
结合目标检测的室内场景识别方法
2021-09-18 06:22徐江浪李林燕万新军胡伏原
计算机应用 2021年9期
徐江浪,李林燕,万新军,胡伏原*
(1.苏州科技大学电子与信息工程学院,江苏苏州 215009;2.苏州经贸职业技术学院信息技术学院,江苏苏州 215009)
(*通信作者电子邮箱fuyuanhu@mail.usts.edu.cn)
0 引言
近些年来,随着互联网的普及以及人们生活水平的不断提高,场景识别技术的发展为人们带来越来越多的服务和便利。室内场景识别是场景识别的关键部分,室内场景识别技术的发展在智能家居、服务机器人、安防监控等领域都有着广阔的应用前景[1-2]。
在早期,室内场景识别一般都是利用颜色、纹理、形状等特征进行识别,随着诸如尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)、加速健壮特征(Speeded-Up Robust Features,SURF)、方向梯度直方图(Histogram of Oriented Gradients,HOG)等算子的广泛应用,比较流行的分类方法是利用各种算子提取场景特征,以此训练出较好的模型实现场景识别,其中应用较广的是词袋(Bag-Of-Words,BOW)模型,产生了基于BoW 模型的一系列场景识别方法。Lazebnik 等[3]提出的一种基于空间金字塔(Spatial Pyramid)的BOW 模型场景识别方法为后来的研究学者提供了思路,不少学者在此基础上作出了改进和创新;但是这类方法很大程度上依赖人工算子进行特征提取,导致泛化能力不足,而深度学习方法在这一方面有了很大的改善。
在基于深度学习的方法中,出现了多种以卷积神经网络(Convolutional Neural Network,CNN)为基础的方法[4-7]。由于复杂的室内场景包含多种目标,全局特征难以表达这些目标特征,基于此,Quattoni等[8]提出结合全局特征(Global Feature)和局部特征(Local Feature)来识别室内场景,利用局部特征表示目标特征,提高了识别准确率。Cheng等[9]提出一种用于场景识别的具有对象性的语义描述符方法,利用不同场景中对象配置的相关性,通过场景中所有对象的共现模式来选择有代表性的和有区别的对象,增强了类间的可区分性。Herranz 等[10]提出了一种基于多尺度特征的方法,将不同尺寸的图像分别送入适合它们的目标网络和场景网络来分别提取特征,解决了图像尺寸和识别网络的匹配问题,但是尺寸的不断增加导致了方法复杂度的增加。Wang 等[11]提出了一种知识指导消歧(Knowledge Guided Disambiguation)策略,利用知识网络提取的目标特征生成场景图像的软标签,指导场景网络最小化损失函数,有效地解决了类间差异小和类内差异大的问题,但是目标特征的利用率仍较低。为了使网络更加关注场景图像的显著区域,Rezanejad 等[12]提出一种基于场景轮廓的场景分类方法,利用场景轮廓传达的形状和表面的几何形状作为信息输入进行场景识别,这种基于中轴的显著性度量方法增加了场景特征中有用的信息。Sun 等[13]也提出一种场景识别的综合表示方法,该方法融合了从物体语义、全局外观和上下文外观这三个区别视图中提取的深层特征,利用特征的多样性和互补性,以及场景图像的上下文信息,提升了识别准确率。尽管上述方法已经取得了显著的效果,但是对于结合目标检测的室内场景识别方法而言,场景图像中目标特征的利用效率极大地影响了室内场景识别效果,而这是当前亟待解决的问题[14-17]。
由于场景图像中包含多种目标信息,但并非所有的目标都对场景识别产生积极作用,甚至有些会产生反作用影响最终的识别效果(如卧室中出现的电脑、餐厅中入镜的沙发等);而且,在进行场景特征和目标特征之间的融合时,由于两种特征的维度不一致,在特征融合时会造成信息丢失等问题。因此,本文提出了一种结合目标检测的室内场景识别方法,主要思想是:1)为了解决特征维度不一致的问题,本文利用类转换矩阵(Class Conversion Matrix,CCM)对目标特征的维度进行转换,使目标特征在与场景特征融合时能够减少信息丢失;2)针对冗余信息的问题,本文采用了上下文门控(Context Gating,CG)机制对目标特征中所包含的冗余信息进行抑制,降低不相关信息的权重,提高室内场景识别中目标特征的利用效率,使网络更加关注图像的相关目标区域,提高室内场景识别的准确度。
1 结合目标检测的室内场景识别方法
1.1 网络结构
本文以Inception 为基础网络架构,网络框架由场景识别网络PlacesNet(本文图示以MR-CNNs(Multi-Resolutions CNNs)为例)、目标检测网络(Object detection Network,ObjectNet)两个部分组成,如图1 所示。PlacesNet 是用来提取场景特征的CNN 模型;ObjectNet 用来提取目标特征,为了获得更精确的目标特征,本文采用了在ImageNet 上预训练过的CNN 模型。然后,提取的特征进入特征融合模块(Feature Fusion Module),该模块通过卷积层+ReLU(Rectified Linear Unit)和哈达玛积的组合将两个网络的输出特征进行融合;最后,经过softmax 层进行分类,输出最终结果。作为改进,本文将CCM 置于ObjectNet 提取的目标特征之后,对它进行转化,使它的特征维度和场景网络提取的特征维度一致;在融合目标特征和场景特征之前,采用CG对目标特征中可能存在的冗余信息进行了抑制,以此提高目标特征的利用效率。

