
基于超高效液相色谱-四极杆串联飞行时间质谱的绿茶产地溯源研究
2021-09-23 00:41贺光云闫志农邱世婷莹罗覃蜀迪
农产品质量与安全 2021年5期
贺光云 侯 雪 闫志农 周 熙 韩 梅 邱世婷 李 莹罗 苹 覃蜀迪
(1. 四川省农业科学院农业质量标准与检测技术研究所, 农业农村部农产品质量安全风险评估实验室 (成都), 成都 610066; 2. 四川省绿色食品发展中心, 成都 610041)
农产品地理标志是指标示农产品来源于特定地域, 产品品质和相关特征主要取决于自然生态环境和历史人文因素, 并以地域名称冠名的特有农产品标志, 是一种质量品质属性和文化标志[1]。 农产品地理标志与无公害农产品、 绿色食品、 有机农产品为传统 “三品一标”, 是国家安全优质农产品公共品牌, 农产品地理标志突出的是农产品品牌,“三品” 强调的是农产品质量安全[2]。 2021 年, 农业农村部启动实施农业生产 “三品一标”(品种培优、 品质提升、 品牌打造和标准化生产) 提升行动, 更高层次、 更深领域推进农业绿色发展。
茶叶, 作为一种兼具独特风味特征和有益人体健康的农产品, 其品质由其内含物质所决定, 而茶叶的生化成分和滋味品质与茶树的生长环境和气候条件等因素密切相关, 因此, 茶叶品质存在明显的地域差异和很强的“风土”特征[3~5]。 茶叶是我国特色地理标志性产品, 具有区域资源优势和深厚的文化底蕴。 2021 年3 月1 日, 《中欧地理标志协定》正式生效, 预示着中欧双方更多特色优质名品将进入彼此市场, 为中欧企业提供知识产权保护, 也为我国地理标志农产品提升知名度、 开拓海外市场提供新的机遇。 我国首批100 个入选地理标志产品中有28 个茶叶, 占比几近三成, 其中四川的 “蒲江雀舌”“峨眉山茶”及“纳溪特早茶” 榜上有名[6]。 产地是消费者选购茶叶的重要依据之一, 产地溯源可保证茶叶的真实性, 保护消费者利益, 促进品牌培育与保护, 防止产地造假、 以次充好等现象, 为维护茶叶市场秩序提供技术支持。 目前, 稳定同位素、 矿物元素、 稀土元素、 近红外光谱及代谢组学等分析技术与化学计量学模型结合是茶叶产地溯源的有效手段。 液相色谱-质谱联用技术 (LC-MS)因其高通量和高灵敏度优势已成为代谢组学最常用的分析技术[7~10]。
本研究采用超高效液相色谱-四极杆串联飞行时间质谱 (UPLC-QTOF-MS) 技术, 结合多元统计分析, 对四川省雅安、 宜宾和绵阳3 个产区绿茶进行产地溯源研究。 利用 MarkerView 1.3.1 和SIMCA 14.1 软件对数据进行主成分分析与判别分析 (PCA-DA) 及双向正交偏最小二乘-判别分析 (O2PLS-DA), 对不同产区绿茶构建分类模型, 探明不同产地茶叶化学成分是否存在显著性差异, 并对模型预测能力进行评价。 结合VIP 分析和t检验, 筛选出50 个具有统计学差异的化合物(VIP>1,p<0.01)。 本研究旨在为茶叶的产地溯源和质量评价提供理论依据。
