
基于BERT 与融合字词特征的中文命名实体识别方法
2021-10-10 03:55朱亚明
电子设计工程 2021年19期
朱亚明,易 黎
(1.武汉邮电科学研究院,湖北武汉 430074;2.南京烽火天地通信科技有限公司,江苏 南京 210019)
在文本处理中,通常会重点关注到诸如人名、地名、组织机构名称等含有特定信息的文本单元,在自然语言处理(Natural Language Process,NLP)中被称为“命名实体”,而命名实体识别(Named Entity Recognition,NER)[1]则是专门用于识别特定命名实体的NLP 基础任务之一。
随着深度学习在各个领域的发展,如今已广泛应用于NLP 各类任务中。该文以经典模型BiLSTMCRF 为基准模型进行研究,针对中文命名实体识别的任务特性,通过引入预训练语言模型BERT 以及Lattice LSTM,在语义字向量表示及字词特征融合处理上进行改进,提升了识别精度,取得了优于基准模型及对比模型的结果。
1 概述
近年来随着深度学习的发展,其在计算机图像处理以及语音识别领域有相当优异的表现,于是NLP 学者将其引入自然语言处理的各类任务中。2011 年Collobert 等在命名实体识别任务中引入神经网络,实现特征的自动化提取,大大减小了传统统计方法的特征工程工作量[2]。此后神经网络逐渐被广泛应用到命名实体识别研究领域。文献[3]提出双向长短期记忆网络(Bi-directional Long Short Term Memory,BiLSTM)获取字级特征表示,文献[4]提出BiLSTM-CRF 结构,使用了拼写特征、内容特征、词语向量和词典特征4 种特征,实验结果表明,加入的特征能够提高识别率。文献[5]提出迭代空洞卷积神经网络(ID-CNNs)模型作为序列标注部分的编码器。序列标签解码常用的结构和方法包括多层感知机和Softmax 层输出[5]、条件随机场(Conditional Random Fields,CRF)[6-7]和RNN[8]等。总的来说,使用深度学习方法处理命名实体识别任务时,RNN-CRF结构得到了普遍应用,尤其是BiLSTM-CRF 模型,成为命名实体识别任务深度学习方法的经典模型。
对于中文命名实体识别,由于中文的特性,字和词都各含有一定的信息和特征,因此有基于字级和词级以及结合字词特征3个方向[9]。文献[10-12]对比研究了字级和词级基于统计方法的表现,发现字级的命名实体识别往往表现得更好。同时也有研究人员尝试在字级命名实体识别结构中加入词级特征进行综合训练[13-15]。其中效果最好的是文献[16]中提出的Lattice LSTM,融合字级与词级特征,在MSRA 语料上F1 值达到93.18%。
