
基于被动DNS流量的Fast-Flux域名检测方法
2021-09-26 05:08刘纪伟
南京邮电大学学报(自然科学版) 2021年4期
张 玉,刘纪伟
(国家计算机网络与信息安全管理中心河北分中心,河北石家庄 050000)
近年来,随着网络犯罪技术的不断发展,僵尸网络(Botnet)已经成为互联网上最突出的威胁来源之一。根据国家互联网应急中心(CNCERT)发布的《2019年中国互联网网络安全报告》,CNCERT抽样监测结果显示,2019年,我国境内存在的木马或僵尸程序控制服务器IP地址的数量为14 320个,我国境内共有近600万台IP地址的主机被植入木马或僵尸程序[1]。黑客攻击者利用僵尸网络实施各类恶意活动,比如传播恶意软件(如勒索软件、木马等)、发送垃圾邮件、进行分布式DDOS攻击等。僵尸主机通过发送DNS数据包与攻击者控制的服务器建立通信,并从服务器接收指令进行网络恶意活动。为了逃避检测,很多大型僵尸网络使用一种称为Fast-Flux服务网络(FFSN)的技术应用来逃避技术手段对恶意域名的检测。FFSN一般是由大量被控制的计算机组成,通过不断变化域名服务器的解析结果,以大量被控制计算机的IP作为域名服务IP[2],从而避免IP检测等技术导致的服务不可用。Fast-Flux服务网络核心目的是为一个Fast-Flux域名分配多个(多达几百甚至上千个)IP地址,通过快速更换Fast-Flux域名所对应IP地址来达到防止被追踪的目的,进而隐藏最终恶意服务器的真实定位。
Fast-Flux技术是僵尸网络常用的一种DNS防追踪技术,主要分为两类:Single-Flux技术和Double-Flux技术。Single-Flux技术是只有一层变化的Fast-flux,模式相对简单,底层域名服务器通过不断变换域名对应的IP地址列表,返回频繁变化的被控制计算机的IP地址,由于这种模式只有一层,相对容易暴露。相对于Single-Flux技术,Double-Flux是一种更加复杂的Fast-Flux技术,它多了一个附加层,通过更改权威名称服务器(Authoritative Name Server)记录来增加误导,这在恶意软件网络中提供了额外的冗余层和可生存性,检测起来更加困难。
内容分发网络(Content Delivery Network,CDN)和循环 DNS(Round Robin Domain Name System,RRDNS)是Web服务器用来实现高可用性和负载平衡的两种主流技术,CDN和 RRDNS访问DNS流量的特征行为与FFSN技术的特征行为非常相似。CDN是由分布在不同地理位置的边缘节点服务器群组成的一种分布式网络,当客户端对采用CND技术的域名发起访问时,域名服务器会通过为客户端提供附近服务器的IP地址集来实现。在RRDNS中,通过将Web服务器的主机名映射到多个IP地址,这种映射以循环方式不断变化,使某个域名的权威域名服务器将工作负载分配到多个冗余Web服务器上,客户端每一次发出DNS查询请求,都可以获取不同顺序的给定主机名的IP地址列表。在实际网络中,访问采用CND和RRDNS这些合法技术的域名也会存在DNS服务器向客户返回多个IP地址,而且TTL值也很低。因此,如何有效区分FFSN和其他两种技术,减少误报率,成为一个亟待解决的问题。
