
小样本下目标特征细分加权的汽车需求量预测
2021-09-23 07:05焦笑任春华司佳顺
现代计算机 2021年23期
焦笑,任春华,司佳顺
(1.西南交通大学,制造业产业链协同与信息化支撑技术四川省重点实验室,成都611756;2.北京机械工业自动化研究所有限公司,北京100120)
0 引言
据汽车工业协会最新对汽车市场的分析结果表明,我国汽车产业经济运行态势恢复良好,2020年9月汽车产销呈两位数增长,累计汽车产销降幅已至7%以内[1]。对于汽车制造企业来说,按需生产,是减少制造成本、提高决策效率的关键途径。本文研究对象为汽车产业链协同平台[2]上的中小型企业,针对该类企业中某一个车型来说,其日销量数据较小,且存在实际销售日期不连续的情况,具有明显的小样本数据特征。本文源于实际“整车销售业务”流程,对目标特征进行细分加权,构建小样本条件下的汽车需求量预测模型,为汽车制造企业制定合理的销售计划提供决策支持。
1 相关工作
小样本数据下的学习模型,主要包括基于模型微调、基于数据增强和基于迁移学习[3]。而对于小样本下的销量预测问题,目前也存在很多基于模型优化的解决方法。常用的时间序列预测模型,如:ARMA、ARIMA等,只适合直接预测短期“下一个”数值[4],而对于需长期预测的场景,基于多学习器集成学习的树模型、处理时间序列问题独具优势的RNN(递归神经网络)及其相关变体[5]、多种算法组合预测模型等应用极为广泛。何喜军等人[6]分别对比XGBoost模型、BP神经网络、SVM支持向量机及BP-SVM组合预测模型,来验证小样本下融合多种特征指标可有效提高预测精度。Pavlyshenko等人[7]则主要使用线性模型、ARIMA、XGBoost来分别对时间序列预测问题进行建模。LSTM(长短时记忆网络)是RNN神经网络的一种变体,被广泛用于处理时间序列问题。Weng等人[8]提出基于LightGBM和LSTM的组合模型来进行供应链销售量预测,该组合模型可快速、高效地解释供应链销售情况。冯晨等人[9]提出了一种基于ARIMA+XGBoost+LSTM的加权组合方法,使用ARIMA预测线性平稳序列,XGBoost进行多维特征分析提取,LSTM则对非线性序列进行拟合。由此可见,结合单一模型的特定优势形成的组合模型,在同时拟合时间序列线性和非线性成分问题上已被广泛应用。
针对下一阶段(一个周、两个周、一个月等)的实时长期预测问题,其训练数据集来源于对实际销量的实时提取,但可能存在一些“未审核”、“未结算”或者需要“反审核”的订单,即所在业务流程“未完成”的数据,从而导致目前数据的可用性无法确定。因此,针对实时销量预测,本文提出一种基于业务流程执行状态的目标特征细分提取方法,以此来增强小样本下特征空间的多样性。
