
关系型数据库内存化存储模型研究
2021-10-14 06:34廖雪花余旭玲
计算机工程与应用 2021年19期
张 俊,廖雪花,余旭玲,雷 蒙
1.四川师范大学 计算机科学学院,成都 610101
2.四川师范大学 物理与电子工程学院,成都 610101
传统关系型数据库(MySQL)通过磁盘管理数据,大数据环境下,高并发请求会频繁地访问磁盘操作数据,由于磁盘的物理结构限制,数据库会面临着高稳定性和高性能的挑战,完全基于磁盘读写的关系型数据库已经不能满足新应用的扩展性和时延需求。然而MySQL在历史上积累了大量数据[1],为了能继续充分利用这些数据,继续为用户提供服务、为企业创造更多的价值,MySQL提供了MEMORY存储引擎。该存储引擎将所有数据放在内存中。但引擎对数据字段类型有限制,表容量较小,随着数据量的增加,需要多次的手动修改以维护容量,应用配置复杂。同时该引擎在数据持久化方面存在严重问题,其数据易丢失。
本文提出基于Redis 实现MySQL 数据库内存化的方案,相较MySQLMEMORY,Redis 支持多种数据结构,拥有NOSQL 高扩展性的优势,同时由于Redis 在高并发场景下表现出的极高性能和易于配置、部署的优势,Redis在内存数据库中获得了广泛的认可。本文利用Redis解决高并发场景下MySQL的I/O瓶颈问题[2],其核心思想是将MySQL中的热点数据迁移到Redis中,应用程序通过Redis访问数据,实现海量热点数据的高效存取。
现阶段大多应用系统使用结构化查询语言SQL 操作MySQL 数据库,但Redis 目前不支持标准SQL 访问,无法兼容现有系统的访问模式;为了降低数据的学习成本和处理成本,本内存化方案后期将展开Redis 对查询语言SQL的支持的研究。本文根据SQL化查询的需要,对MySQL和Redis的存储模型架构进行研究,构建合适的存储模型转换模型,通过数据存储模型实现异构模型的转换[3],进而实现数据迁移。同时在数据迁移过程中不断提高内存利用率,并考虑数据访问和操作效率。
随着数据的爆炸式增长,传统的关系型数据库在高并发模式下存在I/O 瓶颈问题,很多关系型数据库推出了自己的内存化解决方案,内存+关系型[4]数据库的组合成为趋势。主要包括两个方向:内存数据库引擎、关系型内存数据库[5]。
在关系型数据库内存数据库引擎方面,Oracle推出的内存数据库Oracle TimesTen 不提供开源技术支持;2013年IBM新推出的DB2 BLU Acceleration是基于列式的存储,实际应用中需要做数据迁移和模型转换;此外,2016 年微软推出了SQL Server 2016 In-memory OLTP;SAP 推出了包含内存数据库的SAP HANA,它融合行存储、列存储和对象存储的数据库技术,但系统过重,配置、操作异常复杂,应用成本很高;MySQL推出的内存存储引擎MySQL MEMORY在数据类型上有限制,同时在数据持久化方面存在严重问题。
