
基于机器学习模型的制造业企业信用评级研究
2021-10-04 20:07:23王灿华
债券 2021年9期
王灿华
摘要:本文基于可得数据,采用特征工程方法提取影响信用资质的核心因素,并将其作为自变量构建制造业企业信用违约預测的Logistic回归模型和信用评分卡。实证结果显示,企业性质、销售费用/营业收入、流动资产周转率、带息债务/全部投入资本等六个指标对违约概率影响显著。通过建立机器学习模型评级和外部评级之间的映射表,有望实现风险企业排雷、信用价值挖掘、信用风险定价等功能。
关键词:机器学习特征工程 制造业企业信用评级
得益于大数据和非结构化数据处理技术的发展,基于大数据的机器学习模型应用日益广泛。机器学习算法是根据特征对事物进行分类,本质上是降熵过程。企业信用评级是利用不同的信用评分或评级对样本进行分类,进而实现将企业违约概率从等概率分布转换为非等概率分布。非等概率的熵低于等概率的熵,信用评级降熵可用于评价企业信用资质。从功能和目标的角度看,将机器学习模型应用于企业信用评级具有一定优势,但需要以大数据为基础,以保证学习效果和参数估计准确,避免过拟合。考虑到难以具备海量企业样本数据,在建模时,使用有较少参数估计需求的Logistic回归算法更为合适。为减少变量共线性对模型估计的影响,笔者采用特征工程方法提取信用资质驱动核心因子入模。从行业看,制造业企业违约样本数居行业之首,负样本数量相对充足。将特征工程和机器学习方法应用于制造业企业信用评级在技术和数据方面具有较好的可行性。
指标选取、数据来源及特征工程
