
基于word2vec与LDA主题模型的技术相似性可视化研究
2021-10-11 10:14席笑文宋欣娜
情报学报 2021年9期
席笑文,郭 颖,宋欣娜,王 瑾
(1.中国科学院档案馆,北京 100190;2.中国政法大学商学院,北京 100088;3.北京理工大学管理与经济学院,北京 100081)
1 引 言
社会经济的快速发展和需求的快速更迭,迫使研发主体需要不断提高技术创新性与复杂性,以适应瞬息万变的现代经济。这就要求研发主体不断地进行创新活动,来保持自身的先进性,以在激烈的市场竞争中把握先机、抢占技术制高点。而技术相似性是研发主体进行识别潜在竞争与合作伙伴、技术转移、协同创新、并购等创新活动的重要依据[1],同时,也是企业、组织或国家进行技术情报分析的重要内容。由此可见,如何科学、准确地测度技术相似性成为值得考虑的问题。
传统的技术相似性测度方法主要依赖于专利分类体系,然而,分类体系存在着两个明显的问题:一是无法直观地反映专利的技术特征;二是不同类和子类可能出现重要的重叠,从而出现技术相似程度高的专利却属于不同分类的情况。随后,学者们开始尝试从专利引用关系角度进行分析,主要包括专利耦合、专利互引分析等,由于该方法存在专利引文施引动机的不明确性以及专利引用的滞后性等问题,使得技术相似性测度结果的准确性受到质疑。为了解决上述问题,基于文本挖掘的技术相似性测度方法开始受到研究者的广泛关注。该类方法通常采用one-hot向量或者词袋模型表示专利权人的技术主题,一方面,仅考虑词的共现关系,未考虑词间的语义关联性,无法细粒度地表示专利权人的技术主题;另一方面,高维稀疏向量的运算烦琐且复杂,这使得测度结果在准确性上具有较大的局限性。近年来,较为流行的深度学习方法,能够将文本内容包含的上下文语义信息表示为低维稠密向量,能够有效地解决上述问题。
因此,本文引入深度学习方法,构建基于word2vec和LDA(latent Dirichlet allocation)主题模型的技术相似性测度框架,并选取NEDD(nano en‐abled drug delivery)领域为例,论证本文的合理性与科学性,以期为进一步测度技术相似性的研究工作提供借鉴与参考。
2 文献综述
1986年,Jaffe[3]首次运用美国专利局的原始分类体系,将专利划分为400个左右的子类,并基于此计算各发达国家间的技术相似程度,开创了基于专利分类法计算技术相似性的先河。随后,Jaffe等[4]在进行企业间知识流动的研究时,利用专利分类法查看各个企业间专利重叠程度,来衡量企业间的技术相似性。蔡虹等[5]也借鉴此类方法对比了中国与一些创新型地区或国家的技术相似性。Kogler等[6]提出,基于专利分类法计算技术相似性时,应该将专利所属技术类别的权重考虑在内。此类方法主要依赖于专利局的分类体系衡量专利间的技术相似性以及企业专利组合间的相似性,显然存在以下问题:①传统的IPC(international patent classifica‐tion)分类体系坚持以应用为主、功能为辅的分类原则,无法直接体现专利的技术主题特征;②不同的类和子类可能包含重要的重叠,可能出现技术上相似的专利但却属于不同分类的情况。
