
基于人体部件的视频行为识别方法研究
2021-10-13 09:34王亚立
集成技术 2021年5期
夏 鼎 王亚立 乔 宇*
1(中国科学院深圳先进技术研究院 深圳 518055)
2(中国科学院大学 北京 100049)
1 引 言
行为识别是视频任务的一个基础问题,在越来越多的领域中得到应用,如智能监控、机器人交互、视频推荐等。近年来,随着深度学习的发展以及大规模视频数据库的出现,行为识别研究逐步走向成熟。
目前,大多数的方法都是将行为识别看作视频分类,关注于更好地利用视频帧的静态特征与帧之间的动态特征。Karpathy 等[1]提出使用一个二维卷积神经网络,独立地提取每一帧的特征,然后融合时间信息的方法。然而,该方法没有考虑帧之间的动态特征。基于此,Simonyan 和Zisserman[2]提出了双流架构——一个二维卷积神经网络学习静态图片特征,另一个二维卷积神经网络学习光流动态特征。此方法的双流融合策略比较简单,并被广泛扩展到其他方法。其中,时序分段网络(Temporal Segement Network,TSN)[3]采用稀疏采样策略来学习长视频片段特征,并利用光流探索了不同组合策略来融合两个流的特征。但计算光流对计算资源消耗太大,所以时空运动网络(SpatioTemporal and Motion,STM)[4]采用一个模块来学习帧级别的动态特征,节省了计算光流的消耗。与 STM 直接将时空特征与动态特征相加不同,时序激活与聚合网络(Temporal Excitation and Aggregation,TEA)[5]利用动态特征来重校准时空特征,从而加强学习得到的运动模式。除了二维卷积神经网络,三维神经网络也被设计用于学习动态特征。C3D[6]模型将 2D 图像模型扩展到时空间领域,用相似的方法处理空间与时间维度。然而,3D 模型参数较多,对计算资源要求较高。R(2+1)D[7]模型将 3D 卷积分解成 2D 空间卷积加上 1D 时间卷积,节省计算资源。在 3D 模型的基础上,为了更好地利用时间特征,SlowFast[8]使用 Slow 流与 Fast 流捕捉不同的空间与时间特征。这些方法都关注于视频帧级别的高层次特征,易忽视掉动作的细节特征,于是有些方法开始利用更细粒度的特征来提升视频行为分类效果。例如,Wang 和 Gupta[9]利用Region Proposal Network[10]检测出人体位置后,使用图卷积神经网络提取人体级别特征,进行视频行为识别。之后,活动者关系图网络(Actor Relation Graph,ARG)[11]也探索了利用图卷积神经网络提取人体特征的群体行为识别方法。
