
社交网络用户隐私泄露量化评估方法*
2021-09-24 11:12:28谢小杰王梓森董祥祥
计算机工程与科学 2021年8期
谢小杰,梁 英,王梓森,董祥祥
(1.中国科学院计算技术研究所,北京 100190;2.移动计算与新型终端北京市重点实验室,北京 100190; 3.中国科学院大学计算机科学与技术学院,北京 101408)
1 引言
社交网络应用正逐渐成为人们生活中不可或缺的一部分,具有信息类型多样、规模庞大和共享公开等特点。由于社交网络中大多数用户隐私保护意识薄弱,通常会公开性别、所在地和职业等个人信息,网络攻击者可以很容易地获取大量用户数据,挖掘用户隐私信息,造成用户隐私泄露,威胁个人财产和人身安全。因此,开展社交网络用户隐私泄露量化评估的研究,不仅有利于帮助用户了解个人隐私泄露状况,提高公众隐私保护和防范意识,同时也能为个性化隐私保护方法设计提供依据,为隐私保护效果评估提供支持。
目前,社交网络用户隐私泄露量化评估主要面临2个挑战:
(1)如何设计社交网络隐私泄露量化评估方法。现有隐私量化评估方法被广泛应用在通信系统[1]、基于位置的服务LBS(Location Based Ser- vices)[2,3]和社交网络[4]等领域,常用于评估隐私保护方法的保护效果[5,6],无法对社交网络用户的隐私泄露风险进行有效的量化。
(2)如何对隐私泄露进行多视角的量化和分析。目前社交网络用户隐私泄露量化的研究一般将隐私偏好设置作为评估隐私泄露风险的依据[7 - 9],而社交网络包含丰富的用户数据,仅关注隐私偏好设置这一主观因素不足以全面地对用户进行评估。
为了解决目前研究中的挑战,本文提出了一种社交网络用户隐私泄露量化评估方法,设计了属性敏感性、属性公开性和数据可见性指标,量化评估用户的隐私泄露风险。在新浪微博数据上,基于量化评估指标对用户进行了多视角的量化分析,有效地评估了用户的隐私泄露状况。主要贡献包括:
(1)提出了一种社交网络用户隐私泄露评估方法,支持用户隐私泄露风险的量化与评估。
(2)设计了属性敏感性、属性公开性、数据可见性和隐私评分的量化指标,支持多视角量化评估。
2 相关工作
目前隐私量化评估相关的研究主要分为3类:基于信息熵的方法、基于隐私保护效果评估的方法和基于用户隐私偏好设置的方法。
在基于信息熵的方法中,信息熵通常用于度量信息所包含的信息量,熵值越大表示包含的信息量越大[10]。在通信领域,Diaz等[1]利用信息熵来量化匿名通信系统的匿名性,值越大表示确定消息的发送者或接收者真实身份的难度越大,系统的匿名程度越高,隐私保护状况越好。在LBS领域,真实位置通常被视为隐私信息。Hoh等[3]基于信息熵量化位置轨迹隐私,保证位置轨迹的匿名性。Ma等[11]基于信息熵量化V2X(Vehicle to X)车联网系统的隐私泄露状况。在社交网络领域,用户属性信息或身份特征通常被视为隐私信息。Ngoc等[4]基于信息熵量化社交网络用户待发布信息中包含的隐私量,通过检索用户发布的信息中的属性值关键词来推测用户属性的概率分布。Yang等[12]提出了一种基于信息增益的隐私量化方法,通过信息增益确定用户身份,信息增益越大,用户身份泄露风险越大。
在基于隐私保护效果评估的方法中,隐私量化评估方法通常用于衡量系统或数据的隐私泄露状况,主要针对隐私保护方法的保护效果优劣进行评估。k-匿名模型[5]通过限制数据表中的准标识符(用户属性等信息)至少和其他k-1条数据相同,使每条数据被识别的概率降低至1/k。l-多样性[6]使得满足同一个k-匿名集中的数据至少有l种类型来进一步降低数据被链接攻击和同质攻击的风险,l值越大说明数据的隐私风险越低。差分隐私[13]基于隐私预算参数ε,在原始数据上加入随机噪声达到隐私保护的目的,ε值越小说明隐私风险越低。