
智能推荐系统及相关算法原理研究
2021-10-11 02:06马庆祥
科学咨询 2021年30期
马庆祥
(重庆工商职业学院 重庆 401520)
一、推荐系统的结构
推荐系统整体上都有一个类似的结构,如图1所示。首先需要采集用户的行为数据和物品的数据,然后将用户行为数据经过算法建模,形成兴趣模型。然后通过模型预测用户对新的物品是否感兴趣,是就推荐给用户。用户接收到新的推荐后,可以对推荐结果标记感兴趣还是不感兴趣。这样的行为又会被系统记录,并以此重新运算,得到新的模型,然后又用新的模型继续给用户推荐。基于针对不同推荐内容的场景,本文以推荐系统为基础,着重研究各种常用推荐算法的原理及核心结构。

图1 推荐系统结构图
二、基于内容的推荐
数据采集有隐式获取和显式获取等多种方式。显式获取是指用户在应用中注册、完善个人信息、问卷调查,或者线下询问、访谈、调查、跟踪等方式取得的数据。这一类方式操作简便、直接,但用户基于隐私或者嫌麻烦等各种原因,往往不愿意提供数据。尽管显式获取的数据精准度高,但实时效果并不好。隐式获取是业界普遍采用的方式,通过用户在应用上的使用行为来推测出用户的偏好。隐式获取需要注意的就是要随时关注用户的行为变化。
在用户方面,关于用户个人信息的主要有性别、年龄、地址、联系方式等。关于行为方面有页面浏览记录、页面停留时间、该页面的主要内容、页面上的点喜欢操作、点厌恶操作、点赠花操作、分享、收藏等。
在物品方面,不同的业务场景,物品的描述也不一样。比如生鲜APP,配送的就是水果、蔬菜、肉食。这类物品的属性主要就是品牌名称、类型名称、产地、单价、生产日期、保质期等。从物品的适用客户群体分,还有老人、小孩、女性、男性。从适用年龄分,还有婴幼儿、儿童、青年、成年、老年等。
基于内容的推荐,具体原理如下。
假设已经收集到用户和物品的数据,去分析用户喜好的物品,然后寻找与这些物品相似的其他物品来进行推荐。如何判断物品是否相似,就需要提取用户偏好的物品的特征。比如,用户喜欢吃草莓,就可以根据该草莓的产地、口感、颜色、大小、品种、价格等。找到特征后就需要将特征提取出来,由于针对这一类属性的描述大部分情况是文本,非结构化数据,因此需要从文本中将特征提取出,然后转换为向量。计算物品的相似度其实就是在计算特征向量的相似度。最终在用户的推荐列表中,越相似的物品就排名越靠前[1]。
三、基于知识的推荐
知识推荐系统实际上是一种专家问答系统。基于用户现阶段的知识,和综合所有物品的特征信息,来寻找合适的推荐。什么情况下需要基于知识的推荐呢?
比如,一个一年级的学生,把一年级的课程学习完毕后需要开始二年级的学习,若是基于内容的推荐,那么就会发现给该生推荐的内容一直是一年级的。另外对于用户来说购买频次比较低的物品,比如购买新相机、购买了新的房子、购买了一个婚纱照套餐等,这类用户行为间隔周期长的情况,系统是很难建立起用户行为数据,因此会导致推荐的效果较差,这时就需要基于知识的推荐。
基于知识的推荐又分为两种方式,基于约束的推荐和基于实例的推荐。
基于约束的推荐是指:实现给物品分好类,这个分类也称约束,然后给每类物品定义一个过滤条件。此时用户给出需求,推荐系统就寻找满足需求的分类。若是用户对物品有更深入的了解,则提出更多的需求,然后系统会在这个分类下继续寻找过滤条件满足该需求的数据。比如,用户希望买一套房子,首先需要确定分类:是别墅、洋房还是普通高层住宅。用户选择了洋房后,再次提出要求,需要单价大于5000且小于10000的房子,此时系统根据条件进行过滤。用户不断给出条件,系统不断过滤满足条件的数据,直到用户完成数据检索。
基于实例的推荐需要用户对物品特征了解非常多,当筛选出数据后,用户基于自身的知识可以采纳推荐或者放弃本次推荐,系统根据用户的选择来判断下一次应该推荐什么给用户。比如同样是买房子,系统提前建立好每套房子的知识库,用户根据自己了解的信息直接定位到该房子即可。
四、基于标签的推荐
标签是用来描述物品的关键词或者是用户对该目标群体的喜好等,如图2所示,是某公开课网站的会员常用的标签。

