
K-means++算法优化及其在地震前兆分析中的应用研究
2021-10-05 12:54苏倸玉
智能计算机与应用 2021年5期
苏倸玉,李 忠,朱 婷,张 伟
(防灾科技学院 应急管理学院,河北 燕郊065201)
0 引 言
K-means++算法是2007年由David Arthur和Sergei Vassilvitskii提出的,是K-means算法的改进版本。传统K-means算法的聚类效果以及运行时间在很大程度上受到初始聚类中心选择的影响,Kmeans++算法对此进行了改进。虽然K-means++算法在初始化簇中心时,增加了计算量,但在整个聚类过程中,能够显著地提升计算效率和改善聚类结果误差[1],被广泛应用于分类[2]、聚类[3-4]等领域。
但是,由于K-means++依旧存在难以确定合适的K值问题,可能导致聚类结果会产生局部最优解。基于此,本文针对K值难于确定的问题,采用3种方法联合确定最佳的聚类中心个数,从而改进Kmeans++算法,并将优化算法应用于地震地磁数据聚类分析中。
1 K-means++聚类算法
经典的K-means算法是无监督的聚类方法[5],具有简单、高效、易于实现等特点。局部搜索能力较强,且对于大数据样本空间的聚类有较高的效率[6],在数据聚类分析领域应用广泛[7]。但是,Kmeans也存在2个致命缺点:一是K值多以使用者的经验来确定,因此存在很大的主观性,在不同应用场景使用时造成很大困扰;二是初始值采用随机选取方式,可能造成算法收敛速度较慢、计算效率较低的问题。
基于上述问题,有学者提出了K-means++算法。在初始值选取时,采用样本点与中心点的距离作为概率值,距离越远则被选中的概率越大,距离越近则概率越小,从而有效解决了上述第二个问题。
K-means++聚类算法实现步骤如下:
(1)从样本集X中随机选择一个初始聚类中心点,加入到聚类中心集C中;
(2)遍历样本集,计算每一个样本点xi与已存在聚类中心点ck的距离dis(xi,ck),选取最短距离D(xi),如式(1)所示:
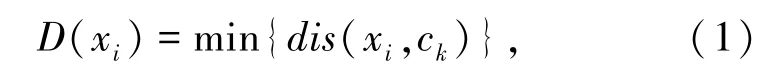
依次计算每个样本点的概率,如式(2)所示:
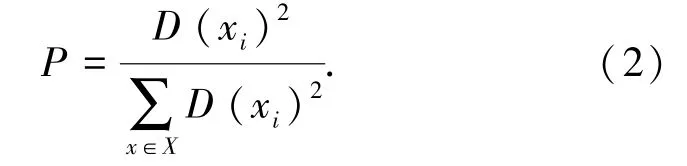
其中,P为一个样本点xi被选中为聚类中心的概率;D(xi)代表一个样本点xi到已有聚类中心的最短距离;代表所有样本点到每个已存在聚类中心的最小距离的平方和。选择概率最大的样本点作为下一个聚类中心点,直至找到K个初始聚类中心;
(3)以各个簇内样本点的中心点更新聚类中心,得到K个新聚类中心;
(4)计算各样本点到K个中心点的距离,按照最短距离归属原则归类,形成K个新类;
(5)重复步骤(3)、(4)直到聚类中心点不变或者达到迭代次数结束计算,并记录最终的K个聚类中心点和簇内数据。
2 K-means++算法改进
从上述介绍可见,K-means++算法解决了Kmeans算法的初始中心选择问题,但对K的选择依然没有改变思路。为解决这个问题,本文采用拐肘法(Elbow Method)、轮 廓 系 数 法(Silhouette coefficient)和Calinski-Harabaz指标法(CH)联合确定K值。
2.1 拐肘法