一、 材料与方法
(一) 仪器与试剂Nexera X2 型超高效液相色谱仪, 日本岛津公司; SCIEX Triple TOF®5600高分辨质谱系统, 美国 SCIEX 公司; WH-3 微型涡旋混合仪, 上海路西分析仪器有限公司。
甲醇、 乙腈和甲酸均为色谱纯, 美国Fisher Scientific 公司。
(二) 样品采集及处理本实验所用绿茶样品分别为宜宾早茶、 北川茶叶和蒙顶山茶地理标志产品, 分别采自四川省宜宾市屏山县、 绵阳市北川县和雅安市名山区, 采摘时间为2020 年3-4 月, 每组10 个样品分别采自3 个茶园, 共计30 个样品。
样品的提取模拟日常饮茶方式, 以茶汤为分析目标[11~12]。 称取 2.0 g 茶叶置于 500 mL 烧瓶中, 加入 300 mL 开水 (80℃), 浸泡 30 min。 取 1mL 茶汤, 过 0.22 μm 滤膜后进行 UPLC-QTOF-MS 分析, 每个样品做3 个平行。
(三) 仪器条件色谱条件: Kinetex 2.6 μm Biphenyl 色谱柱 (2.1 mm×100 mm, 100A); 流动相: 水相为0.1%甲酸水溶液 (A 相), 有机相为甲醇 / 乙 腈 (V/V=30/70, B 相 ); 流 速 : 0.40 mL/min; 进样量: 5 μL; 柱温: 40℃。 梯度洗脱程序: 0~4 min, 3%B; 4~6 min, 3%B→5%B;6~10 min, 5%B→20%B; 10~15 min, 20%B→50% B; 15 ~16 min, 50%B →60% B; 16 ~18 min, 95%B; 18~20 min, 3%B。
质谱条件: 采用电喷雾离子源 (ESI) 在负离子模式下进行全扫描, 一级质谱质量扫描范围m/z100~1 000, 二级质谱质量扫描范围m/z50 ~1 000, 在每个循环内同时进行10 个MS/MS 扫描;喷雾电压为-4 500 V; 工作气为氮气, 雾化气、 辅助加热气和气帘气压力分别为 50、 50、 35 psi; 离子源温度 450℃; 锥孔电压 (DP) -80V; 离子释放延迟, 67 V; 离子释放宽度, 25 V; MS/MS 模式下的碰撞能量为 (40±20) V。
