
基于改进YOLOv3和立体视觉的园区障碍物检测方法
2021-10-08 02:22胡丹丹张莉莎张忠婷
计算机测量与控制 2021年9期
胡丹丹,张莉莎,张忠婷
(中国民航大学 电子信息与自动化学院,天津 300300)
0 引言
由于封闭园区环境具有结构化程度高、道路环境简单、行驶路线固定等特点[1],无人驾驶技术在园区物流、园区巡逻等场景的应用越来越广泛。障碍物的准确检测是园区无人车安全行驶的基础,也是当前无人驾驶技术研究的重难点之一。其中基于视觉的障碍物检测方法具有成本较低、检测内容直观、检测范围广泛等优点,是目前最常用的检测方法。
传统的视觉障碍物检测算法以基于人工特征提取方法为主[2],存在计算复杂度高和检测速度慢等问题[3]。基于深度学习的障碍物检测算法主要分为基于区域建议和基于逻辑回归两类。其中,以R-CNN[4-6]系列模型为代表的基于区域建议算法生成样本候选框,通过卷积神经网络进行样本分类[7],此类算法检测精度较高,但计算复杂度大,无法满足实时性要求;而以YOLO[8-10]系列模型为代表的基于逻辑回归算法不需要生成候选框,网络直接输出边界框信息,检测速度和精度均有所提升,但仍存在少量漏检情况。
因而提升检测精度和速度成为近几年障碍物检测算法改进的重点。针对文献[10]存在的问题,文献[11]采用数据增强、引入CIOU(Complete Intersection Over Union)损失函数等方式,平均精度提升的同时检测速度有所牺牲;其优化版本YOLOv5减小模型体量,检测速度有较大提升,但适用场景和精度均受到影响。
综上发现,文献[10]采用的YOLOv3算法在检测精度和速度上均具有较好的表现。近几年,国内外诸多学者针对基于YOLOv3的检测方法作出了不同程度的改进。文献[12]通过采用Gaussian-YOLOv3与变形卷积技术,有效解决了小目标的检测问题;文献[13]结合Tiny-YOLOv3和目标跟踪算法,提升了无人机针对地面目标的检测速度;文献[14]通过改进特征提取网络和定位损失函数,降低了非机动车类目标的漏检率;文献[15]考虑融入平滑标签,改进特征提取网络结构,一定程度解决了行人检测实时性和精度不能同时兼顾的问题。
基于以上研究,为实时准确获得园区障碍物的类别与位置信息,本文提出一种结合改进YOLOv3和立体视觉的园区无人车障碍物检测方法:通过优化特征提取网络、引入GIOU损失函数、采用k-means++聚类方法对YOLOv3算法进行改进,并结合立体视觉测距原理获得无人车与障碍物的距离,实验结果表明在公开数据集与园区自建数据集上均取得较好的检测效果。