然而,前述的字级中文命名实体识别不能很好地完全提取出汉字字符所包含的信息,无法处理例如字词多义等现象。BERT[17]有效地解决了这个问题,由于其在英文自然语言处理领域多个基础任务上表现优异,且具有优秀的表义能力,从而将其引入中文命名实体识别领域。该文以BERT 作为预训练语言模型(Pre-Training Language Model,PLM),结合LSTM-CRF 基准结构,并针对中文的字级和词级特征,使用Lattice LSTM 作为第二部分的语义编码层,提出BERT-Lattice-CRF 模型结构。
2 BERT-Lattice-CRF模型
BERT-Lattice-CRF 模型由字向量编码—语义编码—标签预测“三步走”的思想分为3 个部分,分别对应结构中的BERT、Lattice LSTM、CRF 3 个子结构。对比传统的LSTM-CRF 结构,该文提出的模型主要在两个方面做了调整:1)在模型头部加入了BERT 预训练语言模型,用以加强模型的语义表征能力;2)利用Lattice LSTM 替代传统的LSTM,这一点主要针对中文命名实体识别任务,因为Lattice LSTM 相较于传统LSTM 考虑到了中文里字词关系的影响,融合了字和词的特征信息,能够更好地进行语义编码。模型整体结构如图1 所示。
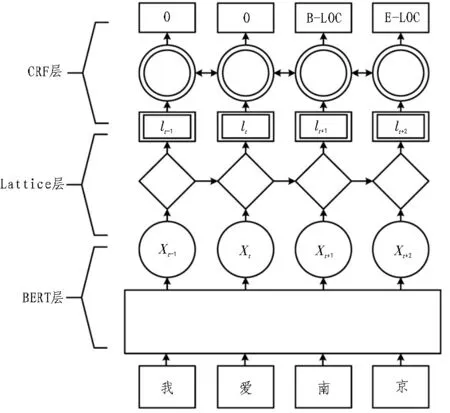
图1 模型整体结构
2.1 BERT预训练语言模型
BERT(Bidirectional Encoder Represent-ations from Transformers)是由Devlin 等人在2018 年提出的预训练语言模型。直观解释为Transformer的双向编码器部分,在预训练过程中会综合考虑全部的上下文来调整参数,从而得到深度双向表示。因而将其作为预处理部分整合到其他的输出层前部,通过微调用以构建多种任务模型。BERT 模型结构如图2所示。
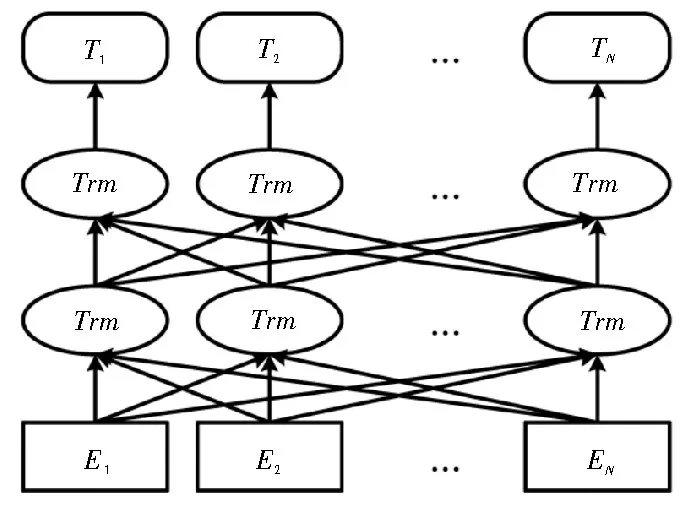
图2 BERT预训练语言模型
Transformer 有别于传统的RNN 和CNN,利 用Attention 机制把文本中所有单词两两之间的距离映射为1,从而很好地解决了NLP 难以处理的长文本依赖问题。Transformer 本质上是一个Encoder-Decoder的结构,BERT 只用到了Encoder的结构,如图3 所示。
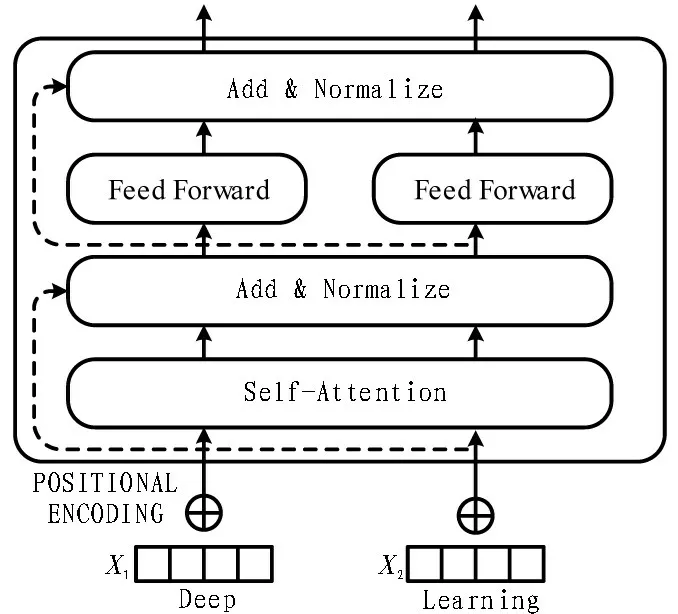
图3 Transformer中Encoder的结构
在Encoder 中,数据首先经过self-attention 模块得到一个加权特征向量Z:
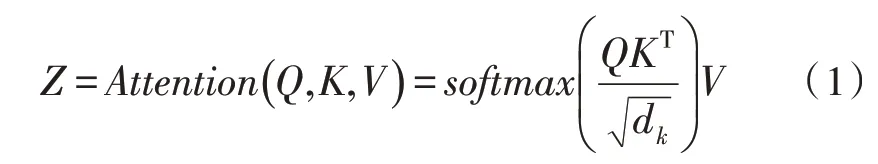
在Self-Attention 中,每个字词对应3 个64 维向量:Query、Key和Value,由嵌入向量x乘以3 个512×64 大小的权值矩阵WQ、WK、WV所得。
在Self-Attention 最后采用了残差网络中的Short-Cut 结构及层归一化,来处理模型退化问题:
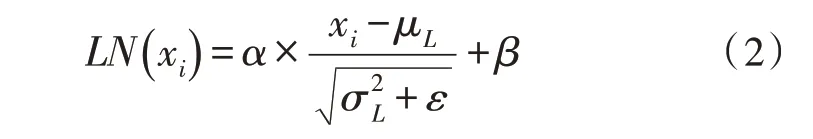
