
基于随机森林算法的塔式起重机安全事故预测及致因分析
2021-10-08 08:57张建荣薛楠楠赵挺生
安全与环境工程 2021年5期
张建荣, 张 伟, 薛楠楠, 赵挺生
(华中科技大学土木与水利工程学院,湖北 武汉 430074)
塔式起重机作为主要的建筑工程施工起重设备,对提高作业人员的劳动效率、加快施工进度具有不可替代的作用。但由于塔式起重机的安装、使用和拆卸过程均存在较大的危险性以及施工现场安全管理不到位等原因,近年来塔式起重机安全事故频发,造成了较大的人员伤亡和财产损失。其主要原因:一方面是作业人员存在侥幸心理,认为塔式起重机安全事故都是一般事故,较大事故发生的概率极低;另一方面是各单位对塔式起重机安全事故类型认识不足,未制订有针对性的应急预案。因此,借鉴以往发生的塔式起重机安全事故报告和相关数据,采用可行的预测方法对塔式起重机安全事故等级和类型进行预测,可为制定塔式起重机安全监控监测方案和隐患排查治理提供依据,将有助于降低塔式起重机安全事故发生的概率和危害后果。
塔式起重机安全事故预测的本质是一个分类问题,常用的分类模型有逻辑回归(Logistics Regression,LR)、K近邻(K-Nearest Neighbor,KNN)、决策树(Decision Tree,DT)、多层感知器(Multilayer Perceptron,MLP)等模型,在面对高维特征的小数据集时,这些分类器训练得到的模型泛化能力有限。而集成学习(Ensemble Learning,EL)通过集成基分类器获取更优的预测结果,且对类别不平衡数据集的分类问题预测更准确。随机森林(Random Forest,RF)算法是一种基于多棵决策树和装袋(Bootstrap Aggregating,Bagging)算法的集成学习模型,通过并行集成基学习器降低过拟合的风险,目前在很多领域得到了广泛的应用。如徐绪堪等构建了洪涝灾害突发事件分类的随机森林模型,以为全过程应急管理提供支撑;刘睿等将随机森林算法应用于巫山县滑坡易发性区划,结果表明随机森林算法具有较高的准确性和稳定性;李文娟等将随机森林算法应用于强对流潜势预测和分类,结果发现该算法对大范围强对流天气进行预测的准确率高;周德红等利用随机森林算法来计算各指标对分类效果的权重,并分析得出了液化天然气储运企业泄漏事故的主要原因;卢彬等以空气中污染物浓度数据和同期气象数据构建随机森林模型用来预测银川市空气质量,结果表明其预测精度达到了88.03%。