Backstrom等[14]针对匿名社交网络数据,用能被攻击者去匿名化的人数来评价匿名效果,人数越多则隐私泄露风险越高。Narayanan等[15]用攻击者对用户去匿名化或者识别用户隐私属性出错的概率作为隐私量化指标,攻击者出错的概率越大说明隐私风险越低。Agrawal等[16]通过计算原始数据和扰动数据之间的互信息来量化隐私泄露风险,互信息越大,则隐私泄露风险越高。Chen等[17]提出了一种针对用户属性特殊性的量化指标IS(Information Sruprisal),用户属性值越特殊,则IS值越大,隐私泄露风险越高。
基于用户隐私偏好设置的方法一般将用户的隐私偏好作为评估用户隐私泄露风险的依据,用户信息被设置公开的程度越大、范围越广,用户的隐私泄露程度就越大。隐私偏好是指用户对隐私信息的重视程度[7],具有个性化的特点,用户可以通过设置隐私偏好来降低隐私泄露风险。朱涵钰等[8]基于用户的隐私偏好设置,通过信息熵度量用户属性的敏感性,发现了“人人网”和“新浪微博”上一些用户行为对隐私泄露影响的规律。Maximilien等[9]提出了一种隐私指数来量化用户的隐私偏好设置存在的隐私泄露风险,基于用户隐私偏好计算不同属性的敏感性和可见性。张盼盼等[7]形式化定义了隐私偏好,并基于用户隐私偏好的策略选择,提出了基于博弈的隐私度量模型,在混合策略下运用策略熵度量用户隐私的泄露情况,不仅考虑了用户主观感受对隐私泄露的影响,还考虑了攻击者与服务提供者之间隐私保护策略选择的博弈关系。
综上所述,目前的隐私量化评估方法主要用于评估隐私保护方法的保护效果,而且针对社交网络用户的隐私泄露量化评估相关的研究主要利用用户隐私偏好设置作为评估用户隐私泄露风险的依据,不足以全面地对用户进行评估。
3 隐私泄露量化评估方法
隐私是可确认特定个人(或团体)身份或其特征,但个人(或团体)不愿被暴露的敏感信息[18]。在社交网络中,用户数据通常包含性别、年龄、职业、所在地、教育背景和宗教信仰等属性信息,可以很好地描述用户的身份特征。因此,本文将用户属性视为用户隐私,并基于用户属性量化与评估用户的隐私泄露状况。
为了便于说明,本文用V= {vi|i= 1,2,…,n}表示社交网络中用户的集合,其中n为用户的个数,vi∈V表示社交网络中的一个用户;A= {attrk|k= 1,2,…,s}为s个用户属性组成的集合,attrk∈A表示一个用户属性,是本文社交网络用户隐私泄露量化评估的对象。
3.1 方法概述
隐私泄露量化评估通常需要考虑多方面的因素,主要包括[19]:
(1)隐私参数:用于计算隐私量化值的参数,如用户的隐私偏好设置、隐私阈值和隐私级别等。
(2)攻击者的推测:攻击者获取用户信息之后,根据后验概率分布,对用户的隐私信息进行推测。
(3)真实隐私信息:用户隐私信息的真实值,可以用来评价攻击者的推测是否正确。
(4)先验知识:关于用户隐私信息的先验统计知识,通常是先验概率分布的形式。
因此,本文基于上述隐私泄露量化的因素,设计了3个量化指标:属性敏感性、属性公开性和数据可见性,对社交网络用户的隐私泄露风险进行量化评估与分析。其中,属性敏感性考虑了隐私参数,将用户对属性的隐私偏好设置作为隐私泄露量化因素;属性公开性考虑了攻击者的推测和真实隐私信息,以属性识别模型的推测概率为隐私量化因素;数据可见性考虑了先验知识,关注从用户数据中获取的先验概率分布。
社交网络用户隐私泄露量化评估的整体流程如图1所示。
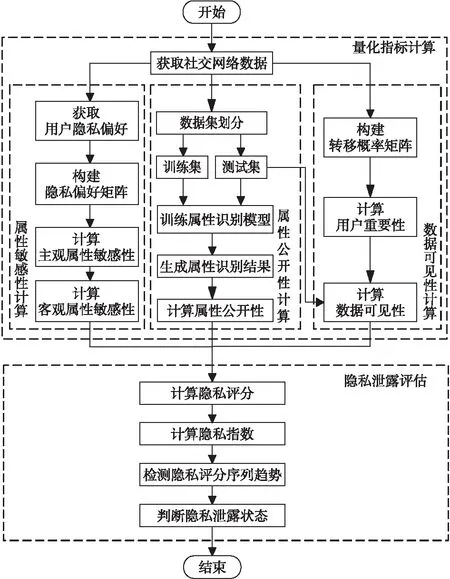
Figure 1 Flowchart of privacy quantitative assessment图1 隐私量化评估整体流程
首先,从社交网络用户数据中获取用户的隐私偏好设置,基于隐私偏好信息,构建隐私偏好矩阵,计算主观属性敏感性和客观属性敏感性;同时,构建转移概率矩阵,计算用户重要性。