由于人体是由人体部件组成,且一个人的行为是由每个部件的动作组合而成,所以本研究提出一种利用人体部件特征进行视频行为识别的方法。该方法更深入地挖掘出行为相关的细粒度特征并加以利用,与其他行为识别方法提取的高层特征(如视频帧特征)具有很好的互补性,可以有效提升视频行为识别精度。最终,在 UCF101[12]与 HMDB51[13]两个标准数据集上验证了人体部件特征对于视频行为识别任务的有效性。本文方法具有以下优点:(1)提出了提取人体部件特征的方法用于视频行为识别;(2)利用更细粒度的人体部件特征,将人体行为视为人体部件动作在时空上的组合,有效提升传统视频行为识别方法的精度。
2 基于人体部件的视频行为识别方法
视频行为识别的目的是识别出视频中人类的行为类别,相对于静态图像中的行为识别任务而言,视频行为识别任务的复杂度更高。该任务的主要难点是,视频中人类行为具有类间与类内方差。具体来讲,人类可以在不同的视角下以不同的速度做出同样的行为。另外,一些具有相似动作模式的行为难以区分。传统上,视频行为识别任务被认作是一个高层视频分类任务。目前,主流的二维卷积神经网络方法仍关注于提取更有效的视频帧之间时空特征。然而,这种方法忽视了对人类行为细节的理解。人类行为是由一系列人体部件动作在时空上的组合形成,通过自底向上地理解人体部件动作以及它们的时空组合方式,可以更好地理解人类的高层语义行为。本研究通过提取人体部件特征,自底向上地将人体部件动作组合成人体行为,利用更细粒度的行为特征提升视频行为识别效果。模型架构如图 1所示。
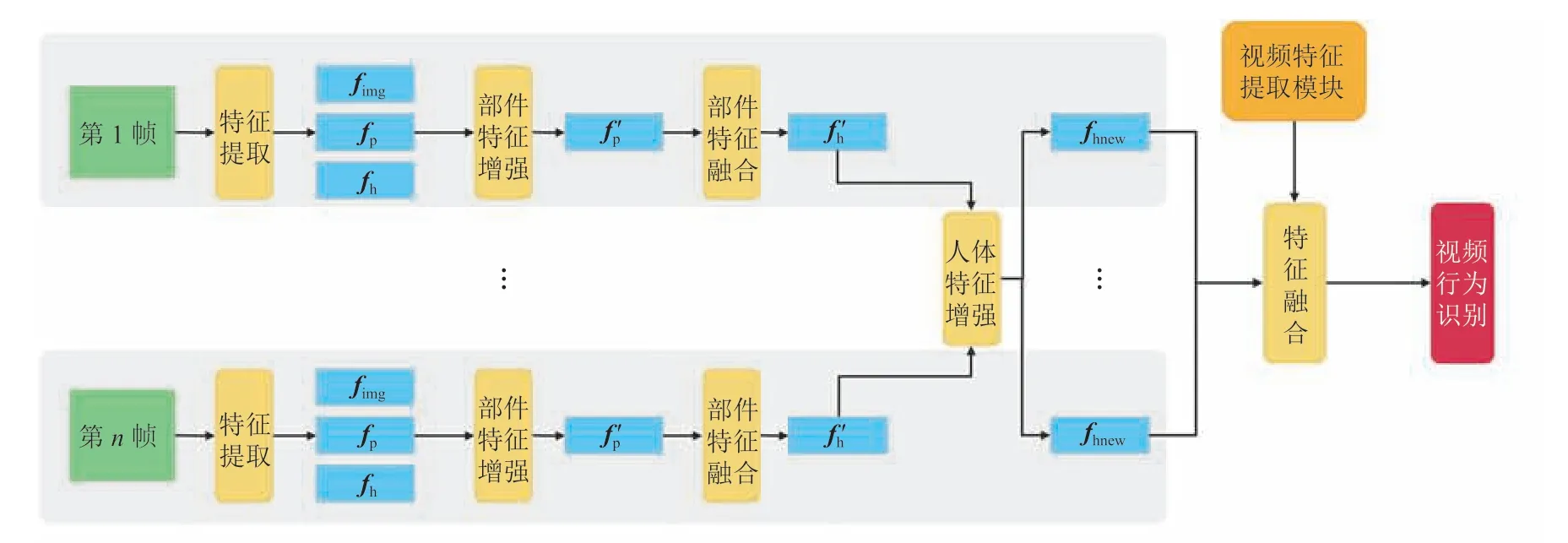
图1 模型架构Fig.1 Model framework
2.1 特征提取
目前,视频行为数据集没有针对人体部件位置的标注,所以本研究通过自动化的方法计算出每个人体部件的位置后,从视频帧提取特征,具体流程如图 2 所示。首先,使用在 Microsoft COCO[14]数据集上预训练的 KeypointRCNN[15]模型检测出每个人的位置框与关节点,之后通过关节点计算出每个人体部件的位置框。使用到的人体部件有:头、左手臂、左手掌、右手臂、右手掌、臀、左腿、左脚、右腿、右脚。然后,使用在 ImageNet[16]数据集上预训练的 ResNet50[17]模型提取视频帧特征,将倒数第 2 个全连接层特征作为视频帧特征,记为fimg。同时,在 stage1 输出的特征图上,根据人体位置框与人体部件位置框,利用 RoIAlign[10]技术提取出人体特征与人体部件特征,维度为 256×7×7,之后通过两层卷积神经网络,重排列成 2 048 维特征向量,记为fh、fp。

