
基于STM32和FPGA的电动汽车主动声浪控制器设计
2021-09-30 01:22:56史晨路武俊杰
石家庄铁道大学学报(自然科学版) 2021年3期
张 贤, 苏 新, 石 岩, 史晨路, 武俊杰
(1.石家庄铁道大学 机械工程学院,河北 石家庄 050043;2.中汽研(天津)汽车工程研究院有限公司,天津 300300)
目前,“低碳化、信息化、智能化”已成为汽车行业发展的潮流方向,汽车电动化已成为不可逆转的趋势。为满足人们对个性化、多元化的体验诉求,主动声浪技术受到了越来越多的关注,已成为电动汽车领域的研究热点之一[1-2]。2012年,Jagla et al[3]通过读取声音数据库中的声音片段进行发动机声音的合成,并进行了实验验证。2015年,奔驰汽车公司开发了一种名为“SLS eSound”的合成声音系统[4],该系统根据电动机和变速箱来制定声音合成控制策略,并通过车内扬声器播放声音来给人带来极具运动感的驾驶体验。现代汽车公司的Park et al[5]开发了一套个性化引擎声音系统(personalized engine sound system,PESS),提供了可定制的驾驶体验,通过车辆音频系统来实现对驾驶室内发出发动机声音,增加了表达个性驾驶乐趣的机会。2016年,英国里卡多公司的Maunder et al[6]设计了现实增强声音(realistic augmented sound by ricardo,RAS-R)系统,利用发动机转速和负载施加额外增益来对驾驶员提供实时车辆动态驾驶反馈。2018年,韩国崇实大学的Park et al[7]提出了利用声音产生和合成原理来制造发动机声音的方法,通过试验证实了该方法可以使用较少的内存来重现发动机声音。Jung et al[8]开发了发动机振动引起的发动机声音(engine sound by engine vibration,ESEV)技术,该技术依据信号控制处理器从发动机振动中获取车辆的速度和负载信息,产生所需的发动机声音,通过车内扬声器来实现声音播放效果。2020年,陈成等[9]提出了一种声音离线分析在线合成的方法,证明了该方法可以较好地模拟发动机排气声音。国外对于车内主动声浪技术研究及控制器的研发已初具规模,研发的相关产品已经应用在部分量产车型上,但是相关的硬件选型以及硬件通信关系并不透明。我国对主动声浪技术的研究起步相对较晚,且主要在声浪技术方面展开研究。2020年底,中国国务院办公厅正式发布《新能源汽车产业发展规划(2021—2035年)》,规划中指出到2035年纯电动汽车将成为主流的销售车辆,公共区域用车也将全面电动化[10]。综上,本文展开对主动声浪控制器的研制具有一定的工程应用意义。
