
基于深度学习的韩国语文本情感分类
2021-10-05 12:47:26赵天锐
智能计算机与应用 2021年5期
赵天锐
(战略支援部队信息工程大学 洛阳校区,河南 洛阳471000)
0 引 言
情感分析本质上属于文本分类任务,是以文本中包含的情感倾向为标准,对文本进行分类。随着计算机和互联网的不断发展,对海量文本信息进行处理、分析后得出信息中的情感分布成为可能。对社交媒体、新闻评论等进行情感分析后得到的结论,也可以进一步应用在舆情分析、观点挖掘等领域当中。
传统情感分析方法分为基于情感词典的方法和基于机器学习的方法,两种方法各有所长。而随着深度学习技术的持续进步,提出了将深度学习和词向量相结合,引入情感分析领域的研究方法。目前在自然语言处理领域,词向量是具有代表性的语义分布式表示方式,其中具有代表性的是Word2Vec[1]和FastText[2]。但是,目前大部分相关研究都是基于英文、中文等通用语。而对韩语而言,无论是韩国国内学者还是国际学者,对韩语情感分析的研究成果较少。因此,本文利用网络爬虫,爬取韩语影评语料形成语料库,使用FastText方法训练词向量,而后使用多个深度学习模型进行对比实验,寻找适合韩语的情感分析模型。进而提出融合卷积神经网络和双向长短时记忆网络,并加入Self-Attention机制的韩语情感分析模型,并在自建的韩语数据集上证明了该模型的有效性。
1 相关研究
情感分析最早是由Pang等[3]于2002年提出的概念。近来,深度学习因在自然语言处理任务中逐渐显露出优越的性能[4],受到越来越多的关注。由于基于深度学习的方法可以使模型从数据中自行学习语言特征,该方法与传统机器学习算法相比通常能取得更好的效果。由于文本的数据结构较为稀疏且长度较大,为了能实现对文本的处理,需要较好的文本特征提取方式,而其中影响力最大的就是词嵌入(Word Embedding)。Milokov等提出的Word2Vec是词嵌入的代表性方法,该方法可以利用上下文信息得出各单词之间的相关性,最终以高维向量的形式将这种相关性展现出来。因为词嵌入的出现,之前被认为缺乏实用性的神经网络算法再次受到关注,并且这种算法也被应用于情感分析任务,收到了较好的效果。文献[5]中提出了可以捕捉文本序列信息的循环神经网络(RNN)。而针对RNN学习长期依赖困难的问题,学界相继提出了长短期记忆网络(LSTM)和双向长短期记忆网络(Bi-LSTM)。这些模型通过在隐藏层增加3种“门”结构,控制神经元的状态,也提高了情感分析的准确度。此外,在图像处理方面展现出优越性能的卷积神经网络(CNN)也被用来解决情感分类任务[6]。在Attention注意力机制提出后,Bahdanau等首先将其应用到机器翻译领域。实验结果证明效果高于传统的神经网络模型。于是,很多专家学者将其应用在文本分类任务中,也收到了较好的验证效果。尤其是引入Attention机制的BiLSTM模型,可以达到很高的准确率。