上述研究表明,随机森林算法善于处理不同领域的分类问题,但在建筑工程安全领域的研究与应用还较少。为此,本文采用随机森林算法构建塔式起重机安全事故预测模型,对该事故等级和类型进行预测,主要包括:①塔式起重机安全事故致因的系统分解;②构建基于随机森林算法的塔式起重机安全事故预测模型;③采用实际发生的塔式起重机安全事故数据,对塔式起重机安全事故等级和类型进行模拟预测;④识别塔式起重机安全事故的关键致因。该研究结果可为塔式起重机安全隐患排查和应急预案制定提供依据,以便预防塔式起重机安全事故的发生和提高塔式起重机作业安全水平。
1 塔式起重机安全事故致因的系统分解
塔式起重机安全的影响因素众多,且一向是国内外学者研究的热点。如Shapira等采用专家访谈法对塔吊使用阶段的安全影响因素及其影响程度进行了研究;丁科等从项目条件、气候环境、人为因素、安全管理和其他因素五个方面建立了塔式起重机安全事故风险因素清单,并结合案例分析了不同风险因素发生的概率;Tam等采用问卷调查和结构化访谈方法对塔式起重机安全事故进行了研究,发现影响塔式起重机安全的主要因素是人的行为,包括从业者安全教育培训不足、工作疲劳和责任感等;Marquez等通过对两起塔式起重机安全事故进行深入分析,发现塔式起重机基础不稳固是导致其安全事故发生的主要原因之一;赵挺生等运用系统思想研究了塔式起重机安全,提取了56项塔式起重机安全影响因素,并建立了广义的塔式起重机安全AcciMap模型。
在上述研究基础上,依据《塔式起重机安全规程》(GB 5144—2006)、《建筑起重机械安全监督管理规定》(建设部令第166号)、《建筑施工塔式起重机安装、使用、拆卸安全技术规范》(JGJ 196—2010)和《建筑施工安全检查标准》(JGJ 59—2011)以及塔式起重机安全管理相关的法律、安全技术标准和规范,参照Rasmussen的社会技术系统层次模型,将塔式起重机安全事故致因系统分解为项目安全管理(P
)、现场人员管理(H
)、塔吊设备管理(M
)和环境管理(E
)4个子系统和21个因素,如图1所示。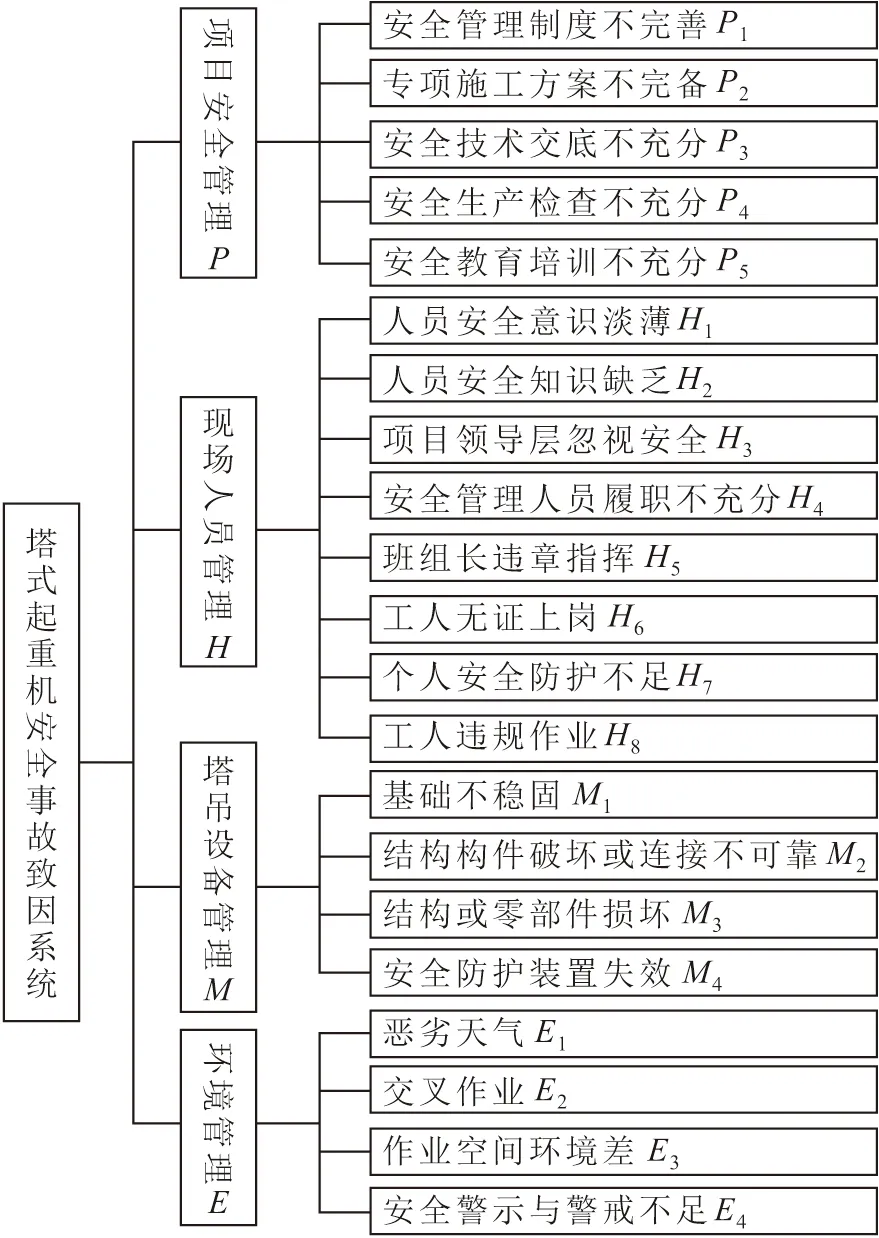
图1 塔式起重机安全事故致因系统Fig.1 Tower-crane safety accident cause system
该系统同时考虑事故致因之间的横向和纵向影响关系,如人员安全意识淡薄(H
)会导致同子系统的个人安全防护不足(H
),安全生产检查不充分(P
)会导致异子系统的工人违规作业(H
)。这种子系统间以及因素间的关联,是确保预测塔式起重机安全事故等级和类型准确性的不可缺少的条件。2 基于随机森林算法的塔式起重机安全事故预测模型构建
2.1 数据预处理