由式(1)得到加权特征向量Z后,进入Encoder的下一子结构——前馈神经网络(Feed Forward Neural Network)。其是一个两层的全连接网络,第一层为ReLU 激活函数,第二层为线性激活函数,可表示为:
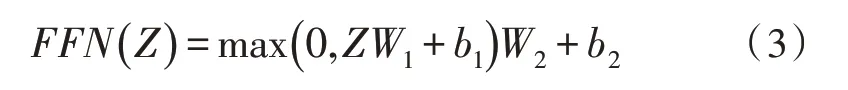
为了解决捕捉顺序序列的问题,将位置编码(Position Embedding)特征信息整合到字词向量编码中,使得Transformer 可以对各位置的字词进行区分。BERT 设计的位置编码规则为:
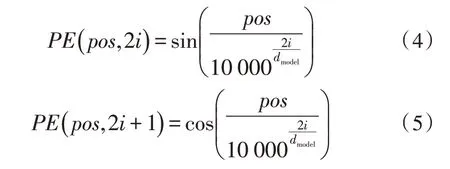
其中,pos表示单词的位置,i表示单词的维度,dmodel是位置编码的特征向量长度。
在训练任务上,BERT 提出一种新的训练任务:遮掩语言模型(Masked Language Model,MLM),随机选择语料中15%的单词,用[Mask]掩码代替原始单词,然后让模型正确预测被遮掩掉的单词。而且具体设计上,被遮掩掉的单词中80%确实被替换成了[Mask]标记,10%被随机替换成另一个单词,10%不做任何处理,保持原单词不变。除了MLM 之外,BERT 模型中还提出了一个“下一句预测”(Next Sentence Prediction)任务,可以和MLM 一起训练文本句子对的表示。具体为在做语言模型预训练时,构建句子对中出现两种情况:1)第二个句子是第一个句子的下一句;2)第二个句子为语料中随机挑选的其他句子。而BERT 模型需要训练学习判断第二个句子是否为第一个句子的下一句。
BERT的问世使得通过预训练语言模型得到字词嵌入向量与下游自然语言处理任务之间的关系发生了变化,与其他语言模型相比,BERT 能够很好地学习到字的上下文信息,获得更好的字向量表示。
2.2 Lattice LSTM编码层
LatticeLSTM 模型整体结构上继承自LSTM 结构,在对字信息的提取上同原始结构一样。而对于词信息,模型先是使用大规模自动分词获得词典,再通过重新设计cell的结构,将句子中的词信息加入模型中,如图4 所示。该模型的重点在于cell的设计。
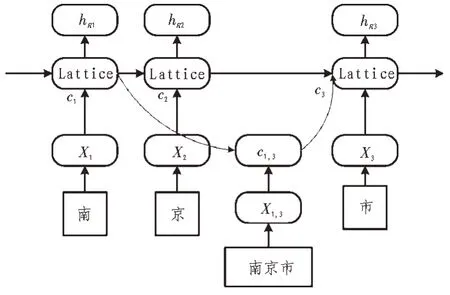
图4 Lattice LSTM词典加入模型
2.2.1 字级特征
当词典中不存在任何以输入的这个字为结尾的词时,cell 之间的传递与正常的LSTM 相同,即假设无任何词典信息时,Lattice LSTM 退化为LSTM,其计算公式如下:
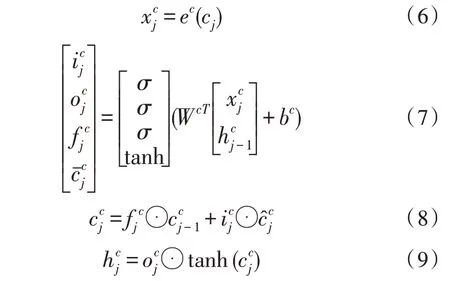
其中,cj是当前的输入,ec是字级别的字向量嵌入字典,就是当前输入的字向量,、和是输入、遗忘和输出门,σ表示sigmoid 函数。
2.2.2 词级特征
