
私有工控协议分类方法研究*
2021-09-23 05:54王绍杰
网络安全与数据管理 2021年9期
关键词:提取
周 帅,王绍杰
(华北计算机系统工程研究所,北京100083)
0 引言
随着我国对工业化与信息化深度结合的推进,新技术越来越广泛地应用到传统工业与制造业上,网络空间作为人类活动的第五维空间,成为一个不同于陆、海、空、天的新的安全疆域。云计算、物联网将原先相对封闭的工业系统暴露在互联网中,由于重视不到位,相关防护措施不足,工控系统的网络安全事件日益增多,我国工控行业所面临的安全问题也日趋复杂,工控系统成为黑客攻击的目标,工控安全研究刻不容缓[1-2]。工控协议研究是工控安全的重要部分,工控协议由于历史原因,存在大量的未知私有协议,由于没有统一的标准,需要进行协议逆向工作进行协议的分析,而目前的协议逆向技术主要是针对一般网络协议的逆向,对工控网络协议的逆向分析较少,已有的针对工控协议的逆向分析中,报文分类方法也仅仅以长度或字符频率当作特征进行分析,存在很大误差[3]。针对以上问题,本文提出了一种基于自然语言处理的协议特征提取方法,将报文中的N-gram片段的概率作为关键词,将每一条报文的关键词作为特征,进行聚类分析,经过实验验证,本文提出的方法能够很好地将协议根据功能进行分类。
1 工控协议逆向技术
1.1 协议逆向技术介绍
协议逆向工程[4](Protocol Reverse Engineering)是指不依赖协议描述的情况下,通过对协议实体的网络输入输出、系统行为和指令执行流程进行监控和分析,提取协议、语义和同步信息的过程。通过多年的相关研究,目前协议逆向领域分为两个研究方向,一个是基于网络流量的协议逆向分析,一个是基于指令执行的协议逆向分析。基于网络流量的协议逆向分析[5],是根据同种报文中各个字段取值和转变规律来提取其格式的方法,由于相同类型的报文格式上存在相同点,通过将类似的报文提取出来放在一起,进行比较推断,从而逆向出可能的协议格式。基于指令执行的逆向分析[6],主要是通过跟踪程序执行过程,掌握分析处理字段的方法,从而了解字段的具体信息。
1.2 工控协议分类
工控协议的逆向研究与通用的网络协议逆向研究存在许多不同,由于工控协议存在自己的特点,因此直接套用现有网络协议的逆向算法效果并不好,需要结合工控协议本身的特点,研究适合工控协议的协议逆向方法。
工控协议是应用在工控系统中各个部分之间通信的规则,主要的工控网络协议按照应用场景的分类如图1所示。

图1 工控协议分类
工控协议根据应用层次一般可分为传统控制网络、现场控制网络、工业以太网、工业无线网四种类型,不同类型的工控协议拥有不同的特征。
传统控制网络:传统控制网络一般包括DCS、CCS等,是将一些探测设备部署在网络终端,使用标准的工控协议进行信息传输,现场设备之间可以相互通信,合力完成对现场设备控制。其通信协议一般是由厂家自己开发的,不对外公开。
现场控制网络:现场控制网络(FCS)是用于过程自动化和制造自动化的现场设备或现场仪表互连的现场通信网络。FCS并没有使用传统控制网络的控制站,将其控制功能分布在现场各个仪表设备中,实现控制功能的分散化,现场总线采用相对一致的协议标准,并没有限制其接入网络类型,可实现多种场景的网络连接,兼容多种类型不同开发商的产品,通过一个网络可以将所有这些相互孤立的设备凝聚成为一个整体。
