
手语识别方法与技术综述
2021-09-26 10:41米娜瓦尔阿不拉阿里甫库尔班解启娜耿丽婷
计算机工程与应用 2021年18期
米娜瓦尔·阿不拉,阿里甫·库尔班,解启娜,耿丽婷
新疆大学 软件学院,乌鲁木齐830046
手语是进行信息交流的一种有效的肢体语言,手部动作可以传递丰富的语义信息。手语作为聋哑人与外界交流的主要方式,在获取知识、与健听人交流、提高生活质量等方面不可或缺。因此,在帮助聋哑人融入社会的各个方面中,手语起到至关重要的作用。随着人们对特殊群体的深入了解,对手语的关注也更为广泛。与口语相同,每种手语都由成千上万的单词组成。手语使用身体不同的部位,如手指、手臂、手部运动轨迹,头部和面部表情等来传递信息[1],是一种结构化的手势形式。在手语中,每个手势都有特定的含义,强有力的上下文信息和语法规则也是在手语识别中应要考虑的因素。
手语识别是指利用算法和技术来识别所产生的手势序列,并以文本或语音的形式阐述其意义[2],其相关识别技术也能应用到其他领域,如智能家居交互[3]、交警指挥识别[4]、人机交互[5]和智能驾驶等。近年来,基于手语识别的研究通常采用深度学习的方式将手势转换成文本或语音,创造了一种新的人机交互方式。深度学习作为机器学习的子领域在图像处理的诸多领域都展现出了更好的成绩,其主要目标之一是避免手工提取特征[6]。深度学习方法允许多个处理层的计算模型来学习和表示具有多层次抽象的数据,以模仿人脑机制,并捕获大规模数据的复杂结构。计算机视觉作为人工智能领域的重要部分,主要任务是对采集的图片和视频数据进行处理以获得关键信息,而这种处理方式是通过深度学习方法来实现。由于手语识别是典型的跨学科问题,涉及计算机视觉、自然语言处理、图像识别、人机交互和模式识别等多个领域[7],且手语词汇量多,表达方式丰富多样,语义语法结构复杂,因此手语识别中的挑战和困难依然存在。
本文对近年来的手语识别方法和技术进行了归纳和梳理。手语识别常用的方法包含动态时间规整[8](Dynamic Time Warping,DTW)算法、隐马尔可夫模型[9](Hidden Markov Model,HMM)、三维卷积神经网络[10](3D Convolutional Neural Networks,3D-CNN)和长短期记忆网络[11](Long Short Term Memory,LSTM)。
1 基于传感器和基于视觉的手语识别
手语是一种有效而自然的交流方式,包含视觉运动和手语的结构化手势形式。根据手语数据获取方式的不同,手语识别类型可以分为基于传感器的识别和基于视觉的识别[12]。
数据手套是常见的基于传感器的设备,广泛应用于手语识别研究。在早期的手语识别研究中,由于计算机的计算能力较差,实时图像处理速度受到了限制,因此基于数据手套的识别技术占据了主导地位。数据手套可以捕获佩戴者的手部关节信息和运动轨迹,通常获取较高的识别精度。1983年,Grimes等人[13]发明了最早期的数据手套为聋哑人使用。佩戴者单手展示美国手语字母所定义的字符状态并将数据传输至接收设备。1999年,吴江琴等人[14]利用BP神经网络和学习判定树的混合方法,使用带有18个传感器的CyberGlove数据手套对30个汉语手指字母进行识别。文献[15]将基于数据手套的识别和基于视觉的识别进行对比,发现基于视觉的手势跟踪算法对不同的照明条件和动态背景非常敏感,而基于手套的手势跟踪算法不依赖于任何背景和照明条件,其识别精度往往高于基于视觉的手识别精度,且手势跟踪算法都是鲁棒和有效的。由于数据手套的识别方法成本高、依赖于硬件设备、用户体验较差,基于视觉的手语识别方法成为了主流。
基于视觉的手语识别通过摄像头捕捉手语图像和视频,利用算法对连续画面分析手语动作并识别出手语动作语义信息。该方法是利用图像处理、深度学习等技术,通过计算机对图像或视频中的手语进行分析和处理获取其特征并利用这些特征进行分类识别的过程。与数据手套不同,利用图像采集设备进行手语数据采集没有过多的束缚,并且图像采集设备成本低廉、容易携带,从这一点来说基于视觉的手语识别更有利于推广和应用。伴随着科技的进步,可以采集三通道彩色图像的设备和深度图像的深度相机逐渐进入图像识别领域。基于视觉的手语识别交互方式简单、设备依赖性较低,且符合日常交流。表1将基于传感器的识别方法和基于数据手套的识别方法进行了比较。本文主要围绕基于视觉的手语识别方法进行阐述。

