
联合知识与CNN的遥感影像目标检测研究综述
2021-09-26 10:42高宇歌杨海涛王晋宇李高源张长弓冯博迪
计算机工程与应用 2021年18期
高宇歌,杨海涛,王晋宇,李高源,张长弓,冯博迪
1.航天工程大学 研究生院,北京101416
2.航天工程大学 航天信息学院,北京101416
随着天基遥感技术的迅猛发展,对地观测卫星的空间分辨率、光谱分辨率、时间分辨率等不断提高,遥感技术现已成为采集地球地物信息及其动态变化的主要技术手段,可以大范围、全方位、高速率地获取全球的资源与环境信息。通过对遥感影像的分析与解译,可以实现作物分类、精细农业、水域普查、灾害监测、城市规划等多领域工作,为不同的用户服务。
遥感影像人工解译模式是几十年来遥感行业所使用的最基本的解译模式,但传统的遥感影像目视解译方法需要大量的人力物力,难以满足海量遥感数据的解译需求。随着天基遥感大数据时代的到来,智能解译模式已逐渐替代人工解译模式,成为遥感解译发展的主流方向。研究利用人工智能技术对海量遥感数据进行处理分析,将大幅提升遥感数据的利用率,推动遥感数据向遥感信息的快速转化。
目标检测是光学遥感图像分析的重要内容,是将图像数据转化为应用成果的关键一环[1]。几十年来,遥感影像目标检测技术随着遥感技术与计算机视觉技术的发展不断更新换代,形成了基于模板匹配、基于知识、基于面向对象、基于传统机器学习以及基于深度学习的五种检测方法[2]。特别是近年来基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习方法的快速发展,推动目标检测的速率与准确率迅速提升。但不同于自然场景影像,遥感影像存在数据量巨大、实例级噪声大、目标分布方向无序、目标成像表观差异大等显著特点[3],其检测任务与遥感解译等相关领域知识关联密切。因而在现阶段的研究中,已有越来越多的学者开始研究将知识融入CNN的遥感影像目标检测方法。
1 数据集和评价指标
1.1 遥感影像目标检测数据集
遥感影像数据集用于目标检测模型的训练、测试与验证,国内外诸多遥感研究团队针对不同类别的目标制作了相应数据集,其中国内武汉大学、西北工业大学等团队制作的NWPU VHR-10数据集[4]、DOTA数据集[5]、DIOR数据集[6],以及国外美国防创新部门实验室和国家地理空间情报局制作的xView数据集[7],规模较大、目标类别较多,具有代表性。
NWPU VHR-10数据集由800张遥感图像构成,影像主要来自Google Earth和Vaihingen数据集裁剪,影像尺寸最大约1 000×1 000,共包含飞机、轮船、储罐、棒球场、网球场等10个对象类别3 775个实例。
DOTA航空影像目标检测大规模数据集,为CVPR2019中Challenge-2019 on Object Detection in Aerial Images使用的数据集,由2 806张遥感图像构成,影像主要来自Google Earth、JL-1卫星和GF-2卫星,影像尺寸从800×800至4 000×4 000不等,最新的1.5版本共包含飞机、轮船、储罐、棒球场、网球场、篮球场、跑道等16个对象类别约40万个实例。
DIOR数据集由23 463张遥感图像构成,影像主要来自Google Earth,影像尺寸为800×800,共包含飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝等20个对象类别192 472个实例。