工业以太网:工业以太网与以太网网络框架相似,在底层两层,应用802.3标准;网络层与传输层,应用TCP/IP协议;最高层取消了会话与表示两层,仅保留应用层。相对于其他的网络类型,工业以太网首先有相对统一的总线标准,提供较宽的通信通道,并且拥有更好的集成性,应用层协议嵌入到TCP/IP帧中。
工业无线网络[7]:工业无线网络是伴随着无线技术飞速发展而出现的新的研究方向,工业无线网的协议,例如ZigBee,HART,SP100等,其关注的核心问题是实时性、可靠性、安全性。
1.3 工控协议特点
工控协议是工控系统通信的语言,工控系统的设备数量、产品种类、供应厂商、行业标准都相当多,工控协议也存在区别。工控系统要求高实时性、高可靠性和高可用性,其中可用性的优先级最高[8],工控协议服务于工控系统,为保证其安全稳定运行,工控协议要有相应的针对性设计,所以工控协议相对网络协议有着自己独特的特征。
工控协议一般有如下特点:(1)由于工控系统的相对封闭,并且对系统的可用性、实时性、可控性要求较高,工控协议很大部分使用明文传输,并没有加密,使得使用基于网络流量的协议逆向方法具有一定的优势;(2)信息传输中,主要以二进制的传输形式为主,工控私有协议逆向主要以二进制协议研究为主;(3)工控系统的信息传输有周期性,协议中交互信息、控制信息都会周期性地出现,并且相同功能的报文,其格式、长度都存在相似性;(4)数据包有相对固定的结构,例如在内容上,一般有明确的发送者和接收者,含有时间戳、校验码以及报文长度字段。
2 私有工业控制系统协议分类方法
对于工控私有协议的逆向分析,由于工控系统的特殊性,基于指令执行轨迹的协议逆向方法一般难以施行,基于网络流量的协议逆向方法是相对更好的选择[9]。在需要分析的系统中,通过一些收集方法获取网络报文,对报文进行处理。结合自然语言处理的算法,将报文类比为语料进行处理,并将每一行报文按照自然语言处理的方法进行分词、关键词提取,最后进行报文聚类分析,其流程如图2所示。
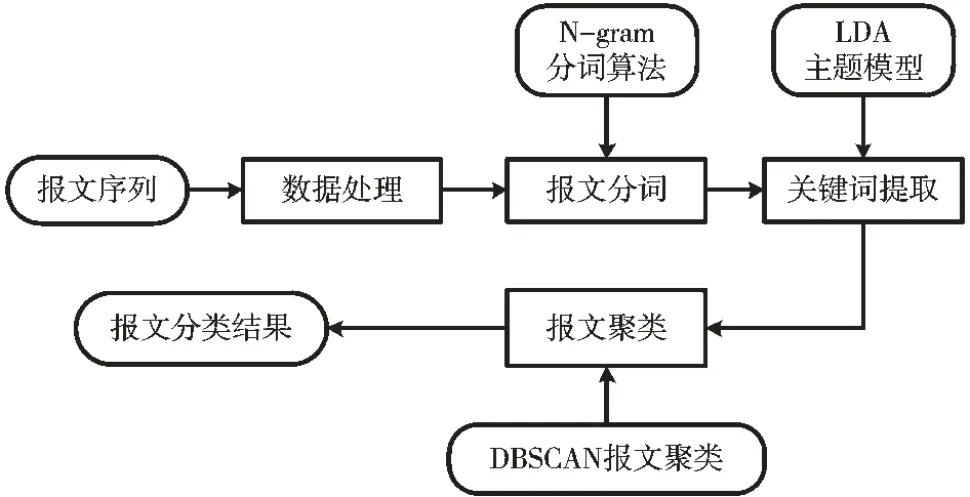
图2 报文分类流程
2.1 数据预处理
通过将设备接入待分析系统中,捕捉设备通信流量,由于系统中可能存在多种流量,截取需要的流量需要一些措施,可以通过筛选IP地址、筛选端口将含有需要协议数据的流量分离出来。工控协议数据在不同应用场合,形式不相同,例如现场总线一般仅有物理层、数据链路层和应用层,而工业以太网一般基于TCP/IP协议[10],在OSI协议模型中一般在传输层以上。工业以太网的数据包从上到下进行封装,不同的协议又有不同的封装方法,例如Modbus是一种应用层协议,在应用层以下都依托于TCP/IP协议进行传输,而S7协议也是TCP/IP协议簇的一员,在OSI对应的7层协议模型中取消了会话层与表示层,将应用层的数据经过S7协议自定义的COTP协议与TPKT协议进行处理,最后利用TCP进行传输。Wireshark工具可以将协议数据进行分层展示,主要是依靠协议不同层之间不同的承接方式,例如对于链路层,在首部有固定的帧结构表示帧内数据,IP协议的首部也有确定的几位来确定其上层的协议类型。应用层协议一般依靠端口号识别,如果是私有协议,则不能识别,直接标记为data字段,所以对于协议的分析,若是已知协议则提取协议相关字段,若为未知的私有工控协议,则需要提取data字段来进行字段提取。