然后,对社交网络用户数据进行划分,分割出训练集和测试集,基于训练集训练属性识别模型,利用模型预测结果在测试集上计算属性公开性,并根据用户重要性计算数据可见性。
最后,计算用户的隐私评分和隐私指数,判断隐私评分序列趋势,基于隐私指数和隐私评分序列趋势评估用户隐私泄露状态。
3.2 属性敏感性
属性敏感性表示用户对某个属性的敏感程度,本文将用户对属性的隐私偏好设置作为隐私泄露量化因素,取值为[0,1],属性敏感性越大,隐私泄露风险越高。
隐私偏好矩阵R∈Rn×s反映了社交网络中所有用户为不同属性设置的隐私偏好,表达了用户对不同属性的重视程度,其中第i行第k列的元素rik表示用户vi根据主观意愿对属性attrk设置的隐私偏好等级,值越大表示越不希望属性attrk暴露。
类似推荐系统中的评分矩阵[20],用户在设置隐私偏好时的尺度并不一致,用户vi设置的隐私偏好rik反映的是用户vi对属性attrk的主观敏感程度,并不是实际的敏感性。同时,不同用户之间的主观敏感程度并不具备可比性,无法统一衡量不同用户对于属性attrk的相对敏感程度,需要综合所有用户的主观敏感性来确定客观敏感性,排除用户主观因素的影响。
因此,属性敏感性的计算需要考虑主观敏感性和客观敏感性,在不引起混淆的情况下,属性敏感性默认指客观敏感性。属性敏感性的具体计算步骤如下所示:
(1)计算用户vi的平均属性敏感性,如式(1)所示:
(1)
(2)采用皮尔逊相似度,计算用户vi关于属性attrk的主观敏感性sbj_senik,如式(2)所示:
(2)
(3)根据所有用户关于属性attrk的主观敏感性,计算客观敏感性,如式(3)所示:
(3)
通过主观敏感性计算,可以对某个用户(相同的隐私偏好尺度)的不同属性的敏感程度进行归一化,得到同一用户不同属性之间主观敏感程度的相对大小。同时,可以根据主观敏感性计算属性的客观敏感性,排除单个用户的主观因素影响,便于后续量化指标计算。
3.3 属性公开性
属性公开性表示攻击者基于用户数据推测属性的确定程度,以属性识别模型的推测概率为隐私量化因素,取值为[0,1],属性公开性越大,用户属性越容易被识别,隐私风险越高。
社交网络中的用户数据可以被攻击者获取,用来推测用户属性信息,进而造成用户隐私的泄露。例如,如果用户发布的信息中经常出现“海淀区”“昌平区”“中关村”等地址类用语,那么即便用户隐藏了地址属性,攻击者也可以根据内容推测出该用户的地址为“北京市”。
攻击者可以利用用户公开数据推断用户属性,用户某个属性的公开性越大,说明对应属性的隐私泄露程度越高。因此,属性公开性是衡量用户隐私泄露程度的重要指标。
攻击者在推断用户属性时,通常是利用属性识别模型得到用户属性的类别概率分布,不能直接用于衡量用户属性的公开性大小。由于信息熵通常用于度量概率分布所包含的信息量,熵值越大表示包含的信息量越大[10],因此可以用信息熵来定量描述攻击者推断用户属性的可能性,具体计算步骤如下所示:
(1)设随机变量X表示用户数据,令x∈X表示用户vi的数据;随机变量Y表示待计算的属性attrk,定义域为γ;
(2)假设Y满足均匀分布,属性取值个数为|γ|,从而得出属性取值y∈Y的先验概率P(y) = 1/|γ|;
(3)利用属性识别方法计算P(Y|x);
(4)利用信息熵计算用户vi在属性attrk上的属性公开性,具体如式(4)所示,易证cerik∈[0,1]。
(4)
用户属性识别方法通常基于同质性假设,考虑社交网络结构[21,22]、用户行为[23]和异质信息[24]等因素,结合机器学习方法进行建模,从而确定条件概率分布P(Y|x),即在给定的用户数据x的条件下,属性取值Y的概率。