在样本选择方面,笔者选择证监会行业分类标准下的制造业,训练正样本为截至2021年一季度末有存量债券、未发生违约事件且评级在A级以上的企业主体,共682家;负样本为2014—2019年发生违约事件或者评级在BBB级及以下的企业主体,共56家。正负样本之比约为12:1。将外部评级为BBB级及以下的企业视为负样本基于两方面考量:一是BBB级以下属投机级,违约风险较高,考虑到外部评级实行发行人付费模式,为审慎起见,将正负切分线上调至BBB级;二是多数金融机构限制准入外部评级在A级及以下的债券,认为BBB级及以下债券的违约风险较高。
在观察期和表现期选择方面,考虑到债券市场的价格敏感度高于评级公司跟踪评级以及真实违约消息,笔者将债券估值偏离度大于10%、评级低于A级、首次违约等三个事件发生之前作为样本企业观察期,将观察期数据作为Logistic回归自变量数据。观察期之后为表现期,将表现期违约与否作为因变量数据。
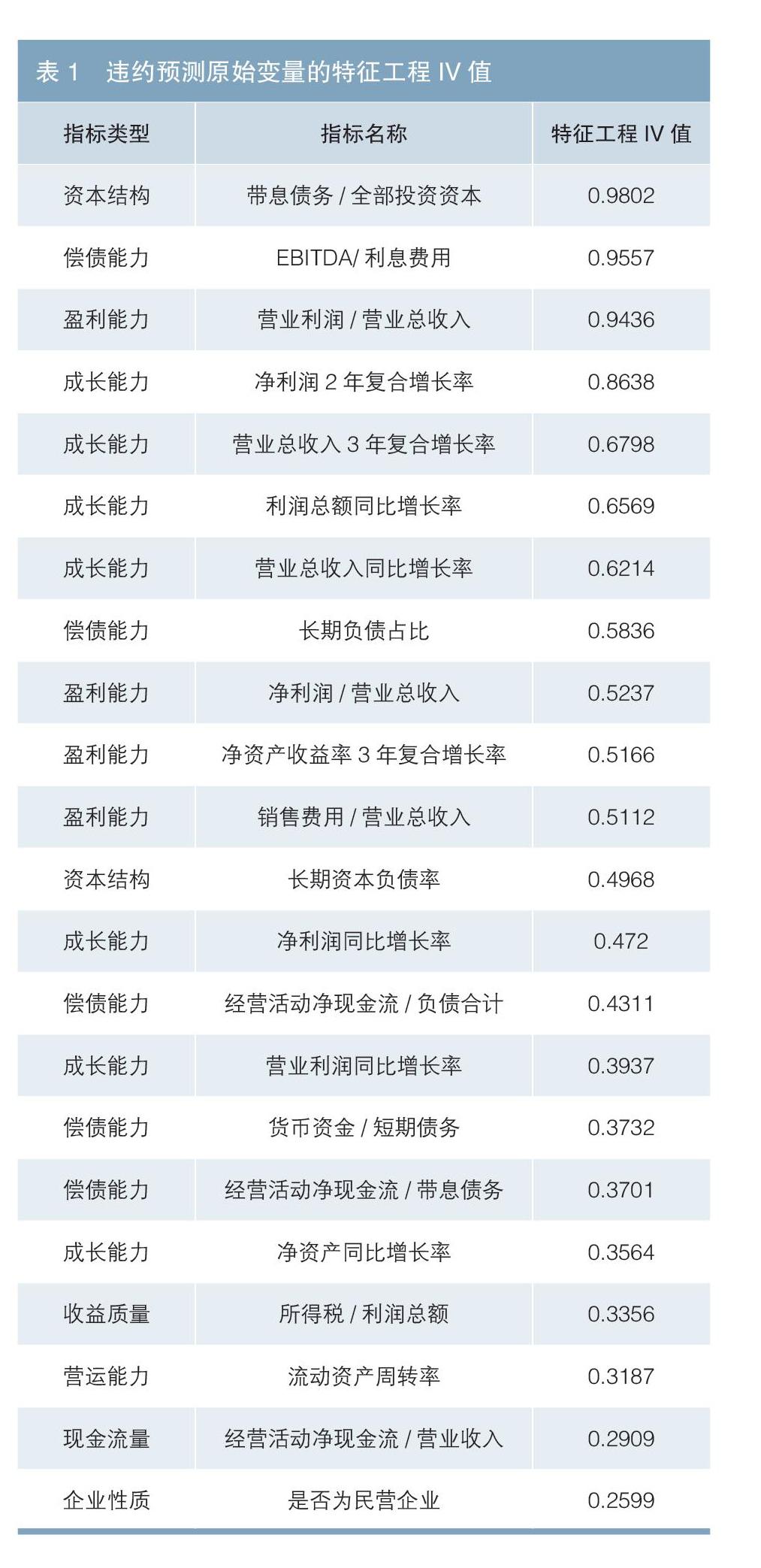
为客观地基于机器学习模型预测制造业企业违约情况,需构建信用资质影响因子矩阵。考虑到信用债发行主体样本总量相对有限,且待估参数过多可能影响估计结果,笔者将企业性质和30项财务指标作为原始指标,具体包括:一是盈利能力指标6项[销售净利率、销售费用/营业总收入、营业利润/营业总收入、税息折旧及摊销前利润(EBITDA)/营业总收入、经营活动净现金流/利润总额、净资产回报率的增长率];二是现金流量指标4项(经营活动产生的现金流量净额/营业总收入、经营活动产生的现金流量净额占比、投资活动产生的现金流量净额占比、投资活动现金净流量/营业总收入);三是营运能力指标4项(存货周转天数、应收账款周转率、流动资产周转率、总资产周转率);四是偿债能力指标5项(长期负债占比、EBITDA/利息费用、经营活动净现金流/带息债务、经营活动净现金