2.2 基于N-gram的分词
提取出的data数据保存为txt格式,对协议格式划分中的协议关键词提取可以联系自然语言处理中的文本关键词进行,关键词提取算法的实现首先需要对文本进行分词,由于本文的处理对象是私有的工控协议,协议内容无法进行提前标注,方法上主要选择无监督的方法进行研究。
N-gram语言模型[11]是一种在NLP领域广泛使用的统计语言模型,广泛应用到分词算法、语音识别、输入法等各个方面,本文将利用N-gram算法对数据进行分词处理,产生关键词提取的语料。将每一行报文作为一个文本,使用N-gram算法进行切分。N-gram算法的关键在于N的选取,不同的N值,对算法效率影响较大,如果N选取过大,会使切分产生的结果数目过于庞大,如果N选取过小,会使关键词被切分开,影响准确率。N值的选取需要结合工控协议的特点进行研究。
通过对一些常见的工控协议包进行观察,发现工控协议的关键词一般在1~2 B[12],所以对于N-gram算法,选取N为1~2,对数据内容进行切分。
2.3 基于LDA主题模型的关键词提取
在工控协议的关键词提取过程中,将每一行报文当做一个文档,将每一个N-gram元素当做一个词,协议的关键词便是一系列N-gram概率的集合,这部分输出将会作为聚类的依据。
依照LDA主题模型[13]提取工控协议关键词的步骤如下:首先利用Dirichlet分布,产生协议的关键词的N-gram元素分布;然后利用Dirichlet分布得到每一行报文的关键词分布。其中两次使用Dirichlet分布需要先确定两个参数α与β,由于Dirichlet分布是一种基于贝叶斯框架的分布,这两个参数便是先验参数。也就是说一共有m条报文,协议的关键词的N-gram元素分布便是由确定一个先验参数α的Dirichlet分布采样所得到的,每一行报文的关键词分布由第二个先验参数β的Dirichlet分布采样所得。
在应用LDA主题模型进行关键词提取时,输入应该是N-gram分词结果,设置主题数与迭代次数,两个超参数使用默认值,进行训练,并通过调节困惑度的值来选择合适的主题数。由于目标是进行按功能协议聚类,因此对应LDA主题模型在自然语言处理中的对于每篇文章的主题输出,选择每行报文的关键词概率输出作为结果,这样每行报文针对不同的关键词概率,代表着不同功能的报文,作为聚类的依据,实现最终的报文聚类。
本文想得到的是可以作为工控协议的关键词的部分,通过将报文输入,输出报文的关键词概率矩阵,作为下一步报文聚类的输入数据,需要的参数主要有三个,第一个是关键词个数,后两个是先验分布的参数α与β。参数的选择需要一个衡量指标,这里选择困惑度作为衡量参数优劣的指标。