xView是世界最大的公开可用的遥感影像数据集之一,具有高分辨率、多光谱特性,由1 129张遥感图像构成,影像主要来自WorldView-3卫星,影像尺寸大约3 000×3 000,共包含60个对象类别超过100万个实例。
1.2 检测算法评价指标
目标检测问题中的每张图片都可能包含许多不同类别的物体,通过目标检测模型进行目标分类与定位后,需要评估算法的实际检测性能,主要评价指标如下:
(1)交并比
在目标检测算法中常用交并比(Intersection over Union,IoU)评价检测框与真实框之间重合程度,即两矩形框的交集与并集的比值。通常情况下对于检测框的判定都会设置固定的阈值(IoU的阈值),一般设置IoU的值大于0.5的时候,即认为成功检测目标。
(2)精度和召回率
检测精度(Precision)和召回率(Recall)是目标检测最常用的评价指标,具体计算公式如下:

TP(True Positive)表示被正确检测出的目标数量,FP(False Positive)表示本身不是目标但被错误地检测为目标的数量,FN(False Negative)表示本身是目标但未被检测出的目标数量。
(3)平均精度均值
精度-召回率曲线(Precision-Recall Curve,PRC)指的是通过设置不同的阈值,以召回率为横坐标、以精度为纵坐标构成的曲线,平均精度(Average Precision,AP)指的是精度-召回率曲线所覆盖的面积,平均精度均值(mean Average Precision,mAP)指的是每类目标计算AP值后再取平均值,mAP也是用来衡量模型目标检测性能的常用指标。
(4)Fβ指标
实际检测应用常需要综合考虑精度与召回率,因此引入指标Fβ进行阈值的选取,Fβ计算公式如下:

当设置β2大于1时,考虑召回率的影响优先于精度;反之当设置β2小于1时则更看重精度的影响;当设置β2等于1时,相当于召回率和精度的调和平均,该值亦是常用的指标称为F1值,使用时取F1最大值时的阈值即可。
(5)FPS指标
目标检测算法的另一项重要评估指标就是速度,通常使用FPS进行评估,即算法每秒可以处理的图片数量。很多目标检测算法都是在准确度和速度上进行权衡,较高的准确度往往需要较大的时间损耗。单考虑准确度不考虑速度,很难实现工程部署;而只考虑速度不考虑准确度,检测算法难以达到应用要求。
2 基于知识的目标检测方法
基于知识的方法是传统遥感影像目标检测的经典方法,该方法通过将目标及其相关的隐性知识转化为可供检测使用的显性规则,检测时通过将目标特征与生成的规则进行匹配计算,最终输出目标检测结果。基于知识的方法主要流程如图1所示。根据使用知识的不同,该方法可细分为基于几何知识的方法、基于上下文知识的方法、基于辅助知识的方法,以及联合上述知识的基于综合知识的方法。
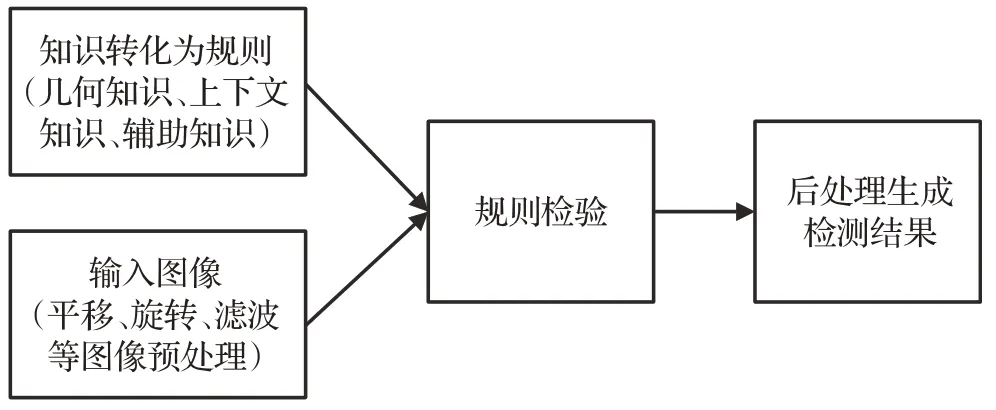
图1 基于知识的遥感影像目标检测流程图Fig.1 Flowchart of knowledge-based remote sensingimage target detection
2.1 基于几何知识