流/总负债、货币资金/短期债务);五是成长能力指标7项(营业总收入同比增长率、利润总额同比增长率、净利润同比增长率、营业利润同比增长率、净资产同比增长率、营业总收入3年复合增长率、净利润2年复合增长率);六是资本结构指标4项(资产负债率、长期资本负债率、带息债务/全部投资资本、流动负债/负债总计)。
利用特征工程方法从原始指标筛选入模变量。在进行特征工程之前利用相关性分析和VIF检验剔除了方差膨胀因子VIF大于10的指标。特征工程首先对原始指标进行分箱,透过卡方分箱方法计算不同指标的证据权重WOE和信息量IV值,如表1所示,最终选取IV值大于0.2的变量入模,确保入模变量具有较好的违约预测能力。
机器学习模型:Logistic回归及结果
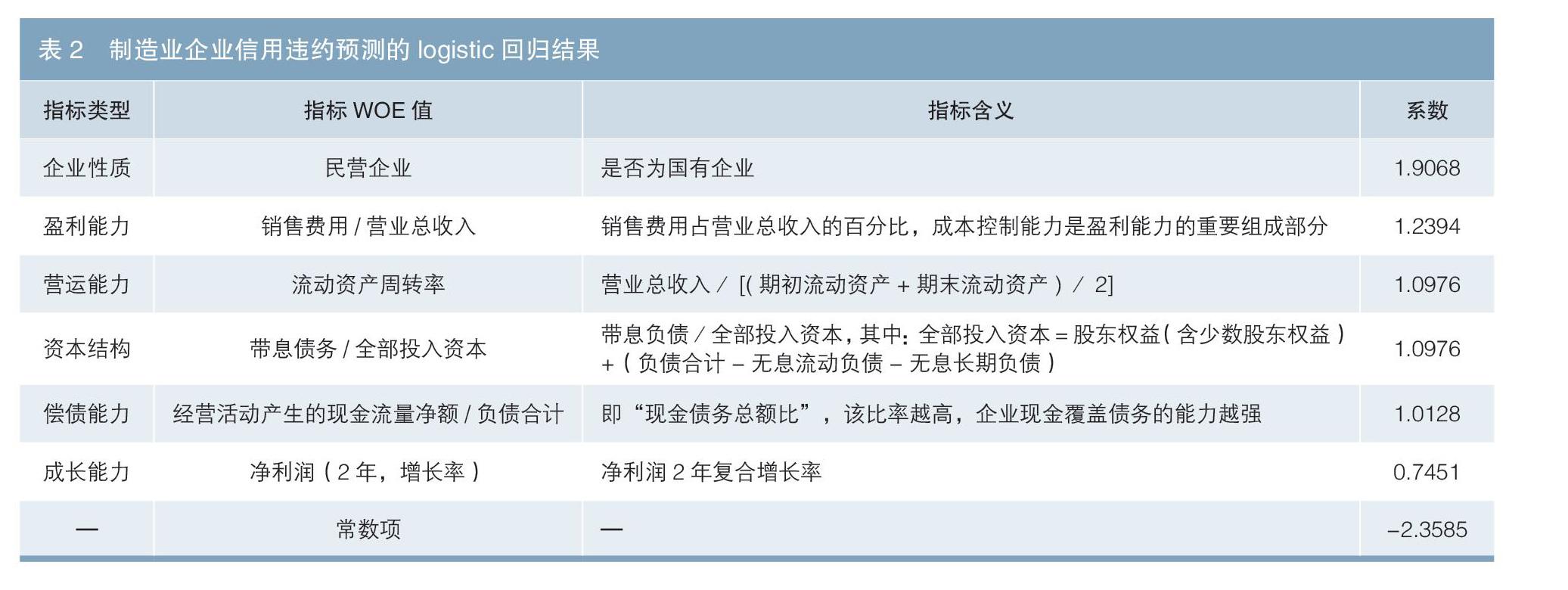
Logistic回归模型将多元线性回归通过Sigmoid函数转为违约概率预测的计算函数,因变量是样本违约与否的结果,自变量为特征工程筛选出的22个特征变量。通过回归结果的p值测量回归系数的显著性大小,结合逐步回归确定最终入模指标。笔者选择显著性较高(p值小于5%)的特征变量。对样本按照7:3的比例随机分为训练集和测试集,训练集回归结果如表2所示。
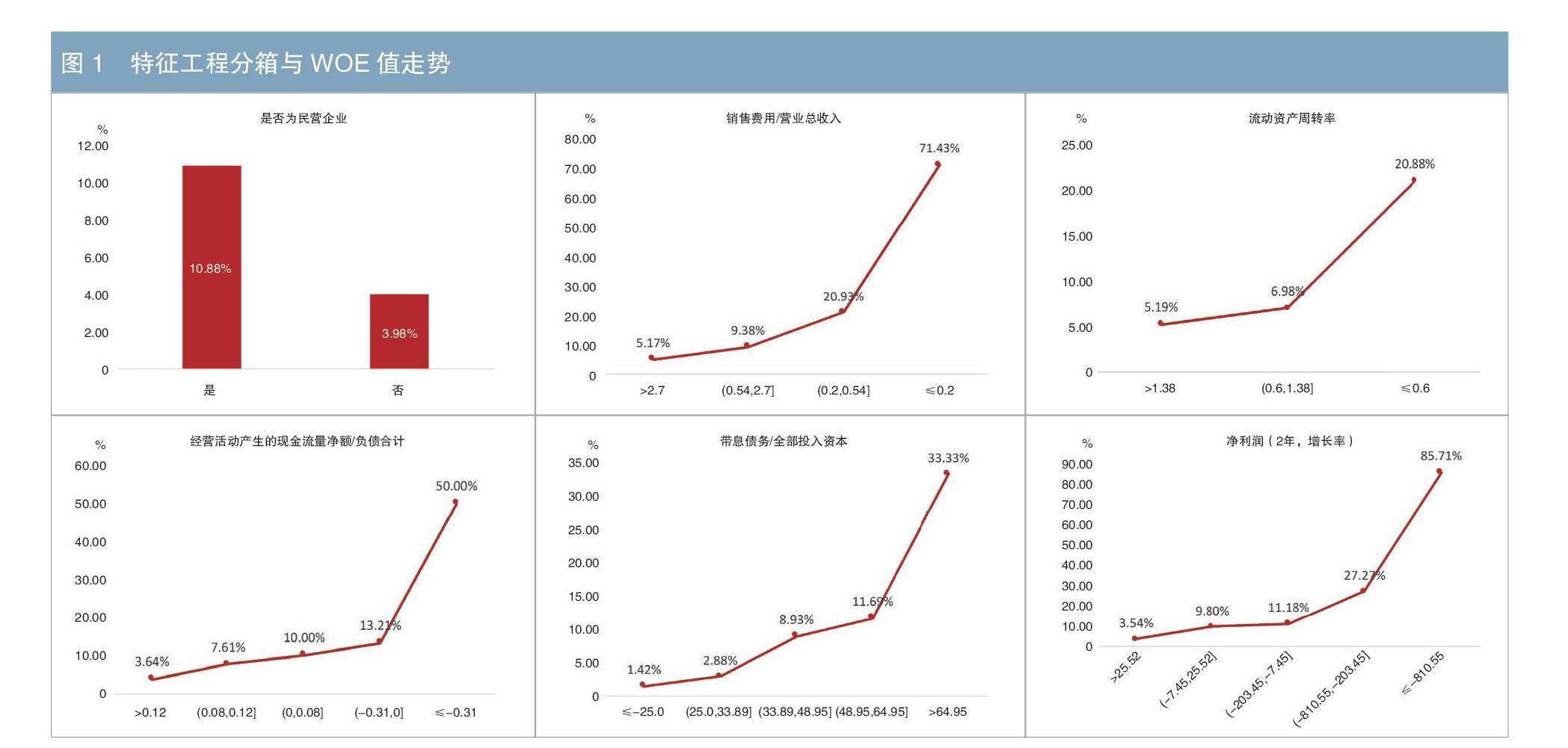
从回归结果来看,制造业企业信用影响因子涵盖企业性质、盈利能力、营运能力、资本结构、偿债能力和成长能力中的6个指标。如图1所示,结合特征工程分箱及不同箱体的WOE值分析内在机理。预期内的结论是:影响信用资质的核心指标包括企业性质、流动资产周转率、经营活动净现金流占负债的比例、有息负债占投入资本的比重、净利润复合增长率。超预期的结论是:销售费用占营业收入的比重越低越容易违约。这说明对于制造业企业来说,销售收入可提高盈利和偿债能力。