上述研究方法大多已应用于通用语的情感分析,韩国国内和国际学者以韩语文本为研究对象也进行了一定的探索。文献[7]中对韩语文本进行分词,训练词向量,而后运用CNN进行文本分类;文献[8]则在进行词嵌入后使用RNN进行分类。此外,结合韩语本身的语言特征,文献[9]完成了以音节为单位,对文本进行预处理的研究;文献[10]则以音素为单位,研究文本的预处理方案;文献[11]中是先通过比较试验,选出了单词、音节、音素中最适合进行韩语文本预处理的单位,而后提出了双向堆叠的Bi-LSTM模型,在电影评论数据集中达到约88.95%的准确率。而Lee[12]以购物评论为对象进行分析,结合不同用户群体评论中的关键字特征,提高了神经网络模型的效率。
2 融入自注意力机制的Bi-LSTM+CNN模型结构
2.1 文本预处理和向量化表示
2.1.1 文本预处理
2.1.2 文本的向量化表示
文本向量化是指将文本的分词结果用词向量进行表示。本文采用的向量化表示方法是Facebook提出的一种高效的浅层网络——FastText。FastText和Word2Vec中的CBOW原理相似,整个模型有输入层、隐藏层和输出层。两个模型的输入都是用向量表示的单词,隐藏层都是多个词向量的叠加平均,输出都是特定的Target。FastText和CBOW区别在于:
(1)前者输入的是多个单词及其n-gram特征,而后者输入的是目标单词的上下文;
(2)前者输入的特征经过嵌入层,后者输入的特征经过独热编码;
(3)前者输出的是对应文档类型的标签,而后者输出的是目标词汇。FastText利用h-softmax的分类功能,通过对分类树所有叶子节点的遍历,寻找概率值最大的标签。本文采用Python语言编写Gensim库中的FastText模型,对构建的语料库中文本进行10 000次迭代后,得到由该模型训练的词向量。
借助FastText输出的词向量,可以更清楚地看到单词间语义的亲疏关系。衡量词义远近关系的标准是余弦相似度,余弦相似度越大则单词间的联系越紧密。在影评语料中与“”关联度最高的10个词见表1。
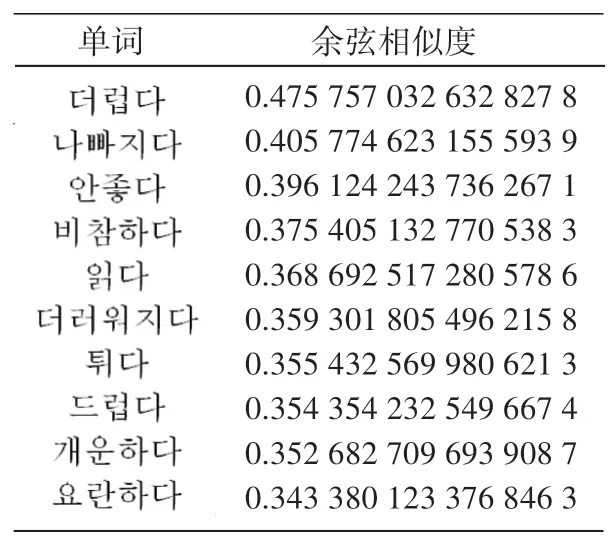
表1 词向量语义相似度Tab.1 Word Vector Semantic Similarity
2.2 卷积神经网络
卷积神经网络最初应用于计算机视觉领域中的图像分类、目标检测、图像语义分割等任务,是一种包含卷积计算的前馈神经网络。后经实验发现,其用于文本分类中也可以得到较好的效果。经典的卷积神经网络包括输入层、卷积层、池化层、全连接层和输出层。其中,卷积层对输入的特征进行特征提取;池化层对提取过后的特征进行下采样以减少运算量,提高运行效率,得到局部最优值;池化层后是全连接层和输出层;为了防止出现过拟合,还要加入Dropout操作,最终通过分类器进行分类。卷积神经网络结构如图1所示。
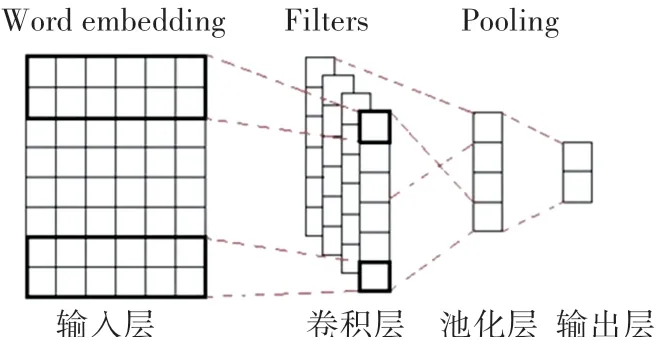
图1 CNN结构图Fig.1 CNN Structure
本文中将CNN的卷积核大小设置为(3、4、5),每个大小相同的卷积核的通道数设置为2。这样CNN可以分别提取词汇在原句中的3-gram、4-gram和5-gram特征。
2.3 双向长短时记忆网络
1997年Hochreiter等针对循环神经网络(RNN)的梯度消失和梯度爆炸等问题,首次提出了长短时记忆网络(LSTM)。与原来的RNN相比,LSTM加入了“门”结构来控制信息的传递,较好地解决了文本的长距离依赖问题。LSTM主要包含输入门(it)、遗忘门(ft)、输出门(Ot)与一个记忆单元(Ct).具体结构如图2所示。