从国家应急管理部、各地应急管理局和相关网站,搜集得到我国2013—2019年间发生的194起塔式起重机安全事故的详细事故调查报告,其中有111起安全事故发生在近三年内,反映当前我国塔式起重机安全管理形势不容乐观。依据《生产安全事故报告和调查处理条例》规定的生产安全事故等级划分标准,194起塔式起重机安全事故均为一般安全事故或较大安全事故,其中一般安全事故占事故总数的比例为84.54%,较大安全事故占事故总数的比例仅为15.46%。根据塔式起重机安全事故的特点,将其进一步归纳为坍塌、物体打击、脱钩、意外高坠、构件坠落、碰撞和触电7种事故类型,如图2所示。其中,坍塌事故不仅发生频率最高,而且在较大安全事故中的占比最高,因此其危害最大。
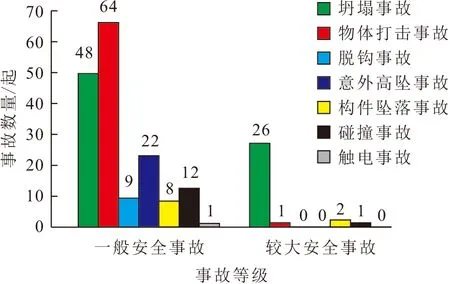
图2 塔式起重机安全事故类型和等级数量分布Fig.2 Distribution of tower-crane safety accident types and levels
通过阅读事故报告,将塔式起重机安全事故致因系统中各影响因素的发生情况、事故等级、事故类型作为样本数据,并进行数据化处理,见表1。塔式起重机安全事故致因系统的21项影响因素属于无序分类变量,若某项因素发生,则将其量化值记为“1”,否则记为“0”;事故等级为无序分类变量,若该事故为一般安全事故,则记为“0”,若该事故为较大安全事故,则记为“1”;事故类型也为无序分类变量,记事故类型为坍塌和物体打击的事故为“1”和“2”,因脱钩、碰撞等事故类型数量较少,所以与意外高坠事故归为一类,记为“3”。

表1 塔式起重机安全事故样本数据的数据化处理Table 1 Data sample processing of tower-crane safety accidents
将194份塔式起重机安全事故调查报告中数据进行数据化处理,转化为194条数据记录,再随机划分为训练集和测试集,并确保两份数据集中3种不同事故类型均有分布。其中,训练集数据记录为164条,包含24条较大安全事故和140条一般安全事故;测试集数据记录为30条,包含6条较大安全事故和24条一般安全事故。为了提升最终预测结果的准确性,通过SMOTE法来降低训练集中类别的不平衡性,即通过人工合成将较大安全事故数据记录扩充为140条,最终训练集包含280条事故数据记录。
2.2 随机森林算法
随机森林(RF)算法由Breiman于2001年提出,是一种集成学习模型,它是在以分类与回归树(Classification and Regression Trees,CART)为基学习器、融合装袋(Bagging)算法的基础上,在树的训练过程中引入随机特征选择,降低了样本的相关性,从而解决了单棵决策树模型的过拟合问题,使得模型具有良好的噪声容忍度。随机森林算法即CART决策树与Bagging算法相结合,其流程如图3所示。