如表3所示,训练集和测试集的KS值分别为0.67和0.65,显著大于0.3,说明模型具有良好的等级区分能力;由表4可见,训练集和测试集的AUC值分别为0.90和0.88,显著高于0.75的界限值,说明模型具有较高的精准性;表4所示测试集的混淆矩阵显示模型应用于测试集的效果较好,违约预测精准度高达73.33%。
制造业企业信用评级模型及评分卡
基于Logistic回归模型及参数估计结果,计算制造业企业的违约概率p,再基于p构建信用评级评分卡,评分Score=500-20?log(p/1-p),即以500分为基准分,以20分为单一等级分数区间,违约概率越高,则评分越低。基于上述逻辑构建制造业企业的信用评分卡,如表5所示。基于评分卡对存量738家制造业企业进行信用评级打分,以30分划分一级,将企业分成12个等级,结果如表6所示。10级以上企业占比为13.69%,与外部评级相比,模型更具区分度。外部评级为AA级及以上的企业占比为70%,AAA级占比高达22%,集中度较高,区分度较低。
在信用违约预测方面,机器学习模型表现较好,违约预测命中率达75%。如表7所示,2020年下半年至2021年一季度实际违约企业4家,其中3家基于2019年数据的评级结果低于6级,基于2018年数据的评级结果均低于7级,仅B公司的评级结果为9级。
研究结果的潜在应用