1 相关研究
Fast-Flux的概念是在2007年由Gadi提出的,2008年 7月,德国蜜网项目组(The Honeynet Project)对Fast-Flux技术展开了完整和详细的研究[2],系统介绍了 Fast-Flux工作原理、分类、特点等,之后针对Fast-Flux域名的检测方法的研究持续开展起来。综合分析大量文献,已有针对Fast-Flux的检测方法的研究主要分为以下2种:
(1)主动域名数据获取
主动域名数据获取是通过采集者向域名服务器发送DNS请求并记录相应的DNS响应记录来实现,记录内容包括比如被解析IP地址、TTL值、NS记录等。基于主动域名数据获取的策略已被广泛探索。Holz等[3]对FFSN网络开展了试验性研究,总结了FFSN和CND的差异并提出了Fast-Flux域名的检测方法。Passerini等[4]分析提取了FFSN的9个特征将其用于FFSN检测,特征包括域名注册时间、注册商、A记录、TTL值等。国内最早开展FFSN相关研究是在2009年汪洋[5]构建了A记录数、IP分散度等4个特征作为检测向量,提出了一个Fast-Flux域名检测机制。褚燕琴等[6]从多个维度对Fast-Flux恶意域名的行为特征进行了全面分析,并进一步开展了特征辨识度的分析和研究。主动获取方式简单灵活,但是获取的数据被局限,有很大的偏向性。这种方法简化了FFSN检测,但需要解析可能与恶意活动关联的域名,而且会耗用大量的内存,无法做到在线快速实时检测,在面向企业网络监控的实施中存在相应的缺陷[7]。
(2)被动域名数据获取
被动域名获取方式主要是通过在DNS域名服务器部署相应的数据获取设备或者软件来得到包含DNS请求或应答记录的日志文件。被动获取的方式获取的数据一般范围较广,随机性强,具有更加丰富的特征和统计特性,在恶意行为的检测中被普遍使用。被动检测方法既可以减轻网络设备的负担,又可以准确地实施检测,已经成为目前的热门检测方法。Bilge等[8]提出了基于被动DNS的恶意域名分析与检测系统EXPOSURE,实现了对恶意活动中的恶意域名进行检测。Perdisci等[9]对DNS流量进行了大规模的被动分析,他们从DNS流量中提取一些相关的特征,并通过C4.5决策树分类器对域名进行分类。周昌令等[10]从域名的时间性、增长性、多样性、相关性等方面共提取了18个特征,构建了一种基于随机森林算法的Fast-Flux域名识别模型。Lombardo等[11]提出一种分析企业网络DNS流量的检测方法,基于静态指标和历史指标来对数据进行评估,检测恶意流量。牛伟纳等[12]结合卷积和循环神经网络,提出了一种基于流量时空特征的速变域名僵尸网络的检测方法,这种方式省略了特征提取过程,但是算法复杂度较高。 Al-Duwairi等[13]提出了一种带有RBF内核的SVM算法,并使用3种类型的人工神经网络对PASSVM进行评估。
