
基于迁移学习的竹片缺陷识别
2021-10-14 05:02胡峻峰张志超赵亚凤
西北林学院学报 2021年5期
胡峻峰,张志超,赵亚凤,陈 振
(1.东北林业大学 机电工程学院,黑龙江 哈尔滨 150040;2.东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨 150040)
竹林是重要的非木质森林资源,我国现有竹子种类500余种[1]。竹席有优良的透气性、凉爽以及不卷曲等特征,竹席有许多优点,所以竹席的需求量长盛不衰[2]。竹片的常见缺陷是各竹片间的形状差异,人工检测作为传统的检测方法,虽然能直观地观测到缺陷但是仍有一些缺点。首先,当缺陷图像与背景灰度差异较小或者缺陷不是很明显或者缺陷所在图像的背景比较模糊,人工检测会产生较大的误差;其次,人工检测很难跟上工业生产中竹片的传输速率,所以对产品检测的实时性会产生影响;最后,在进行人工检测的过程中或多或少的会受到主观因素影响导致缺陷判断的标准不能百分百相同,导致无法保证检测结果统一准确,并且经过长时间的人工检测,会对人的眼睛、身体等造成疲劳,产生疾病。所以目前我们急需一种实时性好、可靠性高、智能的竹片表面缺陷检测识别分类技术[3]。
国内目前对于竹片检测的自动化设备的生产已经逐步扩大。针对竹片缺陷检测的研究,蒋贤明等[4]推出一款竹片分拣机,该机器侧重点是挑选出未炭化的竹片,对于竹片的其他缺陷检测不够准确,算法相对来说比较复杂且检测速率低。华于生等[5]提出了基于嵌入式的竹片表面缺陷监测系统,但检测速度比较慢而且硬件配置比较落后;陈张言等[2]提出基于机器视觉的竹片缺陷检测系统,检测准确率已经可以>90%,但对于炭化竹片来讲无法做到准确识别;王东旭等[6]提出基于BP神经网络的竹片正反面识别,准确率达到97%,但耗时很长,并且无法识别出竹片本身所存在的缺陷。
为了使试验结果更加真实、准确,本研究数据集为作者自行拍摄。由于数量只有几千张,试验过程中通过迁移学习实现缺陷分类。对有缺陷的竹片进行拍照采集,形成1个有4种缺陷的数据集。利用普通深度学习在卷积神经网络模型上对数据库里边的4类图像进行试验,然后使用迁移学习[7]方法对数据集进行训练,将训练结果和深度学习[8]、支持向量机SVM[9]得到的准确率进行比较。为了更好地比较所使用方法的优缺点,使用了混淆矩阵方法。
1 网络结构
1.1 深度学习
深度学习是机器学习算法研究领域内的全新技术,它的提出重点在于建立和模拟大脑在分析学习时的神经网络。深度学习有三大优点,一是可以处理大数据,二是计算能力强,三是不断创新的算法。卷积神经网络的结构相对于其他网络来说比较深入,是解决图像识别、目标检测等难题的常用网络。尽管深度学习已经经过了很多年的发展,但还是存在缺少必要研究,监督学习和无监督学习发展不平衡等问题[10]。
1.2 迁移学习
迁移学习是可以利用从其他任务中获取的知识来帮助进行当前任务试验的一系列方法,利用此方法,可以有效解决过拟合等问题,关键点就是找出新问题和原问题两者之间有哪些相似性[11]。在小样本数据的条件下,由于数据量不足,会导致训练CNN模型时发生过拟合,无法获得理想识别结果[12]。
迁移学习的应用范围非常广泛,比如用来解决标注数据稀缺问题、误差分享、进行机器人训练等等。通过前期对卷积神经网络的不同构架进行性能、准确率等的比较,选择了比较适合的3个网络结构来进行迁移学习缺陷分类识别试验,分别是Vgg 16、ResNet 50和DenseNet 121。
1.3 卷积神经网络CNN
CNN是一类利用卷积运算并拥有深层结构的前馈型神经网络。它的组成包括输入层、卷积层、池化层、全连接层和输出层[13]。根据试验需求,可以自行设置卷积池化层个数,需要注意的是,在使用CNN时,必须保证2种层是相互连接的关系,不能出现跨层连接。CNN的卷积层的工作原理等同于卷积过程,同时在运算过程中还需要考虑权重和偏置,故而称为卷积神经网络[14]。
1.3.1 卷积神经网络之VGG16 VGG模型于2014年由牛津大学VGG研究组提出,也是一种卷积神经网络[15]。VGG16就是把之前的VGG网络的1*1卷积核都换成3*3卷积核,从头到尾只有3*3卷积与2*2池化,增加网络深度的同时可以有效提升网络训练的效果,相对于其他VGG模型,对数据集的泛化能力更强[16],因此VGG16是目前效果最好的VGG网络(图1)。