图2 公开课常用标签
标签的来源有两种方式,一是用户体验了该物品后,由用户给物品打的标签,比如课程“网络爬虫”,用户给出的标签就是“大数据”“爬虫”“程序”“脚本”等。对于课程“python”,用户给出的标签可能就是“编程语言”“数据结构”“解释型”“面向对象”等。用户打的标签,几乎都是对课程的客观描述。另一种方式,就是作者给出的,可能既包含对物品的喜好,也包含物品的描述[2]。
当系统采集到大量标签后,需要进行以下工作:
1.分析该用户经常使用的标签。
2.分析拥有这个标签的所有物品。
3.将物品中没有被该用户打过标签的推荐给该用户。
五、基于图模型的推荐
通过图模型来表达用户行为,也能实现推荐。比如,用户的购买商品记录,是表结构的组织形式,如表1所示。

表1 用户购买物品记录表
其中“✔”表示用户购买过该物品。采集到这些数据后再转换为图的表达形式,如图3所示。其中连线,表示用户购买过物品,用户和物品表示顶点。转换成图形后就计算每个用户顶点到物品顶点之间的路径条数,比如用户A到物品1的路径为:用户A—物品1;用户A—物品3—用户B—物品1;用户A—物品3—用户D—物品1,总共3条路径,其中路径长度分别是:1,3,3,经过的顶点数量分别是0,2,2。基于这样的算法,可以推算出用户A到物品4的最短路径是:用户A—物品2—用户C—物品4,经过2个顶点;用户A到物品5的最短路径是:用户A—物品2—用户C—物品4—用户E—物品5,经过4个顶点。如果各顶点的相关性比较高,路径就会比较短,经过的顶点也比较少,因此可以给用户A推荐物品4。
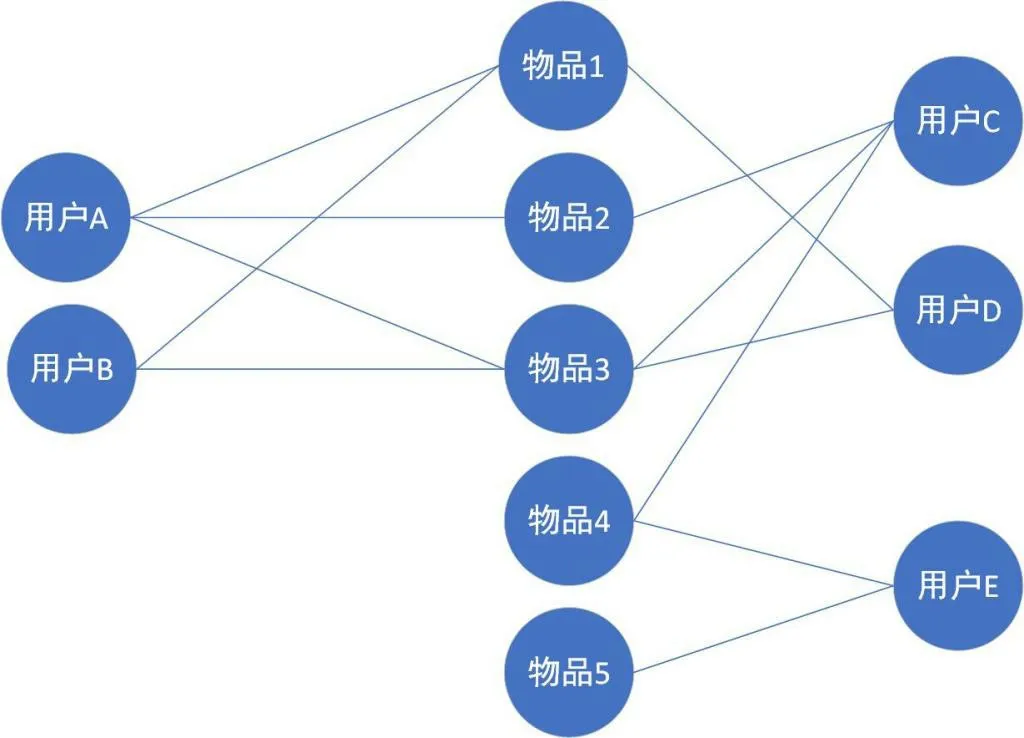
图3 用户采集模型
六、基于关联规则的推荐
关联规则的原理是基于物品之间的关联性进行推荐,是通过对用户的购物记录进行建模,以发现不同用户的购物习惯。注意,关联规则是指物品的关联关系,而不是因果关系。关联规则中有3个核心概念:支持度、置信度和提升度。如表2所示用户的购买记录。