之后很多学者开始借鉴文献计量学的方法测度技术相似性。Lai等[7]依据专利间的引用关系,构建专利分类体系,从而计算专利间的技术相似性。张曦等[8]利用专利共被引分析法,以选取的28家世界500强企业为研究对象,探讨了企业和产业间的技术关联以及技术的相似性。同时,也有部分学者使用专利耦合分析法测度专利相似性。例如,Huang等[9]选取台湾地区的58家高科技电子企业为分析对象,运用专利文献耦合方法计算企业间的技术联系。Lo[10]在专利耦合方法的基础上,创新性的结合相关性分析和多维尺度分析,来探究基因工程领域内重点研发机构间的技术关联。洪勇等[11]在专利耦合分析原理的基础上,改进了耦合强度的计算方法,并构建了企业间技术相似性可视化分析与应用流程框架,且选取平板显示技术领域为实例进行论证。然而,该类方法由于专利引文施引动机的不明确以及专利引用存在的滞后性等问题,显然较难真实地反应专利权人间的技术相似程度。
为了解决上述问题,学者们开始从文本挖掘的角度展开研究。例如,Arts等[2]学者通过关键词间的语义相似性,来度量专利间技术相似性,且由来自不同领域的美国专家进行验证,证明了该方法的测度效果优于基于专利分类体系的测度效果。Yoon等[12]以专利文献为研究对象,采用文本挖掘技术构建关键词的词向量,进而运用欧几里得距离来计算专利的相似度。彭继东等[13]基于文本挖掘技术,以专利标题、摘要、权利要求和说明书4个文本元素的加权相似度作为专利相似度的测量。张端阳等[14]运用LDA主题模型获取专利文档的技术主题向量,并采用余弦相似度来测度专利间的技术相似度。该类方法往往仅考虑词间的共现关系,忽略了词与词间的上下文语义关系,使得技术主题特征的表示缺乏语义,同时,存在计算复杂性高的问题。word2vec模型能够有效解决语义关系抽取问题,且能够将技术主题特征表示为低维稠密向量,使得从词粒度层面对专利权人进行精细语义建模成为可能[15]。
基于此,本文构建了基于word2vec和LDA主题模型的技术相似性测度方法,尝试从“词粒度”层面实现专利权人的精细语义建模;同时,由于缺乏将技术相似性测度结果直观展示并加以应用的流程框架,本文进一步构建了能够综合反应专利权人与技术主题关系的二模网络[16],以全面揭示研究领域专利权人技术布局情况及技术相似性关系,为企业、组织或国家识别潜在竞争关系和合作伙伴提供参考。
3 研究方法
本节内容主要介绍了基于word2vec和LDA主题模型的技术相似性可视化研究框架的构建过程,选取专利文本为研究对象。首先,利用word2vec模型学习特征词在文档集合中的上下文语境信息;其次,结合LDA主题模型,构建的专利权人-专利-技术主题三层概率分布合成“词粒度”层面的主题向量、专利文本向量及专利权人向量;再次,基于向量相似度计算指标计算专利权人间的语义相似度;最后,构建能综合揭示专利权人-技术主题关联的二模网络。本文的研究方法框架如图1所示。
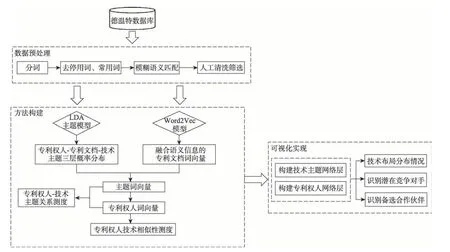
图1 研究框架流程图
3.1 数据预处理
