
基于字典的域名生成算法生成域名的检测方法
2021-09-18 06:22张永斌常文欣孙连山
计算机应用 2021年9期
张永斌,常文欣,孙连山,张 航
(陕西科技大学电子信息与人工智能学院,西安 710021)
(*通信作者电子邮箱920647953@qq.com)
0 引言
僵尸网络、勒索病毒等恶意软件往往将命令与控制服务器(Command and Control server,C&C)的连接信息(如:域名、IP 地址)硬编码在二进制文件中,以便接收指令、窃取收集到的情报或从事其他恶意活动,严重威胁着国家安全和社会稳定,这种方式实现简单,但很容易被黑名单封堵。为躲避黑名单封堵,很多恶意软件采用域名生成算法(Domain Generation Algorithm,DGA)生成大量域名,由于每个周期生成的恶意域名数量较大,导致黑名单无法正常工作。在早期,僵尸网络等恶意软件主要通过DGA 随机选取字符生成域名,即:基于随机字符的DGA,生成的恶意域名在字符构成、字符分布上与良性域名存在很大差异,基于这些特征研究人员提出了很多检测算法[1]。但随着网络对抗力度的加大,攻击者为了更好地躲避检测与封堵,一些僵尸网络采用基于字典的DGA,与早期基于随机字符的DGA不同,基于字典的DGA通过从内嵌的单词列表中随机选取一个或多个单词组合生成域名,由于与良性域名命名规则相近,导致这些算法生成的恶意域名更不易检测[2]。
现有研究主要关注基于随机字符DGA 生成域名的检测,由于域名生成方式不同,基于字典的DGA 生成域名与基于随机字符DGA 生成域名在字符构成上存在很大差异,它与良性域名更为相似,不易检测,而现有检测算法缺乏有效的针对性。因此,本文提出一种卷积神经网络(Convolutional Neural Network,CNN)和长短时记忆(Long Short-Term Memory,LSTM)网络相结合的网络模型——CL 模型,对基于字典的DGA生成域名进行检测。
1 相关工作
目前,学术界针对DGA 生成域名的检测算法可以分为基于传统机器学习的检测算法与基于深度学习的检测算法两大类。在早期研究中,研究人员主要通过从域名字符构成、字符分布、解析结果等方面提取特征,利用随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)等机器学习方法建立检测模型[3-6]。随着深度学习的发展与普及,很多研究人员提出了基于深度学习的检测模型,与早期研究方法相比,研究人员不用再选取具体的分类特征。Woodbridge 等[7]最先采用LSTM 对DGA 生成域名进行检测与分类,与隐马尔可夫模型(Hidden Markov Model,HMM)等传统方法相比,LSTM 的性能明显优于其他方法,在10-4的假阳性率下取得90%的检测率。在后续研究中,大量研究人员提出多种不同的深度网络模型,例如,Berman[8]使用CapsNet,Drichel 等[9]使用残差网络(ResNets),Qiao 等[10]使用具有注意力机制的LSTM 对DGA 生成域名进行检测,在检测性能上均取得较好结果。Sivaguru 等[11-13]分别将LSTM、并行卷积神经网络等典型的深度学习模型与机器学习方法进行对比,结果表明深度学习方法在检测性能上均优于传统的机器学习方法。裴兰珍等[14]对门控循环单元(Gated Recurrent Unit,GRU)、LSTM 等24 种深度学习模型进行了比较,研究结果表明在多种模型中,采用卷积神经网络和循环神经网络组合的方法可有效提升模型的检测性能。但以上研究主要是对基于随机字符DGA 生成域名进行检测,目前,对基于字典的DGA研究才逐步引起关注,相关研究较少。Curtin 等[15]结合域名字符特征和WHOIS 注册信息特征(如:注册商、注册邮件等)一起构建模型对基于字典的DGA 生成域名进行检测,然而根据数据保护条例,WHOIS 信息已不再可用。Koh 等[16]通过使用预训练的词嵌入向量与简单的全连接层结合起来对基于字典的DGA 生成域名进行检测,但该方法需要对域名进行分词处理,由于不同域名包含的词数量不同,导致模型灵活性差。Highnam 等[17]提出混合神经网络Bilbo模型,该模型是通过CNN 和LSTM 并行使用来检测基于字典的DGA 生成域名,模型通过CNN 提取域名中字符的n-grams 特征,对域名中的单词特征进行学习,但简单地将CNN 和LSTM 并行使用,弱化了n-grams 之间的上下文关系。因此,本文提出一种将CNN和LSTM 串行连接使用的网络模型,模型通过CNN 提取基于字典的DGA 生成域名的n-grams 特征,然后利用LSTM 学习ngrams 间的上下文特征,实验结果表明:CL 模型具有更好的检测性能。
