
基于深度学习的复杂场景下车牌定位与识别
2021-10-18 08:15郝达慧王池社陈敏
现代计算机 2021年24期
郝达慧,王池社,陈敏
(1.安徽理工大学,计算机科学与工程学院,淮南232001;2.金陵科技学院,网络与通信工程学院,南京211000;3.江苏省人工智能交通创新应用工程研究中心,南京211000)
0 引言
随着社会经济的飞速发展,汽车的数量也在大幅度增长。汽车在给人们带来便利的同时,也带来了很多安全隐患,如交通事故频发、车辆违规等问题。车牌定位与识别是计算机视觉与模式识别技术在智能交通领域应用的重要研究课题之一[1],在车辆管理方面有着较为广泛的应用,如出入控制、违章监控、违法车辆跟踪等[2]。早期的车牌识别算法大多都是基于机器学习算法进行研究,使用手工选取的特征对车牌进行定位与识别。近年来,随着大数据时代的到来和计算机算力的提升,深度学习在车牌识别方向取得了重大突破,Faster R-CNN[3]、YOLO[4]等深度学习算法的提出使得车牌的定位与识别得到了新的发展。现有的车牌识别技术主要应用于特定的环境,如收费停车场出入口、高速公路ETC通道等。在这种检测区域固定、光照良好的环境下,车牌识别技术的准确率可以达到很高,但是在复杂的场景下识别效果较差。本文针对光照不均、天气异常等场景下的车牌识别,提出了基于无分割的车牌识别算法,基于YOLOv5对车牌进行定位并设计了端到端的字符识别网络(LP⁃CRNet)对车牌字符进行识别。
1 相关工作
车牌识别算法可以分为车牌检测和字符识别两个部分,车牌检测是为了定位车牌在图片中的具体位置,字符识别用于对检测出来的车牌区域的字符进行识别,最终得出图片中的车牌号。
1.1 车牌检测
车牌检测算法分两种,一种是基于手工选取的特征进行检测,另一种是基于深度学习方法进行检测。Yuan等[5]提出使用线密度滤波方法提取车牌候选区域,最后基于线性SVM的级联分类器从候选区域中提出车牌位置。Tian等[6]提出了一种基于边界聚类的检测方法,通过Canny算子获取边界图,然后基于密度的聚类方法将边界划分为不同的聚类,最后使用线性支持向量机对边界定位准确的水平候选区域进行分类。Zhang等[7]设计了一种由卷积神经网络和递归神经网络组成的深层网络,专门针对污损、遮挡等特殊车牌的定位问题。Wang等[8]提出了一种精度更高、计算成本更低的多任务卷积神经网络车牌检测与识别系统(MTLPR),在实际复杂的场景中具有较好的鲁棒性。
1.2 字符识别
车牌字符识别方法分为两阶段和一阶段方法,两阶段方法首先对车牌区域进行字符分割,接着对分割出来的单个字符进行识别。一阶段方法采用端到端的深度学习算法直接对车牌区域进行字符识别。余承波[9]使用垂直投影分割算法进行字符分割,提出了一种融合字符的统计特征和结构特征并结合SVM的字符识别方法。Kessentini等[10]分别两个YOLO模型对车牌进行识别,一个用于对车牌区域进行定位,另一个模型对车牌区域的字符进行识别。Li等[11]在车牌检测的池化层后直接接入基于RNN的识别网络,省去了中间字符分割的处理,整个网络采用联合损失。
