
基于改进Faster R-CNN算法的行人检测
2021-09-23 07:06单志勇张鐘月
现代计算机 2021年23期
单志勇,张鐘月
(东华大学信息科学与技术学院,上海201600)
0 引言
随着智能科技的进步和社会科学潮流的发展,在生活很多的应用中都可以看到智能化技术的身影,基于视觉的行人检测是智能监控、智能驾驶、无人驾驶等领域的重要组成部分。行人检测属于是目标识别领域的研究热点及难点,在生活中有广泛的应用。准确的检测出各类场景中的行人在监控等技术领域上具有重要意义。20世纪80年代,Marr提出了相对完整的计算机视觉理论体系[1]。运动目标的跟踪技术发展是从20世纪80年代开始的,并且成为了计算机视觉技术领域研究的一大热点。
行人检测也就是对图像中的行人进行检测和识别,与此同时确定其行人在图像中所处位置进行定位。行人检测算法大致可以分为以下几类,分别是基于背景建模、轮廓模板、底层特征和统计学习。基于Codebook背景建模算法是通过提取运动前景,缩小检测过程的搜索范围,构建临时块模型,结合行人检测结果更新背景模型,以此来实现行人检测[2]。全局模板法是由Gavrila等人所提出的,该方法构建了近2500个轮廓模板用来对行人进行识别[3]。局部模板法是由Broggi等人提出的,该方法采取一种提取人的头以及肩部的不同大小的二值图像特征模板来进行行人检测识别功能[4]。这种方法是在原本的图像上进行计算,缺点是需要提前构建大量的行人检测模板才能取得比较好的匹配结果。目前所存在的行人检测方法主要有以下几个不足之处:①底层特征的使用对行人的检测能力不足;②行人的特征分辨较差,容易造成分类错误,使得检测错误率高;③目标特征针对性较强使得特征对应单独的场景而在其他场景的情况下很难达到很好的效果。2006年Hinton[5]团队提出了一种模拟人脑进行基于深度学习的算法,将高层特征通过深度卷积神经网络从极多的数据中学习出来。深度卷积神经网络将特征提取、特征选择以及特征分类融合在同一模型中,通过端到端的训练,从整体上优化检测功能,以此来增强了特征的分类。Girshick R团队提出了区域卷积神经网络(R-CNN)模型[6]。为有效解决行人目标的遮挡以及形变等问题,Ouyang等人提出了一种方法即利用卷积神经网络提取行人特征[7]。YANG团队提出了基于稀疏编码的非监督学习方法[8],该方法比传统行人检测算法更有效。
实验中利用Faster R-CNN[9]算法来进行运动中的行人检测,算法中利用DetNet神经进行特征提取[10],采用区域建议网络RPN生成建议候选区域,使用检测网络对行人目标进行分类和定位。与此同时还采用ROI Align来进行图像特征映射。实验中使用INRIA行人数据集和USC行人数据集训练该模型。
