
无人机航拍图像语义分割研究综述
2021-10-14 06:34李彦冬李诚龙
计算机工程与应用 2021年19期
程 擎,范 满,李彦冬,赵 远,李诚龙
中国民用航空飞行学院 空中交通管理学院,四川 广汉 618307
随着近年来计算机视觉算法的迅速发展,深度学习图像处理在监控技术、智慧农场、地理信息和智慧城市等方向有着越来越多的应用。同时,随着无人机技术的逐渐成熟,越来越多的廉价无人机进入市场。由此催生了无人机航拍与深度学习图像识别之间的技术融合。但是这些计算机视觉算法并不能很好地处理无人机采集的视频或图片,因为无人机航拍图像具有特殊的图像特征,如尺度变化大,有许多小目标物体等。因此,研究适用于无人机航拍图像识别的深度学习算法有重要意义。
图像语义是在图像中为每个像素分配一个预先定义的表示其语义知识的类别标签。当每个像素有了计算机能识别的标签,就能应用于目标识别乃至场景理解等应用场景。当前,越来越多的应用场景需要利用图像中的语义知识,包括自动驾驶中的场景识别与理解、无人机控制与应用、医学影像辅助分析、图像搜索、增强现实等[1-3]。
近年来,基于深度学习的无人机航拍应用研究逐渐增多,例如ECCV 和ICCV 等国际学术会议都有关于无人机航拍图像的学术讨论和文章,国内外也有对无人机航拍图像识别的相关综述[4-5]。但是,这些研究大多以目标检测为中心展开,对于像素级别的无人机图像如语义分割技术应用综述性文献较少。本文从无人机航拍图像语义分割技术应用研究的角度对相关技术进行了分析,主要内容包括语义分割技术、语义分割发展历程、无人机航拍数据集特征的介绍、语义分割在无人机航拍图像在一些典型的应用研究成果综述,以及于语义分割技术在无人机航拍图像应用的展望和挑战。
本文首先对计算机视觉技术、语义分割技术、无人机技术及无人机航拍应用发展背景进行概述;然后介绍了语义分割技术的介绍、发展、评价指标以及无人机航拍图像的特点,结合语义分割技术的发展历程和特点,对语义分割技术的不同阶段以及目前主流的语义分割技术支撑基础进行详尽描述;第三部分针对于无人机航拍图像的特点,对无人机航拍图像语义分割算法进行评述,结合无人机航拍图像特点,对无人机航拍图像的挑战点以及关键部分的语义分割模型以及算法进行分析和对比,对常用以及通用解决方法比较了原理和特点;第四部分对无人机航拍图像应用部分综述,对典型的无人机航拍语义分割应用场景的实验以及成果评述;最后,对无人机语义分割算法进行总结,对无人机航拍图像的发展趋势以及应对挑战进行分析和展望。
1 语义分割技术
1.1 语义分割介绍
语义分割(Semantic Segmentation)可以使计算机能够对图像自动分割物体并识别。分割和识别是语义分割最重要的部分,相比于图像分类和目标检测,语义分割是从图像像素级别的分类识别(见图1)。图像分类是基于整张图片的分类与识别,目标检测在图片分类的基础上给出了用于定位物体的矩形区域。而实例分割与语义分割的不同在于实例分割需要区分同类物体不同的实例。
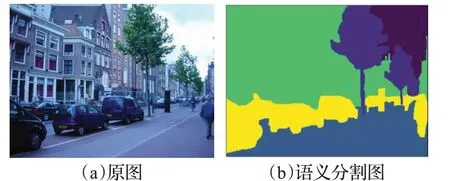
图1 语义分割示意图Fig.1 Example of semantic segmentation
无人机语义分割当前面对的挑战主要包括小目标物体的识别、相似外观物体的分割分类、同类不同形态物体的识别以及在复杂环境下的图像环境理解。其中,小目标物体的识别包括纤细或者较小目标的分割与识别等;相似外观物体的分割分类是指对于颜色或者形状等低级特征相近的物体分割分类,如草坪和树木的颜色相近,但是树木却是障碍物,如果不能将树木和草坪区分开,无人机飞行或降落时会发生危险;同类不同形态物体识别包括不同类型道路的识别,不同建筑物的识别等,不应以建筑物的形状不同而识别出错;复杂情况下的图像环境理解主要指在复杂环境,多个物体种类并存等图像中依然可以使用通用的算法或模型准确的分割和识别。
1.2 语义分割发展
语义分割技术的发展主要经历了三个阶段:传统语义分割方法、深度学习和传统方法结合的语义分割方法和基于深度学习的语义分割方法[6]。目前主流方法是基于深度学习的语义分割方法。
(1)传统语义分割方法
传统语义分割方法与现在大多数使用的人工智能算法不同,主要基于纹理、灰度、几何特征等将图像中不同的物体分割和识别,使物体与图像背景分离。这类方法通常需要人工调整算法的参数,耗费时间和人力,并且模型效果以及精度劣于深度学习方法。如阈值分割法[7]、聚类分割法[8]、图论分割法[9]、区域分割法[10]等。基于图论的分割方法是常用方法,其中马尔可夫随机场(Markov Random Field,MRF)和条件随机场(Conditional Random Field,CRF)是较为经典的方法。基于图论的方法通过构建概率图模型,运用图论方法求解,只适用于较为简单的场景,随着数据集规模的扩大和复杂的图像环境场景,这类方法逐渐不再适用[11]。因为针对高分辨率图片,特征提取的速度呈现几何倍数增长。
