
基于图卷积记忆网络的方面级情感分类
2021-10-12 04:39李鸿宇邱云飞郁博文柳厅文
中文信息学报 2021年8期
王 光,李鸿宇,,邱云飞,郁博文,柳厅文
(1. 辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105;2. 中国科学院 信息工程研究所,北京 100089)
0 引言
方面级情感分类是一种细粒度情感分析任务,目标是确定评论文本中所出现的不同方面的情感倾向[1-2]。如图1中方面级情感分类实例图所示,已知“food” 和“service” 方面词,方面级情感分类模型需要通过文本评论句子和方面词“food”判断出评论者对食物的情感倾向是正向的,依据“service” 方面词推断出服务是不令人满意的。本文实例中方面词使用下划线标识,通过粗体词汇标识评价词,评论者对每个方面词的情感倾向取决于评价词与方面词的对应关系,由于评论者对不同方面词的情感态度存在差异,因此错误地匹配评价词与方面词可能会带来相反的判断。相对于篇章级别、句子级别和词汇级别情感分类任务而言,方面级情感分类的针对性更强,不但可以帮助消费者筛选出满足自身需求的商品,而且还能指导商家进行产品改进。

图1 方面级情感分类任务实例
虽然神经网络模型在方面级情感分类任务中已取得了良好的效果,但现有方法没有很好地利用句法信息来辅助分类。一般来说,方面级情感分类任务中的评价词往往出现在句法关系复杂的文本中,以文本评论“We didn’tknow if weshouldorder adrinkorleave?”为例,在句法关系十分复杂的句子中,判断评论者对方面词“drink”的情感态度需要全局的语义理解和推断,而通过句法分析能够帮助模型找到“drink”相关的评价词,进而完成情感分类。受到文献[3-4]图卷积神经网络(GCN, Graph Convolutional Network)在文本分类领域成功应用的启发,本文提出了一种结合图神经网络和注意力机制的方面级情感分类方法MemGCN,它能够有效利用句法依存信息辅助分类。在三个公开的方面级情感分类数据集上,证明了MemGCN模型的优越性能。
1 相关工作
方面级情感分类的研究工作基于统计机器学习方法开展。Kiritchenko等[5]利用情感词典和特征工程提取情感信息,训练支持向量机(Support Vector Machine,SVM)情感分类模型,在笔记本电脑和餐馆领域的方面级情感分析评测任务中取得当时最好的效果。
由于通过构建情感词典和手工提取特征的方法[6],一方面需要投入高额的人工成本,另一方面机器学习算法很难突破性能瓶颈,无法学习到方面词与句子中上下文词汇之间的关系。随着神经网络算法的兴起,自动提取特征的卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)等深度学习算法在方面级情感分类任务中显著提升了分类性能。Tang等[7]提出带有方面词依赖的TD-LSTM模型,利用两个不同方向的长短时记忆网络(Long Short Term Memory Network,LSTM)分别学习方面词上文信息和下文信息,提升了模型分类效果。
近年来,注意力机制(Attention Mechanism)在机器翻译、文本摘要与问答系统等自然语言处理领域均得到了成功应用[8-9]。注意力机制的变体在方面级情感分类任务中也发挥了重要作用。Wang等[10]将长短时记忆网络和注意力机制进行结合,提出了方面词嵌入方法,使得ABAE-LSTM模型可以关注到方面词所对应的情感信息。曾锋等[11]采用层次注意力机制对词汇维度和句子维度分层建立模型,在由多个句子组成的文本评论中,分类效果获得了显著提高。
Xue等[12]提出的GCAE模型结合了卷积神经网络和门控机制,利用并行计算大幅加快了方面级情感分类模型的训练速度;梁斌和刘全等[13-14]证明卷积神经网络与注意力机制和长短期记忆网络结合均能改善模型;杜慧等[15]将词向量、词性信息和注意力同时融入到卷积神经网络和循环神经网络中,增强了模型的性能。此外,Tang等[16]设计记忆网络(Memory Network)在SemEval-2014,方面级情感分析任务中取得最佳成绩;Ma等[17]训练得到对方面词和上下文信息同时建模的IAN模型提升分类效果;Chen等[18]提出的RAM模型是对MemNet模型的改进;Zhu等[19]提出带有辅助记忆网络的方面级情感分类方法,学习方面词和情感词之间的信息,进一步优化了方面级情感分类模型。
2 基于图卷积记忆网络的方面级情感分类
MemGCN模型由文本表示层、语义学习层、位置记忆层、图卷积神经网络层、注意力机制和情感分类层组成,整体框架如图2所示。为便于理解和描述,文中文本评论句子使用S={w1,w2,…,wt-1,wt,…,wt+l,wt+l+1,…,wn}表示,其中,n表示句子中词的数目,方面词为wt,…,wt+l,可能由一个或多个词构成。t和l分别表示词的位置和方面词的长度,w1,w2,…,wt-1与wt+l+1,…,wn分别指代上文词和下文词。

