
基于多因素特征分析的电力工程数据处理与预测模型
2021-10-10 03:55刘伟
电子设计工程 2021年19期
刘伟
(新疆天富集团有限责任公司,新疆石河子 832000)
电力输电工程建设具有资金投入大、产出周期长等特点,因此造价管控是工程管理的核心内容[1-2]。而输电工程造价又是一个多变量、非线性、非平衡性的系统,难以通过经验进行指导及管控[3]。静态投资是输电工程的主要经济技术指标,因此,投资方和施工单位迫切需要利用已建输电工程的数据信息对静态投资进行准确的预测,以便合理制定建设方案,提高工程管控效率和质量。
文献[4]重点分析了影响电力工程静态投资的设备材料因素,但未建立模型进行预测;文献[5]针对电力工程建设过程中的静态投资偏差进行监控及分析,并提出了相应的解决方案,也未建立预测模型;文献[6]建立了基于BP 神经网络算法的电力工程静态投资预测模型,但预测效果并不理想。
针对以上文献的不足,文中通过对多因素特征进行Pearson 相关系数[7-8]分析,选取主要因素进行标准化处理。基于GBDT 算法[9-11]提出了一种输电工程静态投资的预测方法,实现对投资的精准预测。
1 电力工程数据信息处理
电力工程数据信息由于大多依靠人为记录,且并未进行数据校核等工作,因此存在一定的异常情况[12]。输电工程数据中的异常主要分为语法类异常、语义类异常、覆盖类异常。语法类异常指的是表示实体具体的数据值和格式的错误,比如静态投资字段有的用“元”作为单位,有的用“万元”作为单位;语义类异常指数据不能全面、无重复地表示客观世界的实体,比如塔材价格字段应该大于0,但有的塔材价格值小于0;覆盖类异常指的是值的缺失。
需要对以上异常数据信息进行处理,剔除数据中的异常值,保证数据的完整性、全面性、合法性。一般异常值可视为缺失值处理。缺失值处理一般包含三大类:删除、填补、不处理。删除法简单易行,但是其可能会删除隐藏的有效信息,且会浪费大量资源。填补法是用一定的值(均值、众数、中位数等)填补空值,从而使信息表完备化。