(2)深度学习和传统方法结合的语义分割方法
深度学习和传统方法结合的语义分割方法是将基于图像纹理,灰度等简单特征的传统语义分割方法与深度学习相结合,对物体分割和识别的自动语义标注,如拉普拉斯金字塔[12]。这类算法使用卷积神经网络(Convolutional Neural Network,CNN)[13]模型作为训练像素的特征分类器,但仍然受到传统分割方法的制约,精度普遍较低[14]。
(3)基于深度学习的语义分割方法
基于深度学习语义分割方法主要依靠于深度神经网络的发展,从早期的LeNet[15]手写数字识别应用到ImageNet 竞赛冠军算法AlexNet[16]和VGG[17],以及后来的ResNet[18]、FCN(Fully Convolution Network)[19]等网络的提出,网络结构越来越复杂。随着深度学习的活跃发展,深度学习语义分割网络也不断的被提出,如FCN[19]、SegNet[20]、DeepLab[21-24]、RefineNet[25]、PSPNet[26]等模型被广泛应用。
深度学习语义分割根据不同的网络模型大体分为三类:强监督语义分割、无监督语义分割和弱监督语义分割,分别对应与强监督学习、无监督学习和弱监督学习。目前强监督语义分割精度最高但是对数据集要求也有较高的要求,有时甚至会为了获得较好的效果在数据集上花费大量时间,比如对数据集标注(打标签),数据增强等;无监督语义分割不依赖于人工对数据集的标注,对复杂环境和场景下的图像有较好的适应性,但是语义分割的精度相对较差,相关研究相对较少;弱监督语义分割相比于强监督语义分割和无监督语义分割,数据集不需要大量的人工操作,语义分割精度低于强监督语义分割,需要大量的时间训练,需要长时间消耗计算机计算资源。
另外,在深度学习语义分割成为主流之前,伴随着机器学习技术的流行,也有使用机器学习方法来实现语义分割的研究,如基于纹理基元森林(Texton Forest)和随机森林(Random Forest)等机器学习分类器的语义分割技术。随着深度学习语义分割精度的不断提高,越来越多的学者研究转向深度神经网络。尽管如此,机器学习方法和深度学习方法结合实现语义分割仍然是较好的研究方向[27]。
1.3 常用评价指标
评价语义分割模型的常用指标主要包括模型的运算时间性能指标和评价模型效果的精度指标。时间性能指标通常使用每秒处理的图像个数,通常是帧每秒(Frame Per Second,FPS);评价语义分割模型的常用精度评价指标主要包括像素精度(Pixel Accuracy,PA),平均像素精度(Mean Pixel Accuracy,MPA)等。
设数据集共有K+1 类(包含K类和一个背景类),pii表示本属于第i类预测为第i类的像素点数量,pij表示本属于第i类预测为第j类的像素点数量,pji表示本属于第j类预测为i类的像素点数量。
像素精度计算公式为:
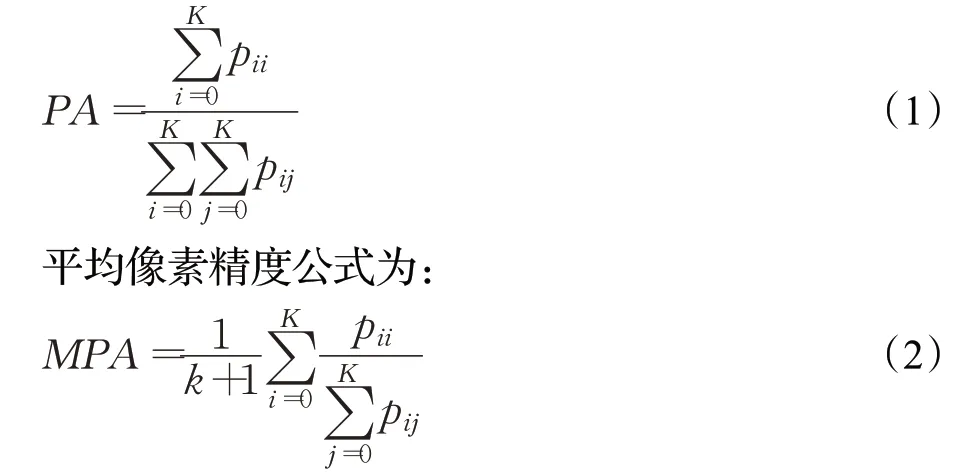
常用的评价指标还有准确率、召回率、F1分数和交并比(Intersection over Union,IoU)(见图2)等。

图2 交并比计算示意图Fig.2 Schematic diagram of IoU
准确率计算公式为:

F1 分数计算公式为:

其中,TP为目标分类正确的像素数量,FP为背景判定为目标的像素数量,FN为目标判定背景的像素数量,P为准确率,R为召回率。
2 无人机航拍图像及数据集
2.1 无人机航拍图像特点
无人机航拍图像由于其拍摄角度等因素与自然场景图像不同,其拍摄角度包括跟随机头的水平角度和从高空俯视或斜向下的角度,除水平角度主要用于无人机避障外,高空俯视或斜向下的角度有更广阔的视野和复杂的场景,包含的物体种类多样,相比于大多数自然场景和静态场景图像如COCO数据集[28]等,无人机航拍图像包含更复杂的语义信息。此外,随着无人机飞行的高度以及俯仰角的变化,无人机航拍图像物体形状大小会大致按照比例变化,有时会导致图像形状的失真。无人机航拍图像中小目标居多,如车辆、人、树木等等,随着无人机高度的增加,物体越来越小(见图3),这为图像语义信息的识别带来了更大的挑战。

图3 无人机航拍示意图Fig.3 Examples of UAV aerial images
2.2 常用数据集