本文以分析领域内的专利权人作为研究对象,通过从专利文本内容(摘要与标题)中提取技术特征词表征专利权人的技术主题集合。因此,需要对专利权人及专利文本内容进行预处理,从而方便研究对象的选取与技术主题的提取。
1)专利权人的清洗
因不同表达形式、中途改名等会使得专利权人名称存在重复的情况,也会因公司并购或解体出现专利权人名称不存在的情况,故本文需要对专利权人的名称进行统一。DII数据库为每个专利权人均提供了唯一且标准化的专利权人代码。因此,本文采用专利权人代码实现专利权人名称的清洗。
2)文本结构化处理
本文使用VantagePoint中自然语言处理相关模块,对专利文本内容(标题和摘要)进行预处理,主要包括分词、去停用词、模糊语义匹配、去除低频词等步骤,以减少文本噪音,提高信息质量。
3.2 构建基于word2vec和LDA主题模型的技术相似性测度方法
1)利用word2vec模型学习特征词向量
word2vec通过训练特征词在专利文档中的上下文语义信息,将包含文本语义的特征词表示为低维稠密向量。其主要包含CBOW(continuous bag-ofwords model)模型和skip-gram模型,前者是利用词的前后n个词来预测当前词,后者则利用当前词所在的语境预测前后n个词[17]。
为了解决LDA主题模型的语义提取及高维稀疏向量的问题,本文尝试引入word2vec学习专利文本的上下文语义信息,更为细粒度地表示专利权人的研究主题特征。具体来说,将分词后的专利文本集合作为模型的输入,通过不断调参,得到包含语义信息的特征词向量,从而为后续生成专利权人的技术主题向量奠定基础。
2)利用LDA主题模型构建专利权人-专利-技术主题概率分布
LDA主题模型的基本思想是将文档看作多个隐含主题的集合,然后不断模拟文档生成过程,从而识别语料或者文档中的潜在主题信息,利用获得的文档-主题概率关系来反映每个文档的潜在主题,通过获得的主题-主题词项概率分布来反映每个主题的主要内容。通过对大规模的语料库或者文档的建模,能够挖掘出文档中隐含的主题信息。
本节首先通过专利文档集合训练LDA主题模型,得到专利-主题、主题-主题词项间的概率分布关系;然后,依据专利文本与专利权人所属的对应关系,构建专利权人-专利-技术主题三层概率分布。三层概率分布的具体构建方法如图2所示。
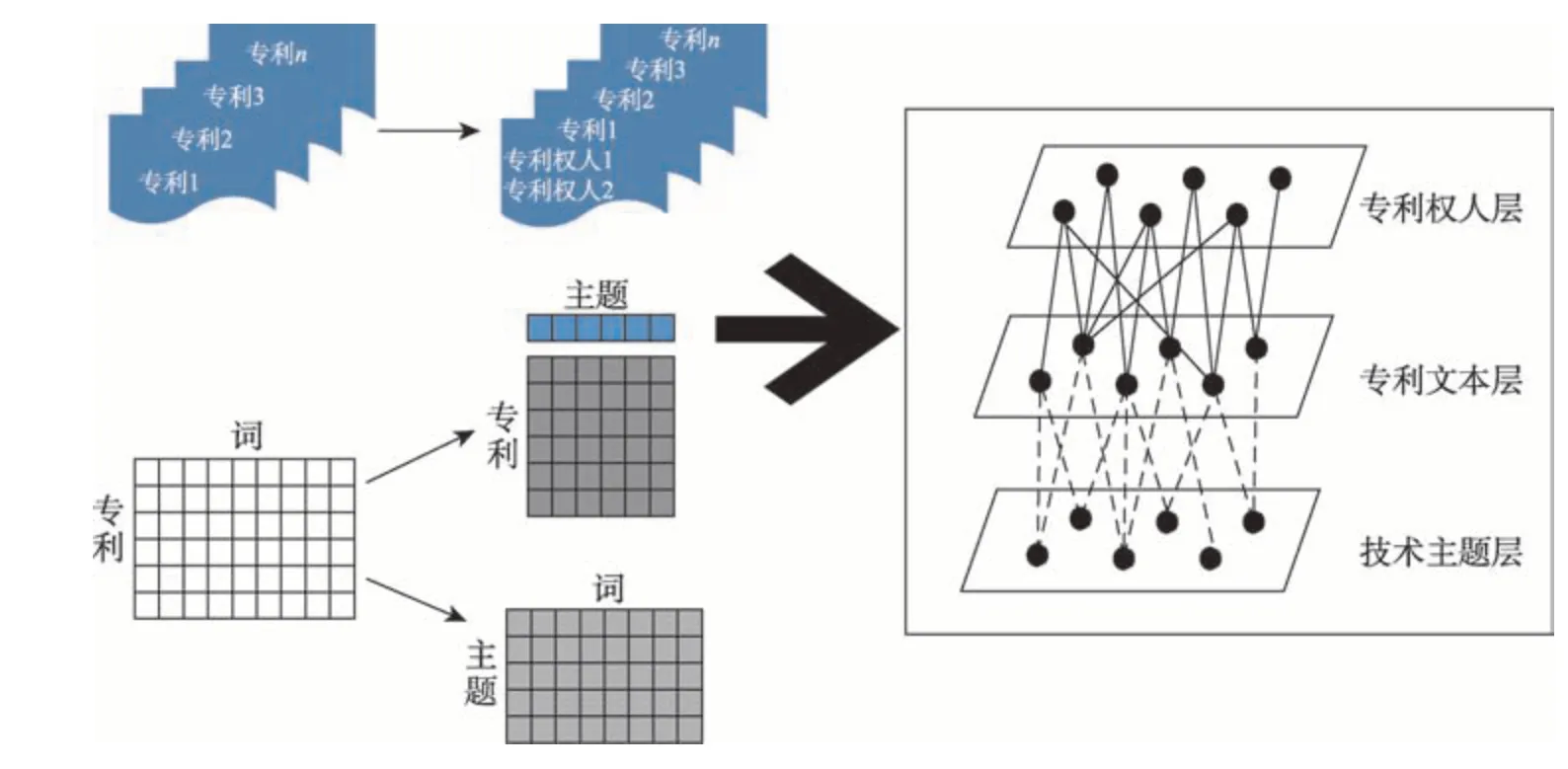
图2 专利权人-专利-技术主题三层概率分布
3)基于词向量的主题向量及专利权人向量表示
假设专利文档集合D={d1,d2,…,dn},共包含V个词{w1,w2,…,wv}。首先,利用word2vec训练出文档集合所包含词的词向量{v(w1),v(w2),…,v(wv)};然后,基于LDA主题模型得到主题-主题词项概率分布,假设专利文本共包含N个主题{t1,t2,…,tn},其中,将第i个主题ti生成的第j个词记为tij,将生成第j个词的概率记为θij。本文认为,一个主题词项所属主题概率越高,该主题词项就越能够表征该主题的主题信息,也就应赋予该主题词项更高的权重。因此,为计算出基于词向量的主题向量,将选取每个主题中主题词分布概率位于前h的词,进一步对每个主题在选中的h个词上的分布概率进行归一化处理,即