(四) 数据处理与多元统计学分析使用MarkerView 1.3.1 软件进行数据预处理。 处理参数设置如下: 时间范围0.4~17.5 min; 质谱范围m/z100~1 000; 保留时间窗口 0.2 min; 质量偏差0.01; 最小强度 1% ; 变化峰强度阈值 100; 去除少于3 个样本中出现的峰, 最大峰数目8 000, 除去同位素峰, 对数据进行分组并进行峰面积归一化完成对数据的标准化处理, 提取到7 192 个峰。 首先利用 MarkerView 1.3.1 软件中的PCA 数据处理方法进行分析, 并进行分组t检验。 同时, 将提取到的峰值数据集导入SIMCA 14.1 软件进行PCADA 和 O2PLS-DA 分析。
二、 结果与讨论
(一) UPLC-QTOF-MS 分析采用 UPLCQTOF-MS 技术[13]在负离子模式下分析了四川省宜宾、 绵阳、 雅安3 个产区绿茶的代谢产物, 得到总离子流图 (TIC 图, 见图 1)。 在该条件下样品得到了良好的色谱分离及较强的离子强度峰。 从图1中可以看出, 样品的离子峰主要出现在0.4~17.5 min, 其中8~12 min 离子峰较为集中。 总体看来,除了保留时间约2 min、 5 min 和10 min 处离子峰强度在雅安和绵阳产绿茶中高于宜宾产绿茶外, 3个产地茶叶的出峰数量和相对丰度观察不到其他明显差异。 因此, 需要进一步通过多元统计方法对数据进行挖掘与分析。
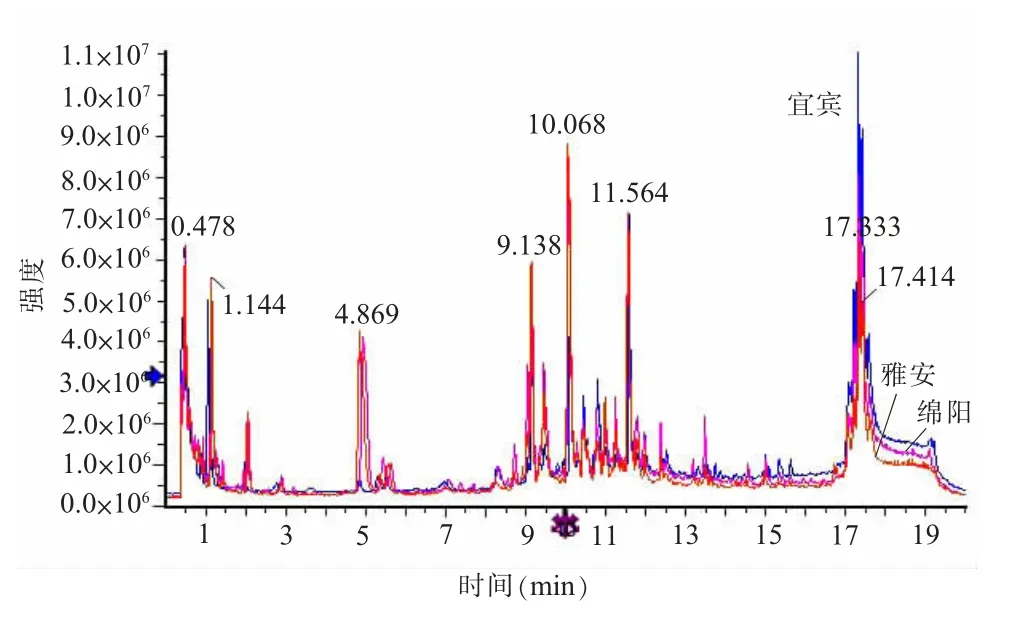
图1 不同产地绿茶的总离子流图
(二) 数据统计分析
1. 分类模型建立。 UPLC-QTOF-MS 原始谱图经过分段积分、 滤噪、 峰匹配、 标准化和归一化处理后得到包括7 192 个峰变量、 保留时间及峰面积构成的数据集。 采用MarkerView 1.3.1 软件进行PCA-DA 分析[14], 选择 Pareto 方法对数据进行缩放, 模型得分图见图2(a)。 可以看出 3 个产地茶叶样品点各自聚集在不同区域, 宜宾产绿茶样品主要分布在主成分1 的负半轴和主成分2 的中间位置,而绵阳产绿茶主要分布在主成分1 的中间和主成分2 的正半轴, 雅安产绿茶分布在主成分1 的正半轴和主成分2 的负半轴。 主成分1 和2 的贡献率分别为50.5%和49.5%, 累计贡献率达到100%, 说明前2 个主成分就能够充分反映原始数据信息, 只是样品的聚集程度不够理想。
PLS-DA 分析属于有监督的模式识别方法,其有效降低组内个体差异对模型的影响, 突出样本组间差异, 有利于寻找差异性代谢物[15]。 将数据集进行 PLS-DA 分析, 结果见图 2(b)。 可以看出, 3个产地茶叶基本实现有效区别, 雅安地区茶叶样本聚集程度最好, 而来自绵阳和宜宾的茶叶样本可能是因为采样区域跨度较大, 得分图中样品点仍然比较分散。 该模型的 R2X (cum) =0.573, R2Y (cum)=0.774, Q2(cum) =0.763, R2和 Q2均>0.5, 说明模型已具有较强的解释能力和预测能力。
