
基于SR-VGG19的人脸表情识别算法研究*
2021-10-08 13:56杨词慧张杰妹
计算机与数字工程 2021年9期
张 业 杨词慧 张杰妹 蒋 沅
(南昌航空大学信息工程学院 南昌 330063)
1 引言
人脸表情识别是计算机视觉、模式识别和人类情感理解等领域的研究热点之一[1],在人机交互、网络安全、情绪分析、人工智能和智能家居[2]等方面有着广泛的应用。在人脸表情识别中,特征提取是最核心的一个步骤。如何提高表情识别的准确性和鲁棒性,弱化个体差异信息产生的负面影响是人脸表情识别领域亟待解决的关键问题。针对以上问题,本文提出一种基于空间金字塔池化(Spatial Pyramid Pooling,SPP)[3]和改进的区域候选网络(Improved Regional Proposal Network,IRPN)[4]的VGG19网络模型[5](VGG19 network model based on SPP and IRPN,SR-VGG19)用于表情识别。采用IRPN固定窗口代替滑动窗口来避免特征的重复提取,通过结合Dropout[6]和BN[7]策略提高网络模型的泛化能力,并应用SPP方法,增强特征的表达能力。
在表情特征提取方面,研究学者们提出了多种方法。1978年,心理学家Ekman与Friesen[8]提出了面部动作编码系统(Facial Action Coding System,FACS),该系统根据面部特征类型和运动特征定义了基本形变单元。Heikkilä等[9]利用中心对称局部二值模式算法来提取更具判别性的局部二值模式特征,在此基础上利用支持向量机来进行分类。该算法在降低特征维度的同时,有效地提取了局部特征。以上方法虽在一定程度上可以实现人脸表情的识别,但仍存在以下问题:1)人为设计的特征取决于算法的设计,算法设计周期较长,成本相对较高;2)特征提取和分类是两个独立的过程,无法融合到端对端模型,当人为设计的特征出现问题时,之后的表情分类会受到较大的影响。
自2012年Alex[10]提出卷积神经网络之后,许多学者将其应用在人脸表情识别领域,并取得了较好的识别效果。如Nair等[11]提出一种改进的深度置信网络(Deep Belief Network,DBN),在DBN的最顶层加入三阶波尔兹曼机,并在三维物体识别数据库NORB上进行实验,获得了较好的识别效果,例证了DBN可实现优于传统的SVM等浅层模型的分类识别性能。虽然上述基于卷积神经网络的方法可有效提高人脸表情识别的准确率,但浅层神经网络仍存在以下几点不足:1)浅层的神经网络只能学习图像中低层次的简单特征;2)浅层神经网络提取的特征鲁棒性较差。针对上文所提及的人为设计特征提取算法和浅层神经网络算法的不足,本文尝试用改进的深层卷积神经网络来提高表情识别的准确率。
2 SR-VGG19网络模型表情识别算法概述
VGG网络在2014年的ILSVRC定位和分类两个问题上分别取得了第一名和第二名。该网络结构相对较深,通常含有16~19层,本文将重点介绍VGG19网络模型。该模型采用多个3×3的卷积核来代替之前的大尺寸卷积核,并可以多次利用非线性激活层,大大地降低了网络中的参数量,提高网络计算效率。与单一结构的卷积层网络比较,VGG19可以更好地提取图像特征以及提高网络计算效率。但VGG19网络模型限制了输入图片的尺寸大小、泛化能力弱,并且由于网络结构中含有三层全连接层,使网络参数大幅度增加,从而需要占用更大的计算内存,耗费计算资源。针对该网络结构存在的以上不足,本文对VGG19网络模型主要进行以下三个方面改进。