困惑度的概念来自于信息论,一般用来评价一个概率分布模型或者概率模型的质量,越低的困惑度,表示模型的质量越高,预测效果越好。对于工控协议,将所得到的模型对一条报文的关键词进行预测,这个关键词的不确定程度便是困惑度。其计算如式(1):
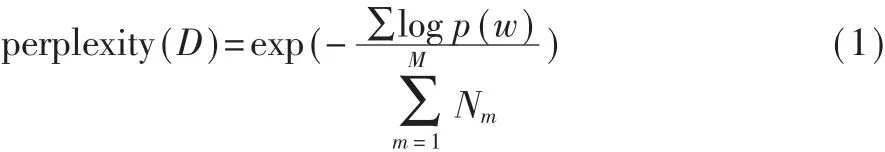
其中N为所有单词的长度和,p(w)代表N-gram元素的频率。
2.4 协议聚类
网络中捕获的通信协议一般包括多个种类,根据实现的功能不同,它们有着不同的结构,例如S7协议的请求报文仅包含Header和Parameter部分,而功能相关报文则除了这两部分还有Data数据段。由于结构不同,在协议逆向中,需要把不同功能的报文区分出来,这就需要聚类操作。
经过LDA主题模型的关键词提取后,会得到两个概率分布,对于报文相关功能的聚类,需要使用与报文相关的关键词作为特征,选择LDA主题提取模型生成的文档-主题矩阵,也就是协议报文,与报文对应关键词概率矩阵作为特征,进行聚类。这里选用的聚类方法为DBSCAN。
DBSCAN聚类算法是一种基于密度的聚类算法,也就是根据样本数据分布的紧密程度来进行区分,将分布集中的视为一个簇,分为一个类。DBSCAN的特点是不需要事先确定类别数,对于私有工控协议,网络抓包是随机的,并不能确定其中含有的不同功能的报文有多少种,而且DBSCAN对报文聚类的形状没有要求。
2.5 轮廓系数
轮廓系数[14]是用来评价聚类好坏的一种评价方式,其取值一般在(-1,1)之间,值越大表示聚类效果越好,小于0一般表示样本被错误分类,0附近表示边界有重叠,而大于0表示同一类中的样本更加相似。
对于轮廓系数的计算,每一个样本各自计算其值,首先随机选择一个向量,计算其到同一分类样本的区别程度的均值,表示簇间的集中程度,再计算其到其他分类样本间的区别程度的最小值,表示不同簇间的区别度,则此样本轮廓系数的计算如式(2)所示:

对于整个样本空间,求所有样本点轮廓系数的均值作为样本空间的轮廓系数,从而判定聚类的好坏。
3 实验验证
应用欧姆龙CJ2M-CPU31系列PLC与上位机工程师站之间通信数据作为实验需要的初始数据,工程师站为Windows 7系统,在交换机配置镜像口,使用设备接入镜像口进行监听网络流量,监听设备为Windows 7计算机,使用软件为Wireshark,图3为通信数据监听示意图。
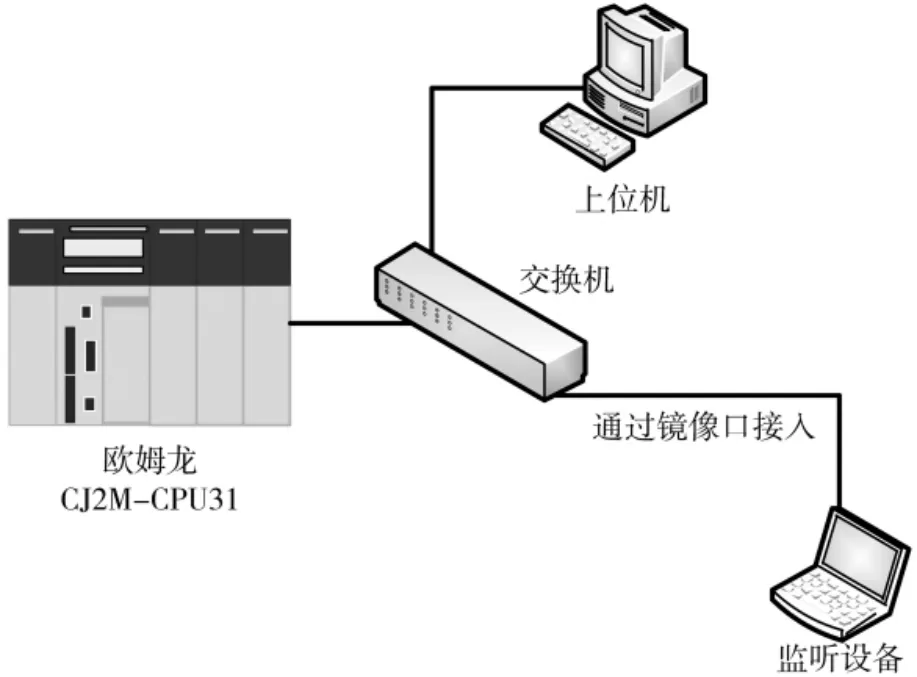
图3 通信数据监听示意图
由于获取到的数据都是静态的,基于网络流量的分析也是基于一些静态特征进行的,对于样本中数据的出错、分片是无法处理的,因此实验中并不考虑样本中分片、出错等情况。使用Wireshark将数据保存为pcap文件格式进行后续分析,对私有工控协议的逆向,选用已知的协议,全程选择无监督的方法,最后与已知的协议规范进行对比,实现未知协议的协议逆向的验证。
3.1 样本提取
pcap文件是一种保存数据报的文件格式,其中的数据报文按特定的格式储存,提取出的报文需要对pcap文件进行解析。