将制造业企业外部评级和基于机器学习方法的信用评级建立二维映射表,如表8所示,单元格内容代表外部评级为该列对应外部等级和机器学习模型评级为所在行对应模型等级的企业家数。映射表可用于三个方面。一是风险企业排雷,当企业外部评级低于AA-级且模型评级低于5级时,可认为信用风险较高,应避免投资。二是信用价值挖掘,当企业外部评级在AA-级及以下,但模型评级为9级及以上时,可进一步研究,挖掘被市场误判带来的信用溢价。三是警惕市场高估,当企业外部评级在AA-级以上,但模型评级为5~9级时,可考虑结合进阶信用研究并利用债券借贷等做空机制参与做空。
学习模型结果还可用于信用风险定价和内部评级检验。利用模型评级结果计算不同等级的违约概率,并将违约概率应用于不同信用等级制造业企业的信用风险定价。模型评级还可为机构内部评级提供交叉验证和补充,助力内部评级方法的改进和完善。
注:1.单元格内数字代表同时具有相应外部评级和模型评级的企业数量
2.橙色区域为可选优质企业区,绿色区域为信用价值挖掘区,深蓝色区域为市场高估区,红色区域为排雷区
作者单位:东莞银行资产负债管理部
责任编辑:陈森 鹿宁宁
猜你喜欢
江苏安全生产(2022年6期)2023-01-15 03:02:21
江苏安全生产(2022年6期)2022-07-29 01:22:52
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
电影(2018年8期)2018-09-21 08:00:06
中国军转民(2017年6期)2018-01-31 02:22:13
中国军转民(2017年8期)2017-12-13 08:37:01
股市动态分析(2016年22期)2016-12-27 17:06:46
IT时代周刊(2015年8期)2015-11-11 05:50:22
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