无人机航拍图像语义分割数据集常用的包括ICG Drone Dataset、UDD(Urban Drone Dataset)[29]、Aeroscapes[30]和UAVid[31]等。在地理信息和遥感图像应用方面,ISPRS 数据集较为著名,ISPRS 数据集既可以作为无人机航拍图像数据集也可以作为遥感图像数据集使用。ISPRS数据集是多个数据集的集合,包括著名的Vaihingen数据集、Potsdam 数据集等,不仅有用于深度学习语义分割的图片数据集,还有3D 点云数据等。另外在无人机航拍建筑物提取应用方面,INRIA[32]数据集和WHU数据集也较常使用,各类常见图像数据集的特点如表1所示[33-37]。

表1 无人机航拍语义分割常用数据集Table 1 Semantic segmentation datasets for UAV aerial images
3 无人机航拍图像语义分割算法研究
语义分割在无人机航拍图像上的模型及算法多是局限于一些特定应用,而对无人机航拍图像通用语义分割算法较为缺乏,许多无人机航拍图像语义分割算法都针对某一类或某学科应用,如遥感、电力巡检、车道线检测[5]等。对于通用的无人机航拍图像语义分割网络和模型,大多由通用语义分割模型在迁移学习或者简单的网络修改后进行实验及应用。对于无人机航拍图像语义分割技术,有许多的挑战和突破点,包括模型的实时性、模型小目标分割、模型多尺度及上下文信息融合等。
3.1 典型方法分析
在最常用的强监督语义分割中,深度学习语义分割网络模型主要使用编解码方法、多尺度信息整合方法等。编解码方法由编码器和解码器两大部分组成,编码器通常使用卷积神经网络和下采样,降低分辨率并提取图像特征映射;而解码器是将低分辨率的图像及特征转换为图像的分割映射到像素级的预测上,常用反卷积(deconvolution)[38]进行上采样,并且最后一层网络结构多为softmax分类器来对每个像素进行分类。编解码方法,或称为编码器-解码器方法,是深度学习语义分割较为经典的方法。基于FCN[19]结构(见图4)的SegNet[20]是一个典型的使用编解码方法的网络结构。SegNet 移除了全连接层,优化了模型的速度,对明显的较大目标有较好的分割效果;SegNet 使用最大池化并基于VGG16结构,对小目标的分割效果较差。因此,对于无人机航拍图像而言,SegNet等基于编解码器的网络结构更适合在遥感、中高空无人机航拍图像等大尺度的场景,如建筑物、森林、植被等图像的语义分割。

图4 FCN结构示意图Fig.4 Schematic diagram of FCN structure
多尺度信息整合方法主要解决的是深度学习网络对图像局部信息和全局信息的平衡和考虑上下文信息对各种信息的整合。由于大多数卷积网络中卷积核尺寸大小是一定的,滤波器会检测提取特定尺寸的特征,影响到最后的特征映射[1]。常用的多尺度信息结构是图像金字塔结构,即将图像缩放成不同的比例,分别应用卷积神经网络模型中,从而实现提取和预测多个空间尺度和包含上下文的信息;空洞卷积(dilated convolution)[39]则使用不同大小的空洞卷积核完成卷积操作,空洞卷积核采用输入等间隔采样或零填充的方式,对于空洞为1,尺寸大小3×3的卷积核,感受野为7×7(见图5)。具有代表性的Deeplab 网络结构使用空洞卷积和ASPP 模块,其中空洞卷积优化了普通卷积网络的空间、边界、内部数据结构等信息丢失问题,增加了网络结构的鲁棒性,同时也优化了小目标的重建问题;其中ASPP 模块是多尺度特征提取的解决方法,避免了信息的冗余。由于Deeplab模型增加了感受野,优化了小目标语义分割,而且具有一定的上下文整合能力,适合种类多样性、细节丰富的中低空的无人机航拍图像,如线缆、行人等语义分割。

图5 空洞卷积示意图Fig.5 Schematic diagram of dilated convolution
3.2 小目标检测分割
小目标检测和分割一直是深度学习语义分割挑战性问题,甚至目标检测也存在同样的情况。由于卷积神经网络的特性,小目标物体的漏检错检等问题仍然没有较完美的解决方案,通常的解决方法是利用多尺度和上下文信息来弥补卷积神经网络对小目标检测分割的缺陷,包括扩大感受野,改变编解码网络结构、金字塔结构等方法。Deeplab[21]最初是基于全卷积网络改进的,使用空洞卷积[39]的方式增大了感受野,使用双线性插值和条件随机场对网络进行优化。DeeplabV2[22]加入了空洞空间卷积池化金字塔结构(Atrous Spatial Pyramid Pooling,ASPP)。DeeplabV3[23]提出了级联并行的结构,优化了空洞空间卷积池化金字塔结构并去除了条件随机场。DeeplabV3+[24]对整体网络进行了优化,压缩模型,减少了模型的参数。PSPNet[26]利用图像的上下文和多尺度信息,对低分辨率图像有较好的效果,而且具有一定的实时性。