2 检测方法
基于字典的DGA 生成域名时,是以有意义的单词为单位,通常从一个或多个单词列表中抽取单词,组合生成域名,如:Matsnu家族包含动词单词列表及名词单词列表,在生成域名时,先从动词列表中随机抽取单词,然后在名词列表中随机抽取单词,进行组合后生成域名,如“charactermarry.com”。Nymaim 家族包含两个单词列表,生成域名时,先后从两个单词列表中随机抽取单词,组成生成域名,如“recent-hospitality.com”。
为了便于人们的理解和记忆,良性域名通常采用有意义的单词或词组来命名,如:“facebook.com”,而基于字典的DGA 生成域名也是由有意义单词的构成,由于命名规则的相近,基于字典的DGA 生成域名与良性域名在字符分布上十分相近、差异并不明显,如图1所示。而基于随机字符的DGA在生成域名时,往往以字符为单位,通过随机抽取字符生成域名。由于生成域名的方式不同,基于随机字符的DGA 生成域名在字符构成、字符分布上与良性域名、基于字典的DGA 生成域名存在着显著区别,更易于检测与识别。
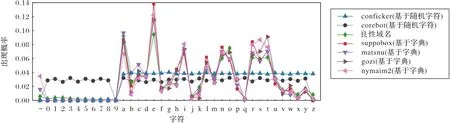
图1 DGA域名与良性域名的字符分布概率Fig.1 Distribution probability of DGA domain names and benign domain names
虽然良性域名与基于字典的DGA 生成域名命名规则相近,但良性域名选词广泛,而字典DGA 的命名空间却受限于内嵌的单词列表及从不同列表中取词的顺序,因此,可通过学习字典DGA 所有单词列表中的单词及不同列表中单词之间的组合关系,对基于字典的DGA生成域名进行检测。
基于字典的DGA 生成域名由英文单词构成,英文单词主要由词根、词缀组成,通常词根决定单词的意思,前缀可以改变词义,后缀决定单词词性。为更好地学习基于字典的DGA生成域名中的单词特征,本文借鉴文本分类思想提出CNN 与LSTM 串行连接的CL 模型,该模型首先利用CNN 捕捉域名的局部特征,对于域名来说,局部特征就是由若干字母组成的滑动窗口,CNN 可有效提取域名字符构成中关键的n-grams 信息,如:词根、词缀的特征,同时可选择不同大小卷积核学习多个不同长度的n-grams信息,因此,CL模型通过CNN 可有效学习基于字典的DGA 各个内嵌单词列表中单词的关键n-grams特征。由于CNN 学习到的特征具有平移不变性,学习到的n-grams 特征缺少在域名中出现的位置信息,因此,CL 模型进一步利用LSTM 学习n-grams 之间的上下文关系,如:前缀、词根、后缀之间的顺序关系,目的是进一步强化对单词列表中单词特征的学习,同时学习基于字典的DGA 中不同单词列表之间单词的组合关系,以便从单词特征及单词间组合关系对基于字典的DGA 生成域名进行检测。CL 模型充分利用了CNN和LSTM 的优点,与传统基于字符的LSTM 模型相比,CL 模型使用的是n-grams之间的特征而不是单个字符之间的特征,可更有效地学习基于字典的DGA 生成域名中的单词特征,与CNN、Bilbo模型相比,CL 模型有效地保留了n-grams之间的位置信息,更利于学习单词特征及单词之间的组合关系。
3 检测模型和实现方法
3.1 CNN
CNN 是深度学习的代表算法之一,在图像识别领域取得了巨大成功,如人脸识别等。目前,CNN在自然语言处理领域也得到广泛应用。在文本处理过程中,一维卷积窗口在文本上滑动,提取不同位置的单词序列特征。卷积核与词向量进行卷积计算,生成每个位置有效的特征映射:

其中:k表示文本中的k个位置;⊕(wi:i+k-1)表示卷积窗口内的词向量wi,wi+1,…,wi+k-1,xi为第i个窗口的连续向量;u为卷积核中的权重向量;b是偏置;g为非线性激活函数。
3.2 LSTM
LSTM是一种能够学习长期依赖性的网络模型,广泛应用于自然语言处理领域,LSTM主要通过“门”结构控制信息的输入与输出,LSTM 引入了3 个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),这3 个门主要用于捕获各个状态的依赖关系。LSTM 还需要计算候选记忆细胞。当前时间步记忆细胞ct的计算组合了上一时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘门和输入门来控制信息的流动。有了记忆细胞后,通过输出门来控制从记忆细胞到隐藏状态ht的信息的流动。相关方程为:

其中:σ是sigmoid 激活函数;W是权重矩阵;xt是当前时刻的输入向量;ht-1是上一时刻的输出向量;b是偏置;∘表示按元素乘法。
3.3 CL模型
CL 模型主要由字符嵌入层、特征提取层和全连接层三部分组成,网络模型如图2所示。

图2 CL模型Fig.2 CL model
1)嵌入层。对输入域名的有效字符(小写字母、数字和连字符)进行编码,每个字符通过128维的向量表示。
2)特征提取层。通过选取不同大小卷积核的CNN 学习不同长度的n-grams 特征,将CNN 学习到的特征输入到LSTM中进行再次学习,以便通过LSTM 学习n-grams 之间的上下文关系,最后将所有LSTM 的输出进行Concatenate。实验结果表明:卷积核大小(kernel_size)为3 和4,卷积核的数量为128时,模型性能最佳。
3)全连接层。在神经网络中起到“分类器”的作用,将学习到的特征表示映射为样本标记的类别属性,即良性域名或恶意域名。在实验时,使用binary_crossentropy 衡量模型的损失,sigmoid作为模型的分类函数。
CL模型的伪代码如下所示。

4 实验与结果分析
目前,典型用于检测DGA 生成域名的深度学习网络模型有:CNN[11-13]、双向LSTM(Bi-directional LSTM,B-LSTM)[11-13]、LSTM[7]和Bilbo[17],前三种网络模型主要检测基于随机字符DGA 生成域名,Bilbo 模型是混合网络模型,主要用于检测基于字典的DGA 生成域名。本文在同一数据集上,从以下几个方面,将CL模型与这四种典型的网络模型进行对比。
1)检测能力对比:比较模型对良性域名和基于字典的DGA生成域名的检测能力。
2)泛化能力对比:比较模型在各家族之间的泛化能力,即对未训练家族的识别能力。
3)时间依赖性对比:测试不同模型的时间依赖性,即时间变化对模型检测性能的影响。
4.1 数据集
本文所使用的数据均来自公开数据集,如表1 所示。良性域名数据集来自Alexa的前100万个域名,基于字典的DGA生成域名使用了两个数据源:DGArchive 逆向工程生成的DGA 域名样本和Netlab 360 DGA 发布的真实DGA 域名。使用DGArchive 逆向工程生成2018年4个基于字典的DGA 家族的域名数据,用于模型的训练和测试。对于时间依赖性的检测,使用DGArchive 生成2020 年的域名数据样本,以及Netlab 360 DGA在2020年6月—7月发布的真实DGA域名。

表1 实验数据集Tab.1 Experimental datasets
4.2 实验结果与分析
4.2.1 模型的检测性能
为比较模型在良性域名和基于字典的DGA 生成域名的检测能力,进行了不同家族数量和良性域名的二分类对比实验。
实验1 三个家族二分类对比。
实验首先复现文献[17]所使用的3个基于字典的DGA家族的二分类实验,即Suppobox(S)、Matsnu(M)、Goz(iG)家族。实验数据包含良性域名3 万,DGA 域名3 万,其中每个家族域名各1万。实验结果如表2所示。

表2 三个字典DGA家族的实验结果Tab.2 Experimental results of three dictionary-based DGA families
从表2可看出:CL、LSTM和B-LSTM模型都能达到很高的检测率,但CL 模型在准确率上比LSTM 提升了0.93%,比CNN提升了2.90%。
实验2 四个家族的二分类对比。
在三个家族二分类对比的实验基础上添加Nymaim2(N)家族。实验数据包含良性域名3 万,DGA 域名3 万,每个家族域名各7 500个。其实验结果如表3所示。

表3 四个字典DGA家族的实验结果Tab.3 Experimental results of four dictionary-based DGA families
从表3 可看出:添加一个家族之后,各模型指标均有所下降,但CL 模型各项指标仍比其他模型高。其中每个家族的Recall值如表4所示,整体上CL模型仍高于其他模型。从表4中可以看出,各个网络模型在各家族的检测结果上具有一定的差异。CL 模型的最高和最低Recall 值分别为96.22%、91.03%,Bilbo 网络模型的最高和最低Recall 值分别为97.20%、83.06%。除Gozi家族之外,CL模型在其余各家族的Recall 值上均高于其他网络模型。尤其是对Suppobox 家族的检测上,CL 模型比CNN 模型提升了14.29%,比Bilbo 网络模型提升了15.84%。