图1 网络框架Fig.1 Network framework
1.2 特征转换
为了将ObjectNet 提取的目标特征转化为场景特征,避免目标特征与场景特征两种不同特性的特征直接进行融合,提升特征融合模块的融合效果,本文在目标检测和场景识别相结合的方法中引入CCM,如图2 所示,将CCM 置于ObjectNet的特征之后,将目标特征进行加权和,最终转换成和场景特征相同维度。输入目标特征xobject是从ObjectNet 中提取的,输出特征为yobject→scene,CCM的计算如下:

图2 特征转换示意图Fig.2 Schematic diagram of feature conversion

其中 :xobject∈Rn;权 重W∈Rm×n,偏 差b∈Rm,yobject→scene∈Rm是与xobject相关的输出。n是输入向量的维数,m是输出向量的维数。如果将ImageNet数据集用于训练对象模块,则n=1 000。如果将Places 2数据集用于训练场景模块,则m=365。CCM 不仅可以应用于不同的数据集,而且可以应用于相同的数据集,即m=n,如具有Places 2 数据集格式的CCM 的参数W∈Rm×m和b∈Rm,则具有相同数据集格式的输入xobject∈Rm和输出yobject→scene∈Rm。而且,从CCM 的权重中可以分析目标和场景之间的关系,即目标和场景之间的相关程度,如果一个目标频繁出现在场景中,权重则越高;相反则越低。这意味着场景识别性能可以获得进一步的提高。
1.3 冗余信息抑制
每一幅场景图像中都可能包含各种各样的目标,而当一幅场景图像中出现某一特别的对象时,这个场景就很有可能属于某一特别的类,如一张床对于卧室,或浴缸对于浴室的重要性,但是其他不相关特征可能会影响网络的判断。为了降低不相关特征的权重,本文引入了CG,它的计算公式为:

其中:xscene表示由场景网络提取的场景特征;⊗表示一种矩阵相乘法;σ(x)=1/(1+exp(-x))是值为(0,1)的sigmoid 激活函数。如图3(a),由于sigmoid 激活函数的特性,左端无限趋于0,右端无限趋于1,构成一个限制信息的“门”,当不相关信息通过门控时,函数取值趋向0,可以抑制不相关的信息。在目标特征中不相关信息有可能占据较高的视觉激活,CG 模块可以通过上述门控方法抑制这些不相关信息的传递,降低不相关特征对识别效果的影响,使网络更加关注图像的相关目标区域。如图3(b)所示,一个场景中可能存在一个或多个关键特征,图中用key feature1 和key feature2 代表这类特征,不相关特征会被门控大量抑制,关键特征得以保留。
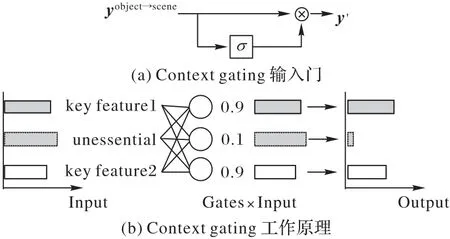
图3 CG输入门及原理Fig.3 Input gate and working principle of CG
1.4 特征融合模块
本文采取特征融合模块用于融合来自两个网络的特征,获得最终用于分类结果预测的特征,本文采用了卷积层+ReLU 和哈达玛积的组合结构,具体如图1 所示。场景网络获得的特征表示为:

