
不同粒度嵌入单元的端到端语音合成技术研究
2021-10-18 08:13姑丽斯坦奥布力喀斯木帕力旦吐尔逊艾斯卡尔艾木都拉
现代计算机 2021年24期
姑丽斯坦·奥布力喀斯木,帕力旦·吐尔逊,艾斯卡尔·艾木都拉
(1.新疆大学软件学院,乌鲁木齐830046;2.新疆大学信息科学与工程学院,乌鲁木齐830046)
0 引言
语音合成技术(text to speech,TTS)又称文语转换技术,是一种通过计算机辅助手段将任意输入的人类规则化文本转换为所对应人类规则化语音的技术[1]。在人机交互、人工智能领域中,语音合成技术是实现它的关键技术之一,在实际应用场景中其应用价值也越来越受到重视,在自动驾驶、问答系统、智能机器人、盲人辅助系统、自动化办公、交通通讯等场景有着非常广泛的用途[2]。从图1可以看出传统语音合成技术是由前端语言处理模块和后端声学模型生成模块等两部分所构成,不同模块负责不同的语音信息处理工作,非常方便地解决语音合成中的问题诊断以及针对不同模块的优化问题,是一种高内聚低耦合的组合方式。其中前端从语言学背景出发,对文本信息进行处理,包含文本正则化、分词、词性预测、多音字标注等文本预处理工作[3-4]。后端根据前端文本处理工作的结果,通过优质的声学模型生成其对应的语音波形从而达到语音合成的目的,其具体工作包括合成单元粒度的选择、语音持续时间模型的建模、声学特征预测模型的建立、声码器等[5-12]不同的子模块。由上述所知,传统的语音合成技术相对复杂,不同的模块需要花费大量的时间、精力、大量领域专业知识和特征工程去构建文本分析、声学模型、音频合成等模块。并且模块之间的组合过程也会出现很多问题,尤其是像维吾尔语这种本身就缺乏足够的数据资料、大众相对难理解的低资源小语种,设计新的语音合成方法相对更难,实现的门槛相对更高。
在人工智能技术的帮助下,传统语音合成技术的设计方法和实现难度发生了一个质的变化。借助深度学习方法的技术支持,传统专业门槛极高的语音合成技术取得了不俗的成绩,但也存在一些不足。例如WaveNet[13],一种能产生原始音频波的神经网络,虽然语音合成效果相对较好,但是需要一个复杂的前端文本分析系统,速度较慢。Deep Voice[14-15]是由百度所提出的实时神经网络文本到语音合成系统,将传统TTS系统流水线中的每一个模块分别用神经网络架构进行替代,虽然便于语音合成工作中的问题诊断,但它的每一个模块都需要单独训练实现成本相对较高。基于语料库、基于HMM、基于神经网络、基于BiRNN[16]的维吾尔语语音合成前后被提出,但生成模型相对复杂,设计难度高并且合成效果在自然度、清晰度等方面不够理想。针对以上存在的前端复杂、模型设计难的问题,迫切需要一个端到端的,将不同的模块集成到一起,实现一个直接连接输入和输出的模型。
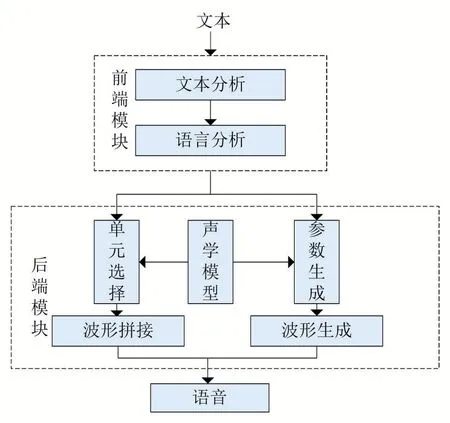
图1传统语音合成系统架构