2 目标特征细分及加权方法
2.1 基于业务状态的细分加权方法
通过对汽车产业链平台上多家制造厂的“整车销售业务”流程分析,针对一条销售数据,其业务主要包括“表单审核”、“开票结算”、“交付收货”等3个关键节点,即状态序列Ti中包括以下5种状态:
Ti=1,表示状态“待审核”;Ti=2,表示状态“已审核,待结算”;Ti=3,表示状态“已结算,待交付”;Ti=4,表示状态“已交付”;Ti=5,表示状态“已取消或已删除”。
通过以上5种业务状态判别,为整车销量数据划分了更细的粒度。为实现进一步特征增强,可对各细分状态进行线性加权,以得到新特征SF,如公式(1)所示。
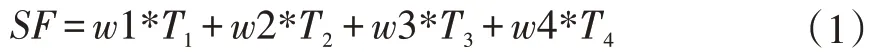
其中,[T1,T2,T3,T4]为每个状态对应的销量数据,(w1,w2,w3,w4)∈(0,1)且w1+w2+w3+w4=1。
为选择一组最优权值[w1,w2,w3,w4],本文采用“Pearson相关系数”来观测5组权值下的SF特征和预测值之间的相关关系[10]。各组对比结果如表1所示。
根据以上5组不同权值的Pearson相关系数分析,可看出(0.1,0.2,0.3,0.4)这一组权值与预测目标值的相关性最高。此外,分别使用以上5种加权特征在XGBoost模型训练,得出的预测结果也是如此(见实验部分表5)。综合表1分析,当越接近“完成”状态的特征所占权值越高,其加权特征与目标值的相关度越高,这也刚好符合业务流程执行的过程,即业务流程越接近完成,数据可靠程度越高。
2.2 预处理及特征构造
针对“HB”制造厂中某车型,其日销量较小,且存在实际销售日期不连续的情况。若按日统计销量,会导致大量数据缺失。结合实际调研,制造厂会根据历史销量提前人为制定下一阶段的销售“周计划”、“月计划”。因此,按周统计销量,相较于按天统计,构造的数据集缺失更少,也更符合实际需求。除销售数据外,该车型的当前市场保有量也可能对整车需求量存在制约关系,可通过“客户档案”和“汽车档案”间接获取。结合以上分析,数据预处理过程主要包括如下5个步骤:
(1)选取某车型,按日提取其历史销售数据,注意:剔除“无效数据”(T5状态)。
(2)连续日期补全,并按周统计销量。缺失的个别周销量,使用当月各周均值代替。
(3)计算截止到当前周,该车型的整车保有量。缺失的个别周,使用当月各周均值代替。
(4)根据每条周销量数据细分状态,统计对应各状态的销量及加权特征,