表1 基于传感器和基于视觉方法比较Table 1 Comparison of sensor-based and vision-based approaches
2 手语识别分类
根据手语识别研究方法的不同可分为静态手语识别和动态手语识别。动态手语识别又可分为孤立词识别和连续语句识别,其分类如图1所示。由于手语是一系列动作构成的具有相似特征的快速运动,传统的静态手语识别方法很难处理动态手语手部动作中复杂的词汇表达方式和大幅度的变化。动态手语是在短时间内由动作连接起来的一系列姿势,其视频序列既包含时间特征又包含空间特征,在识别过程中需要考虑手部运动轨迹、位置及上下文的语义信息。因此,动态手语识别算法难度比静态手语识别算法难度大。在动态手语识别方法中,手的形状变化和快速移动给手语识别带来了许多挑战[16]。基于视觉的动态手语识别技术具有灵活性,可扩展性和低成本等特点,相比静态手语,动态手语词汇量大,种类多,表达方式丰富,更具有实用性,是当前手语识别研究的热点。
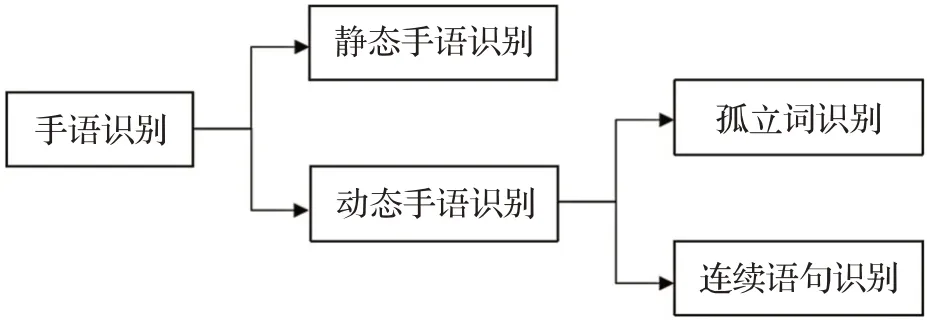
图1 手语识别分类图Fig.1 Sign language recognition classification map
2.1 静态手语识别
静态手语识别的研究对象为图像中手部的外观特征,对手势进行特征提取、分类与识别的过程。换言之,静态手语识别是一种简单的图像分类问题,因此一般识别较为准确。通常静态手语识别的研究是对手语字母的识别,即利用手指的指式状态代表字母,其难点在于手语图像会受到光照、背景环境等因素的影响。Amaya和Murray等人[17]提出了基于主成分分析(Principal Component Analysis,PCA)和支持向量机(Support Vector Machine,SVM)的静态手语识别方法来识别英文中5个元音字母,PCA用于对手部区域进行特征提取,SVM用于分类。Aich等人[18]在自己构建的数据集上使用卷积神经网络(Convolutional Neural Networks,CNN)来识别孟加拉手语中的36个字符,准确度达到92.7%,但其图像背景单一,可扩展性不高。Hasan等人[19]利用CNN对美国手语字母进行识别,识别率达到97.62%。
2.2 孤立词识别
孤立词识别的识别对象是单独的词汇,它由连续时间段的图像序列组成。相对于连续语句识别,孤立词视频较短。1997年,Grobel和Assan等人[20]提出了一种基于HMM的荷兰孤立词识别模型,从两名操作者收集了262个单词进行实验。实验发现,若训练和测试均只有一名操作者完成,实验准确率均在90%以上。若一名操作者用于训练而另一名操作者用于测试,则准确率降至56.2%和47.6%。同时使用两名操作者对数据集进行训练可以将准确率提高到91.3%。
对于视频中存在许多冗余帧问题,Huang等人[21]提出了一种基于关键帧为中心剪辑(Keyframe-Centered Clip,KCC)的孤立词识别方法。该方法将用CNN从RGB视频流中获取到的手部关键帧的特征信息与深度运动地图的梯度方向直方图和骨骼关节的轨迹特征通过多模态KCC特征的特征融合层进行融合。利用LSTM编译码网络对该特征融合层进行联合训练,对中国手语数据集中的310个孤立词进行实验,实验结果表明不使用KCC和使用KCC的准确率分别为89.87%和91.18%,同时也证明了该方法优于HMM、DTW、CNN和LSTM。
Liao等人[22]提出了一种结合三维卷积残差网络和双向长短期记忆网络的BLSTM-3D残差网络(B3D ResNet)用于孤立词识别。利用Faster R-CNN检测手部,并从背景中分割出手的位置,然后利用双向长短期记忆网络(Bi-directional Long Short Term Memory,BLSTM)对输入图像序列进行分类,由三维卷积残差网络联合提取空间和时间特征。该方法中,处理的不是整个视频帧,而是首先定位手部位置并提取其关键点信息,然后在此基础上研究剩余帧的特征信息,这一过程减少了网络计算时间和复杂性。
2.3 连续语句识别