1 YOLOv3算法
如图1所示,YOLOv3的网络结构主要包括基础网络和YOLOv3分支。其中Darknet-53负责特征提取,YOLOv3分支负责目标检测。YOLOv3网络将图片尺寸放缩到416×416作为网络输入,输入的障碍物图像经过daknet-53特征提取网络后得到3个尺度(13×13、26×26、52×52)的特征图。接着将输入的图像分为S×S个网格,每个网格单元负责预测3个边界框。预测信息包含边界框的位置及尺寸信息(目标中心坐标(x,y)与边界框尺寸(w,h))、置信度得分及其属于某类别的条件概率。最后设置得分阈值,通过非极大值抑制过滤分数较低的边界框,其余边界框信息将作为最终的障碍物检测结果输出。
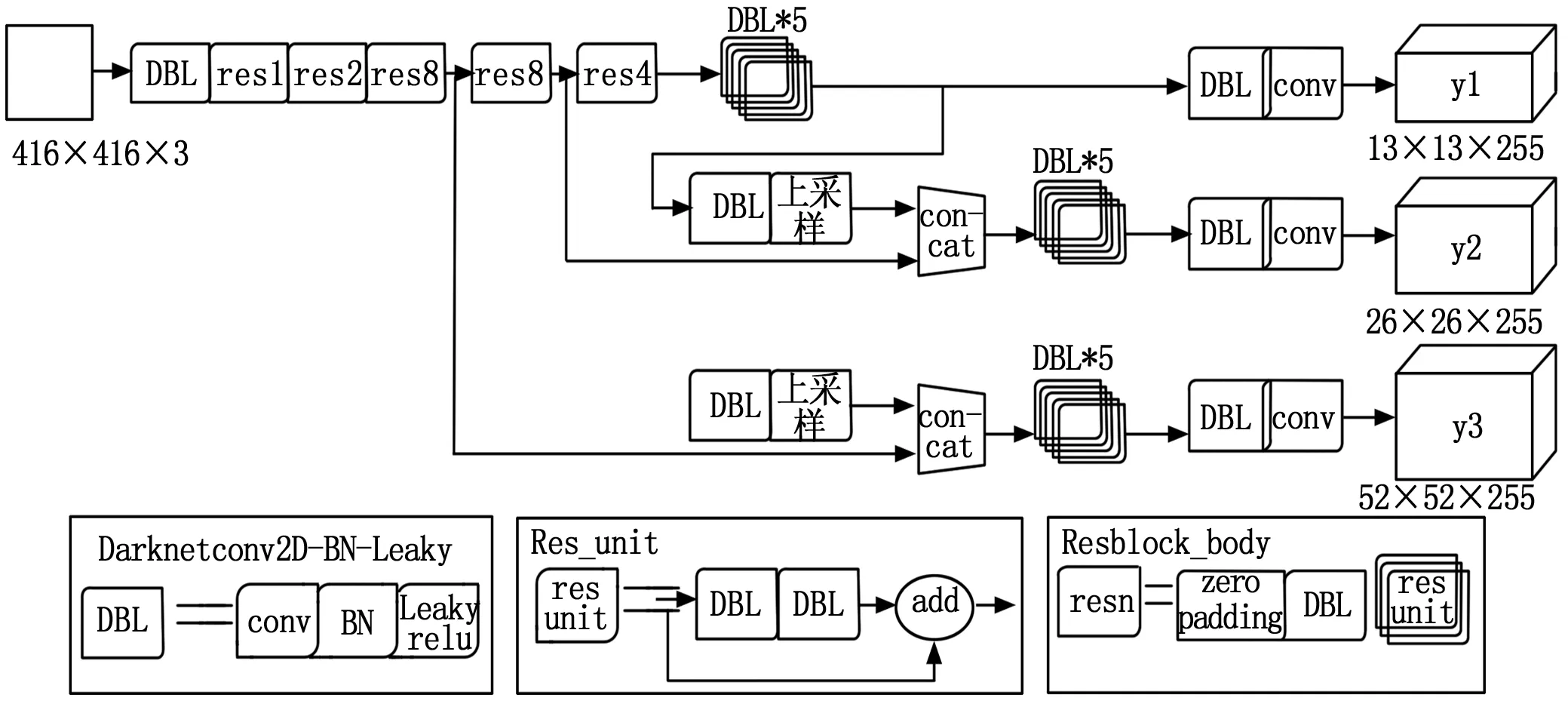
图1 YOLOv3网络结构图
2 结合立体视觉的改进YOLOv3算法
目前基于YOLOv3的障碍物检测研究中普遍存在检测实时性差、具体场景检测准确率低等问题,本文针对园区无人车障碍物检测场景,对YOLOv3算法进行特征提取网络结构、损失函数和聚类方法三方面的的改进。
2.1 特征提取网络结构改进
考虑到无人车障碍物检测的实时性要求以及园区检测目标多为行人和非机动车的中小型目标的情况,对YOLOv3采用的Darknet-53特征提取网络结构进行以下改进。
1)网络结构简化:
如图1所示,DBL是YOLOv3的基本组成部件,在DBL单元结构中,批次归一化(batch normalization,BN)层一般置于卷积层之后,非线性处理单元(Leaky RELU)之前。其计算过程[16]如公式(1)所示,首先计算输入数据均值μ和数据方差σ,然后对输入数据进行标准化操作,训练缩放因子γ与偏置参数β,经γ、β线性变换后得到新的输出值y。
yi←γxi+β≡BNγ,β(xi)
(1)
对输入数据进行标准化操作之后,能够有效解决梯度消失与梯度爆炸的问题,在模型训练时起能加速网络收敛,并减少过拟合现象出现的可能性。但同时BN层会在网络前向推理时增加模型运算量,影响检测性能,占用更多存储空间,导致检测速度变慢。本文将BN层的参数合并到卷积层,进而减少模型运算量。合并后的权值参数ω、偏置β与缩放因子γ、均值μ呈正相关,进而提升模型前向推断速度。