2 特征选取
为了将 FFSN网络与 CDN以及 RRDNS等(FFSN网络检测的主要挑战)合法网络区别开来,根据FFSN特点[10],本文提出了以下8个关键特征。虽然,通常情况下FFSN的TTL值一般都很小,但是并不认为TTL值是一个好的特征参数,这是因为合法的域名(如通过CDN技术托管的域名)在适应网络拥塞或服务器中断的速度方面与FFSN有类似的要求,它的TTL值有时也会很小。
(1)域名解析IP的累计数量NIP
由于单个节点的可靠性较低,相比CDN,Fast-Flux技术通常使用大量IP地址。在DNS查询中返回A记录(IP地址)累计数量是衡量Fast-Flux攻击流动性的一个简单指标。在大多数Fast-Flux攻击中,域名服务器将返回5个或者更多的IP地址。然而,合法的域名通常不需要返回许多IP地址。在每次Fast-Flux攻击中,与恶意流量域名关联的不同的IP地址数量都在增加。经过很长一段时间后,域名解析IP的值NIP可以达到数百或数千。但普通合法网络的NIP累积值不会持续增加。显然,NIP是一个用来确定流量是否合法的非常有用的度量标准。
(2)最大回答长度MA
由于Fast-Flux域名单个A查询返回的IP地址数量一般要高于合法域名,选取单个A查询中IP地址数量的最大值MA来作为一个特征。
(3)ASN累积数量NASN
合法的域名,甚至是通过CDN托管的域名,往往只返回一个或者少数特定ASN(自治系统编号)记录。相比之下,FFSN网络因为受感染的机器分散在不同的ISP上,它们通常属于不同的自治系统,有着不同的ASN。所以,在一段时间中,所有“A”记录的累计自治域ASN数量NASN是衡量Fast-Flux流量攻击的一个简单度量。
(4)IP在不同AS中分散的程度DASN
对一些初步的Fast-Flux数据包的分析表明,尽管ASN绝对数量在一般情况下非常有用,但在某些情况下,ASN的绝对数量并不是一个特别明显的特征,而其与IP数量NIP的比值更合适。为此,本文定义了量化IP在不同AS中分散程度的度量指标DASN。 这个量的取值范围从DASN~0(当所有的IP都在同一个ASN并且IP的数量很大时)到DASN=1(当每个IP都在不同的ASN时),表达式为
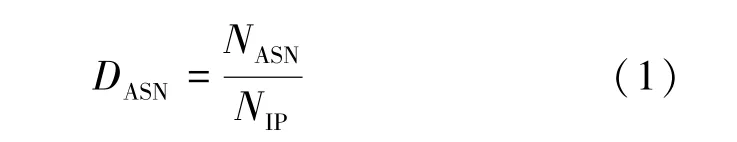
(5)IP所属网络分散的程度EIP