2 基于深度学习的车牌识别算法
车牌检测是车牌字符识别的基础步骤,检测结果直接影响后续字符识别的准确率。本文的检测模块基于YOLOv5对图像中的车牌进行定位,由于只需要检测车牌一个类别,选用YOLOv5中深度最浅的YOLOv5s网络结构。
传统的车牌字符识别大都是基于字符分割的识别方法,识别效果受字符分割的影响很大,当存在车牌图像倾斜角度过大、光照昏暗等干扰时,字符分割效果并不理想。本文的识别模块基于CRNN网络[12]设计了一个端到端识别车牌字符的LPCRNet网络。
2.1 检测模块
检测模块使用CSPDarkNet作为主干特征提取网络,从输入车辆图像中获取丰富的特征信息,有效缓解了大型卷积神经网络的梯度消失问题。Neck部分选用PANET(FPN+PAN),用于生成特征金字塔,会增强模型对于不同尺度的车牌的检测。检测模块的网络结构如图1所示。
Bounding box损失函数采用的是GIoU_Loss,GIoU的计算公式如下:
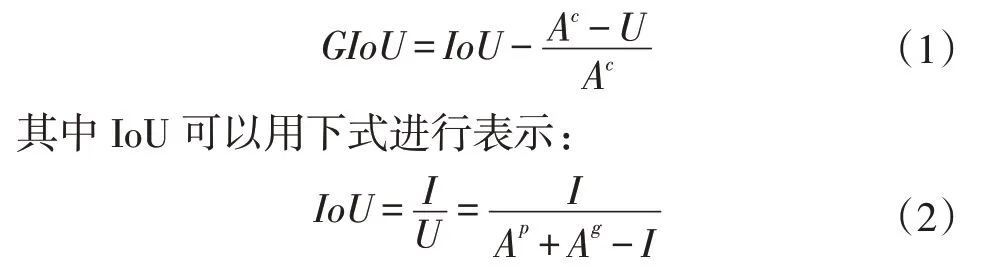
其中I表示预测框与目标框的相交面积,U为预测框的面积Ap与目标框的面积Ag之和减去I,Ac为预测框与目标框的最小外接矩形的面积。
2.2 识别模块(LPCRNet)
CRNN网络由卷积层、循环层、转录层3部分组成,本文基于CRNN网络设计了LPCRNet。由于车牌图像的特征较为简单,LPCRNet的卷积层采用网络较浅的ResNet18中的卷积层来提取车牌图像的特征;循环层采用BiLSTM(即双向LSTM),BiLSTM对车牌的上下文信息有较好的表示能力,合并正向LSTM和反向LSTM的序列信息完成对序列标签的预测;最后的转录层使用CTC方法对BiLSTM输出的预测序列进行对齐映射,输出预测的车牌号码。识别模块结构如图2所示。
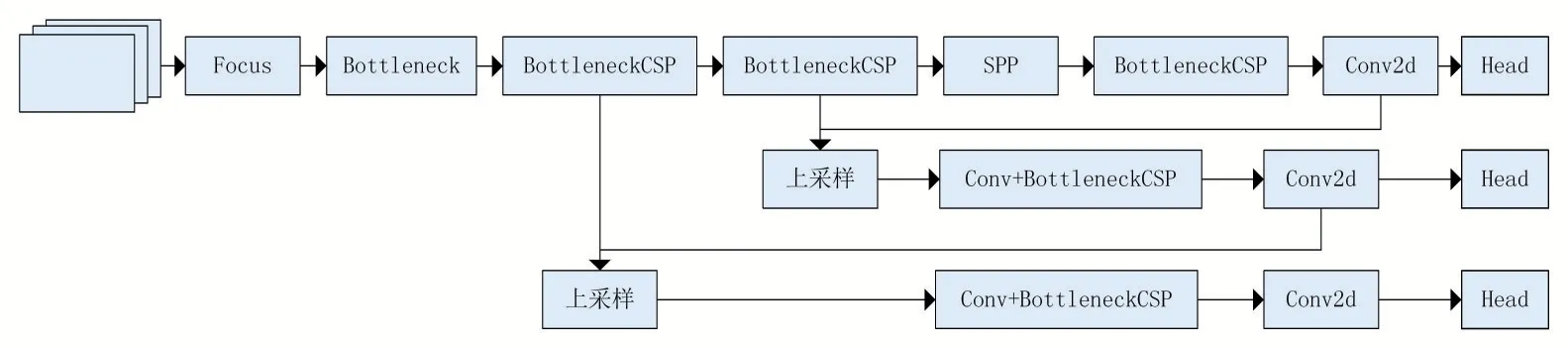
图1检测模块网络结构
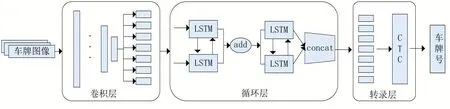
图2识别模块网络结构
循环层通过叠加两个BiLSTM网络将输入的序列特征进行解码,第二层LSTM的处理过程可以用以下公式表示:
识别模块的训练过程中,目标是通过循环层的输出序列找到概率最大的近似最优路径。
3 实验结果与分析
3.1 数据集与评价指标
(1)数据集。实验数据集来源于中科大的研究人员构建的CCPD数据集[13],包含25万多张图片,其中包括9种不同的场景:模糊、异常天气、倾斜等。具体内容如表1所示。
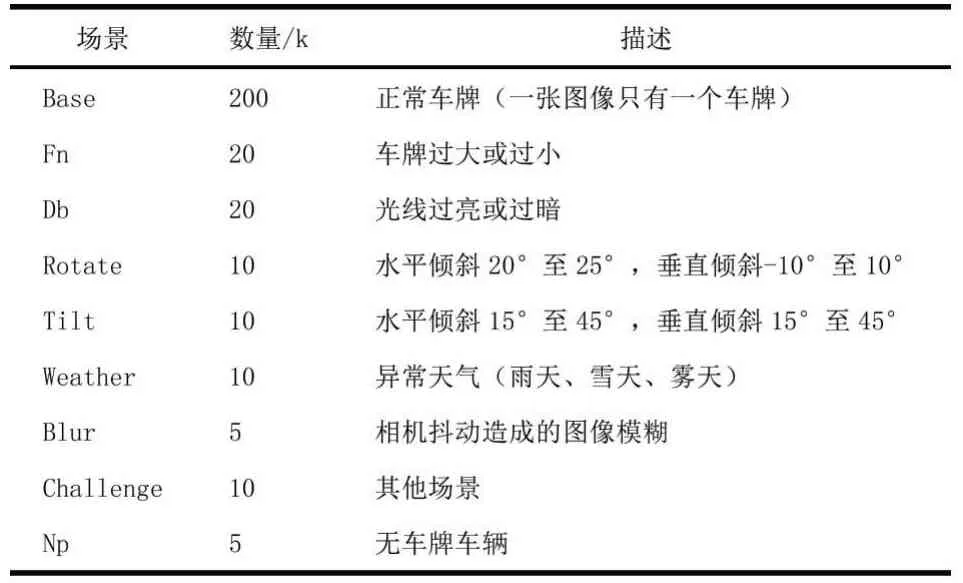
表1 CCPD数据集内容
实验随机选取除无车牌外的其他8种场景下的10000张图作为车牌检测的数据集,根据图片中车牌的坐标截取出的10000张车牌图像作为识别模块的数据集,其中8500张作为训练集,1500张作为测试集。