其中YOLOv3中卷积计算结果如公式(2)所示,xi、ωi分别为输入数据和权值参数,输出为二者卷积之和。公式(3)中μ、σ分别为数据均值和方差,γ、β分别为缩放因子和偏置参数,xout即为BN计算结果。
(2)
(3)
将BN层参数与卷积层合并后的计算结果如公式(4)所示,变量含义与上文相同。合并后权值ωi和偏置β如公式(5)~(6)所示。
(4)
合并后权值ωi为:
(5)
偏置β为:
(6)
故合并后的计算结果为:
(7)
卷积层与BN层合并后,可以共用Blob数据,进而降低内存的占用,提升速度。
2)多尺度检测改进
将输入图像尺寸统一放缩到416×416,特征提取网络对输入图像进行下采样(subsampled)操作,每次下采样对应得到一个尺度的特征图。具有较大分辨率的浅层特征图涵盖更多的位置相关信息,具有小分辨率的深层特征图涵盖更多的语义相关信息。将深层残差块采样得到的特征图与浅层残差块采样得到的特征图进行融合,可以增强浅层特征的语义信息,同时在细节信息最多的特征图上给待检测障碍物分配最精准的边界框,提高对小目标物体的检测性能。
如图2所示,本文在 YOLOv3原有3个检测尺度的基础上进行扩展,添加一个尺度的特征图。经过2倍上采样后,特征尺度输出为104×104,将第11层特征提取层与第109层route层、第85层与第61层,第97层与第36层进行融合,充分利用各层特征。特征图大小依次变为了208、104、52、26、13;4个尺度大小为104×104、52×52、26×26和13×13。4个特征尺度分别为:104×104,52×52,26×26和13×13。最后借鉴特征金字塔网络(FPN,featu-re pyramid network)结构进行特征融合,其中新增加的104×104特征图采用更精准的锚框(anchor box),提高算法对小目标的检测精度,同时缓解了在密集车辆和行人环境下待检测目标的错检和漏检问题。
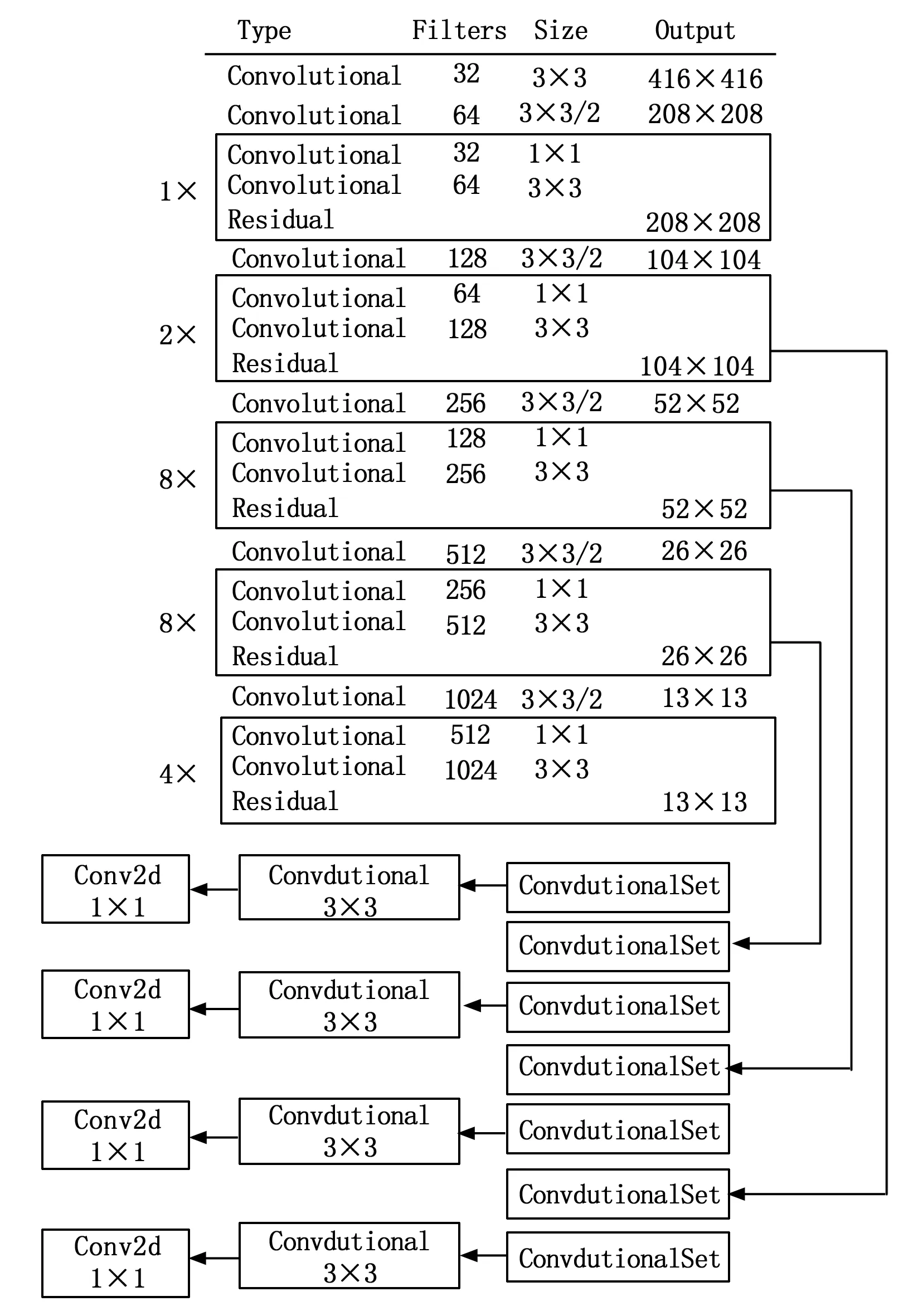
图2 多尺度YOLOv3网络结图
网络首先依次对4个尺度(13×13、26×26、52×52、104×104)大小的特征图进行处理;然后将前3个尺度(13×13、26×26、52×52)的特征图上采样后与较大一个尺度的特征图拼接后分别送至检测大、中、小目标的YOLO层;最后与新增加的104×104的特征图进行拼接操作后送到剩余YOLO层,实现4个尺度的融合操作。由此可以获得一个强语义信息,并且在每个融合后的特征层上单独进行预测。