图2 MemGCN模型的整体框架
2.1 文本表示层
Word2Vec、FastText、GloVe等[8,20]无监督词表示方法广泛应用于自然语言处理的各项任务中,能够表示文本的语义信息。将词向量集合表示为T∈Rd×|V|,其中,d为词向量维度,|V|是词汇个数,句子S映射到低维、连续、稠密空间后对应V={v1,v2,…,vt-1,vt,…,vt+l,vt+l+1,…,vn}。借助词嵌入方法思想,本文将方面词和评论文本中的词汇的词性映射到低维、连续、稠密的空间。文本表示层的输出包括词向量、词性向量和方面词向量,xt={[v1;pos(w1);aw],[v2;pos(w2);aw],…,[vt-1;pos(wt-1);aw],[vt;pos(wt);aw],…,[vt+l;pos(wt+l);aw],[vt+l+1;pos(wt+l+1);aw],…,[vn;pos(wn);aw]}。若同一条评论中不止有一个方面词被提及,则分开处理。
2.2 语义学习层
文本评论数据中词之间存在时间序列关系,循环神经网络能够学习到长距离的语义依赖信息。门控循环单元[21](Gate Recurrent Unit,GRU)是一种循环神经网络,其结构如图3所示,门控机制能避免RNN梯度弥散问题, 而且比LSTM拥有更少的参数量,所以训练模型的速度更快。
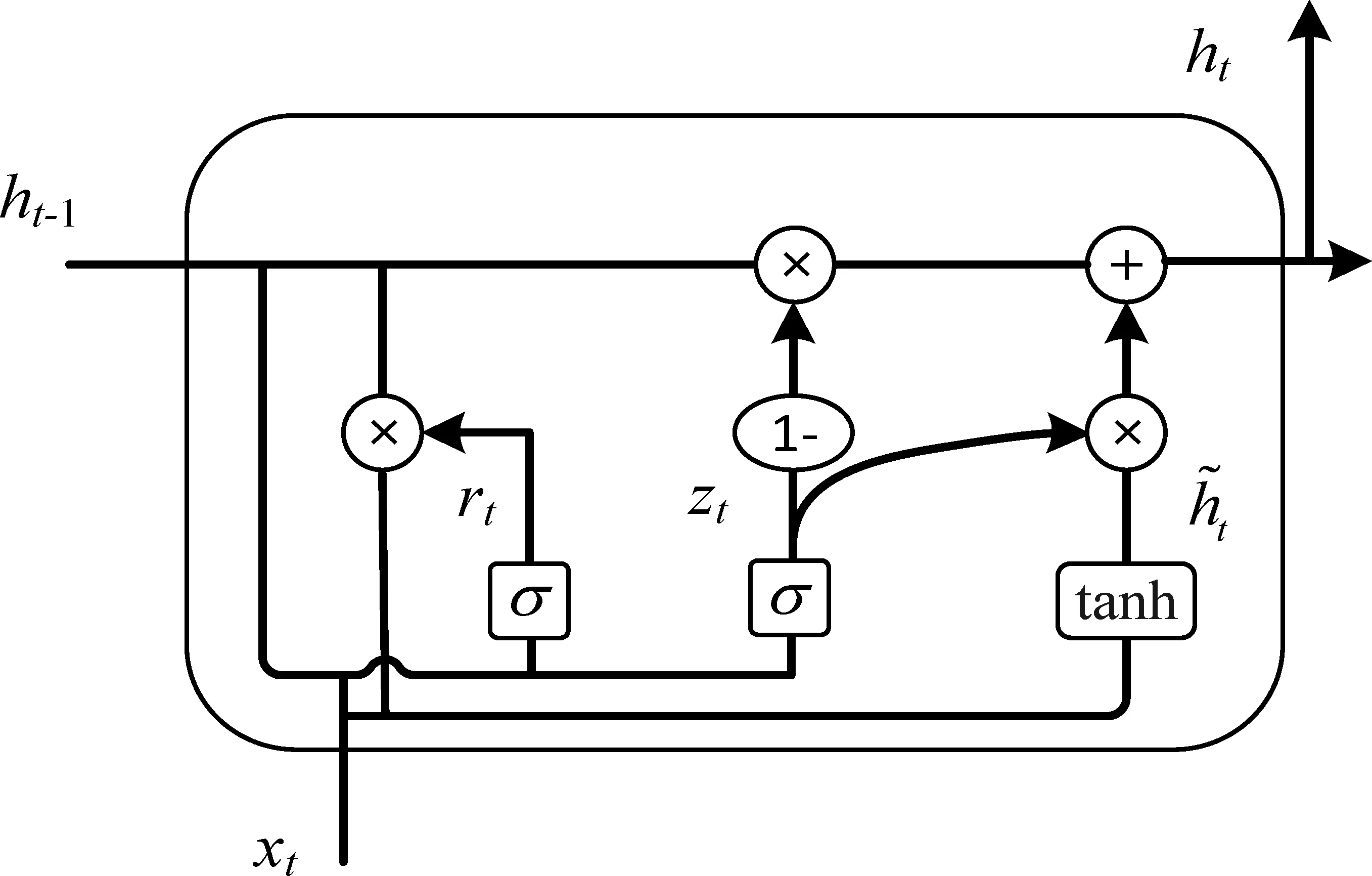
图3 门控循环单元的结构
图3中的xt和初始化为xt的ht-1为门控循环单元的输入,分别表示t时刻文本表示层输出信息和上一时刻门控循环单元输出信息。更新门zt和重置门rt的计算方法如式(1)、式(2)所示。