采用STM32+FPGA(field-programmable gate array)的架构设计了一种电动汽车主动声浪控制器,建立基于电机转速和油门踏板开度为主要参数的声音样本读取控制策略,通过对相应的硬件模块搭建以及软件编程开发,制作出主动声浪控制系统工程样机,并在实车上进行试验验证,解决电动汽车车内声浪实现的问题。
1 主动声浪控制系统总体方案设计
主动声浪控制器读取车辆实时车速、电机转速、油门踏板开度等参数,然后根据这些参数进行相应的数据处理,产生对应的模拟声音信号,并传递给数模转换模块和功率放大器,来驱动车载扬声器系统播放发动机声音,达到主动声浪模拟的目的。主动声浪控制系统总体方案如图1所示,主动声浪系统结构由信号输入、主动声浪控制器和信号输出3部分组成。

图1 主动声浪系统总体方案
电动汽车控制器局域网络(controller area network,CAN)作为系统的信号输入,可获取电动汽车的挡位、车速、电机转速和油门踏板开度等实时运行参数信息,信号经过CAN_H和CAN_L 2条信号线传输给主动声浪控制器。
主动声浪控制器作为系统的核心控制部分,主要包括STM32最小系统和FPGA开发板。STM32通过与CAN总线通信,将接收并过滤处理后的电机转速(revolutions per minute,RPM)和油门踏板开度(accelerator position sensor,APS)信号通过USART(universal synchronous/asynchronous receiver/transmitter)串口通信传输到FPGA。FPGA开发板板载一片W25Q128型128 Mbit大小的Quad-SPI FLASH,其具有非易失特性,可作为声音样本数据库和控制程序的存储器。FPGA根据STM32发送的2个参数信号实时对声音样本数据库中的声音样本进行读取并合成,同时合成的声音数据通过I/O拓展接口传输到双通道DA输出模块,将合成声音数据的数字信号转换成模拟信号输出。
功率放大器及扬声器作为系统信号输出,将模拟信号声音通过功率放大器进行功率放大,并由车载扬声器系统播放,发出实时状态下的模拟发动机的声音。
2 控制器硬件设计
