
基于支持向量回归和高斯过程回归的水文时间序列特征提取方法
2021-09-26 02:04万定生
科学技术与工程 2021年25期
王 瑞,万定生
(河海大学计算机与信息学院,南京 211100)
中小河流的水文数据有时序特点和复杂性特点,水文时间序列预测前提是需要提取符合时序数据的特征,要能够学习中小河流复杂的数据特征。为了确保水文时间序列预测结果更为准确,水文时间序列特征提取成为预测工作的关键步骤。支持向量机[1](support vector machine,SVM)在结构风险最小化理论保证了其具备良好的推广能力。近年来,支持向量机模型与其他方法相结合逐渐成为研究热点[2]。
时间序列的特征提取方法有4种,分别是基于统计特征的分类特征提取、基于构建模型的分类特征提取、基于变换的分类特征提取以及基于分形理论的特征提取。基于统计量的特征提取方法是最直接的特征提取方法,提取时间序列数据在统计学上的特征构成特征向量,统计特征有两种:时间域与频率域。时间域特征包括均值、峰值、方差、均方根和峰值因子等[3];基于构建模型的分类特征提取方法是将提取时间序列特征等价于提取模型因子,首先分析数据特点,并根据已完成分析的不同的数据特点构建不同的模型[4],如针对相对稳定的时间序列数据,可以通过自回归滑动平均模型提取特征,针对相对不稳定的时间序列可以对数据进行神经网络建模,利用神经网络模型演化求解代表时间序列数据变化的特征;基于变换的分类特征提取方法,将时间序列特征数据在不同域中映射变换,时域和频域的变换是比较常见的域变换,使得显著特征在特定维度凸显,典型的域变换有傅里叶变换和小波变换[5];基于分形理论的分类特征提取方法是针对符合递归生成原则和自相似结构特点的现象,如自然界中广泛分布的分形现象如水位线,河流的流向等进行理论分析,利用分形理论对时间序列数据进行特征提取时,将时间序列数据转换成信号,分析信号在特定尺度下的可分形特征[6]。
然而,在实际展开水文时间序列预测研究中,基于构建模型的分类特征提取方法应用居多,采用经典神经网络建模提取特征[7];或者直接选用距离预报前时刻4 h或距离预报前时刻6 h作为基本特征[8],缺少对水文时间序列特征提取的更深层更细致研究。