O2PLS-DA 分析是经典的最小二乘法CLS 和OPLS 的结合, O2PLS-DA 建立一个线性隐藏变量模型, 在分别代表类型数据的X 和Y 矩阵之间的2 个方向上进行预测, 进一步提高了模型的解释功能, 具有更优越的预测性能[16]。 为了提高分类识别效果, 进一步对数据进行O2PLS-DA 分析, 模型得分图见图 2(c)。 可以看出, 3 个产地茶叶样本分离和聚集程度均大大提高。 R2和Q2为数据模型质量参数, 数值越接近1 说明模型的拟合效果和预测能力越好[17]。 该模型中 R2X (cum) =0.958, R2Y(cum) =0.923, Q2(cum) =0.912, 说明模型具有优异的预测能力。
从图2 中还可以看出, 在3 种模型下宜宾产绿茶和雅安产绿茶样品之间的距离均最远, 表明这2个产地绿茶间代谢物差异性最大, 而绵阳产绿茶与二者之间的代谢物差异相对较小。
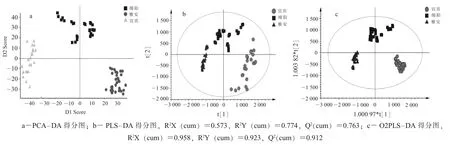
图2 不同产地绿茶的多元统计分析
采用置换检验 (permutation test) 对模型的可靠性进行验证[18], 置换检验次数为200 次, 结果见图3。 从图3 中可以看出, 原始模型的预测能力(即Q2值) 大于左边任何一个Y 变量随机排列模型的 Q2值, 宜宾、 绵阳、 雅安绿茶的 Q2分别为(0.0, -0.308)、 (0.0, -0.302) 和 (0.0, -0.305),在y 轴上的截距均<0, 表明模型没有出现过拟合,可靠性较好。
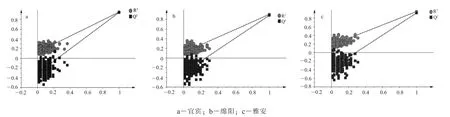
图3 不同产地绿茶的O2PLS-DA 置换检验结果多元统计分析
2. 差异代谢物筛选。 产地溯源研究的关键是筛选出能表征地域信息的有效溯源指标, 建立判别模型。 O2PLS-DA 模型的变量投影重要性 (variable importance in the project, VIP) 在代谢组学研究中是一个常用的判断差异性代谢物的标准, 其值代表了物质对组间分离的贡献, VIP>1 表明此物质为可能的潜在差异性代谢物[19]。 本研究首先采用VIP 值筛选出对组间区分贡献大的变量, 再结合t检验中p值 (<0.01) 对差异性成分进行逐步过滤,原始代谢物的数量逐步减少, 将初步筛选的离子质荷比输入PeakView 1.3.1 软件中提取相应的离子峰, 选择峰型好、 响应高、 二级质谱图质量良好的离子峰, 最终获得50 个具有统计学差异的化合物(VIP>1,p<0.01)[20], 其质荷比 (m/z)、 保留时间(RT) 及 统计学 信 息见 表 1。 