主动声浪系统控制器硬件主要由CAN滤波器、STM32最小系统、FPGA开发板、双通道DA输出模块组成。其中,STM32最小系统采用基于Cortex-M3内核的STM32F103C8T6,FPGA开发板采用Xilinx公司的AX545。基于控制器的硬件构成对硬件通信电路进行设计,主要包括CAN总线解读模块、STM32与FPGA通信模块、DA数模转换模块。
2.1 CAN总线通信模块
控制器局域网络是国际标准化的串行通信协议,具有数据传输速度快和抗干扰能力强等特性,在汽车中广泛应用。STM32F103C8T6芯片在其内部集成了一个标准的bxCAN,支持CAN协议2.0A和CAN协议2.0B,波特率最高可达1 Mbps。它可以接收和发送11位标识符的标准帧,也可以接收和发送29位标识符的扩展帧,具有2个接收先入先出队列(first input first output,FIFO)缓存,每个FIFO有3层深度。CAN滤波器采用NXP(恩智浦)公司的TJA1050芯片,其符合通信速率为125 kbps~1 Mbps高速通信的ISO11898标准。CAN总线通信原理如图2所示,根据CAN_H与CAN_L 2条线来判断CAN总线电平状态,经过TJA1050内部转换将CAN_H和CAN_L上的差分信号转换为逻辑电平传输到bxCAN。
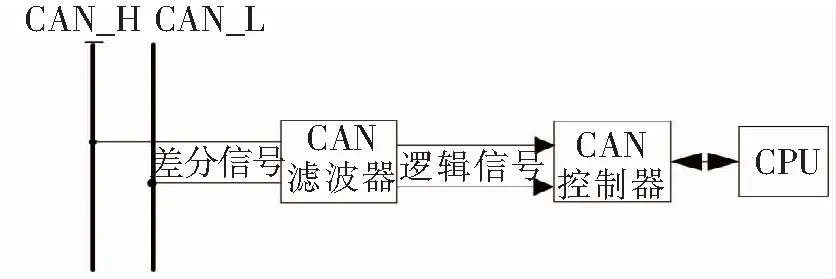
图2 CAN总线通信原理
2.2 STM32与FPGA通信模块
在主动声浪控制器设计中,利用USART实现STM32最小系统与FPGA开发板之间的通信和数据传输。USART是一个全双工通用同步/异步串行收发模块,作为一种应用最广泛和高度灵活的通信总线,是硬件间最为常用的串行通信方式。USART支持同步双向通信,只需TXD、RXD 2根信号线即可完成。需要注意的是,硬件设计为了使系统达到预期的控制效果,只需要将STM32的数据单向传输给FPGA,因此只需要一根数据发送信号线TXD和一根共地线GND,来实现STM32与FPGA开发板间的通信。
2.3 DA数模转换模块
DA输出模块作为控制器中的一部分,用来将数字信号转换成模拟信号,该模块选用ANALOG DEVICES公司的双通道AN9767。该模块主要由AD9767、低通滤波、第一级运放和第二级运放等4部分组成,其数模转换原理如图3所示。
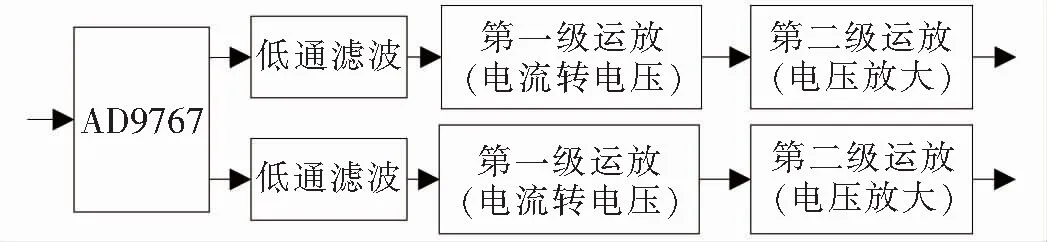
图3 DA数模转换原理