表4 每个家族实验结果的Recall值Tab.4 Recall of experimental results of different families
实验3 不同家族数量的二分类对比。
通过对比实验2 的表3 与实验1 的表2,增加一个DGA 家族之后,所有模型检测指标都有所下降。在实验1、2 中,分别覆盖了三个家族和四个家族,为验证不同家族数量对模型的影响,分别补充一个家族及两个家族实验,之后对比4 个实验结果的Accuracy 值和Recall 值,如图3~4 所 示。其中:S 为Suppobox家族;SG为Suppobox家族和Gozi家族;SGM为Suppobox 家族、Gozi 家族和Matsnu 家族;SGMN 为Suppobox 家族、Gozi家族、Matsnu家族和Nymaim2家族。
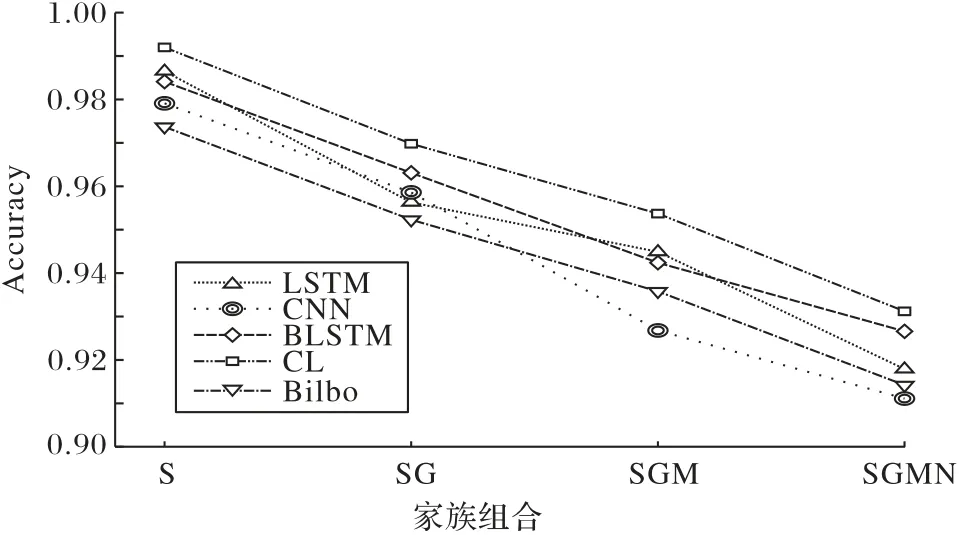
图3 四次实验结果的Accuracy值对比Fig.3 Accuracy comparison of four experimental results
从图3~4 可以看出,随着家族数量的增加,各个模型的检测能力都在下降,但通过对比Accuracy 值和Recall 值可以发现,CL模型降低的幅度更小,具有更好的稳定性。
4.2.2 模型的泛化性能
为测试模型的泛化性能,使用4个家族中任意3个家族训练模型,用剩下的1个家族测试模型,检测结果如表5所示。