水文时间序列特征选择是典型的迭代优化问题,神经网络的参数训练也是迭代问题,同时神经网络参数训练是一个比较耗时的过程,如果使用神经网络计算特征选择过程的误差,求解这组特征组合等价于双层神经网络优化问题,时间复杂度较高。
因此,基于构建模型的分类特征提取方法,现提出一种基于支持向量回归和高斯过程回归的水文时间序列特征提取方法,首先列出水文时间序列候选特征,并随机组合特征,不同特征组合下,分别对训练数据进行支持向量回归建模与高斯过程回归建模,利用遗传算法演化求解一组目标特征组合,使得支持向量回归和高斯过程回归输出误差同时最小。以屯溪流域水文时间序列数据进行实验分析。
1 相关研究
1.1 支持向量回归
给定i个水文时间序列样本数据集{xi,yi},xi为训练样本输入,yi为训练样本输出,φ(xi)为xi通过非线性映射函数将低维特征映射到高维特征空间H的特征向量,f(xi)对应的最优超平面为
f(xi)=wTφ(xi)+b
(1)
式(1)中:w为法向量;b为偏置量。
当且仅当f(xi)与yi完全相同时,记为损失为零,SVM认为此时学习到的超平面最优。与此不同,支持向量回归(support vector regression,SVR)[9]引入松弛因子ε,并定义当f(xi)与yi之间的差别绝对值大于ε时才计算损失,当f(xi)与yi之间的差别绝对值小于ε时认为学习到的超平面为最优。SVR问题形式化为

(2)

约束条件为

(3)
最终得到函数表达式为
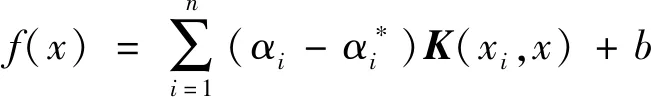
(4)

1.2 高斯过程回归
高斯过程回归(gaussian process regression,GPR)[10]基于高斯过程先验对数据进行回归分析。高斯过程回归模型包括回归残差和高斯过程先验两个内容。假设一个存在残差的回归模型。其计算公式为
Y=f(X)+ξ
(5)

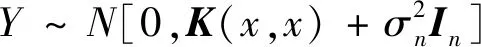
(6)
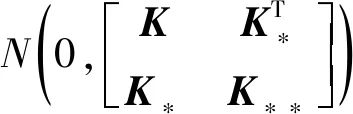
(7)