2 多因素特征分析
输电线路在整个电网运行中承担着电能输送和分配的任务[13]。输电工程的主体建设主要由导线、地线、杆塔、绝缘子、拉线、金具6 部分组成[14]。通过搜集处理某地区125 组输电工程,可得数据信息共计56 个影响因子[15-16]。由于影响因子较多,因此可能存在潜在的维数灾害,从而造成预测模型性能变差或过拟合、无法拟合等问题。因此,通过Pearson相关系数对影响因子与预测目标静态投资进行相关性分析,筛选出核心影响因子作为最终研究数据,代入预测模型。
Pearson 相关系数ρX,Y表达式如下:
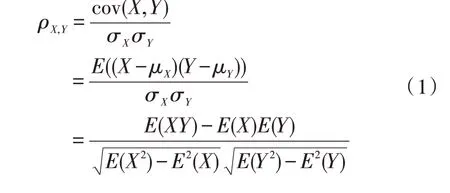
式中,X、Y表示比较的两个变量,σX、σY表示标准差,μX、μY表示均值,E(·)表示数学期望。ρX,Y值介于-1 与1 之间,大于0 表示正相关,小于0 表示负相关,绝对值越接近1 表示相关性越高。一般相关系数大于0.6 就属于强相关,但考虑到大于0.6的影响因子仍较多,且有些影响因子存在高度共线性的情况,因此选取相关系数绝对值大于0.8的影响因子,如表1 所示。
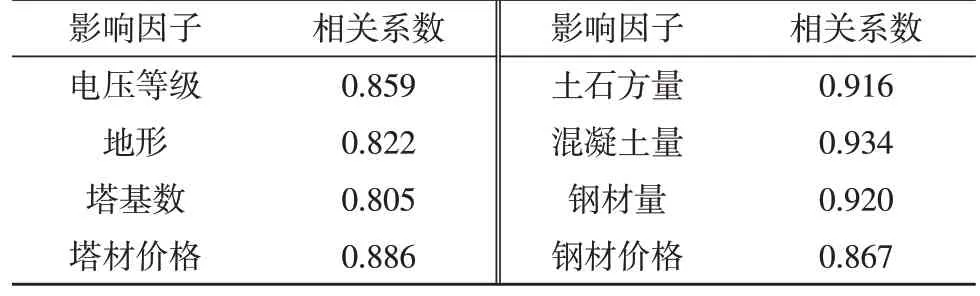
表1 核心影响因子表
3 预测模型研究
3.1 GBDT算法
梯度提升迭代决策树(GBDT)是以决策树为基评估器的一种Boosting 算法。GBDT 要求弱学习器必须是CART 模型,且GBDT 在模型训练时,要求模型预测的样本损失尽可能小。简单而言,若每一轮预测和实际值有残差,则下一轮根据残差再进行预测,最后将所有预测相加即为结果,如图1 所示。
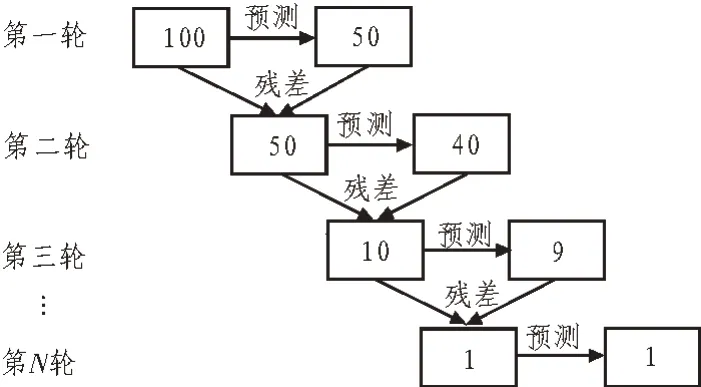
图1 GBDT训练原理
GBDT 模型可以表示为决策树的加法模型:
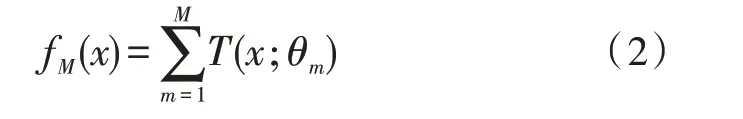
其中,T(x;θm)表示基评估器(决策树);θm表示基评估器的参数;M表示基评估器的数量。采用前向分布算法,首先自定义初始基评估器f0(x)=0,第m步的模型是:
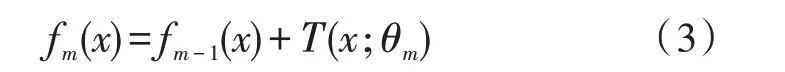
采用经验风险结构极小化的方法确定下一个基评估器的参数,即使残差尽可能小,从而找出最优划分点:
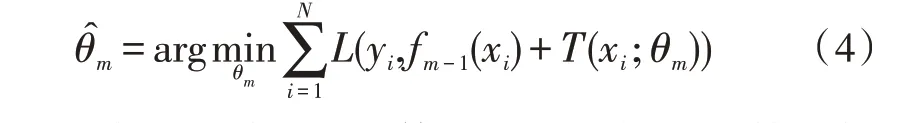
L(·)是损失函数,回归算法选择的损失函数一般是均方差(最小二乘)或绝对值误差。
3.2 数据准备
筛选出的核心影响因子由于量纲和数值的量级不同,因此需要对原始数据进行min-max 标准化处理,得到[0,1]区间的数据集,使不同影响因子对预测目标具有相同的尺度。
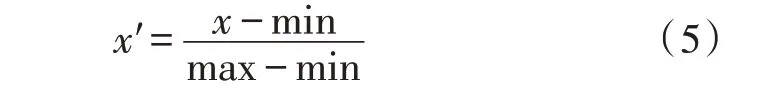
式中,max 表示数据样本中的最大值,min 表示数据样本中的最小值。处理后的数据如表2所示。
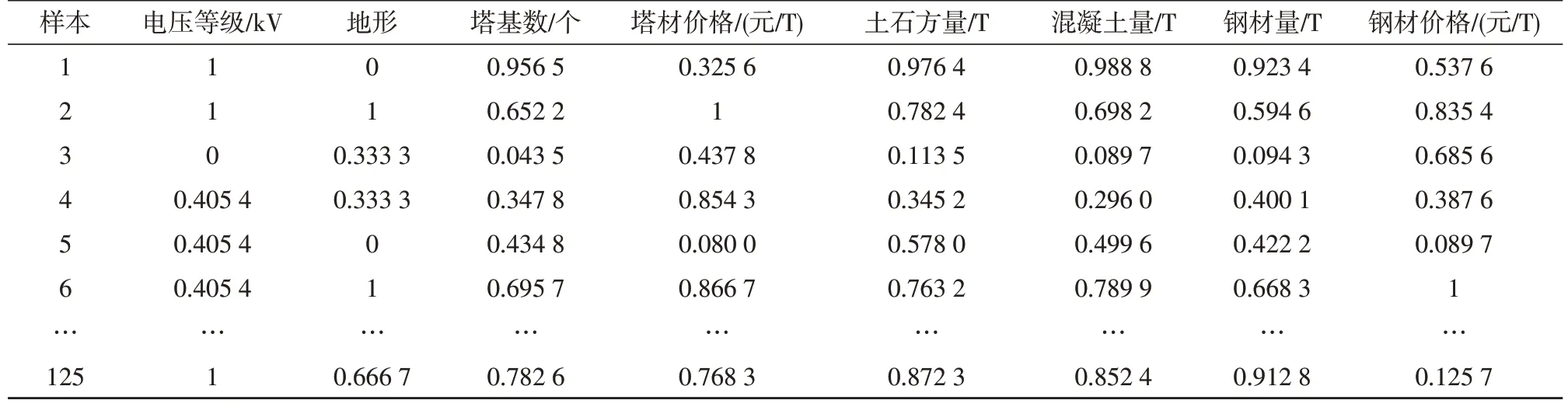
表2 输电工程数据标准化结果
将标准化处理后的数据样本进行数据集的划分。一般完整的流程会划分为训练集、验证集和测试集3 个集合。其中,训练集的作用是将其样本代入GBDT 模型进行训练;验证集的作用是为了初步评估GBDT 模型的预测性能。在模型训练过程中,会单独留出一些样本作为验证集,同时针对性能差的模型进行参数调优;测试集用来测试、验证、评估最终GBDT 模型是否过拟合或者欠拟合,即模型的泛化能力。文中随机抽取80%的数据样本即100 组输电工程数据作为训练集和验证集,剩余25 组数据作为测试集。验证采取5 折交叉验证法,将100 组数据平均分成5 份,每份20 组数据样本,依次将其中4份(80 组数据样本)作为训练集,剩余一份(20 组数据样本)作为验证集,计算每次验证集的评价指标分数。最终GBDT 模型预测性能的评价指标分数为5次结果的均值,如图2 所示。