几何知识主要指目标的形状(如线形、矩形、T形、L形等)等先验知识,通过将其转化为参数检验模型,实现对道路、建筑物等形状较为规则的目标检验。Mcglone等人[8]基于建筑物几何形状具有的垂直线和水平线的知识,生成建筑物检测假设模型。Treash等人[9]基于道路的形状边缘特征,设计边缘检测器提取道路。Wang等人[10]提出了一种不依托灾前影像进行受损道路检测的方法,首先提取道路中心线,再根据道路的矩形度、纵横比等知识构建检测模型,最后结合道路损坏评估的领域知识,使用道路受损宽度比进行道路受损评估。但基于几何知识的方法对目标的几何特征过于敏感,面对影像中目标遮挡、相似纹理等情况时,常出现目标漏检、错检等现象。如影像中公路与机场跑道几何形状相似、建筑物被其他物体阴影遮挡等情况,均会影响该方法检测效果。
1.3 造模 在含有10%FBS的RPMI-1640中培育(37℃、 5% CO2培养箱)HepG2/ADM细胞,经传代后取指数生长期的 HepG2/ADM细胞,使用缓冲液稀释悬浮,稀释密度为1×109/ml,按照每只0.2 ml分别注射至每只裸鼠左侧或右侧腋部[7]。接种后1周左右可见瘤体长成,10 d左右瘤体直径约0.6 cm,造模成功[8]。
2.2 基于上下文知识
上下文知识主要指待检目标与背景环境、相邻目标之间的空间联系,如道路检测可将行道树、斑马线以及道路上的车辆等作为上下文信息,机场检测可将机场的跑道、停机坪上的飞机等作为上下文信息。Ok[11]通过引入建筑物所投射的阴影信息,使用概率方法对建筑物及其阴影之间的定向空间关系进行建模,检测阴影标识可能的建筑物区域。Wu等人[12]基于船舶与水域的空间位置关系,先进行水域分割,再根据船舶存在靠岸和离岸两种状态设计算法完成检测。Lin等人[13]结合桥梁和河流的上下文关系,提出通过阈值分割获得可能存在桥梁的水域区域,再结合长宽比、角度等桥梁特征进行检测。但基于上下文知识的方法需要明确待检目标与周边环境、目标的关系,并需要人工地选取周边有用的关联信息,同时由于增加了其他目标的检测,导致检测算法时间、空间复杂度整体提升。
2.3 基于辅助知识
辅助知识主要指地形图、高程图、定位信息以及其他多源遥感信息等,通过辅助知识与目标影像的匹配处理,能够为目标检测提供丰富的数据支撑。项盛文等人[14]利用机场的空间掩膜图像、多源遥感图像以及控制点位置等多种辅助知识,结合飞机目标的变化会导致纹理特征的变化等相关知识,实现机场飞机的变化检测。张继贤等人[15]结合已有的土地利用与覆盖矢量图与遥感影像进行配准,构建各类别遥感数据知识库,通过计算遥感影像特征统计量,检测出相应的土地利用与覆盖类别。Bouziani等人[16]利用已有的地理数据库结合先验知识生产检测规则,实现对城市建筑物的变化检测,再将变化情况滚动更新地理数据库。Mazzarella等人[17]提出将海上交通知识、自动识别系统信息与遥感影像船只检测相结合的方法。基于辅助知识的方法需要获取有效的多源信息支撑,但制作整理多源信息的过程确有难度,且地形图、矢量图等与遥感影像进行时间、空间匹配亦需要较大开销。
2.4 基于综合知识
由于遥感影像地物场景的复杂性以及目标特征的多变性,仅仅依靠单一知识进行目标检测,很难快速准确地完成检测任务。因而越来越多学者开始研究联合几何知识、上下文知识、辅助知识等相关信息的方法,通过综合多源知识信息进行交叉印证,更加准确地实现对目标的检测。