通过计算用户属性的公开性,可以从攻击者角度对用户的隐私泄露风险进行量化,揭示从用户数据中获取用户隐私信息的可能性大小;同时,可结合属性敏感性,为用户个性化的隐私泄露量化评估提供数据基础。
例1对于性别属性attrk,其定义域γ={男,女},假设存在标注样本{(关键词 = {哥哥,兄弟,爷们},男),(关键词 = {本仙女,化妆,可爱},女)},则对于用户vi的数据x= {哥哥,兄弟,化妆},利用朴素贝叶斯作为属性识别方法,采用拉普拉斯平滑,可得P(男)=1/2,P(女)=1/2,P(男|x)=2/3,P(女|x)=1/3,从而属性公开性cerik≈0.9183。
3.4 数据可见性
数据可见性表示用户数据的曝光程度,以先验概率为隐私量化因素,取值为[0,1],数据可见性越大,隐私风险越高。
用户数据的曝光程度越高,被其他用户获取的可能性也就越大。为了定量描述用户数据的曝光程度,本文对用户获取数据的行为进行了分析,估计其他用户获取当前用户数据的可能性,从而计算用户数据可见性的大小。
设pij表示用户vj能够获取到用户vi的个人信息的概率,用户vi的数据可见性visi的计算如式(5)所示:
(5)
即用户vi的数据可见性visi由所有用户的期望概率计算得到。
具体地,本文以新浪微博为研究对象,对visi的计算进行分析。对于用户vi,从用户vj的角度可以定义4个随机事件:
(1)A= “用户vj看到用户vi的一条微博”;
(2)B= “用户vj查看用户vi的主页”;
(3)C= “用户vj通过一条微博获取到用户vi的个人信息”;
(4)D= “用户vj获取到用户vi的个人信息”。
设用户vi某个时间段内共发了li条微博,则P(D) =1-(1-P(C))li,而通过图2展示的新浪微博用户获取他人信息的一般过程,可以得出P(C)=P(AB) =P(A)P(B|A)。易知pij可以通过P(D)估计,因此计算pij的关键在于P(A)和P(B|A)。P(A)与社交网络结构、用户在网络中所处的位置和信息的传播方式有关,而P(B|A)只与用户vj的行为有关。

Figure 2 General process of Sina Weibo users obtaining other people’s information图2 新浪微博用户获取他人信息的一般过程
本文假设P(B|A)为系统设置的固定参数h∈[0,1],h值越大表示用户vi的信息被用户vj阅读的可能性越大,但不影响用户vj看到用户vi微博的概率P(A)。
设UR=(ur1,…,uri,…,urn)T表示社交网络中所有用户的重要性向量,uri表示用户vi在社交网络中的重要性。
邻接矩阵E∈Rn×n表示用户间的连接关系,第i行第j列的元素eij表示由vi指向vj的有向边,其值表示边的权重,值为0表示边不存在;T∈Rn×n表示转移概率矩阵,第i行第j列的元素tij表示用户vi指向用户vj的边的转移概率,反映了用户vi对用户vj的关注程度。
P(A)可通过2种用户获取信息的方式计算得到:
(1)主动方式:用户vj关注了用户vi,并通过刷新看到用户vi的一条微博;此时P(A)取决于用户vj对用户vi的关注程度,使用转移概率tji估计。
(2)被动方式:用户vj未关注用户vi,并通过搜索推荐等方式看到用户vi的一条微博;此时P(A)取决于用户vi在社交网络中的重要程度,使用用户重要性uri估计。
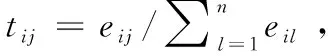
对于用户重要性的计算,本文基于PageRank算法[25],提出计算用户重要性uri的UserRank算法,具体如算法1所示。
算法1社交网络用户重要性算法UserRank
输入:转移概率矩阵T,阻尼系数q,用户数n,可接受误差ε。
输出:社交网络用户重要性向量UR。
/*初始化X为元素都是1/n的n维向量*/