词级特征分为两部分,以图4 为例,假设当前输入的是“京”字,则它在词典中匹配到的是“南京”这个词,那么此时的词级特征的输入向量为“南京”这个词开头的“南”这个字在模型中的隐向量(即“南”这个字被输入时的,记为,其中b表示这个词开头的字在句子中的开始位置的index)以及“南京”这个词直接嵌入的向量(记为,其中b、e表示这个词开头的字在句子中的开始位置的index 和结束位置的index)。得到两个输入向量后,以作为正常LSTM 中的作为正常LSTM 中的进行计算:
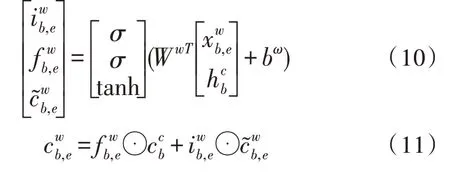
对词级的特征处理不需要输出门,因为这一步并非所需要的输出,网络结构最后将字信息和词信息融合之后由输出门控制。而且不加输出门可以确保这一信息会被使用,即默认分词信息的加入对模型有所帮助。
2.2.3 字词级特征融合
以南京举例,只出现了一个词,但对部分字来说,可能会在词典中匹配到很多词,例如“桥”这个字就可以在词典中匹配出“大桥”和“长江大桥”。为了将词、字信息融合,进行一步类似Attention的操作:
对于匹配出的每个词的向量都进行如下操作,计算属于它的输出门:
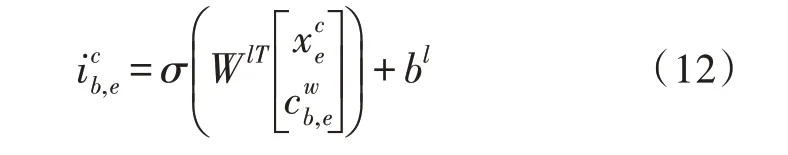
再使用当前字计算出的输入门和所有词的输入门做归一计算权重:
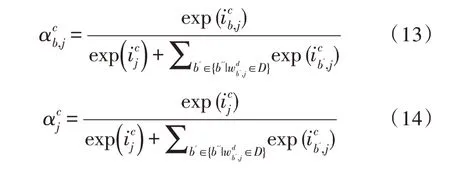
最后与通常计算Attention 特征向量相同,利用计算出的权重进行向量加权融合:
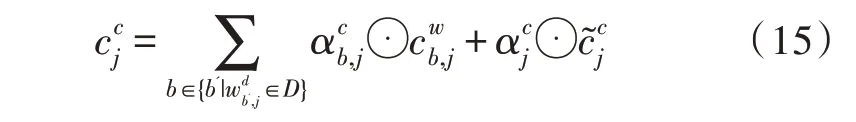
对于及其最后输出的计算同原来的LSTM的计算一致:
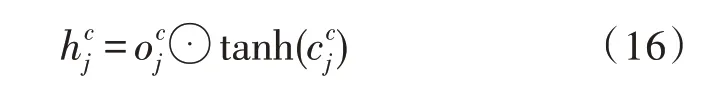
2.3 CRF标签预测
Lattice 不能考虑标签之间的关系,在命名实体识别中,有些标签遵循着一定的逻辑关系,CRF 能够充分利用标签相互间的关系,得到全局意义上的最佳标签序列。
对于模型而言,CRF 层的参数是一个(k+2)×(k+2)的矩阵A,其中,k是标注集的标签数,元素Aij表示的是从第i个标签到第j个标签的转移得分,则在标注某个位置时即可考虑其前面位置的标签进行标注。加2 是因为需要在句首与句末分别加一个表示起始和终止的标签。若记一个长度等于句子长度的标签序列y=(y1,y2,…,yn),则模型计算句子x的标签等于y的打分为:
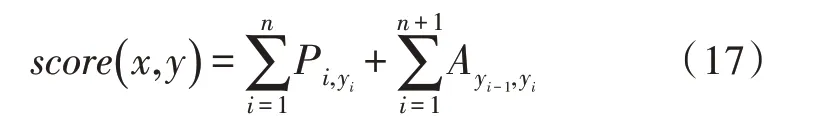
可以看到整个句子的打分由每个位置的LSTM层输出Pi,yi与CRF 转移得分Ayi-1,yi两部分之和算得。最后用softmax 算得归一化后输出的概率:
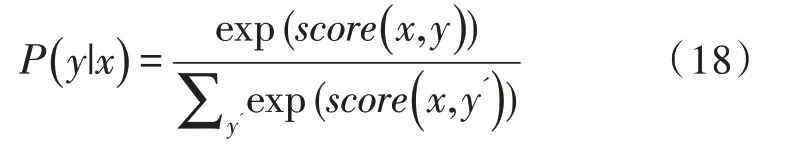
模型训练时通过最大化对数似然函数进行参数分析,以得到全局最优解:
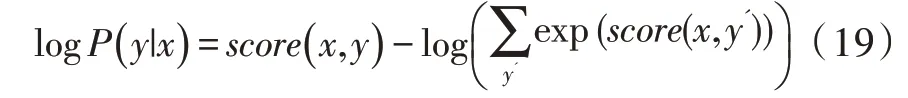
模型在预测时使用动态规划的Viterbi 算法来求解最优路径:
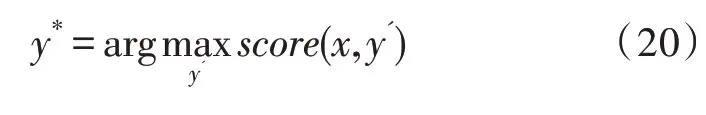
3 实验准备与结果分析
3.1 实验数据集
文中使用的数据集为公开数据集MSRA,该数据集是微软亚洲研究院公开的中文命名实体识别标注数据集,有3 种命名实体,分别为人名、地名、机构名,使用nr、ns、nt 表示。数据集分为训练集和测试集,训练集有46 364 个句子,测试集有4 365 个句子。
3.2 序列标注方法
在命名实体识别中,有BIO、BIOS、BIOES 3 种较为常用的标注方式。文中采用BIOES 序列标注方式,其中B 标识实体的开始、I 标识实体的中间部分、E 标识实体的结束、S 标识只有单字的实体、O 标识非实体的部分。人名、地名、机构名分别标注为PER、LOC、ORG,则共有11 个标签待预测:B-PER、I-PER、E-PER、B-LOC、I-LOC、E-LOC、B-ORG、I-ORG、E-ORG、S、O。
3.3 评价指标
该实验评价指标为查准率(Precision)、查全率(Recall)和F1 值。查准率又叫准确率,是针对预测结果而言的概念,表示的是预测为正确的样例中有多少是真正的正确样例;查全率又叫召回率,是针对原样本而言的概念,表示的是样本中的正确样例有多少被预测正确。一般来说希望查准率和查全率都很高,但实际上两者是相矛盾的,无法做到同时很高,因此出现一个新的指标F1 值。F1 值是查准率和查全率的调和平均值,可以同时考虑并让两者同时达到最高,取得平衡。各指标的公式为:

其中,TP表示识别为实体标签,实际也是实体标签;FP表示识别为非实体标签但实际为实体标签;FN表示识别为非实体标签,实际也是非实体标签。
3.4 参数设置
Google 以checkpoint的形式提供了预训练的模型,包括英语、汉语和多语言等类别模型,对于汉语只有一个版本——BERT-Base,模型词表中包括简体字和繁体 字,共12 层,768 个隐单元,12 个Attention head,110M 参数。文本长度阈值设为128个字符,训练时的batch_size 为16,学习率为5×10-5,dropout为0.5,LSTM 模型的hidden size 设置为200。
3.5 实验环境
该文全部实验进行的环境:操作系统Windows7、CPUInteli7-9700K、内存16G、GPU Nvidia GTX 1080Ti(8 GB)、Python 3.6、Pytorch 1.2.0+cu92。
3.6 实验过程
BERT-Lattice-CRF 模型的训练有两种方式:1)训练全部参数(BERT-Lattice-CRF-f);2)只训练Lattice-CRF 参数而保持BERT 参数不变。实验中选择以下模型进行对比:1)LSTM-CRF 模型;2)BERTLSTM-CRF 模型;3)Lattice-LSTM-CRF 模型。
3.7 实验结果
两种训练方式得到的结果对比如表1 所示。
