
基于LSTM+FP-Growth算法的印刷设备故障预警及诊断
2021-10-15 12:40:46江朋陆远胡莹
南昌大学学报(工科版) 2021年3期
江朋,陆远,胡莹
(南昌大学机电工程学院,江西 南昌 330031)
随着科学技术的发展,印刷设备的工作要求不断提高,其结构也趋于复杂化和精细化。在印刷设备运行过程中对连续运行要求高,且其检修、维护较为困难。因此,如何实现对设备故障的及时诊断和提前预警成为了印刷企业最重视的问题。
传统的故障诊断技术多采用单一参数指标,通过对其特征提取来完成设备的故障预警,而现代机械设备由于其复杂性和精密性,运行过程中有着多个关键参数,且常常伴随着多个故障同时出现的情况。因此传统故障诊断技术已远远不能满足企业的实际需求,采用多参数融合技术[1]进行设备的故障预警逐步成为研究的热点。近几年,国内外不少学者致力于多参数融合预警技术的研究,并取得了很大的成效。对于复杂旋转机械的故障诊断问题,王炳成等[2]提出了一种基于多参数融合的非线性度来解决,通过运用相空间重构理论和信号特征整合的方法,对多个非线性故障信号进行时间序列重构及特征参数融合,实现对不同故障信息的准确识别。冯玉芳等[3]通过将BP神经网络模型和改进量子蜂群算法相结合来处理多信号参数的输入,完成对旋转机械的故障诊断及预测。Cai等[4]则提出了一种基于面向对象的贝叶斯网络(OOBNs)的复杂系统的实时故障诊断模型,通过多源信息融合技术来解决故障诊断中的不确定性。Jiang等[5]采用离散熵的多序列聚合方法,结合LSTM神经网络,对高维度的多个数据集进行分解、聚合等处理,最大程度保留了多尺度参数的有效信息,实现对航空发动机健康状态的预测。
本文提出了一种新型的集成故障预警模型——基于长短期记忆网络和FP-Growth算法相结合的故障预警方法。该方法针对印刷设备的特点,采用FP-Growth算法对历史运行数据进行特征提取,并结合设备故障检修记录对故障进行分类匹配,构建设备故障诊断专家知识库,完成对设备运行现场数据的故障诊断。核心部分还引入LSTM网络处理运行参数的复杂关系和时空特征,将多个相关参数统一考虑,实现对设备运行状态的有效预测,完成设备的故障预警。最后,通过相关仿真测试验证了模型的可行性。
1 LSTM网络与FP-Growth算法原理
1.1 长短期记忆(LSTM)网络
1997年,Hochreiter等联合发表了与长短期记忆[6](long short-term memory,LSTM)相关的论文,自此,长短期记忆网络开始逐步进入人们的视野。
长短期记忆网络是一种特殊的递归神经网络(recurrent neural network,RNN)。RNN结构如图1(其中w、u、v为各类权重,X表示输入,O表示输出,S表示隐层处理状态)。

图1 RNN模型展开图
但当时间序列间隔和延迟较长时,RNN会出现梯度爆炸及梯度消失现象,这严重影响了数据预测的准确性。因此,引入其改进模型LSTM,来处理和预测长时依赖问题。LSTM模块结构如图2所示。