拐肘法的核心思想,是通过计算各个K值时的畸变程度,画出畸变程度与K值的关系图,找出拐点。畸变程度就是每个簇的质点与簇内样本点的均方差。一个簇畸变程度的高低,表明簇内成员的松散程度高低。随着K值的增大,到达拐点后,畸变程度会得到很大改善,下降幅度趋于平缓,此时这个拐点就可以考虑为聚类性能较好的点,可以确定其对应K值作为聚类个数,如式(3)所示:

其中,SSE是畸变程度;ci代表第i个簇;p是ci中的样本点;mi是ci的质心,即ci中所有样本的均值。
利用拐肘法获得的K值记作K1。
2.2 轮廓系数法
轮廓系数(Silhouette Coefficient)是由Kaufman等人提出的一种用来评价算法聚类质量的有效性指标。该指标结合了凝聚度和分离度,不仅用以评价聚类质量,还可用来获取最佳聚类数[8]。假设样本集X包含n个样本点x1,x2,....,xn,将样本集分为K个簇,每个样本点的轮廓系数如式(4)所示:
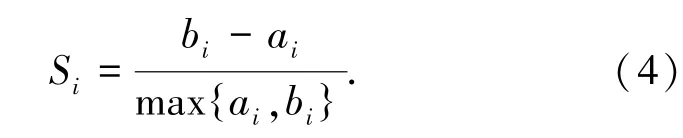
其中,Si为第i样本点的轮廓系数;ai是样本点i到其所属簇中所有其它点的平均距离;bi为样本点i到其它簇中所有点的最小距离。Si介于[-1,1],接近-1则说明样本点i更应该分类到另外的簇,接近0则说明样本i在2个簇的边界附近,越趋近于1则聚类效果越优。
所有点的轮廓系数求平均,得到最终的平均轮廓系数。对于现有的分类数,求取轮廓系数的最大值Sk,与之对应的K值就是最佳聚类数[9]。
利用轮廓系数法获得的K值记作K2。
2.3 CH指标法
CH指标由分离度与紧密度的比值得到[10]。假设数据集被划分为K个类,CH指标计算如式(5)所示:
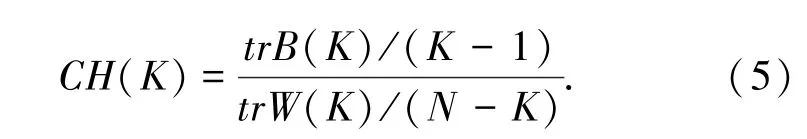
其中,N为数据集总样本数;K为类别数;tr表示对矩阵求迹,即矩阵主对角线元素之和;B(K)为类别之间的协方差矩阵;W(K)为类别内部数据的协方差矩阵。
CH越大代表类内越密集,类间越分散,聚类结果性能越好,对应的K值也是最优的聚类数。利用CH指标法获得的K值记作K3。
2.4 联合法确定K值
从上述3种求K值的算式和求取过程可以看出:拐肘法实际上计算聚类的最小距离,理论上距离越小越好,但聚类个数太多就失去意义了。因此,K值是在下降率突然变缓时刻的值,认为此时聚类效果最佳。轮廓系数法强调的是簇内部凝聚度最大、簇间分离度最大时聚类效果最佳,符合客观实际,其值域在[-1,1],越靠近1说明对应的K值越佳。CH指标法实质上要求类别内部数据的协方差越小越好,类别之间的协方差越大越好,类似于轮廓系数法,而且指标值越大,对应K值的聚类效果越佳。
鉴于3种方法从不同的角度求取K值,因此本文将3种方法获得的K值综合求取平均值,即:
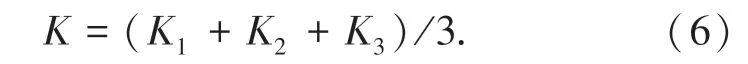
依据四舍五入原则确定最终的K值,这样求取的K值既兼顾了簇内集中簇间分散的要求,又兼顾了距离最小原则,达到最优聚类结果。
3 地震地磁前兆数据分析
聚类分析方法在地震监测、地震裂缝分布预测[11]等地震数据分析领域应用较多,能够从大量的地震数据中获取规律性的知识,避免了不同学者的主观性问题。地震地磁前兆数据,是地震台站通过地磁仪长期观测到的时间序列数据,单位为奥斯特。根据地震学家的研究结果表明,在地震前1个月内,震中一定范围内会出现地磁异常变化。因此可以通过长期的观测并通过数据挖掘方法搜索离群点,从而发现地震发生前期地磁变化,为地震预测带来可能。
3.1 数据来源及预处理
