
制作文字底稿的高级技术
2021-09-27 08:57国防科技大学电子对抗学院徐济仁
电子世界 2021年15期
国防科技大学电子对抗学院 琚 振 徐济仁
73676部队 刘同赞
安徽建筑大学电子学院 吴东升
合肥工业大学机汽学院 赵小兰
底稿,俗称草稿,原稿。从广义上讲是出版、印刷的原始根据,在印刷的五大要素(原稿、印版、承印物、油墨、印刷机械)中居于首位。一般由客户提供。文字原稿由作者和编辑决定,其社会效果取决于原稿的内容,印刷质量只与印刷技术和条件有关。
底稿的来源多种多样,有的来自于出版社的书,有的来自于网络,有的来源于广告宣传手册,等等。出版书的书经过作者的反复锤炼和修改,错误很少,所以书的内容值得我们借鉴和使用。书里面的内容可以通过扫描,然后使用ocr文字识别软件,通常这些文字识别软件识别正确率是非常高的,我们平时用的比较多的两款软件CAJViewer和Adobe Acrobat,都自带ocr文字识别功能。
1 从印刷品到可编辑的文字
书是最重要的印刷品。
首先,第一步我们需要对书的内容进行扫描,我们尽可能的把书贴近扫描仪的玻璃板,用力按住书。然后再在书的外面盖上一块黑色的布,不要漏光。最好能够将书拆成一页一页地进行扫描,这样扫描的效果是最好的。
现在的书大部分都是黑白的,使用OCR文字识别软件处理的时候,识别准确率非常高。基本上不会有什么错误,或者错误很少。但是有的书里面有彩色的插页,我们可以先把它转成灰色图像,然后在进行ocr文字识别。
有的书在印刷的时候。正文采用了白底黑字,注释部分采用了其他的颜色背景,比方说淡黄色,如图1所示。

图1 书扫描效果截图
我们这张扫描图片是将书拆开之后单页扫描的,扫描仪的分辨率是200dpi。分辨率不能太低,会影响OCR文字识别准确率的。分辨率如果低于100 dpi,文字识别准确率会受到影响。
我们将扫描页面分成两个明显的区域,分别给予编号:1和2,编号1区块,不是正文,相关链接类似于注释,背景是淡黄色,OCR文字识别准确率非常低,编号2区块是正文,白底黑字。Ocr文字识别率准确率非常高。
因为是单页扫描。扫描的时候,扫描仪玻璃板上面有一个盖板,完全可以把单页纸盖住,因为不漏光,所以扫描的效果非常好,没有一点点的黑色(扫描的时候,漏光的部分都是黑色的)。这也是我们向大家推荐使用扫描仪扫描书的时候,要尽可能的把书拆成单页进扫描的原因。
在正式扫描之前。需要使用图像处理软件ACDSEE对扫描图片进行简单的处理。
(1)观察扫描图片有无上下偏移,有的不是非常明显的上下偏移,肉眼没有办法进行观察,我们可以用acdsee打开这个扫描图片,点击ACDSEE左边工具栏里面的“旋转”按钮,图像处理软件ACDSEE会显示校正用的网格线,如图2的的示。将文字和网络线进行比对就可以看出,文字有没有上下偏移。如果有偏移,可以通过这个旋转操作功能,将文字调整成水平。

图2 旋转操作时显示的网格线
(2)对扫描的图片进行适当的裁剪。把不需要的部分统统去掉,包括页眉、页脚和页码等,把需要文字识别的正文和注释部分以及其他需要识别的部分保留下来。
经过旋转和裁剪后的图片,下一步进行OCR文字识别。
有的扫描仪随机赠送ocr文字识别软件。扫描一页后,自动进行旋转校正和裁剪,后然进行OCR文字识别;也可以手工进行旋转校正和裁剪,然后进行OCR文字识别。
有的扫描仪没有随机赠送ocr文字识别软件,或者功能一般,识别准确率不高,功能也一般。
无论扫描仪带不带OCR文字识别软件,建议大家使用我们平时用的比较多的两款软件CAJViewer和Adobe Acrobat,都自带ocr文字识别功能。因为,它们的识别准确率和扰干扰能力都非常强,而且通用性强。
2 Adobe Acrobat使用方法(适用于出版社图书,多页处理)
具体操作方法如下:
(1)扫描图片,经过旋转和裁剪之后,我们用acrobat将它们合并成一个PDF文件。
(2)点击菜单栏里面的“视图”->“工具”->“文本识别”,在窗口的右侧弹出工具栏。点击“文本识别”->“在本文件中”,系统弹出“识别文本”对话框,如图3所示。
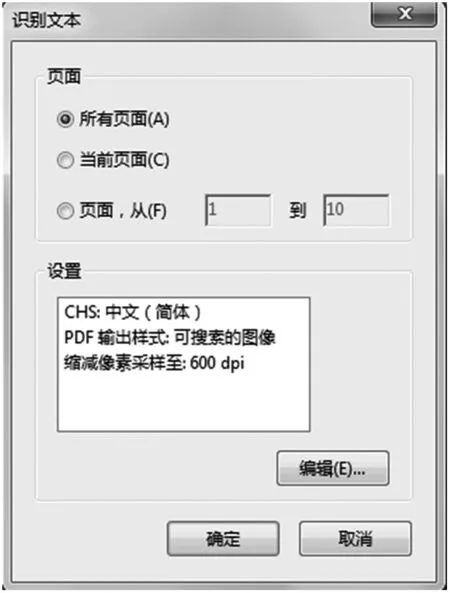
图3 识别文木界面
点“确认”关闭“识别文本”对话框。随后ACROBAT软件,调用内嵌的OCR文字识别软件,对图像进行旋转,纠偏,分解页面,处理,后处理,如图4所示。最后得到可编辑的文字。