一个恶意的Fast-Flux域名往往被解析到许多不同网络的不同IP地址。与该域名相关的不同网络数量越多,主机就越分散,并被用作Fast-Flux恶意域名的概率就会越大。本文引入信息论中熵的概念来表示解析IP地址集的分散程度,计算IP地址的16 bit前缀(IP/16)的熵,熵越大,IP地址集越分散。假设IP地址集的集合为P,IP的16 bit前缀x在集合 P 中所占的比例为 p(x),p(x) = count(x)/|P|,count(x)表示IP地址的16 bit前缀为x的个数,则IP所属网络分散的程度表示为
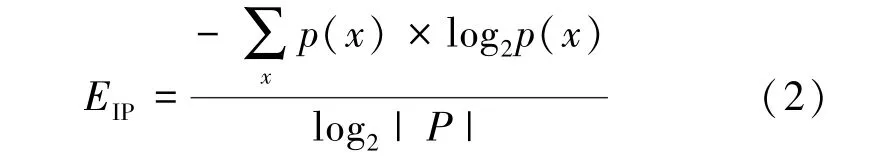
(6)域名服务器记录数量MNS
单次DNS解析中的NS域名记录数量是衡量Fast-Flux攻击的一个简单指标。在Double-Flux攻击中,母体Mothership在FFSN网络中托管他的权威名称服务器,由Mothership控制的恶意DNS服务器为了发动Fast-Flux攻击,往往会返回多条NS记录。相反,合法域名在单个DNS查询中只返回少部分NS 记录[14]。 因此,在一次 DNS 查询中,Fast-Flux 域名的NS记录比合法流量攻击域的更多,选取检测时间内单次查询中域名记录数量的最大值MNS来作为检测特征。
(7)IP池的变化情况CIP
IP池指某域名解析IP地址的集合,合法域名要提供正常网络服务,必须用合法的IP解析地址,这些解析IP地址多是稳定的服务器,IP地址相对固定,即便更换,IP地址替换的范围也在有限数量的地址池内。FFSN由于单个节点的可靠性较低,为了保持可用性,FFSN通常占用更多IP地址资源,这些IP通常是缺乏保护的终端主机,在线时间不稳定并且可能随时离线,FFSN必须在生存期间继续快速添加新IP。所以一般认为FFSN的IP池不断发生变化。假设检测时间为T,将检测时间T均分n个时间切片,记为Ti,i的取值为1~n,表示第i个时间段Ti中IP池IP数量。是一个基于历史的指标,表示某个域名在所有时间段IP池中IP数量的平均值。
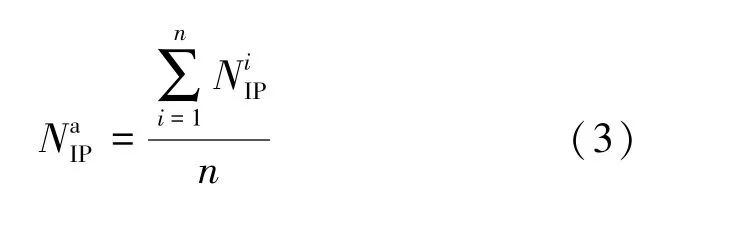
NIP是检测时间为T内,域名解析IP的累计数量,本文定义了一个度量标准,以一种非常简单的方式度量IP池中的变化
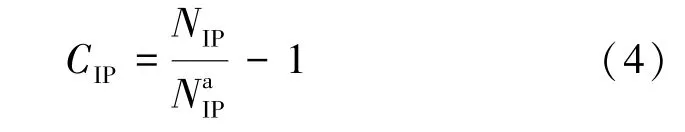
如果IP池稳定,每个时间段IP池数量和内容都一样,那NIP和相等,CIP为0。当IP池从一个时间段到另外一个时间段发生了很大的变化,则域名解析IP的累计数量NIP一定会大大超过,从而导致CIP变大。
(8)ASN池的变化情况CASN
对合法域名解析出的IP地址分布一般都比较统一,ASN数量较少,变化也缓慢。而Fast-Flux恶意域名因为被控计算机分布的不确定性,往往位于不同的自治系统,随着时间的变化,ASN池集合也会发生较大变化。对照IP池集合的变化CIP,提出ASN池集合的变化CASN,是某个域名在所有时间段IP池中ASN数量的平均值。

3 检测流程和算法分析
3.1 检测流程
