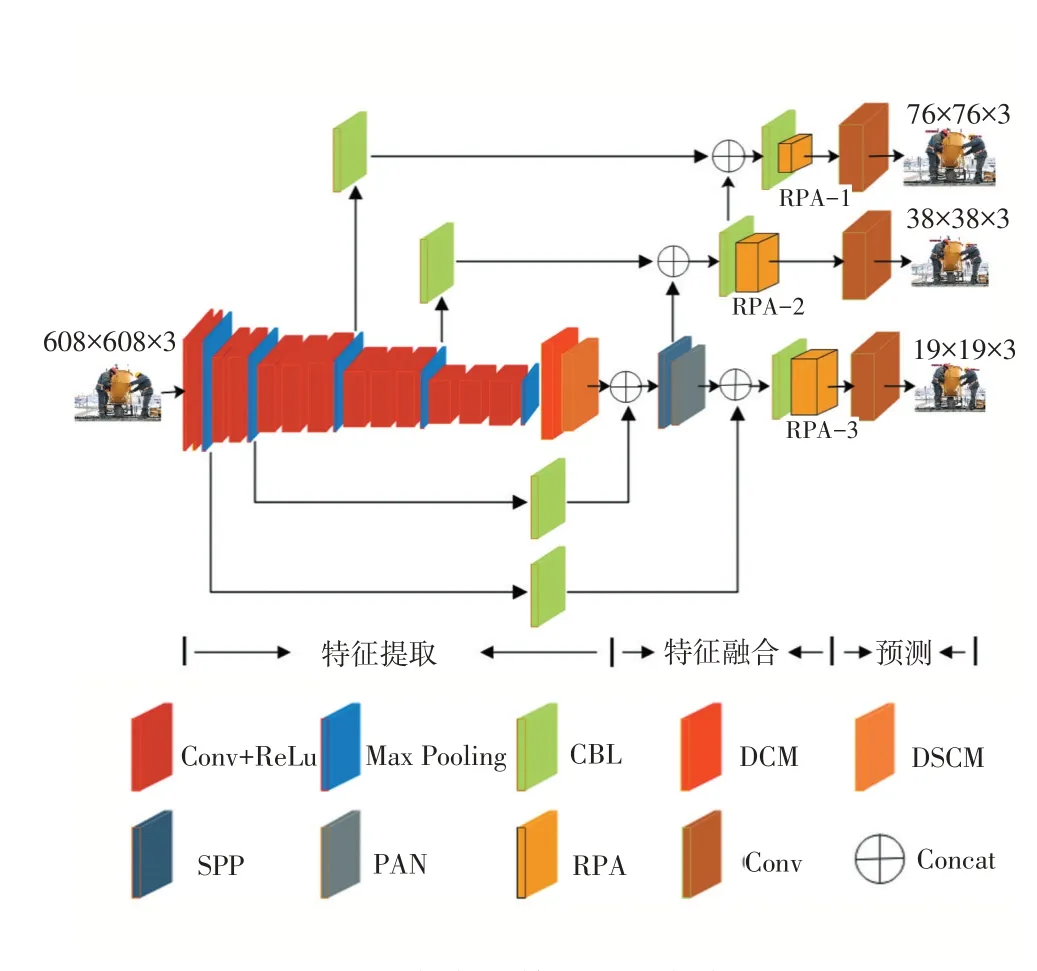
图1安全带检测网络框架
首先是图像输入,图像大小为608×608。整个网络框架由3部分组成,第一部分是特征提取模块,在这部分中主要是由Conv+ReLU和Max pooling组成,分成5个Conv+ReLU小模块,在每小模块后都运用Max pooling。每一小模块中运用不同的卷积层和Re⁃LU主要针对不同尺度目标的检测,在第一小模块中输出76×76大小的图像,第二部分输出38×38的图像。在第三模块中为了提高小目标的检测精度,运用3个较大尺度的卷积层和ReLU来增强上下文语义信息,此时再输出76×76的图像,第三部分输出38×38的图像,在最后一小模块中输出的是19×19的图像。由于在特征提取时每次运用卷积网络后难免会存在图像语义信息丢失的现象,而ReLU激活函数的作用是增加了神经网络各层之间的非线性关系,否则,如果没有激活函数,层与层之间是简单的线性关系,运用ReLU函数每层都相当于矩阵相乘,这样很好能够完成我们需要神经网络完成的复杂任务。ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing Gradient Problem),使得模型的收敛速度维持在一个稳定状态,对增强上下文语义信息起到很好的效果。运用Max pooling的作用是因为保证特征的位置与旋转不变性和减少模型参数数量,减少过拟合问题。在每次特征提取输出后都会出现部分被数据丢失的现象,此时引入CBL,此模块由Conv+Bn两者组成,起到数据增强的作用。
在特征提取输出图像19×19的图像后引入空洞卷积(DCM)[16]是为了解决传统卷积和池化操作造成的内部数据结构丢失和空间层级化信息丢失,以及由于多次池化操作造成小物体信息无法重建的问题。为了使得在池化减少图像尺寸以增大感受野和上采样增大尺寸这个过程能保留更多特征信息,在不通过池化操作以扩大感受野的前提下引入空洞卷积。空洞卷积过程,引入了一个新的超参数d,(d-1)的值则为塞入的空格数,假定原来的卷积核大小为K,那么塞入了(d-1)个空格后的卷积核大小n为:
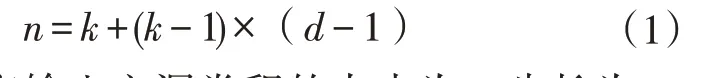
进而,假定输入空洞卷积的大小为i,步长为s,空洞卷积后特征图大小O的计算公式为:
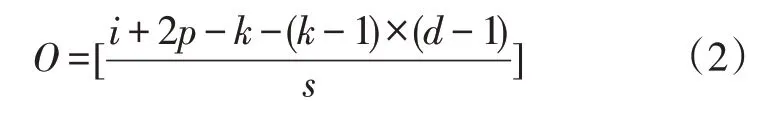
引入深度可分离卷积(DSCM)[17]是为了减少神经网络模型参数量和计算量而研究出来的一种轻量级卷积结构,并且由此构建的轻量级模型如MobileNet[18]等广泛应用于移动端设备和嵌入式设备中。深度可分离卷积操作分为逐通道卷积和逐点卷积,前者在特征图的每一个通道上进行普通卷积,而后者则是将逐通道卷积后的特征图使用1×1大小的卷积核进行普通卷积,在同等输入和输出条件下,深度可分离卷积的参数量是标准卷积的