刘文等人[40]对DeeplabV3+网络改进,加入倒置残差和特征图切分的方法,提出了DeepLabV3plus-IRCNet,一般的残差是先压缩后扩张,而倒置残差先扩张后压缩,从而获得更多的特征,特征图切分模块使用切分比率将特征图切分成许多小份,然后将切分后的每个模块通过上采样方法恢复原来的尺寸大小,从而达到小物体“放大”的效果。刘文等人[40]的实验还表明切分特征图时,切分比率过大会破坏邻近像素点的关联性,进而丢失整体信息。
除了利用图像的多尺度信息,在语义分割基础网络上设置并联的小目标检测分割网络也是可行的。胡太等人[11]对小目标语义分割的解决方法是将小目标分割任务从完整的图像分割任务中脱离,与一般的多尺度网络结构不同,其网络结构包括小目标检测分割网络和Deeplab-Attention 语义分割网络两部分,呈并联结构。在建筑物提取方面,王明常等人[41]将残差结构和特征金字塔结构融入UNet 中来解决小目标语义分割的问题,建立FPNRes-Unet 模型。曹春红等人[42]使用多级特征级联的方式,提出快速语义分割模型MFCNet。
综上,利用空洞卷积、金字塔结构等方法是较为主流的方法,现阶段小目标的检测识别与模型扩大感受野息息相关,因为卷积神经网络在卷积操作时一般会损失一些图像信息,特别是图像细节。提升小目标检测和分割精度主要还是通过扩大感受野,降低卷积操作时的损失以及建立新的网络结构解决。
3.3 实时性
深度神经网络(Deep Neural Network,DNN)逐渐成为深度学习语义分割主流方式,但是随着网络的层次的增加和网络结构的逐渐复杂,高精度网络往往伴随着大量的模型参数,如PSPNet[26]、FCN[19]等都需要大量的计算资源和时间去拟合网络。为了使深度学习语义分割在无人机航拍领域以及在嵌入式中更好的发展和应用,解决计算的实时性十分重要。缩小图片尺寸是最容易的方法,但是缺点也很明显,缩小图片尺寸会使语义分割效果变差,因为单纯的缩小图片尺寸会丢失图像的细节以及空间尺度信息。另一种较为简便的方法使剪枝网络结构,但是修剪后的网络结构对上下文信息的提取较差。最佳方式则是对深度学习网络模型的结构等进行改进和创造,但是网络结构的更改和新网络结构的研究是十分复杂的。
SegNet[20]使用小型的网络架构,从网络结构的角度出发,减少了模型网络参数,ENet[43]同样使用少量的下采样来提高网络的计算效率,ESPNet[44]使用改进的金字塔模块来提高计算速度,BiSeNet[45]使用空间路径和上下文路径平衡感受野和空间细节。
注意力机制的提出和引入,使深度学习语义分割模型更加的易解释并且能够提高神经网络的性能。尹鹏峰等人[46]将注意力机制、带孔金字塔等结合,提出DPANet。鲍海龙等人[47]使用自我注意力机制(Self-Attention)提出了基于区域自我注意力的语义分割模型,加入轻量级的注意力模块RSA 和交互注意力模块LCIA,降低了自我注意力机制的计算量并保留通道的完整性。
总的来说,深度学习语义分割算法的实时性实现与模型检测精度相互平衡应是模型建立和应用所需考虑的,对于大型网络的优化,网络剪枝以及网络模型压缩是经常使用的方法;同时,针对CPU的模型优化和可演化的网络模型框架研究也是研究热点之一。
3.4 多尺度和上下文信息
多尺度和上下文信息包含图像整体与局部信息的融合,是语义分割不可或缺的一部分,常用的方法包括条件随机场(CRF)、空洞卷积和多尺度特征融合等。图像金字塔结构、编解码结构、空间金字塔池化也都可以达到多尺度以及上下文信息的获取和整合(见图6)。
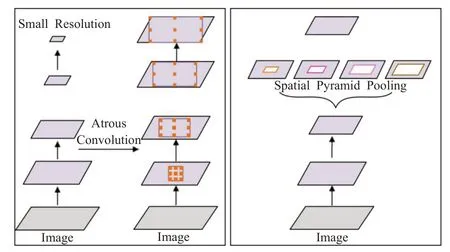
图6 空洞卷积和空间金字塔池化示意图Fig.6 Schematic diagram of atrous convolution and spatial Pyramid pooling
条件随机场(CRF)常作为后处理模块来对多尺度信息的聚合,条件随机场将像素强度相似的点标记为同一类别,是一种分割图模型。Deeplab 模型[22]使用了全连接条件随机场(Fully Connected CRF),改善了深度卷积网络(Deep Convolutional Neural Network,DCNN)的效果。与此同时,CRFasRNN模型[48]使用条件随机场优化网络分割结果,融合全卷积神经网络(FCN)视为循环神经网络(Recurrent Neural Network,RNN)结构,成功地将条件随机场融入到端到端的网络。