根据上文的特征属性分析以及Fast-Flux恶意域名的检测需求,Fast-Flux域名的检测流程如图1所示。

图1 基于实时特征的FFSN检测流程方法
(1)数据过滤
1)协议过滤。首先基于53端口号和UDP协议获取DNS数据包。
2)黑/白名单的过滤。采用基于黑/白名单的过滤方式缩小相对庞大的DNS流量,如果当前数据包的数据与黑白名单中的记录相匹配,则不再检测。白名单选取Alexa前10万条域名以及本地常用合法域名,黑名单为已知Fast-Flux恶意域名。
3)基于实时特征的过滤。根据对Fast-Flux域名可用性模型的研究[5],当 TTL大于1 800 s时,Fast-Flux网络的可用性概率接近为零。因此TTL大于1 800 s的查询将被过滤。
(2)流量检测
这是FFSN检测的第二阶段,主要是针对上一阶段过滤出来的剩余流量进行准确分析与检测。利用机器学习算法和训练数据构建检测模型,然后对过滤后流量进行特征向量提取,选取的特征内容见第2节特征选取,使用训练好的检测模型对提取出来的特征向量数据集进行检测,得出被检测的域名是否为Fast-Flux恶意域名。
3.2 算法分析
3.2.1 算法概述
决策树算法是机器学习算法中一种非常经典的分类方法,主要优点是模型简单直观,具有可读性,分类速度快,但是决策树算法一般容易产生过拟合问题,导致模型的泛化能力不强。虽然可以通过剪枝方法解决模型过度拟合的问题,但是会增加算法的复杂性。随机森林算法是利用训练数据产生很多棵决策树,形成一个森林,然后每次从森林中选择若干棵树进行预测,选择结果最多的作为预测结果。随机森林算法因为引入了随机性,不容易发生过拟合,分类准确率较高,能够有效地在大数据集上运用。一般来说,随机森林算法的判决性能优于决策树算法,拥有广泛的应用前景[15-16]。综合随机森林算法的以上优点,本文选用随机森林算法作为恶意域名的识别算法。
随机森林采用的典型决策树的算法主要有ID3算法,C4.5算法以及CART算法等。ID3算法是一种最早提出的传统的决策树算法,它的核心是在决策树的各个节点上利用信息增益准则来进行特征选择,递归地构建决策树。ID3算法的优点是实现简单,构建速度快,但是这种算法由于使用信息增益来选取特征,使得有一种倾向性,偏向选取取值较多的特征,而这个特征并不一定是最优的。C4.5算法是目前较主流的一种决策树算法,它对ID3算法进行了改进优化,用信息增益率取代信息增益值来进行特征选择,从而避免了ID3算法中的归纳偏置问题。在树的构造过程中能够完成对连续属性的离散化处理,而且可以通过剪枝操作进行优化,缺点是相对于ID3算法,计算复杂度略高。CART算法也是一种常用的决策树算法,它是使用基尼系数作为数据纯度的量化指标来构建决策树,既可以用作分类,也可以做回归。目前,随机森林算法最常用的决策树算法是C4.5和CART算法,分别基于信息增益率和基尼系数来进行特征选择,由于信息增益率和基尼系数都是特征选择的重要指标,本文选择信息增益率和基尼系数的线性组合作为节点分裂的指标。