式中:In为n维单位矩阵;K(x,x)=(xij)为对称正定协方差矩阵,xij通过核函数度量xi与xj之间的相关性;K(x*,x)=K(x,x*)T为训练集x和测试集x*之间的协方差矩阵;K(x*,x*)为测试集本身的协方差矩阵。平方指数核函数具有无穷可微的特点,使高斯过程回归平滑,因此选用平方指数核[11]。其计算公式为
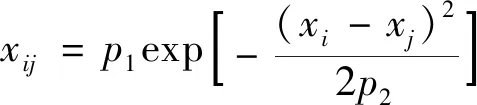
(8)
式(8)中:p1、p2为高斯函数中的可调参数。预测值y的后验分布为

(9)

(10)
1.3 遗传算法
遗传算法(genetic algorithm,GA)[12]是一种自适应全局搜索最优解的迭代算法,基于生物进化论自然选择和遗传学机理的生物进化理论,模拟自然进化过程,即保留遗传过程中优势特征,淘汰劣势特征。
遗传算法中问题的每一个候选解被编码成染色体个体,若干个个体相互排列组合构成若干个群体,即所有可能解。遗传算法在迭代开始时,首先随机产生一个初始解,根据设定的目标函数对单个个体进行评估,计算此时的适应值,根据适应值对个体进行轮盘赌选择策略、交叉运算、选择操作等操作产生新一代种群,对产生的新一代种群进行适应度计算评估,直至达到目标函数优化终止条件。
遗传算法过程图解如图1所示。
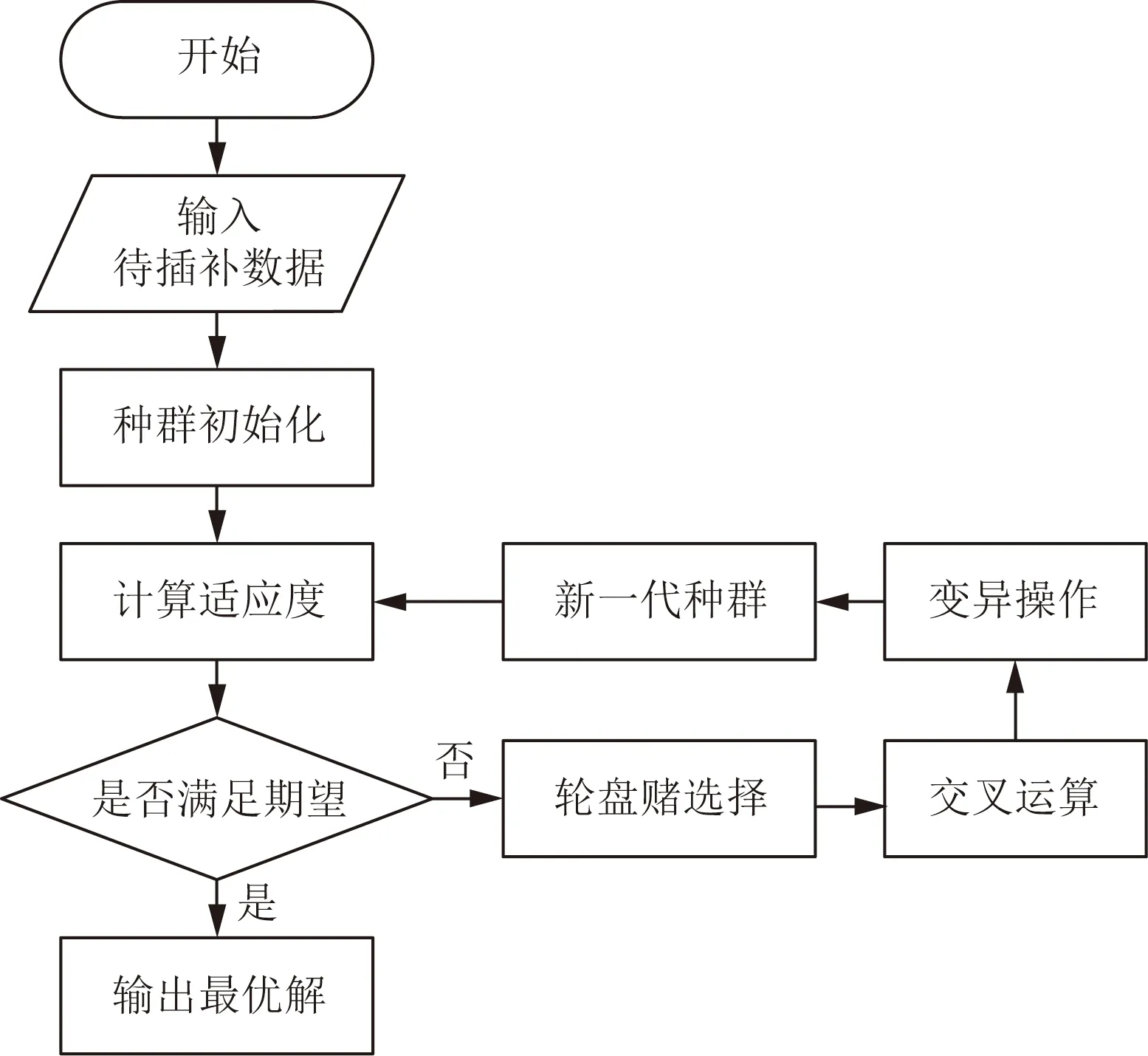
图1 遗传算法过程图Fig.1 Genetic algorithm process diagram
2 基于支持向量回归和高斯过程回归的水文时间序列特征提取方法
基于支持向量回归和高斯过程回归的水文时间序列特征提取方法架构总体分为两部分。
模块一:从屯溪流域屯溪水文站获取原始水文数据,将水位时间数据按照相等小时时间间隔排列,构造待插补数据输入序列,构建Stacking集成学习法,Stacking集成学习小波神经网络和支持向量机对数据分析的结果,将待插补水位数据序列输入已构造好的Stacking学习模型中,输出插值补充好的完整的水文时间序列。
模块二:将插补好的水文时间序列作为特征提取的输入,首先对数据集逆行归一化处理,然后分别构建支持向量回归模型和高斯过程回归模型,利用遗传算法迭代求解最优特征组合。