低通滤波电路可将AD9767输出的2通道信号首先进行滤波,以减少外界对其的干扰影响,滤波后的电流信号经过第一级运放和第二级运放,来达到电流信号转换成放大的电压信号,最终输出的模拟信号电压范围在-5~+5 V之间。其中,第一级运放可将电流转换成-1~+1 V电压,第二级运放可将-1~+1 V的电压放大来达到幅值增大的目的,也可通过在调整板上旋转可调电阻来实现幅值变化这一过程。
3 系统软件设计
主动声浪系统软件设计分为STM32程序设计和FPGA程序设计2部分。使用C语言在Keil uVision5开发环境中完成STM32程序编写工作,使用硬件描述语言Verilog HDL在ISE Design Suite 14.4开发环境中完成FPGA程序编写工作。
3.1 STM32程序设计
基于STM32的CAN和USART通信硬件连接在系统硬件电路设计部分进行了详细的介绍,这里对STM32的程序设计进行介绍,程序设计采用模块化思想完成。
(1)CAN通信模块程序设计。CAN通信模块的程序通过硬件电路完成与汽车CAN总线通信,CAN通信是控制器能否正常运行的前提条件。CAN通信模块程序流程图如图4所示。
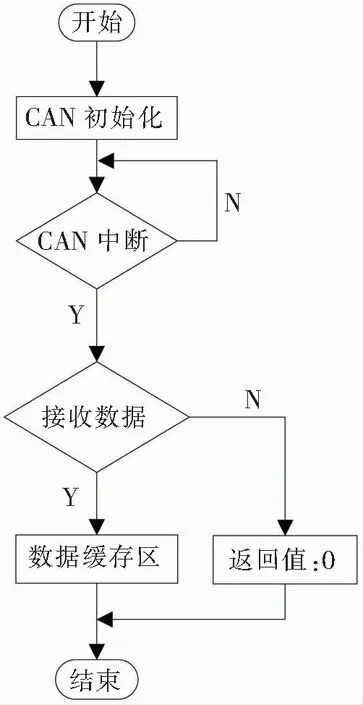
图4 CAN通信模块程序流程图
通信模块程序中需要对CAN的工作方式进行配置,其中波特率的配置最为重要。CAN通信波特率计算公式为
(1)
式中,fck为APB总线时钟频率;tbs1、tbs2分别为时间段1和时间段2的时间单元;tsjw为重新同步跳跃时间单元;prescaler为波特率分频器系数。
在实际的CAN通信过程中,电动汽车CAN总线波特率为500 kbps。由于CAN总线基于相同波特率进行通信,其通信接口挂载在APB1时钟总线上,其频率为36 MHz,在式(1)中将tbs1、tbs2、tsjw、prescaler项目参数分别设置为1、3、2、12,即可得到匹配的波特率。
(2)数据处理模块程序设计。数据处理模块接收并处理来自CAN总线数据,bxCAN提供可配置的标识符过滤器组,通过软件编程设计,对接收到的数据帧进行标识符匹配过滤的配置,在引脚收到的报文中过滤掉不需要的报文,而与过滤器匹配的报文会被放入FIFO缓存。对于电动汽车而言,电机转速和车速的比值始终为一个常量,因此在设计中将车速和油门踏板开度2个参数标识符配置,匹配的数据帧作为RPM和APS变量向FPGA的发送数据信号。数据处理模块程序流程图如图5所示。