关系型内存数据库也是解决传统关系型数据库I/O瓶颈的重要方案,它将传统的关系型数据库表搬到内存中,内存数据和数据库数据之间进行结构映射。实际使用可以将热点数据存放在内存中,降低和数据库之间的交互频率,提升数据访问速度;但直接使用也涉及到数据迁移,且该技术生态尚未完全成熟,直接使用也存在较多限制。
不同的数据库进行转换涉及到不同的数据库之间不同存储模型的转换;大量的研究者从事基于不同数据库和不同存储模型的存储模型转换工作,提出了不同模型之间转换的思想和方案。
Lee 等人[6]2015 年提出了通过MySQL 和HBase 数据库自动进行SQL 到NoSQL 模式转换,提供了一个从SQL 到NoSQL的转换模式。Stanescu 等人[7]2016年提出了将MySQL数据模型转换为MongoDB模型的算法,借助Pentaho 集成工具,使用Net Beans Java IDE 实施了该算法。2017 年,也提出了通过设计数据模型转换器将关系型行存储转化到文档存储MongoDB 中,并通过SVM对MongoDB中的数据的进行快速分析和处理。2018 年,杨明眠等人[8]利用二进制日志文件将MySQL的行存储模型转换为Oracle的行存储模型切实可行的方法,实现关系模型到关系模型的转换。同年,Yassine等人[9]在MySQL数据转换到MongoDB数据库做了大量的研究,最终将MySQL的数据存储模型转换为MongoDB的文档存储模型后进行存储。贾天宇等人[10]公开了一种关系型数据库到MongoDB的模型转换和数据迁移方法的专利发明,该发明通过对关系型数据库的日志信息进行了挖掘,进行更加科学的模型转换。国内外数据迁移[11]工具的研究现状,是这些迁移工具虽然都可以完成数据的迁移工作,但是整体上存在以下几点问题:
(1)对迁移的数据库的模式和组织结构有一定的局限性。
(2)数据迁移的前期准备工作复杂、多样,配置复杂,实施困难。
(3)未长远地考虑到数据迁移后的数据应用。
(4)大多研究都基于开源关系型数据库MySQL和文档存储数据库MongoDB,开源关系型数据库MySQL和键值数据库的数据模型转换还没有较为成熟的开源方案。
1 关系型数据库内存化架构
在本文内存化方案中,MySQL仅用作数据源使用,Redis 用于请求访问,首先在数据库层通过数据初始化模块初始化Redis中的数据。请求通过访问层访问数据层Redis中的数据,同时为了确保数据安全,按备份策略调用备份模块将Redis 中的数据备份到MySQL 中。本文的研究工作重点为数据初始化模块。方案的难点在于MySQL中的热点数据如何迁移到Redis中[13],并保证数据的高效存储和访问。MySQL数据库内存化架构如图1所示。
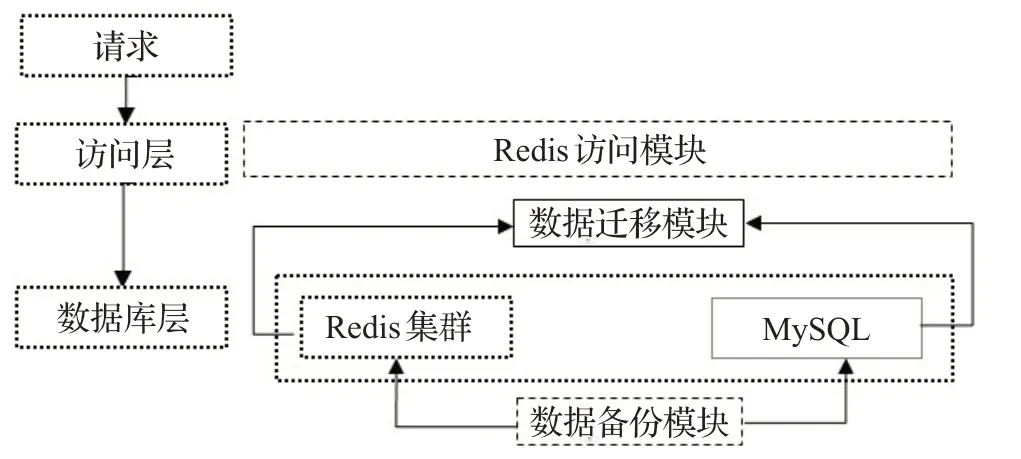
图1 MySQL数据库内存化架构Fig.1 MySQL database in-mesmory architecture
2 存储模型转换流程