步骤1setX=(1/n…, 1/n, …, 1/n)n;
/*初始化S为元素都是(1-q)/n的n维向量*/
步骤2setS=((1-q)/n, …, (1-q)/n, …, (1-q)/n)n;
/*执行一次更新*/
步骤3UR=S+q·TT·X;
/*更新前后的向量距离大于ε,则继续更新*/
步骤4while ‖UR-X‖2>εdo
X=UR;
UR=S+q·TT·X;
步骤5returnUR;
输入转移概率矩阵T,阻尼系数q,用户数n和可接受误差ε,算法1输出用户重要性向量UR。步骤1是对n维向量X进行初始化;步骤2~步骤4是对用户重要性向量进行迭代更新,直到UR与X之间的距离小于ε时停止,其中‖·‖2表示欧氏距离;步骤5返回用户重要性向量UR。
通过主动方式和被动方式估计P(A),结合P(B|A),可以得出pij的估计值P(D)。因此,在新浪微博中,用户vi的数据可见性visi的具体计算方法如式(6)所示:
cond1=I(eji=0∧vi≠vj)(11-(1-urih)li),
cond2=I(eji>0)(1-(1-tjih)li),
(6)
其中I表示指示函数。
通过计算用户的数据可见性,可以量化用户数据的曝光程度,而用户数据的曝光程度是属性公开性的决定性因素,直接影响了攻击者从用户数据中获取隐私信息的可能性大小。在计算属性公开性时考虑数据可见性,可以更加精确地刻画用户隐私泄露风险。
3.5 隐私量化评估
为了量化评估社交网络用户隐私泄露风险,本文基于3个量化指标:属性敏感性、属性公开性和数据公开性,从静态角度和动态角度评估用户的隐私泄露风险,具体评估方法如算法2所示。
算法2隐私泄露量化评估算法
输入:待评估用户vi,属性敏感性obj_senk,属性公开性cerik,数据可见性visi,用户集合IU,时间窗口大小d。
输出:用户隐私泄露状况。
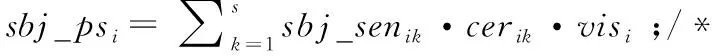
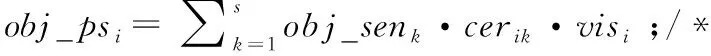

步骤4PSS=(sbj_psti,sbj_pst2,…,sbj_pstd);/*获取主观隐私评分序列(动态角度)*/
步骤5ifobj_psi>PIorUptrend(PSS)/*如果客观隐私评分超过隐私指数或者主观隐私评分序列呈上升趋势 */
returnfalse;/*false表示异常状态*/
endif
步骤6 returntrue;/*true表示正常状态*/
输入待评估用户vi,属性敏感性obj_senk,属性公开性cerik,数据可见性visi,用户集合IU,时间窗口大小d,输出用户vi的隐私泄露状态。
本文定义用户的隐私泄露状况在某一时刻存在2种对立状态:
(1)正常状态:用户的隐私泄露状况正常,用户无需关注个人隐私泄露问题;
(2)异常状态:用户的隐私泄露状况异常,用户需要根据评估结果有针对性地采取保护措施。
用户集合IU表示用于计算隐私指数的用户,根据不同的隐私保护需求,存在4种选取方式:
(1)全部用户:全部用户隐私评分的均值反映了整体的隐私泄露状况,是最基本的选取方式,默认使用全部用户作为IU集合。
(2)高风险用户:隐私评分较高的一部分用户的隐私评分均值。如果用户对隐私保护要求不严格,接受一定程度的隐私泄露,可以选择高风险用户计算隐私指数。
(3)低风险用户:隐私评分较低的一部分用户的隐私评分的均值。如果用户对隐私保护要求严格,可以选择低风险用户计算隐私指数。
(4)自定义:用户可以根据自己的偏好选取一部分其他用户组成IU,被选择的用户表示期望比较的对象。
算法2中步骤1和步骤2根据用户vi的属性敏感性、属性公开性和数据可见性计算主观隐私评分和客观隐私评分。主观隐私评分基于用户的主观敏感性,反映了用户自身不同时刻或不同状态下的隐私泄露状况;客观隐私评分基于客观敏感性只与属性本身有关,用户之间可以相互比较。