本次实验数据选取2008年1~6月份四川省成都市的地震地磁前兆数据。由于地磁前兆数据存在数据缺失、非标准化等问题,需要进行插值、整理、规范化处理等预处理操作,以保证数据的可用性。缺失数据采用均值法补齐,规范化采用z-score标准化方法进行完成,并去掉量纲。经过处理的数据符合标准正态分布,按照时间排列构成标准化的数据集。
3.2 计算结果与分析
首先以拐肘法、轮廓系数法和CH指标法分别计算K1、K2和K3值,如图1所示。
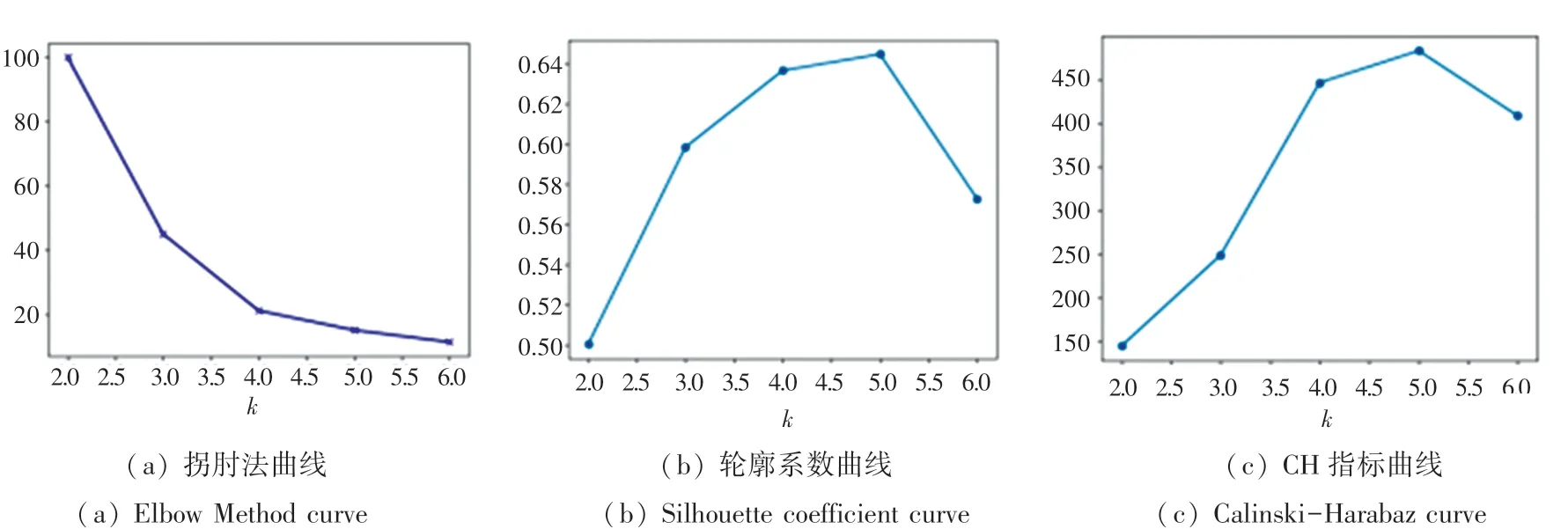
图1 不同算法求得K值折线图Fig.1 Line graph of K-value by different algorithms
根据聚类性能标准评估原理,从图1(a)的拐肘法得到K1值为4,从图1(b)的轮廓系数法得到K2值为5,从图1(c)的CH指标法得到K3值为5。
其次求取平均值作为最优K值,K=(4+5+5)/3=4.7≈5。因此K=5是最佳的聚类类别个数,此时可以达到最好的聚类效果,计算结果如图2所示。
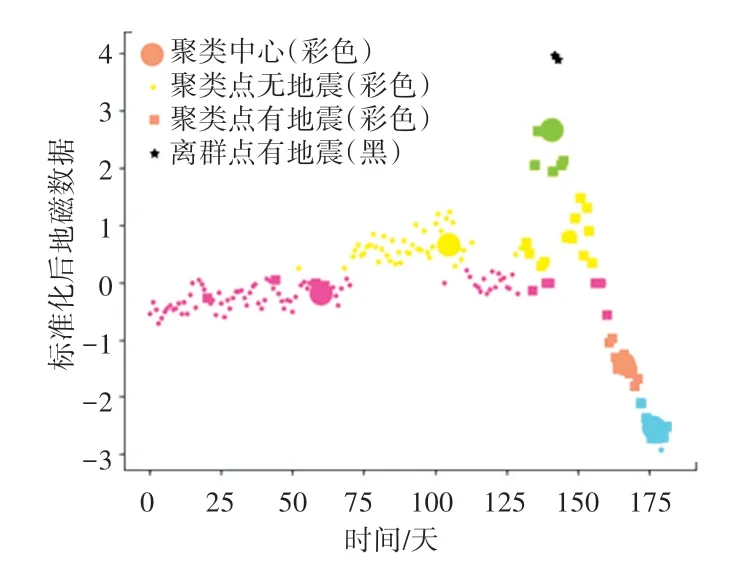
图2 K-means++的聚类结果Fig.2 Clustering results of K-means++algorithm
由图2可见,存在5个聚类中心。即图中大圆点,检测到2个异常点,即图中五角星,正好与2次地震对应。详尽信息见表1。

表1 两次地震情况Tab.1 Details of two earthquakes
作为对比,同样以K=5作为聚类数,利用传统K-means算法对成都地震地磁前兆数据进行聚类分析,结果如图3所示。

图3 K-means的聚类结果Fig.3 Clustering results of K-means algorithm
从图3可知,传统K-means聚类方法没有找到异常离群点。实际上,在实验过程中,K-means聚类方法因初始聚类中心选择的随机性问题,该方法难以发现离群点,并且每次计算结果差异较大。这也说明,同样的K值下,K-means++聚类方法比Kmeans方法效果更好。
4 结束语
文中在介绍了K-means++算法基础上,通过拐肘法、轮廓系数法和CH指标法联合求取K值,优化了K值的确定方法,从而很好地解决了K-means++聚类算法中K值难以确定的问题。利用改进后的K-means++聚类算法对2008年1~6月份四川省成都市的地震地磁前兆数据进行聚类分析,发现了2个离群点,正好与发生的2次地震相对应,效果明显优于传统K-means结果。得到结论如下:
优化后的K-means++聚类算法优于传统Kmeans算法,K-means++聚类算法可以较好地解决地震地磁的聚类问题。通过离群点检索可以发现可能发生的地震,对地震监测预报工作具有重要的现实意义。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
电脑报(2020年12期)2020-06-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电脑报(2019年4期)2019-09-10
时代英语·高一(2019年5期)2019-09-03
新课程·小学(2019年1期)2019-03-18
电子技术与软件工程(2016年23期)2017-03-06
大众摄影(2015年9期)2015-09-06
大灰狼(2009年7期)2009-08-26
舒适广告(2008年9期)2008-09-22