3.2.2 基于随机森林算法的检测模型构建
(1)模型训练整体流程
1)随机样本集选择:假定随机森林要建立M棵决策树,每棵用于训练的决策树都是通过随机、Bootstrap有放回的从全部训练数据中选取和原始数据集相同的训练数据集,此要求是为了防止每棵树用于训练的数据一样,从而导致训练出的每一棵树都一样。
2)随机特征集选择:对决策树每个节点向下进行分裂时,用Forestes-RI方法从待选K个特征中随机选取n个特征,n的取值一般为log2K+1,使得森林中的每棵树都可以彼此不同,从而提升分类性能。
3)特征选择,构建决策树:从特征子集中选择最优分裂特征和分裂值来建立M棵决策树,组成随机森林。
4)结果输出:汇总M棵决策树的分类结果,概率最大的一个分类结果为最终输出结果。
(2)决策树节点分裂指标构建
对于随机森林中常用的决策树算法:ID3算法、C4.5算法以及CART算法,决策树特征选择的对应指标主要有信息增益、信息增益率和基尼系数。在随机森林算法中,普遍选择信息增益率或者基尼系数作为节点分裂指标。
1)基尼系数
基尼(Gini)系数表示某特征下包含属性的杂乱程度,一般来说,总体内部纯度越高,基尼系数越小,内部包含越混乱,基尼系数越大。假设某节点样本集为S,包含样本的种类数目为k,pi为某节点中某类样本数目和该节点中样本总数的比值,则该节点的基尼系数为
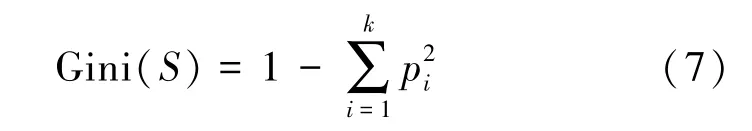
如果样本集S被某个特征T划分为两个子集T1和T2,S1为子集T1中样本数量,S2为子集T2中样本数量,划分后的基尼系数为
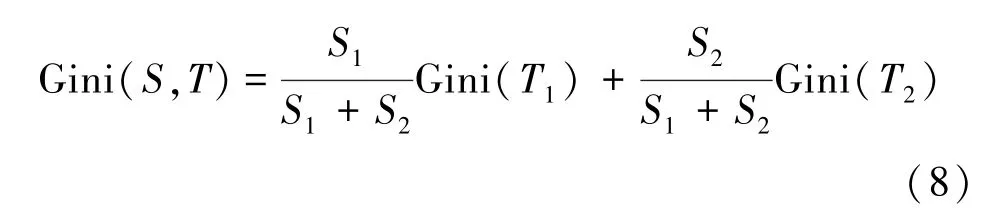
2)信息增益率
信息增益(Gain)是在信息熵的基础上得来的,表示在某个条件下,信息复杂度(不确定性)的减少程度。由于信息增益作为特征选择指标容易产生多值偏向性的问题,在信息增益指标基础上引入了信息增益率指标。对于特征T,它的信息增益率GainRatio(T) 表示为
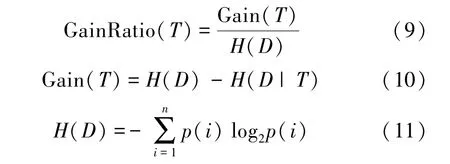
其中,H(D)表示数据集D的熵值,H(D|T)为确定了特征T之后数据集的熵值,Gain(T)表示信息增益,表示在确定特征T之后,对应数据集熵值的减少程度。
3)基于线性组合的节点分裂指标构建决策树
由于Gini系数和信息增益率都是节点分裂的重要指标,本文在节点分裂时,选择Gini系数和信息增益率的线性组合作为特征选择的指标,表达式为
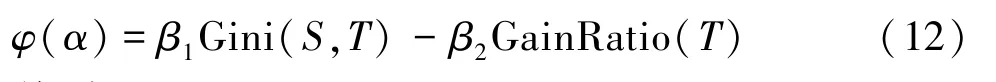
其 中,βi(i=1,2) ∈ (0,1),Gini(S,T) 和GainRatio(T)分别表示基尼系数和信息增益率,计算分别见式(8)和式(9)。 选择φ(α)值最小的特征作为节点分裂选择特征。