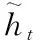
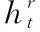
2.3 位置记忆层
在方面级情感分类任务中,利用方面词与上下文词汇的相对位置信息可以有效地辅助模型判断[22]。因为评价方面词的情感词一般存在于方面词周围,所以方面词附近的词汇理应具备更高的重要性。位置记忆层中用于计算词汇相对位置权重的计算如式(8)所示。
2.4 图卷积神经网络层
方面级情感分类任务中的评论大部分属于长难句,因此能够辅助模型梳理句法结构信息会增强方面词与评价词之间的联系,使得情感分类更加准确。文本评论的依存句法分析树借助SpaCy工具获得,如图4所示实例“Greatfoodbut theservicewasdreadful!”的依存句法树结构中蕴含着丰富的句法信息。

图4 依存句法树实例图
本文将图卷积神经网络[23-24]应用于解决方面级情感分析任务中,充分利用依存句法分析树,让模型具备句法感知的能力。融合句法信息的图卷积神经网络层实例结构,如图5所示。

图5 图卷积神经网络层实例结构
通过将词汇表示为节点,词汇之间的关系抽象为边,可以将评论文本使用图结构进行表示。利用图卷积神经网络具备提取相邻节点之间特征的能力,学习评论文本中词汇之间的关系。邻接矩阵A归一化的计算如式(10)所示。
其中,D表示依存句法树的度矩阵。

2.5 注意力机制
本文提出综合语义、词性、方面、位置和句法信息的注意力机制[26],将语义学习层、位置记忆层和图卷积神经网络层获取的文本信息进行有效利用。

2.6 情感分类层
方面级情感分类是一种多分类任务,由正向、中性和负向三种情感标签组成,情感分类层将注意力机制关注的信息ha作为输入,每种情感标签概率Ps按照式(15)进行计算。
其中,softmax为多分类任务中的激活函数,Ws和bs分别为情感分类层的权重和偏置。
3 实验
3.1 数据集
通过在三个公开数据集上的实验来验证本文提出模型的优越性,分别为SemEval-2014任务四[18]的餐馆和笔记本电脑领域的方面级情感分类数据集,以及由Dong等[6]所整理Twitter社交领域的方面级情感数据。该数据集中的每条样本都是由评价者真实生成的句子、句子中出现的方面词和方面词对应情感类别所组成,并且标签只包含正向的、中性的和负向的情感,数据集标签类别分布情况见表1。