2.1 SPP
由于VGG19网络对输入图片的尺寸有限制,因此在对VGG19网络模型训练之前,需对不符合VGG网络模型的输入图像进行缩放或裁剪处理,但缩放会在一定程度上使图片发生形变,而裁剪可能会导致图像空间信息丢失。针对此问题,本文在VGG19网络中引入SPP方法。SPP通过利用多个不同尺寸窗口对最后一层卷积层提取的特征图进行池化处理,分别将得到的结果进行合并从而得到固定长度的输出。通过SPP可实现任何尺寸的输入,从而解决VGG19网络模型限制输入图片尺寸的问题。SPP是一种多尺度的池化,可以从不同尺度反映图像的特征信息,提高了尺度的不变性;且多窗口的池化操作可提高网络识别的准确率。从某种程度上来讲,通过SPP可以增强图像提取特征的表达能力,进一步提高VGG19网络模型对表情进行识别的准确率。
2.2 Dropout和BN
为了提高网络的泛化能力和鲁棒性,在网络结构的全连接层之前应用Dropout策略。在深度学习网络模型训练过程中,Dropout主要分为两个阶段,即学习阶段和测试阶段。在学习阶段,对隐藏层神经元按一定概率使其从网络中随机失活,以减小训练的网络规模;在测试阶段,采用模型预测平均的方法对整个神经网络输出的概率值进行计算。为避免网络模型在训练过程中出现梯度消失或梯度爆炸等问题,本文在网络的每一卷积层中加入BN方法。通过对每个输入层进行规范化来解决内部协变量转移的问题,以提高网络模型的训练收敛速度。
2.3 IRPN
为进一步提高网络对人脸表情识别的准确率,本文引入了IRPN网络来生成多个候选区域以提高识别精度。RPN是一个基于滑窗的无类别物体检测器,主要用于生成候选区域,用来估计目标物体的位置和大小。该方法在最后一个共享卷积层的卷积特征图上滑动一个小网络,该小网络以输入卷积特征图的一个n×n的滑动窗口作为输入。每个滑动窗口都映射到一个512维特征向量的低维空间,该特征向量被输入到两个同级的全连接层——回归层和分类层。但该方法存在以下两个弊端:1)对于不同尺寸的人脸表情图像,RPN都采用固定尺寸的滑动窗口,因此可能出现窗口尺寸相对于图片尺寸过大或过小的情况,这会限制其在人脸表情识别中的应用。2)滑动窗口会产生较多的窗口冗余,增加了网络的计算量。针对RPN的上述缺点,本文采用IRPN方法,具体的IRPN结构如图1所示,本文采用三种固定尺寸的分割方法,固定尺寸分别为2×2、3×3、5×5,产生的候选框总个数为k×(2×2+3×3+5×5)。使用固定窗口代替RPN中的滑动窗口,即将原固定大小N×N空间窗口变为多尺寸空间窗口的操作,相当于构建了多个RPN网络。并在最后一层的共享卷积层输出的卷积特征图上进行M种固定尺寸图像分割,将划分出来的每个分割窗口映射到K种形状估计,对VGG19网络(512维)的特征向量进行拼接,得到分类层为2K分数和回归层为4K坐标。

图1 IRPN结构