在特征融合模块中运用每个Concat来进行张量拼接,在这一模块中引入了SPP和PAN网络,SPP模块采用1×1、5×5、9×9、13×13的最大池化的方式,进行多尺度融合,由3个不同尺度的maxpool将前一个卷积层输出的特征图进行多尺度的特征处理,再与原图进行拼接,一共4个scale,将不同尺度的特征图进行Concat操作。相比于只用一个maxpool,本方法提取的特征范围更大,而且将不同尺度的特征进行了有效分离。接着将不同尺度的特征图进行Concat操作后输出不同大小的特征图,再将特征图都进行下采样操作,主要是增加感受野,提升小目标检测精度,提高图片的高分辨率,在FPN模块中对不同尺度的图片运用不同层次的卷积网络进行上采样操作,将输出的特征图进行Concat操作,再运用CBL进行数据增强。接着将不同尺度的特征图运用不同层次的卷积网络进行下采样操作,主要为增大整体感受野,提升低分辨率的图片精度。
最后是预测模块,运用不同层次的卷积网络,以及运用改进后的渐进注意力机制模块,有利于增强安全带佩戴检测的特征,特别是用于检测小尺度安全带的特征,来输出3种尺度大小的检测图。
2.2 渐进注意力机制
对于远离摄像头工地人员的安全带佩戴检测问题,由于此时工人的上半身区域在采集图像中只占了一小部分,因此图像在经过重复的下采样操作后(如卷积和池化),特征的分辨率会逐渐降低,最终导致最高层特征图即使能表达强语义信息,但此时的安全带表示特征已经很少甚至消失。此时运用改进后的渐进注意力机制模块成为有利于安全带佩戴检测的强特征,特别是用于检测小尺度安全带的特征。给定在第l-1层的特征图θl-1∈RC×H×W,则该层的空间注意力特征图αl-1由公式(3)和公式(4)计算得到:
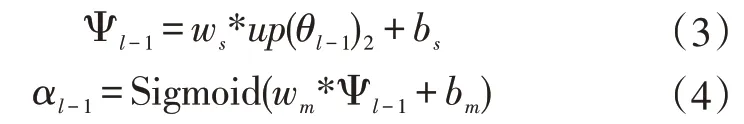
其中,∗表示卷积操作,Ws∈RC/2×C×3×3和Wm∈Rk×k表示卷积核,bs∈RC和bm∈R1表示偏置项。up(∙)2代表以因子为2的上采样操作,在这里采用的是双线性采样。公式(3)表示将对上一层次经过上采样的特征图进行通道减半的卷积,以提升特征抽象表示能力。公式(4)则表示对通道减半的特征图以卷积的方式生成空间位置特征图并使用Sigmoid(x)=1/(1+e-x)函数进行归一化。现在θl-1的空间注意力特征图αl-1∈[1,0]2H×2W就可以指导θl有选择地生成强特征,如公式(5)所示。

2.3 损失函数