表1 数据集标签类别分布统计表
3.2 评价指标
本文采用准确率Accuracy和Macro-F1值(简写为F1)作为评价指标,验证方面级情感分类任务中的模型性能。
其中,P为由计算式(18)得出的Macro-Precision,R代表Macro-Recall,由式(19)计算得到。
其中,C的值取3,因为类别中包括正向的、中性的和负向的三种标签。真阳率TP和真阴率TN分别表示模型正确预测正向、中性和负向情感类别的样本数,假阳率FP和假阴率FN则分别表示模型错误预测正向、中性和负向情感类别的样本数。
3.3 目标函数
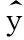
其中,D表示训练集数据样本量,C与式(18)和式(19)中的C意义相同。为缓解模型训练时过度拟合训练集的问题,使用系数为λ的二范数作为正则化项。
3.4 参数设置
优化器使用Adam算法,模型使用10-3学习率,连续5次性能不提升则提前停止学习。词嵌入方法分为两种,一种是GloVe840B[20]预训练的300维词向量,另一种使用包含12层网络结构的BERT[27]预训练语言模型输出作为词向量,维度是768维。文本中出现的未登录词和词性向量的维度均为50,随机初始化矩阵中的参数满足(-0.01, 0.01)的均匀分布。同时,为防止模型缺乏泛化能力,使用值为0.5的Dropout参数随机失活神经网络的神经元,正则化系数λ设置为10-5。
3.5 对比模型
本文对比模型如下:
•SVM[5-6]: 支持向量机分类器,通过人工构造大量特征,并引入外部情感词典等方式完成分类。
•LSTM: 长短时记忆网络模型,用于方面级情感分类。
•TD-LSTM[7]: Target-Dependent LSTM模型,在方面词前后上下文分别建模,使用正向和反向两个LSTM进行细粒度情感分类。
•ATAE-LSTM[10]: Attention-Based LSTM with Aspect Embedding模型提出方面词嵌入概念,并采用注意力机制加深文本评论中方面词相关词汇的关注度。
•GCAE[12]: Gated Convolutional Networks模型,结合门控机制和卷积神经网络进行方面级情感分类,卷积核数目为100,卷积核尺寸是[3, 4, 5]。
•IAN[17]: Interactive Attention Network模型,通过注意力机制分别对方面词和上下文建模进行方面级情感分类。
•RAM[18]: Recurrent Attention Network on Memory模型,提出循环注意力机制完成方面级情感分类任务,多跳数目设置为3。
•AOA[28]: Attention-over-Attention Network模型。联合学习方面词和上下文表示,利用注意力机制自动关注文本评论中的重要词汇。
3.6 实验结果与分析
实验在搭载Intel(R)Xeon(R)CPU E5-2620处理器和型号为Tesla P100 GPU,拥有32GB内存的服务器上进行。软件环境为Ubuntu 16. 04. 6 LTS操作系统,Python 3.6.2开发平台,基于PyTorch深度学习框架构建模型。在三个领域的测试集上模型的指标对比结果如表2所示,评价指标分别是3.2节所介绍的准确率Accuracy和宏平均的F1值,最好的结果加粗表示。由于SVM模型用到未知的特征无法进行复现,因此本文引用Kiritchenko等[4]与Dong等[18]论文中的结果进行实验对比,NA表示没有获得的结果,表2中其余模型表现均为本文实验复现结果。此外,除MemGCN-BERT模型之外,均采用预训练的GloVe词向量进行文本表示,并且最终结果为5次实验的平均值[29]。