1 Faster R-CNN的行人检测方法
Faster R-CNN是区域卷积神经网络,它的提出是为了解决选择搜索方式中寻找建议区域速度太慢的问题。Faster R-CNN整体的流程可以分为三步:首先,输入图片,图片经过预训练网络(实验中采用的是DetNet),提取出图片的特征;其次,将提取的特征经过RPN网络,产生一定数量的候选框(每张图上都有2000个候选框);最后则是预测的分类与回归结果,将候选框和图像特征都输入到ROI head里面,对候选区域进行分类,判断其类别,与此同时还会对候选区域的位置进行微调。改进的Faster R-CNN结构流程如图1所示。
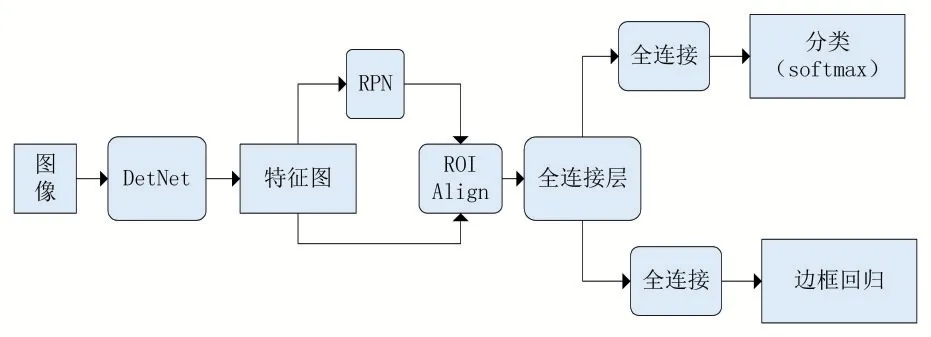
图1 改进的Faster R-CNN结构流程图
1.1 DetNet主干网络
要解决的问题有以下两个:使得图片中小目标不会消失的同时能够确保获得的特征图有清楚的边界,则从图片中提取出的特征图要能够有足够大的尺寸;通过采用减少下采样的方式来确保特征图的分辨率足够高而且感受野的大小也不会受到影响。对于图像的特征提取网络这里选择使用DetNet。DetNet网络结构如图2所示,DetNet结构中的阶段1到阶段4的网络结构与ResNet50结构相同,而阶段5中的结构与ResNet50结构中的区别主要体现在ResNet50结构中原尺寸是该stage5的特征图的32倍。该网络结构还增加了额外的阶段6。由图2可以看出,阶段4到阶段6这三个阶段的幅度都是16,也就是说该网络结构下原图尺寸是这三个阶段的特征图尺寸的16倍。图中可以看出阶段5和阶段6都有256个输入通道,与每个阶段通道数都增加一倍的传统主干网络不同,这一做法是考虑了计算量和内存的问题。
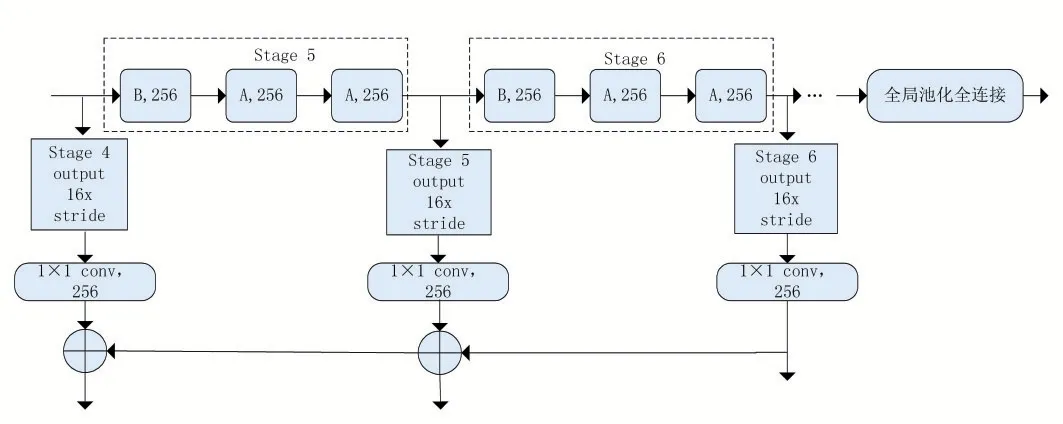
图2 DetNet网络结构
DetNet网络结构中使用了dilation技术,其中di⁃lated bottleneck分为A和B两种,DetNet和ResNet残差对比如图3所示。确保特征图尺寸的大小也就是要增大感受野是该技术的主要目的。
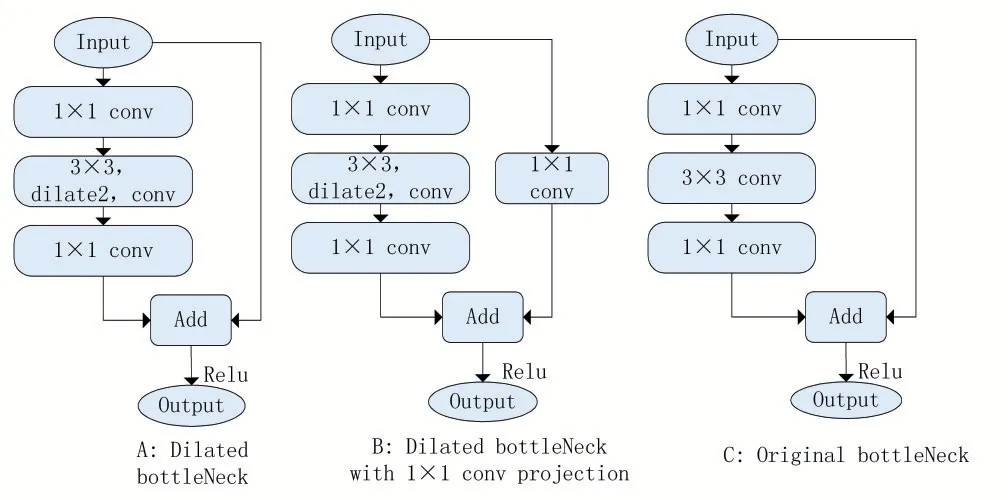
图3 DetNet和ResNet残差对比
1.2 RPN网络
在候选框的产生上面,采用了区域选取网络(RPN)。RPN网络结构如图4所示。
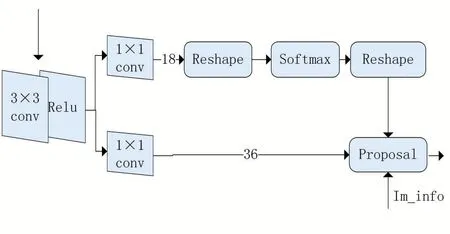
图4 RPN网络结构图