并将归一化结果作为每个主题词项的权重。
综上,基于词向量的主题向量表示为某主题中前h个词的词向量分别乘以其权重并加和,即
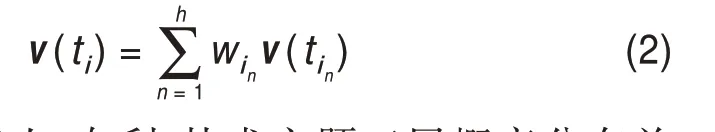
基于专利权人-专利-技术主题三层概率分布关系,由于专利文档中一个技术主题所属概率越高,该技术主题越能够表征该专利文档的主题信息,就应赋予此技术主题更高的权重。其中,将第i个专利文档di生成的第j个技术主题dij的概率记为Xij,故首先选取专利文档中技术主题分布概率位于前m的技术主题,并将每篇专利文档在选中的m个技术主题上的分布概率进行归一化,即
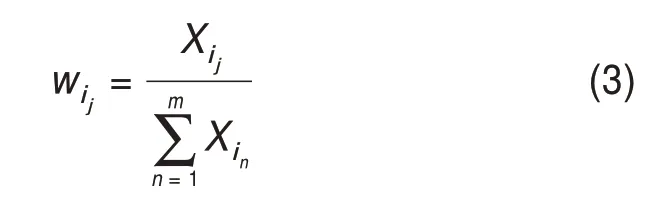
且将归一化结果作为每个技术主题的权重。因此,基于词向量的专利文档向量表示为某专利文档中前m个技术主题向量分别乘以其权重后加和,计算公式为
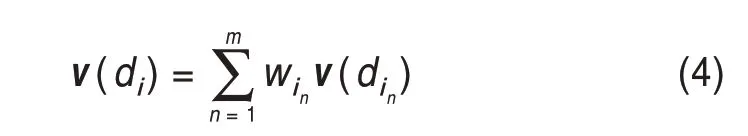
专利权人Ci的向量表示为专利权人所包含文档向量总和与文档总数之比,即

4)利用词向量计算专利权人的语义相似度
将分析领域里的每一个专利权人表示为一个固定维度的空间向量后,专利权人间的技术相似性测度就转变为专利权人向量间的空间相似度问题。若计算结果相似度值越高,则说明未来变成竞争对象或者合作伙伴的概率也就越大[18]。代表性的向量间相似度计算方法包括欧几里得度量相似度、余弦相似度及Jaccard系数等。本文选取余弦距离来计算相似 性,Ci=(c1,c2,c3,…,cn)和Cj=(c1,c2,c3,…,cn)分 别 表示为两个专利权人的向量,具体计算公式为
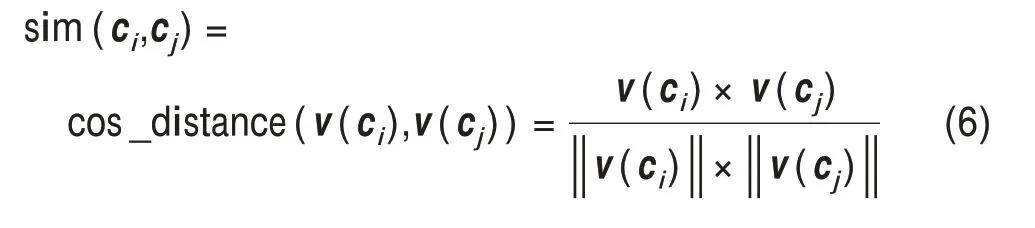
3.3 构建专利权人-技术主题二模网络
为了更加直观地将技术相似度测度分析结果应用于技术情报分析中,本文绘制出专利权人技术主题二模网络,如图3所示。其中,专利权人网络表示专利权人间技术相似性关系。节点大小表示专利权人持有专利数量的多少,节点间连边的粗细程度表示专利权人间所持技术的相似程度。在技术主题网络中,节点表示所分析技术领域的热点技术主题,节点大小表示该技术主题受关注程度。两层网络间的联系表示为专利权人所包含的技术主题。该图谱可直接作为企业技术情报人员分析特定技术领域的技术布局情况、潜在竞争对手与备选合作伙伴等分析的主要依据。
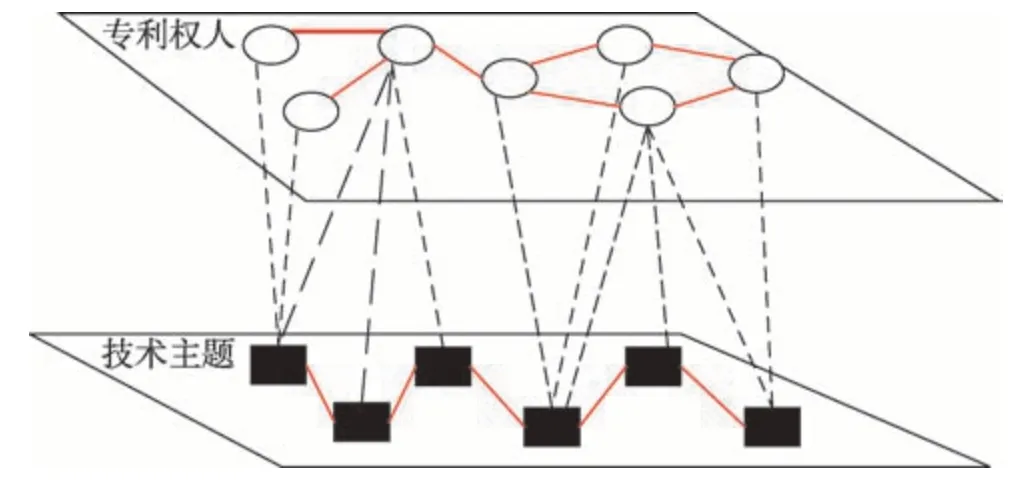
图3 专利权人-技术主题双层复杂网络图
4 实证分析
以纳米导药系统领域特定时间段内的专利权人为研究对象:首先,基于word2vec和LDA主题模型生成包含文本语义关系的专利权人向量;其次,利用余弦相似性计算专利权人间的语义相似性;再次,构建专利权人相似性网络及专利权人与技术主题关系网络;最后,基于实例与LDA主题模型测度结果进行对比,从而验证该模型在技术相似性测度分析中具有更好的效果。
4.1 数据获取及预处理
本文选取纳米导药系统为案例进行研究,采用Zhou等[19]的检索策略在德温特数据库上进行检索,时间跨度定为1999—2019年(时间截止到2019年2月16日),共检索得到16293条记录。