内存化方案模型转换原型架构如图2 所示。首先通过MySQL 驱动与MySQL 交互获取MySQL 中元数据MetaData和数据Data,然后构建存储模型转换模型,最后以模型转换的结果为基础,通过Java Redis驱动与Redis 服务器连接实现自动化数据迁移[14]。其中,模型转换核心分为MySQL Schema解析和创建Redis Schema,难点在于模型转换,即如何构建模型实现异构数据库存储模型的转换[15-16]。本文综合Redis Hash 结构的优势,构建行式键值和分段列式交叉键值模型实现存储模型转换。
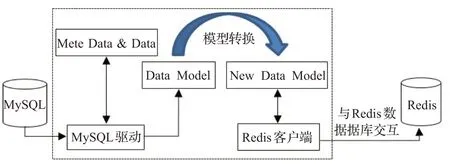
图2 模型转换原型架构Fig.2 Prototype architecture of model transformation
3 行式键值模型
3.1 模型构建流程
行式键值模型的核心是将原MySQL库表中的每行数据转变为Redis中的一个Hash结构。其中key由唯一序列、库名、数据表名、主键名构成,唯一序列用于区分同一个数据表中的不同数据行,确保Hash结构中key的唯一性,field为行数据的列,value为对应列的值。行式键值模型流程如图3,具体核心步骤如下:

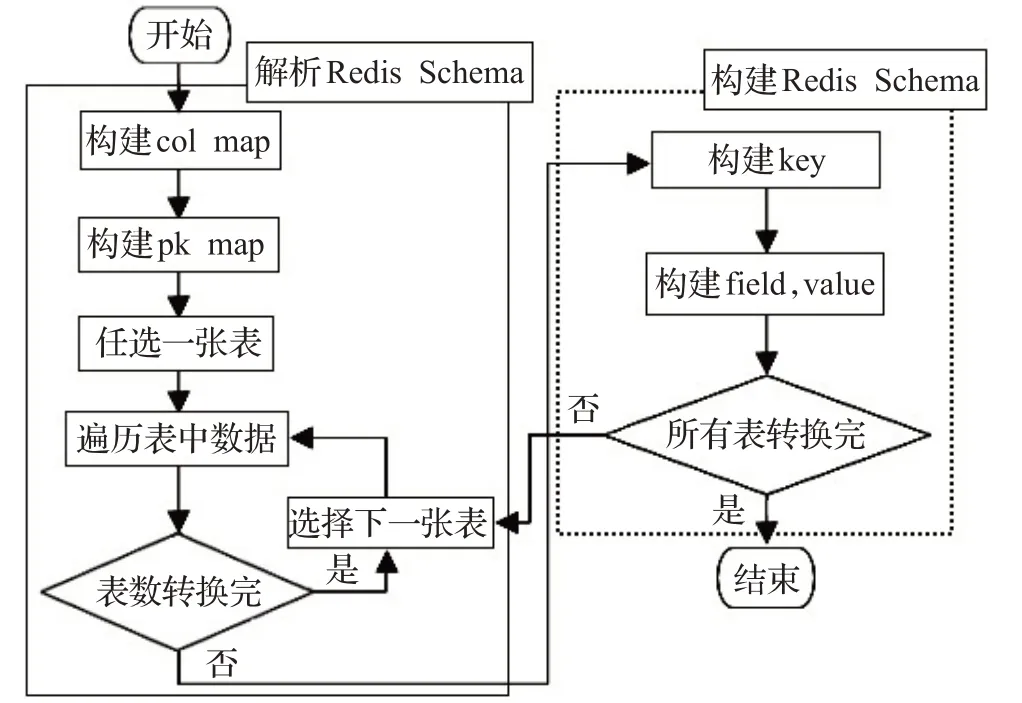
图3 构建行式键值模型流程图Fig.3 Flow diagram of building RB-KVM
3.2 模型构建算法
3.2.1 构建key
在Redis中,数据按照键值对的形式进行组织、索引和存储。利用key去定位value是一个复杂度为O(1)的操作,为了保证查询效率,本文的key 采用String 类型,key由唯一序列、库名、数据表名、主键名构成;唯一序列是为了区分原MySQL 表中的不同记录,主键名用作后期研究不同的数据进行关联或者查询的关键枢纽。唯一序列全局唯一,在数据迁移过程中将生成唯一序列号。key的构建原理如图4所示。

图4 行式键值模型key构建原理Fig.4 Key construction principle of RB-KVM
key的构建流程描述如下:
(1)定义MySQL 中数据库名称DB,利用(1)中的Ti方法在DB中的所有表中选择任意i∈(count(Tai))表Tai;
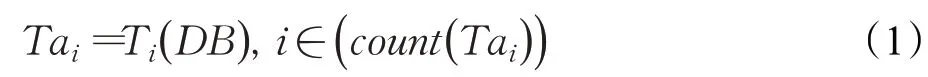
(2)若Tai中主键PK存在,通过式(2)中的Pi方法获取到Tai中的主键PKx,否则PKx的值为默认值dpk。
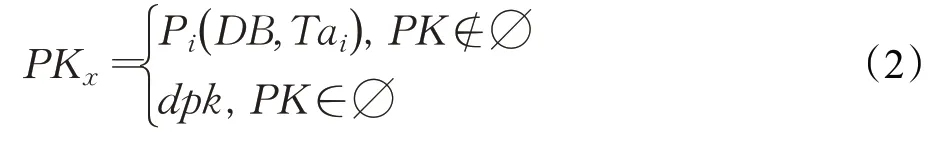

(4)利用(3)中的结果和唯一序列r,通过M方法得到Ki,其中Ki原MySQL每行数据对应到Redis的key-value结构中的key,如公式(4)。

3.2.2 构建Field和Value
RB-KVM 的field 为MySQL 行存储中每行记录的字段名,value 为字段对应的值,如图5 所示,在users 表中的userid 列值为“001”的行数据迁移到Redis 中构建一个Hash,其中Hash 中的key(K1)是利用3.2.1 小节中构建key 的结果,Hash 中的field 和value 由原行的所有的列名和值对应构成,例如:列“userid”和对应值“001”转换为field 为“userid”,value 为“001”的数据。进行数据迁移时,为降低内存占用率,本文在构建存储转换模型时,MySQL表中的null值将不被存储。