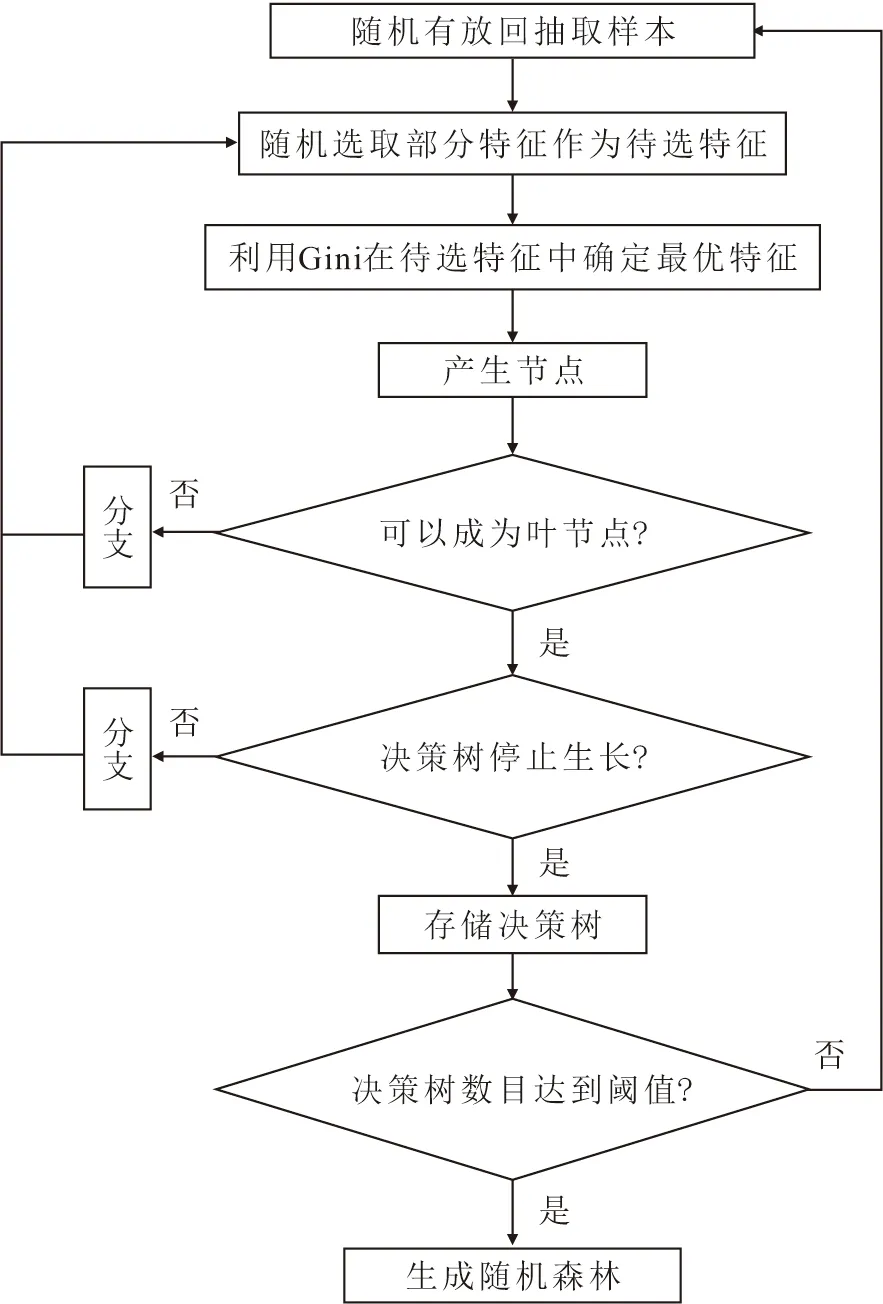
图3 随机森林算法流程图Fig.3 Flow chart of random forest algorithm
Bagging算法以降低结果的方差来避免过拟合的发生,它通过有放回的抽样方法在原始数据集进行m
轮抽样,得到新数据集Q
(i
=1,2,…,m
),新数据集中存在重复的数据。对于某条数据,每轮被采集到的概率为1/m
,如公式(1)所示,每轮随机采样,训练集大约有36.8%的数据未被采集,这些数据未参加训练集模型的拟合,称为“袋外数据”,可作为验证集测试模型的泛化能力。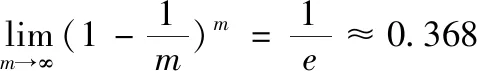
(1)
决策树学习采用自顶向下的递归方法,其基本思想是以信息熵为度量构造一个熵值下降最快的树,分类与回归树以基尼系数作为特征分裂依据,在分类问题中,假设有K
个类别,第k
个类别的概率为p
,则概率分布的基尼系数为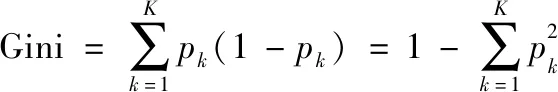
(2)
对于给定的样本集合Q
,其基尼系数为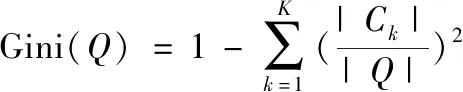
(3)
式中:C
为样本集合Q
中属于第k
类的样本子集;K
为类别的数量。样本集合Q
可根据特征A
是否取某一可能值a
被分割成Q
和Q
两部分,即Q
={(x
,y
)∈Q
|A
(x
)=a
}(4)
Q
=Q
-Q
(5)
式中:(x
,y
)表示样本集合Q
中的一个样本,其中x
表示样本的特征值,y
表示样本的标签。则在特征A
的条件下,样本集合Q
的基尼系数定义为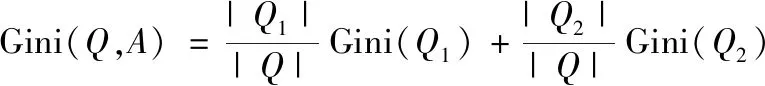
(6)
基尼系数Gini(Q
)表示样本集合Q
的不确定性,基尼系数Gini(Q
,A
)表示在条件A
=a
分割后样本集合Q
的不确定性,且基尼系数越小,模型不纯度越低。基于随机森林算法的塔式起重机安全事故预测模型构建过程如下:
(1) 从280条塔式起重机安全事故数据记录中随机有放回地抽取样本,得到决策树S
(i
=1,2,…,m
)。(2) 从决策树S
随机选取21项特征中的部分特征,以基尼系数最小化准则进行最优分割点筛选,直到满足停止分裂条件。(3) 每一棵树都能进行一次预测,最终的分类结果取m
棵决策树输出结果的众数。2.3 模型准确度评价