表2 用户购买商品记录表
消费记录中,所有商品组成的集合称为总项集,A={卤肉、凤爪、红酒、白菜、苹果、草鱼、花生、啤酒、荔枝、猪肉、莴笋、香蕉、榴莲、鸡腿、牛肉、鲫鱼}。项集是指总项集的一部分,可以是一到多个物品的组合,比如{卤肉}、{卤肉、凤爪}、{卤肉、凤爪、红酒}等,称为k-项集。规则就是至少两个项组成的k-项集,比如{卤肉}—{凤爪}是一条规则,{卤肉}—{卤肉、凤爪、红酒}也是一条规则。这种规则中,项之间的关联强度,用支持度和置信度来衡量。
支持度是指:两件商品A,B在消费记录中同时出现的概率,就是买了A也会买B的概率。如上图的购买记录,有5个订单,其中买了卤肉的有4条,买了凤爪的3条,同时股买卤肉、凤爪的是3条。那么{卤肉}项的支持度是4/5=0.8,{凤爪}项的支持度为3/5=0.6,{卤肉、凤爪}项的支持度也为3/5=0.6。
置信度是指:用户购买了A还会买B的概率。同样依据上面的消费记录,用户在购买卤肉又购买了凤爪的记录有3条,则推断用户在购买卤肉的前提下会同时购买凤爪的置信度是3/5=0.6。购买了卤肉,又购买了啤酒的记录有1条,因此置信度为1/5=0.2。基于这样的原理,可以将卤肉与凤爪搭配销售。
提升度是用于衡量关联规则是否有效的一个度量。意思就是:用户买了A同时买了B的次数,高于单独购买B的次数,说明商品A对商品B具有提升作用。依据用户的消费记录,{卤肉、凤爪}同时出现的有3次,{卤肉}单独出现只有1次,说明凤爪对于卤肉的销售具有提升作用。提升度的计算就是:{卤肉}的支持度:C1=4/5=0.8,{凤爪}的支持度:C2=3/5=0.6,{卤肉、凤爪}的支持度:C3=3/5=0.6。置信度={卤肉、凤爪}的支持度/卤肉}的支持度*{凤爪}的支持度=0.6/0.8*0.6=1.25。当置信度大于1则说明规则有效,小于1则无效。关联规则的推荐过程就是寻找所有项组合置信度比较高的规则,然后根据规则进行推荐。
实际上,若是简单地基于上述规则计算,效率会非常低。因此,实际应用中一般选择求频繁项集的置信度,寻找的是强关联规则。然而寻找频繁项集也是个计算量巨大的过程,因此业内提出Apriori算法来寻找频繁项集。该算法有两个固定性质:
✧频繁项集的子集也是频繁的
✧非频繁项集的超集是非频繁的
Apriori的计算过程就是:统计每一个商品项的支持度,将支持度过于低的商品移除,同时也将该商品的超集也移除,这个移除称为减枝。将剩余的单项商品两两组合,再次计算对应的支持度,将组合情况下支持度低的移除,同时将对应的超集移除。基于此规则不断迭代,直到无法再次进行组合,此时会得到一个频繁项集。最后,将该频繁项集进行拆分,取出其中一个商品,比如k1,则剩下k-1个商品。此时,计算{k1}集与{k2,k3,kN-1}集之间的置信度。根据此原理,然后计算{k2,k3}与{k1}之间的置信度。一直迭代,直到计算出所有规则下的置信度。最后根据业务规则,取出置信度大于1的规则来为用户进行推荐。
七、基于协同过滤的推荐
实际上,只要是基于用户人口属性和行为的推荐都称为协同过滤。包括图、关联规则、知识都是协同过滤推荐的一种。纯粹依靠人口行为数据来进行推荐的典型代表是:基于用户的推荐、基于物品的推荐。基于用户的推荐步骤是:首先需要找到兴趣相似的用户,然后找到其他用户喜欢,但是被推荐用户又没接触过的物品,如表3所示,可以看到用户A与用户B有两个相似的物品,则认为A与B用户兴趣相似,然后就可以将物品2推荐给用户B[3]。

表3 用户与物品的关联分析表
基于物品的推荐则是用户喜欢一个物品,然后寻找与该物品相似的物品来进行推荐,如上图所示,用户C喜欢物品1和物品2,此时计算出物品4与物品1和物品2相似,则给用户C推荐物品4。
八、结束语
“个性化推荐系统”这一概念首次提出,是由于电子商务的兴起而逐渐发展成熟,慢慢变成了一个单独的概念。如今,个性化推荐系统更是得到了更为广阔的发展,在很多领域都有应用,如教育、影视、音乐、社交,甚至阅读学习,都有个性化推荐系统的应用。个性化推荐技术的核心主要在于两个方面,即推荐算法和推荐应用。应用原理就是根据不同推荐应用的需求和限制条件,选择不同的推荐算法。随着对推荐算法研究的不断深入,各种配套科技也在不断发展,智能化成为大势所趋,而个性化推荐作为智能化发展过程中重要的部分,也将越来越受到重视。
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
农村百事通(2020年8期)2020-04-26
农村百事通(2020年8期)2020-04-26
计算机与数字工程(2018年10期)2018-10-23
扬子江(2018年5期)2018-09-26
计算机与数字工程(2017年2期)2017-03-02
小小说月刊(2016年7期)2016-07-29
小雪花·小学生快乐作文(2015年1期)2015-03-11
小雪花·小学生快乐作文(2015年1期)2015-03-11
故事林(2013年8期)2013-05-14