空洞卷积[39]或者带孔卷积,可以扩大感受野和获取上下文信息,它可以指数级别地扩大感受野而不增加卷积核的参数。普通卷积相当于扩张率或空洞为1 时的空洞卷积。Deeplab 系列模型、ENet[43]以及PSPNet[26]都使用了空洞卷积,在不增加计算资源的前提下,获取上下文信息和扩大感受野。在深度学习语义分割模型中,空洞卷积获得了广泛的应用。
深度学习语义分割模型可以通过各种方式提取图像不同尺度的特征,然后对不同尺度的特征进行融合。包括金字塔结构以及一些具有多尺度的编解码结构,使用不同大小的卷积核与图像卷积和滤波,得到不同尺度的特征图,通过串联融合等方法对不同的特征图进行融合,从而得到上下文信息。
最后,在深度学习语义分割模型网络中,上下文信息的提取仍然没有较为完美解决的方案,图像中要素的关系如线与线平行等关系仍不能较好地解决。目前常用的做法是针对不同的应用和场景,对网络模型调整和改进。
4 无人机航拍图像语义分割应用研究
随着ImageNet[49]数据集的出现,更复杂、更庞大的深度卷积神经网络相继被提出和使用,通过这类大型数据集驱动的大型网络和深度学习模型结构(如AlexNet[16]),开启了全新的计算机视觉和监督学习的发展历程。与此同时,PASCAL[50]、COCO[28]等数据集的不断发展,从目标检测的矩形框(bounding box)逐渐演变到像素级别的物体分割和分类,推动了深度学习语义分割的发展。具有代表性的例子如KITTI[51]和Cityscapes[52]等数据集为深度学习在车辆自动驾驶场景下的语义分割做出了重要贡献。
无人机航拍图像由于其拍摄角度和场景等特点,结合深度学习等人工智能算法能够完成多种类型的任务,可应用于地理信息、遥感图像、自动化农业、线缆检测与巡视、建筑物识别和检测、城市地块划分、道路路网的提取、车辆检测识别以及通用识别等等。本文重点对无人机航拍图像语义分割线检测(见表2)[53-57]、农业应用和建筑物提取等应用展开讨论和总结。
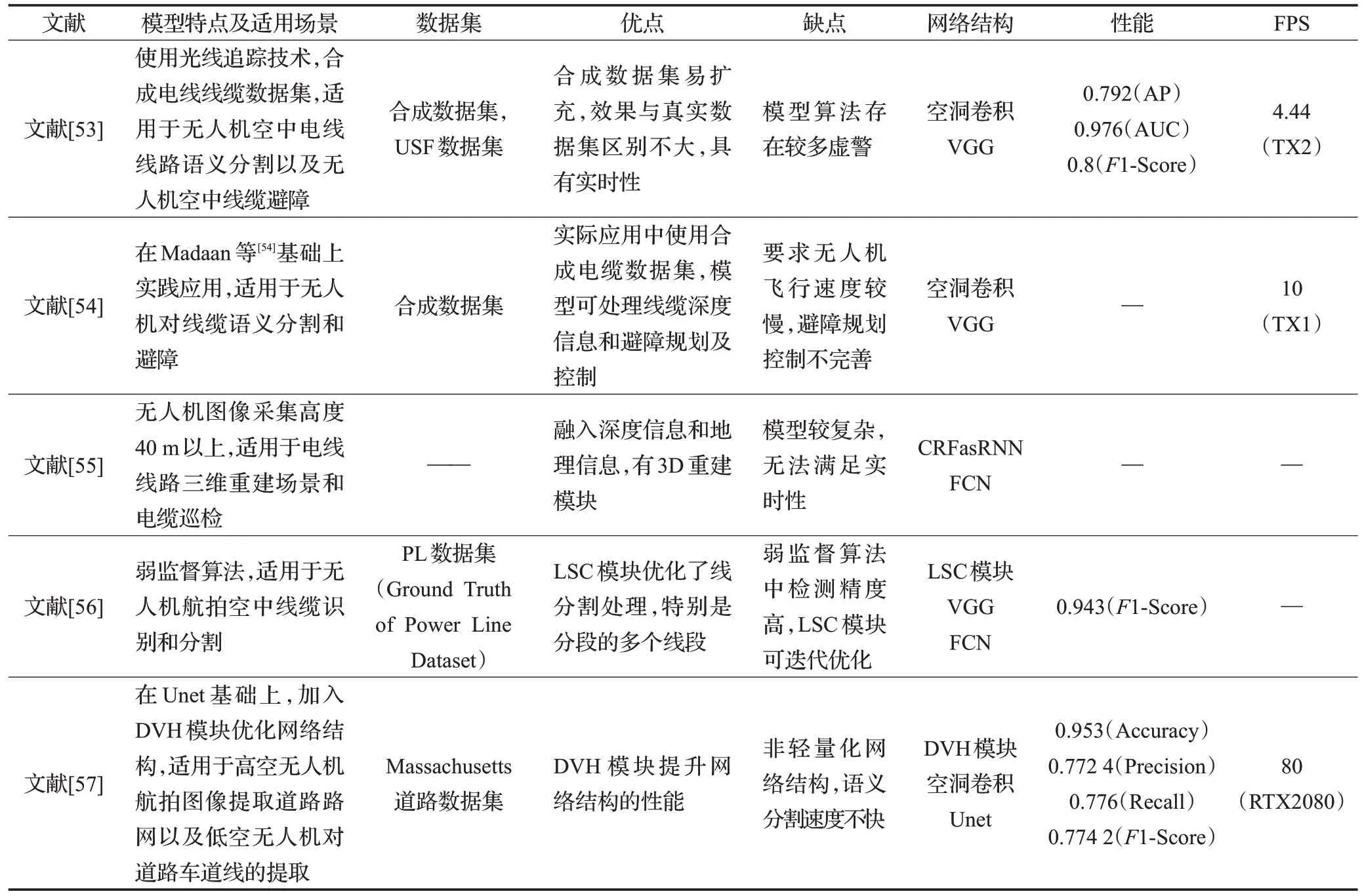
表2 无人机航拍图像语义分割线检测应用研究Table 2 Summary of semantic segmentation line detection applications of UAV aerial images
4.1 线检测
线检测,即面向图像中的电缆、道路引导线等线状目标的检测。线检测的研究主要面向三种典型的应用场景,首先,线检测可以保障无人机安全航行,保障无人机飞行时避开电线和线缆等障碍物;此外,线检测可以保障电线运输,检测电线是否损坏、断裂等等;同时,线检测还在高空航拍数据集和遥感图像数据中被用于检测道路信息,生成道路路网信息。线检测是一个具有挑战性的问题,由于图像中的线元素一般仅有很少量的像素,可以出现在任何位置和方向,较难分辨。未来,自动航行的无人机越来越多,电线、缆绳、铁丝网等物体无疑使飞行环境变得复杂和危险。对自动航行的无人机来说,航拍图像的实时处理和检测精度都要有较高的标准而且需要相互平衡,防止出现短板效应。先前的研究大多假设电线等物体为直线,或者有其固定的灰度值,线与线之间彼此平行,可以使用高斯分布或者二次多项式拟合[58],如将边缘检测(edge detection)与霍夫变换(Hough transform)结合等[58],这些方法需要参数调优,并且局限于特殊场景和任务,并不能广泛使用[53]。
Madaan 等[53]使用光线追踪(ray tracing)技术渲染合成电线并覆盖在无人机航拍图像上,生成训练数据集,建立空洞卷积模型,使用NvidiaJetson TX2设备,图像分辨率使用480×640,对比网络为FCN[19]、SegNet[20]和ENet[43],平均精度为73%,使用了单目相机和网格搜索方法。取模型最优结果,AP值0.729,AUC值0.976,FPS值4.44。Madaan 等[53]建立的语义分割模型表明使用合成渲染的图像和航拍图像叠加组成的训练集对模型也是可行的,对线缆图像而言合成图像比真实航拍图像更易获取,可以产生大量的图像数据;其次,在便携开发板上达到了4 FPS 的速度,模型更加的轻便,可以满足实时性,但缺点是检测精度并不高,电线等物体分割效果并不完美。
空中线缆由于其不易被发现的特点,对于无人机的航行安全具有很大的威胁,特别是飞行高度较低的直升机和小型飞机[59]。Dubey 等[54]使用Madaan 等[53]的模型实现了无人机自动航行的空中线缆检测和避障,Dubey等[54]的实验中微调了网络模型,并设置阈值来降低虚警率(false positives),以防无人机飞行不稳定。