改进后的SR-VGG19网络模型具体结构如图2所示。该网络模型包含5段卷积,共有16个卷积层,对每一卷积层中都进行BN处理,以提高网络模型的收敛速度。每一段卷积,都包含2个~4个卷积层级联,每一段卷积之后都连着最大池化层,以缩小图片的尺寸。在第5段卷积层之后,利用IRPN方法对卷积特征图进行穷举,以获取更多的目标候选框。对不同大小的候选框,经SPP处理之后,生成固定长度的特征。为了避免网络在训练过程中出现过拟合现象,在全连接层加入Dropout。
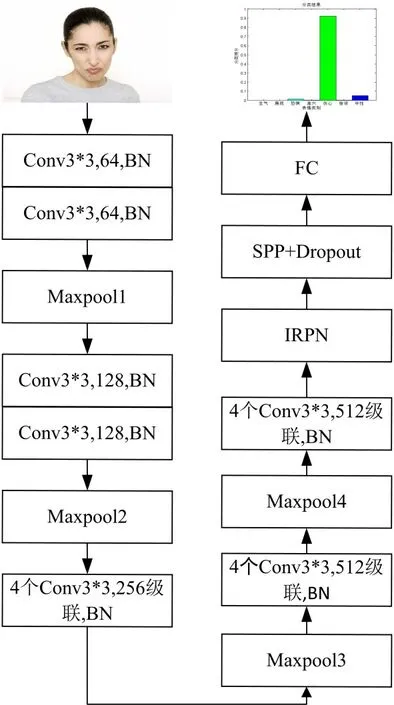
图2 SR-VGG19网络模型结构
2.4 激活函数
在SR-VGG19网络模型中,本文采用常用的Relu激活函数,表达式如下:
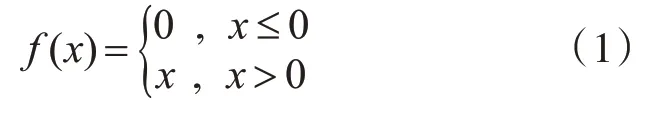
式中x表示神经元的输入。Relu函数是一个分段函数,把所有的负值都变为0,而正值保持不变。这种单侧抑制的作用使得神经网络中的神经元具有稀疏激活性,使网络模型能够更好地挖掘相关特征,拟合训练数据,有效地防止网络梯度消失问题,使得模型的收敛速度处于一个稳定状态。
2.5 损失函数
就分类问题而言,目前较常用的损失函数主要有以下三种:0-1损失函数、均方误差损失函数和交叉熵损失函数。0-1损失函数虽然可以用于衡量误分类问题,但该函数曲线是非凸的,呈现阶跃和不连续现象,在求最优解时较为复杂。均方误差损失函数通过求解数据之间的最小距离平方获得最优解,多用于最小二乘法中。应用于深度学习训练时,其使得多个训练点到最优线路距离最短。均方误差损失函数与Sigmoid激活函数一起使用会导致输出层神经元学习率下降变缓慢。而交叉熵损失函数为对数函数,曲线趋势为单调性,从而使梯度随损失单向变化,有利于梯度下降反向传播,从而可以更好地更新每一层的参数,以缩短预测值和实际值之间的距离。所以本文采用的损失函数为交叉熵损失函数。交叉熵损失函数用来表示预测值和实际值之间的差距,损失函数的值越小,其得到分类结果越准确。具体的表达式如下:
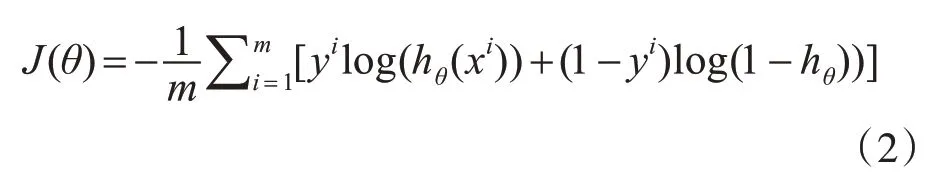
式中,xi表示每一类的数据,yi表示每一类的正确答案,hθ(xi)表示经过SR-VGG19之后得到的预测值,m代表类别个数。
3 实验设计
3.1 数据集
本文实验选用FER2013和CK+表情数据库作为测试数据集。FER2013数据集总共有35887张图片,其中28709张用于训练,其余7178张图片用于测试。FER2013数据集中的每张图片大小均为48×48,并按人物的表情分为七类:生气,厌恶,恐惧,开心,伤心,惊讶,中性,具体如图3所示。

图3 CK+数据集样例图
CK+数据库是在Cohn-Kanade数据集基础上扩展而来的。该数据库包含123个被试对象,共含有593个视频序列,其中118个被试对象具有相应的人脸表情标签,共327个视频序列。
用数字0~6分别表示图像序列中人脸面部的种表情,即0=生气,1=蔑视,2=厌恶,3=恐惧,4=伤心,5=伤心,6=惊讶,具体如图4所示。

图4 CK+数据集样例图
3.2 数据增广