图4 四次实验结果的Recall值对比Fig.4 Recall comparison of four experimental results
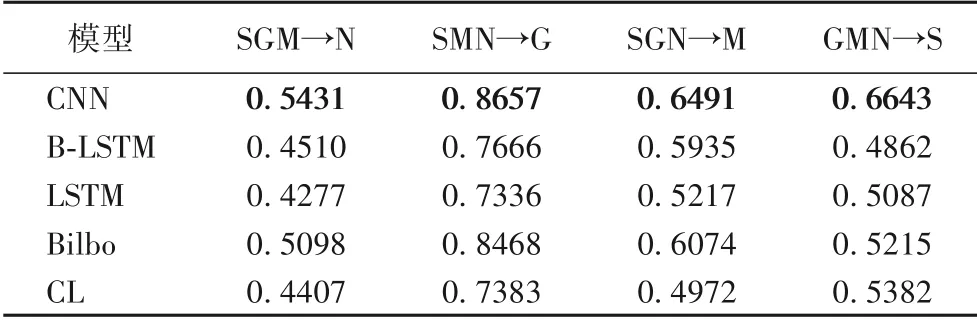
表5 不同模型对字典DGA家族的泛化性能比较Tab.5 Comparison of generalization performance of different models for dictionary-based DGA families
实验结果表明,CNN 网络模型在泛化性能上优于CL 模型。当使用Suppobox(S)、Matsnu(M)、Nymaim2(N)三个家族一起作为训练家族,Goz(iG)作为测试家族时,所有模型的泛化结果都表现为最好。使用Suppobox(S)、Gozi(G)、Matsnu(M)三个家族一起作为训练家族,Nymaim2(N)作为测试家族时,模型的泛化结果都较差。
4.2.3 模型的时间依赖性能
为测试模型的时间依赖性,使用了4 个家族的二分类模型对DGArchive 生成的2020 年数据进行测试,其实验结果如表6所示。
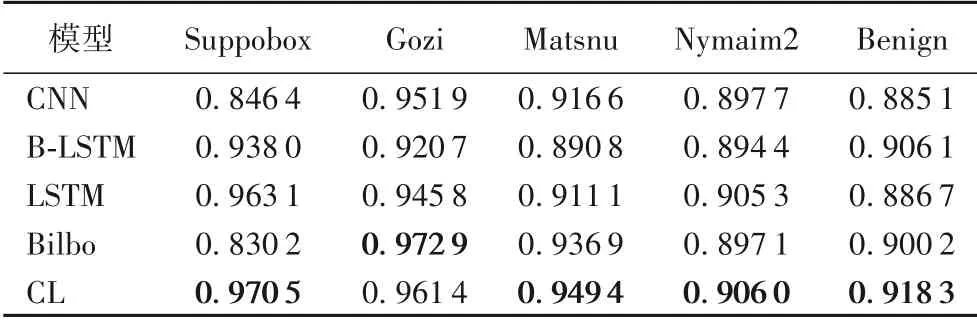
表6 2020年DGArchive测试结果的Recall值Tab.6 Recall of test results of DGArchive in 2020
对比表6 和表4 可以发现,所有网络模型在2018 年和2020 年的数据检测上均无显著差异。这说明当内嵌单词列表未发生变化时,生成域名的种子变化对网络模型均不会造成影响。为验证模型在真实数据上的检测能力,选取Netlab 360 的字典DGA 进行检测,但由于Netlab 360 只提供了4 个基于字典的DGA 家族中的Suppobox 和Matsnu 2 个家族数据。因此只对这两个家族进行了检测,其检测结果如表7所示。

表7 2020年Netlab 360测试结果的Recall值Tab.7 Recall of test results of Netlab 360 in 2020
从实验结果可以看出,Suppobox 家族与2020 年DGArchive检测结果相似,但Matsnu家族与2020年DGArchive检测结果存在较大差异。对Matsnu家族的2020年DGArchive数据Netlab 360数据进行分析,两者词重复率高达97.81%,域名重复率为8.15%。Netlab 360 数据中Matsnu 家族平均连字符数为1.2,而DGArchive 中Matsnu 家族的平均连字符数为0.13。因此本文认为,由于连字符的变化,使各个网络模型学习n-grams之间的关系发生了改变,所以对Matsnu家族的检测结果产生了影响。
4.3 实验总结
以上实验结果表明:在检测性能上CL模型各项指标都最优,明显优于其他模型,在四个家族的二分类实验时,其Accuracy 为93.12%,比CNN 提升了2.20%,比Bilbo 提升了1.87%。随着恶意家族数量的增加,CL 模型的Accuracy、Recall 下降最低,具有更好的稳定性。在泛化性上CNN 表现最好,这是由于CNN 学习到的n-grams 特征具有位置无关性,同样由于缺少n-grams 间的上下文关系特征,导致CNN 的Accuracy 最差。B-LSTM 和LSTM 是循环神经网络,主要学习字符之间的上下文特征,其各方面表现居中。Bilbo 和CL 模型都是基于CNN 和LSTM 的混合模型,不同之处在于Bilbo 模型使用的是并行的CNN 和LSTM 结构,由于Bilbo 模型保留了CNN 的位置无关性,其具有较好的泛化性能。CL模型是多个CNN 和LSTM 串行连接的网络结构,通过不同的卷积核学习不同的n-grams特征,并通过LSTM 学习不同n-grams之间的上下文特征,导致其在泛化性能上较弱,但在其他各个方面表现最优。
5 结语
本文提出一种卷积神经网络与长短时记忆网络(CL)相结合的基于字典的DGA 生成域名的检测模型,该模型利用卷积神经网络与长短时记忆网络提取n-grams 信息及其上下文特征。实验结果表明,CL 模型在分类性能及时间依赖性上优于其他模型。在未来研究中,将进一步探索模型的泛化性能,研究影响泛化性能的结果的影响因子。
猜你喜欢
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
读者(2016年14期)2016-06-29
农机使用与维修(2014年10期)2014-10-23