图2 特征提取流程Fig.2 Pipeline of feature extracting
2.2 网络模块
该网络由 3 个模块组成:部件特征增强模块、部件特征融合模块和人体特征增强模块。其中,部件特征增强模块负责利用人体特征与视频帧特征等粗粒度的环境信息增强人体部件特征;部件特征融合模块负责将人体部件特征融合成人体特征;人体特征增强模块利用图卷积神经网络,学习视频中所有人之间的关系,从而获得视频级人体表征,用于行为识别。
2.2.1 部件特征增强模块
本文研究以人体部件特征为基础,所以需要增强直接从视频帧上提取的原始人体部件特征fp,作为整个算法的基础。相对人体部件而言,视频帧与人体都属于粗粒度环境信息。该模块通过拼接的方式,将视频帧特征与人体特征等环境信息融合到人体部件特征中,并经过两层全连接层以及一层 dropout[18]层进行降维处理,得到增强的人体部件特征全连接层中间使用ReLU[19]作为激活函数。公式如下:

2.2.2 部件特征融合模块
部件特征融合模块的目标是将增强的各人体部件特征融合成人体特征。由于人体具有自然的分级结构,所以本模块自底向上地分级融合人体部件特征,过程如图 3 所示。首先,融合手掌和手臂的特征,得到手的特征,之后融合左右手与头的特征,得到上半身特征;然后,融合脚与大小腿的特征,得到腿的特征,随后融合左右腿与臀部的特征,得到下半身特征;最后,融合上半身与下半身特征,得到新的人体特征。其中,融合操作由特征拼接操作与一层全连接层组成。

图3 部件特征融合模块Fig.3 Body part feature fusion module
2.2.3 人体特征增强模块
由于视频行为识别需要综合视频中所有人的行为进行判断,所以人体特征增强模块负责综合所有人的行为与位置信息,增强每个人的人体特征,架构如图 4 所示。参考 ARG 网络,该模块使用人体的图像特征以及位置信息来学习每个特征之间的关联性,构建关系矩阵,计算公式如下:

其中,Gij为关系矩阵第i行j列的值;N为所有视频帧上的人体总数;xi、xj表示第i和j个人的位置框左上角与右下角坐标;表示融合后的第i和j个人的人体特征;为对两个人之间的图像特征关系进行建模;为对两个人之间的位置信息关系进行建模。

由于多个人之间的关系比较复杂,所以在此模块对所有人构建了多个关系矩阵G1,G2,…,GNg,其中Ng表示关系矩阵的个数,每个关系矩阵不共享参数。之后利用图卷积神经网络进行信息传递过程,计算公式如下:
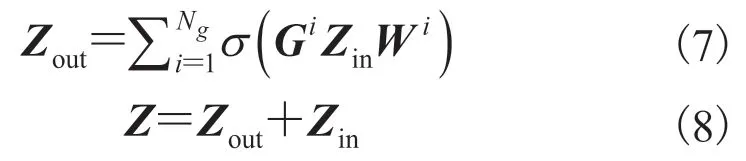
其中,Zout为中间层特征;Zin为由人体特征组成的特征矩阵;W为可学习的权重矩阵;为激活函数,本文使用 ReLU[19]函数;Z为增强的人体特征组成的特征矩阵,记增强的人体特征为fnewh。流程如图 4 所示,每一层的计算如公式(7~8)所示。

图4 人体特征增强模块Fig.4 Body feature enhancement module
3 训练网络
训练网络的主要功能是提取人体部件的细粒度行为特征,融合成人体特征fnewh。在视频行为识别任务中,还需要结合作为环境信息的视频帧特征fframe。记提取视频帧特征的网络为视频特征提取网络,其可以使用 TSN、时序偏移网络(Temporal Shift Module,TSM)[20]、STM、TEA等经典的二维卷积神经网络。由于数据集的大小、数据分布不同,训练网络可能造成过拟合问题,所以本文采用以下两种策略:在出现过拟合问题的数据集上采取独立训练策略,在未出现过拟合问题的数据集上采取联合训练策略。
(1)联合训练。将每一视频帧上的所有人体特征经过平均池化层后,与视频帧特征拼接,之后经过全连接层预测出每一帧的行为分数。随后将所有帧上的行为分数经过平均池化层后得到预测的视频行为分数,取分数最大的类别为预测的视频行为类别。此时,该网络与视频特征提取网络联合训练参数。计算公式如下:

(2)独立训练。与联合训练类似,该策略不拼接fframe、fhuman,而是使用它们独立训练两个网络。测试时将两个网络预测的视频行为分数相加,作为最终视频行为分数的预测值。
4 实验与讨论
本研究使用两个经典的视频行为识别数据集HMDB51 与 UCF101 来验证方法效果。接下来将介绍使用的数据库,以及针对各数据集的实验结果进行分析。
4.1 数据库介绍
HMDB51 数据集是通过各种渠道搜集到的真实视频组成的视频集,如电影和网络视频,包含51 个动作类别的 6 766 个视频片段。本文试验使用标准的 split1 划分方式划分训练与测试集。UCF101 数据集包含 101 个动作类别,13 320 个视频片段。本文实验在两个数据集都采取标准的split1 划分方式划分训练与测试集。
4.2 对比实验
首先,本文在 HMDB51 数据集上进行实验。由于该数据集比较小,联合训练会造成严重的过拟合问题,所以在该数据集上的实验采取独立训练策略。基础网络分别使用 TSN、TSM、STM、TEA 网络作为对比基准,它们的主干网络都选择 ResNet50[17],并在 ImageNet[16]数据集上进行预训练。训练时每个视频等间隔采样 8 帧,每帧选取面积最大的 3 个人。学习率为 0.001,在第 30 和 60 个 epoch 时分别下降至 0.1 倍。采用带动量的随机梯度下降策略,momentum 为0.9,同时加上 L2 正则化,参数为 0.000 5。将两个网络分别训练好后,测试时将二者的预测值经过 Softmax 归一化后相加,数值最大的类别为预测的视频行为类别。表 1 结果显示,对于 4 种基础网络,加上本文方法后都能取得精度提升。例如,使用 TSN 时,本文方法精度提升了 1.43%;使用 TEA 时,达到了过拟合状态,然而使用了本文方法后精度提升了 2.61%。该实验结果表明,基于人体部件的细粒度行为特征与基于视频帧的粗粒度行为特征具有很好的互补性,且能部分解决过拟合问题。

表1 HMDB51 数据集对比实验Table 1 HMDB51 dataset ablation study
其次,在 UCF101 数据集上进行实验。由于该数据集较大,不会造成过拟合,所以采取联合训练策略。基础网络同样采用 TSN、TSM、STM、TEA 作为对比基准,它们的主干网络都选择 ResNet50,并在 ImageNet 数据集上进行预训练。学习率为 0.01,在第 30、45 和 55 个 epoch时分别下降至 0.1 倍。其他参数与在 HMDB51上的实验相同。采用联合训练策略,将两个网络联合训练好后,测试时将视频行为预测值经过 Softmax 归一化,选取数值最大的类别为预测的视频行为类别。表 2 结果显示,对于 4 种基础网络,本文方法都能取得精度提升。例如,使用TSN 时,本文方法精度提升了 2.67%;使用 TEA时,本文方法精度提升了 1.22%。该实验结果同样表明基于人体部件的细粒度行为特征的有效性。

表2 UCF101 数据集对比实验Table 2 UCF101 dataset ablation study
4.3 结果可视化分析
首先,在 HMDB51 测试集上选取性能提升最大的 20 个动作类别进行详细的精度对比。采用的基础网络为 TSN,结果如图 5 所示。从图 5可知,在与人体部件动作强相关的行为类别上,本文方法取得了较大的精度提升,如 shoot_ball、throw、jump、pushup 等。图 6 是基础网络为 TEA 时的对比结果,在 shake_hands、climb、shoot_ball 等与肢体动作强相关的类别上,本文方法同样取得了较大的精度提升。