图1 VGG 16网络结构Fig.1 VGG 16 network structure
1.3.2 卷积神经网络之ResNet50 ResNet即残差神经网络,是指通过对传统卷积神经网络加入残差学习,使得深层网络里梯度扩散以及准确度降低的问题,使得网络层次可以越来越深,既使得精度提高,又加快了速度。
ResNet50是以现有的训练网络作为基础而提出的一类拥有易优化、计算负担轻等特点的残差学习框架[17]。ResNet50有2个基本的块,分别名为Conv Block和Identity Block,其中Conv Block作用是改变网络的维度,Identity Block是用于加深网络的。残差学习的单元图见图2:
由图2可见,对每层的输入学习形成残差函数,残差块中有2层:

图2 ResNet 50残差单元Fig.2 ResNet 50 residual unit
F=ω2σ(ω1x)
(1)
式中,σ表示非线性函数Relu,ω1、ω2为权重。再利用shortcut以及第2个Relu,获得输出y:
y=F(x,{ωi})+x
(2)
当输入以及输出的维数需要变化,需要在shortcut的时候对x进行线性变换,表达式如下:
y=F(x,{ωi})+ωsx
(3)
1.3.3 卷积神经网络之DenseNet121 DenseNet的核心思想是将每一层与后面的层连接,即对某一层而言,它的输入是前面所有层输出的连结。DenseNet减轻梯度消失,提高了特征的传播效率和利用效率,减少了网络的参数量[18]。在DenseNet中,有如下公式:
xl=Hl(x0,x1,…,xl-1)
(4)
式中,(x0,x1,…,xl-1)表示将0到l-1层的输出特征进行拼接。Dense块的结构见图3。

图3 DenseNet 121网络结构Fig.3 DenseNet 121 network structure
2 数据集
选择在保持同样的拍摄距离和角度的情况下采集图像,拍摄工具为魅族魅蓝e3,保证数据集不因拍摄工具不同而图像质量有区别。给数据集中每张照片进行了编号,这样可以从编号确定照片属于哪一种类,由于相机拍摄时不稳定删除了部分模糊化的图像。数据集内的每一张照片,进行手动裁剪,将每张照片改为统一的256×256,使图像更易于被处理,试验中还采用了原始图像与直方图均衡增强的图像的对比,看是否对结果产生影响。
针对竹片缺陷数据集,共拍摄4类6 360张有缺陷的图像,竹片缺陷种类见表1。表1中a~d表示采集的4种缺陷,图4为原始采集图片和经过直方图均衡增强以后的图片。
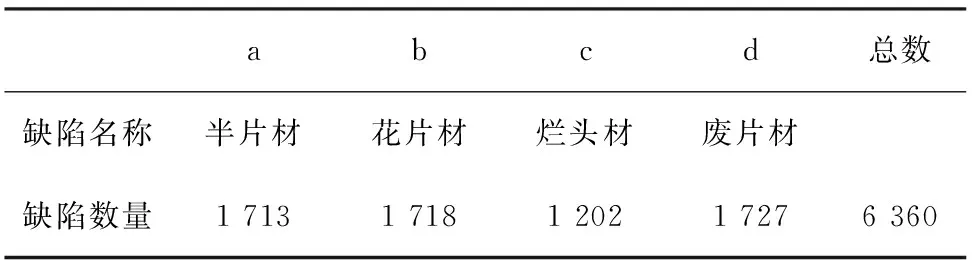
表1 竹材缺陷类别Table 1 Defect categories of bamboo