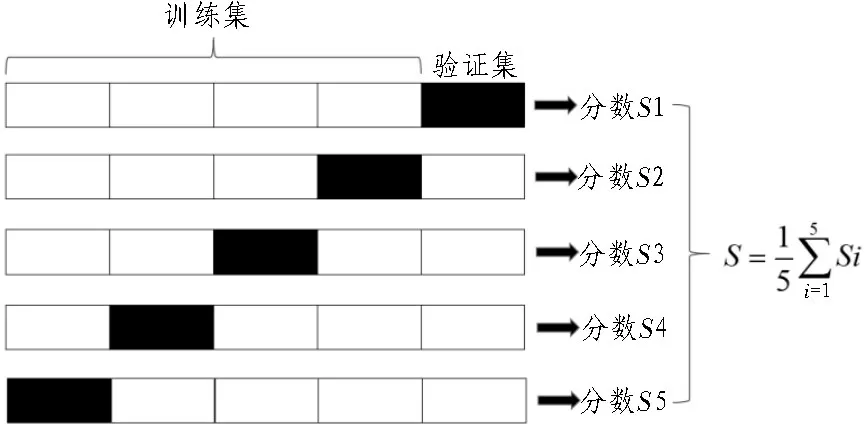
图2 交叉验证原理
3.3 模型建立
表2 为输电工程数据标准化后的结果,根据GBDT 算法原理,建立静态投资预测模型,流程如图3 所示,x表示核心影响因子。在模型建立过程中,需要进行调参,以优化输出效果。GBDT的参数主要分为两类:Boosting 框架参数以及基评估器参数。
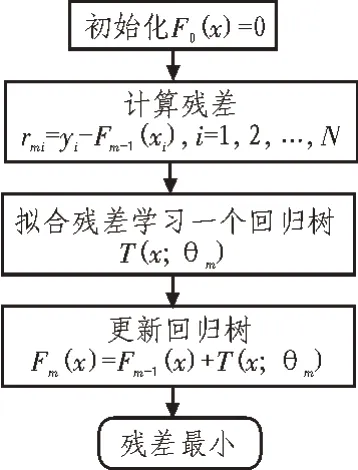
图3 预测模型建立流程
基评估器的参数较多,常用的包括max_features最大特征数、max_dept 最大树深、min_samples_split内部节点再 划分所需最小样本数、min_weight_fraction_leaf 叶子节点最小的样本权重和max_leaf_nodes 最大叶子节点数,这样可以避免产生过拟合。
4 实验结果分析
4.1 评价指标
评价输电工程静态投资预测模型的预测效果时,需要通过量化的指标对预测值和真实值进行比较。文中选取了预测模型常用的MAE 以及MAPE作为评价指标。
MAE是指真实值和预测值的误差绝对平均值,表示偏离程度。值越小,预测模型效果越好,表达式为:
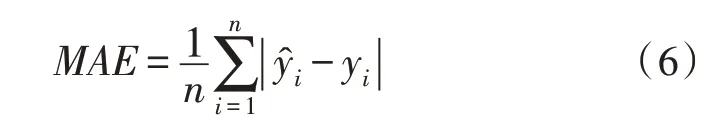
式中,yi为真实值,为预测值,n为样本量。
MAPE是指真实值和预测值误差率的绝对平均值,不同输电工程的基数标准可能相差较大,其公式为:
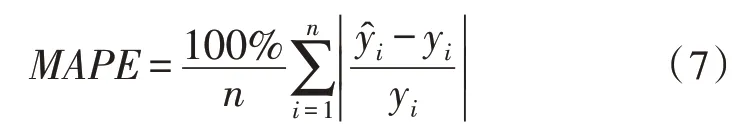
MAPE的取值范围 为[0,+∞),一 般MAPE大 于10%表示劣质模型。
4.2 评价结果