图5 本文方法与 TSN 网络在 HMDB51 测试集上的类别精度对比Fig.5 HMDB51 class accuracy comparison of ours and TSN
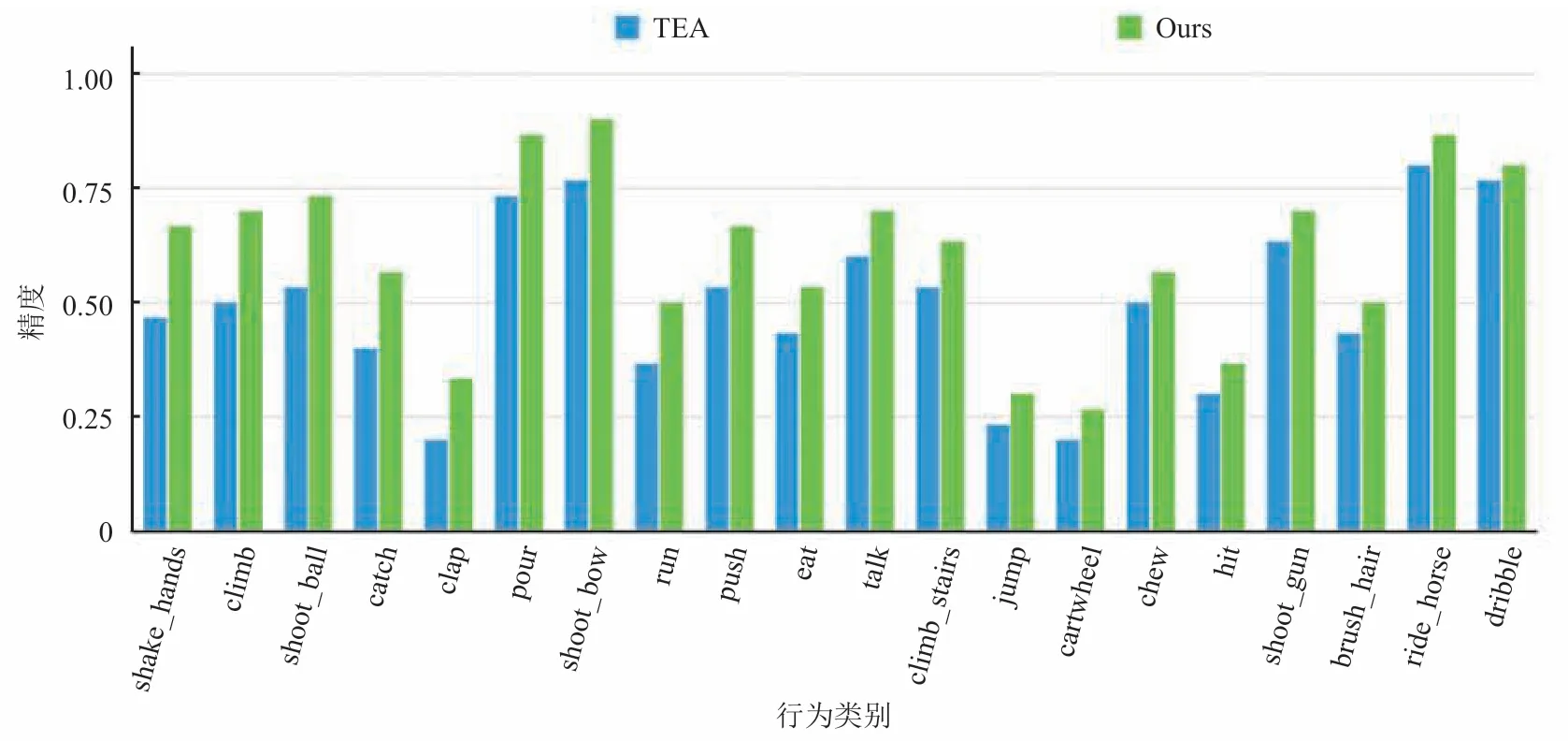
图6 本文方法与 TEA 网络在 HMDB51 测试集上的类别精度对比Fig.6 HMDB51 class accuracy comparison of ours and TEA
然后,在 UCF101 数据集的实验中,选取基础网络为 TSN 时性能提升最大的 20 个动作类别的精度进行对比。图 7 结果显示,在与人体部件动作强相关的类别上,本文方法都能取得较大的分类精度提升,如 BodyWeightSquats、HandstandWalking。图 8 是基础网络为 TEA 时的对比结果,在 JumpingJack、Lunges 等与肢体动作强相关的类别上,本文方法同样取得了较大的精度提升。
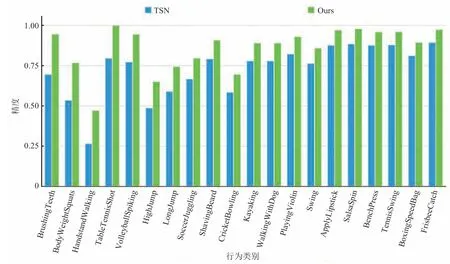
图7 本文方法与 TSN 网络在 UCF101 测试集上的类别精度对比Fig.7 UCF101 class accuracy comparison of ours and TSN