1)专利权人清洗
由于专利持有量较少的专利权人在技术领域内的影响力相对较弱,本文选择持有专利数量前30位的专利权人作为研究对象,共持有专利2287条,如表1所示。其中,加利福尼亚大学(简称“加州大学”)获得的授权专利数量最多,为234件;其次是麻省理工学院(141件)和法国国家科学研究中心(136件)。
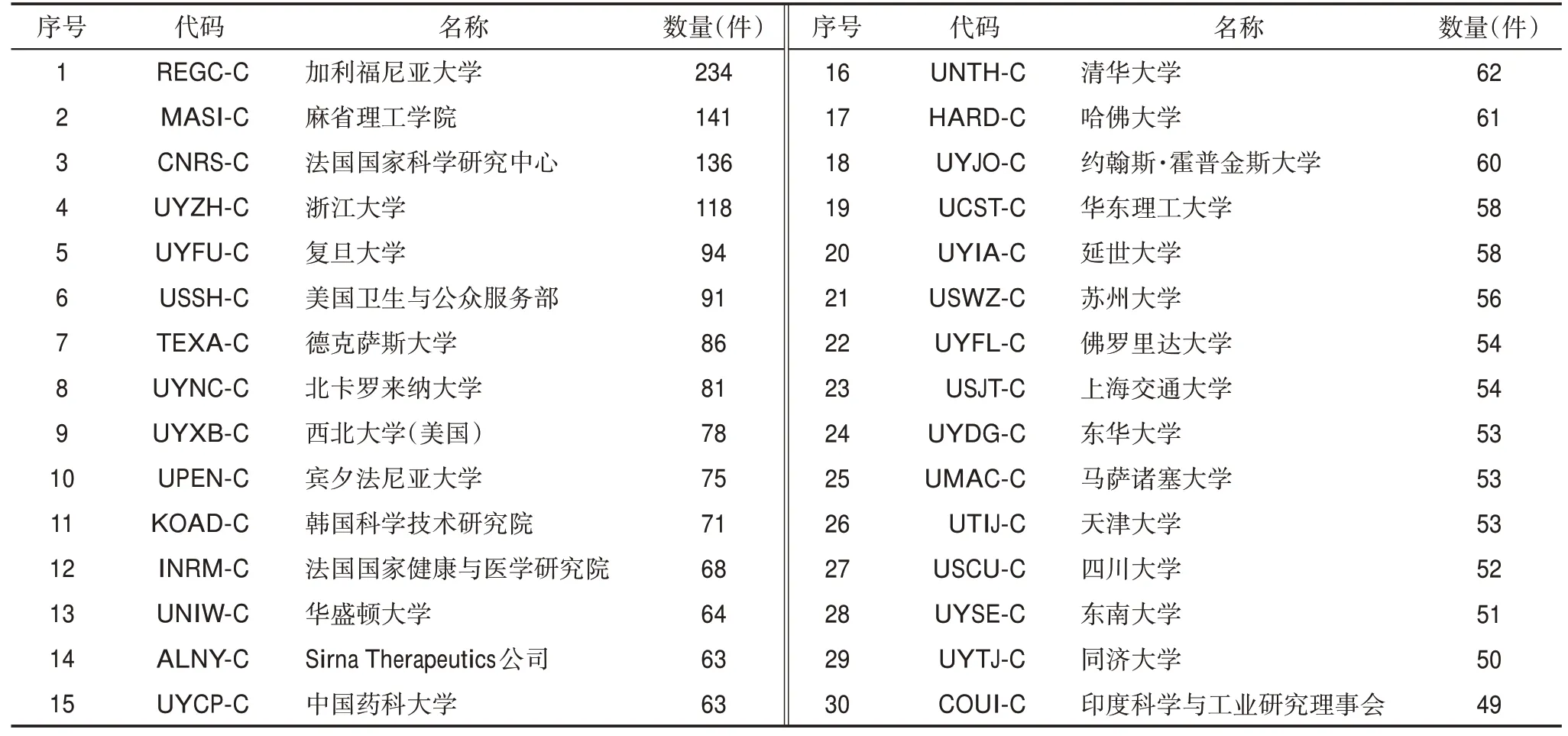
表1 Top30的专利权人及拥有专利数量
2)专利文本清洗
本文运用VantagePoint软件实现文本内容的结构化处理。①合并专利文本的标题和摘要并进行分词处理,选取长度为1~3、词频不低于4的特征词;②经过去停用词、去常用词、模糊语义匹配及人工筛选等步骤,得到8000个特征词;③以单个专利为维度,根据获得的主题词表分别提取16293条专利的特征词,形成16293个词表文件。
4.2 构建基于word2vec和LDA主题模型的技术相似性测度方法
首先,选取word2vec模型中的skip-gram模型进行专利文档的训练,得到包含上下文语义信息的特征词向量,通过多次实验结果对比,设置向量维度参数值为200,滑动窗口参数值为2。然后,基于吉布斯采样法训练LDA主题模型,得到专利权人-专利-技术主题三层概率分布,通过多次实验结果对比,发现当主题数设置为20时,技术主题内容间的交叉性最小,故主题数确定为20。接着,合成“词粒度”层面的主题向量、专利向量、专利权人向量。最后,基于余弦相似性计算专利权人间的语义相似度,部分研发主体技术相似性测度如表2所示。
由表2可知,该矩阵为对称矩阵,对角线上的数值均为1,说明专利权人与自身的技术相似度为100%,这与实际情况相符。从矩阵中的其他数值能够看出不同专利权人间的技术相似性。例如,矩阵中第9行第1列,数值为0.831196,则表示加州大学与西北大学(美国)所授权专利中有超过83%的研究内容相似。通过对比两者所关注研究内容发现,加州大学与西北大学(美国)在纳米药物载体、药物递送、肿瘤治疗纳米药物、抗菌治疗纳米药物、纳米检测等内容均有交集,存在技术上的相似性,且两者曾围绕纳米材料的合成、特性及癌症治疗等方面有过论文合作。
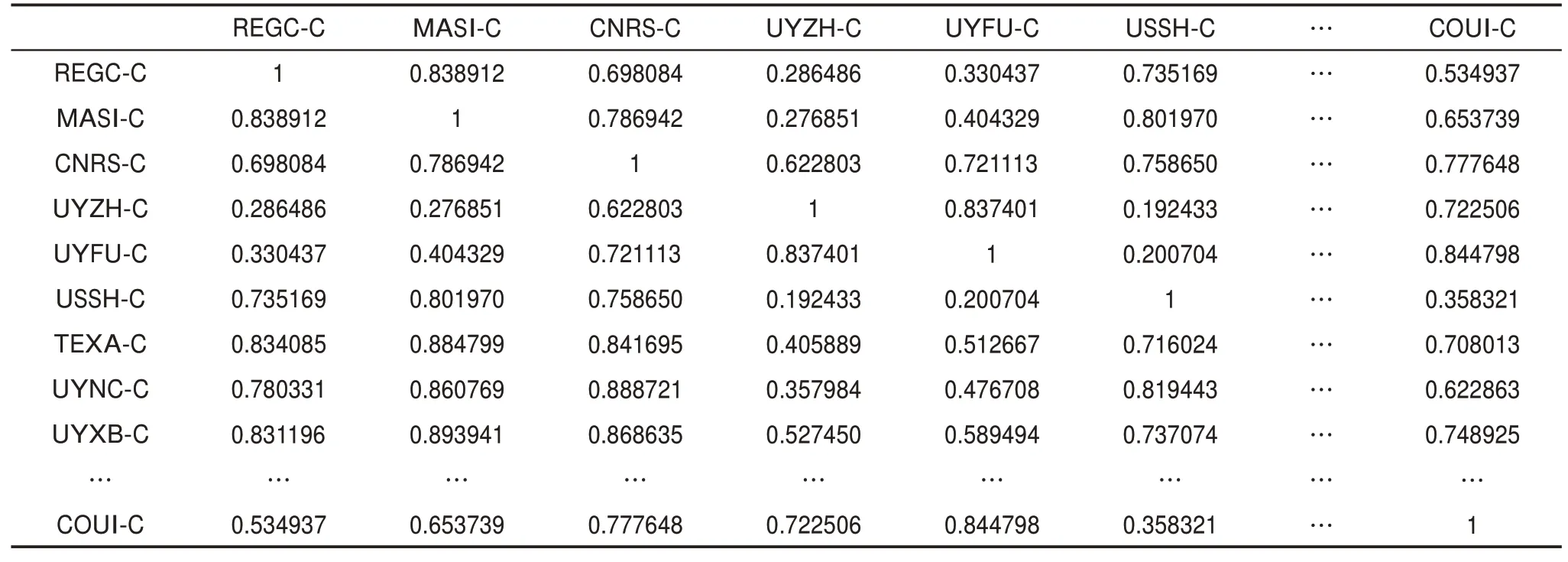
表2 部分专利权人技术相似性测度结果
4.3 构建专利权人-技术主题二模网络
为了更加直观地将技术相似性测度结果应用于企业、组织或国家间技术相似性分析,有效指导企业、组织或国家技术情报分析实践,本文构建了专利权人技术相似性网络以及专利权人-技术主题关系网络图。
1)专利权人技术相似性网络有效分析
为了更加直观地展现专利权人间的技术相似性情况,将上述技术相似性矩阵导入Gephi中,构建网络图如图4所示。