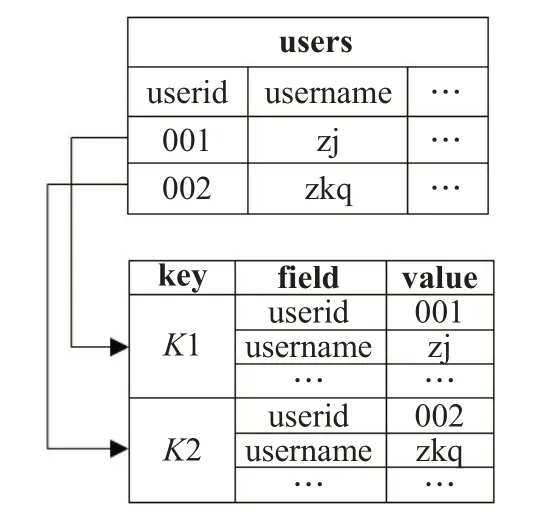
图5 行式键值模型field和value构建原理Fig.5 Field and value construction principle of RB-KVM
4 分段列式键值交叉模型
4.1 模型构建流程
结合列式存储对必要列进行查询的优点,本节基于Redis 的Hash 结构,提出构建分段列式键值交叉模型。其核心思想是将原MySQL库表中的每个表中数据转变为Redis 中的一个Hash 结构。其中Hash 中的key 标识表,field值为表中的所有列,每个field对应的value值为列filed的所有数据。但因为数据较多时,列式存储会造成Redis 中大value 的情况,会严重影响Redis 的性能。本方案在key中加入分段信息,通过分段策略将该表分为多个Hash存储,拆分大value,保证Redis的性能。
模型构建流程与3.1 节中一致,不同体现在模型构建算法不同,具体算法参考4.2节。
4.2 模型构建算法
4.2.1 构建key
分段列式键值交叉模型中key 的构建流程与行式键值模型中key的构建流程类似,这里不再赘述。不同点在于当表中的数据量N超过阈值T,可以自定义分段值T,将表中的数据分段存储为个Hash,以此拆分大value。其中每个Hash的key中将每次分段的开始行s和分段结束行e作为前缀,如公式(5)所示。key中的表名和分段值可以区别不同的表的数据和同表但不同段的数据,因此分段列式键值交叉模型的key中不需要唯一序列。
启示:这句谚语告诉我们,人生的道路并不是畅通无阻的,要坦然面对阻碍和困境,事到临头,必定会有解决的办法。但办法不会自己出现,还需要我们开动脑筋,主动思考:遇到山,要会迂回前进,寻找出路;遇到水,要会积极应变,寻找渡水的手段,这样才能达到既定的目标。
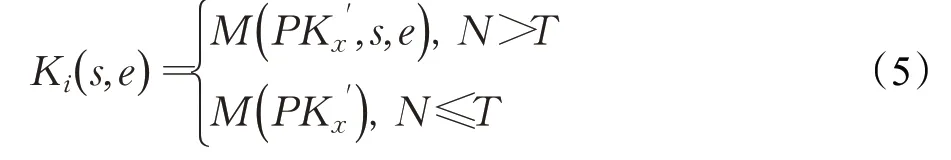
4.2.2 构建field和value
在分段列式键值交叉模型中,Hash 中的一个field存储表中的一个字段名,每个field 对应的value 值即为表中某列的所有值的set 集合,为保证每个列值保持与原行的联系,将每个列数据与对应行的主键值绑定作为Set 中的元素;这种方案仍然需要一定量的内存开销。在列式存储模型中同一个表的字段,若不考虑分段,则只存储一次;相较于在行式存储模型中,若原表中有n条记录,每个字段将会被记录n次,降低了内存开销。field和value的构建原理如图6所示。

图6 列式数据模型构建原理Fig.6 Construction principle of PCB-KVM
定义Tbi,数据行rt(t∈count(row)),字段列ck(k∈count(col)),数据值为v(t,k);定义表示行rt,即MySQL每行中的主键值;定义vtk表示ck列对应的所有数据。ck即field,vtk为value,其vtk的构建核心步骤如下:
vtk分为当前列是主键(ck∈pk)和非主键(ck∉pk)两种情况。当ck∈pk,聚合ck列对应的所有值的集合;当(ck∉pk),需要先通过F函数融合当前列ck与当前行主键值得到T(t,k),对行非主键列的值绑定对应行主键值。
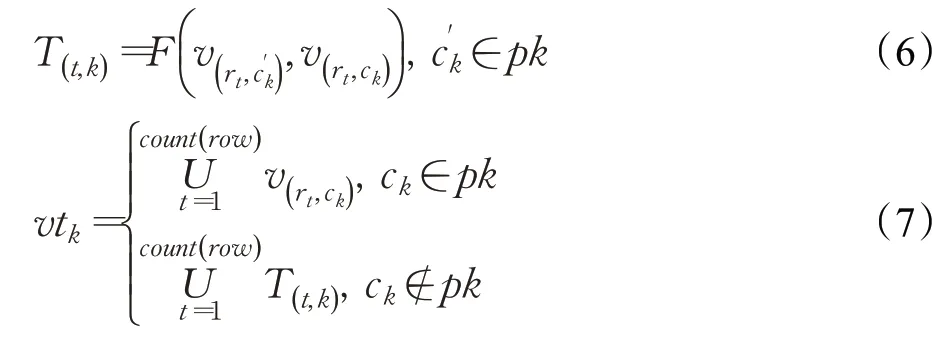
5 实验对比与分析
5.1 物理环境
本文测试服务器系统为Centos5.2,配置源数据库MySQL 和目的数据库Redis,其中分布式Redis cluster包括6个节点。关键配置如下:
(1)配置6台Redis集群服务器,端口分别为:8001、8002、8003、8004、8005、8006。启动Redis集群。
(2)配置MySQL 数据库和Redis cluster 集群的连接信息。
5.2 模型对比与分析
5.2.1 数据迁移结果
将MySQL 的jlabordispatch 库(以users 表为例,如图7)中的100 000 数据迁移到Redis 集群中。采用行式键值模型迁移后的效果如表1所示,以10 000分段采用分段列式键值交叉模型迁移后的效果如表2所示。

表1 RB-KVM数据迁移结果Table 1 Data migration results of RB-KVM

表2 PCB-KVCM数据迁移结果Table 2 Data migration results of PCB-KVCM
图7 用户表中部分数据Fig.7 Partial data of user table
5.2.2 模型分析与结果对比
针对数据迁移过程,若采用行式键值模型,需要先获取MySQL 中需要迁移数据的表结构的元信息,再批量获取同一个表中的数据得到结果集R,其中包含N条数据,对数据进行预处理(主要包括null的预处理)过程中,需要对结果集R中数据逐条处理并存储结果,则要额外申请结果集R的长度个空间,其空间复杂度为O(n);在进行null的预处理时,需要遍历处理R中的所有数据,时间复杂度为O(n),空间复杂度为O(n),采用多线程处理后(设定为x个线程),时间复杂度为,空间复杂度为O(n);预处理后的数据,进行二次构建形成新的适合Redis的数据结构,并迁移到Redis中,其空间复杂度为O(1) 。
分段列式键值模型的处理流程、处理流程与行式键值模型基本一致,数据预处理开销也一致,只是在构建部分的具体构建方式不同,主要体现在:当数据读取结果集为R,共有N条数据,需要遍历处理R中的所有字段,时间复杂度为O(n2),空间复杂度为O(n),其中N为结果集R中元素个数,采用多线程处理后(设定为x个线程),空间复杂度与原来一致,时间复杂度为O(n2/x)。
RB-KVM 基于最简单的Hash 结构,数据添加(一般情况)、删除、修改、读取的平均时间复杂度都为O(1) 。在PCB-KVCM 中,每个field 对应的value 是一个HashSet集合,对于新增、删除和contains,平均时间复杂度为O(1) 。