同样,目标网络获得的特征表示为:

最终融合之后的特征表示为:

其中:⊙表示哈达玛积,即矩阵对应位置相乘;yscene为经过特征融合模块的最终特征表示,其经过softmax 层进行分类,获得最终的预测结果。
1.5 损失函数
ObjectNet 能够检测出场景图像中存在的目标对象,本文利用目标检测网络的这种优点与场景网络进行联合训练。在本文的实验中,当两个网络联合训练时,如果其中一个网络的判别性较强,整体损失较小,则会阻碍判别性较差的网络的优化。为了避免其中一个网络控制训练过程,首先,ObjectNet和PlacesNet 分别针对给定的场景进行训练;然后,将训练好的两个网络从头开始完全训练特征融合模块和分类器。在训练过程中,通过最小化以下目标函数来同时预测结果:

其中:D表示训练数据集;Ii表示第i张图像;yi表示第i张图像的真实标签;pi表示预测的场景标签;fi表示目标网络产生的标签;λ是平衡两项的参数;n和m分别对应两个网络的特征维度。这种联合学习方法能够通过利用包含在目标网络中的额外知识作为归纳偏差来提高泛化能力,并减少过度拟合对训练数据集的影响。图4 为本文方法的准确率收敛曲线,在迭代1 500次时准确率逐渐趋于稳定。

图4 准确率收敛曲线Fig.4 Accuracy convergence curve
2 实验与结果分析
2.1 实验平台及数据集
本文方法的具体实现使用的是深度学习框架Tensorflow,实验环境为Ubuntu 16.04 操作系统,使用4 块NVIDIA 1080Ti图形处理器(GPU)加速运算。本文采用数据集包括:MIT Indoor67数据集,该数据集包含67个室内类别,总共15 620张图像,每个类别至少有100 张图像;SUN397 数据集,它由108 754 张图像组成,包含了397 个图像类别;ImageNet 数据集,它是ObjectNet 训练用来提取场景图像中的目标的,包含了1 000 个对象类别;Scene-15 数据集,该数据集包含15 个不同类别的4 485个室内外场景图像,其中室内场景类别分别是卧室、工厂、厨房、客厅、办公室和商店。MIT Indoor67 数据集部分场景示例如图5所示。

图5 MIT Indoor67数据集部分场景示例Fig.5 Some scene examples of MIT Indoor67 datasets
2.2 实验参数及结果分析
实验使用梯度下降法进行训练,设置权重衰减(weight dacay)系数为0.000 1,动量(momentum)系数为0.9,batch size设置为64,初始学习率设置为0.001。实验中要学习的参数是权重W∈Rm×n,偏差b∈Rm,m和n表示维度,与训练数据集的类别数有关,因此不会增加参数的规模,对模型的学习速度不会产生大的影响。λ是需要人为给定的参数,经过多次实验验证,当λ=0.5时,训练的效果最好。
本文使用的评价指标分别为:召回率Rec(Recall)、精准率Pre(Precision)和识别准确率Acc(Accuracy),其公式定义如下:

其中:TP(True Positive)表示预测为正例,实际为正例;TN(True Negative)表示预测为负例,实际为负例;FP(False Positive)表示预测为正例,实际为负例;FN(False Negative)表示预测为负例,实际为正例。TP、TN、FP和FN分别表示预测的真假性与实际场景的关系。本文绘制了精准率-召回率PR(Precision-Recall)曲线来分析模型,图6 中展示了SOSF(Spatial-layout-maintained Object Semantics Features)[13]、HoAS(Hierarchy of Alternating Specialists)[18]、SDO(Semantic Descriptor with Objectness)[9]、VSAD(Vector of Semantically Aggregated Descriptors)[19]四种方法和本文方法的PR曲线。PR曲线表现了召回率和精准率之间的关系,曲线越靠近右上角,表明模型的性能越好。从图6 中可以看出本文方法在这方面优于其他几种方法。