步骤3根据客观隐私评分计算隐私指数PI,综合考虑了集合IU中所有用户的平均客观隐私评分,是用户隐私泄露风险的静态量化指标。
步骤4根据主观隐私评分和时间窗口d获取用户vi的隐私评分序列PSS,考虑了用户vi在某一段时间内隐私泄露风险的变化,是量化评估的动态指标。
步骤5和步骤6根据隐私指数PI和隐私评分序列PSS评估隐私泄露状态,用户处于隐私泄露状态的条件是:(obj_ps>PI)∨Uptrend(PSS),其中Uptrend是趋势检验函数,输入一个序列,如果序列有明显的上升趋势,则返回true,否则返回false。本文采用曼-肯德尔(Mann-Kendall)检验法[26]进行趋势检验。
在检测用户隐私泄露状况的同时,为了定性地描述用户隐私泄露的程度,用户可根据个性化隐私保护需求,设置界定隐私泄露程度的阈值α和β(α>β>1)。对于存在隐私泄露的用户vi,在满足obj_psi>PI的前提下,可根据式(7)确定隐私泄露程度leakage_degree:
(7)
4 实验与效果评估
本文实验使用爬虫爬取新浪微博,收集了169 246个用户、234 890 000篇博文和4 485 488条关注关系作为原始数据,其中用户的个人信息包括:用户ID、用户头像、用户昵称、是否认证以及性别、所在地、教育信息和职业信息等属性。
因为本文通过用户属性的角度来度量用户隐私泄露情况,因此从原始数据中筛选了32 170个在性别、所在地(省份)上有标注良好的用户以及50 626 106篇博文和228 939条关注关系作为实验数据。
本文按9∶1的比例将数据集划分为训练集和测试集。训练集用于训练属性识别模型,测试集用于评估用户的隐私泄露状况。
4.1 属性敏感性实验
因为实验数据中不包含用户的隐私偏好,所以本文假设用户在个人主页上公开属性信息即表示对应属性隐私偏好为1,否则隐私偏好为0。
为了得到更加精确的结果,本文基于原始微博数据来计算性别、所在地、教育信息和职业信息的属性敏感性,其中性别和所在地的属性敏感性将用于全局隐私评分的计算。
通过用户隐私偏好和属性,可以构造隐私偏好矩阵,从而利用第3.2节的计算方法计算属性敏感性,结果如图3所示。
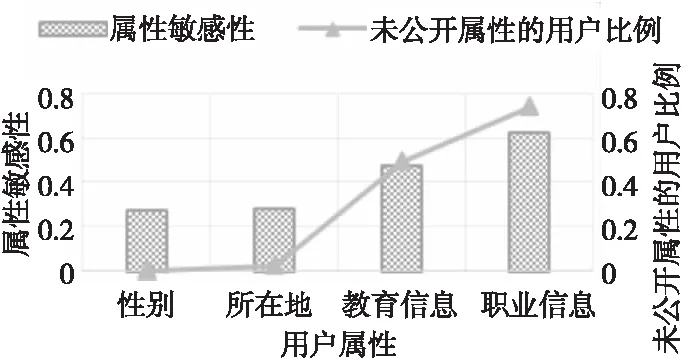
Figure 3 Experimental results of attribute sensitivity图3 属性敏感性结果
从图3中可以得出如下结论:
(1)所有用户都公开了性别,只有极少一部分人隐藏了所在地,近一半人公开了教育信息,大部分人都未公开职业信息。
(2)属性敏感性与隐藏属性的用户数相关,未公开的用户数越多,属性敏感性越高。但是,属性敏感性还与其他属性的隐私偏好设置有关,因此虽然隐藏性别的用户数为0,但属性敏感性不为0。
4.2 属性公开性实验
本文采用属性识别模型MSIE(Multi-Source Infromation Embedding)识别用户的性别和所在地属性,将实验数据按标注率0.1~0.9划分,得到MSIE的识别结果如图4所示[27]。

Figure 4 Accuracy comparison of attribute inference models图4 属性识别模型准确率对比
从图4中可以看出,与CANE(Context-Aware Network Embedding)[28]、TFIDF(Term Frequency-Inverse Document Frequency)[29]、node2vec[30]、Doc2Vec[31]和DeepWalk[32]相比,MSIE获得了最佳的属性识别准确率。MSIE在性别上的准确率为88.63%,性能提升了5.49%~26.66%;在所在地上的识别准确率为69.28%,性能提升了8.11%~25.54%。