Tacotron端到端的语音合成系统的出现为解决上述问题提供了一个新的思路,该系统可以接受文本或者注音字符的输入即可输出相对应的音频波形[17]。此系统中前端模块得到了极大简化,甚至可以直接省略掉。Tacotron语音合成技术已成功运用于中文语音合成[18],同时也成功运用于闽南语等一些地方性方言的语音合成工作中[19]。对于维吾尔语这类低资源语言的语音合成,Tacotron端到端技术提供了一种高效的实现方法。
本文针对维吾尔语语音合成中前端预处理繁琐等问题,拟采用Tacotron端到端的语音合成技术,使用文本及所对应的音频数据作为学习模型,实现对维吾尔文本的语音合成。并在改进的Tacotron模型上分别对维吾尔词、维吾尔词素以及维吾尔字符为编码粒度单元进行语音合成实验,根据实验结果进行主观客观评价得出相应的结论。这也是端到端语音语音合成技术在维吾尔语音合成方面的首次运用,实验结论将有助于今后维吾尔语语音合成技术的进一步发展。
1 深度学习语音合成
在语音合成技术方面,深度学习方法消除并弥补了基于高斯-隐马尔可夫模型及拼接合成等传统方法缺陷,获得了高质量的合成效果,极大程度地降低了语音合成的门槛及实现难度。其中由DeepMind所提出来的WaveNet语音生成模型得出的合成语音,相对传统方法合成的语音效果显的更加自然、清晰[5]。从图2 MOS评分结果中可以明显看出,WaveNet在中文和英文中合成语音的MOS得分结果,远远超过了传统的波音拼接合成和参数合成得到的分数。
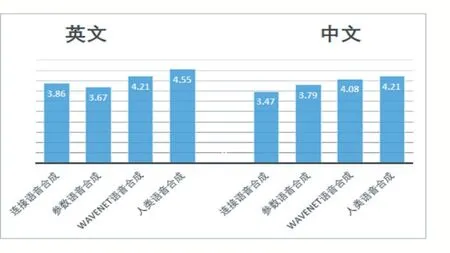
图2 WaveNet中英文MOS评分结果
WaveNet通过对音频流X={X1,X2,X3,…,XT}的联合概率建立模型,对每一帧Xt的条件概率求乘积。其所构建的联合概率函数表达式如下所示:
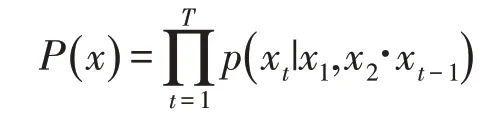
其中,每一帧Xt取决于原先的音频流样本。同时由于语音是从至少16 KHz的采样频率进行取样,这意味着,每秒的音频至少有16000个样本。用传统的LSTM或者RNNs进行建模是不可行的,因此使用CNN对一维的音频信号进行处理,在因果膨胀卷积的作用下,WaveNet网络结构可以进行时间依赖性进行建模,如图3所示。加上Mu-law压缩使模型大大减少输出量,提高了训练和推论的速度。
使用WaveNet将文本合成为语音,但是并不能直接使用文本音频数据对其进行训练,从而获得一个可以直接将文本合成为语音的模型,而是需要对文本进行一系列的前端处理才能将其运用于语音合成。然而这种方法在某种程度上并不是端到端语音合成,而是类似于Deep Voice的基于深度学习的模块化语音合成。Tacotron的提出让端到端语音合成成为可能,通过直接使用文本以及所对应的音频数据的学习模型,真正意义上实现了端到端的语音合成。Taco⁃tron通过将文本直接输出常用的语音特征图——梅尔图谱,通过Griffin-Lim算法将梅尔图谱转换为对应的音频从而达到语音合成的目的。其模型的总体架构如图4所示。
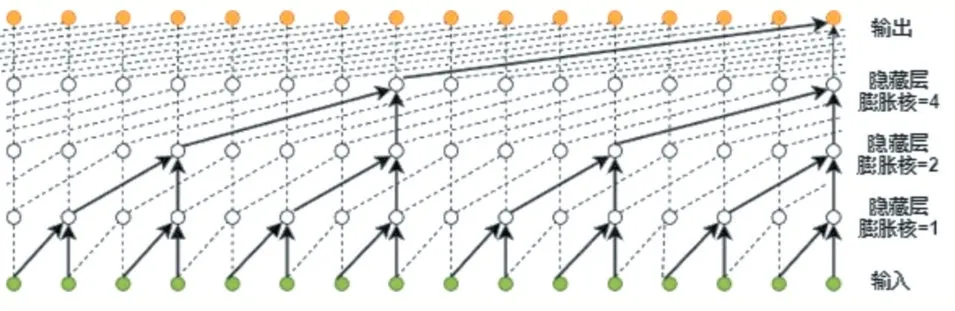