由图4可知,节点表示专利权人,节点标签大小表示专利权人拥有专利数量的多少,节点间的连线表示专利权人间的技术相似程度,连线越粗、颜色越深则表示技术相似程度越高。以麻省理工学院为例,与其技术相似程度排名前3位的专利权人情况如表3所示。通过对比专利权人所关注领域发现,表3中3位专利权人与麻省理工学院分别在纳米递药系统、药物载体、纳米颗粒及癌症治疗等方面具有一定的重叠性,存在技术上的相似性。初步推断,麻省理工学院可能与这3位专利权人存在合作关系。据调查发现,麻省理工学院曾与哈佛大学合作研发名为BIND014的纳米药物递送系统,曾与约翰斯·霍普金斯大学在Science上共同发表有关碳热震荡合成纳米粒子方法的研究成果,曾将勒梅尔森奖授予西北大学(美国)国际纳米技术研究所所长Chad Mirkin,以表彰其对纳米领域作出的杰出贡献。

表3 与麻省理工学院技术相似性排名前3位的专利权人情况

图4 专利权人技术相似性网络图
2)专利权人-技术主题关系网络有效分析
为了直观展示专利权人的技术布局情况,将专利权人与技术主题关系矩阵导入UCINET中,构建专利权人-技术主题关系网络图如图5所示。
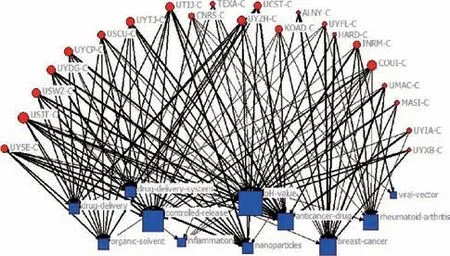
图5 专利权人-技术主题二模网络图谱
首先,由技术主题层能够明晰研究领域当前的技术热点。如纳米导药领域的研究热点主要为纳米药物载体、药物递送、肿瘤治疗纳米药物、纳米粒子缓控释药物、免疫学疾病治疗纳米药物、纳米检测、纳米催化物的制备等。
其次,由专利权人-技术主题关系层能够明确专利权人的技术布局情况。如UTIJ-C主要从事纳米颗粒、纳米粒子缓控释药物等的研究,UMAC-C主要研究肿瘤治疗纳米药物、抗菌治疗纳米药物等,TEXA-C主要关注纳米递药系统、纳米颗粒制备、癌症治疗等。据报道,2019年,TEXA-C在PNAS(《美国科学院院刊》)发表了利用X射线和铜-半胱胺纳米粒子治疗深部肿瘤的研究成果[20]。
最后,结合专利权人相似性网络与专利权人-技术主题关系网络能够识别潜在竞争对手及合作伙伴。关于潜在竞争对手的识别,在专利权人相似性网络连线越粗、颜色越深的专利权人之间越具备技术上的相似性,越有可能成为技术竞争对手。专利权人可根据专利权人-技术主题关系图,判断竞争者的技术布局情况,并采取相对应的竞争策略以占领技术高地。
关于合作对象的选取,则需要考虑两种不同情况:①集聚力量攻克研究领域内共同面临的“卡脖子”问题。该类合作需要彼此间在共同关注领域上具备较高的技术相似程度与较强的技术实力,因此,需寻求在专利权人相似性网络中彼此连线较粗、颜色较深,且在专利权人-技术主题网络中关注同一研究领域的专利权人展开合作。例如,加州大学、复旦大学两者具有较高的技术相似性和技术实力,且两者共同关注肿瘤治疗纳米药物的研究,基于此,推断两者可能存在相关的合作。通过已有合作调查发现,两者共同开发了一种红细胞膜包覆药物纳米晶的主动靶向仿生纳米药物,并进行了抗脑胶质瘤治疗的相关研究。②解决不同技术环节的融合问题,该类合作需要彼此间在不同关注领域具备较高的技术研发实力,因此,需寻求在专利权人-技术主题网络中关注不同研究领域,且在专利技术相似性网络中节点较大的专利权人进行合作。例如,浙江大学在改良纳米颗粒、纳米材料制备的研究中具有较强的技术实力,加州大学在纳米药物缓释控、药物递送方面具有较强的技术实力,基于此,推断两者可能存在跨研究领域的合作。据报道,在2005年中国浙江省人民政府、中国浙江大学和美国加州纳米技术研究院三方共建浙江加州国际纳米技术研究院,且之后与加州大学劳伦斯伯克利国家实验室共同研发纳米生物医药、纳米递送系统。