大数据环境下,数据库Redis 的性能主要体现在对海量数据的存取效率上,两种模型保存数据到Redis 平均时间复杂度都为O(1) 。但在PCB-KVCM中,获取具体的数据之前可以先判断元素是否存在,存在再对HashSet进行迭代取值,其中迭代的时间与实际HashSet的size和HashSet中的capacity之和呈线性关系,其取数据效率低于RB-KVM。
本节对MySQL数据库中表(以users为例,见图7),对users表中不同数量级(1 000,10 000,100 000,1 000 000)的数据分别利用两种模型完成数据迁移,经多次测试后,数据占用内存如图8所示。其中分段列式键值交叉模型中分段采用10 000分段。
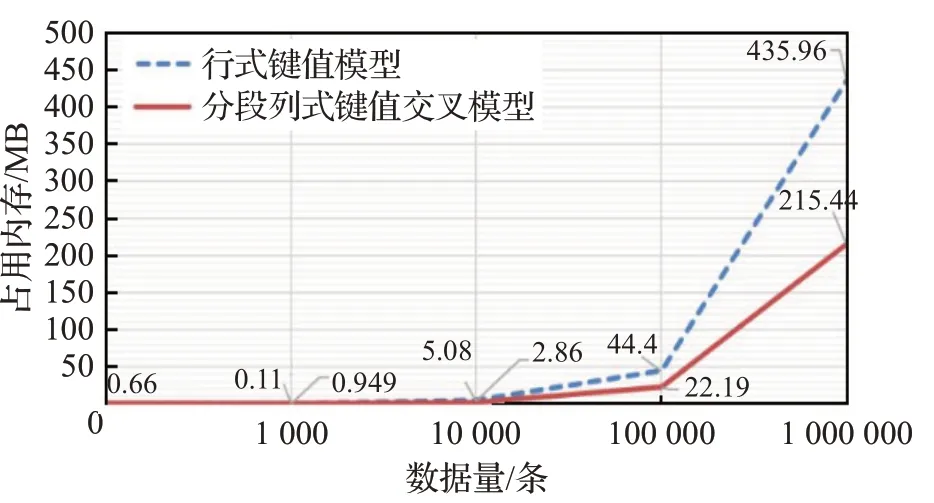
图8 不同模型数据迁移内存占用结果Fig.8 Data migration memory usage results of different models
为了减少数据迁移过程中与Redis 交互次数,提升数据迁移的性能。本文利用Redis 的批量操作方法,以10 000 批量为例,进行批量操作,数据迁移时间对比如图9所示。
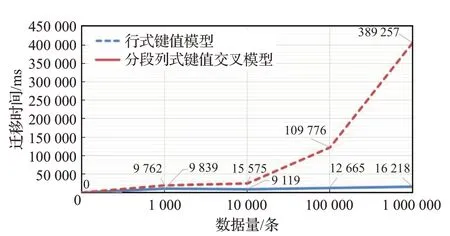
图9 数据迁移时间对比Fig.9 Time usage comparison of data migration
对比不同数量级下的运用两种模型进行数据迁移内存占用结果,有以下结论:
(1)横向对比不同数量级的数据采用相同的模型算法进行数据迁移,内存占用都随着数据的增多而升高。
(2)纵向对比相同数量级的数据采用不同的模型算法进行数据迁移,随着数据量的上升,行式键值交叉模型是分段列式键值交叉模型内存占用的2倍。
特别地,以10 000 条数据量为例批量进行数据迁移,对比运用两种模型进行数据迁移的时间开销,随着数据量的上升,分段列式键值交叉模型迁移时间开销基本为常数,而行式键值交叉模型迁移时间明显低于分段式模型。
6 结论
两种模型都可以实现关系型数据库(以MySQL 为例)到Redis的数据迁移,从而解决大数据环境下海量热点数据的高效存取。大数据环境下,数据库Redis 的性能主要体现在对海量数据的存取效率上,两种模型下存数据平均时间复杂度都为O(1),一般情况下,RB-KVM取数据的效率更高,但PCB-KVCM 具有更高的内存利用率(接近两倍);在数据迁移时间方面,分段列式键值交叉模型的数据迁移时间较行式键值交叉模型,随着数据量的增大,迁移时间优势越明显。
猜你喜欢
无线互联科技(2022年15期)2022-11-03
电脑爱好者(2020年18期)2020-09-26
教育界·中旬(2019年7期)2019-11-24
教师·下(2017年10期)2017-12-10
电脑爱好者(2017年9期)2017-06-01
读写算·小学低年级(2017年1期)2017-02-06
中国信息化·学术版(2013年3期)2013-06-25
云南教育·小学教师(2012年10期)2012-11-22
数学大世界·小学低年级辅导版(2010年4期)2010-03-25
网络与信息(2009年9期)2009-10-30