图3 WaveNet模型
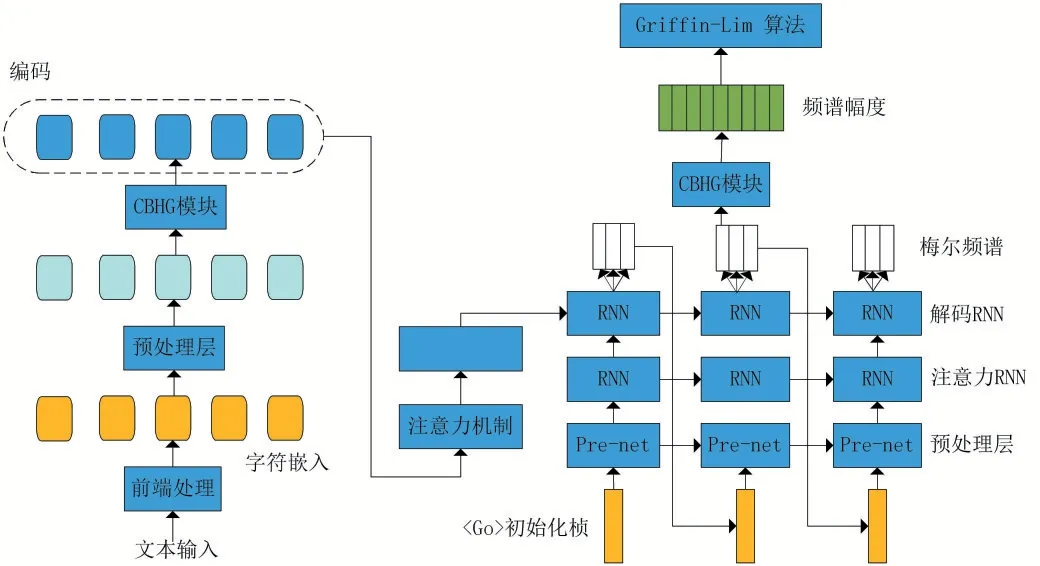
图4 Tacotron模型图
由图4可以看出Tacotron模型在设计思路上使用了端到端模型,由编码器模块以及解码器模块所构成,且利用注意力机制进一步提高语音合成效果。本文对维吾尔文利用Tacotron模型实现语音合成,并且此基础上对维吾尔文本进行不同粒度单元的对比实验从而得出适合语音合成的最佳粒度单元。
2 端到端语音合成
端到端是对数据处理或学习系统的多阶段处理模块,通过神经网络将其整合为一个黑盒子的解决思路,不用花费大量时间去了解语音合成系统中需要用的模块或者领域知识,直接用深度学习的方法训练出一个TTS模型,将不同的模块集成到一起,实现一个直接连接输入和输出,给定input模型就能生成对应的音频。在原本的Tacotron模型前添加文本-词、文本-词素转换模块,对其合成效果与Tacotron本身的字符级粒度单元的模型效果进行对比,并对Tacotron模型的编码器,解码器以及后处理网络等实现模块进行详细研究。
2.1 文本-词、词素、字符
维吾尔语是典型的形态丰富的黏着性语言,句子中的词是自然分开的,构词和形态都是通过词干(或词根)后面连接不同词缀来派生出来的。词干是具有独立语义的单元[20],并且是开放集,主要表达词的意义。而词缀是辅助功能单元且闭合集,功能强大、种类繁多、连接形式各式各样,在句子中提供语法信息(所属性、形态、复数)起到非常重要的作用。
词(word)是维吾尔语中能够独立运用的最小的语言单位,句子中词与词之间有空格隔开,不存在分词问题。词素是构成词的要素,是语言中最小单位的音义结合体。词素是比词低一级的语言单位,从语言词的本身来讲,很多词可以进一步分析成若干个最小的音义统一体。字符是指类字形单位或符号,包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。
维吾尔语言由于这种派生特性,在词素上有很多种组合,从而增加了词汇量。因此基于词素这样较小粒度单元的建模,可以提供更强大的语义信息及更好的覆盖率,从而能建立出更好、更可靠的模型。让更多的人更容易看明白,数据使用了实验室自主开发的“维吾尔语拉丁文转换工具”对维吾尔文本进行拉丁维文处理,通过实验室独有的词、词素、字符转换工具得出的不同粒度单元结果如图5所示。
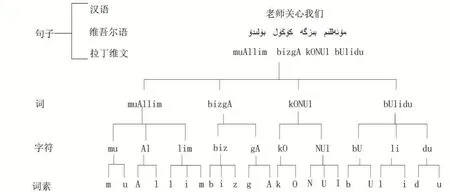
图5不同粒度单元
2.2 编码
由于本模型的建立涉及到将文本内容转换为高维度的语音信号,因此对编码器的泛化能力要求非常高。其具体处理过程涉及到将文本内容进行向量化处理,通过利用预处理网络模块对文本内容进行非线性变换。再将其输出的序列利用CBHG模块进行特征提取,其过程如图6所示。

图6 CBHG模型