Ding[18]通过引入机场相关领域知识(如图2所示),系统梳理了跑道的形状、结构、瞄准点等12种识别特征,并根据上述特征生成不同的检测规则,然后使用视觉显著性分析、灰度模板匹配和线段检测技术分阶段实现机场跑道的提取。柴宏磊[19]从港口的形状特征、结构特征、地理位置着手,通过构建检测规则实现对候选区域的提取,再通过防波堤与港口的空间关系确定港口的位置。袁文亮[20]提出首先根据建筑物的光谱和空间特征生成形态学算子进行初检,再利用建筑物的形状、阴影等相关知识进行约束验证,有效减少目标的误检。遥感解译知识库更是基于综合知识方法的典型应用代表,通过将目标的波谱知识、几何知识、纹理知识、空间关系知识以及其他专家知识存储入库,实现目标检测的流程化、高效化。近年来许多学者通过结合专家知识建立解译知识库,实现了对自然灾害[21-22]、水体[23]以及地表植被[24]等目标的检测。但基于综合知识的方法需要收集整理较多的目标相关知识,仍需较大的时间开销,同时将知识转变为合适的检测规则亦有难度,解译知识库所需的专家成本更是难以估量。

图2 机场跑道领域知识Fig.2 Airport runway domain knowledge
3 基于CNN的目标检测方法
2012年,Hinton和他的学生Alex设计的AlexNet[25]夺得了当年ImageNet竞赛冠军,掀起了CNN等深度学习方法的研究热潮,后来的VGGNet[26]、DenseNet[27]等经典网络模型进一步优化提升网络性能。2014年,R-CNN[28](Regions with CNN features)算法率先将CNN应用到自然图像的目标检测任务中,后续Faster R-CNN[29]、YOLO系列算法的陆续出现,更是构成了当前目标检测算法的主体。在自然图像上的成功应用使得该方法被迅速推广到遥感影像中,后逐渐替代了遥感影像目标检测的传统方法并大范围应用。
根据检测阶段的不同,该方法可以具体分为基于候选区域的两阶算法和基于回归的一阶算法。基于CNN的遥感影像目标检测方法主要流程如图3所示。
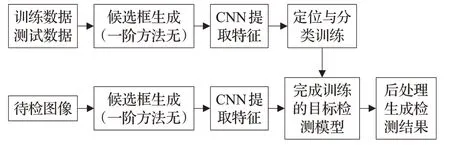
图3 基于CNN的遥感影像目标检测流程图Fig.3 Flowchart of CNN-based remote sensing image target detection
3.1 两阶检测算法
2014年R-CNN通过选择搜索算法提出候选框、CNN提取图像特征、支持向量机进行分类、非极大值抑制修正定位等系列操作,完成目标检测任务;后续SPPNET[30]在此基础上提出空间金字塔池化方法,改进候选框尺度调整问题。2016年Fast R-CNN[31]提出感兴趣区域池化(ROI pooling)、多任务同时训练的改进方法;其后的Faster R-CNN提出区域预测网络(Region Proposal Network,RPN)生成候选框的新方法,极大地改进了检测速度;R-FCN[32]则进一步将全卷积网络应用于Faster R-CNN,使得整个网络的计算可以共享。2017年FPN[33]采用了特征金字塔的网络结构,通过自底向上、自顶向下以及横向连接方法进行特征融合,解决目标检测中的多尺度变化问题;同年Mask R-CNN[34]将FPN和Faster R-CNN合并,再增加mask预测分支,能够同时实现目标检测与实例分割。2018年Cascade R-CNN[35]创新性提出使用不同IoU阈值的多级联检测器,通过逐级提高IoU阈值,使得前一级重新采样过的提议区域能够适应下一级更高的IoU阈值,进一步提高检测精度。2019年RepPoints[36]使用基于点集的新方法来替代基于锚点生成边界框的方法,提供了更细粒度的定位描述;同时使用可形变卷积与算法搭配,实现更精确的特征提取。
3.2 一阶检测算法