混淆矩阵(Confusion matrix)可被用来描绘塔式起重机安全事故的真实属性与预测结果之间的关系,是评价分类器性能的一种常用方法。对于事故的分类预测,训练集中每类事故等级或事故类型分别含有D
个数据(i
=1,2,…,N
),采用随机森林算法构造分类器,可得到N
×N
维混淆矩阵: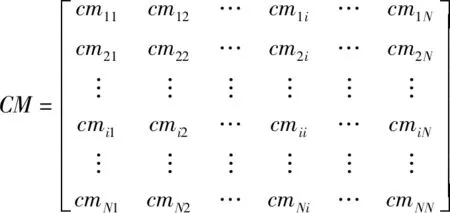
(7)
式中:cm
表示第i
类被分类器判断成第j
类的概率。然后引入准确率Accuracy、精准率Precision、召回率Recall和F1-score作为评价指标,对模型预测的准确度进行评价,具体评价指标的计算公式如下:
准确率Accuracy的计算公式为

(8)
类别i
的精准率Precision的计算公式为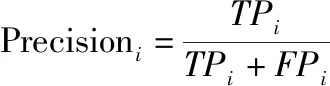
(9)
类别i
的召回率Recall的计算公式为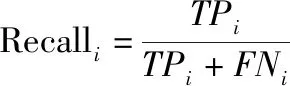
(10)
F1-score综合了精准率和召回率的产出结果,其值越高代表模型的输出结果越好,其计算公式为
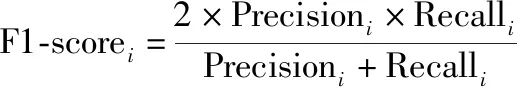
(11)
上式中:TP
表示被正确预测为第i
类的数量;TN
表示被正确预测不为第i
类的数量;FP
表示被错误预测为第i
类的数量;FN
表示被错误预测不为第i
类的数量。3 实证分析
本文以Jupyter Notebook为实现平台,利用Python的Scikit-learn开源机器学习模型库建立基于随机森林算法的塔式起重安全事故预测模型,通过对原始数据进行预处理并对模型参数进行调整,对模型预测结果的准确率进行评价,并与MLP、KNN、DT分类算法进行对比发现,随机森林算法在处理塔式起重机安全事故等级预测的二分类问题上的准确率较高(见表2)。考虑到较大事故的高危害性,除准确率外,其余3项指标的计算均以较大事故的预测结果为依据进行计算。采用随机森林算法可进一步预测塔式起重机安全事故类型,得到各因素影响权重,通过混淆矩阵对预测结果进行评价。
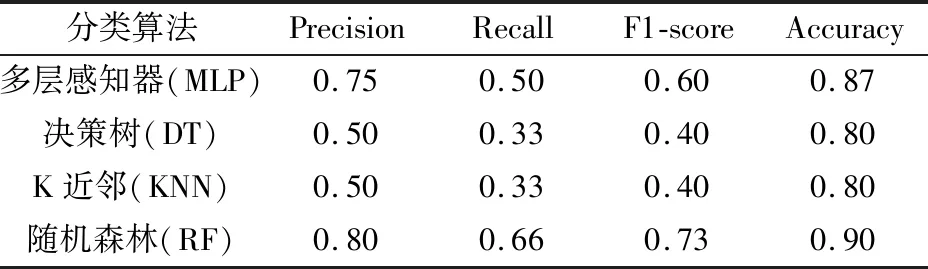
表2 不同分类算法对塔式起重机安全事故等级预测的准确率Table 2 Accuracy of tower-crane safety accidents’ level prediction based on different classification algorithms
3.1 塔式起重机安全事故等级预测
随机森林算法是基于Bagging框架的决策树模型,因此随机森林的参数择优包括RF框架参数择优和决策树参数择优,本文利用网格搜索法对塔式起重机安全事故等级预测时的最佳参数进行调优,见图4。