预测的输出张量中包括3部分内容,分别是障碍物边界框、障碍物目标和障碍物类别。改进后的YOLOv3将融合后生成的特征图细分为S×S的网格(根据具体特征图包含13×13、26×26、52×52、104×104),每个网格需要预测3个不同的边界框,进而输出张量应当表示为S×S×[3×(4+1+3)],包含4个障碍物边框偏移参数,1个障碍物目标和3个障碍物类型。
2.2 损失函数改进
交并比(IOU,intersection over union)是比较两个任意形状之间相似性最常用的指标,IOU定义如公式(8)所示,其中A、B表示预测框与真实框。
(8)
YOLOv3原始算法采用IOU作为性能指标和边框损失函数。但物体重叠时IOU值为零,无法反映两物体之间的距离;物体不重叠且梯度为零时,无法进行参数优化。因此本文选用推广IOU(generalized intersection over union,GIOU)[17]代替IOU。GIOU与IOU定义一致,并且维持尺度不变性,在重叠情况下与IOU具备强相关性。GIOU的计算公式如公式(9)所示,C为可以将A和B包围在内的最小封闭形状。
(9)
在YOLO和YOLOv2的基础上,YOLOv3将分类损失调整为二分交叉熵。如公式(10)所示,其损失函数依次由五部分组成:边框中心位置误差、边框宽度与高度误差、边框内包含检测目标时的置信度误差、边框内不包含检测目标时的置信度误差和目标分类误差。
(10)
若值为1,则第i个网格的第j个anchor box负责预测该目标边界框。本文采用GIOU作为边框损失函数,首先输入预测边界框与真实边界框的坐标值,并将预测值进行排序,然后分别计算、及二者交集的面积 ,随后找出最小包围框I,其中:
(11)
最小包围框的面积为:
(12)
最后计算GIOU、LGIOU,其计算公式如公式(13)~(14)所示。
(13)
LGIOU=1-GIOU
(14)
2.3 聚类方法优化
YOLOv3采用anchor box机制进行边界框预测,并选用k-means聚类方法对anchor box进行初始化,获得一组固定尺寸的候选框。特征图的尺度与anchor box的尺寸信息成反比,较大尺度的特征图使用较小的anchor box进而获得小目标的检测信息,较小尺度的特征图使用较大的anchor box进而获得小目标的检测信息。例如,YOLOv3在COCO数据集上,可得9种anchor box的尺寸信息如表1所示。