2016年YOLO v1[37]算法改变了R-CNN系列算法先生成候选区域再进行分类回归的思路,创造性地使用一阶网络直接进行目标检测。紧接着SSD[38]结合了Faster R-CNN的锚点机制与YOLO v1的网格思想,使用带有不同预选框锚点的多尺度特征图进行检测。2017年YOLO v2[39]在v1基础上提出使用DarkNet、设置预选框等改进策略,以及多尺度训练、多阶段训练等技巧方法;同年RetinaNet[40]首次提出Focal Loss用于解决训练过程中正负样本类别数量极度不平衡的问题,将由负样本主导的损失函数调整为由正负样本共同主导。2018年YOLO v3[41]使用优化的网络结构DarkNet-53、引入残差结构,提升训练收敛速度,缓解梯度消失;同时算法引入多特征图,融合深层、中层及浅层特征,提升多尺度目标检测能力。2019年EfficientDet[42]基于EfficientNet[43]分类网络,使用新的多尺度特征金字塔BiFPN,同时仿照EfficientNet的复合缩放方法,通过提高网络深度、网络宽度、输入图像分辨率等操作,形成了系列检测网络。2020年YOLO v4[44]在原有YOLO系列目标检测架构的基础上,采用了包括Mosaic数据增强算法、SPP扩大感受野、PANet进行特征融合等各种技巧,实现了检测精度与速度的最佳平衡。
3.3 遥感影像目标检测适应性改进
近年来在许多学者在一阶、两阶算法基础上开展遥感影像目标检测研究,并针对遥感影像数据量大、目标尺度多变、背景复杂、训练样本有限等特点难点进行适应性改造。
相比于自然图像,遥感影像背景复杂,待检目标在整幅图像中占比往往较低,且在同一影像中不同目标、同类目标均有尺度差异,造成小目标检测难及目标虚警率高等诸多问题。许多学者采取调整骨干网络、进行特征融合等解决方法,Xu等人[49]在YOLO v3上改用DenseNet增强网络特征提取能力,同时增加多尺度检测层数提高小目标检测能力;董彪等人[50]则采用了修改特征图分辨率、重新计算先验框维度等策略方法;Qu等人[51]在SSD基础上使用FPN网络结构进行特征融合、利用扩展卷积扩大特征图范围等方法进行改进。还有学者考虑到遥感影像中目标旋转角度多变,采用矩形框训练降低了实际检测精度,提出引入旋转框的方法。Fu等人[52]通过在RPN中增加预设角度的锚点框,同时进行带有方向的ROI池化等操作(如图4所示),增强了目标检测的旋转鲁棒性。

图4 带有方向的ROI池化操作Fig.4 ROI-O pooling operation
基于CNN的目标检测方法需要大量标注准确的样本,人工地进行遥感影像目标标注需要消耗大量人力物力。一些研究通过数据增强的方法提升样本数量和质量,Ren等人[53]在模型训练阶段使用随机覆盖的增强方法,并结合可行变卷积、传输连接块等改进策略,有效提升被部分遮挡目标的检测能力。还有一些研究使用半监督学习的方法,杜兰等人[54]针对SAR图像设计的方法仅需要少量的切片级标记样本,再配合较多的图像级标记样本,实现了与全监督方法近乎相同的检测性能。还有一些研究尝试使用生成对抗网络[55]、迁移学习[56]等方法,以上研究一定程度缓解了样本不足的问题,但仍需要足够的样本才能满足模型训练的需要。
4 联合知识与CNN的目标检测方法
基于知识的方法将目标的几何知识、上下文知识、辅助知识等诸多信息引入目标检测,特别是遥感解译知识库的建立将专家知识转化为实际的检测规则,能够实现对已入库特定目标的有效检测。但基于知识的方法需要大量的人工参与,检测精度尚不能完全满足工程应用需要。基于CNN的深度学习方法的出现,实现了对目标特征的自动提取,且该方法泛化性更强、检测准确率更高。但遥感图像成像范围巨大、目标种类众多,且目标与目标之间、目标与场景之间关联密切,直接套用针对自然图像设计的深度学习方法性能提升有限。近年来越来越多的学者开始探索将遥感解译知识与CNN相结合的方法,现阶段的研究主要将知识应用在改进遥感影像数据集、调整检测算法网络结构、实现目标上下文推理检测等方面。