基于支持向量回归和高斯过程回归的水文时间序列特征提取方法架构图如图2所示。
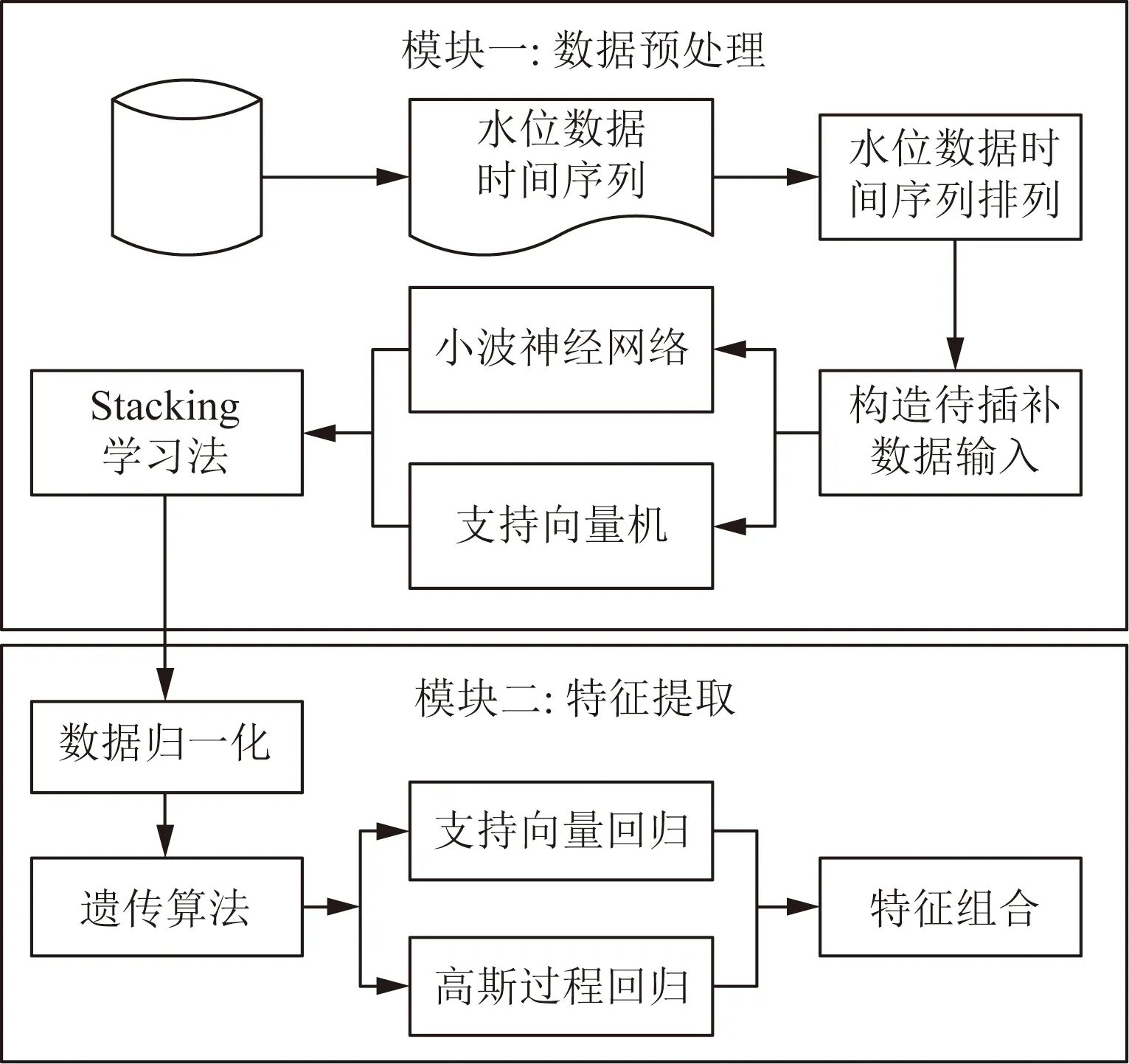
图2 特征提取方法架构图Fig.2 Feature extraction method architecture diagram
2.1 水文时间序列特征提取方法原理分析
水文时间序列的连续性是把某一时间段内水文数据按整点时间的连续性进行排列,须保证整点时刻均为有效数据。中小河流原始水文数据缺失情况普遍存在,提出采用Stacking集成学习法,融合小波神经网络(wavelet neural network,WNN)[13-14]模型和支持向量机(support vector machine,SVM)模型,预测待插补水文数据空缺值。具体实现算法如算法1所示。
算法1
输入:待插补水文时间序列观测数据集D={(x1,y1),(x2,y2),…,(xm,ym)};
输出:预测值result
1:输入X(m)
2:数据归一化
/*本实验采用0-1标准归一化*/
3:fori=1,2,…,mdo
4:WNN预测;
5:end for
6:fori=1,2,…,mdo
7:SVM预测
8:i++;
9:end for
10:Stacking融合WNN模型&SVM模型
11:做出预测结果
12:输出待插补预测数据
在特征提取过程中,将水文时间序列数据输入,列出水文时间序列候选特征,置为0或1两个状态,0代表舍弃当前特征,1代表选择当前特征,列出特征组合的所有解,将求解最优特征组合问题等价于0-1规划问题,并对水文时间序列数据分别构建支持向量回归模型和高斯过程回归模型,利用遗传算法迭代求解一组最优特征组合。具体实现算法如算法2所示。
算法2
输入:水位时间序列数据X(l);
输出:最优特征组合Fj;
Fj表示距离当前预报时刻的第j个时刻
1:输入X(l)
2:水位时间序列数据进行数据归一化
/*本实验采用0-1标准归一化*/
3:GA种群初始化
4:轮盘赌选择、交叉和变异
5:GA演化
6:计算适应度fitness
7:SVR建模&GPR建模