(5)由于销量数据上下界存在较大波动,需将销量进行对数平滑和归一化处理,见公式(2)-式(3),从而缩小数据范围,尽量缓和波动较大数据对模型预测的影响[11]。

依据上述预处理过程,本文主要从以下4个维度来对当前时间周t进行特征向量提取。
(1)实时销售数据:按周提取最近一个月内四周的观测值及平均值。
(2)加权特征数据:按周提取最近一个月内四周的销量细分加权特征及平均值。
(3)时间维度特征:当前年份、当前月份、当年的第几周。
(4)整车保有量数据:提取截止到当周前的整车市场保有量数据。
3 基于XGBoost+LightGBM+LSTM的组合预测模型
3.1 模型相关理论
(1)XGBoost模 型。XGBoost是 一 种 在 基 于GDBT(梯度提升决策树)算法演化而来的Boosting集成学习算法[12],其预测值基于Boosting加法模型,即将每棵树中样本特征所对应叶子节点的分数相加,公式如下:
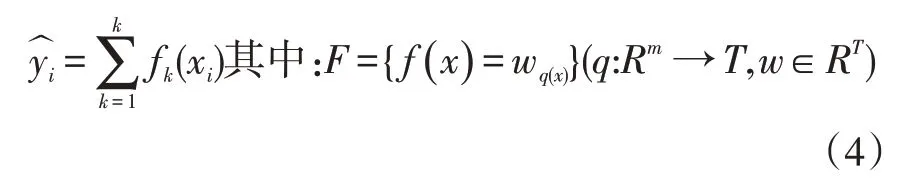
XGBoost目标函数与GBDT的不同在于,引入了L1和L2正则项函数,定义如下:
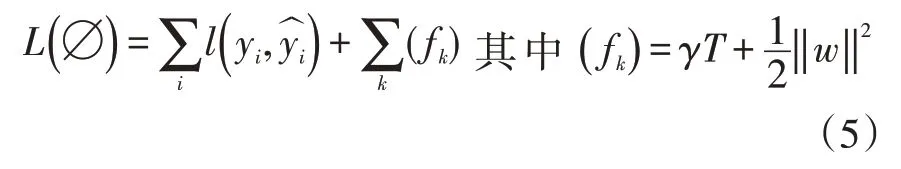
目标函数由损失函数和正则项函数两部分组成。是预测输出,yi为目标值,T是树叶子节点树,w为叶子权值,γ和λ为惩罚正则项。正则项对每棵树的复杂度进行惩罚,以达到剪枝和防止过拟合的效果。
(2)LightGBM模型。LightGBM也是基于GBDT原理实现,针对传统Boosting算法在大样本高维度环境下寻找最优切分点造成的耗时问题,LightGBM设计了一系列策略来优化模型的特征选择,加快模型迭代速度[13]。如采用基于Histogram直方图的决策树算法来减少特征离散化所需的空间与计算代价;使用leaf-wise深度优先分裂策略并添加一层最大深度限制,来防止模型过拟合;此外,采用基于梯度的单边采样算法(GOSS),在计算信息增益梯度时,选取较大梯度的样本点,小梯度样本添加系数随机采样,以提高特征选择的效率。为解决高维度空间的数据稀疏问题,提出互斥特征绑定算法(EFB)借助图模型对稀疏空间中的互斥特征进行合并。
(3)LSTM模型。LSTM模型是RNN的变体,其在原始RNN基础上分别增加了输入门、输出门、遗忘门,并引入独特的长时间选择性记忆单元,有效解决了RNN的梯度消失、梯度膨胀及长期记忆能力不足等问题[14-15]。LSTM神经网络记忆细胞结构如图1所示。
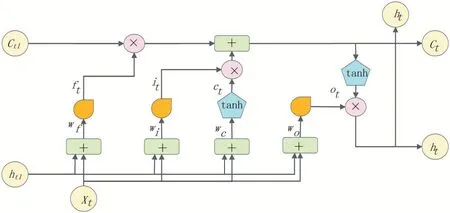
图1 LSTM神经网络记忆细胞结构