连续语句是由一系列手语及手势产生的有意义的完整句子。现有的大多数连续语句识别技术是将孤立词作为构建块,在预处理阶段进行孤立词时间分割,最后进行句子合成。连续语句识别中的挑战包括将句子标记为单独的单词,标记句子的开始与结束,一个动作的结束到下一个动作的开始这一时段的检测与建模[23]。连续语句识别是一项非常具有挑战性的任务,其手语词汇量非常庞大,可组成的手语词组和语句更是不计其数,且一个视频序列同时包含了时间特征和空间特征。空间特征是从视频帧中提取的,而时间特征是通过连续视频帧获取语义信息,且不同时序的视频帧是相关联的。
Rao等人[24]提出了一种基于人工神经网络的连续手语识别方法,操作者一手拿着自拍杆,另一只手做手语动作。为了减少噪声,操作者穿戴黑色衣服,且只有一只手在做手语动作,可扩展性和实用性不高。Ariesta等人[25]提出了一种基于3D-CNN和双向循环神经网络(Bi-directional Recurrent Neural Network,BRNN)的连续语句识别模型,3D-CNN从每个视频帧中提取空间特征,BRNN用于分析特征序列,随后生成一个可能的句子。Pu等人[26]在CVPR会议上提出了一种基于RGB视频输入的连续手语识别的迭代对齐网络,该网络模型利用三维卷积残差网络(3D-ResNet)和编码器-解码器网络,分别用于特征学习和序列建模。将3D残差网络与堆叠扩张CNN和连接主义时态分类(Connectionist Temporal Classification,CTC)相结合,用于特征提取,并在序列特征和文本句子之间进行映射。使用了一种迭代优化策略来克服CTC和CNN参数关联性差的问题。在使用CTC为视频剪辑生成一个初始标签后,对CNN进行微调以完善生成的标签。在RWTH-PHOENIXWeather数据集的实验结果表明该模型更具有优越性,其单词错误率(Word Error Rate,WER)降低了1.4%。然而,从连续视频中识别手语动作并检测其语义时间位置仍是一个具有挑战性的问题。
3 手语识别主要步骤
手语识别步骤如图2和图3所示。其中,由于动态手语识别需要获取连续帧之间的上下文信息,因此需要对手部进行跟踪。本章从图像预处理、检测与分割、跟踪、特征提取、分类等手语识别步骤进行阐述。
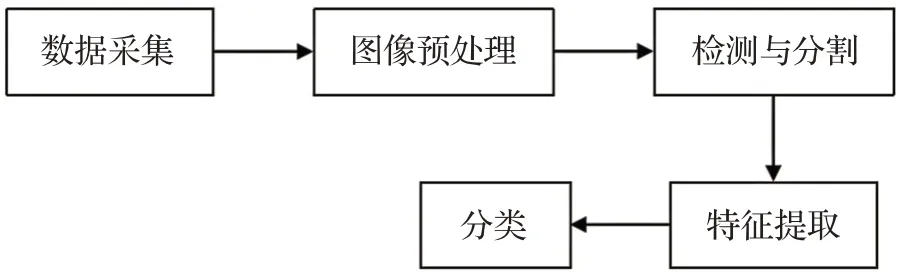
图2 静态手语识别步骤Fig.2 Steps of static sign language recognition
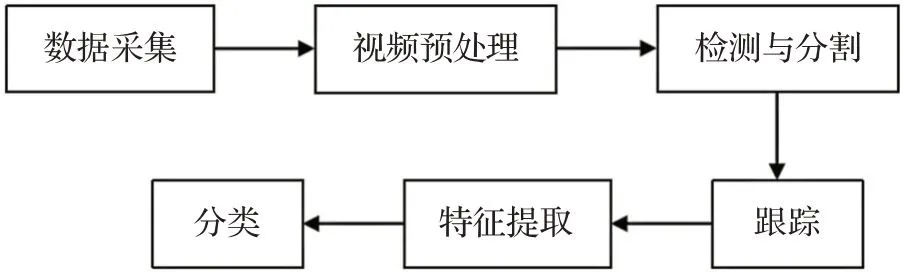
图3 动态手语识别步骤Fig.3 Steps of dynamic sign language recognition
3.1 数据采集
手语识别中的输入数据是通过图像或视频采集装置,如标准摄像机、网络摄像机、手机、微软Kinect或Leap Motion传感器等,将采集到的图像或视频传输到视觉算法中进行计算,最终得到所需信息。
Leap Motion传感器和Kinect是一种可以采集深度信息的三维摄像机,是收集手语数据的常用设备。Leap Motion传感器[27]是2013年发布的深度传感器,它将信号转换成计算机指令。作为一种基于手势的人机交互输入设备,它能够准确地检测手和手指,使用红外线成像技术实时确定有限空间内预定义目标的位置[28]。Chuan等人[29]利用Leap Motion传感器收集了美国手语字母表中的26个字母,分别使用K近邻算法和SVM进行分类。
目前常用的手语数据集,如中国手语数据集(Chinese Sign Language,CSL)是由Kinect[30]设备采集的。Kinect由RGB摄像头、深度传感器、红外线发射器等组成,可实时捕捉颜色和深度信息,并准确地获得关节位置,因此广泛应用于许多现有的手语识别方法中。其优势在于能够捕捉每个动作,并通过内置的3D传感相机将其转换为可用的特征。相较于传统的三通道彩色图像,由Kinect获取的深度图像可获取场景中的深度信息,并将其用图形化表示,每个像素点的灰度值代表物体距离摄像头的远近,数值越小表示场景距离伸向头的距离越近。
3.2 图像预处理