8:if fitness=Min(RMSE)
9:else go to 6
10:输出最优特征组合Fj
3 实验
3.1 实验准备
以屯溪流域为中小河流代表流域进行研究,屯溪流域地势西高东低,气候湿润。屯溪位于新安江上游,新安江上游多为峡谷,河形弯曲,右岸靠山,左岸河谷平原,经新安江上游率水、横江两溪汇流以后成为屯溪。屯溪流域地形图如图3所示。
中小流域的水文数据受水文数据观测仪器精度,地理环境和气候环境因素等影响,中小河流数据记录缺失和数值缺失现象普遍存在。
采用Stacking集成学习法,融合小波神经网络模型和支持向量机模型预测水文数据空缺值,预测水文缺失数据,并将完整的水文时间序列结果作为输入数据。

图3 屯溪流域地形图Fig.3 Tunxi basin topographic map
选取屯溪流域屯溪水文站2020年5月1日00:00—6月2日1:00的水位时间序列数据,时间间隔1 h。前620条用于训练,提取水文时间序列特征;后154条数据用于测试,将提取的水位特征应用于水位预测,测试本方法所提取特征在水文预测中的表现能力。水文时间序列数据的输入格式如表1所示。

表1 输入数据格式Table 1 Input data format
模型参数的设定是模型成功的重要因素。通过暴力破解算法穷举法,设初始种群个数为20,交叉率为0.5,变异率为0.5,种群迭代次数为100次。
3.2 实验准备
(1)均方根误差。采用均方根误差(root mean squared error,RMSE)作为特征选择评价指标。即RMSE越小,则本次特征提取越具有代表性。其计算公式为

(11)
式(11)中:n为测试样本总数;yi为预测值;Yi为真实值。
(2)决定系数。决定系数R2度量自变量解释比例,反映回归方程拟合优程度。其中。R2越接近1,说明数据拟合效果就越好。其计算公式为
(12)
3.3 实验结果与分析
对于选定训练数据集进行水文时间序列特征提取,将距离预报时刻前10 h水位特征进行提取,被提取特征结果为[1,2,5,6],表示将预报时刻前第一个小时,第二个小时,第五个小时,第六个小时水位数据作为数据特征,应用于水文时间序列预报。水文时间序列特征提取结果如表2所示。