图4 数据图像Fig.4 Data image
3 试验与结果
3.1 网络训练
分别使用PyCharm和MATLAB软件进行缺陷识别分类研究,使用的Python语言,在使用PyCharm平台时利用的是pytorch框架。采用ubuntu系统,使用拥有16 GB内存的服务器,处理器为第7代英特尔,显卡是NVIDIA的GeForce GTX 1080 Ti。
为防止产生过拟合现象, 在之后的试验中,采取不同比例的数据集分配进行,把竹片缺陷数据集分配成80%、20%(A:80%是训练集,20%是测试集),60%、40%(B:60%是训练集,40%是测试集),40%、60%(C:40%是训练集,60%是测试集),20%、80%(D:20%是训练集,80%是测试集)。同时,训练集和测试集必须包括所有的4类缺陷图片。
采用3种方法:一是支持向量机SVM,使用此方法时,必须人为地提取图像里的特征,即HOG和GLCM;二是利用普通深度学习方法从初始状态开始对训练集进行训练;三是利用迁移网络,也就是迁移学习,与普通深度学习的差异在于权重的初始状态不同。通过比较,分析这3种方法对于训练-测试集的性能差距。试验参数如下:
为了保证结果的可信性及公平性,经过多轮调试之后,最终选取的超参数如下:
学习衰减率:0.001;动量:0.5;学习率:0.01;权值衰减率:0.000 5;批量:32;轮数:60;算法:随机梯度下降。
3.2 研究方法
将6 360张竹片缺陷图像分为4种类型的训练集以及测试集,即A、B、C、D,A类型时,有5 088张训练图像,1 272张测试图像;B类型时,有3 816张训练图像,2 544张测试图像;C类型时,有2 544张训练图像,3 816张测试图像;D类型时,有1 272张训练图像,5 088张测试图像。并且在训练过程中,分别使用VGG16、ResNet50和DenseNet121 3种卷积神经网络进行训练。
由于卷积神经网络在对原始图像进行特征提取时可能出现误差,所以利用直方图均衡增强图像测试在3种卷积神经网络模型中的识别准确率看是否会产生变化。
最后,利用生成的混淆矩阵图,对迁移学习试验数据进行分析与统计,并且分别表示出VGG16、ResNet50以及DenseNet121的混淆矩阵图。
3.3 结果分析
支持向量机SVM、普通深度学习、迁移学习卷积神经网络模型在4类不同百分比分配数据集中的识别正确率对比见表2,可以看出,4种不同分配比例的数据集试验结果里,利用传统深度学习方法得到的最高精度各是81.13%、75.07%、72.72%、68.47%,迁移学习的最高识别精度为88.13%、82.62%、77.27%、70.36%。可以看出,当训练集所占比例的不断减少时,试验识别准确率也在不断变低,当训练集占20%的时候,利用SVM得到的准确率为40.63%,达到最小值,普通深度学习最低识别准确率为33.81%,迁移学习最低识别准确率为63.84%。
原始图像试验结束以后,对经过直方图均衡增强的图像进行试验,结果表明,经过图像增强以后的图像识别准确率与原始图像相比,准确率提升(表2)。从表2中可以看出,4种不同分配比例的数据集试验结果里,利用传统深度学习方法得到的最高精度各是87.42%、83.73%、75.47%、71.62%,迁移学习最高识别准确率为98.97%、94.26%、79.87%、73.66%。当训练集为20%比例时,利用传统深度学习得到的准确率为57.86%,为最小值。利用迁移学习得到的准确率是69.65%,同样是最小值。