4.1 改进遥感影像数据集
该方法在建立遥感影像数据集时即引入目标的状态信息、几何特征信息、地理位置信息、上下文信息等相关知识,通过知识的联动有效改进影像数据集包含的信息量,一定程度上突破了单一依靠改进算法结构难以提升模型检测性能的瓶颈限制。
一些研究将知识用于增强模型对目标状态的检测,俞利健[57]通过使用不同状态的电力塔影像进行训练(如图5所示),使检测模型能够实现电力塔倒塌、截断、正常等不同状态的判定,为实际的高压线运行状态检测与告警提供科学依据。但不同状态的遥感影像获取仍需专业的遥感解译知识支撑,因而一些研究探索将知识用于解决目标的小样本问题。郑鑫等人[58]同样针对电力塔问题进行研究,其创新之处在于考虑到电力塔在自然图像与遥感影像上的纹理和形状等特征的相似性,使用电力塔自然图像训练后再进行迁移学习,有效解决了电力塔遥感影像数据集的获取与标注困难的问题。还有一些研究将知识用于增强数据集信息的多样性,Wu等人[59]考虑到云、雪的存在与海拔、经纬度等地理信息密切相关,建立了云、雪检测遥感影像数据集,该数据集的创新之处在于每幅图像均包含相应的地理记录。Luo等人[60]考虑到建筑物等目标的阴影会造成其他物体的遮挡,进而影响遥感图像的解译分析,提出使用Inria[61]航空图像的数据源建立专用的阴影检测数据集。

图5 使用不同状态的电力塔影像进行模型训练Fig.5 Using images of power towers in different states for model training
4.2 调整检测算法网络框架
该方法主要通过分析目标的几何知识和上下文知识,在网络结构搭建、锚点框设计、ROI区域选择、损失函数计算等方面结合相关知识调整算法网络框架,优化算法检测性能。
为了获取更加丰富的目标特征,一些研究将上下文知识融入模型整体的网络结构设计。Zhang等人[62]设计了一种遥感影像目标检测网络CAD-Net,其中GCNet部分用于提取影像中目标与场景之间的全局上下文特征,如飞机目标与机场场景的联系;PLCNet部分用于提取图像中目标与其相邻物体之间的局部上下文特征(如图6所示),如船舶目标与邻近船舶以及靠泊码头的联系。有一些研究聚焦模型的ROI区域、损失函数进行优化设计,宫一平[63]提出结合目标的空间上下文,利用遥感影像中目标内部各部件之间、目标与周围领域之间、目标与目标之间以及目标与周围环境之间的空间位置关系,在ROI区域进行上下文扩展,进一步丰富目标的特征表达。Hamaguchi等人[64]结合建筑物与其周围道路的上下文关系,在模型的损失函数中增加道路检测损失,而且道路标签通过另外的预先训练过的模型进行提取,不需要增加额外的训练。上述研究重点运用目标的上下文知识,还有一些研究结合目标的几何知识改进模型的锚点框设计,Chen等人[65]提出根据机场跑道的形状特征修改Faster R-CNN算法的滑窗尺度和纵横比,同时引入与跑道形状相似的其他目标作为负样本参与训练,有效提升机场的检测精度。梁杰等人[66]则是针对机场跑道在不同探测视角下透视畸变检测开展研究,结合跑道前视的几何形状,改进不同形状和尺度的四边形锚框,并设计了四边形角点回归的新方法。