图2 LSTM模块结构图
设定Wf、Wi、Wo、Wc以及bf、bi、bo、bc分别为3个门和单元状态输入的权重矩阵及偏差项,W为输出层和隐藏层间的权重,b为输出层的偏差项。
首先计算3个门的值和单元输入状态的值。遗忘门和输入门用于更新单元内部状态:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
输出门控制当前单元状态,决定输出的内容:
Ot=σ(Wo·[ht-1,xt]+bo)
(3)
单元状态输入则通过tanh层生成新的候选值添加到单元状态中去:
(4)
通过遗忘门与前单元状态输入丢弃不必要的信息,输入门和单元状态输入保留新输入的有效信息,得到单元的输出状态为:
(5)
然后,利用输出门和单元的输出状态决定处理模块的输出:
ht=Ot·tanh(Ct)
(6)
通过上述LSTM模块计算所得的ht值,预测网络的输出:
xt+1=W·ht+b
(7)
本文主要借助LSTM模块的神经网络训练模型,从一组与时间序列相关的数据中提取出数据未来的特征变化,完成对各个参数的有效预测。
1.2 FP-Growth算法
常用的挖掘频繁项集的算法主要是Apriori算法,其缺陷在于原始数据量过大时,频繁项集的发现速率相对低下。为改善其不足,提出FP-Growth算法,通过对原始数据集进行两次扫描完成对频繁项集的搜索,提高了对数据的处理效率。
FP表示的是一种频繁模式,其算法步骤如下:
1) 扫描原始数据集,获取数据集中每个元素出现的频率;
2) 进行支持度过滤操作,删去其中不符合最小支持度的元素项;
3) 扫描保留的频繁元素项,并按照元素项的关键字进行降序排序,构建FP-Tree;
4) 从构建完成的FP-Tree中抽取频繁项集。
FP-Tree的构建中使用到最小支持度,其描述如下。
设
Z={z1,z2,z3,z4,…,zk}
(8)
是由k个不同的数据项目组成的集合,其中:每个元素称为项,项的集合称为项集。给定一个事务数据库:
B={T1,T2,T3,T4,…,Tm}
(9)
式中:每一个事务T都是项集Z的一个子集,|B|为B中的总事务数,X、Y都是T中的项或项集,且X和Y满足X∩Y=φ。若事务T同时包含X和Y,设S为满足条件的事务T在事务数据库B中的所占的比例,即支持度,则
(10)
设C为B中所包含的事务X中又包含事务Y的比例,即信赖度,则
(11)
最小支持度和最小信赖度分别用支持度阈值Smin和信赖度阈值Cmin表示。
该算法虽能更高效地发现频繁项集,但不能直接用于发现关联规则。关联规则的挖掘还需要利用该算法得出的频繁项集来产生,其流程如下:
1) 对事务数据库中的数据进行预处理;
2) 初步设定事务数据库的支持度阈值和信赖度阈值;
3) 采用FP-Growth算法构建FP-Tree,搜索频繁项集;
4) 根据事务库中数据的实际情况调整支持度阈值和信赖度阈值,修剪非频繁项集;
5) 利用满足支持度阈值和信赖度阈值的频繁项集抽取关联规则。
同时满足支持度阈值和信赖度阈值条件的频繁项集所产生的规则称为强关联规则,即为数据挖掘的目标。规则的抽取就是选取符合条件的频繁项集按照与预处理步骤相逆的过程所生成的关联规则。本文目的就是通过关联规则挖掘算法将各参数的异常变化与设备故障类型间的关联规则进行发掘,利用各参数的预测值对设备的状态进行预测。
2 故障诊断及预警模型设计
2.1 模型框架
印刷凹印设备常常由于其主传动轴不对中、不平衡,润滑及传动系统故障产生各类事故。因此,本文提出的基于LSTM网络和FP-Growth算法相结合的印刷设备故障诊断及预警模型用于设备状态预测,其系统架构如图3所示,主要由数据采集、数据存储、数据预处理、数据分析及模型应用五大模块构成。