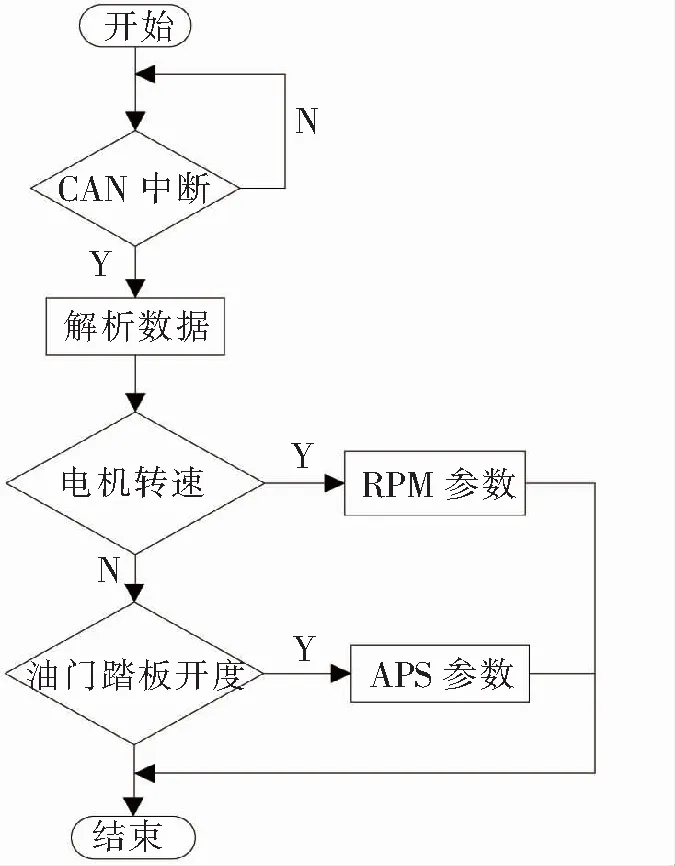
图5 数据处理模块程序流程图
(3)USART通信模块程序设计。USART通信模块程序流程如图6所示,USART通信模块程序将数据处理后的参数通过USART传输给FPGA,来完成数据发送。与CAN通信同理,硬件之间的USART通信也是根据相同波特率进行通信,STM32串口波特率通过USART_BRR进行配置,USART_BRR的前4位用于表示小数,后12位用于表示整数,波特率寄存器支持分数设置,以提高精确度。波特率计算公式为
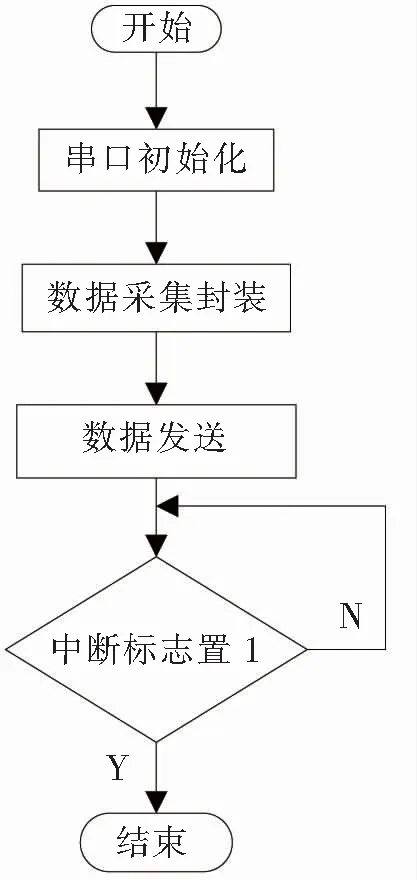
图6 USART通信模块程序流程图
(2)
式中,fck为外设的时钟频率;USARTDIV是一个无符号的定点数,表示对时钟频率进行分频。
设计的USART挂载在APB2时钟总线上,其频率为72 MHz,波特率设置为115 200 bps,由式(2)计算得到USARTDIV的值为39.0625,赋值给USART_BRR寄存器。
3.2 FPGA程序设计
FPGA采用自顶向下的设计方法,利用软件编程,通过综合、逻辑映射、布局布线,将逻辑网表配置到具体的FPGA芯片上。FPGA程序设计主要包括FPGA与STM32通信程序和声音样本合成算法程序。FPGA与STM32通信模块程序流程如图7所示。FPGA接收来自STM32的通信数据,对声音样本库中的声音样本进行读取,声音样本合成算法程序根据读取的声音样本实时合成处理。
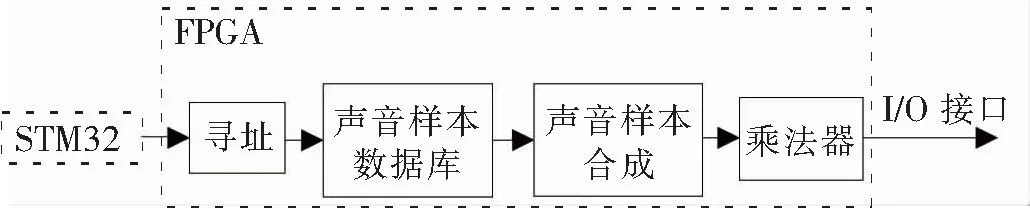
图7 FPGA与STM32通信模块程序流程图
3.2.1 FPGA与STM32通信模块程序
FPGA程序基于USART串口与STM32通信,USART通信的功能是接收STM32发送的RPM和APS参数数据。为保证通信协议相同,USART通信的两端设定相同的波特率即115 200 bps。利用RPM参数对声音样本数据库进行寻址,读出相应的声音样本,APS参数来对该样本声音的幅值进行修正。
3.2.2 声音样本合成模块程序
声音样本合成模块程序基于声音样本的在线时域同步叠加合成,而声音样本的制作则是通过对采集原始发动机声音信号离线分解来完成。
发动机声音具有周期性非正弦特性,因此发动机声音的分解利用此特性进行展开分析[11]。对于四冲程发动机加速声音而言,主阶次频率
(3)
式中,ne为发动机每分钟转速;Nc为发动机气缸数量。
在转速不变时,连续时间信号t的发动机声音模型表达式为