在图像分割和图像识别领域,一般在训练模型前需要对数据集图像进行预处理,这是因为在特征提取时,避免图像中的噪音等干扰因素很强的信息影响最后的训练结果、精度和处理时间。常用的图像预处理方法包括归一化处理、灰度转换、平滑滤波处理、降噪以及各种形态学变换等。中值滤波和高斯滤波是减少图像或视频噪声的常用技术。随着深度学习技术的发展,一些预处理方法已经融合到深度学习模型中。在手语识别研究中,通常在分割前和后续阶段会调整输入图像大小,以减少计算负载。降低输入图像的分辨率也能提高计算效率。文献[31]对Sobel边缘检测、低通滤波、直方图均衡化、阈值化和去饱和等图像预处理方法进行了性能分析和比较。实验表明,当预处理方法仅有去饱和操作组成时,取得了最佳的效果,分类精度可达83.15%。Pansare等人[32]在静态手语识别中,首先对图像进行灰度阈值化得到二值图像,再使用中值滤波和高斯滤波去除噪声,最后使用形态学操作进行图像预处理。
3.3 检测与分割
手语检测是检测图像中的手部信息,并找出图像中手部的具体位置。分割是在图像中分离出手部和其他特征,便于后续操作,有利于减少计算量,提高识别精度。分割方法通常分为两种,即上下文有关与上下文无关。上下文有关分割考虑到特征之间的空间关系,比如边缘检测技术。而上下文无关不考虑空间关系,而是基于全局属性对像素进行分组。深度学习的崛起给手语分割带来了新的契机,通过海量的数据来进行训练,自动学习目标手语特征从而完成目标手语的检测,通过检测出来的目标手语完成相应的手语分割。基于深度学习的方法与传统的识别方法相比,无需人工分析手语特征,使得分割更加便捷,在手语分割方面有较好的应用前景。但也存在一些缺点,部分网络层次结构复杂,分割速度缓慢,另一方面,部分边缘信息比较模糊,边缘检测精度有待提高。基于肤色的分割是最常用的分割方法。
Yang等人[33]在进行手部检测时,先利用人脸检测技术移除脸部区域后,采用基于肤色的检测方法得到手部轮廓。对于连续手语识别中的时间分割问题,Huang等人[34]提出了一种具有潜在空间的分层注意网络(LSHAN),该网络由三部分组成,用于视频特征表示生成的双流3D-CNN、用于桥接语义的潜在空间(LS)和基于潜在空间的分层注意网络(HAN),双流3D-CNN从视频中提取全局-局部时空特征,层次关注网络(HAN)是LSTM的一个扩展,用于将手语映射为文本序列,LS对两种信息进行整合。LS-HAN巧妙地规避了动态手语不易进行时间分割的难题。
3.4 手语跟踪
动态手语识别除了进行手部检测和分割外,还需要对手部进行跟踪来识别其动态特征。跟踪是追踪分割出的手部特征信息与时序上连续的图像帧信息相对应,以理解观察到的手部变化。成功的跟踪可以提高识别精度,从而解释手部的位置、姿势或手势所传达的语义。手的形状变化、物体遮挡或背景环境等因素使得手部跟踪更具有挑战性。常用的手势跟踪算法有粒子滤波[35]、Camshift算法[36]、Meanshift[37]算法、KLT[38]算法等。
Roy等人[39]利用肤色检测和轮廓提取技术对视频中的手语进行检测,然后利用Camshift算法对手部进行跟踪,最后利用HMM对手语进行分类。Saboo等人[40]进行手部检测时,首先对人脸进行检测和移除,然后使用YCbCr颜色空间进行皮肤过滤,三帧差分法用于检测手的运动。利用基于特征和基于颜色的跟踪方法实现手势跟踪。对KTL算法增加了特征点的数量,大幅减少了手部形状和照明条件等因素造成的影响。随后采用基于颜色的Camshift算法对手部边缘区域进行二次检测。
3.5 特征提取
将输入数据中的感兴趣部分转换成特征集称为特征提取。完成手部分割和跟踪后,需要提取图像中的特征信息。特征不但包括时间信息,还包括空间信息。动态手语识别中的特征可以分为局部特征、全局特征和融合特征。局部特征主要提取图像序列变化较为明显的局部特征点,主要包括角点、兴趣点等,旨在寻找图像中的对应点和对应区域。全局特征在深度图像的基础上提取特征,包括纹理、形状等,旨在获取图像的表征信息。融合特征主要包含全局特征和局部特征两种。Pankajakshan等人[41]利用灰度转换和阈值化方法对图像进行预处理,采用HSV颜色模型对手进行分割,Canny边缘检测算法作为图形特征提取方法。Yasir等人[42]首先对归一化后的手语图像采用高斯分布和灰度转换技术进行预处理,尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)用于从手语图像中提取特征,对获取的特征利用K-means算法进行聚类,利用SVM进行分类。基于深度学习的手语识别方法由于强大的自主学习能力无需人工提取特征。