表2 竹片缺陷图像识别精度Table 2 Defect image recognition accuracy of bamboo slices
在图像识别过程中,利用传统的支持向量机、普通深度学习和迁移学习,试验结果说明不管是原始图像还是直方图均衡增强图像,不管数据集中训练测试分配比例情况怎样,使用迁移学习获得的识别准确率相比于SVM和普通深度学习均得到了提升。
图5是竹片缺陷识别准确率折线图,可以较好地比较出各种方法在识别准确率上的差异。红色线表示VGG16,蓝色线表示预训练VGG16,绿色线表示ResNet50,紫色线表示预训练ResNet50,黄色线表示DenseNet121,黑色线表示预训练DenseNet121。从折线图可以看出,当训练集占80%,测试集占20%时,使用迁移学习得到的准确率要优于普通深度学习。

图5 竹片缺陷识别折线Fig.5 Broken line diagram of bamboo slice defect identification
3.4 混淆矩阵
使用了混淆矩阵方法对试验结果实施比较。在图6、图7中,蓝色背景代表分类准确率,蓝色越深,则识别精度越高。x轴为数据集测试集,y轴为数据集训练集,1~4分别对应表1中的a~d 4种竹片缺陷类别。其中训练集占80%共5 088张图片,测试集占20%共1 272张图片。
从图6中可以看出,图6(c)的识别准确率最高,在1 272张测试图片中识别正确1 112张图像,其中,第3类识别错误率最高,有4张被识别为1类,43张识别为2类,58张识别为4类,图6(a)识别正确的数量为1 004张,图6(b)识别正确的数量为1 083张。

图6 普通深度学习混淆矩阵Fig.6 General deep learning obfuscation matrix
从图7中可以看出,图7(c)的识别准确率最高,在1 272张测试图片中识别正确1 259张图像,其中第1类识别错误率最高,有5张被识别为2类,1张被识别为4类,图7(a)识别正确的数量为1 166张,图7(b)识别正确的数量为1 170张。

图7 迁移学习混淆矩阵Fig.7 Transfer learning confusion matrix
由此可见,迁移学习得到的结果最优。虽然部分图片分类产生错误,但是总体上识别准确率较高。分类出错的图片主要是缺陷之间可能会由于纹理、形状比较近似等造成相似性过高的原因。
4 结论与讨论
把迁移学习运用到少量数据样本的竹片缺陷识别里,通过和普通深度学习方法以及支持向量机SVM进行试验对比,对训练集、测试集进行训练测试,结果表明当训练集、测试集所占比例为80%、20%时,利用迁移学习的竹片缺陷最高识别准确率是98.97%,比普通深度学习提高了11.55%,比SVM分类方法提高了13.04%,该方法的使用令识别准确率得到很大提高。
使用支持向量机SVM对竹片缺陷图像进行缺陷识别。尽管试验结果比普通深度学习得到的结果要高一些,但是因为本试验所拍摄的图像较少,所以不满足在进行深度学习时需要大量数据样本的条件。而且支持向量机SVM提取特征时必须通过人为的指定图片里的各种特征。图像内部各类特征在进行设定的时候是非常复杂的,如果数据集发生少量或部分改变时,必须对特征进行重新提取。本研究中采用的迁移学习算法的提出经过了充分的资料查阅,利用CNN进行训练,使用相同的数据集、相同的训练-测试集分配比例,以及选取相同的网络模型下与普通深度学习和传统方法SVM相比分类效果比较明显。
本研究同时也面临几个问题:一是竹片缺陷部分图像在缺陷位置、缺陷形状方面有相似性,从构建的混淆矩阵中可以看出,部分图像有几张甚至几十张会被识别为其他类的图像,这种情况对识别准确率产生了一定的影响。二是目前使用的算法只能把图像强制的分为4类,无法做到将识别错误的图像归为单独的一类。针对以上问题,在接下来的时间中会进行深入的学习,通过选用新的算法,改进CNN网络结构,找到以上问题的解决方法。
猜你喜欢
林业科学(2022年6期)2022-10-15
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
小学生导刊(2017年35期)2017-02-25
家教世界·创新阅读(2014年11期)2014-12-15