图2 LSTM内部结构图Fig.2 LSTM Structure
最初提出的LSTM模型在处理自然语言时,只考虑了上文的语义信息而忽略了下文信息,为了弥补这个缺陷,可以使用双向长短时记忆网络(Bi-LSTM)模型。Bi-LSTM通过构建对齐的双层LSTM模型,同时进行自前向后和自后向前传播模型。Bi-LSTM模型包含了输入层、前向传递层、后向传递层和输出层。本文使用的Bi-LSTM结构如图3所示:

图3 Bi-LSTM模型结构Fig.3 Bi-LSTM Structure
为充分考虑文本的上下文信息,准确提取文本的特征,将预处理过的每条短文本表示为向量形式后,作为Bi-LSTM网络的输入。假设:输入内容X={x1,x2,…,xt},X是每条短文本中所有单词向量组成的句向量,每个xi(i=1,2,…,t)是单个词向量。前向传递层和后向传递层分别用于学习上下文的文本信息,同时连接到输出层。Wi1、Wi2分别为输入门到前向单元和后向单元的权值矩阵,Wf1、Wf2分别为前向和后向传递层隐含单元遗忘门的权值矩阵。Wo1、Wo2分别为前向和后向传递层到输出门的权值矩阵。本文中的Bi-LSTM接受词向量作为输入,最终输出值由前向传递层和后向传递层共同学习到的语义信息组成。如将这句话输入到模型当中,分词后得到,而后3个单词的词向量会输入网络,前向传递层会得到3个向量{hf0,hf1,hf2},后向传递层也会得到3个向量{hb0,hb1,hb2}。将前后传递层的最后一项输出进行拼接,可以得到[hf2,hb2],将该向量作为输入接入全连接层,可以进行文本情感分类。
2.4 自注意力机制
注意力机制的出现最早是为解决计算机视觉领域的问题,Google Mind在循环神经网络的基础上,添加了注意力机制处理图像分类任务。随后Bahdanau等[13]将Attention机制引入自然语言处理领域,实现了在机器翻译任务中翻译和对齐同时进行。2017年,Google机器翻译团队大量使用了自注意力(Self-Attention)机制,并在不同的自然语言处理任务上进行实验,取得了良好的效果。自注意力机制的基本结构如图4所示。

图4 Self-Attention基本结构Fig.4 Self-Attention Structure
Google团队在发布的论文中提出放缩点积Attention机制(scaled dot-Product attention),其实质是在原本使用点积进行相似度计算的Attention基础上,除以一个标准尺度起到调节作用。这可以防止Q和K的点积结果过大,然后通过softmax操作将注意力得分归一化为概率分布。注意力机制的得分计算如式(1):

2.5 融入自注意力机制的Bi-LSTM+CNN模型
本文采用融入自注意力机制的Bi-LSTM+CNN模型,作为韩国语情感分析模型。模型整体架构如图5所示。

图5 融入自注意力机制的Bi-LSTM+CNN模型结构Fig.5 ATT-Bi-LSTM+CNN Structure
本文建构的神经网络模型,利用Bi-LSTM和CNN分别对输入的词向量进行特征提取并进行组合,而后通过词语关联度的注意力机制对组合后的特征进行进一步的优化,将优化后的特征作为全连接层的输入,以完成情感分类任务。该模型的优势在于将Bi-LSTM和CNN的优势进行有机结合:前者关注与文本语境相关的特征,后者关注局部特征,从而对文本信息的捕捉更加全面。这种网络对传统单一神经网络存在的问题,如:忽略词汇上下文语义信息,梯度消失和梯度离散等能起到一定的缓解作用。注意力机制的引入让神经网络在进行分类时,能给予情感关键词更高的权重,有助于情感分类。
3 实 验
本文在预处理过的文本上使用FastText模型训练词向量,而后将所得词向量输入Bi-LSTM+CNN模型,进行迭代训练后输出预测的情感标签。实验环境见表2。

表2 实验环境Tab.2 Lab Environment
3.1 实验数据

表3 实验数据样例Tab.3 Sample Experimental Data
3.2 评价标准
本文采用准确率(Precision)、召回率(Recall)和F1-score3种通用的国际标准,对各种实验模型进行评估。其中,准确率指被正确分类的样本占总体样本的比例;召回率是被正确分类的样本占此类样本的比例;F1-score是当a=1时的准确率和召回率的调和均值。3种评价标准的计算公式见表4。公式中各项数据的含义见表5。

表4 实验评价标准计算公式Tab.4 Experimental Evaluation Standard Calculation

表5 混淆矩阵Tab.5 Confusion Matrix
3.3 模型参数
实验参数的设置要经过多轮实验调整才能得到良好的效果。在本文进行的实验中,首先要在数据集上使用FastText训练词向量,然后利用训练的词向量进行情感分类。经过多次对比实验,结合数据集的实际状况,最终设置的FastText模型参数见表6;在得到词向量后要利用其进行情感分类,本文提出了融入自注意力机制的Bi-LSTM+CNN模型,最终设置的模型参数分别见表7和表8。