4.4 技术相似性测度效果评价
为了证明本文提出的方法相对于目前应用较多的LDA主题模型测度结果的精确性,进一步运用NEDD领域的数据,将两种方法测量结果进行对比。
利用LDA主题模型测度技术相似性的部分结果如表4所示。由表4可知,相似性最大的为REGC-C与MASI-C,其值为0.990251,这表明两个专利权人持有的NEDD领域技术几乎完全相同。相似性最小的为UTIJ-C与INRM-C,其值为0.728429752,这表示相似程度最小的两个专利权人仍共同持有70%以上的NEDD领域技术。
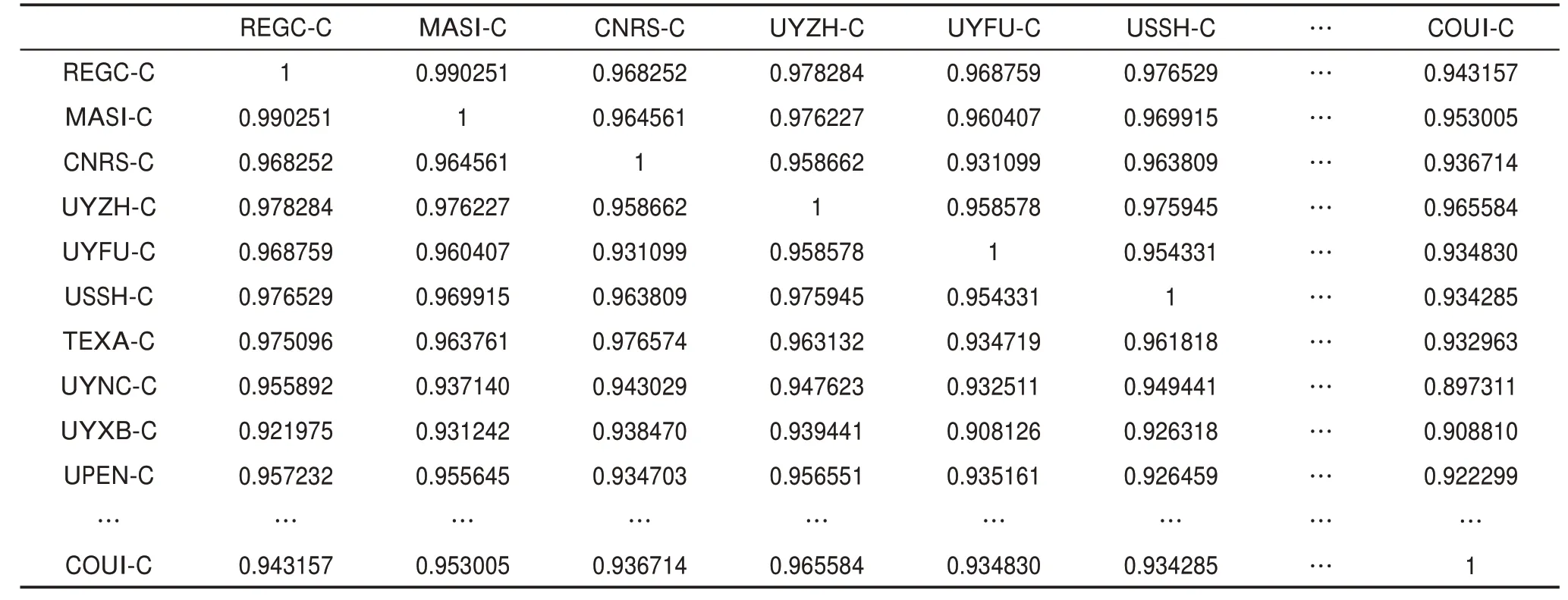
表4 基于LDA主题模型的部分研发主体技术相似性测度结果
为比较两种方法在测度结果上的准确性,本文选取LDA主题模型测度结果排名前10位和后10位的专利权人组合作为验证对象,通过对专利权人组合间主要关注领域进行对比,并参考专家意见对两种方法的测度结果进行评价。
1)排名前10位的专利权人组合技术相似性测度结果对比
两种方法的测度结果如表5所示。观察表5可发现,以上专利权人组合中,REGC-C出现次数较多,因此,选取含有REGC-C的专利权人组合MA‐SI-C®C-C(序号1)、UYZH-C®C-C(序号3)以及USSH-C®C-C(序号5)3组进行对比研究,并在专家的指导下枚举各个专利权人主要涉及的研究内容。
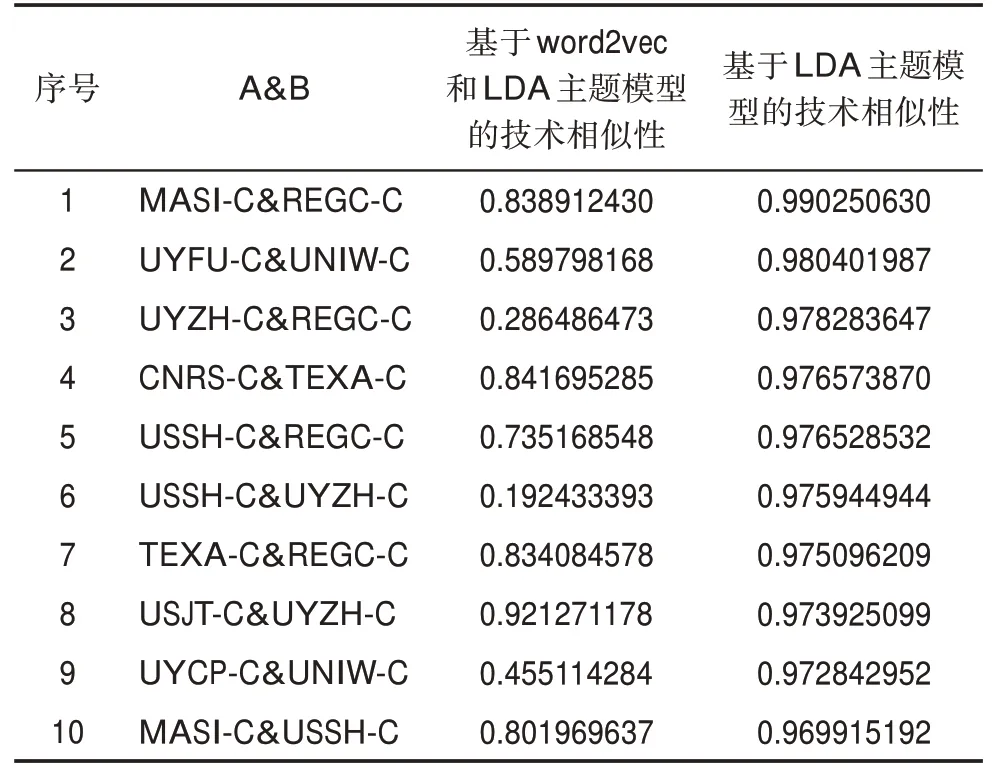
表5 排名前10位的专利权人组合两种测度方法结果对比
REGC-C持有专利数量234件,内容涉及广泛,如纳米药物载体、疾病治疗纳米药物、纳米探针、纳米材料、纳米递送系统、纳米测量等;MASI-C持有专利数量141,主要涉及纳米药物载体、纳米药物治疗、纳米粒子及纳米粒子缓控释药物等的研究。由此可见,REGC-C与MASI-C的研究内容在纳米药物载体、纳米药物治疗、纳米粒子方面存在交叉性,但并非完全相同,因此,两者间的技术相似性不应高达99%。REGC-C与UYZH-C均在纳米粒子制备、纳米递送系统方面有所涉及,但REGCC明显研究内容范围更广,由此判断,两者间的技术相似性也不应高达97%。USSH-C研究内容主要为纳米药物载体、癌症治疗纳米药物与纳米粒子缓控释药物等,发现其与REGC-C的研究内容具有一定的重叠性,但仍存在各自独具的研究内容,如纳米粒子缓控释药物的相关研究,显然两者间的技术相似度达不到96%。
2)排名后10位的专利权人组合技术相似性对比
两种方法的测度结果如表6所示。本节选取测度结果差异较大的UTIJ-C&INRM-C(序号1)、AL‐NY-C&UTIJ-C(序号8)以及KOAD-C&UTIJ-C(序号10)三组进行对比分析。
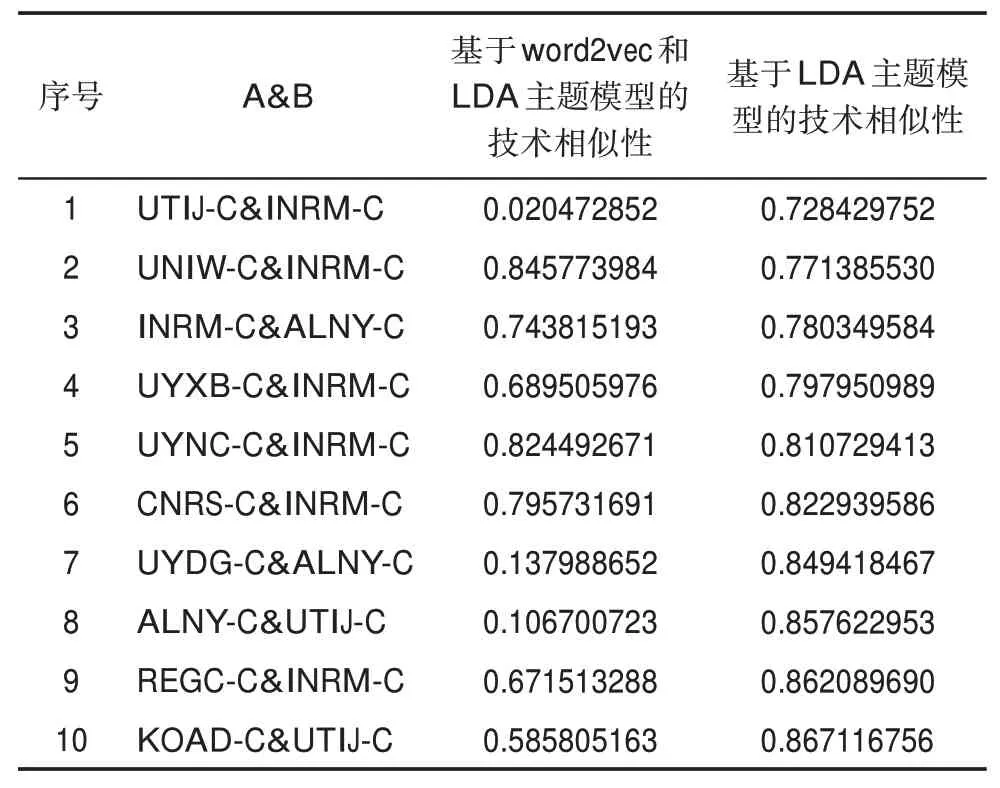
表6 排名后10位的专利权人组合两种测度方法结果对比