由图1可看出,LSTM模型通过3种类型的门来控制当前t时刻的单元状态。①遗忘门,通过ft决定上一时刻单元状态ct-1被传递到的程度。②输入门,it决定输入信息,~ct为此次输入生成的新信息。③输出门,Ot用来决定当前时刻ct输出多少信息,ht为LSTM当前输出。以上各个状态的产生,满足如下公式:

其中,sigmoid函数产生[0-1]的值,1表示全部保留,0表示全部忘记。tanh函数则将值处理为[-1,1]之间。wf,wi,wc,wo为权重矩阵。bf,bi,bc,bo为偏置项。
3.2 组合模型构建
针对下一阶段的实时销量预测,属于典型的时间序列预测问题。LSTM模型最大优势在于对长时间跨度的历史数据具有选择性感知记忆能力,适合处理长期的销量预测问题[16]。由于按周统计的销量数据具有小样本特征,与整车需求量相关的影响因素指标又较多,为防止所有特征指标均输入到LSTM模型造成网络结构过于复杂,导致模型过拟合而影响预测精度。本文首先采用Boosting集合中的两个代表算法XGBoost和LightGBM对多维变量指标进行特征抓取,然后将两者的预测值进行加权融合,再与原始销量特征进行合并,输入到LSTM中进行模型训练。该组合预测模型框架如图2所示。
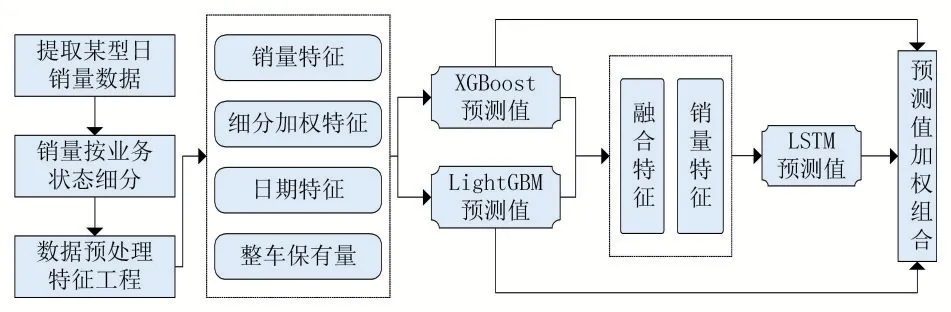
图2 预测模型整体框架
具体模型构建步骤如下:
(1)训练数据集构造。针对每个目标值y,提取与之对应的特征向量序列x进行数据集构造,即
(2)XGBoost和LightGBM预测。将数据集分别放入XGBoost和LightGBM模型中作训练,经过模型调参,分别得最优模型下的预测值res1和res2。
(3)融合特征构造。将XGBoost的预测值res1和LightGBM的预测值res2进行加权组合得res12,拼接res12和原始销量特征成为下一层模型的训练数据集D。加权组合策略如下:
①加权条件:当res1和res2分布居于目标值Label的“上下”,即偏离目标值的程度满足“一个上一个下”时,线性加权效果最优,如实验部分图4所示。
②算术加权:res12=a*res1+(1 -a)*res2,其中a∈(0,1)。
(4)LSTM模型多维多步时间序列预测。针对需要预测的m周,分别构造预测每个周的训练数据集,即:利用前k个周的特征预测当周销量,k为序列长度。
(5)模型组合加权。分析3个单一模型的预测结果,结合上述模型组合策略,对3个单一模型进行有效组合,得到最终的最优预测结果Pred。
4 实验与结果分析