(2)评价指标。检测模块使用目标检测中较常使用的准确率(Precision)和召回率(Recall)进行评估性能。车牌字符识别有两种常用评价方法,一种是整体评价,另一种是字符级评价。整体评价是指车牌所有字符都识别正确的数量在测试集总数中所占的比例,公式如下:

其中,Cp表示字符全部识别正确的车牌数量,Np表示测试集的样本总数。还有较为常见的5字识别率和6字识别率,分别表示车牌中正确识别5个字符和6个字符的数量与测试集总数的比例。
字符级评价指的是测试集中识别正确的字符数占所有字符的比例,公式如下:

其中,Cc表示所有识别正确的字符数,Nc是指测试集中所有字符数。
本文基于以上两种评价方法对识别模块进行评估。
3.2 实验结果
各场景下车牌检测效果如图3所示,由检测结果可知,检测模块对于多种复杂场景下车牌定位具有较好的效果。

图3车牌检测实例
本文检测模块与其他目标检测算法在CCPD数据集上的实验对比结果如表2所示,由对比结果可知,本文方法的准确率和召回率明显高于SSD算法,且速度都较快于其他算法。
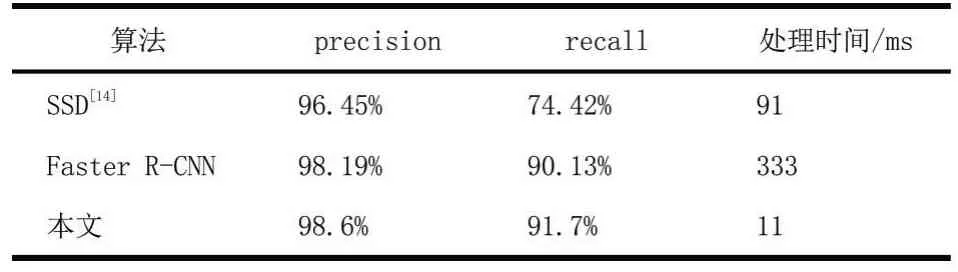
表2不同车牌检测算法的检测结果对比
识别模块与其他字符识别算法的对比结果如表3所示,结果表明LPCRNet在识别率和速度上都优于对比算法。
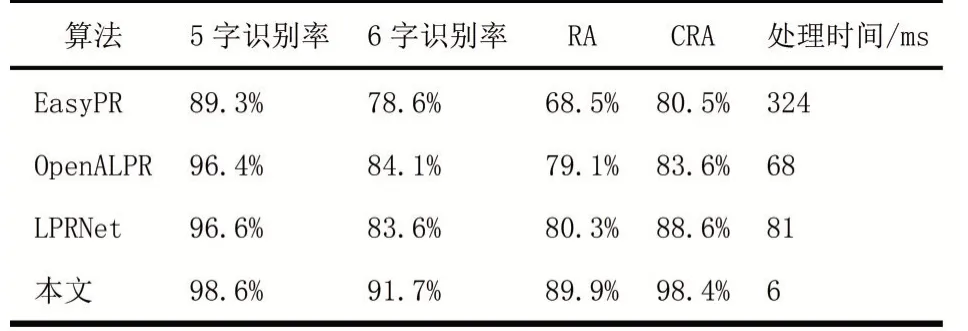
表3不同车牌识别算法的识别结果对比
4 结语
由于车牌识别在光照过亮或过暗、车牌倾斜、异常天气等场景下的识别效果不尽如人意,本文提出了基于深度学习的车牌识别算法,检测模块基于YO⁃LOv5网络结构定位出图像中的车牌位置,识别模块设计无分割的字符识别算法(LPCRNet),首先将图片输入卷积层对车牌图像进行特征提取,接着将车牌的序列特征送入双层的BiLSTM网络对序列标签进行预测,最后使用CTC对预测标签转录得到最终的预测车牌号。本文提出的算法在CCPD数据集中各复杂场景下的车牌检测准确率达到了98.6%,字符识别的准确率达到了88.9%,实验结果表明,本文提出的算法对于复杂场景下车牌的检测和识别都有较好的鲁棒性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
电脑报(2021年41期)2021-11-04
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑知识与技术(2019年29期)2019-12-16
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电脑爱好者(2019年8期)2019-10-30
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
农机使用与维修(2014年10期)2014-10-23