初 步 判 断 ,m/z289.0712、 305.0658、 441.0829 及 457.0782 分别为(-)-表儿茶素、 (-)-表没食子儿茶素、 (-)-儿茶素没食子酸酯、 (-)-表没食子儿茶素没食子酸酯及其异构体, 可见, 儿茶素类在不同产地绿茶间代谢差异显著[21~22], 可以作为绿茶产地溯源的部分指标, 其他差异组分的结构鉴定及代谢机理有待进一步研究。

表1 50 个统计学差异的化合物 (VIP>1, p<0.01)
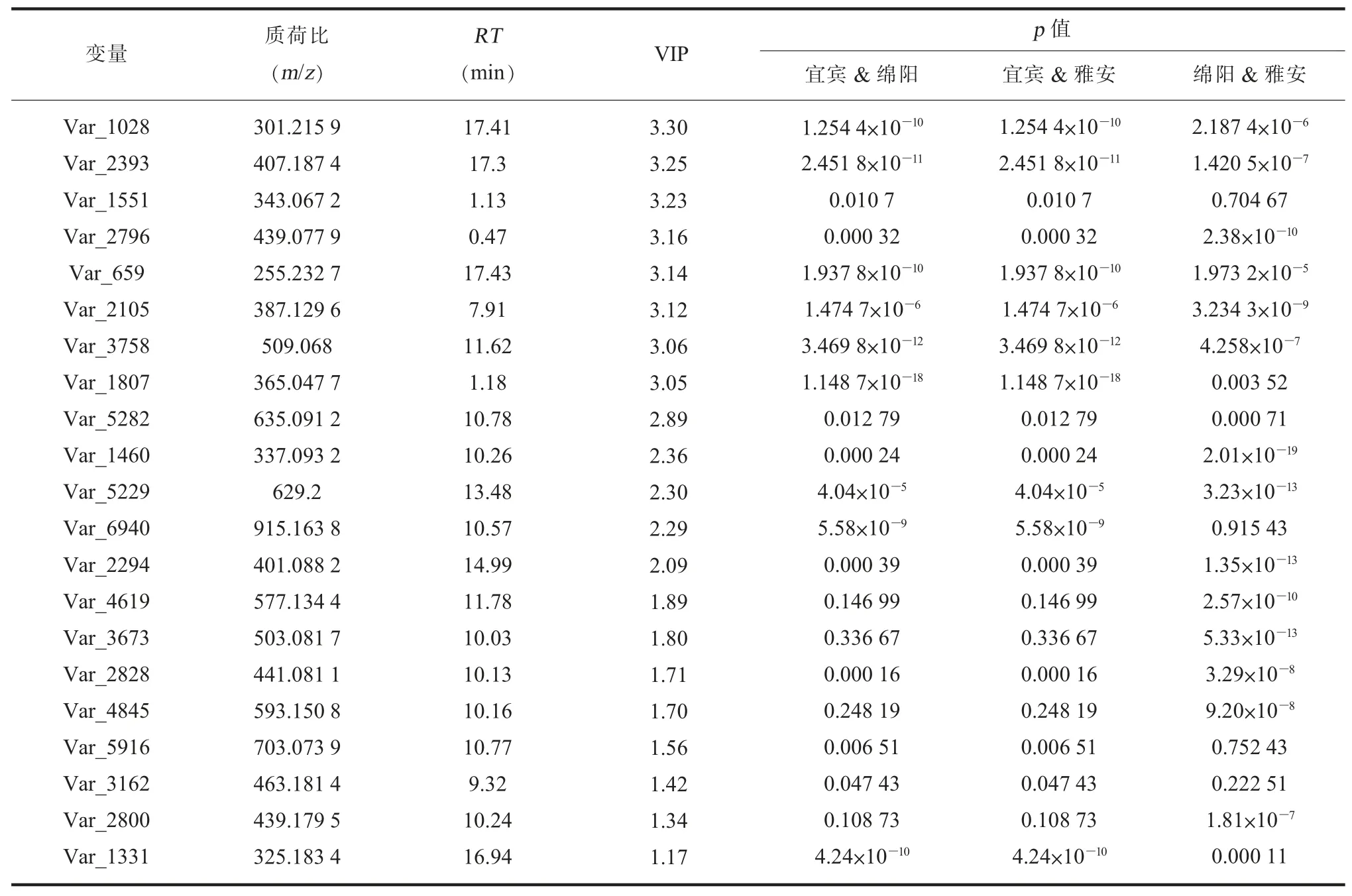
续表1
将筛选出的50 个差异成分作为特征变量建立统计模型 O2PLS-DA, 结果见图 4。 可以看出 3个产区的绿茶样品可以有效区分, 模型的典型相关系数 R2X(cum)=0.983, R2Y(cum)=0.887, 说明98.3%的变量可解释88.7%的组间差异, Q2(cum)=0.849, 表明该模型具有较好的预测能力[17]。

图4 不同产地绿茶基于50 个差异成分的O2PLS-DA得分图
三、 结论
本研究基于茶叶的生化成分和滋味品质与茶树的生长环境和气候条件等因素的密切关联, 采用UPLC-QTOF-MS 分析技术结合多元统计方法,建立了四川省雅安、 宜宾和绵阳3 个产区绿茶的产地溯源方法。 分别通过主成分分析与判别分析(PCA-DA) 及双向正交偏最小二乘-判别分析(O2PLS-DA) 对不同产区绿茶构建分类模型, 典型相关系数及置换检验 (permutation test) 表明O2PLS-DA 模型具有优异的预测能力。 结合VIP分析和t检验, 初步筛选出50 个存在统计学差异的化合物 (VIP>1,p<0.01)。 有关差异代谢物的结构鉴定及代谢机理有待进一步研究。 本研究建立的分类模型为茶叶的产地溯源和质量评价提供理论基础和科学依据。
猜你喜欢
现代临床医学(2022年4期)2022-09-29
中山大学学报(自然科学版)(中英文)(2022年4期)2022-08-05
现代仪器与医疗(2022年1期)2022-04-19
食品安全导刊(2021年20期)2021-08-30
现代仪器与医疗(2021年2期)2021-07-21
今日农业(2021年4期)2021-06-09
海峡姐妹(2020年2期)2020-03-03
中国外汇(2019年22期)2019-05-21
意林·全彩Color(2018年9期)2018-10-12
分析化学(2018年12期)2018-01-22