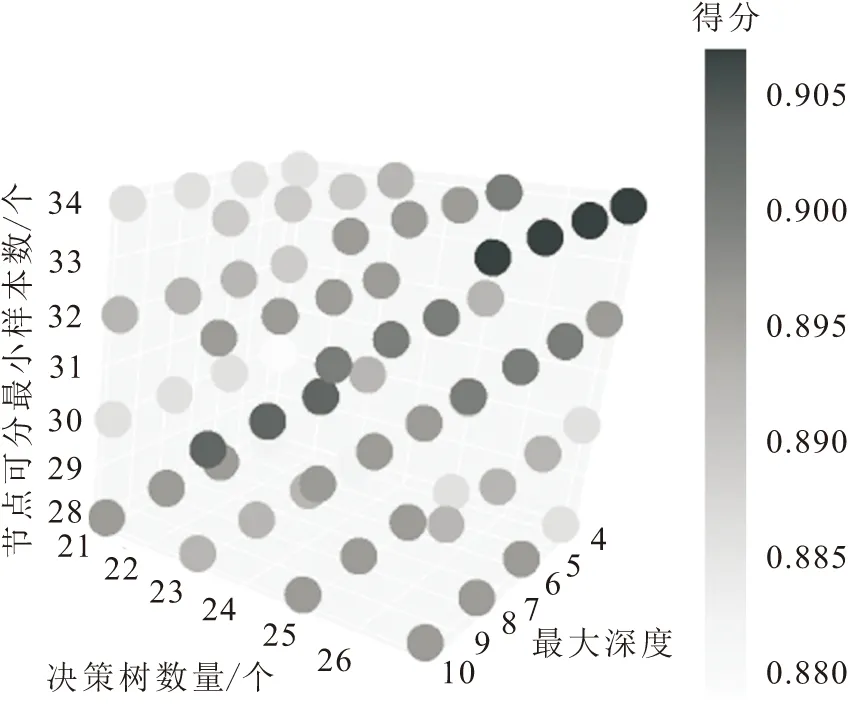
图4 网格搜索三维可视化图Fig.4 Three-dimensional visualization of grid search
由图4可见,当基于随机森林算法的塔式起重机安全事故等级预测模型的决策树数量为26个、最大深度为4、节点可分最小样本数为34个时,模型袋外准确率得分最高,训练模型达到最优。
为了验证随机森林算法分类模型的优越性,调用30份塔式起重机安全事故数据记录作为测试集,其中较大安全事故6份、一般安全事故24份,再分别利用DT、MLP、KNN、RF算法进行分类预测,并比较其预测结果,各分类算法的分类预测结果用混淆矩阵表示,见图5。由于较大塔式起重机安全事故往往会造成更多的人员伤亡和财产损失,所以较大事故预测的准确度越高越好。

图5 不同分类算法对塔式起重机安全事故等级预测的混淆矩阵Fig.5 Confusion matrix of tower-crane safety accident level prediction based on different classification algorithms
由图5可见:随机森林算法表现最优,24份一般安全事故中有23份预测正确,6份较大安全事故中有4份预测正确;其他分类器虽然预测一般安全事故较为准确,但预测较大安全事故的错误率高,因此整体准确率不如随机森林算法。
3.2 塔式起重机安全事故类型预测
随机森林算法在分类问题上具有较高的准确性和稳定性,因此本文采用与第3.1节相同的测试集在训练好的随机森林模型上进行测试,此时基于随机森林算法的塔式起重机安全事故类型预测模型的决策树数量为61个。基于随机森林算法的塔式起重机安全事故类型预测的混淆矩阵,见图6。
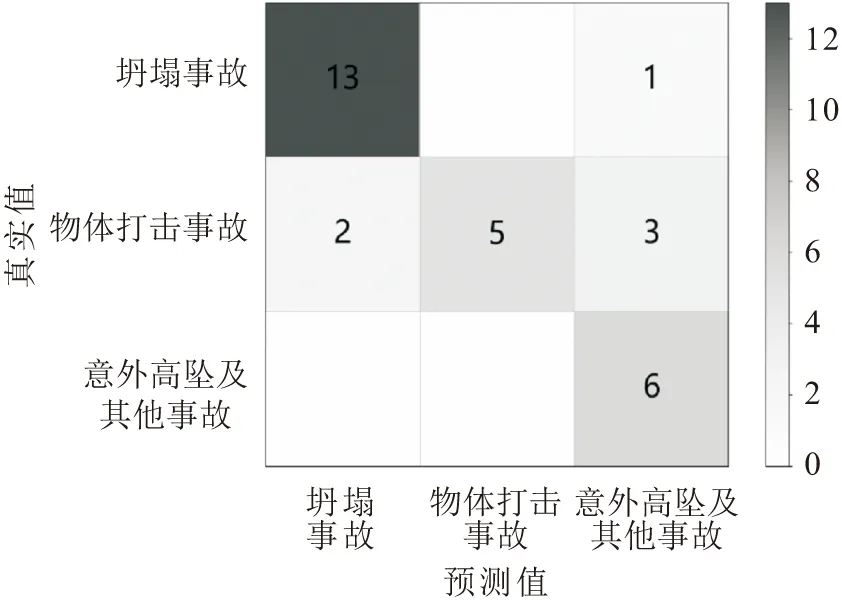
图6 基于随机森林算法的塔式起重机安全事故类型预测的混淆矩阵Fig.6 Confusion matrix of tower-crane safety accident type prediction based on Random Forest (RF)
由图6可见:14份坍塌事故中有13份预测正确,1份误预测为意外高坠及其他事故;10份物体打击事故中有5份预测正确,2份误预测为坍塌事故,3份误预测为意外高坠及其他事故;6份意外高坠及其他事故全部预测正确。
采用公式(8)~(11)计算各个事故类型的准确率、精准率、召回率和F1-score,其结果见表3。