图8 本文方法与 TEA 网络在 UCF101 测试集上的类别精度对比Fig.8 UCF101 class accuracy comparison of ours and TEA
由此可知,在与人体部件动作强相关的类别中,细粒度的人体部件特征能与粗粒度的视频帧特征形成良好的互补,提升视频行为分类效果。
4.4 案例分析
相较于传统方法,本文方法在大部分行为类别上有比较大的精度提升,然而在部分类别上依然有所不足。在 UCF101 数据集上,本文方法在Haircut、HammerThrow 等类别上的错误相对较多,如图 9 所示。其中,Haircut 失败样例大部分都是误识别为 BlowDryHair,从图 9 样例可知,Haircut 与 BlowDryHair 的主要区别是手持工具的不同,由于手掌级别的人体部件动作相似,当算法不能识别出工具时,本文方法就容易进行误识别。对于 HammerThrow 类别,失败样例大部分都是误识别为 ThrowDiscus。通过样例分析可知,该方法主要通过物体与场景进行两个类别的区分。当不能识别出物体时,主要依靠场景进行类别区分。在 HammerThrow 类别中,场景都比较相似,本文方法不能识别出该场景,故容易误识别为 ThrowDiscus。

图9 UCF101 样例分析Fig.9 UCF101 examples analysis
从图 9 可知,在与人体部件动作强相关的类别上,本文方法精度有较好的提升,但在识别人体部件动作相似,主要依靠物体与场景区分的易混淆类别时,本文方法表现不足。由于本文使用的人体部件特征没有更精细化到手指等级别,所以在部分人体部件动作相似的类别上仍然需要依靠物体与场景进行识别。
5 讨论与分析
现阶段对视频行为识别的研究,主要集中在使用粗粒度特征的领域,如视频帧特征或人体特征。然而每个人体部件的细节动作都与视频行为相关,这些方法没有更进一步对细粒度的人体部件特征进行探索,易忽视掉许多行为细节。在不使用 Kinetics[21]数据集预训练,且只使用视频帧的图像数据条件下,TSN 方法在 UCF101 数据集和 HMDB51 数据集上的精度分别为 84.59%、52.29%,此时只使用视频帧特征进行视频行为识别的方法均达到过拟合的状态。融合本文方法后,精度分别为 87.26%、53.72%,分别取得2.67%、1.43% 的提升。可见,对于视频行为识别任务来说,人体部件特征与视频帧特征具有非常好的互补性,同时能够部分解决过拟合问题。本文初步提出一种使用人体部件特征的有效方法,然而相对于 ARG 等网络使用人体特征的方法,本文研究利用人体部件特征的方法显得比较直接。
6 结论
针对现有视频行为识别使用特征层次过高,在关注动作细节的类别上效果不是很好的问题,本文提出一种基于人体部件特征的视频行为识别方法。该方法可以对人体部件进行自动定位,提取基于人体部件的细粒度行为特征,从而有效地进行视频行为识别。同时,本文介绍了两种训练策略,针对不同的数据集可以采取更合适的对应策略。实验结果表明,使用不同的基础网络,本文方法都可以有效地提升视频行为识别效果。在实际的视频行为数据中,每个人体部件都有各自的动作,然而当前的数据集的标注只针对视频级别或者帧级别进行标注,没有提供每个人体部件级别的监督信息,所以大部分的方法都没有细化到提取人体部件特征。本文初步证明了人体部件特征的有效性。未来工作中,将重点关注人体部件特征融合方式的探索,以及如何更有效地将细粒度的人体部件特征与粗粒度的视频帧特征结合起来,以提升视频行为识别效果。
猜你喜欢
装备制造技术(2020年4期)2020-12-25
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
制造技术与机床(2018年9期)2018-09-19
民族古籍研究(2018年1期)2018-05-21
海外华文教育(2017年6期)2017-08-07
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
中国中医药现代远程教育(2014年16期)2014-03-01