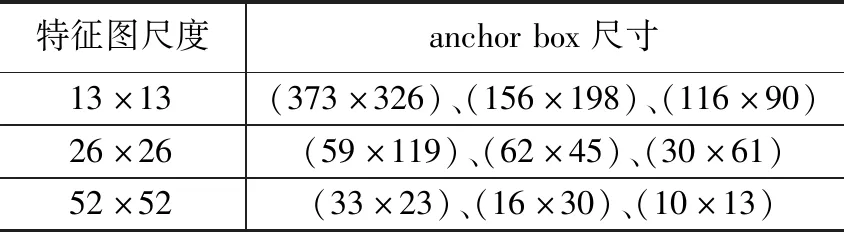
表1 YOLOv3 的先验框尺寸
考虑到KITTI、PennFudanPed等数据集中图像尺寸过大,且k-means聚类方法在初始聚类点选择时具备过强的随机性和较大的时间复杂度,本文采用k-means++算法[18]对数据重新进行聚类,获得更恰当的聚类中心。
k-means++的基本思想是使所有被选择的初始聚类中心之间的距离值尽量大。首先从输入的众多数据点中任意选择一个数据点作为首个聚类中心x,然后针对数据集合中的每一个点a,计算其与最近聚类中心(当前已选择的聚类中心)的距离:d(a);接着对聚类中心点重新进行选择(依据是当前d(a)最大的点),重复以上操作,直至k个聚类中心点均被选出;最后用选出的k个初始聚类中心运行原始k-means算法,进而获得k个anchor box的尺寸信息。
考虑到本文数据集与公开数据集的差异,原始参数会影响模型训练时间和准确性,因此本文采用k-means++算法对园区障碍物数据重新进行聚类分析,针对设置的4种尺度,基于本文数据集最终得到如表2所示的12种anch-or box大致尺寸信息。

表2 k-means++聚类的先验框尺寸
2.4 结合立体视觉的障碍物检测流程
针对封闭园区场景内无人车障碍物实时检测需求,首先对立体视觉相机左侧图像使用改进YOLOv3网络模型进行障碍物目标检测,得到其类别及预测框信息;然后结合立体视觉相机获取左右两侧图像,进行立体匹配处理,通过深度计算获取障碍物与相机的距离信息,最终实现障碍物的类别与位置检测。检测流程如图3所示。
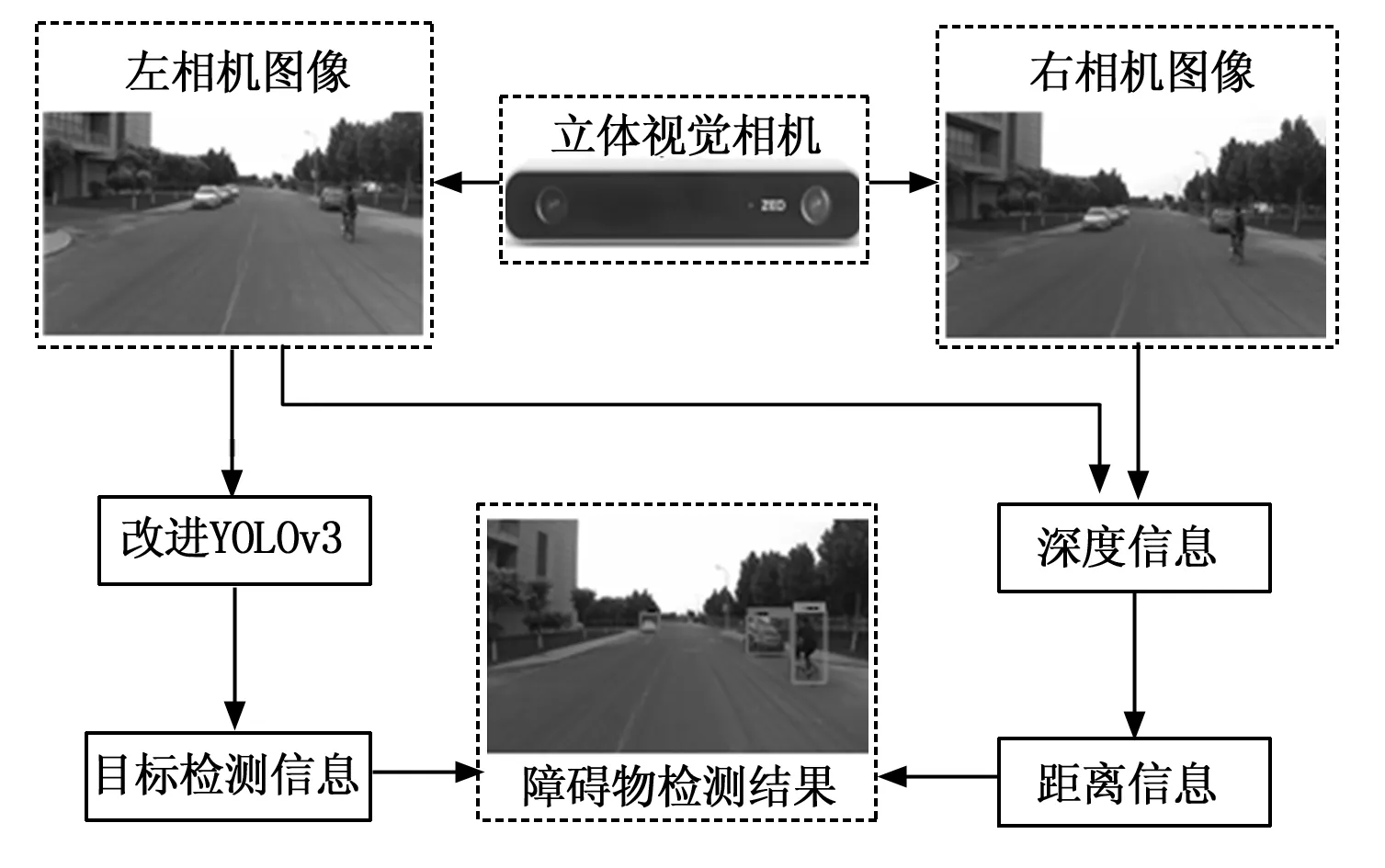
图3 障碍物检测流程
3 实验
3.1 实验设置与数据集制作
本文实验选用NVIDIA GTX1060 GPU,操作系统为Ubuntu 16.04,软件环境为CUDA9.0、Open CV3.4。ZED双目立体视觉相机用于获取深度信息,其基线距离为120 mm,帧率最高可达100 fps(Frames Per Second,每秒传输帧数)。