对于连续型特征,需要将连续性特征转换为离散属性再进行下一步处理。假设训练数据包含N个样本,从任意两个相邻样本数据之间寻找分类点,计算每一个分裂情况的φ(α),取值最小的作为分裂点即可。
3.2.3 评估方式
本文选择召回率(Recall)、精确率(Precision)以及准确率作为提出方法的标准评价,表1对评估过程所需要参数做了定义。

表1 评估参数
4 实验结果与分析
4.1 实验环境
由于网络流量数据量较大,本实验需要处理的数据较多,需要系统具备较好的运算能力和响应处理能力,硬件环境配置如表2所示。

表2 实验环境参数表
4.2 数据集选取
本文实验数据集采用的是ISOT数据集[17],数据集包括公开的恶意数据集和非恶意数据集。恶意数据集是从德国蜜网项目(The Honeynet Project)中获取的,主要包括Strom和Waledac僵尸网络流量数据。非恶意数据集表示非恶意的日常使用流量,由两个不同的数据集合并而来,分别是来自匈牙利爱立信研究中心交通实验室以及劳伦斯伯克利国家实验室(LBNL)的数据集,包含来自各种应用程序的大量通用流量、流行的 bittorrent客户端(如Azureus)流量以及企业网络流量等。数据集中数据分布情况如表3所示。
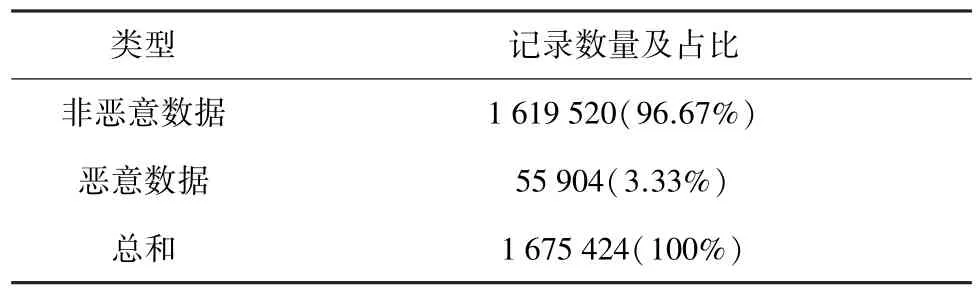
表3 ISOT数据集记录数量
首先对数据集数据进行数据预处理,从数据集中提取协议类型为DNS协议的数据类型,然后针对响应报文数据包进行特征向量提取,形成实验数据集。
4.3 算法对比实验
为了确保对比效果的有效性,采用10折交叉验证(Cross Validation)的方法进行检验,实验均值为模型得分。在决策树节点分裂指标上,将本文提出的Gini系数和信息增益率的线性组合作为结点分裂指标的方法与文献[9]采用的C4.5决策树算法、文献[10]采用的传统随机森林算法以及文献[13]采用的SVM算法进行比较,比较的指标为3.2.3节评估方式中的3个指标,如图2所示,在召回率(R)、精确率(P)和准确率(ACC)上更有优势。
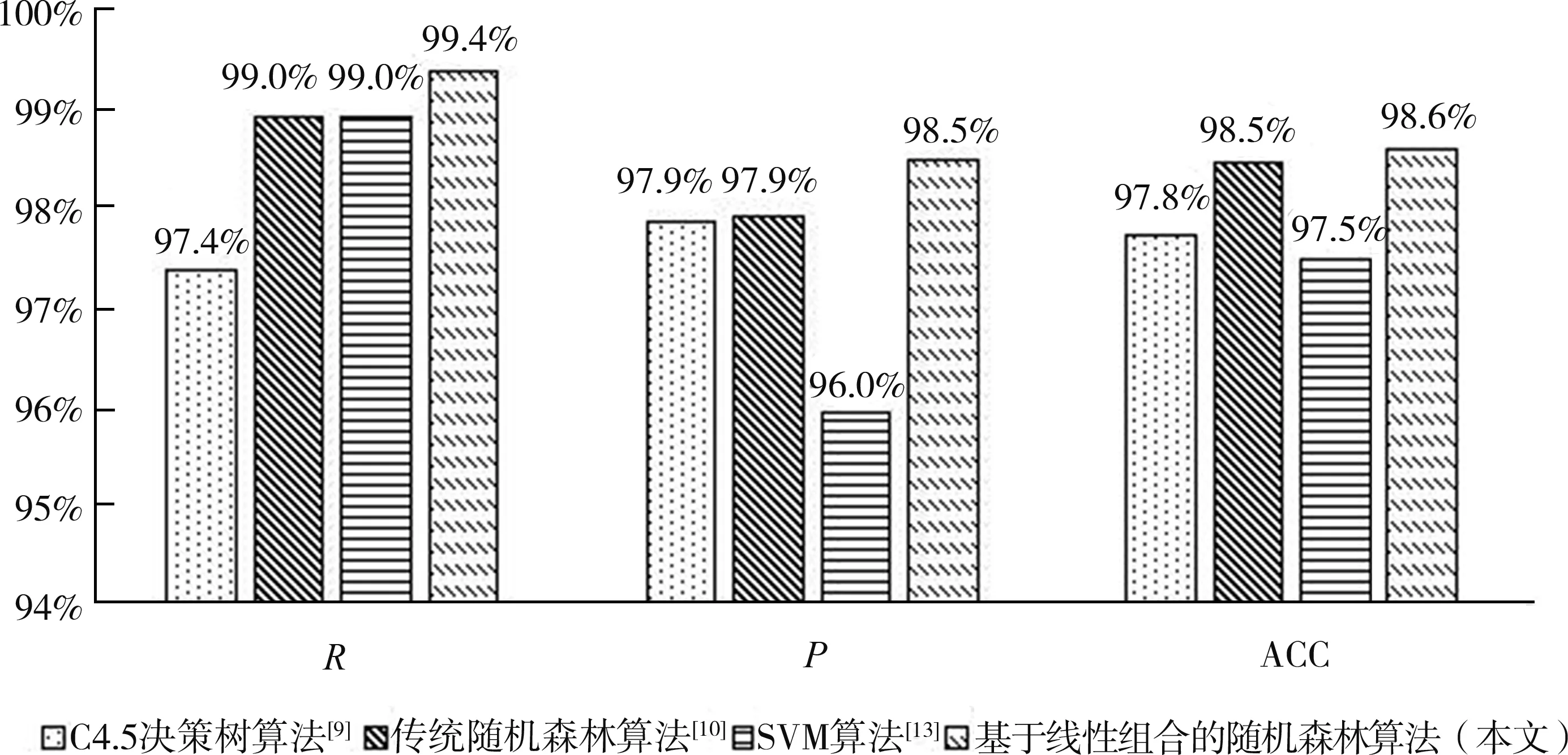
图2 不同算法效果对比结果
4.4 现网数据测试
本文选取基础电信企业DNS服务器日志数据作为现网测试数据,将测试数据分为5组,选取数据如表4所示,经过数据过滤环节,进行特征提取,然后使用建立好的检测模型对5组测试数据流量进行检测,得出分类结果。
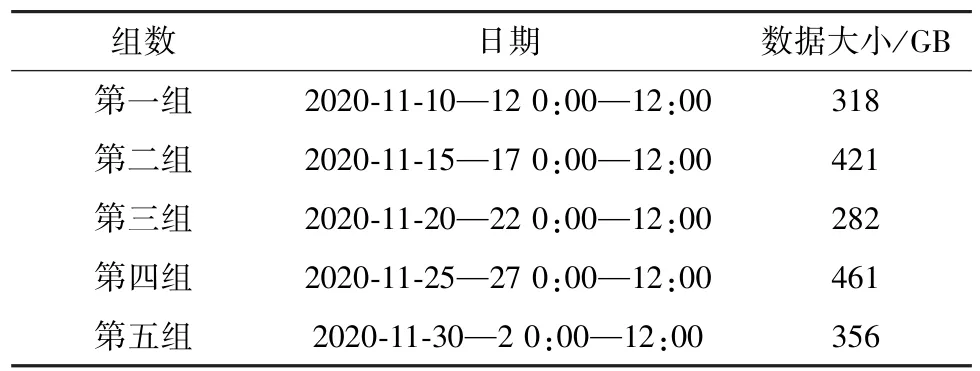
表4 实验数据
以第一组数据为例(2020-11-10—12 0:00—12:00),通过DNS协议、黑白名单过滤、域名特征过滤后的DNS日志约有54 244 904条。因为数据量过大,选择1 h为一个检测周期,通过模型检测,最终发现如下疑似Fast-Flux恶意域名,如表5所示。