其结构最初源自于机器翻译模型,由多层卷积网络、高速网络、双向门循环控制单元所构成。其中多层卷积网络设置不同的卷积核从而提取不同的上下文信息,将其堆叠到一起进一步增强泛化能力,在训练过程中,通过使用Dropout来达到一个防止过拟合的效果,从而获得高维度文本向量的表示特征的上下文向量。其具体过程为在编码过程中以编码粒度单元为准,都会成为一个256维的向量,即编码器所输出的上下文向量的大小为[N,256],其中N表示输入向量的文本长度,在这里文本的粒度单元的大小会直接影响其语音合成的效果。
2.3 解码器
解码器模块是由预处理网络、注意力循环神经网络、解码器循环神经网络所构成。其中解码器模块中的预处理网络和编码器模块中的预处理网络相同,主要对输入做非线性变换,进一步提高泛化能力。注意力循环神经网络则将预处理网络的输出和注意力模块的输出作为输入。注意力循环神经网络的结构为一层包含256个GRU单元的循环神经网络,将预处理网络输出和注意力机制网络输出的上下文矢量拼接成一个矢量输入到两层单向循环长短时记忆网络,长短时记忆网络的输出再一次和注意力机制网络输出的上下文矢量拼接,拼接后的矢量通过线性转化投影成预测频谱同样的解码器循环神经网络,每层同样包含了256个GRU单元。由于每个字符在发音的时候,可能对应了多个帧,因此每个GRU单元输出为多个帧的音频文件。
2.4 音波合成
在Decoder-RNN输出之后并没有直接将输出转化为音频文件,而是又添加了后处理的网络。后处理的网络可以在一个线性频率范围内预测幅度谱(spectral magnitude),并且后处理网络能看到整个解码的序列,而不像端到端网络(Seq2Seq)那样,只能从左至右的运行。后处理网络可以通过反向传播来修正每一帧的错误,然后通过Griffin-Lim进行语音信号的重构。通过对后处理网络的频谱幅度以及其变换相位进行构建,对其进行多次的短时傅里叶变换得到其估值系数,然后进行逆傅里叶变换获得音波波形。其重建过程如图7所示。

图7 Griffin-Lim算法流程
3 实验结果与分析
在实验过程中,本文使用实验室收集到的数据集上进行实验。数据集包含音频文件和音频对应的文本文件,其中维吾尔语数据集包含2497个句子,时长为5.79小时,其中音频文件的采样率为16kHz,采样位数为16bit,单声道wav格式。其中对数据集的训练集、验证集,测试集的划分如表1所示。

表1 数据集划分
对音频文件提取音频特征中,帧长设为50 ms,帧移动为12.5 ms。同时根据音频文件的采样率,将其Mel频谱特征设为80维,线性谱特征设置为1025维。其中模型的训练超参数如表2所示。

表2模型参数设定
在进行语音合成实验过程中,使用以词,词素为基本单元和字符为基本单元进行对比实验,不同单元的解码如图8所示。由图8可以看出,使用词素为基本单元语音合成在发音稳定性和连续性上不如字符为基本单元的语音合成,但其曲线的像素点表明其对齐准确率要优于字符为基本单元的语音合成。原因主要是因为端到端的语音合成是不等长的序列到序列的建模过程,而文本特征相比声学特征在序列长度上相差较大,增大文本特征序列有助于模型更好地学习到对齐信息。以字符为基本单元的方式建模,可以扩大文本特征序列,并且根据音素组成和发音时长动态的提取不同长度的文本特征序列。而词素嵌入方式则是一种静态的文本特征提取方式,序列长度不会随着词素组成和发音时长而发生改变。因为词素嵌入对词素发音时长信息的表征不如字符嵌入,所以在发音的稳定性和连续性上词素嵌入不如字符嵌入,但是由于词素嵌入对词素整体性的表征更佳,故在对齐准确率上稍优于字符嵌入。