空中输电线路长期暴露在外部环境中,常常出现线路老化、电线破损、断裂等情况,巡检需要大量的人力和时间,使用无人机实现电网沿线检测是很好的方法。Maurer 等[55]对线路周围场景三维重建,基于全卷积建立语义分割模型并以循环神经网络形式做条件随机场处理(CRFasRNN),使用了RGB 和LAB 颜色空间转换等。Choi 等[56]使用卷积神经网络和LSC(Line Segment Connecting)建立弱监督学习模型,对比VBP[60]、FCN[19]、AFN[33]算法,F1-score 达到了94.3%。由于使用了弱监督学习,标记成本大大降低。
常规方式提取路网需要实地测量,需要大量的人力物力,而使用无人机航拍图像自动化提取城市的道路路网就十分便捷。但是,图像中的阴影、树木等都可能影响道路的提取,导致路网提取不完整、不准确等。Liao等[57]使用空洞卷积提取特征,提出并使用DVH(Dilated convolution with Vertical and Horizontal kernels)建立模型,在马萨诸塞州道路数据集(Massachusetts Road Datasets)上做验证实验,提取航拍图像中的路网,对比Unet[34]、HFCN[61]、VH-HFCN[62]等网络模型达到了95.3%的精度,召回率达到了77.6%,F1 分数为77.42%。
针对线检测部分,使用光线追踪技术生成空中线缆是发展趋势,合成的数据集不仅有效,而且可以快速生成大量的数据,降低了传统方式即无人机航拍采集数据的风险,并在改善无人机飞行的电磁运行环境下,确保了无人机飞行的安全。同时,合成的空中线缆等数据集也能满足模型的验证和模型之间的比较。另外,在未来无人机线检测领域,低对比度和低质量图像的线检测是一大挑战,因为在低能见度或低气象等条件下,图像的特征不再明显,甚至在极端情形下目视也很难区分。
4.2 农业
精细农作(precision farming)是未来可持续发展农业的重要部分,灵活便捷的无人机越来越多的用于农田自动监视。无人机航拍图像语义分割的应用使农田的监视更加的便捷、高效,而且成本低廉(见表3)[63-67]。除此之外,无人机航拍图像语义分割技术还可以识别农田中的杂草区域以及被害虫侵蚀的农作物,利用无人机可以对农田进行选择性使用农药以及选择性除草等。
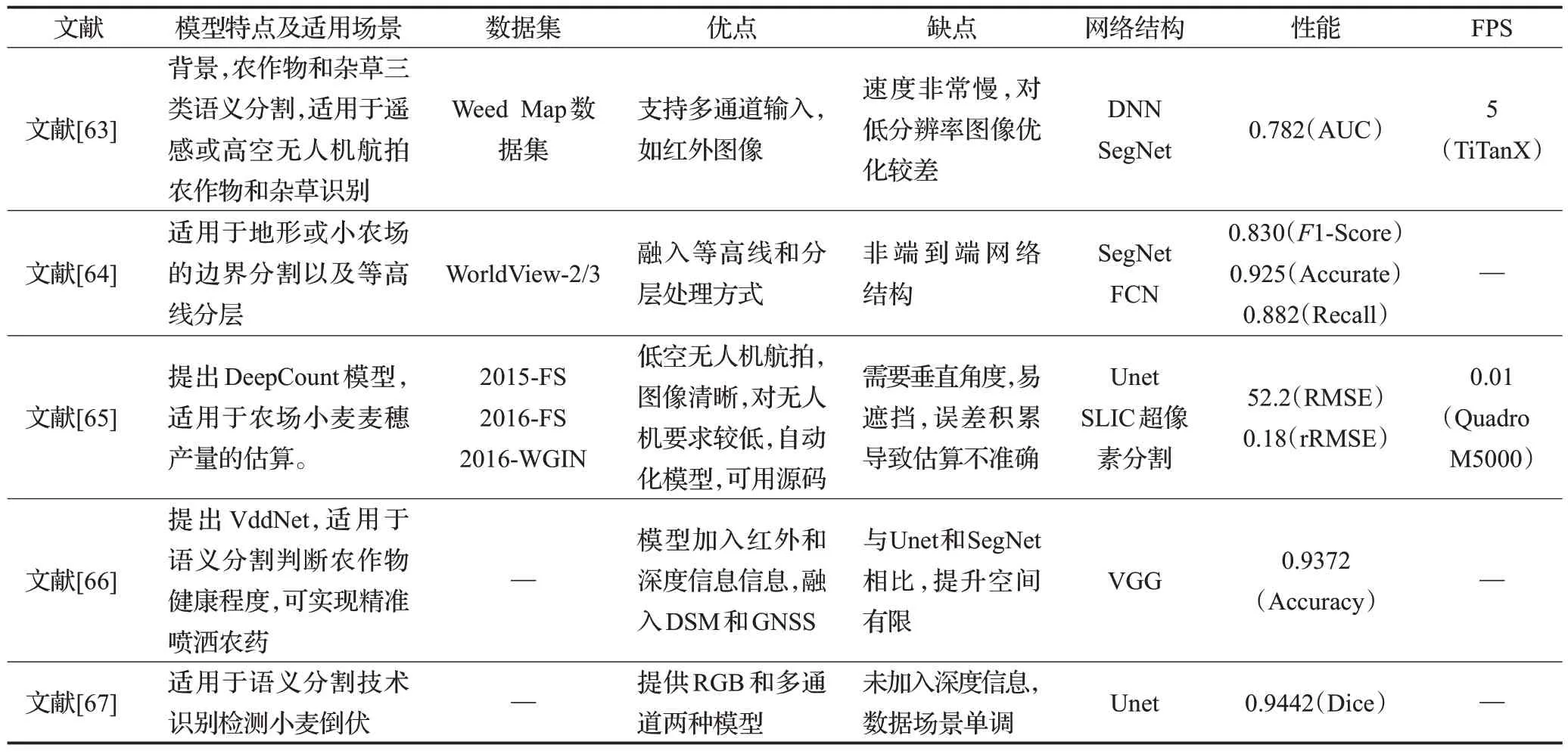
表3 无人机航拍图像语义分割农业应用研究Table 3 Summary of semantic segmentation agriculture applications of UAV aerial images
尽管机器学习技术在无人机航拍图像对农作物分割应用已经取得不错的成绩[68],但是农作物的多元化和模型的人工手动调整等仍然降低了自动化的效率。而深度学习却能很好的弥补这些缺点,使分割更加的智能,从而提高自动化的效率。无人机航拍图像语义分割在农业的应用也正在由机器学习向深度学习方向发展转变。
Sa 等人[63]使用深度神经网络DNN 和滑动窗口(sliding windows)在无人机航拍获得的多光谱图像上,实现甜菜和杂草的分割,对比SegNet[20]网络结构下,AUC 值提高了0.2,达到了0.8。Sa 等人[63]指出,相对于农作物,杂草的分割更具有挑战性,并且使用简单的数据增强方法来增加训练数据集规模反而会导致DNN模型精度降低。同时,该模型消耗了较多的GPU资源,很难实现便捷设备的实时性。
针对于小农场,农作空间不规则,同一空间内含有不同的农作物等特点使不同农作物之间没有明显的界限,此时不同农作物区域的划分十分重要。边缘检测等方法在区分不同农作物方面精度达不到要求[64],Persello等人[64]使用全卷积网络[19]对面积小、区域不规则的小农农作区域进行划分,指出基于深度全卷积网络模型在复杂地形和任务的情况下依然有较好的准确性且优于传统技术,并且在特定情况下,SegNet[20]网络模型更具优势。
Sadeghi-tehran 等人[65]使用深度卷积网络分割和提取小麦麦穗并用于小麦麦穗的计数,对比边缘检测,形态学等方法,验证了模型的有效性和鲁棒性。文献[65]提出了DeepCount模型,模型克服了形态学等传统方法需要大量的先验知识、良好的照明环境等条件,而且模型仅仅需要RGB图像便可以精确的实现小麦麦穗的语义分割。
Kerkech等人[66]使用深度学习语义分割技术检测农作物的健康程度,使用葡萄实验,检测农作物是否健康,从而实现精准农药喷洒。文献[66]首先对无人机航拍影像进行配准,然后提出VddNet 模型,对比SegNet[20]、U-Net、DeepLabv3、PSPNet[26]等网络模型实验,VddNet效果模型有所提高,而PSPNet[26]效果最差。VddNet 模型在图像基础上还添加了多光谱和深度高度等信息。