表2 水文时间序列特征筛选结果表Table 2 Table of hydrological time series feature extraction
将预报时刻前第一个小时、第二个小时、第五个小时、第六个小时的水位数据作为特征输入数据,未来1 h的水位Yt+1作为输出进行预报,即
Yt+1=f(Xt-6,Xt-5,Xt-2,Xt-1,Yt)
(13)
为了使实验对比更明显,利用CNN单一神经网络方法提取的历史水文时间序列特征,所筛选特征表示为Xt-4,Xt-3,Xt-2,Xt-1,结合LSTM应用于水文时间序列预测,其预测结果如图4所示。
基于支持向量回归和高斯过程回归建模,并用遗传算法演化出一组水文时间序列特征组合,将筛选出的这组特征与水文时间序列作为输入数据,通过相空间重构将低维时间序列转换成高维时间序列,并结合长短期记忆(long short-term memory,LSTM)神经网络对其进行水文时间序列预测。其预报结果如表3所示。
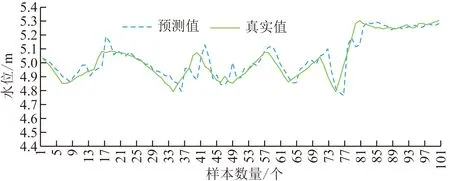
图4 CNN特征提取方法预测结果Fig.4 Prediction results of CNN feature extraction method
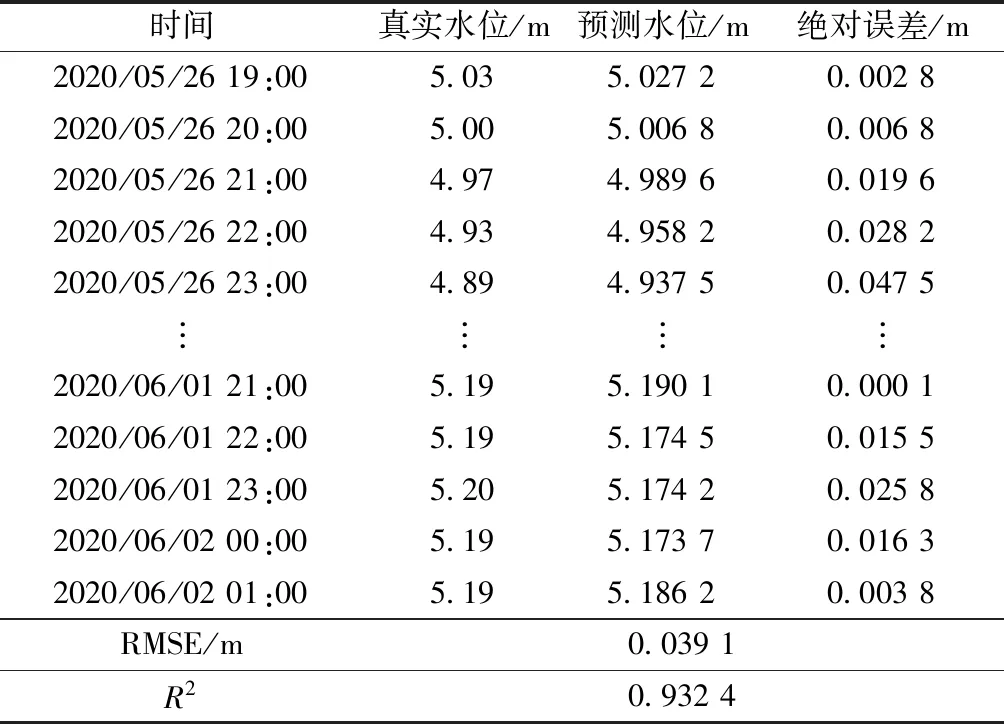
表3 支持向量回归和高斯过程回归方法的水位预测结果Table 3 Table of hydrological time series method based on SVR_GPR
为了使实验效果更清晰,选出101条预测结果进行展示,经支持向量回归和高斯过程回归特征提取方法应用于水位预测结果如图5所示。
将基于CNN提取的水文时间序列特征与基于支持向量回归和高斯过程回归提取的特征用于水文时间序列预测,并将其预测结果进行对比,同时选择RMSE和R2对上述两种提取方法进行模型参数检验,得到的参数统计结果如表4所示。
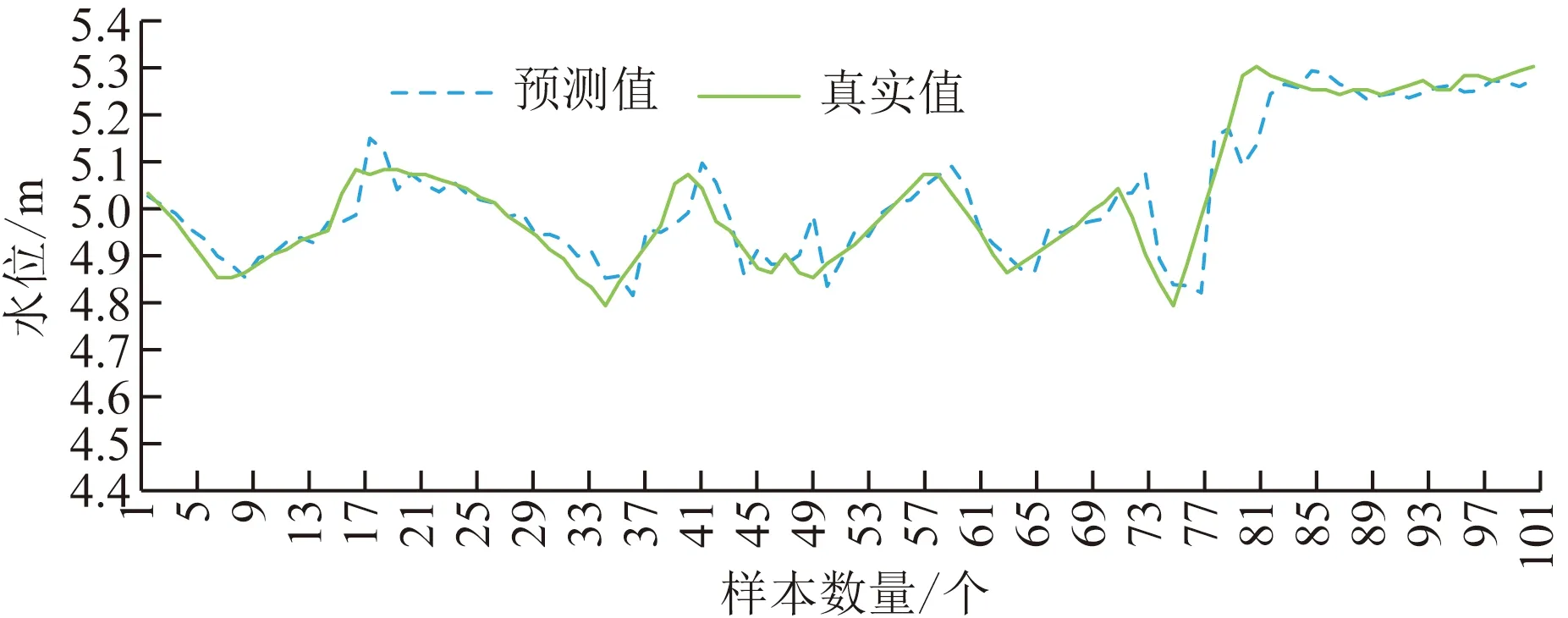