得到pcap文件,需要对其进行解析。pcap文件格式是规范的,根据其文件格式将相关报文提取出来,Wireshark工具提供了Tshark命令行工具,可以将pcap文件中特定的协议字段提取出来。实验需要的是data部分的字段,使用Tshark将其直接输出为txt文本形式,部分提取结果如图4所示。

图4 欧姆龙协议data字段
3.2 报文分词
将提取出的data字段利用N-gram算法进行分词,设置N=(1,2),结果如图5所示。

图5 报文分词结果
3.3 LDA特征提取
在应用LDA主题模型进行关键词提取时,输入应该是N-gram分词结果,设置主题数与迭代次数,两个超参数使用默认值,进行训练。通过困惑度的值来选择合适的主题数,困惑度值用来衡量LDA主题模型,其值越小,表示效果越好。使用不同的主题数,设置迭代次数为2 000进行实验,最后可得折线图如图6所示。
图6中,在主题数为3时困惑度取到了最小值。主题数取3则代表所有序列中能有三种关键词,每个关键词为一组N-gram序列,每行报文可以被这三个关键词标记。

图6 主题数与困惑度折线图
3.4 报文聚类
LDA主题模型提取主题词后,每一行报文都被关键词的概率标记,由于关键词代表了每行报文N-gram元素的重要程度,因此其可以作为这行报文的特征,根据关键词进行报文聚类,可以将不同功能的报文进行分类。DBSCAN聚类有三个参数可以进行设置,第一个是聚类半径r,第二个是邻域密度MinPts,第三个是距离函数,这里距离函数选用默认的欧氏距离。使用轮廓系数进行聚类评估,通过轮廓系数的值来进行调参,由于输入向量为高维向量,因此使用PCA降维算法,将其降为2维,通过调参,最终实验结果为:领域半径r=0.087 5,领域密度MinPts=3,其轮廓系数为0.788 4。图7为聚类结果。

图7 DBSCAN聚类结果
由图7可知所有报文可以被聚类为4类,代表4种不同功能的报文。
4 结论
本文通过对协议逆向技术的研究,结合工控系统的实际情况,选用基于网络流量的协议逆向方法,通过对欧姆龙PLC上的协议进行分析,设计了一套协议逆向算法,并将实验结果对应原协议规范进行了对比验证,实验证明,本文提出的方法能很好地进行报文按照功能分类。
本文基于网络流量进行分析,实验效果受样本完整性和样本多样性的影响较大,在更加复杂的网络环境中,可能分类效果会受影响。下一步工作首先需要对样本的采集和处理方法进行研究,其次本文提出方法涉及的参数较多,参数调整带来的模型变化需要进行验证。在协议逆向的整体流程[15]中需要进一步进行协议格式推断以及状态机推断的研究,实现对私有工控协议有效且完整的逆向工作。
猜你喜欢
法制博览(2016年12期)2016-12-28
绿色科技(2016年20期)2016-12-27
现代农业科技(2016年20期)2016-12-20
文艺生活·中旬刊(2016年11期)2016-12-13
法制与社会(2016年32期)2016-12-01
企业技术开发·下旬刊(2016年9期)2016-11-23
中学生物学(2016年10期)2016-11-19
文艺生活·中旬刊(2016年9期)2016-11-07
科技视界(2016年22期)2016-10-18
科技视界(2015年25期)2015-09-01