3.6 识别与分类
手语分类是对提取的手语时空特征进行分类,是实现手语识别的最后一个阶段。用提取到的手语特征信息对测试数据集进行分类和识别。常见的分类方法有DTW、SVM、HMM和基于神经网络的方法。近年来,基于深度神经网络的方法在计算机视觉、图像处理等领域取得了重大突破。因此,基于深度学习的手语识别方法成为了主流。
4 手语识别常用方法
传统的识别方法需要针对手语数据集来训练特定的分类模型,且训练的数据量有限,不适用于大型数据集,难以推广和使用。基于深度学习的识别方法由于强大的自主学习能力和自适应性等优点,普遍应用于手语识别领域。深度学习方法可以自动提取图像特征用于自学习,学习分类强,容错性高,逐渐成为了研究人员的关注热点。
4.1 动态时间规整算法
DTW算法是基于模板匹配的方法,在手语识别中用于比较参考数据与捕捉的数据之间的相似性。Plouffe等人[43]使用k-Curvate算法在轮廓上定位指尖后,使用DTW算法来选择手势候选,并将观察到的手势与一系列预先记录的参考手势进行比较来识别手势。对55种静态和动态手势的平均识别率为92.4%。但是该方法受数据集大小的限制,在手语数量大、手势复杂和手语组合的情况下,识别效果和稳定性较差。Gibran等人[44]利用Kinect收集了20个孤立词,骨架关节点作为输入计算每个关节位置之间的最小欧氏距离,并利用DTW算法进行分类。Ahmed等人[45]首先利用基于肤色检测方法对输入数据进行二值化得到脸部和双手区域,根据连续帧之间手的方向以及距离帧中心的距离跟踪手部轨迹,然后基于分析手部位置和人脸中心的变化进行识别,并利用DTW算法计算训练和测试数据间的相似性。DTW算法没有采用统计模型框架进行训练,同时难以联系上下文的语义信息,因此在解决大数据量、复杂手势等问题时存在劣势。
4.2 隐马尔可夫模型
HMM是一种基于贝叶斯的统计模型,主要用于处理基于时间序列或状态序列的问题。早期HMM在语音识别和手写字体识别中得到了良好的识别效果。Starner等人[46-47]于1995年提出了一种基于隐马尔可夫模型的美国手语识别方法。要求操作者在两只手上戴着不同的彩色手套,对包含40个词汇的99个测试句子进行实验。实验结果表明,该方法的准确率达到90.7%。1998年,他们又提出了基于两种不同角度的手语识别方法,并使用HMM实现了基于计算机视觉的手语识别。Koller等人[48]将CNN嵌入到HMM中,该框架结合了CNN的强识别能力和HMM的序列建模能力,并在三种连续手语识别数据集上进行了验证,得到了良好的识别结果。
4.3 卷积神经网络
CNN在许多基于图像的计算机视觉任务中取得了巨大的成功,并被扩展到视频识别领域。CNN通过不同通道数的卷积层、池化层等结构尽可能多地提取特征信息,尽量减少人工设计细节,通过监督学习把计算机的计算能力发挥出来,主动寻找合适的特征数据。在机器学习中,CNN是一种深度前馈人工神经网络,其利用多层感知器的变化来达到最小的预处理,是一种共享权值架构。CNN主要分为一维、二维和三维卷积神经网络。在手语识别中通常采用二维卷积神经网络和三维卷积神经网络。
Kopuklu等人[49]提出了一种分层的双流CNN模型,通过使用滑动窗口方法对RGB和深度视频两种模式的实时手势检测和分类进行在线高效运行。其中,轻量级CNN用于检测手势,再用深度CNN对检测到的手势进行分类。Pigou等人[50]提出一种基于CNN的手语识别方法,在ChaLearn数据集中的20种单词进行识别,采用两组不同的输入数据分别用CNN提取手部特征以及上半身特征。采用滑动窗口法进行时间分割,利用人工神经网络进行分类。
三维卷积神经网络提取整个视频的时空特征,以获得更全面的信息。3D-CNN通过三维卷积,从空间和时间维度上提取特征信息,从而捕获多个相邻帧中手语的运动信息。该模型从输入帧中生成多个通道的信息,并将各个通道的信息结合起来得到最终的特征表示。Nutisa等人[51]利用Kinect收集了64个泰语孤立词作为视频流,并利用3D-CNN作为网络模型来学习时间和空间特征。Jing等人[52]提出了基于3D-CNN的多通道多模态框架,其中多通道包含颜色、深度和光流信息,多模态包括手势、面部表情和身体姿势。