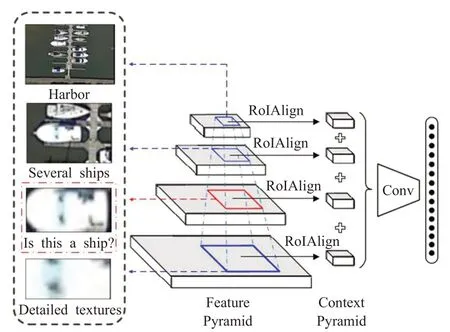
图6 PLCNet的框架结构Fig.6 Framework of PLCNet
4.3 实现目标上下文推理检测
该方法主要利用目标之间的上下文关系及相关领域知识,先使用基于CNN的深度学习方法检测出关联目标,再结合关联目标与主目标之间的包含、组成、邻接等关系进行目标的推理,间接完成主目标检测。
为了提升大范围区域目标的检测能力,一些研究通过检测区域内子目标后再进行目标推理。周伟伟[67]以道路交叉口与交通路网的上下文关系为突破点,首先训练Faster R-CNN算法模型检测道路交叉口,再使用基于图论的图像分割算法进行道路交叉口同质区域提取,获取道路交叉点中心坐标、道路分支宽度及方向等道路关键信息。Zeng等人[68]首先使用全球土地覆盖图、全球数字表面模型等辅助知识完成机场大范围筛选,再对候选区域进行飞机检测,最后结合机场与飞机的依存关系,根据飞机数量推理机场检测结果,实现了对大范围区域内机场目标的快速准确检测(如图7所示)。李圣琀[69]考虑到停车场典型特征不统一、具体区域难以界定等实际难题,先通过YOLO v3算法检测出图像上的车辆及道路,再结合停车场与车辆的空间位置关系,同时基于道路检测去除周边区域的无关车辆,推理得到图像上的停车场及停车位信息。还有一些研究结合领域知识进行深入的目标信息关联,Chen等人[70]针对运河泄漏检测问题,引入运河泄漏将影响周围区域的土壤湿度和地表温度,从而造成植被覆盖情况的变化等运河巡查员的领域知识;通过Landsat 8多光谱遥感影像导出像素级的地表温度、植被覆盖率和温度植被干度指数3项物理参数,再结合历史的运河检测记录生成对应标签进行深度学习训练,有效降低算法的时间复杂度。Chen和Zhang[71]等人针对山区滑坡检测问题,考虑到滑坡会导致地表的植物、建筑物发生变化,先使用CNN提取滑坡前后影像的特征进行变化检测,再对候选区域使用归一化差分植被指数和基于纹理的建筑物存在指数进行筛选,最后再结合坡度在7°以内区域不可能产生滑坡等知识,使用DEM信息完成后处理。上述研究均取得较好的检测效果,但采用的领域知识专业程度较高,推广复用有一定难度。

图7 根据飞机检测结果推理机场区域Fig.7 Infer airport area based on aircraft detection results
5 不同类型检测方法分析比较
基于知识的目标检测方法中,几何知识构建规则相对简单,但检测性能受相同几何形状噪音、目标遮挡等因素影响严重,虚警率较高;上下文知识则通过提高目标周边信息的利用率,缓解遮挡、噪音等因素对检测的影响,但引入其他目标增加了总体检测时间和计算量;辅助知识为目标检测提供更多的外部相关信息,进一步提高检测性能,同时实现目标的变化检测,但多源信息的匹配又增加了时间、空间开销;综合知识将上述知识进行结合使用,并引入遥感解译知识库,实现更加准确、高效的检测,但专家知识、多源信息的获取与利用都有难度。基于CNN的目标检测方法中,两阶段算法先生成候选区域再进行分类与回归,其检测精度普遍较高,但检测速度相对较慢;一阶段算法直接对影像进行分类与回归,没有显式的候选区域提取过程,其检测速度普遍较快,但检测精度相对较差。联合知识与CNN的目标检测方法中,改进遥感影像数据集在检测模型前端部分进行优化,提升了检测目标类别数量以及对目标不同状态的检测能力,同时缓解了目标的小样本问题;调整算法网络框架在检测模型中间骨干部分进行优化,重点提升目标检测精度;进行目标上下推理在检测模型后处理部分进行优化,利用知识推理间接提升了检测性能以及目标的精细化检测能力。但联合知识与CNN的目标检测方法需要足够的遥感解译与深度学习知识支撑,才能够合理高效地把知识运用于CNN检测模型。表1对上述三种方法进行了总结归纳。