由图4可以看出将图像的特征图输入到RPN网络结构中,通过3×3 conv和relu层后分成两个1×1 conv部分,一部分通过Softmax预测分类概率,分析是目标本身还是图片背景从而获得最有可能存在物体的先验框anchor;另一部分是计算针对原图坐标的偏移量从而选取准确的区域。最后综合正先验框和对应的边框回归偏移量来提取目标区域。
RPN网络的运行机制如图5所示:图像的卷积特征图上的每个像素点都有k个先验框,然后去判断这个框有没有覆盖到物体,并且会为含有物体的先验框进行坐标调整。检测目标和背景分为两类属于二分类所以class layer得到2k个scores。而坐标修正是x、y、w和h,所以reg layer得到4k个坐标。RPN整体上是依靠在一个图片特征图上的滑动窗口,可以为每个像素点生成9种目标框。先验框的面积分别有128×128、256×256、512×512,长宽比是1:1、1:2、2:1,所以由面积和长宽比两两组合会形成9种目标框an⁃chor。
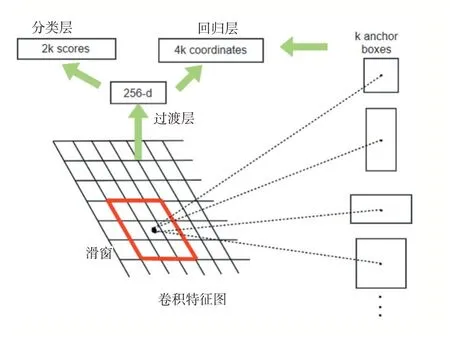
图5 RPN网络的运行机制
1.3 ROI Align
传统技术中ROI Pooling中区域不匹配是因为两次量化而产生的,所以这里采用了ROI Align区域聚集方式来解决该缺点。ROI Align会经过特征图上每个选取的区域,此时边界是浮点数类型的,ROI Align不对该边缘信息作量化处理。然后将建议选取区域分割成k×k个矩形单元,分割所得的单元的边界信息不进行量化处理。在每个矩形单元中按照一定的规则确定四个点的位置,再用双线性插值的方式计算出这四个点位置的具体值。最后,在这四个值上进行最大池化操作。其中双线性插值法具体做法如图6所示。
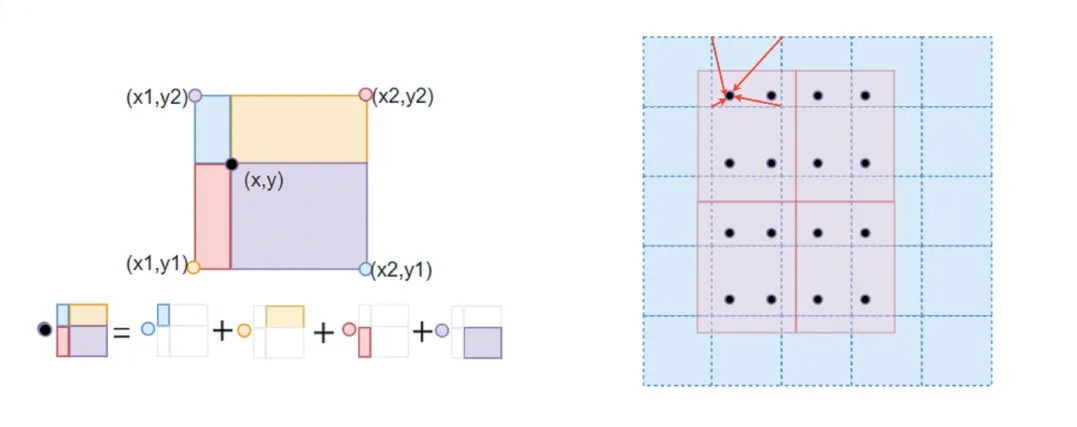
图6 ROI Align双线性插值
ROI Pooling的反向传播公式为:
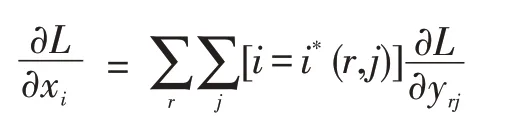
其中,xi表示池化前特征图上的像素点,yrj表示池化后的第r个候选区域的第j个点。进行最大池化操作后挑选出来的最大像素值存在的点的坐标就是i*(r,j)表示yrj像素值。由以上公式可以看出,要想使得某个点可以在xi处回传梯度,该点必须满足池化后的某一个点的像素值在池化过程中采用了当前点xi的像素值即满足i=i*(r,j)。
在ROI Align中,xi*(r,j)是一个浮点数的坐标值也就是前向传播时计算出来的采样点。特征图在进行池化操作前,能接收对应的点yrj回传的梯度的要求是每一个和i*(r,j)横纵坐标都要小于1的点。ROI Align的反向传播公式如下:

其中,d(,)代表两点之间的距离,∆h、∆w表示xi和xi*(r,j)横纵坐标的差值,它们将作为双线性内插的系数与原始梯度相乘。
2 实验结果及分析
实验采用INRIA行人检测数据集以及USC数据集等公开数据集,以及道路上采拍图像共计10111张图片,公开数据集中含有原始图像及其标注文件,实验开始前将公开数据集分别转化成VOC格式的数据集以便训练模型。道路采拍图像选择用labelImg标注工具进行自行标注。按VOC格式需要建立文档作为备用。INRIA行人检测数据集中的图片来源于个人网站以及谷歌网页等,清晰度很高便于训练模型。USC数据集有三个数据集包,涵盖了各个角度拍摄的行人图像,包括正面背面以及侧面,人与人之间有无遮挡的图像也均含有。
实验硬件配置为Intel Core i7处理器,内存16G,远程连接外部服务器,GPU是NVIDIA GeForce 1080Ti,11G显存,62G内存。实验中行人检测结果如图7所示。

图7 行人检测效果
实验记录了模型训练过程中各类损失曲线图,如图8所示:roi_loc_loss、roi_cls_loss、rpn_loc_loss以及rpn_cls_loss分为两类损失,一部分是分类损失,另一部分是回归损失。由图可以看出,模型训练过程中损失整体呈现下降趋势。
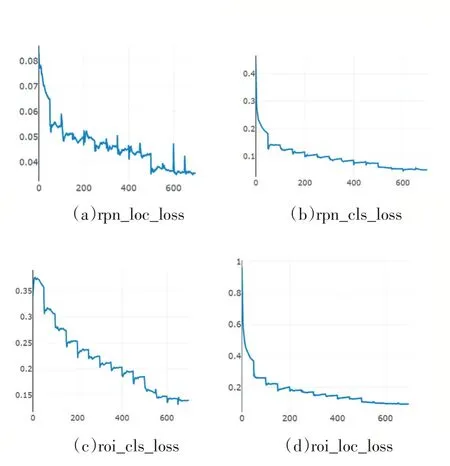
图8 两类损失曲线
实验中测试的MAP值随着迭代次数的增加逐渐增大最后逐渐趋于稳定,迭代次数达到6次时MAP值为0.6150,迭代次数达到12时,MAP值为0.6934;当迭代次数达到18时,MAP值为0.7627;当迭代次数达到20时,MAP值达到最大为0.7810。
3 结语
实验利用公开的USC行人数据集和INRIA数据集以及自制的数据集进行模型训练和测试,验证了DetNet主干网络提取特征值以及使用ROI Align进行映射池化对行人检测模型产生的有效性,为之后在实际场景中的应用提供了基础。
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
意林(2021年5期)2021-04-18
计算机系统应用(2019年9期)2019-09-24
扬子江(2019年1期)2019-03-08
智能计算机与应用(2018年2期)2018-05-23
小天使·一年级语数英综合(2017年6期)2017-06-07
科技视界(2016年18期)2016-11-03
软科学(2014年8期)2015-01-20