图4 Acrobat软件对图象的处理操作步骤图
(3)点击“编辑”->“全部选定”(快捷键CTRL+A),
如果是首次使用,会弹出“扫描页面警告”对话框,如图5所示。
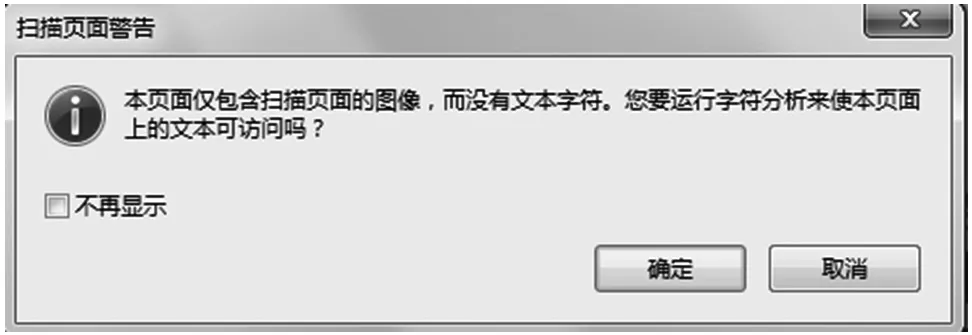
图5 首次使用提示对话框
点“确认”关闭对话框。
(4)点击“编辑”->“复制”(快捷键CTRL+C),OCR文字识别的结果已经在剪切板上。
(5)在WORD中新建文件,按CTRL+V,将剪切板上内容粘贴在新文件上。
对照原文,注意观察文字识别准确率,有的识别率非常高,可以直接使用。有的识别率非常底,需要重新处理。我们发现图1中,编号1区块文字识别准确率非常低,可能是黄色背景的原因。有的出版社为了防止盗版,专门加入一些特殊的背景,使用OCR文字识别软件,文字识别准确率非常低。
处理方法非常简单,在图1中,将单页分成二个区块,编号2区块识别率高,直接使用。编号1区块识别率非常低。用ACDSEE图像处理软件将编号1区块单独剪辑出来,如图6所示。

图6 单独剪辑效果图

图7 自动爆光效果图
如果认可这种处理效果,点击完成。
点击菜单项上面的“修改“-》更改色深-》256阶灰度,结果如图8所示。

图8 灰色图象效果图

图9 曝光效果
如果认可这种处理效果,点击完成。
这时,如果用OCR文字识别软件来识别,识别率应该非常高。
我们来试一试,看识别率是多少?
①将图片另存为一个图片文件。
②将这个图片文件转换成一个单独的PDF文件。
③点击菜单栏里面的“视图”->“工具”->“文本识别”,在窗口的右侧弹出工具栏。点击“文本识别”->“在本文件中”,等待系统识别结果。按CTRL+A键,按CTRL+C键,在WORD文件中,按CTRL+V键,将结果粘贴出来,看识别结果。
我们发现识准确率提高了非常多。
3 CAJViewer使用方法(适用于期刊,单页处理)
具体操作方法如下:
(1)扫描图片,经过旋转和裁剪之后,我们用acrobat将它们合并成一个PDF文件。
(2)点击“工具”->“文本选择”。
将鼠标移动到图像文本上,我们会发现鼠标箭头变成了另外一种形状,而不是编辑状态。
(3)点击“工具”->“文字识别”。鼠标箭头变成十字丝,选中需要识别文字图象,系统自动弹出“文字识别结果”对话框,文字识别结果显示在编缉框内。
猜你喜欢
计算机工程(2020年3期)2020-03-19
网络安全和信息化(2020年1期)2020-01-15
中国听力语言康复科学杂志(2019年3期)2019-06-24
模具制造(2019年3期)2019-06-06
中学科技(2018年12期)2018-12-19
中学科技(2018年10期)2018-12-18
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
电脑知识与技术(2016年5期)2016-04-14
湖南城市学院学报(自然科学版)(2016年4期)2016-02-27