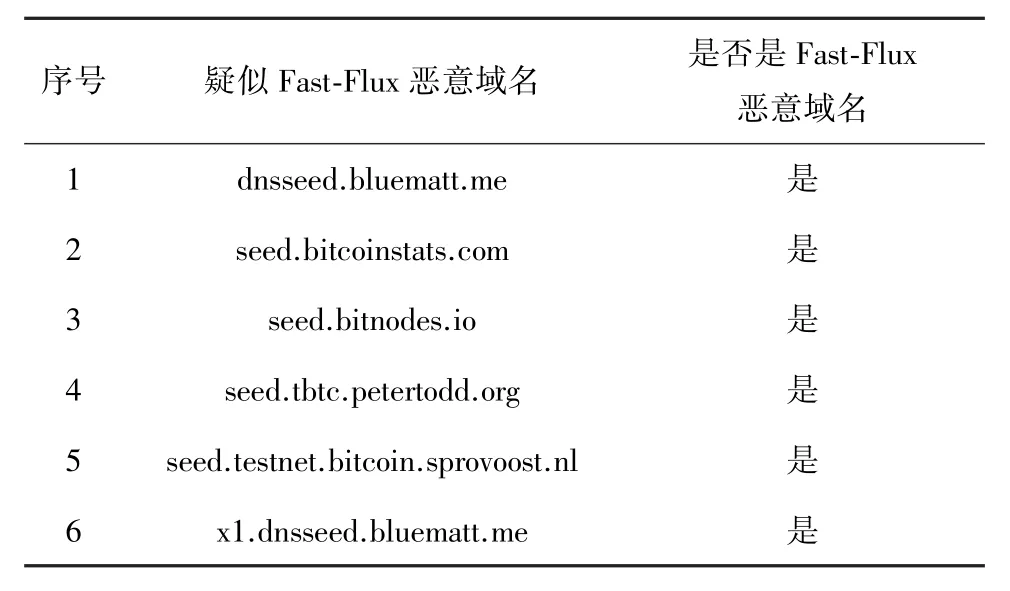
表5 疑似Fast-Flux恶意域名
实验结果是否是Fast-Flux恶意域名是通过特征分析以及恶意域名网站验证的方法来验证的,但是virustotal.com和微步(x.threatbook.cn)等恶意域名网站在很多情况下,只能标记域名是否是恶意,但是没有对恶意域名是否是Fast-Flux恶意域名进行分类,而且对于一些新出现的域名,存在是Fast-Flux恶意域名,但是没有进行标记的情况,所以,本文验证方法采用先用恶意域名网站验证,如果标记为Fast-Flux恶意域名,验证结束,否则再以特征分析进行验证。
以x1.dnsseed.blue matt.me域名为例,对其特征进行分析,表6为在实际数据中该域名在DNS服务器221.5.203.108和221.7.92.108上得到的解析IP的情况

表6 疑似Fast-Flux恶意域名解析情况
观察其请求的具体行为,他们解析IP地址数量相比正常域名返回的解析IP地址数量多,ASN码和网络分散程度也比正常域名的多,IP在不同ASN中分散的程度很大,存在较为明显的Fast-Flux僵尸网络中恶意域名的特征。
通过特征分析以及恶意域名网站验证的方法来验证实验结果是否是Fast-Flux域名,分别计算5组现网测试数据精确率。通过验证,该检测方法精确率的平均值为92.32%,模型的处理速度可以达到5 947条/s,一天数据的检测时长约为6 h,达到较好的检测效果。实验证明本文采用的检测特征数量较少(8个),提取简单,但是实际运用效果很好,不存在模型复杂度过大的问题,而且计算复杂度较小,更适合实际环境应用。
5 结束语
本文针对Fast-Flux技术进行研究,提出了一种基于被动DNS流量的Fast-Flux恶意域名检测方法。首先,基于DNS协议、黑白名单、DNS流量实时特征对流量数据进行过滤,然后,构建了识别Fast-Flux网络的8个简单有效的特征集,采用基于Gini系数和信息增益率的线性组合的随机森林算法建立相应的识别模型,进行Fast-Flux恶意域名检测。最后,将基础电信企业DNS服务器日志数据作为实验数据,证明了系统的有效性。本文的局限性在于Fast-Flux恶意域名的公开数据集较少,本文采用的ISOT数据集中Fast-Flux恶意域名数据集较小,导致训练数据集规模较小,检测模型的性能可以进一步提升。
猜你喜欢
数码世界(2020年4期)2020-06-18
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
科学中国人(2017年14期)2017-01-28
中国信息技术教育(2015年22期)2015-09-10
新课程·上旬(2014年6期)2014-08-22
决策与信息·下旬刊(2013年1期)2013-03-11