图5 支持向量回归和高斯过程回归特征提取方法预测结果Fig.5 Predicted results of SVR-GPR method

表4 不同特征提取方法预测结果对比Table 4 Table of comparison of prediction results of different feature extraction methods
4 结论
提出的基于支持向量回归和高斯过程回归的水文时间序列特征提取方法,对屯溪流域水文时间序列数据进行应用分析。基于支持向量回归和高斯过程回归的水文时间序列特征提取方法,避免神经网络优化遗传算法不断寻参的过程,采用支持向量回归模型和高斯过程回归模型对水文时间序列进行建模,将双层网络优化简化为单层优化问题,大大提高了水文时间序列特征筛选的时间效率,在水文时间序列预测上具有实际的应用意义。
实验结果说明,基于支持向量回归和高斯过程回归的水文时间序列特征提取方法依赖于水文时间序列变化趋势,不同于直接选用预报前几个小时的数据作为特征输入数据,通过这种提取水位特征方法,能及时有效地捕捉影响当前水位的高度相关特征,并将提取的特征结果结合神经网络应用于水文时间序列预测,大大提高了水文时间序列预测的精准度,同时为水利信息化建设提供一些实质性的方法捕捉水文时间序列特征。
研究将从对水文时间序列进行汛期与非汛期不同周期出发,研究汛期与非汛期的水文时间序列特征提取,找出水文时间序列预测中的更具普适性的水文时间序列特征。
猜你喜欢
现代经济信息(2021年3期)2021-11-23
陕西档案(2021年2期)2021-05-21
北京航空航天大学学报(2019年9期)2019-10-26
小天使·二年级语数英综合(2019年4期)2019-10-06
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
小学生学习指导(低年级)(2019年6期)2019-07-22
电子制作(2018年19期)2018-11-14
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
电影故事(2015年16期)2015-07-14