实验选用KITTI公开数据集中的校园场景图像数据,包含车辆、行人等园区内主要类别障碍物,由于该数据集中车辆类别占比较大,导致首次训练模型平均精度均值(mean Average Precision,mAP)仅为33%。因此,实验增加复旦大学PennFudanPed行人数据集和自制园区数据集HD-campus并进行数据扩充。最终根据实际场景将园区内主要障碍物分为Car、Pedestrian、Cyclist三类,共包含11 050张图像,按照6:2:2的比例分为训练集、验证集和测试集,将测试效果最好的模型用于实时场景检测。
3.2 模型训练
本文将训练集中图像统一转换为416×416大小输入网络,训练时设置32张图像为一个批次,其它参数设置如表3所示。
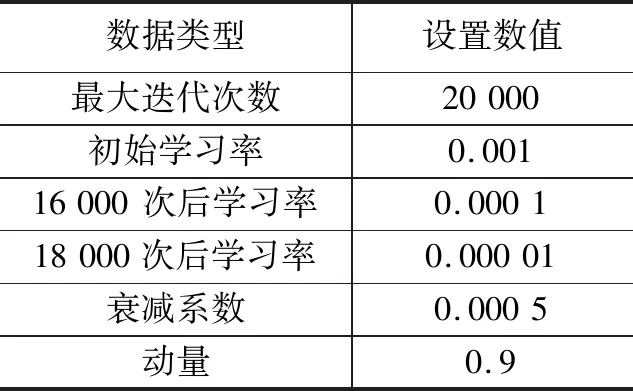
表3 模型训练参数设置表
经过20 000次迭代后的损失函数变化情况如图4所示,横坐标为迭代次数,纵坐标为损失函数值。可以看出,前2 000次迭代中平均损失下降速度较快,2 000~10 000次迭代平均损失缓慢下降,10 000次以后趋于稳定,只有小幅振荡,说明模型训练效果较好。
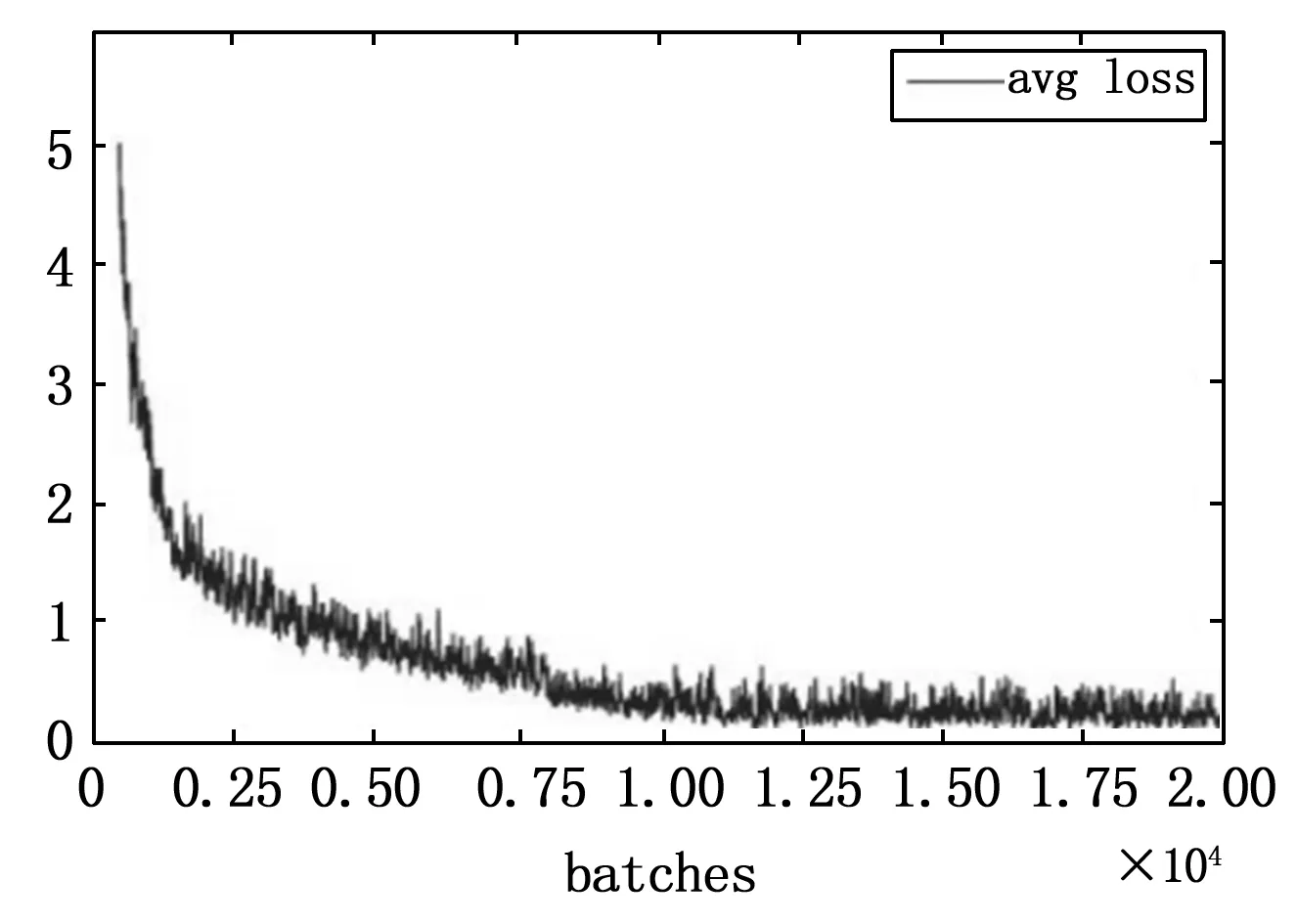
图4 模型损失函数变化图
结果显示,迭代20 000次的收敛效果最为稳定,所以选取对应的权重文件作为障碍物检测实验的网络模型。
3.3 实验结果与分析
1)分步改进实验:
为了提升模型的检测速度,本文将BN层参数合并到卷积层,并随机选取测试集中的10张图片,在其他实验设置相同情况下进行测试,对比合并前后的单帧图像检测速度。如表4所示,参数合并后,在本文实验平台上单帧图像检测时间平均减少25 ms,录制视频数据检测帧率提升50%,且合并后检测准确程度不受影响。
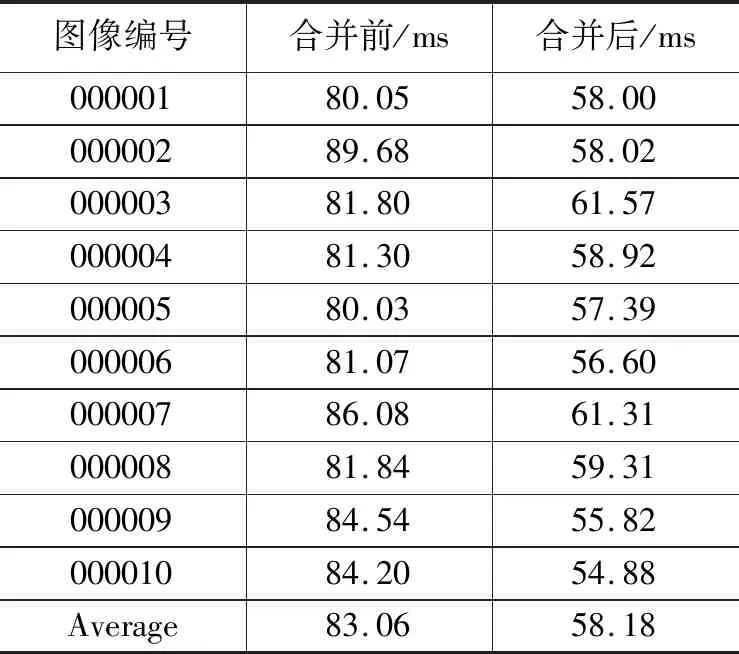
表4 单帧图像检测速度对比表
合并参数后,为了降低较小障碍物的漏检率,本文在YOLOv3的基础上增加了一个检测尺度。如表5所示,四尺度的特征提取网络结构较之前具有更高的检测精度。其中,Car类提升效果最为明显,mAP为98.55%,检测帧率达到40 fps。其它数据类型也有明显改善,平均检测精度提升2.42%,平均帧率提升6 fps。数据表明,增加至4尺度的YOLOv3模型针对每一类数据的特征提取更精准,分类识别能力更强。
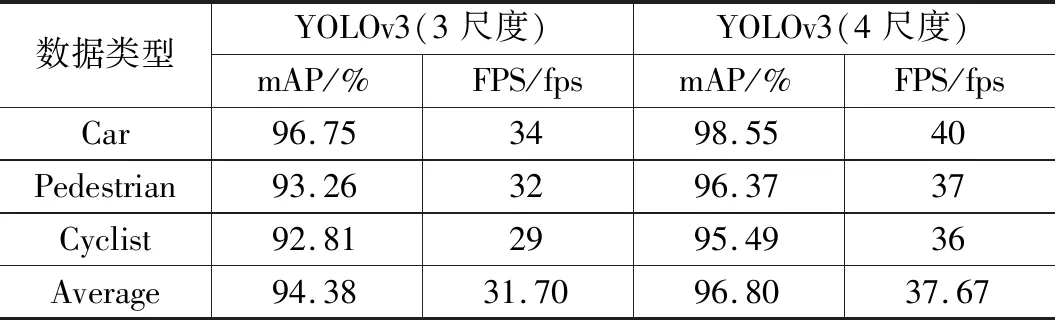