通过属性识别模型MSIE可以得到测试集用户在性别和所在地属性上的类别概率分布P(Y|x),从而利用第3.3节的计算方法计算测试集用户的属性公开性。
将属性公开性的计算结果按0到最大值等分成20段,属性公开性分段作为横坐标,其值落在对应分段的用户比例作为纵坐标,得到属性公开性分布如图5所示,其中图5a展示了性别的属性公开性分布,图5b展示了所在地的属性公开性分布。

Figure 5 Distribution of attribute openess图5 属性公开性分布
从图4和图5中可以得出如下属性公开性的结论:
(1)性别属性的区分度比较高,容易造成性别信息的泄露。在用户数据较多的情况下,MSIE识别性别的准确率较高,导致部分用户性别属性公开性较大。
(2)所在地属性区分度较低,不容易造成所在地信息的泄露。所在地的属性公开性分布集中在均值附近,加上MSIE识别所在地的准确率较低,导致属性公开性高的人数较少。
4.3 数据可见性实验
本文实验设系统参数h=1,阻尼系数q=0.85,可接受误差ε= 10-4。为了得到更加精确的结果,本文实验在原始微博数据上,根据用户之间的关注关系构建转移概率矩阵,通过UserRank算法计算用户重要性,并利用第3.4节中的方法得到用户的数据可见性。
将数据可见性的计算结果按0到最大值等分为20段,将用户的数据可见性分段作为横坐标,数据可见性值落在对应分段的用户比例作为纵坐标,得到数据可见性分布如图6所示。
从图6中可以看出,数据可见性分布基本上符合长尾分布,大部分用户的可见性比较低,可见性高的用户比较少。
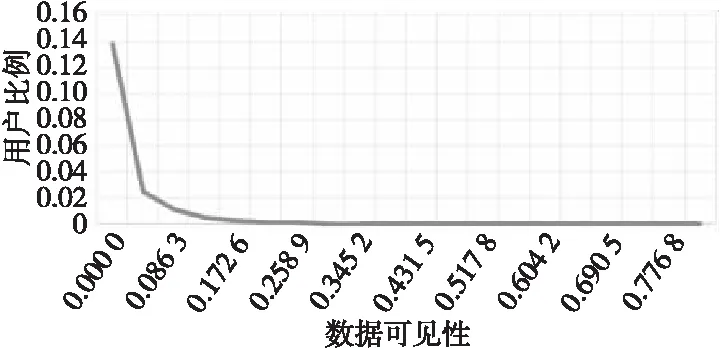
Figure 6 Distribution of data visibility图6 数据可见性分布
4.4 量化指标统计对比
对不同人群的隐私评分及其他各项指标进行统计对比分析,针对不同的性别和是否认证分别将用户分为2组,计算每个组内各个指标的均值,结果如表1所示,粗体为该列最大值,下划线为该列最小值。
对表1中的量化指标进行百分比统计,得到对比结果如图7所示。
从表1和图7中可以得出:
(1)认证用户的各项指标基本都高于全集均值,平均全局隐私评分非常高,说明认证用户较活跃,在社交网络中产生了较大的影响,因此认证用户通常更容易泄露隐私。
(2)女性用户的隐私评分略低于男性用户,说明女性用户的隐私泄露状况比男性用户稍好。对数据进行分析发现,女性用户的社交关系比较简单,关注用户和粉丝数都比较少,相对更不容易泄露隐私。但是,女性用户各属性的公开性都比较高,说明女性用户产生的用户数据比较容易泄露隐私。

Table 1 Statistic comparison of quantitative metrics表1 各量化指标均值统计对比
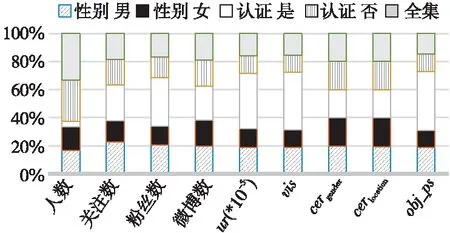
Figure 7 Percentage comparison of quantitative metrics图7 各量化指标百分比对比
4.5 实例分析
为了对社交网络整体以及用户个体隐私泄露状况进行细粒度的评估,帮助更加直观准确地了解社交网络用户的隐私泄露状况,本文从实验数据集所有用户构成的社交网络中选择了一个弱连通子图进行可视化,其中包括836个节点和1 475条边。
可视化结果如图8所示,节点有正常与异常2种隐私状态,大小代表用户的隐私评分,节点越大表示对应用户的隐私评分越大。
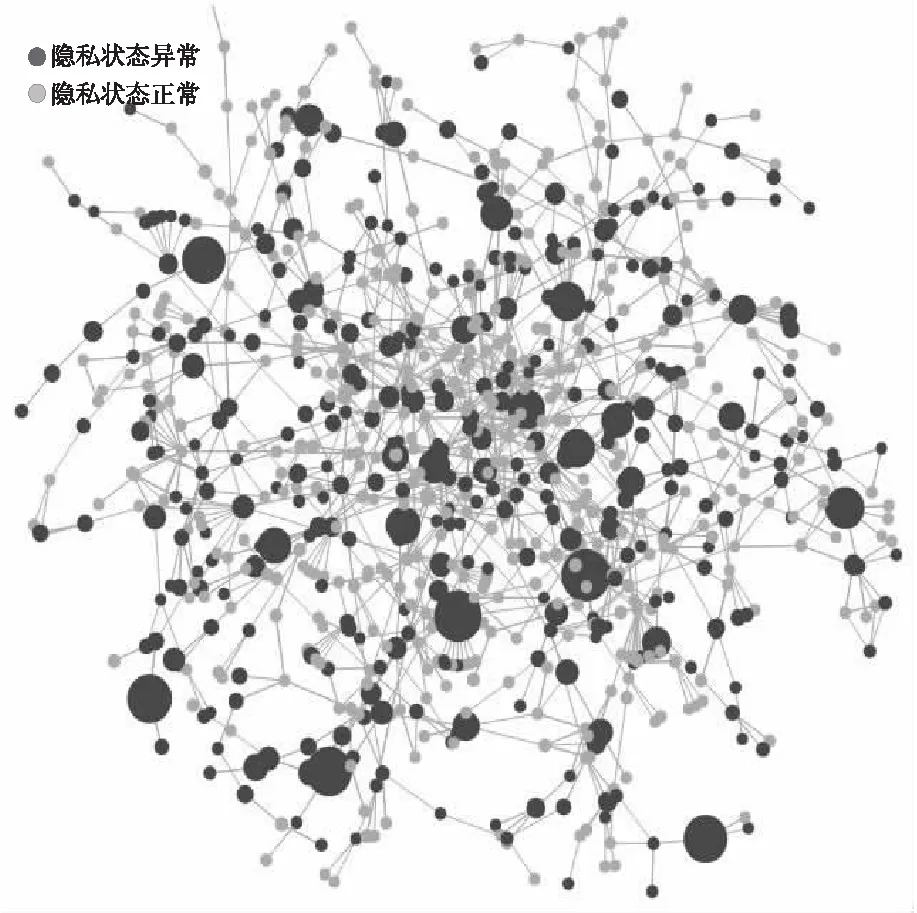