表2 测试集上模型的评测结果表

续表
从表2可以看出: 首先,基于统计机器学习的SVM模型在Restaurant数据集上的效果优于LSTM模型,但它们都无法解决评论者对不同方面词情感态度不一致时的方面级情感分类问题。其次,TD-LSTM模型借助双向LSTM对方面词与上下文建立联系,三个数据库中均取得了模型性能的提升。再次,ATAE-LSTM模型的性能相对于LSTM模型获得了1%~3%幅度的性能提升,这证明了方面词向量和注意力机制的有效性[30-31]。最后,基于CNN的GCAE模型,在全部评测数据集上均与TD-LSTM有着相近的表现,但是其具有可以并行计算、模型训练和预测速度更快的优势。
IAN、RAM与AOA模型均采用了将注意力机制与RNN结合的方式改进模型,从表2的结果可以看出,IAN模型在Laptop和Restaurant数据集上的性能略低于RAM模型,而在Twitter数据集上模型效果显著提升,AOA模型在三个公开数据集上均取得优秀的方面级情感分类效果,这说明通过注意力机制与循环神经网络结合方式的设计改进,对于优化方面级情感分类模型性能有重要意义。
本文提出的融合注意力机制与词性、方面、位置和句法等辅助信息的MemGCN模型在Laptop、Restaurant和Twitter数据集上均取得优异的方面级情感分类效果。与LSTM相比,MemGCN模型在SemEval-2014任务四中F1值均提高超过7%,Twitter数据集上准确率取得了3%左右的提升。此外,实验中尝试采用预训练语言模型对用户评论进行文本表示, MemGCN-BERT模型在全部公开数据集上均达到最佳的表现,这证明了BERT相比于 GloVe更擅于表示文本,下游的图卷积记忆网络模型能够捕获到更多的情感信息。虽然使用预训练语言模型可以获得分类效果的进一步提升,但是训练模型和使用模型进行预测时需要花费更多的时间,而且模型训练也会占用大量内存、计算资源和存储空间。另外,在样本量充足且均衡的社交领域数据上,通过两种文本表示方法训练出来的模型效果较为接近。
为验证词性、方面、位置和句法四种辅助信息对MemGCN模型分类准确率和F1的影响,实验中对MemGCN模型进行了如图6和图7所示的消融实验。在柱状图中,使用黑色表示包括所有辅助信息的MemGCN模型性能,灰黑色、灰色、灰白色和白色柱用于区分去掉位置、句法、词性和方面信息的模型表现。

图6 句法与辅助信息对分类准确率的影响
首先,在图6和图7中均可以看出,词性、方面、位置和句法四种辅助信息都有益于MemGCN模型进行方面级情感分类。其次,本文提出的句法信息对于模型性能的影响是最大的。最后,其余辅助信息对MemGCN模型性能影响的重要程度依次为方面信息、位置信息和词性信息。

图7 句法与辅助信息对分类F1影响
为进一步探索不同模型的方面级情感分类效果,本文分别将GCAE、IAN、RAM和AOA模型与本文所提出的MemGCN模型实例分类效果进行对比分析。各模型在两个实例、三个方面词上的分类结果见表3,其中,“真实”列表示评论者的正确情感类别。在对比中可以发现,MemGCN模型具备根据特定方面词进行情感分类的能力,而在句法结构复杂的句子中,对比模型难于给出正确答案。

表3 实例分析
图8~图10分别为MemGCN在餐馆领域正向、负向和中性情感实例的可视化分析,如图所示,颜色越深则代表注意力权重越大。

图8 “food”“service”方面注意力权重示意图

图10 “drink”方面注意力权重示意图
在图8中,实例的两个评价词分别修饰两个方面词。对于“food”方面词来说,本文提出的MemGCN模型对带有明显正向情感的形容词“Great”注意力机制的权重最大,于是能够将方面词“food”归于正向评价。同样地,当方面词为“service”时,MemGCN模型的注意力集中在“dreadful” 评价词上,因此将服务方面评论的情感态度分类为负向。
通过图9对以上评论文本依存句法分析树的可视化,证明了在一句话中同时出现多个方面词与多个评价词时,MemGCN可以正确匹配方面词对应的评价词,这样可以保证记忆网络在看到新的评价词“dreadful”时,不会遗忘“Great”对“food”方面的修饰,也可以解决模型过于关注评价词“Great”而与“service”方面词错误匹配的问题。

图9 实例的依存句法树可视化示意图
从图10可以看出,在句法结构较为复杂的实例中,MemGCN模型的注意力集中在否定词“n’t”“should”和“leave”词汇上,将此实例的情感判别为中性。由于训练数据中中性情感的样本量较小,而且有离开之意的“leave”词距离方面词很近,可能将这条数据错误预测为负向情感。
4 总结
为解决复杂句法结构中的方面级情感分类方面词与评价词之间的依赖问题,本文使用注意力机制,结合记忆文本语义、词性、方面与位置信息的记忆网络,以及基于依存句法分析树的图卷积神经网络,提出了一种句法信息感知的方面级情感分类模型。实验结果证明,通过加入句法信息,可以增强评价词与方面词之间的联系,能够明显改善方面级情感分类的效果。在未来的工作中,我们将尝试更先进的预训练语言模型优化语义信息,并计划将本文提出的模型在其他细粒度情感分析任务,如评价对象提取中进行尝试。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中华诗词(2021年3期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
大连民族大学学报(2021年2期)2021-07-16
电子制作(2019年11期)2019-07-04
中华诗词(2018年3期)2018-08-01
北京航空航天大学学报(2018年1期)2018-04-20
中华诗词(2018年11期)2018-03-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