为使得本文整体网络框架具有良好的性能,目标在减小预测值与真实值之间的差值,为获取的训练图像标注了各个作业人员的位置以及是否佩戴安全带,通过训练图像训练卷积神经网络获得损失值,通过损失值更新网络参数,直至网络收敛,得到预置卷积神经网络模型。为提高整体检测性能以及达到实时性的效果,所提出损失函数主要从几个方面考虑,分别是重叠面积、中心点距离和长宽比。故受回归损失函数的启发,本文提出的改进回归框(improved bound⁃ing box regression,IBBR)损失函数定义为:

3 结果与讨论
3.1 数据集统计
拟议的基准数据集是通过下载由搜索引擎使用关键字检索到的Internet图像生成的,该图像涵盖了场景、视觉范围、照明、单个姿势和遮挡的较大变化。此图像数量为2627,已分为1313进行训练(GDUTHWD trainval)和1314进行测试(GDUT-HWD test)。它包含8163个实例,分为2个类,每个实例都带有一个类标签及其边界框。值得注意的是,在此数据集中,小规模实例(面积≤322像素)的数量最多,这给利用磨损检测带来了挑战。因此,为了测试探测器在不同大小的物体上的能力,我们还根据其大小将实例划分为3个比例类别:小物体(面积≤322像素)、中等物体(322<面积≤962)和大物体对象(面积大于962像素)。每个类别的实例如表1所示。
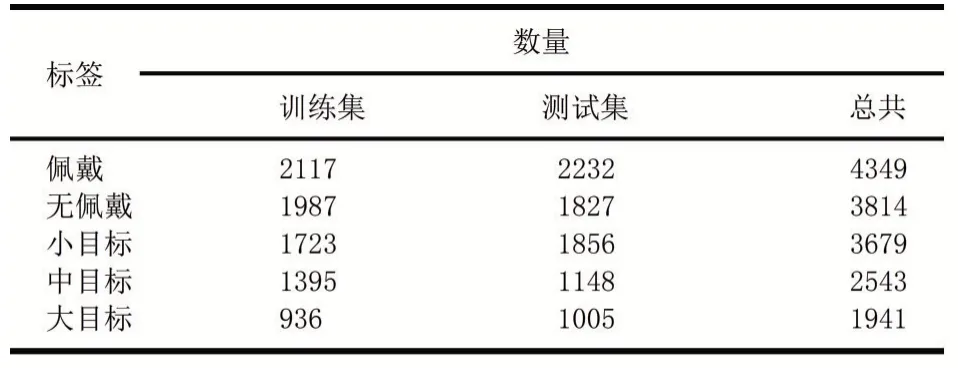
表1类别实例
请注意,标签“无”表示未佩戴安全带的人
3.2 评估指标
由于本文提出的安全带佩戴检测问题属于多目标的检测问题,因此在评价模型的性能时采用目标检测领域最为流行的平均精确率均值(mean average precision,mAP)和类别平均精确度(average precision,AP)。其中,AP是由精确度和召回率曲线下的面积计算得到,而mAP则是计算安全带两个类别AP的平均值。安全带某个类别的准确率和召回率由公式(7)和公式(8)计算得到。

其中TP定义为交并比(intersection over union,IoU)大于等于0.5的正确检测数。FP定义为安全带类别错误的检测数,而FN为未检测出来的类别真值检测数。IoU由预测边框Bp和真值边框Bgt之间的重叠区域除以它们之间的并集区域得出。在实验中,如不特殊说明,IoU设置值都为0.5。计算IoU值如公式(9)所示。

3.3 网络参数配置及硬件实现
采用PyTorch软件包训练和测试所有的深度学习模型。所有网络模型均在Intel Core i5-9600K CPU@3.40 GHz×6和NVIDIA GTX 2080 Ti GPU的电脑上进行训练。所有测试任务均在Intel Xeon E5-2360 v3 CPU@2.40 GHz×16且没有GPU的电脑上实现。
3.4 实验结果