Huang等人[53]提出了一种基于多模态输入的3DCNN网络模型,多模态输入包括颜色、深度和骨架关节点信息。通过对相邻视频帧进行卷积和次采样来集成多模态信息。在自己构建的25个孤立词数据集上比较了3D-CNN和GMM-HMM模型。实验结果表明,3D-CNN的准确率达到94.2%,高于传统的GMM-HMM模型。
4.4 长短期记忆网络
RNN在语音识别、机器翻译、计算机视觉等领域都取得了成功,它的一个显著的优势是能处理不同长度的输入,有效地提取帧间时序特征。LSTM作为RNN的改进,加入了一个用于判断信息是否有用的处理器,因此LSTM普遍应用于时序分类。LSTM不仅能够感应手语中的时间变化,而且还能够学习到手势变化的对应关系,从而进一步改进手语分类[54]。一些手语动作进行识别时需要较长时间,因此许多研究人员使用LSTM网络来预测手语的下一步动作。Liu等人[55]提出了以4个骨架关节点的运动轨迹作为输入的基于LSTM的手语识别模型。Xiao等人[56]提出了基于双LSTM和一对HMM的手语识别方法用于孤立词和连续语句识别,其中双LSTM用于融合手和骨架序列信息,一对HMM用于分类。
4.5 混合网络模型
基于混合网络模型的手语识别广泛应用于动态手语识别领域。其目的是利用各个模型的优点来提高识别精度。Cui等人[57]提出了一种完全基于视频序列的RNN用于连续手语识别。通过引入RNN进行时空特征和序列学习来解决视频序列和标签序列对齐问题。网络模型由4个部分组成,CNN用于时空表征学习;BLSTM用于学习特征序列与标签序列的映射;CTC作为对齐方案的目标函数;基于滑动窗口的检测网络用于正则化预测序列和检测结果之间的一致性。
Ye等人[58]提出了三维循环卷积神经网络(3DRCNN),该模型结合了3D-CNN与全连接循环神经网络(FC-RNN),其中3D-CNN从颜色、光流和深度通道中学习多模态特征,FC-RNN获取从原始视频分割的视频序列时序信息。
Masood等[59]提出了CNN和RNN混合模型,其中CNN网络Inception模型用于提取空间特征,RNN用于提取时间特征。该网络模型使用了两种不同的方法来对时空特征进行分类,第一种方法中,使用Inception模型提取单个帧的空间特征,使用RNN提取时间特征。然后,每个视频都由CNN对每个帧的一系列预测来表示。这将作为RNN的输入。第二种方法中CNN被用来训练模型的空间特征,并在池化层输出进行预测之前将池化层输出传递给RNN。得到的结果分别为80.87%和95.21%。
Zhang等人[60]提出了一种基于3D-CNN和卷积LSTM交替融合的神经网络模型用于动态手势识别,每个手势视频被分割成16个连续帧,再把这些帧序列输入到三组交替出现的3D-CNN和卷积LSTM中进行多次特征提取和预测,分别在三种数据集上进行了验证。卷积LSTM是基于卷积运算和LSTM提出的一种网络结构,它不仅像CNN一样提取空间特征,还可以像LSTM一样构建时间序列模型。
Li等人[61]提出了关键动作和联合CTC的连续语句识别模型。首先ResNet用于提取每帧的空间特征,然后用三层BLSTM从手语视频中提取关键动作的特征,逐步获得从帧到动作,从动作到单词,从单词到句子的层次关系。并引入LSTM从目标句中捕获上下文语义,联合训练CTC和LSTM来优化序列对齐和依赖关系。
根据上述提到的手语识别方法,按手语识别三个分支,可以总结出静态手语识别相关工作如表2所示,孤立词识别技术及代表性工作如表3所示,基于深度学习的连续语句识别技术及代表性工作如表4所示。
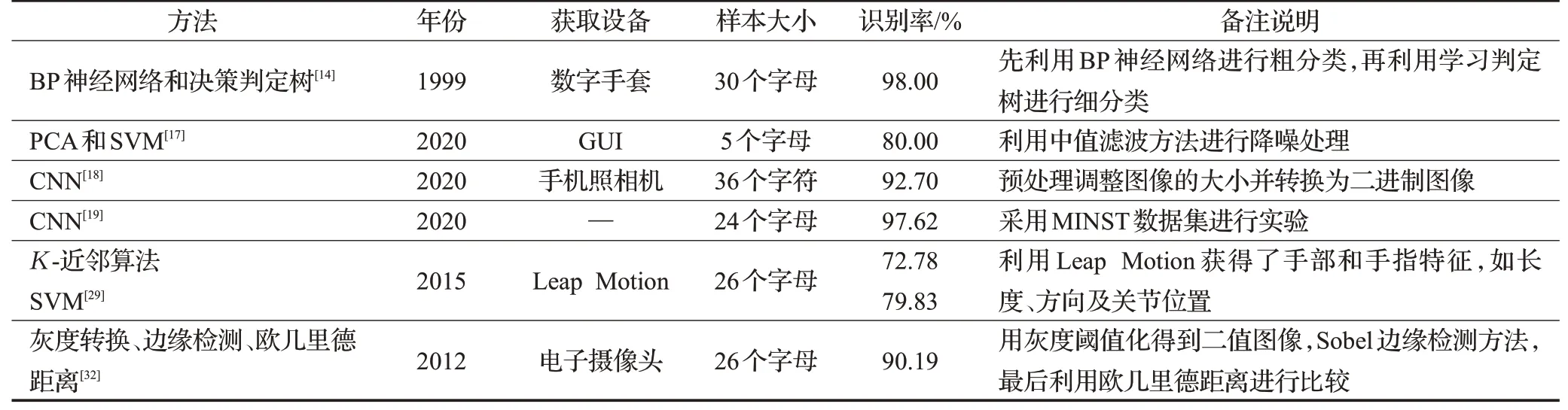
表2 静态手语识别相关工作Table 2 Summary of static sign language recognition
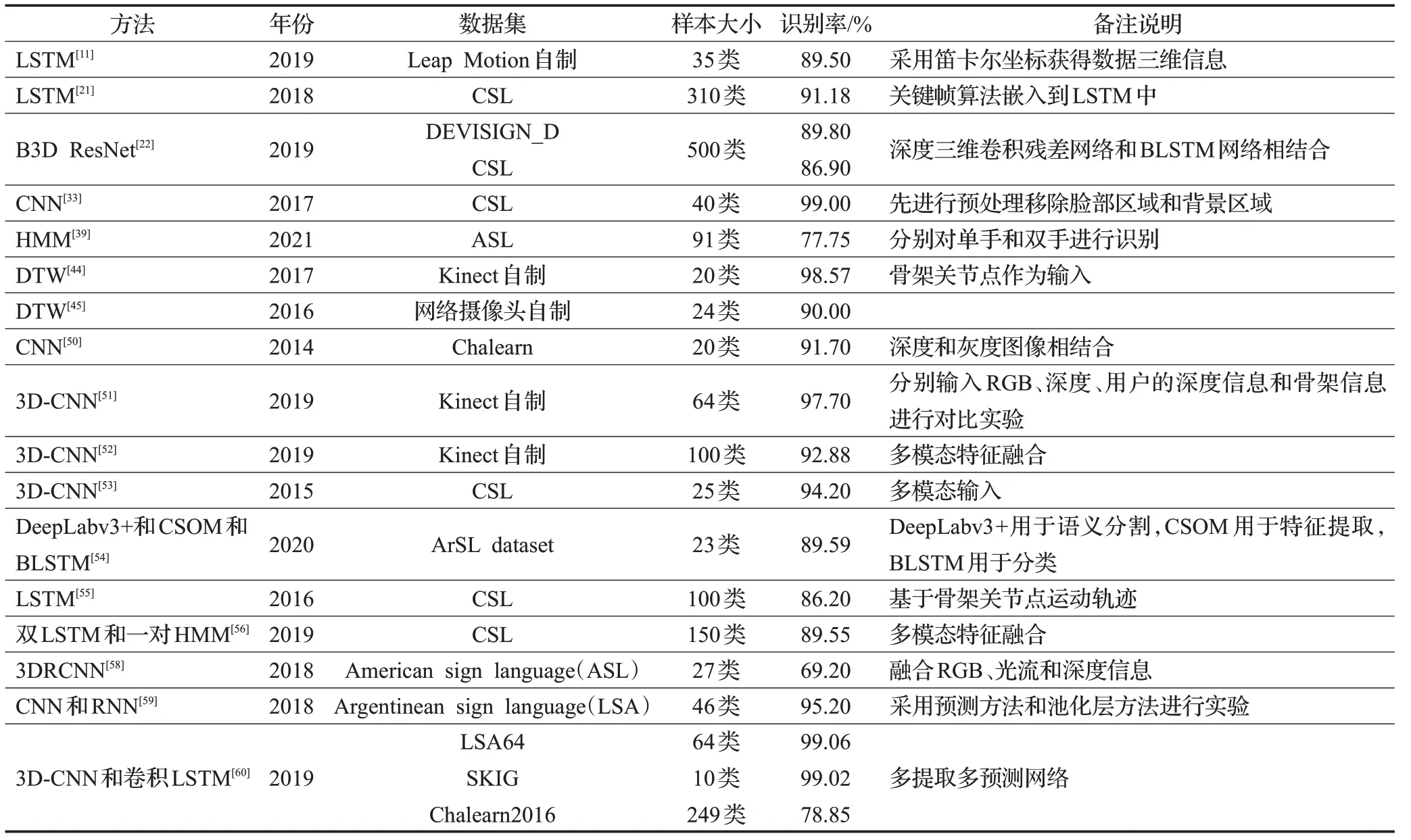
表3 孤立词识别相关工作Table 3 Summary of isolated sign language recognition
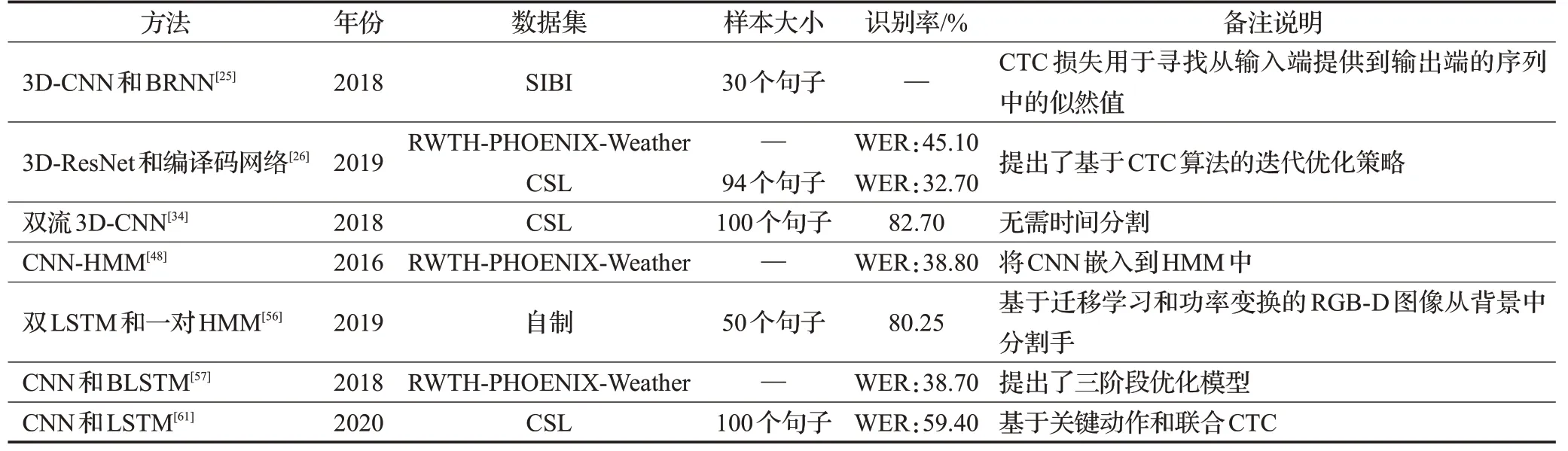