实验数据集来源于汽车产业链平台上的“HB”制造厂,提取实时数据库中2014年至2020年的3款不同车型(“HB610W”、“HB610”、“1030W10FV”)实时备份的日销售数据,分别构建原始特征集(Original)和添加“目标值状态细分加权特征”的新数据集(Sub⁃Divison),并对测试样本(样本数据中最后的3个月的m周)进行整车需求量预测。
4.1 实验环境及模型参数
本文实验环境:操作系统Windows 10(64位);基于Python 3.6.5的编程环境;XGBoost模型为0.90版本;LightGBM模型为3.1.1版本;LSTM模型为Keras 2.2.4深度学习框架,后端搭建TensorFlow 1.12.0。经过多次实验调试,各最优模型参数分别如表2—表4所示。

表2 XGBoost模型核心参数表

表3 LightGBM模型核心参数表

表4 LSTM模型核心参数表
本文的LSTM模型包括:第一层LSTM层,神经元个数为32;第二层LSTM层,神经元个数为32;第三层是一层输出为1维的神经网络,激活函数选用PReLU函数。
4.2 实验结果及分析
为更好评价模型的预测效果,本文采用4种常用指标来进行误差评估,分别是均方根误差公式(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、对称平均绝对百分比误差(SMAPE),公式如下:
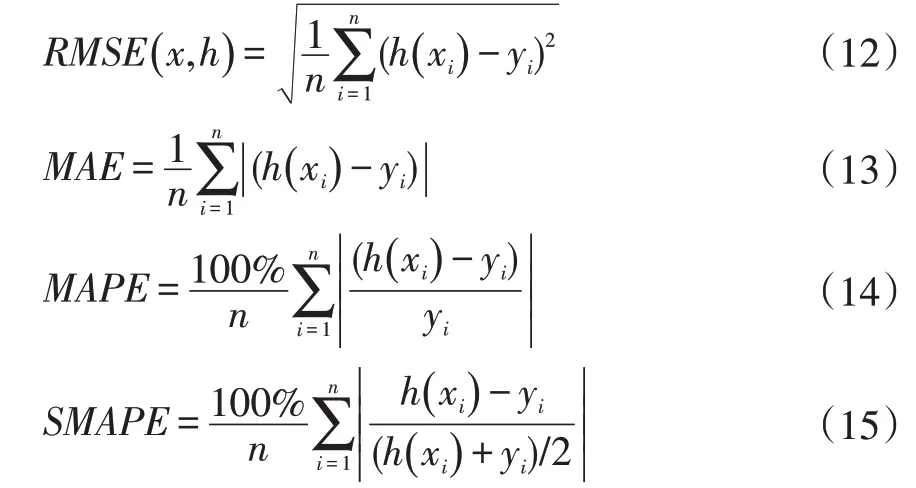
(1)“目标值细分加权特征”的权值选择实验。第一组实验选用“HB610W”车型的数据,在XGBoost模型上进行训练、验证,预测结果如表5所示。
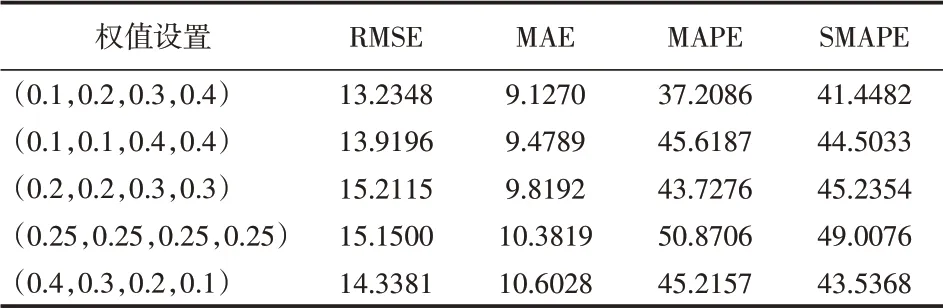
表5 5组权值预测结果误差对比结果
综合实验结果可知,(0.1,0.2,0.3,0.4)这一组权值构造的特征,其预测效果最好。与3.2小节中“Pearson相关系数”计算的对比结果基本保持一致。(0.1,0.2,0.3,0.4)这组权值在本实验中表现较好,但对于最优权值的判定,仍需进一步通过权值优化算法得出。
(2)不同车型同一模型的预测结果对比。第二组实验对3款不同车型的销售数据,分别构造“Origi⁃nal”和“SubDivison”两种特征集,然后分别在XGBoost模型上进行训练、验证,预测结果如表6所示。
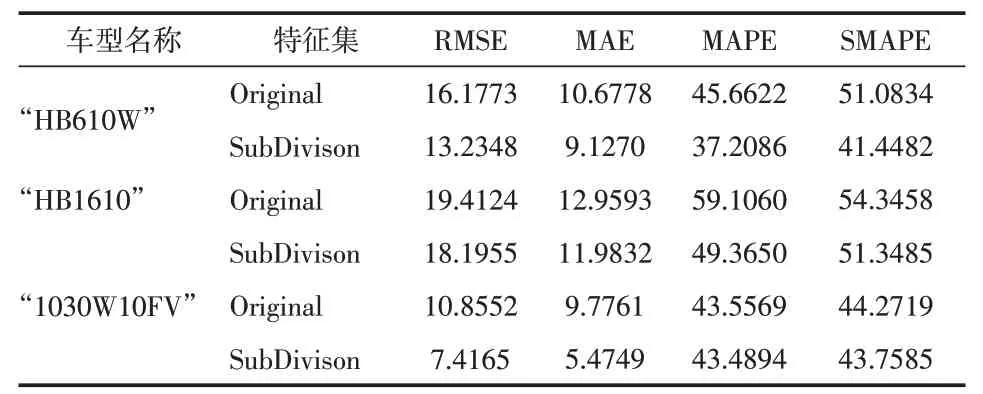
表6 3种数据集上的预测结果误差对比
综合以上3种数据集分析,“添加了目标值细分加权特征”的模型,其4种误差评价指标相较于原始特征,皆有所下降。由此可见,对目标销量进行状态细分,提取其加权特征,可进一步提高“整车需求量预测”准确度。同时,该目标值细分提取方法对于不同的样本数据集具有一定适用性。