表2中显示可看出在Faster R-CNN实验中检测精度是最低的,且在检测速度上也是最慢的。在本文提出的方法中,在这几个实验结果对比,无论在检测精度还是速度上都达到了最好的效果,从而说明本文提出方法的有效性。
3.5 检测可视化图
检测可视化结果如图2所示。

表2实验结果对比

图2
4 结语
用于识别安全带使用情况的自动系统提供了一种减少人身伤害风险和提高建筑工地安全性的有效手段。先前的研究已经指出了通过计算机视觉技术而不是基于传感器的方法来检测安全带的重要性。但是,大多数研究已经采用多阶段方法来解决该问题,但在适应工地条件和实际可行性方面存在局限性。同时,在回顾文献时,没有基准数据集,由于机密性的限制,无法获得该领域的公开数据和真实的工业数据。这项研究的目的是通过基于YOLO的方法从现场场景中识别任何个人的安全带。因此,对所提出的基准数据集进行的大量实验证明了所提出方法的有效性。在这项研究中,发现基于YOLO的安全带磨损检测方法在广泛的现场条件(例如视觉范围、照明、个人姿势和遮挡)中具有显着的可靠性和稳定性。关于在远场图像中识别小规模个体的安全带磨损的问题,本研究发现,YOLO框架中的具有扩散卷积和深度分离卷积模块的特征聚合可以提高性能。评估1309张图像的测试集并与在训练中训练的现有流行目标检测模型进行比较证明了其优越性,主要包括引入空洞卷积以改善接收场以增加高分辨率特征图,将大大提高小尺度物体的检测精度,减少神经网络模型参数和计算量。深度可分离卷积简化整体网络复杂度,可以改善整体检测速度,整体网络检测可以实现更好的实时性能,从而提高了在建筑工地上进行高空作业的安全性。
本文方法是基于YOLO的安全带识别与检测框架,创新点主要包括运用不同层次的Conv+ReLU激活函数和Max pooling以及提升感受野的空洞卷积和减少神经网络模型参数量和计算量的深度可分离卷积。在针对小目标检测上引入改进的渐进注意力机制,有利于进行多尺度检测,在小目标检测精度上提升显著。整个网络框架是端到端,达到很好的实时性和准确性。本方法在检测精度上达到了很好的效果,特别是在小目标检测上。但建筑工地中高空作业是高危工作,保障从业人员的安全极为重要,故在实时性上还有待提升,例如可以考虑采用简化整个网络模型的复杂度,提升整体检测速度以达到更好的实时性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
汽车实用技术(2022年4期)2022-03-07
中外文摘(2020年23期)2020-01-01
上海师范大学学报·自然科学版(2019年5期)2019-12-13
语文周报·教研版(2018年14期)2018-05-03
儿童故事画报·发现号趣味百科(2017年9期)2018-03-13