INRM-C中存在部分内容(如纳米粒子制备)在UTIJ-C所研究的范围内,但INRM-C有很大一部分内容是UTIJ-C没有涉及的,如纳米药物载体、纳米粒对艾滋病、老年痴呆症等疾病的治疗等。UTIJ-C与ALNY-C、KOAD-C亦是如此,如ALNYC、KOAD-C与UTIJ-C均在纳米粒子制备方面存在一定的重叠性,但各自却拥有大部分UTIJ-C未涉及的研究方向。由此可见,LDA主题模型的测度结果值均偏高。
究其原因,发现LDA主题模型是基于词的共现频率来提取文本中潜在的主题信息,未考虑到专利文本上下文间的语义关联性,导致其无法细粒度的表示专利权人的技术主题特征,使得测度结果值偏高。而word2vec模型能够将专利文本内容中的语义信息表示为稠密低维的向量,使得从词粒度层面表征专利权人的技术特征成为可能。因此,基于word2vec和LDA主题模型的技术相似性测度结果更为准确,与实际判断情况相符。
5 结论
技术相似性是专利权人识别潜在竞争和备选合作伙伴的重要依据,是作为企业、组织或国家技术情报分析的主要内容。因此,技术相似性测度结果在精确性上有较高的要求。针对传统LDA主题模型测度方法未考虑专利文本上下文间语义关系的问题,本文提出基于word2vec和LDA主题模型的技术相似性的可视化研究方法。首先,基于word2vec模型学习特征词在文档集中的上下文语境信息,并结合LDA主题模型,构建专利权人-专利-技术主题三层概率分布生成“词粒度”层面的主题向量与专利权人向量;其次,通过向量相似度指标计算专利权人间的语义相似度,并在此基础上构建能综合反映专利权人-技术主题关系的双层复杂网络图谱;最后,以NEDD领域为例验证了该方法在技术相似性测度结果准确性上的优越性。
从方法上讲,深度学习、机器学习与技术相似性测度的成功融合和应用,表明深度学习与机器学习方法的结合也可拓展应用于与此相关的技术情报分析的其他方面,如基于深度学习和机器学习结合的主题聚类及其演化分析、文本分类等。
从内容上来讲,专利权人-技术主题二模网络图谱的展示对于企业、组织及国家技术情报分析与技术创新实践具有重要意义。首先,通过技术主题层可以明晰研究领域的热点技术主题;其次,通过专利权人技术相似性网络层能够识别企业、组织或国家主要潜在竞争对手与合作伙伴;最后,通过专利权人-技术主题层能够直观展示企业、组织或国家的技术布局情况。
本文仅选取了NEDD领域30家主要研究机构作为分析对象,在该领域技术情况反映的全面性上还存在局限,未来将扩大分析对象的范围,拓展专利数据的来源。
猜你喜欢
福州大学学报(自然科学版)(2021年6期)2021-12-31
华中师范大学学报(自然科学版)(2021年2期)2021-04-10
经济与管理(2020年4期)2020-12-28
河北画报(2020年8期)2020-10-27
大陆桥视野·下(2017年6期)2017-09-05
雪莲(2017年2期)2017-05-12
数学教学通讯·高中版(2017年3期)2017-04-17
环球市场信息导报(2017年1期)2017-04-08
科技经济市场(2016年3期)2016-06-17
俄罗斯问题研究(2013年1期)2013-03-11