(3)同一车型多种模型预测结果对比。第三组实验选用“1030W10FV”车型及其“添加了目标值细分加权特征”的“SubDivison”的特征集,分别在多种单模及其加权组合模型上进行训练、验证,预测结果如表7所示。
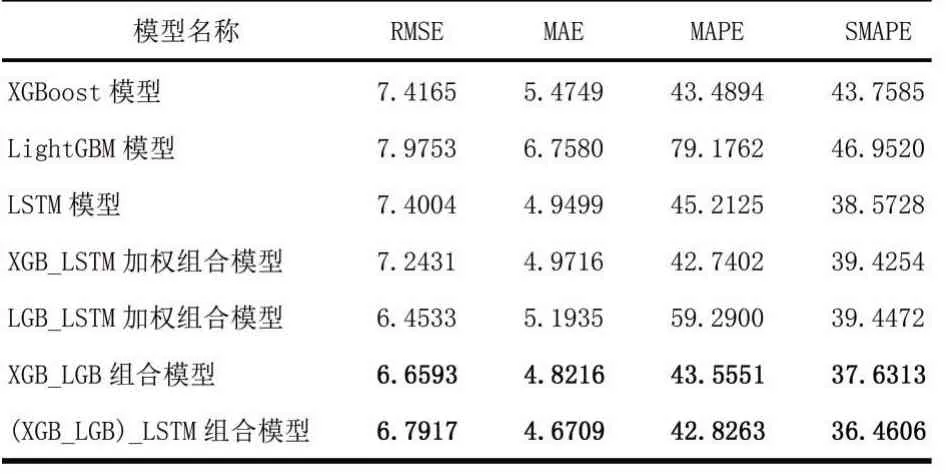
表7 “1030W10FV”车型数据在多种模型上的预测结果误差对比
从表7可知,单一模型中,LSTM模型效果最佳,其预测误差相对较小,各模型对比结果如图3所示。由3.2小节模型加权组合策略可知,当两个模型的预测结果偏离目标值刚好“一上一下”时,其组合效果最佳。实验显示,“XGB_LGB组合模型”相比于其他“两两”组合,其预测误差较小。此外,将“XGB_LGB组合模型”结果与LSTM再进行加权融合,可看出预测效果再次提升,如图4中紫色折线所示。通过实验表明,组合预测模型相较于单一模型,有效提高了模型预测的泛化性和准确度。
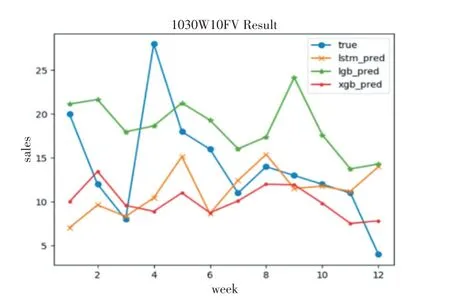
图3 单一模型上预测结果对比
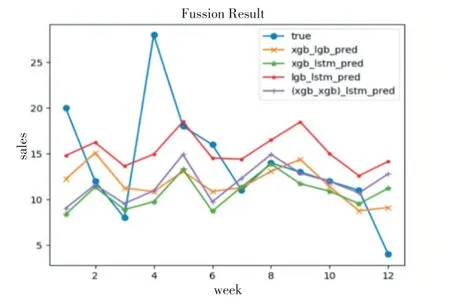
图4 不同模型加权组合预测结果对比
5 结语
本文研究实际“整车销售业务”流程,提出了基于业务执行状态的目标特征细分处理方法,从而进行小样本条件下的特征增强。通过3组实验表明,使用“添加目标细分加权特征”的数据集训练模型,其性能优于“原始特征”训练,进一步验证了小样本下对目标特征进行细分加权的可行性和实际意义。本文虽然对比了5组不同的加权特征,最终选定一组最为合适的权值,但这组权值可能并不是最优的,如何更加科学地找出最优权值组合,是下一步需要改进的方向。此外,实验结果显示,针对小样本数据集,组合模型预测可以有效提高预测精度,未来还需研究更多不同模型的组融合方案。
猜你喜欢
消费电子(2022年6期)2022-08-25
成都信息工程大学学报(2022年3期)2022-07-21
电子产品世界(2021年6期)2021-02-10
电子产品世界(2021年5期)2021-02-09
华人时刊(2020年19期)2021-01-14
戏曲研究(2020年1期)2020-09-21
华人时刊(2020年23期)2020-04-13
大陆桥视野·下(2017年1期)2017-03-09
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