Figure 8 Visualization of privacy disclosure in social networks图8 社交网络整体隐私泄露状况可视化
从图8中可以看出:
(1)多数节点比较小,说明多数用户隐私状态正常,隐私评分比较低;
(2)与隐私状态异常的节点相连的边比较多,说明社交关系复杂的用户发生隐私异常的可能性更大。
图9是图8所示的社交网络中用户隐私泄露状况的统计结果,从图9中可以看出,有13%的用户隐私风险过大,18%的用户隐私风险呈上升趋势,12%的用户隐私风险过大且呈上升趋势。这与《2018年网民网络安全感满意度调查报告》中近一半受访者认为个人信息保护状况不好的结果相吻合。

Figure 9 Statistics of privacy leakage图9 隐私泄露状况统计
图10展示了用户个体隐私泄露状况可视化示例,图10a和图10b分别表示隐私状态正常的用户“小男人也彪悍1984”和隐私状态异常的用户“王梓萌Mm0820”对应的个人信息和各量化指标随时间变化的曲线。

Figure 10 An example of user privacy leakage visualization图10 用户个体隐私泄露状况可视化示例
图10中,横轴的起始时间为2009年11月27日(横坐标为0),结束时间为2012年10月18日(横坐标为10),时间间隔约为100天。
对于图10a所示的隐私状态正常的用户,其隐私评分总体变化不明显,隐私泄露风险较低。对于图10b所示的隐私状态异常的用户,其隐私泄露风险大且呈上升趋势,性别属性泄露程度持续增大。更细粒度地可以看出,该用户在2010年3月13日各量化指标均低于基线;在2011年5月9日,性别属性公开性为0.277 8,高于基线0.137 5,说明此时其性别属性存在隐私泄露风险,但整体风险不大;在2012年10月18日,性别属性公开性为0.530 7,高于基线0.145 9,隐私评分为0.144 2,高于基线0.011 1,此时其性别属性隐私泄露程度进一步增大;同时,数据可见性为0.495 1,高于基线0.093 2,说明数据可见范围大,整体隐私泄露风险较高。
5 结束语
针对目前隐私量化评估方法主要用于评估隐私保护方法的保护效果,无法有效评估社交网络用户的隐私泄露风险的问题,本文提出了一种社交网络用户隐私泄露量化评估方法,设计了数据可见性、属性公开性和属性敏感性3个量化指标,并综合了3个量化指标计算隐私评分,用于评估社交网络用户隐私泄露状态。在新浪微博数据上进行的实验表明,本文所提方法能够有效地评估用户的隐私泄露状况。从实验结果可以发现,微博认证用户较为活跃,各项指标基本都高于用户均值,更容易泄露自身隐私;同时,实例分析发现,有43%(近一半)的用户存在隐私泄露风险,与《2018年网民网络安全感满意度调查报告》中近一半受访者认为个人信息保护状况不好的结果相吻合。未来的研究工作将基于隐私泄露状况的量化评估结果设计隐私保护方案,为用户提供针对性的隐私保护。
猜你喜欢
英语世界(2023年6期)2023-06-30 06:28:28
意林彩版(2022年2期)2022-05-03 10:25:08
安徽警官职业学院学报(2020年6期)2020-07-21 01:38:44
第一财经(2020年4期)2020-04-14 04:38:56
文苑(2018年17期)2018-11-09 01:29:28
中国有色金属学报(2018年2期)2018-03-26 07:58:26
决策与信息(2017年9期)2017-09-07 15:53:23
合作经济与科技(2017年11期)2017-06-07 07:36:53
现代经济信息(2016年31期)2017-03-08 21:39:49
焊接(2016年1期)2016-02-27 12:55:37