图6 不同方法的PR曲线Fig.6 PR curves of different algorithms
表1 为本文方法在Scene-15 数据集上得到的混淆矩阵以及相应的召回率和识别精度,矩阵第i行第j列的值表示第i类场景被预测为第j类场景的样本数。表1 中序号分别对应Scene-15 数据集中的类别,分别为:1)Living;2)MITmountain;3)MITopencountry;4)MITforest;5)store;6)MIThighway;7)CALsuburb;8)MITstreet;9)industrial;10)kitchen;11)PARoffice;12)MITinsidecity;13)MITcoast;14)bedroom 和15)MITtallbuilding。从表1中可以看出,办公室的类别召回率为100.0%,精准率为95.7%;厨房的召回率也达到100.0%,卧室和客厅两个室内场景类别容易被相互误分类,分类错误的原因是客厅中的目标(如沙发)与卧室场景中的目标相似。本文方法在室外场景上也有不错的效果。

表1 Scene-15数据集的混淆矩阵Tab.1 Confusion matrix of Scene-15 dataset
2.2.1 多种方法在数据集MIT Indoor67和SUN397上的比较
目前,已有多种方法对场景识别进行了研究。本文将多种方法分别在数据集MIT Indoor67 和SUN397 上进行了对比实验,主要与以下几种方法作为对比实验:Object-Scale[10]、VSAD[19]、MR-CNNs(Multi-Resolution CNNs)[11]、SDO[9]、Semantic-Aware[1]、HoAS[18]、SOSF[13],结果如表2所示。在MITIndoor67数据集上进行的实验,VSAD[19]虽然利用了PatchNet来指导特征提取,但是该网络对Local patch的提取能力并不强,准确率只有86.20%;MR-CNNs[11]的准确率为86.70%,它在网络结构上进行了创新,结合了多分辨率网络,但没有利用局部特征,导致在准确率上并没有提升很多;Semantic-Aware[1]在场景的语义信息方面有所改善,但是面对复杂场景时受语义分割的影响,场景识别效果也受到限制,准确率为87.10%;另外,HoAS[18]解决了场景的类内差异性和类间相似性的问题,SOSF[13]的结果是对比方法中效果最高的为89.51%,但还是缺乏对场景的目标特征足够的关注。因此,本文在利用目标特征进行分析的同时,抑制了不相关特征的权重,识别准确率达到了90.28%,相比上述方法最好的结果,仍有0.77个百分点的提升。同样,在SUN397数据集上,本文方法识别准确率达到了81.15%,相较于另外几种方法中准确率最高的方法HoAS(为79.66%),准确率提高了1.49 个百分点。实验结果表明,通过对目标特征进行转换并对冗余信息进行抑制,增强了特征的表达能力和特征融合的效果,显著提高了识别准确率。
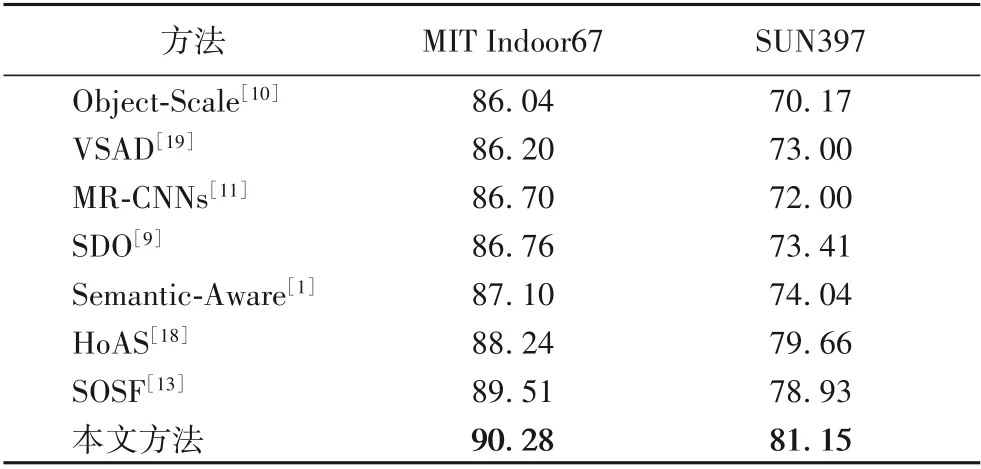
表2 多种方法在MIT Indoor67和SUN 397数据集上的准确率 单位:%Tab.2 Accuracy of various methods on MIT Indoor67 and SUN 397 datasets unit:%
2.2.2 目标和场景之间的关系分析
CCM 的权重体现了目标以及场景之间的关系紧密程度,本文对CCM 的权重进行了分析,结果显示权重值越高,表明该目标越经常出现在该场景中;反之亦然。本文在MIT Indoor67数据集上进行实验,通过表3~4数据对它们的关系展开分析。表3 和表4 分别显示了CCM 权重的前3 名和后3名。