(4)
式中,Ai(t)和φi(t)分别为i阶次谐波幅值和初相位;ωi(n)为i阶次附带的随机信号成分。通常情况下,k=Nc/2对应的阶次谐波能量最大,即主阶次对应的谐波。
四冲程发动机曲轴每转1圈,对应的主谐波波形有m个过零点数,每个气缸完成一次点火为一个周期,共计有2m个过零点数。因此,声音样本截取的长度为发动机2个周期数据的倍数加上固定声音叠加区数据之和,并对每个声音样本依次赋予对应声音频率值和电机转速值,通过此操作可实现每个声音样本具有相同的初始相位以及相同的重合叠加区。将上述分解步骤得到的各个声音样本按主阶次频率由低到高依次排列,制作而成声音样本数据库,存储在主控声浪控制器的FLASH中,以此为基础进行发动机声音的合成。
声音样本合成程序将读取声音样本库中的样本声音实时在线合成,来达到发动机声音合成的效果,声音样本合成过程如图8所示。
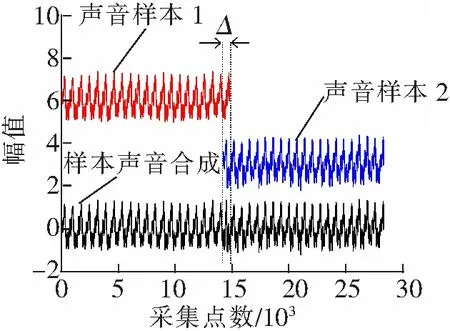
图8 声音样本合成示意图
由图8可知,声音样本1和声音样本2分别为声音样本库中的2个随机声音样本,Δ为每个声音样本的固定叠加区域。将此固定叠加区域设置为512个数据点,目的是实现加权平滑过渡,保证声音合成过程中的连续稳定。
4 实车试验
为了验证主动声浪控制器的声音合成效果,在国产某型SUV电动汽车上进行实车试验。原始声音数据采集工作在中国汽车技术研究中心整车半消声实验室中进行,某型四缸四冲程发动机转速从1 000 r/min到5 000 r/min缓加速,加速过程时间为110 s,采集到的发动机声压波形、发动机转速与加速时间曲线如图9所示。对采集的声音信号离线分解,将其制作成声音样本数据库,并存储在主动声浪控制器的FLASH中。
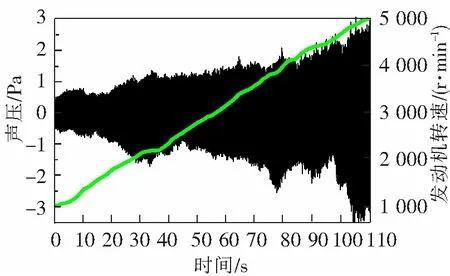
图9 采集的发动机声压波形、发动机转速与加速时间曲线
搭建主动声浪控制器并将汽车CAN总线和扬声器系统通过线束与控制器相连接,形成电动汽车车内主动声浪系统,麦克风与主动声浪控制器的安装位置如图10所示。

图10 麦克风与主动声浪控制器实车安装
为达到车内声音的动态合成效果,制定了20%、40%、60%、80% 4种油门踏板开度随车速变化的控制方案,通过实车试验分别得到了不同油门踏板开度下车内合成发动机声音的频谱瀑布图,见图11。
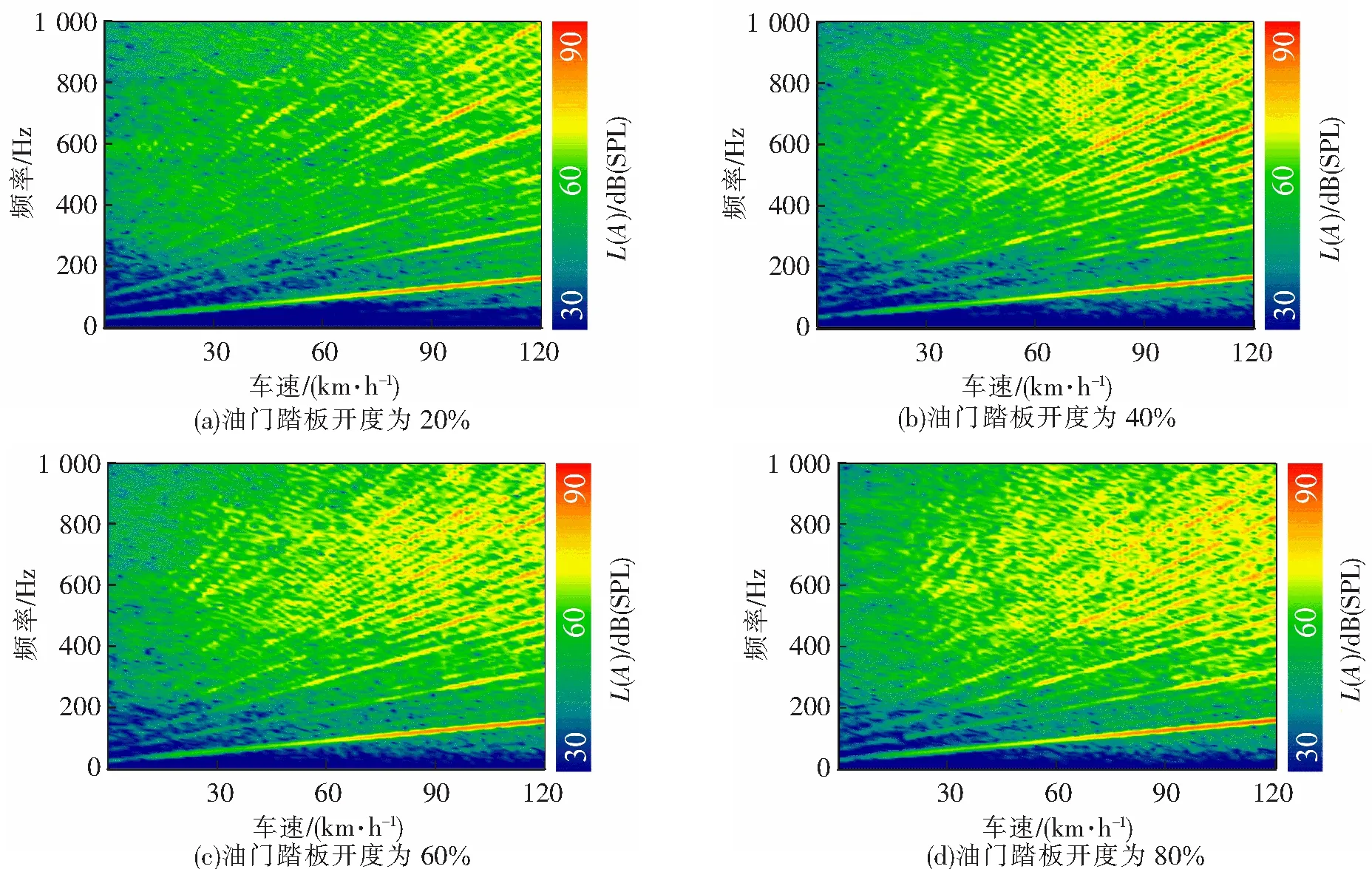