将100 组输电工程数据代入GBDT 模型进行训练,5 折交叉验证后得到MAE为8.743 8 万元,MAPE为3.92%,模型训练效果较好。将25 组测试集样本代入模型进行静态投资预测,预测结果(部分)如表3所示。
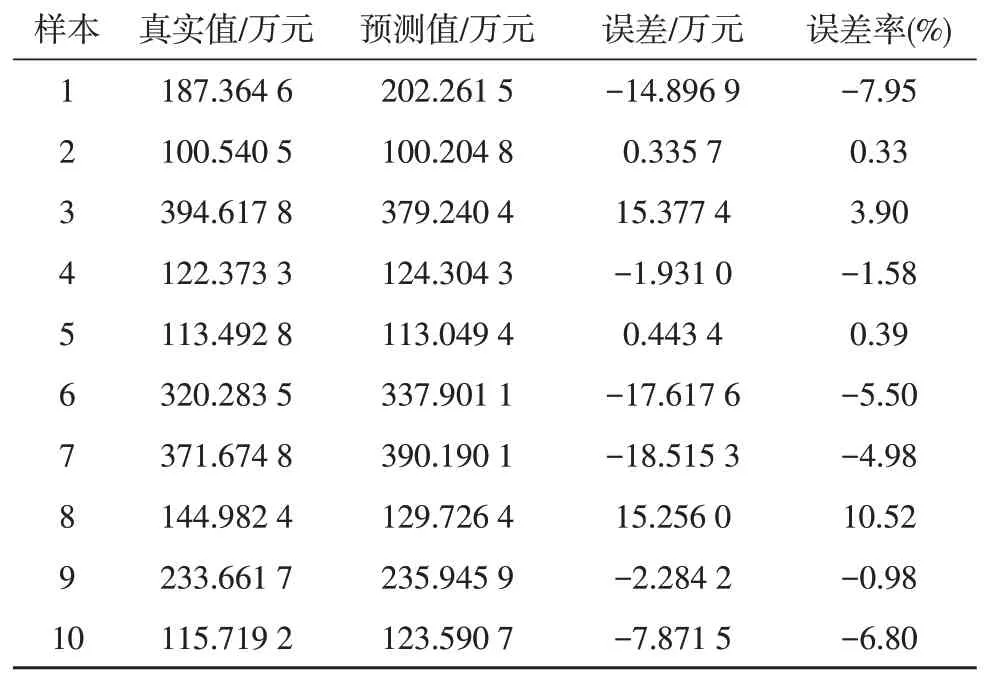
表3 测试集静态投资预测结果表(部分)
静态投资预测值与真实值结果如图4 所示,静态投资误差与误差率如图5 所示。真实值与实际值的最大误差为19.517 9 万元,最小误差为0.335 7 万元,最大误差率为10.52%,最小误差率为0.33%。MAE为9.660 4 万元,MAPE为4.39%,相比训练集的MAE、MAPE有所增加,后期可通过搜集更多样本训练模型进行优化。实验验证了所选取核心影响因子的合理性及预测模型的准确性。
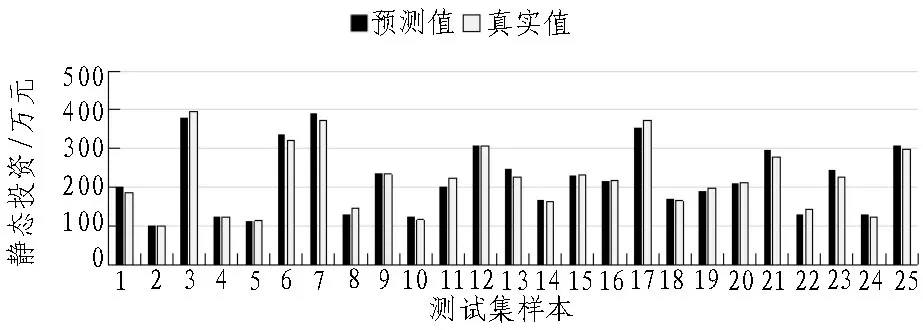
图4 测试集样本预测值与真实值结果
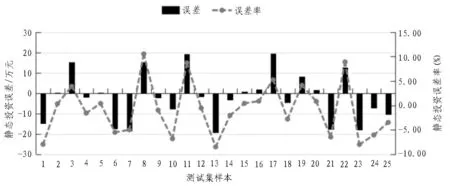
图5 测试集样本静态投资误差与误差率
5 结束语
文中分析了输电工程静态投资的影响因子,采用Pearson 相关系数筛选出大于0.8的极强相关因子,通过标准化处理将数据样本划分为训练集、验证集、测试集,基于GBDT 算法利用5 折交叉验证的方法进行模型调优及初步评估,最后通过测试集验证了所提预测模型的正确性,MAPE低至4.39%,对于项目投资具有一定的参考价值。由于数据样本较少只有125 组,因此测试集的性能低于验证集,后期将通过搜集更多数据样本对预测模型进行训练优化,提升测试集样本的预测准确性。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
云南画报(2021年8期)2021-11-13
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
电子设计工程(2015年15期)2015-02-27