表5 多尺度改进检测结果
如图6所示,引入GIOU代替IOU作为边框损失函数后mAP值较改进前提升了6.3%。其中,Car类检测准确率最高,而Cyclist类检测准确率提升效果最为明显。实验表明,采用GIOU能有效提升模型检测精度与目标定位能力。
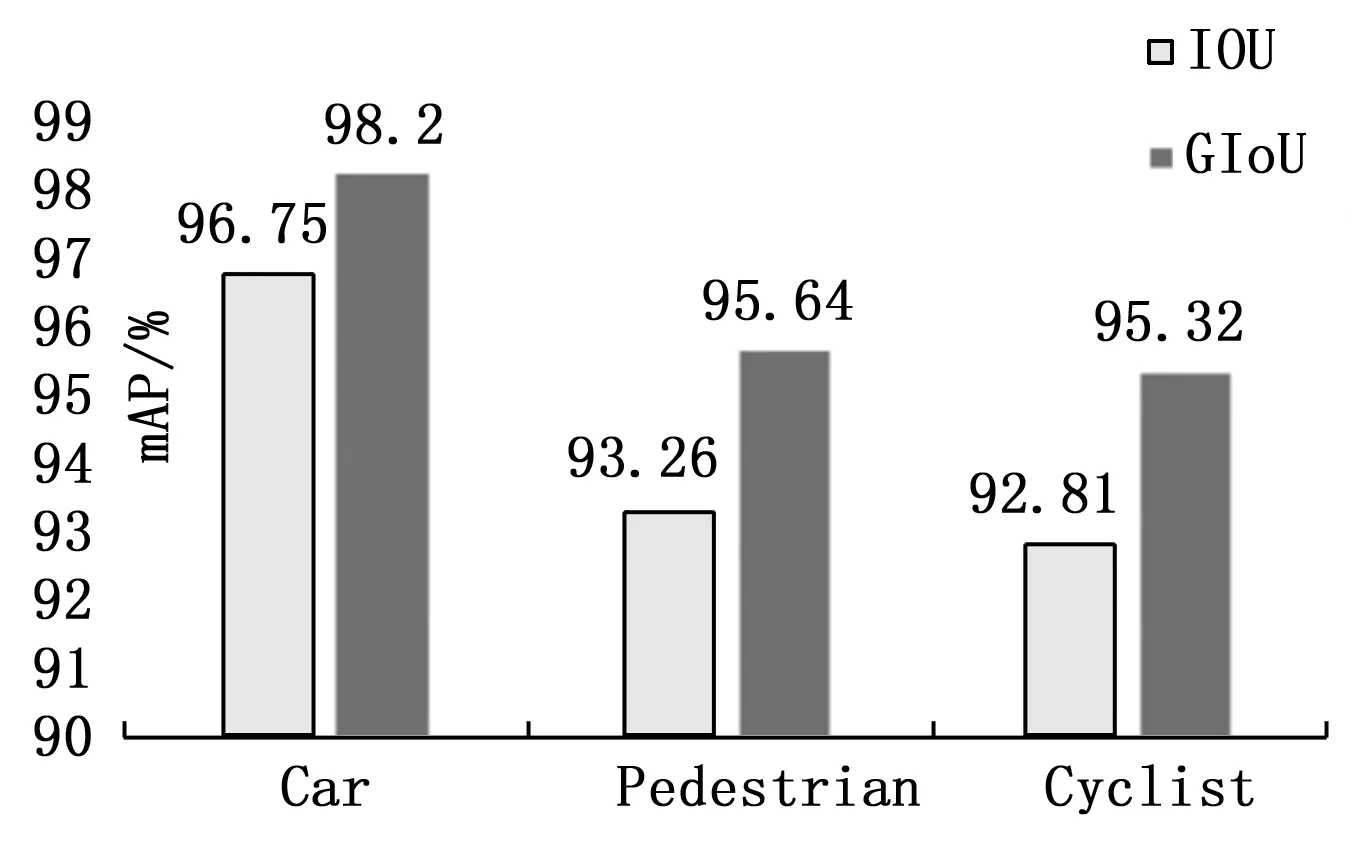
图5 改进前后mAP对比图
本文将改进后的模型与双目测距算法结合,使用ZED双目相机在校园(封闭园区)场景进行实时检测。改进后的模型检测平均帧率可达40 fps,满足实时要求。图6为实时检测效果截图,图(a)、(b)和(c)中类别检测未出现错检、漏检情况,模型目标检测效果较好。

图6 实时检测效果截图
本文将改进后的模型与双目测距算法结合,使用ZED双目相机在校园(封闭园区)场景进行实时检测。
本文根据公式(15)计算测距误差e,其中dm和dt分别为测量距离和真实距离。
(15)
表6为图6中障碍物测距实验数据,参考相机参数及数据可知校园场景中3~20 m内障碍物测距检测结果较为准确,图(b)与图(c)中距离较近或较远的障碍物测距误差稍大,平均测距误差为4.67%,效果较好。

表6 实际场景测距结果
2)消融实验:
本文从特征网络改进、改进多尺度融合、定位损失函数、聚类方法四方面对YOLOv3进行改进,为单独分析每一项对检测效果的影响,设置消融实验。如表7所示,设置五组实验,确保其它实验设置一致的情况下,从原始YOLOv3算法逐一添加改进项。实验1只对特征网络进行改进,实验2在实验1的基础上增加改进多尺度融合操作,实验3在实验2的基础上采用GIOU作为边框损失函数,最后一组即为本文改进后算法。

表7 消融实验结果
对比YOLOv3与实验1可得,特征网络改进不仅提升了检测精度,检测帧率也有明显改善;对比实验1、2、3和本文改进算法实验,可以发现改进多尺度融合、采用GIOU边框损失函数和优化聚类方法均能有效提升检测精度,但会增加计算量,使帧率稍有下降;最终改进算法mAP达到98.57%,较原始算法提升4.19%,帧率提升5.1 fps。由此可见,本文的改进方案对园区障碍物检测具有实际意义。
3)检测效果对比实验:
改进后模型检测效果如图7所示,进行数据扩充后训练得到的权重文件更容易检测到Pedestrian和Cyclist类别。图(a)、(b)为KITTI园区数据集改进前后检测效果对比,原模型未检测出的障碍物,改进后模型均能有效检测(图(a)、图(b)白色框选部分);图(c)选取了不同光照情况下的真实园区场景图像数据进行检测,原始YOLOv3模型法无法检测出障碍物,改进后模型可准确检测,对强光及阴影等环境适应性较好;图(d)选取了多类型障碍物场景,原始模型存在漏检现象,改进后模型使障碍物漏检率降低,且帧率仍满足实时检测要求,可见本文算法可以提升园区环境内障碍物检测效果。

图7 改进前后检测效果
将SSD、Faster R-CNN、近两年改进算法、YOLOv3以及本文选用算法检测结果进行比较分析。如表8所示,与YOLOv3原始算法相比,本文算法帧率增加了8 fps,mAP提升了4.19%,具有明显改进效果;而SSD与Faster R-CNN在检测精度或检测速度存在明显不足;与文献[14-15]的改进算法相比,本文算法的mAP与帧率也有一定提升;与YOLO的较新版本YOLOv4和YOLOv5(YOLOv5中较为完善的版本YOLOv5l)相比,本文的算法能同时兼顾检测精度与速度,可以较好适应园区环境障碍物检测。
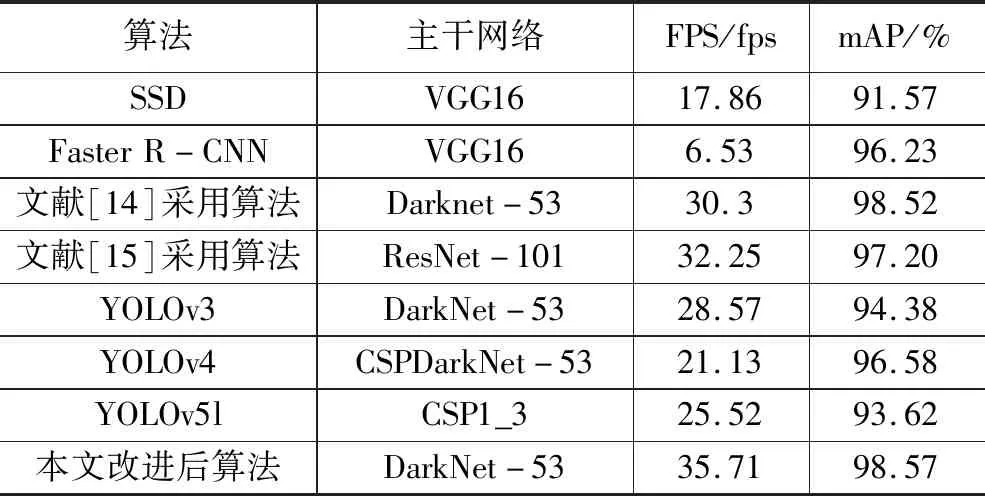
表8 多种算法检测对比结果
4 结束语
针对园区无人车障碍物检测存在的问题,本文提出结合改进YOLOv3和立体视觉的检测方法。实验表明,改进后的模型单张图像检测速度和实时检测帧率均有提升,满足实时性要求;针对阴影及强光照等恶劣环境的漏检情况有较好改善;测距误差稳定维持在厘米级。可见,本文的方法能更好地适用于封闭园区无人车障碍物检测。
在接下来的工作中,将针对存在的问题进一步研究,丰富真实场景数据集和实验平台,继续改进相关算法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
社会科学战线(2022年7期)2022-08-26
汽车实用技术(2022年4期)2022-03-07
动漫界·幼教365(中班)(2020年3期)2020-04-20
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
创新作文(1-2年级)(2019年4期)2019-10-15
好孩子画报(2019年10期)2019-01-10
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