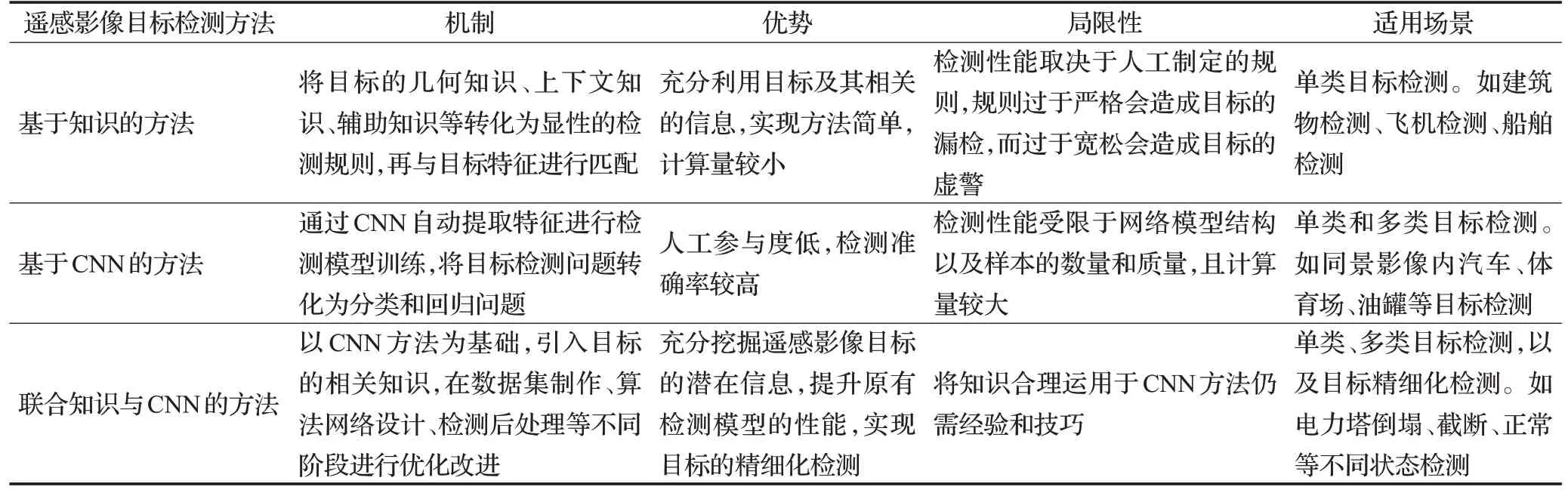
表1 不同类型遥感影像目标检测方法比较分析Table 1 Comparison and analysis of different types of remote sensing image target detection methods
6 总结与展望
遥感影像目标检测技术经过近几十年的探索发展,检测性能不断得到提升。但同时随着遥感技术的进步,成像手段不断多样、图像分辨率不断提升等新的变化带来一系列新的挑战和问题,现有的遥感影像目标检测方法仍面临以下问题:
(1)特定领域目标的小样本问题。对于遥感影像解译来说,地球上的任何物体都可能成为检测对象。而现阶段的遥感影像数据集样本多以机场、飞机、体育场、汽车等典型目标为主,针对特定领域的遥感影像样本仍有较大缺口,如工业污染监测方面,化工厂等工业目标仍无大规模、权威性的遥感影像数据集,造成后续研究进展缓慢。
(2)大型目标的精细化检测问题。目标精细化检测指的是在识别目标类别的基础上,进一步对目标的组成、状态、分布等开展解译分析,如检测到机场后需要再检测机场的跑道、候机楼、飞机、停车场等各个部分。现有的遥感影像目标检测研究大多以飞机、船舶、油罐等单个目标为主,而遥感影像本身具有图像范围大、目标种类数量多等特点,因而对于大范围区域目标的快速精细检测势必会成为未来遥感领域研究发展的重点和难点。
(3)遥感视频影像的目标检测问题。地面视频影像检测技术在行人、车辆等诸多方面已成功应用[72],近年来随着国产视频遥感卫星的快速发展,已实现通过凝视成像模式获取亚米级分辨率彩色动态视频[73],但当前遥感视频目标检测技术的研究相对较少,特别是视频影像中动态目标的检测、跟踪与定位方法仍有较大研究空间。
综合上述众多研究成果的对比分析,未来遥感影像目标检测技术可以从以下方面展开研究:
(1)针对特定目标小样本问题,采用弱监督学习、无监督学习、迁移学习加领域知识的方法开展检测模型的设计,将是解决遥感目标全领域检测的可行思路;同时生成对抗网络在图像处理领域的快速发展,将其与遥感领域知识结合生成高质量特定目标样本的方法还需探索。
(2)针对目标精细化检测问题,深入研究联合专家知识与CNN的方法将是解决上述难点的有效途径,进一步探索建立目标间的关系模型,充分挖掘现有遥感影像的潜在信息,能够为后续遥感智能解译工作提供强有力的支撑,具有非常广阔的应用前景和研究价值。
(3)针对遥感视频目标检测问题,注重借鉴改进地面视频目标检测的最新技术,探索现有深度学习方法应用于遥感影像视频目标检测的可行性,同时在检测的基础上向动目标跟踪、定位等方向进行深入研究。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
作文小学中年级(2020年6期)2020-07-24
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
自然资源遥感(2014年3期)2014-02-27
意林(2011年10期)2011-05-14
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