图3 印刷设备故障诊断及预警系统架构
各功能模块具体描述如下:
1) 数据采集。数据来源主要包括各类型传感器所采集到的数据,凹印设备控制器所记录的印刷设备各项运行参数及专家知识库中的故障诊断记录等。其温度传感器与流量传感器安装的点位分别分布在压印、印版、集色滚筒两侧,共6个测点。
2) 数据存储。线边控制系统通过以太网与PLC、凹印设备控制器及故障诊断专家知识库连接,将相关数据提取到线边数据库,为设备预警提供信息支撑。线边数据库又分为实时数据库和关系数据库两部分,实时数据库主要用于存储设备控制器及PLC采集的实时数据,然后将这些数据信息通过抽取、提炼和持久化转换为有效参数存入关系数据库中。
3) 数据预处理。通过设备管理系统每隔固定时间同步线边数据库,读取到相关数据。同时通过数据清理和数据变换,保证数据的准确性和完整性。数据清理过程包括对数据进行缺失值补充,对错误或重复数据的剔除等;数据变换则是将数据规范化,使其转换成适用于数据挖掘的形式,主要方式有数据归一化、文字数值化等。
4) 数据分析。该模块在数据预处理的基础上对数据的各项特征进行提取。采用FP-Growth算法对各数据集进行挖掘,得到与故障类型相关的关联规则,并将新规则存入故障诊断专家知识库进行规则更新,用于设备故障的在线诊断。同时运用LSTM网络建立预测模型,通过不同的数据集对模型进行训练,得到各数据在下一时段的预测值,然后借助专家库对设备进行故障预测。
5) 模型应用。根据数据分析模块对设备故障的诊断和预测,对其分析结果进行可视化操作,以图或表等形式向用户直观地展现各类故障预警信息。
2.2 基于FP-Growth算法构建专家知识库
对印刷设备来说,不同的故障类型直接反映在设备的故障维修记录中,因此印刷设备故障关联规则挖掘的首要目标是各个故障维修记录。根据故障维修记录中设备各运行参数的数据特征与设备故障代码、维修诊断结果等的相关关系,产生一定的关联规则,用于构建初始的故障诊断专家知识库。其构建流程如下:
1) 读取设备故障维修记录中的各项数据;
2) 对数据进行预处理,并设定支持度与可信度阈值;
3) 构建FP-Tree,搜索频繁项集;
4) 调整阈值,修剪非频繁项集;
5) 搜索完成,抽取关联规则;
6) 将获取的规则进行规则逻辑性检验,检测无误后存入故障诊断专家知识库中,完成初始专家库的构建。
运用专家知识库进行印刷设备的在线故障诊断,其诊断流程图如图4所示。对于与专家知识库既有规则不匹配的故障类型进行规则检验,若其不包含错误信息,则根据实际维修情况增加新规则。对于可通过专家知识库诊断出的实时故障,应及时出具诊断说明,并制定相应的维修计划对设备进行检修。每次诊断完成后,还应实时更新专家知识库(包括诊断规则、故障类型及规则信赖度等)。

图4 在线故障诊断流程图
2.3 基于LSTM网络的设备状态预测模型的建立与仿真
2.3.1 构造模型的输入与输出
设备状态预测模型的输入主要为设备故障特征参数A、设备运行参数B及环境因素C等,对应的设备的每一个工作状态X都有对应的A、B、C值,如式(12)。
X={A,B,C}
(12)
1) 故障特征参数:印刷设备可依据各类传感器反映的设备故障特征参数来监控设备运行状态,例如:使用电涡流传感器测得轴的径向位移,监控轴的平衡与对称性;采用红外温度传感器测量滚筒的轴承温度,以保障合适的设备运行温度;使用流量计计量润滑油脂流量,监测设备润滑系统的工作。
从印刷凹印设备的实际工作情况出发,发现设备出现故障时,易导致其温度和润滑油脂流量产生较明显的异常变化,如轴故障、齿轮故障等。温度的变化对于运动件来说,是其是否在正常工作范围的重要指标,而润滑油的作用则是对运动件进行润滑、降温,减少机械磨损等,故选取轴承温度及润滑油脂流量作为设备主要的故障特征参数。
2) 设备运行参数:主要是原凹印设备控制器在设备运行时所监控的各项参数值,包括设备运行时的电压、电流、工作负载、运行转速等数值。
3) 环境因素:包括设备工作空间的温度、湿度等。
为保证各输入参数在同一量纲下,需要采用不同的数据处理方式对不同的参数类型进行规范化处理。待各参数特征提取完成后,按以下规则构造模型的输入与输出:
1) 数值分布较为集中的数值类变量(如轴承温度、润滑油脂流量等)采用离差标准化的方法处理,通过对原始数据的线性变换,使其结果值映射到[0,1]之间,如式(13)。
2) 原始数据分布呈近似正态分布的数值类变量(如环境温度、湿度等自然因素)采用Z-Score标准化方式处理,使变量数值都聚集在0附近,方差为1,如式(14)。
3) 文字类型变量,则需先对变量进行分类,然后按照顺序分别转成数值1,2,3,…进行处理;若此类变量只存在发生与不发生两种情况,则按情况有无发生转换成数值1或0。
(13)
(14)
其中:xmax、xmin分别为某参数样本数据中的最大值与最小值;μ为某参数所有样本数据的均值;σ为其标准差;x为参数变量处理前的指标数值;x*为处理后的指标数值。
2.3.2 构建设备状态预测模型
设备的工作状态与其运行过程中的关键参数息息相关,且各参数间也存在着特定的联系,故本文采用LSTM网络构建印刷设备工作状态预测模型。本模型的输入与输出参数一致,其核心模块为一个3层的循环模块,其结构如图5虚线部分所示。主要包括两个全连接层和一个隐藏处理层,第1个全连接层负责对输入的不同参数进行特征整合;第2个连接层则作为数据分类层,输出不同类型参数的预测值;隐藏层即为LSTM神经网络处理模块,实现对输入值的预测。其余参数再选取为工业界常用的一般值,这些参数包括学习率、初始权重、网络结构参数等,模型架构如图5所示(图中at表示t时刻参数a的值)。