同时我们对由词、词素、字符不同粒度单元所合成的语音效果从主观以及客观方面进行了不同的测试,在主观方面使用MOS测试,分别使用不同合成模型中的测试集中取出20个句子。每个句子有5个人打分,计算出针对不同粒度单元的合成效果。在客观方面使用MCD(Mel Cepstral Distortion)来评价语音质量。针对不同建模粒度单元的效果如表3所示。

表3 不同粒度单元的主客观评测结果
由表3可知,字符为粒度单元的合成效果最好,其原因是因为字符覆盖度相较于词素和词覆盖范围度更好,不存在集外词等问题。同时在本实验中数据集中的序列长度较短,因此在整体的建模过程中,以字符为粒度单元的合成效果要优于词和词素的效果。

图8 不同粒度单元解码对比
4 结语
本文针对传统维吾尔语语音合成存在的前端预处理繁琐及模型复杂的问题,采用基于Tacotron的端到端深度学习方法,使用文本以及所对应的音频数据作为学习模型,成功实现了低资源语言维吾尔语的语音合成。并且在此模型基础上分别对维吾尔语词、词素、字符等不同粒度单元的文本进行语音合成对比实验。对结果进行主观及客观评价得出以词素为基本单元的端到端语音合成效果优于以词为基本单元的语音合成效果,以字符为基本单元的端到端语音合成效果优于以词素为基本单元的语音合成效果的结论。这是第一次将端到端语音合成技术应用到维吾尔语文本上面,以上结论有助于维吾尔语语音合成技术的更进一步发展。然而由于训练数据量较少的原因,在某些测试任务上未能形成完整的结果并存在杂音。Tacotron是第一个端对端的TTS神经网络模型,目前已经发展出了Tacotron2。Tacotron2使用了一个和WaveNet十分相似的模型来代替Griffin-Lim算法,同时也对Tacotron模型的一些细节也做了更改,最终生成了十分接近人类声音的波形[12]。在后期的研究工作中,将会研究Tacotron2模型在维吾尔语语音合成中的应用以及如何以少量数据得到最优化的语音合成结果。
猜你喜欢
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
中国民族博览(2019年10期)2019-11-29
电脑爱好者(2019年8期)2019-10-30
知识文库(2018年16期)2018-05-14
电脑知识与技术(2018年3期)2018-03-21
北方文学(2018年2期)2018-01-27
新作文·高中版(2017年6期)2017-07-06
科技与企业(2015年12期)2015-10-21
农机使用与维修(2014年10期)2014-10-23