由表3可知,随机森林算法模型在预测坍塌事故和意外高坠及其他事故时表现较好,召回率分别为0.93和1,所有事故类型预测的准确率为0.8,总体上达到较高水平。
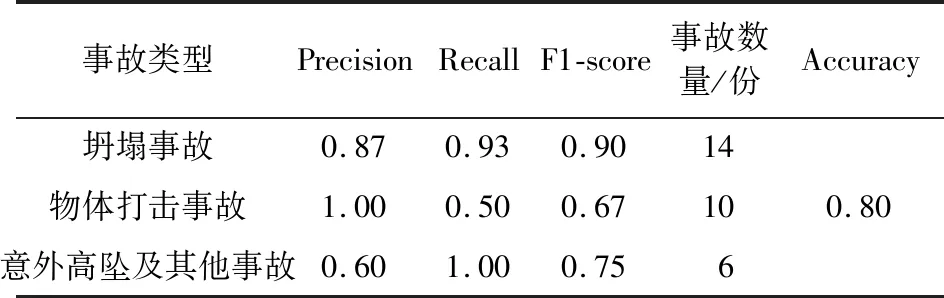
表3 基于随机森林算法的塔式起重机安全事故类型预测的准确率Table 3 Accuracy of tower-crane safety accidents’ type prediction based on Random Forest (RF)
3.3 塔式起重机安全事故致因影响权重计算
塔式起重机安全事故致因影响权重计算是对事故后果的反演,通过对导致事故发生的各影响因素的分析,推演事故发生过程和解析事故的因果关系,以建立事故预警机制,进行安全防范。采用随机森林算法算法对导致塔式起重机安全事故因素的影响权重进行计算的流程如下:
(1) 对于基于随机森林算法的塔式起重机安全事故预测模型中的决策树S
,使用相应的袋外数据计算其袋外数据误差,记为E
1。(2) 随机对袋外样本中某一特定塔式起重机安全事故影响因素X
加入噪声干扰,再次计算其袋外数据误差,记为E
2。(3) 假设随机森林中有m
棵树,记因素X
的影响权重为I
,其计算公式为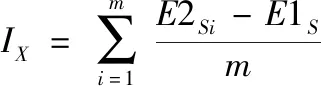
(12)
采用公式(12)分别计算影响事故等级和事故类型的各因素的权重并降序排列,其结果见表4。
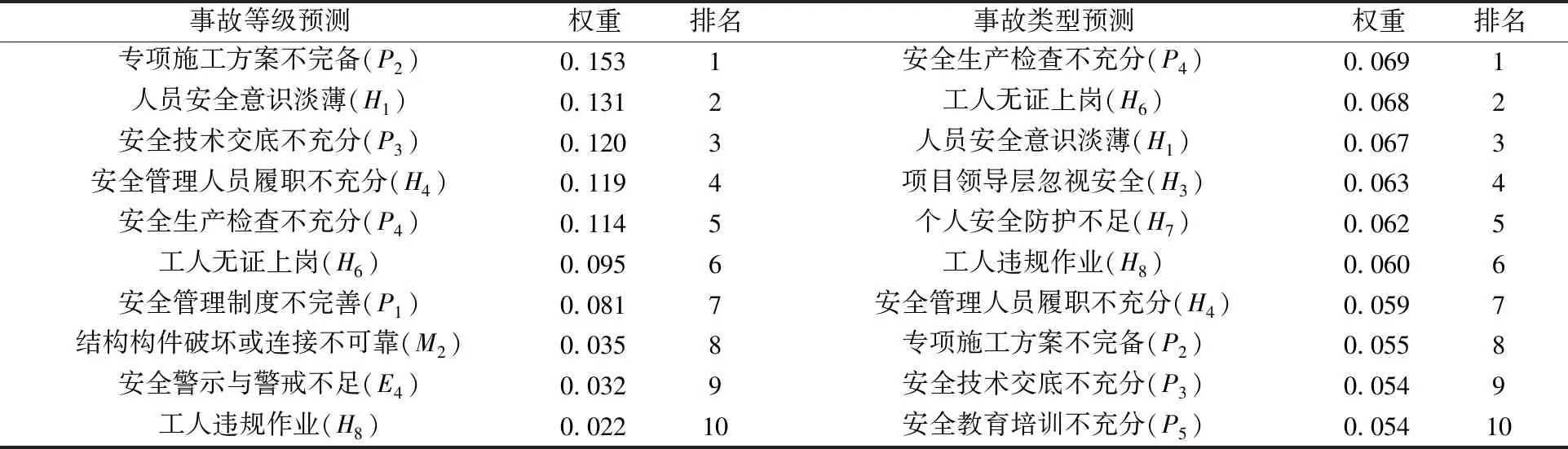
表4 塔式起重机安全事故致因影响权重Table 4 Weight of influence of tower-crane safety accident causes
由表4可知:对塔式起重机安全事故等级影响权重最大的3个因素分别为专项施工方案不完备(P
)、人员安全意识淡薄(H
)、安全技术交底不充分(P
);对塔式起重机安全事故类型影响权重最大的3个因素分别为安全生产检查不充分(P
)、工人无证上岗(H
)、人员安全意识淡薄(H
)。除去重复的影响因素,共得到5个关键因素。3.4 案例分析
2018年5月17日海南省五指山市某工地在塔式起重机拆卸时发生坍塌较大事故,造成4人死亡,直接经济损失达663万元。经调查分析,引发事故的原因有专项施工方案不完备(P
)、安全技术交底不充分(P
)、安全生产检查不充分(P
)、项目领导层忽视安全(H
)、安全管理人员履职不充分(H
)、工人无证上岗(H
)、结构构件破坏或连接不可靠(M