图11 不同油门踏板开度下车内声音频谱瀑布图
从图11可以看出,在20%、40%、60%、80% 4种不同油门踏板开度下,随着车速在0~120 km/h的范围内逐渐增加,车内模拟声音的声压级也逐渐增强,且模拟声音清晰还原了原始发动机声音丰富的阶次成分,并存在明显的主阶次成分;在车速不变的情况下,对比油门踏板开度分别在20%、40%、60%、80%处时可知,车内各个阶次声压级随着踏板开度的增加而增强,满足汽车行驶时根据车速和油门踏板开度下发出动态声音特性的要求。实车试验结果表明,所设计的主动声浪控制器能够较好地模拟电动汽车在行驶状态下高度匹配的传统发动机声浪。
在实际的电动汽车驾驶过程中,车速与油门踏板开度是实时变化的,通过车速对声音样本数据库中的声音样本进行实时读取,油门踏板开度对读取的声音样本幅值进行调整,结合时域同步叠加方法对声音样本进行合成,来模拟符合汽车实时运动状态的发动机声音。
5 结论
本文设计了一种基于STM32最小系统和FPGA开发板为核心的电动汽车车内主动声浪控制系统,具体包括系统的体系架构、硬件设计和软件开发;研发制作了主动声浪控制器原理样机,并进行了实车试验,得到以下结论:
(1)根据CAN通信实现对汽车车速和油门踏板开度等控制信号的实时读取,利用STM32作为控制核心,FPGA的高速数据处理能力来对声音样本进行合成,通过车载扬声器系统对合成声音播放。
(2)研制的主动声浪控制系统原理样机完成的声音模拟,具有良好的发动机声音的线性阶次能量分布特性,且满足车内声浪动态模拟的控制需求。
(3)本文为电动汽车车内主动声音的模拟控制提供了一种解决思路和方法,还可以应用到驾驶模拟器、虚拟现实平台等相关领域的开发中。
猜你喜欢
名车志(2023年5期)2023-10-18 21:20:47
车主之友(2022年6期)2023-01-30 07:58:16
东坡赤壁诗词(2022年3期)2022-05-29 02:21:00
智能制造(2020年5期)2020-07-03 06:24:00
黄河之声(2019年23期)2019-12-17 19:08:43
汽车实用技术(2019年17期)2019-09-21 03:46:32
电子测试(2018年7期)2018-05-16 06:27:18
家用汽车(2017年4期)2017-06-27 09:01:45
黄河之声(2017年13期)2017-01-28 13:30:17
中国汽车界(2016年8期)2016-02-27 01:57:35