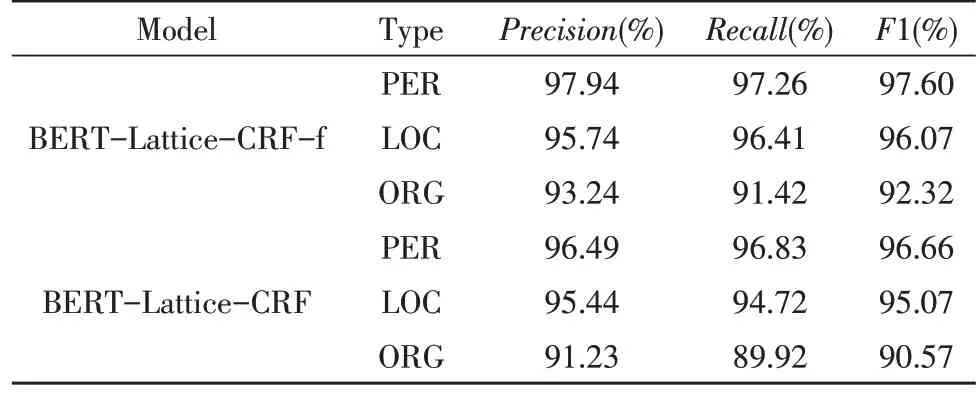
表1 不同命名实体的识别结果
可以看到,相比于人名和地名,机构名预测准确率偏低,分析原因为在机构名实体中普遍存在着实体嵌套、简写缩写名称、歧义表述等问题,难以进行准确预测。而训练全部参数得到的模型比固定BERT 层参数只训练Lattice-CRF 层参数得到的模型,就识别结果而言预测准确率更高,这是可以预见的,因为训练全部参数可以针对训练数据集得到更能表征特征的参数集,从而得到更好的预测结果。
文中使用的模型与对比实验模型的结果如表2所示。
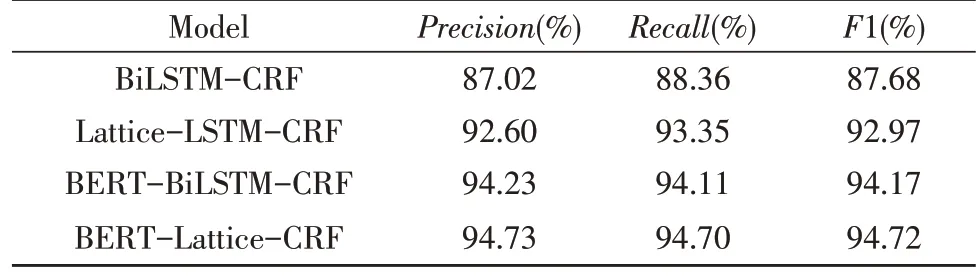
表2 不同模型的识别结果
与经典的LSTM-CRF 序列标注模型相比,基于BERT 预训练模型的BERT-LSTM-CRF 模型表现更好;与Lattice-LSTM-CRF 模型相比,文中提出的BERT-Lattice-CRF 模型表现更好,说明BERT 预训练语言模型能够更好地获取到中文字级的语义特征。同时Lattice-LSTM-CRF 相比于LSTM-CRF 模型,识别准确率更高;且BERT-Lattice-CRF 相比于BERT-LSTM-CRF 模型识别准确率更高,说明Lattice-LSTM 结构相较于LSTM 结构来说,能够融合中文字和词级的语义信息,对于提升识别性能是有意义的。而文中提出的将BERT 预训练语言模型与Lattice-LSTM 模型相结合,既能得到更深层次的中文字级语义特征,同时针对中文语言特性、融合字级和词级特征信息,能够得到更好的命名实体识别结果。
4 结论
由于在中文命名实体识别领域,传统词向量不能表示多义字词信息,针对这个问题引入BERT 预训练语言模型,同时针对中文语料的特点,结合能够融合字词信息的Lattice LSTM 结构,提出了BERTLattice-CRF 模 型。BERT 基 于Transformer 中的Encoder 部分构建双向编码器结构,配合Masked Language Model 和Next Sentence Prediction 两个训练任务,可以得到更强大的字向量语义表示;而Lattice LSTM 独特的晶格结构融合了中文字级和词级的特征,在中文命名实体识别任务上能有更好的表现。整体模型优于当前主流的BERT-BiLSTM-CRF 模型,提升了中文命名实体识别的识别率。
但文中提出的模型有其存在的问题。首先,BERT 模型在预训练时会出现特殊的[MASK],但在下游的fine-tuning 中不会出现,则会产生预训练阶段和fine-tuning 阶段不一致的问题;此外Lattice LSTM 将句子的输入形式从链式序列转换为图,会大大增加句子建模的计算成本。因此如何解决以上问题,自然成为下一步研究的方向。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
公民与法治(2016年10期)2016-05-17