)。将该事故报告经数据化处理后输入基于随机森林算法的塔式起重机安全事故预测模型中,经由决策树根节点逐层判断至叶节点可得到预测结果,见表5。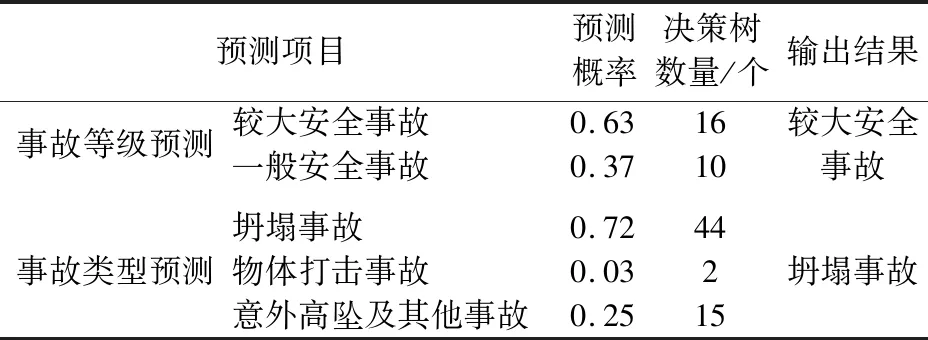
表5 基于随机森林算法的塔式起重机安全事故案例预测结果Table 5 Prediction results of a tower-crane safety accident case based on Random Forest (RF)
由表5可知:基于随机森林算法的塔式起重机安全事故等级预测模型中共有26棵决策树,其中10棵预测为一般安全事故,16棵预测为较大安全事故;基于随机森林算法的塔式起重机安全事故类型预测模型中共有61棵决策树,其中44棵预测为坍塌事故,2棵预测为物体打击事故,15棵预测为意外高坠及其他事故。根据相对多数投票法,模型对该起案例的事故等级和类型的预测结果与实际情况基本一致,从而验证了模型的有效性和实用性。
4 结论与建议
(1) 基于系统思维和Rasmussen管理框架,将塔式起重机安全事故致因系统分解为项目安全管理、现场人员管理、塔吊设备管理和环境管理4个子系统和21个因素。
(2) 以194份塔式起重机安全事故报告为数据样本,构建了基于随机森林算法的塔式起重机安全事故预测模型,经计算得到随机森林算法对塔式起重机安全事故等级和类型预测的准确率分别为0.9和0.8,高于MLP、KNN、DT等单一分类器。
(3) 采用随机森林算法对导致塔式起重机安全事故因素的影响权重进行计算,得到5个关键因素为专项施工方案不完备(P
)、安全技术交底不充分(P
)、安全生产检查不充分(P
)、人员安全意识淡薄(H
)和工人无证上岗(H
)。(4) 以某塔式起重机较大坍塌事故为例对模型进行验证,发现模型对该案例事故等级和类型的预测均正确,且5个关键因素中有4个因素在本案例事故中出现,与因素影响权重的计算结果高度吻合。
(5) 在今后的研究中需细分塔式起重机安全事故21个致因因素,加大对塔式起重机安全事故致因的研究深度,进一步扩大研究样本,并建立具备实时存储、编辑等功能的塔式起重机安全事故数据库,以提高事故等级和类型预测结果的准确性。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
科学与信息化(2019年28期)2019-10-21
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
科学与财富(2016年32期)2017-03-04
少儿科学周刊·少年版(2015年3期)2015-07-07
金点子生意(2014年4期)2014-04-10
决策与信息·下旬刊(2013年1期)2013-03-11