为了防止网络过快地出现过拟合现象,本文对公开的数据集进行增广处理,如图像旋转、翻转、切割、镜像等。在网络的训练阶段,通过对原输入图像的左上角、右上角、左下角、右下角和中心区域进行随机切割,得到的图像尺寸为45×45。并对随机切割后的图像进行随机镜像处理,将处理之后的图像作为输入图像对网络进行训练。在网络的测试阶段,采用均值法减少由于数据处理不当而产生的训练样本异常现象。测试后,对得到的概率取平均值,以减少异常值,降低错误分类。
4 实验结果与对比分析
4.1 SR-VGG19与VGG19对比实验分析
表1是SR-VGG19与VGG19网络模型对人脸表情识别的对比实验结果。从表1中可以看出,本文提出的SR-VGG19网络模型在FER2013公开数据集和私人数据集上的人脸表情识别的准确率均高于VGG19网络模型的准确率,其分别为71.608%和73.168%。这主要是由于SR-VGG19网络模型在VGG19网络模型的基础上,引入了IRPN网络,该网络可以产生更多的目标尺寸,其对于极端的人脸表情图像有很好的识别效果,并且该网络模型可以实现多种尺度表情特征的共享,增强了模型分类识别的能力;同时,采用Dropout和BN结合策略,从一定程度上解决了网络模型在训练过程中出现的过拟合问题,并提高了网络模型的泛化能力。除此之外,由于本文训练数据集图片尺寸为48×48,不符合经典VGG19网络模型对输入图片尺寸224×224的要求,原网络模型需要对输入图片进行裁剪或缩放等处理,导致图像空间信息丢失或形变。因此为解决输入图片尺寸受限同时不丢失原输入图像的空间信息问题,本文在经过IRPN网络之后的卷积特征图应用SPP代替最大池化。应用SPP方法,解决了原VGG19网络模型限制输入图片尺寸的问题,从而提高了网络的泛化性。改进后的网络模型在训练过程中,随着训练次数的增加,人脸表情识别的准确率也随之增加,具体如图5所示。

表1 SR-VGG19与VGG19人脸表情总值别准确率对比实验
4.2 在FER2013数据集上的对比实验分析
表2为2013Kaggle比 赛[12]前 十 名 算 法 和DNNRL、FC3072、CPC方法以及SR-VGG19网络模型对人脸表情识别的准确率。表中前10行是2013kaggle人脸表情识别比赛前十名算法的准确率,11~13行是近些年提出的DNNRL、FC3072、CPC新网络结构模型的识别效果,最后一行是本文提出的SR-VGG19网络模型的准确率。由表2的对比实验结果可知,本文提出的SR-VGG19网络模型在FER2013数据集上对人脸表情的识别率达到73.168%,与以上提出的算法相比较,本文算法的识别率具有明显的优势。主要原因在于本文在原VGG19网络结构基础上,加入BN和Dropout策略,有效地防止了网络过深而出现的过拟合现象,并加快了网络模型的训练收敛速度;同时引入SPP方法有效地解决了VGG19网络对输入图片尺寸的限制问题;且IRPN网络的应用有效地提高了网络的识别精度。从而验证了SR-VGG19网络模型对人脸表情识别的准确性和适用性。
4.3 在CK+数据集上的对比实验