表4 连续语句识别相关工作Table 4 Summary of continuous sign language recognition
5 手语识别数据集
常用的手语数据集如表5所示。其中,CSL和RWTHPHOENIX-Weather是最常用的公开数据集。CSL是由中国科学大学于2015年采用Kinect 2.0录制的,包括连续语句和孤立词两部分,每个实例均包含RGB视频、深度视频和骨架关节点坐标序列。孤立词数据集包含500个单词,由50名操作者演示5次。连续语句包含100个句子,总时长超过100个小时,词汇量达178个,每个视频实例都由一名专业的手语教师进行语义标记。
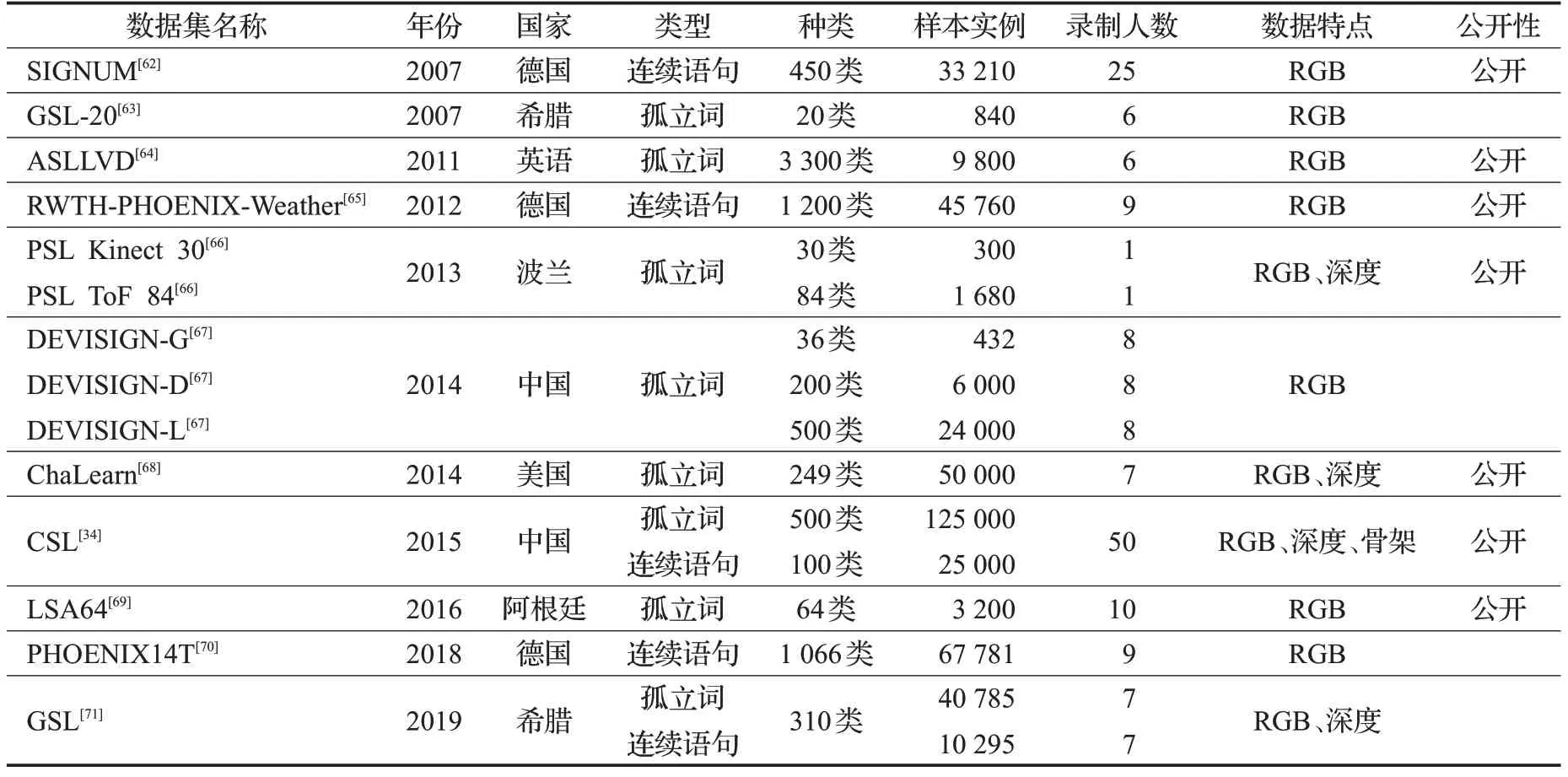
表5 手语数据集总结Table 5 Summary of sign language datasets
RWTH-PHOENIX-Weather数据集由德国亚琛工业大学录制,用于德国凤凰公共电视台每日新闻及天气预报节目的手语解说。分别于2012年、2014年录制,其中2014年版本是对2012年版本的扩充。
6 不同语种手语识别分析
6.1 中国手语识别
中国手语识别主要是在CSL数据集或自制的小型数据集上进行研究。Pu等人[72]在2016年首次将3D-CNN用于中国手语识别。作者提出了一种基于RGB视频和关节轨迹两个通道数据的手语识别框架,用于CSL中500个孤立词的识别。关节轨迹中,关注双手和肘部4个关节点,形成形状上下文特征矩阵,利用LeNet进行特征提取。在原始RGB视频中提取出70×70像素的边界框的手部区域,使用3D-CNN提取特征。最后,将这两种特征信息融合起来利用SVM进行分类。
对于连续语句识别中句子分割和单词对齐问题,Xiao等人[73]提出了双向时空LSTM融合注意力网络(Bi-ST-LSTM-A),绕过了序列分割步骤。对于输入的RGB视频,使用双流Faster R-CNN检测帧图像中的人脸和手部,分别分析全局运动信息和局部手势表示,随后将这两类信息输入ST-LSTM进行时空信息融合。注意力机制与Bi-ST-LSTM编解码框架相结合将特征序列翻译成文本句子。虽然该方法具有较高的识别精度,但训练时间较长。
Hu等人[74]提出了一种全局-局部增强网络(Global-Local Enhancement Network,GLE-Net)用于连续语句识别,并提出了一个关注非手性特征的汉语孤立词手语数据集(NMFs-CSL)。输入视频首先通过几个卷积层来进行特征提取。全局增强模块捕获全局上下文关系,而局部增强模块用于强调细粒度线索。两个模块相互促进,以相互提升。最后,通过这两个分支的融合进行预测。
6.2 美国手语识别
美国手语(ASL)是美国和加拿大英语地区聋哑人最常用的语言。Li等人[75]提出了一种新的大型美国孤立词手语数据集,数据集以互联网为主要来源,经过严格筛选和整理,包含2 000多个单词,共有20 863个视频。该数据集有119操作者参与录制,每个操作者至少演示3次。且在每个视频中,一个操作者在不同背景下演示同一个单词,这将极大提高算法的鲁棒性。文献[76]中,作者提出了一种基于游戏的实时美国手语学习应用程序原型。由于ASL字母中同时存在静态和动态符号(J,Z),因此采用基于输入序列处理的LSTM和k-近邻法的分类方法。使用Leap Motion传感器,通过提取单手的30个特征点来进行识别,准确率为91.82%。但是这项研究有几个局限性。首先,Leap Motion传感器的位置、角度和用户数量会影响模型的准确性。其次,Leap Motion传感器可以检测到多个手势,但该方法仅限于识别一个手势。最后,该方法只考虑右手样本和训练,而实际手语中需要双手来进行操作。
6.3 德国手语识别
德国手语识别主要是基于RWTH-PHOENIX-Weather系列数据集进行研究。Cui等人[77]提出了一种基于迭代训练实现连续手语识别的深度神经框架,采用具有叠加时间融合层的深度CNN作为特征提取模块,引入BLSTM作为序列学习模块。将RGB和光流数据融合作为输入在RWTH-PHOENIX-Weather-2014数据集上的单词错误率为22.86%。Koller等人[78]提出了一种针对视频流的弱监督学习方法,侧重于顺序并行学习,在三流HMM中嵌入了CNN-LSTM模型,三流之间具有中间同步约束的弱监督学习机制,三流CNN-LSTM-HMM网络分别用于学习手语标签、嘴形和手形特征。使用该方法后WER降低到26.0%。