Zhao 等人[67]使用U-Net 和无人机航拍图像检测水稻倒伏,发现使用高分辨率的RGB 相机比多光谱相机的效果更好。同时,文献[67]指出基于点云(pointcloud)分析小麦倒伏会有更好的效果,但模型和运算更加复杂[69]。
对于农业场景的应用,无人机航拍图像应用大多从遥感图像演变而来,大多数情况都是沿用遥感图像处理的方式。在无人机航拍图像的基础上,无人机上还可以安装多光谱传感器,深度或高度传感器,红外传感器等。当无人机飞行高度在100 m以上时,较难分辨植物的叶片,对于图像细节等损失较严重。未来,无人机航拍在农业方向的应用应逐渐趋于飞行高度低于100 m的低空和超低空,并且在无人机航拍图像应用的基础上,实现自动化和智能化。
4.3 建筑物提取
使用无人机航拍图像提取建筑物常常用于动态监视城市的变化,建成区面积估算,人口估计等,对城市的规划和发展有指导性建议,但建筑区域的视觉特点和其他自然环境有可能高度相似,如建筑物的颜色和形状和山或湖泊相似等(见表4)[70-73]。无人机航拍图像语义分割在建筑物提取应用方面与人工智能发展趋势大体相同,如Cote等人[74]使用Haar特征,Yi等人[75]使用SIFT[76],Mountrakis等人[77]使用支持向量机(Support Vector Machine,SVM)对无人机航拍图像或遥感图像的建筑物分割识别和提取。
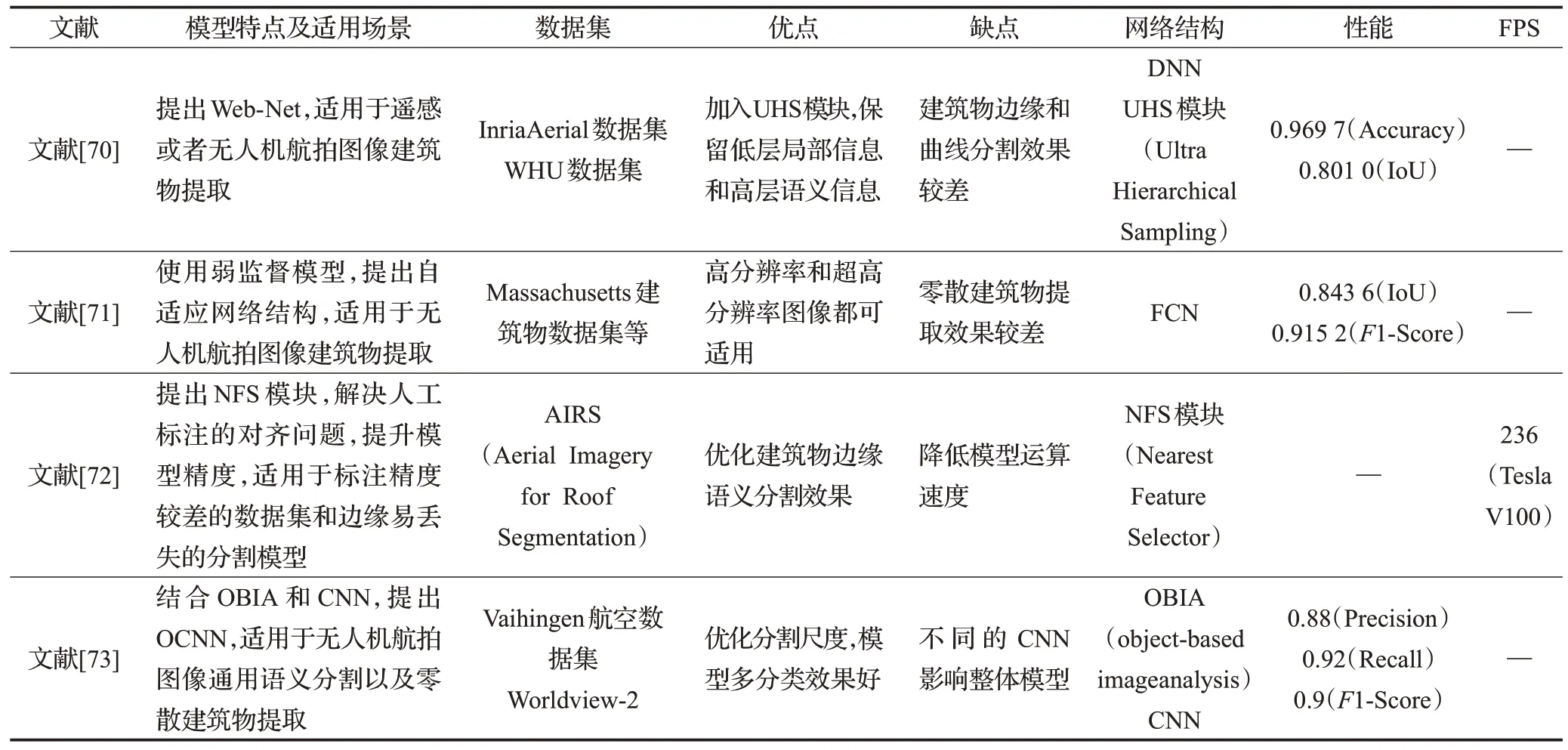
表4 无人机航拍图像语义分割建筑物提取应用研究Table 4 Summary of semantic segmentation building extraction applications of UAV aerial images
Zhang等人[70]指出,在航拍图像中,建筑物被阴影区域覆盖时,经常会出现无法识别出建筑的情景。对此,文献[70]提出了Web-Net,使用UHS(Ultra-Hierarchical Sampling)进行特征采样和融合,使用Inria[32]和WHU[78]数据集验证实验。Iqbal等人[71]使用弱监督网络,提出自适应网络结构OS-WAN 和LT-WAN,使用Potsdam[79]和Massachusetts[80]数据集实验验证,提出Rwanda 数据集,对比U-Net[34]、LTA[81]和OSA[82]等网络结构,LT-WAN效果最优。Wang等人[72]提出NFS(Nearest Feature Selector)模块,动态调整标签从而解决标签对齐的问题。由于全卷积监督网络模型的标签大多为人工手动创建,难免会造成误差,不对齐的标签信息会影响网络模型的精度以及建筑物提取的精度。在使用NFS 模块时,计算速率会下降,精度会提升。Majd等人[73]使用OBIA(Object-Based Image Analysis)方法,基于对象分析而不是基于像素分析,将OBIA 和卷积神经网络结合,提出OCNN,使用ISPRS 的Vaihingen 数据集,对比MCNN(Multiscale CNN)、神经网络NN模型等,实验表明了OCNN的结果好于单独的MCNN 和Object-Based Classification模型。Wang 等人[83]使用FCN[19]和ResNet[18]等网络对多伦多城市使用航拍图像进行实验,提取和分析城市的特点,如整个城市的土地利用分类以及使用面积等。
在建筑物提取应用方面,虽然航拍图像在地理信息、遥感图像处理等方面大多还是采用飞行员驾驶飞机飞行,但是随着无人机的广泛应用和发展以及全球导航卫星系统(GNSS)的发展应用,在地理信息以及遥感上应用的航拍图像采集逐渐会从驾驶员驾驶飞机过渡到无人机飞行。随着无人机的发展,固定翼无人机不再是航拍图像在遥感或地理信息应用的主流,旋翼无人机也会加入并胜任在地理信息领域航拍图像语义分割场景。
4.4 无人机航拍图像语义分割应用模型讨论