表3给出了不同的方法在CK+数据集上对人脸表情识别准确率的比较结果。因为CK+是一个小样本数据集,样本量小且容易产生过拟合,因此本文采用Dropout和BN策略解决过拟合问题。为了验证本文算法的有效性,利用10次交叉验证方法,即将数据集分为10份,每次选8份作为训练集,两份作为测试集。从表3的对比结果可以看出,本文提出的SR-VGG19网络模型的准确率均优于以上对比实验方法,其准确率达98.990%。该网络模型在CK+数据库上测试的过程中,随着测试次数的增加,准确率也随之增加,具体如图6所示。由表2和表3的对比实验结果可知,本文提出的同种网络模型应用在不同的数据集上,识别率有较大的差距。其主要原因是由于CK+数据集是在实验环境下获取,且该数据集经过了增广处理,图像质量相对较高,所以在该数据集上进行人脸表情识别准确率较高。

表3 在CK+数据集上的对比实验

图6 SR-VGG19在CK+测试的准确性
4.4 测试实例
为了进一步验证SR-VGG19网络模型对人脸表情识别的准确性。基于已训练好的网络模型,本文随机选取10张测试图片分别对已训练好的SR-VGG19网络模型进行测试。其具体的测试过程主要包含以下几部分。首先,将待测试的图片输入SR-VGG19网络,经过该网络的前向传播得到其相应的预测值;然后,利用交叉熵损失函数计算实际值与预测值之间的距离;最后,通过反向传播更新网络模型每一层的参数。图7给出了其中两张测试图片的具体测试结果。第一张测试图片经过SR-VGG19网络模型的识别分类,得到的七种分类结果概率值分别为生气97.82%、蔑视0%、恐惧0.35%、高兴0%、伤心1.48%、惊讶0%、中性0.35%,其中生气的表情概率最高,即97.82%,与测试图片表情一致,故表情类别为生气。第二张测试图片经过SR-VGG19网络模型的识别分类,得到的七种分类结果概率值中,伤心表情的概率值最高,即为96.37%,其次中性表情概率值为3.28%,而生气、蔑视、恐惧、高兴、惊讶这五种表情概率值接近于0%。故得到对应的表情类别为伤心,与测试图片表情一致。其余8张图片也均达到了96.28%以上的识别准确率。
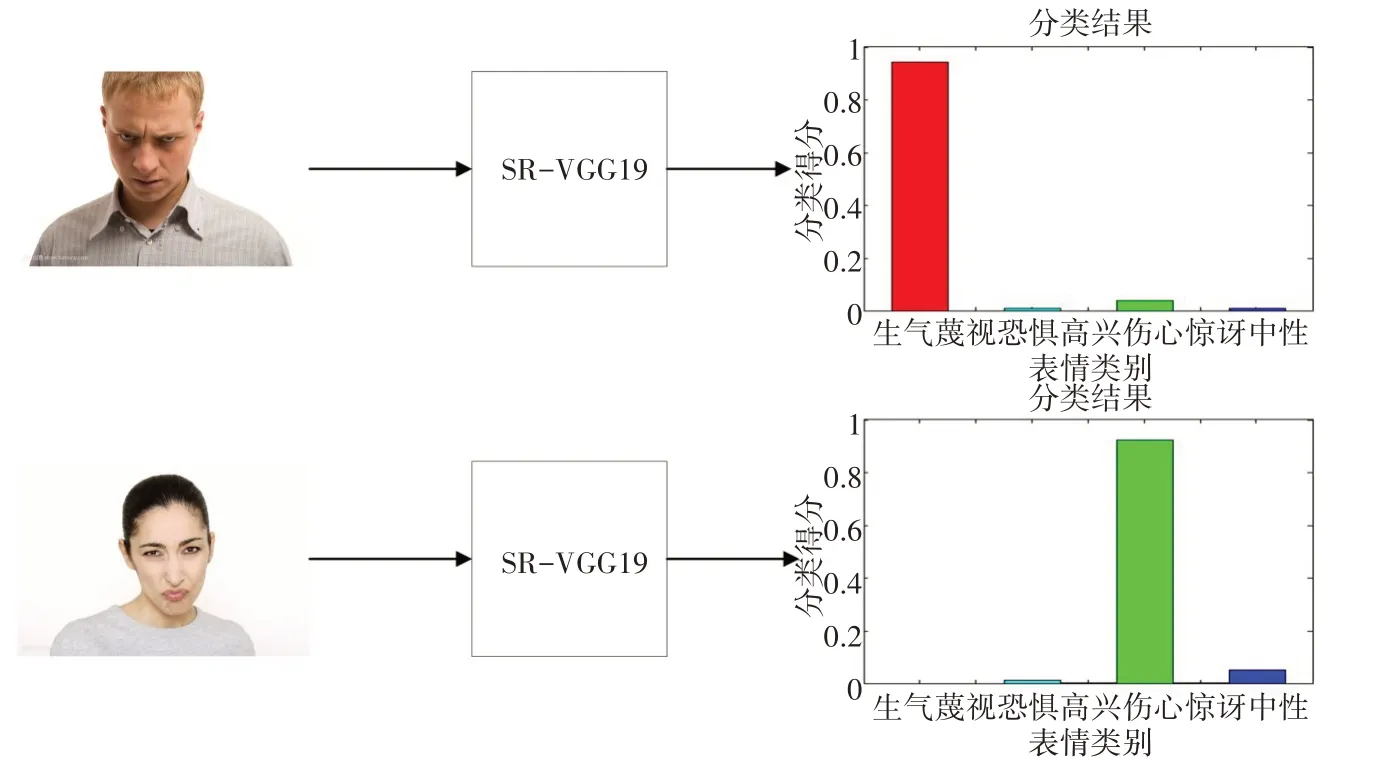
图7 测试实例
5 结语
本文提出了一种改进的SR-VGG19网络模型,采用SPP方法,解决了VGG网络模型限制输入图片尺寸的问题,同时增强了图像提取特征的表达能力。在网络结构最后一层卷积层之后,引入IRPN方法,使用固定窗口代替滑动窗口对卷积特征图进行穷举,以获取更多尺寸的候选框。在网络的训练过程中,使用Dropout方法,来避免网络出现过拟合现象。实验结果表明,本文提出的SR-VGG19网络模型可以有效地对人脸表情进行分类,并取得较好的识别效果。本文提出的网络模型虽有效地提高了人脸表情识别的准确率,但对于某些人脸表情,如伤心、难过的识别率还有待提高。其原因主要有以下两点:1)用于网络训练的数据集太少,且许多难以区分的表情数据及相对应的标签数据也相对较少,故需要增加大量的训练样本,以提高网络的鲁棒性。2)伤心和难过的表情差异在现实生活中也是难以区分的。因此本文下一步将针对该问题设计子网络结构或集成多个网络模型,并对初始特征进行特征融合,以期进一步提高人脸表情识别的准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
奥秘(2021年5期)2021-06-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小雪花·初中高分作文(2017年9期)2018-05-21