图5 设备状态预测模型架构图
2.3.3 模型训练及仿真
为保证模型训练精度,选取南昌市某特种印刷企业某台凹印设备2019年全年运行数据的数据集作为训练样本对设备状态预测模型进行训练,全部样本数为300组,约3 600条数据记录。通过对设备历史运行数据进行预处理,将其分割成多个连续的时间序列数据,其中80%作为训练样本,20%作为测试样本。每个训练样本都由两个相邻时间段的时间序列组成,随机选取训练样本对构建完成的状态预测模型进行训练。
为了使模型训练过程可视化,引入平均绝对误差(mean absolute error,MAE)作为损失函数,对模型的训练结果进行监测。当该数值越趋近于0时,则说明预测模型的拟合度越好,预测数据的准确度越高,其计算公式如式(15)。根据MAE值及误差反向传播算法不断调整模型各权重系数,经过预测值与真实值的对比分析,最终得出拟合准确度较高的预测模型。

(15)
式中:NMAE为网络模型训练时的损失函数值;y(i)为数据的实际监测值;y*(i)为设备状态预测模型输出的预测值。
1) 计算不同时间步长下训练数据集的MAE值确定模型的时间步长。取不同的时间步长的对模型进行训练,观测其训练效果,如图6所示。
由图6可知,不同时间步长下,模型的训练效果有差异,随着步长的增加,模型训练效果逐渐变好,但当时间步长增加到6时,模型表现变差。故时间步长为5时,模型训练效果最好,即通过参数前5个时间序列的数据预测第6个数据值。

时间步长
2) 取时间步长为5,对模型进行训练并观察其损失值变化,其模型训练过程中损失函数的变化如图7所示。
从图7可以看出,经过600次左右的模型训练后,损失函数指标稳定在0.25左右,最终训练样本的拟合度约为98.5%,模型训练效果较好。拟合度计算公式如式(16)、式(17)所示:

训练周期
Q=∑(y-y*)2
(16)
(17)
式中:Q为残差平方和;Rnew为拟合度指标;y为实测值;y*为预测值。
模型训练完成后,通过测试样本中t时刻的设备运行参数值at即可得出其下一相邻时刻t+1的参数预测值at+1,然后采用迭代方法[8]逐点预测设备未来各时刻的运行参数值。通过设备状态预测模型完成对各关键参数值的预测,针对其中异常的A、B、C参数,会触发对异常数据的提取过程,然后结合专家知识库进行故障在线诊断,完成对设备工作状态的预测,实现对设备的有效预警。
3 模型验证
在设备正常运转过程中,其运动件的温度、润滑油脂流量在预警系统中实时显示(图8),且都有一定的限值(温度限制值为48 ℃,流量上、下限值分别为65 mL·min-1及80 mL·min-1),超限则意味着设备发生故障,例如:油管破裂、脏堵及阀门损坏易引起流量超限,轴承、轴等的变形及磨损易导致温度超限。通过对不同的温度、流量监测曲线与正常工作曲线的比较分析,借助温度与流量的变化幅度来判断运动件的工作状态,如图9所示。
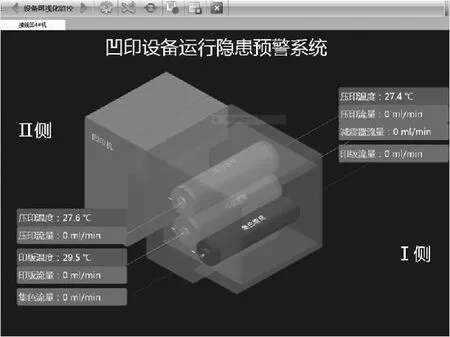
图8 系统实时画面
如图9(a)中监测的温度发生了尖峰突变,可判断出运动件发生损坏等情况,发出预警信号。图9(c)处流量曲线发生阶梯变化,根据曲线阶梯的大小,发出管道破裂或堵塞的预警信号。图9(b)、(d)中,温度、流量曲线发生波动,可依据波动范围的大小及曲线斜率的突变,判断设备相关部件的状态,超限时发出预警信号。通过模型故障特征参数温度、流量,设备运行参数工作负载、运行转速等因素的异常变化,结合专家知识库来判断设备所存在的故障及其故障类型。