总的来说,无人机航拍图像语义分割模型大多是基于通用语义分割模型的技术上在无人机航拍图像的迁移应用。不难发现,在线检测应用方面,空洞卷积与卷积神经网络的结合是常用的方式,空洞卷积的大感受野和信息保留较传统卷积较好,更适合线缆、标线和道路等具有特殊的空间信息以及小目标。由于普遍的编解码模型会丢失一定的上下文信息,在模型中依据特征加入不同的模块来优化语义分割的模型,提升分割效果;在农业应用方面,低空无人机航拍图像应用要优于高空无人机航拍图像。高空无人机航拍图像需要高分辨率或超高分辨率图像,基本无法满足边缘计算的要求。而且,高空无人机航拍对无人机飞行高度升限要求较高,通常航拍设备成本较高,不易于广泛的应用。低空无人机航拍能够在更小的分辨率的图像拥有更大的细节范围,而且成本较低,如DeepCount模型使用SLIC降低了模型复杂度,而且无人机飞行航拍高度低,使无人机在农业应用的实时成为可能。目前无人机航拍语义分割在农业应用的数据集还是以高分辨率图像为主,大多数模型还是基于可见光、红外和深度信息建立模型。农田中通常农作物单一,细节信息不丰富,经典分割模型如SegNet也能有较好的结果,但是不同农业应用数据集可能需要自行制作;在建筑物提取方面,语义分割模型易被非建筑物部分影响,如天气、植被等,导致建筑物分割的零散和不稳定。同样,建筑物提取对图像细节要求较低,高分辨率图像和模型居多。对于建筑物提取分割边缘不规则,以及整个建筑物提取出现多个零散块问题,通常是在模型基础上加入不同的优化模块解决,同时分割尺度参数也会影响到提取的效果,例如融入OBIA的OCNN模型优化了建筑物的零散提取问题。
5 总结与展望
本文阐述了无人机航拍图像语义分割相关算法以及应用研究,介绍了语义分割技术和无人机航拍图像的应用发展,对无人机航拍图像语义分割的挑战和困难进行分析和说明,对当下主流的深度学习语义分割技术在无人机航拍图像的研究以及应用进行了综述,总结不同方法的特点以及相关实验结果。总的来说,深度学习语义分割在无人机航拍图像应用中越来越广泛,而且分割识别的效果优于传统的语义分割方法和机器学习算法,但是这些低层次图像特征等仍然可以作为网络输入数据融合到语义分割模型中。无人机航拍图像语义分割会随着无人机的广泛应用发挥出其价值,在不同的学科领域和场景上发挥作用,对无人机本身而言,无人机航拍语义分割促进了无人机的自动化和智能化,包括无人机依据自身的光学传感器实现应急降落、障碍物的识别、避障规划等等。对于无人机航拍语义分割算法而言,未来的相关研究是向模型的轻量化以及图像处理的实时性和准确性方向发展。但是,目前无人机航拍语义分割技术仍然存在许多研究方向和挑战,主要包括:
(1)无人机航拍数据集。无人机航拍数据集的多样化导致了无人机航拍数据集的不统一,无法像通用场景的语义分割拥有较为标准的数据集作为实验基准和评价。其次,无人机航拍图像在低空和高空的图像特征并不相同而且差异较大,当无人机在低空飞行时,航拍图像包含人、树木、道路、斑马线等,图像包含物体种类多样,物体细节丰富;当无人机航拍图像在高空飞行时,航拍图像大多包含建筑物、山脉、森林等。目前无人机航拍图像语义分割研究很少提及模型和数据集是用于低空还是高空环境,但无人机不同高度的航拍图像有较大的差别应予以区分。当无人机穿越不同高度时,图像特征也可能会变化,从而影响语义分割模型。例如,当无人机依靠图像实现着陆时,航拍图像会跨越多个飞行高度。
(2)实时语义分割和轻量化模型。实时性和准确性在语义分割模型中较难平衡,现阶段语义分割模型研究重点主要还是在模型精度上,但是对于无人机等嵌入式设备上,设备运算效率较低,存储资源有限,需要响应更快的轻量化模型。
(3)三维语义分割。随着激光雷达点云等设备的应用,点云等三维数据的获取更为便捷,目前大量的无人机航拍语义分割模型工作基于二维图像、三维图像数据集以及语义分割模型是未来的一个研究方向。
(4)弱监督和无监督语义分割。弱监督和无监督语义分割模型可以不依赖大量标注的数据集,但精度仍需提高,弱监督和无监督语义分割也是未来发展的趋势。
最后,对相关研究的检索数据可视化,展示无人机航拍图像语义分割研究活跃期刊和地区(见图7)。可以发现在无人机航拍图像语义分割研究领域,中国学者研究最为活跃,其次是美国;对于期刊而言,Remote Sensing和Sensors 的无人机航拍图像语义分割研究文章相对较多。
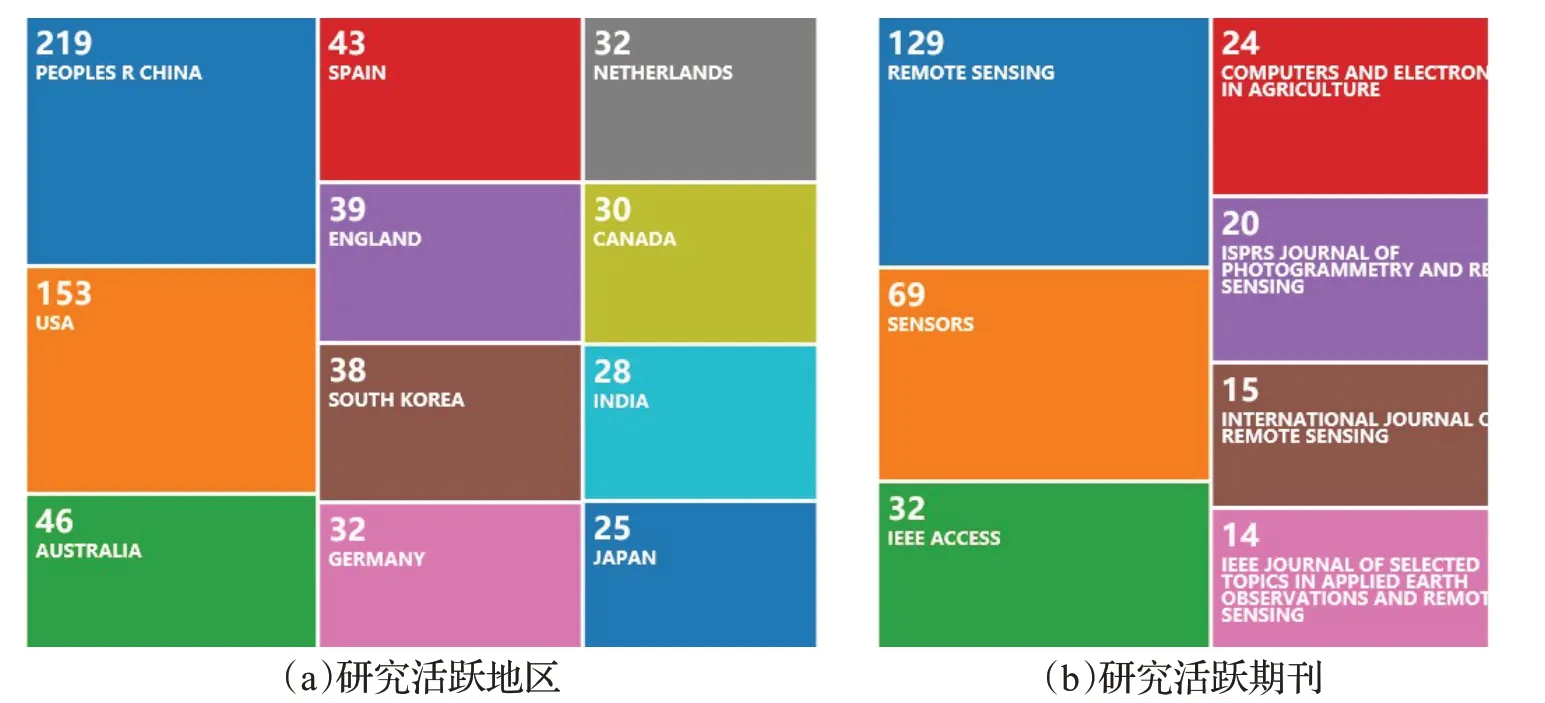
图7 相关研究活跃地区和期刊Fig.7 Related research active regions and journals
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
时代邮刊·下半月(2020年9期)2020-09-23
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
金桥(2018年6期)2018-09-22
小学生优秀作文(低年级)(2018年6期)2018-05-19
北京航空航天大学学报(2018年1期)2018-04-20
作文通讯·高中版(2017年6期)2017-07-10
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