表3 CCM权重的前3名Tab.3 Top-3 of CCM weights
表3 数据显示的是某场景类中可能存在的合理对象,权重最高的是bedroom 中的bed,达到了0.097 21,表明这种搭配合理度最高;另外两个kitchen 和stove 以及bathroom 和toilet的权重也分别达到了0.094 80、0.093 16,这表明它们的搭配合理性也很高。这个数据验证了CCM 正确反映了目标对于场景的积极影响。
同理,根据表4 的数据显示,权重值越小的值所对应的场景类别和对象类别的组合其合理性也越小,权重为负值时,表明该目标对场景识别起到了负面影响,需要对其权重进行抑制。比如表4 中所列的bathroom 和stove、office 和slipper 等组合。从实验数据可以看出,该实验结果表明了CCM 权重对室内场景识别是有效的。本文方法合理体现了对于目标和场景之间的关系程度。

表4 CCM权重的后3名Tab.4 Bottom-3 of CCM weights
2.2.3 冗余信息抑制效果
为了测试本文方法对于冗余信息的抑制效果,在MIT Indoor67 数据集上分别利用了目标检测网络和本文方法进行了效果对比。首先,利用目标检测网络检测室内场景图像中包含的目标;然后,本文以类激活图(Class Activation Map,CAM)[20]的形式分析CG 模块对识别效果的影响,该方法以直观的视觉形式表现出了网络对于图像的关注区域。
目标特征中的冗余信息抑制结果如图7 所示:图7(a)为原图;图7(b)为经过目标检测网络的输出图像,可以看出场景中一些明显的物体被检测出来,如床、桌子、椅子以及电脑等;图7(c)为经过本文方法的CAM 可视化效果。从图7 可看出,相对于图7(b)中目标检测网络的效果,本文方法将关注点集中在图中主要的物体上,对目标检测网络提取的特征中包含的冗余信息有明显的抑制效果。

图7 冗余信息的抑制效果Fig.7 Suppression effect of redundant information
2.3 消融实验
CCM 模块和CG 模块可分别作为网络的一部分来改善网络性能。为了测试本文方法分别在CCM、CG以及它们的组合情况下的性能,本文通过它们的多种组合来分析模型在MIT Indoor67和SUN397两个数据集上的识别准确率,如表5所示。
根据表5 的数据显示,在MIT Indoor67 数据集上,网络在分别只有CCM 和CG 的情况下,准确率为88.35%和87.91%,相较于二者都没有的情况下的86.40%,识别准确率分别提高了1.95 个百分点和1.51 个百分点;而在同时具备CCM 和CG时,即本文方法识别准确率达到了90.28%。在SUN397 数据集上,本文方法也取得了不错的效果,在只采用CCM 或CG 情况下,准确率分别提高了1.55 个百分点和2.39 个百分点;而同时采用CCM 和CG 时,最终识别准确率达到了81.15%。以上实验表明,CCM 和CG 模块对室内场景识别产生了积极的影响,提高了识别的准确率。

表5 CCM和CG的不同组合效果对比Tab.5 Effect comparison of different combination of CCM and CG
3 结语
本文针对室内场景识别中目标特征与场景特征性质和维度不一致、特征信息冗余等问题,在结合目标检测和场景识别的基础上,提出一种改进的室内场景识别方法。通过CCM 将场景图像中的目标特征转换为场景特征,使得二者具有相同的特征维度,减少特征融合时的特征信息丢失;然后,利用CG抑制特征中的冗余信息,降低了不相关信息对场景识别的影响,提高了目标特征在室内场景识别中的作用。最后,本文分别在Scene-15、MIT Indoor67 和SUN397 三个场景数据集上进行了实验,并通过和其他方法对比,验证了本文方法有效提高了室内场景识别的准确率。
猜你喜欢
心理学报(2022年5期)2022-05-16
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