t/min
3.1 状态预测模型预测效果测试
通过样本的随机选取,确定以2019年7月9日设备运行数据作为测试样本对训练模型进行测试,用于预测后1 d设备全天(9:00—20:00)运行各参数值,并与当天设备实际记录的各参数值进行对比,采用相对误差作为衡量标准来评价模型预测的准确度,如表1(选取轴承温度、润滑油脂流量两个重要的故障特征参数作为模型验证参数)。

表1 模型部分参数的预测值及相对误差表
由表1的预测结果可以看出,该模型对不同参数的预测值与其实际检测值近似,相对误差基本控制在4%以内,表明模型预测准确度较高。
3.2 专家知识库故障诊断测试
测试一:通过对设备历史维修记录的收集,得到了233条故障记录,以此分别建立含200条故障记录的挖掘库和含33条故障记录的测试库,在计算机上进行故障诊断实验。
为了测试借助FP-Growth算法所构建的专家库用于设备故障诊断的优越性和准确性,设计测试内容如下。
1) 将挖掘库中200条故障记录通过数据预处理按故障性质分组,分别采用FP-Growth算法和Apriori算法挖掘频繁项集,产生关联规则,构建专家知识库。
2) 设备实际运行过程中发生故障概率较低,因此向测试库中继续添加567条设备正常运行的数据记录,利用专家知识库对共600条测试数据分别分成3组(每组包含189条正常数据和11条故障数据,数据随机抽选),针对轴故障、轴承故障、润滑故障、阀故障、齿轮故障、电机故障等多种设备常见故障进行故障诊断。测试结果如表2所示。

表2 不同算法故障诊断的效果比较
测试二:随机选取2020年某个月(测试中选取4月份数据,共30组,约360个数据样本)的设备运行数据,记录该月凹印设备实际的故障发生情况,通过设备状态预测模型对该月设备的故障特征参数温度、流量的变化,设备运行参数工作电压、电流及环境因素等进行预测,将预测数据作为测试样本,借助测试一中FP-Growth算法所构建的专家知识库进行设备故障诊断测试。
针对测试结果与实际故障情况进行比较,其诊断结果如表3所示。可知,该模型故障预测的准确率为90%,且误诊率较低,约为1.67%,诊断效果较好。

表3 模型故障诊断的测试记录

续表3 模型故障诊断的测试记录
4 结束语
结合设备中多个监测参数间的耦合关系,本文采用多参数信息融合预警技术及关联规则数据挖掘算法提出了一种基于LSTM和FP-Growth算法相结合的印刷设备故障预警模型,并通过相关的模型仿真及故障测试,取得了期望的预测效果,充分证明了模型的有效性和可行性。综上所述,得出结论:
1) 过LSTM网络来处理和预测时间序列参数,有效解决了传统神经网络构建模型中的权值更新问题,提升了模型的训练效果。
2) 用FP-Growth算法产生关联规则,用其所构建的专家知识库对于印刷设备的故障预警效果更好,故障预测准确率更高,且其算法速度快,对设备的故障诊断效率大大提高。
故采用LSTM网络结合FP-Growth算法所构建的预警模型满足模型预测标准,能够应用于印刷设备的故障诊断与预警。进一步提高对设备故障预测的准确性及实现设备状态的长时间预测是下一步的研究目标。
猜你喜欢
制造技术与机床(2019年6期)2019-06-25 10:17:46
中国交通信息化(2016年9期)2016-06-06 07:42:23
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
图书馆研究(2015年5期)2015-12-07 04:05:48
卷宗(2014年5期)2014-07-15 07:47:08
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
机械与电子(2014年1期)2014-02-28 02:07:31
计算机工程(2014年6期)2014-02-28 01:26:12
河南科技(2014年3期)2014-02-27 14:05:48
网络安全与数据管理(2010年1期)2010-05-18 07:28:54