表6 FastText模型参数设置Tab.6 FastText Model Parameters

表7 CNN参数设置Tab.7 CNN Model Parameters

表8 Bi-LSTM参数设置Tab.8 Bi-LSTM Model Parameters
3.4 实验结果与分析
为证明模型的有效性,在自建数据集上将经典的情感分类算法和本文提出的融入自注意力机制的Bi-LSTM+CNN模型进行对比实验。为控制变量,实验采用的词向量皆为在数据集中通过FastText模型训练得到的词向量。
(1)CNN模型:CNN模型注重局部特征,在自建韩国语文本数据集上取得的效果较差;
(2)LSTM模型:LSTM与传统的循环神经网络相比,加入了“门”机制,可以部分解决梯度爆炸和梯度离散问题;
(3)Bi-LSTM模型:Bi-LSTM模型可以提取文本上下文相关的全局特征,相较于单向的LSTM模型分类效果有所提升;
(4)ATT-CNN模型:应用注意力机制的卷积神经网络可以缩短训练时间,同时通过注意力机制弥补了捕捉信息的不足;
(5)ATT-Bi-LSTM模型:在Bi-LSTM模型中加入了Self-Attention机制。先利用Bi-LSTM网络提取文本序列的信息,而后借助Self-Attention机制对关键词给予更多权重;
(6)ATT-Bi-LSTM+CNN模型:本文提出的模型,先使用Bi-LSTM和CNN网络分别提取文本的上下文和局部特征,而后经过Self-Attention优化进行情感分析的算法。
本文算法与其它算法在自建数据集上的表现见表9。
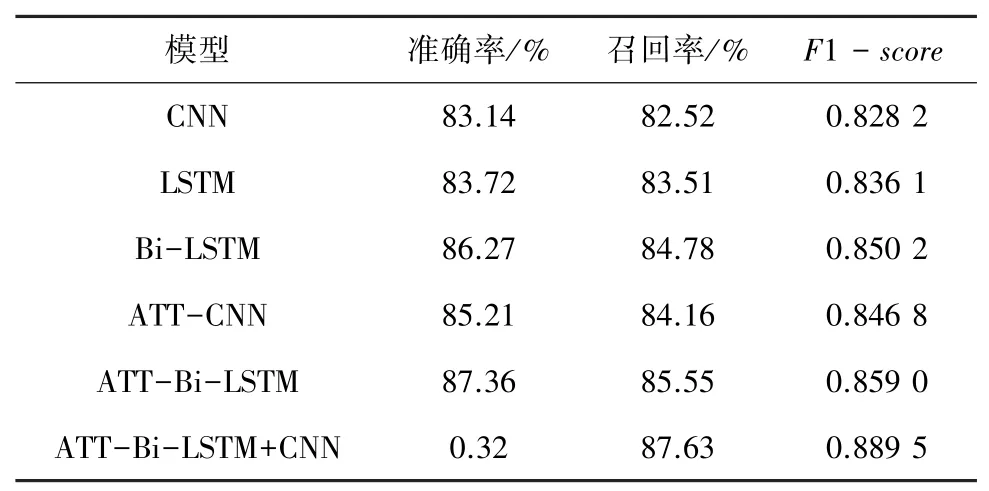
表9 不同模型评价标准对比Tab.9 Comparison of Different Models
通过表(9)的数据,可以得到如下结论:
(1)通过对比LSTM和Bi-LSTM的数据,双向模型更好地考虑上下文的信息,在自建数据集上的表现较单向模型更优;
(2)分别对比CNN与ATT-CNN、Bi-LSTM和ATT-Bi-LSTM的数据可知,在原有的模型中增加注意力机制,可以有效地实现对文本中重点信息的关注,从而提升模型的表现。CNN加入注意力机制后准确率、召回率和F1-score的值分别提升了2.08%、1.64%和0.0186;Bi-LSTM则分别提升了1.09%、0.77%和0.008 8。
(3)通过对比ATT-CNN、ATT-Bi-LSTM和ATT-Bi-LSTM+CNN的效果可知,相比于单一的CNN和Bi-LSTM,两者提取特征的组合更能在上下文语境信息和局部特征两方面取得平衡。本文提出的模型在数据集上取得了较好的效果,准确率、召回率和F1-score均高于其它模型,证明了本文提出算法的有效性。
4 结束语
本文提出了融入自注意力机制的Bi-LSTM+CNN韩国语短文本情感分析模型,使用FastText模型训练词向量。综合利用CNN和Bi-LSTM关注局部特征和提取上下文语境信息的优势。为证明模型有效性,本文设计了对比实验,结果显示本文提出的模型在自建数据集中取得了优于其他算法的效果,证明了模型的有效性。
然而本文在处理文本时,只考虑了上下文信息,并未充分利用韩国语的词性、音素等语言学特征,因此未来可以考虑在分类时加入此类特征,观察其对分类结果的影响。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
韩国语教学与研究(2020年4期)2020-05-17 00:48:36
韩国语教学与研究(2020年3期)2020-03-17 08:08:08
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
西江文艺(2015年6期)2015-05-30 23:51:45
韩国语教学与研究(2014年2期)2014-10-17 01:35:56