6.4 总结
主要介绍了手语识别中最有代表性的三种手语识别。根据本文所提到的相关工作可以发现随着深度学习技术的进步,手语识别领域近年来迎来了飞速发展。由于CNN强大的特征提取能力,大多数算法都利用CNN从输入图像中提取特征。在视频输入的情况下,大多数模型中都使用了RNN和LSTM来学习序列信息。此外,一些模型还结合了两种或更多的方法,以提高识别精度。同时,模型中还使用了不同类型的输入数据,如RGB信息、深度信息、骨架关节点、光流信息等。在具体细节方面,摄像机和Kinect正在成为主要的数据获取方法,HMM和SVM是使用最多的分类方法,CNN也被广泛应用。
美国手语识别研究主要是以RGB信息为主导。自2015年以来,CSL数据集的出现使中国手语识别迅速发展。中国手语识别近年来大多使用深度信息和RGB信息相结合的方式。德语手语和大多数其他手语主要基于RGB信息进行识别。从连续手语识别研究趋势的角度来看,RWTH-PHOENIX-Weather数据集目前已成为手语识别领域的标准基准数据集。因该数据集词汇量大的优势,德国手语识别研究比较领先。中国手语识别需要考虑的一个问题是,连续语句识别滞后于孤立词识别,这将是今后的研究重点。然而无论是什么语种的手语研究,都只针对手形和时空特征,缺少对面部表情和身体因素的融合。
7 结束语
手语识别在计算机视觉,人机交互等领域有着广泛的应用潜力,一直是一项持续的研究热点。但由于以下原因手语识别的鲁棒性和准确性仍待提高:
(1)由于视频数据比图像数据规模大且复杂,在有限的GPU内存中难以有效地处理视频数据。与二维图像数据相比,视频数据中增加了时间维度,使识别难度提升。因此动态手语识别比静态手语识别更有难度和挑战性。对此,需要在今后的研究中增加模型的上下文语序衔接结构,提高模型聚合时空信息的能力。
(2)大多数现有的数据集均在实验室环境下录制,背景比较单一,难以支撑面向实际复杂环境下算法验证的应用落地。目前大多数手语识别的研究仍停留在使用公开数据集或自制数据集的层面。这种研究方式不具有泛化性,不易于推广和使用。对此,在今后的研究发展中,需要采集词汇量大、涉及范围广、且在自然环境下录制的大型连续语句数据集。
(3)在日常手语交流中,除手势之外,还会使用面部表情、唇形和头部运动等非手性特征。然而,目前绝大多数手语识别研究只关注手部姿势和位置移动,而忽略了非手性特征。因此,将手性特征和非手性特征相结合的手语识别将成为这一研究领域的重点。在手语识别中还应关注人脸、身体和手等视觉角度进行多模态集成,提高模型的泛化性。
(4)手部的遮挡、背景环境、不同的光照背景、操作者服装等因素对识别结果起到了干扰作用,但这些因素与自然环境息息相关。在今后的研究中,手语识别研究应将与自然环境相结合以提高识别的适应性和鲁棒性。
(5)嵌入到实际应用中的模型难以应用到低端设备,开发轻量级模型以方便实际使用。在应用方面,深度学习方法已成功地应用于与手语识别领域相关的许多领域,预计不久的将来,手语应用领域不仅会扩展到聋哑人,也会扩展到社会中其他依赖手语作为日常交流中语言交流的补充语言的人。因此,还有很多的改进空间,需要更多的研究和投资。
虽然已有许多模型应用于手语识别,但需要进行进一步的研究来提出精度更高且能实时应用于实际生活的模型。大多数的模型是仍停留在孤立词手语识别的范畴。然而解决连续手语识别仍存在诸多挑战,未来在连续手语识别任务中仍有较大提升空间,包括实时进行手语识别、能应用于低端设备、同时关注手性特征和非手性特征的模型。手语识别任务应结合不同领域交叉融合,构建更加轻量、准确、实时的人机交互方式。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
活力(2019年15期)2019-09-25
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
现代特殊教育(2016年21期)2016-12-14
青少年科技博览(中学版)(2015年8期)2015-10-28
实用手外科杂志(2015年4期)2015-08-27
中华皮肤科杂志(2014年4期)2014-12-19
