
基于自监督学习的社交网络用户轨迹预测模型
2021-09-18 06:21代雨柔张凤荔
计算机应用 2021年9期
代雨柔,杨 庆,2,张凤荔,周 帆*
(1.电子科技大学信息与软件工程学院,成都 610054;2.中国电子科技集团公司第十研究所,成都 610036)
(*通信作者电子邮箱fan.zhou@uestc.edu.cn)
0 引言
在基于位置的社交网络(Location based Social Network,LBSN)中,预测人类的移动轨迹是一项重要且困难的任务。在日常的生活中,人们不断地从一个地方到另一个地点移动,但移动的规律因人而异,且受各种如节假日、天气、心情等因素的影响。通过预测人们的轨迹,在某些方面能够反映出该用户的生活方式、移动规律以及人脉关系网络等。获取这些信息可以帮助用户提前做好路线规划、周边购物与饮食推荐等实际建议,这也为学习用户移动行为提供了新的研究,如社会中的关系推断[1]、友情预测[2]、轨迹-用户预测[3]、个性化社交事件推荐[4]、轨迹预测[5]等。
在用户的轨迹预测中,最重要的是预测下一个将要去的兴趣点(Point Of Interest,POI)。准确预测出人们的下一个兴趣点,不仅能方便个人的出行,也能给其他人的出行带来影响。以往收集轨迹数据主要是通过问卷调查的方式,但问卷调查不仅成本高、效率低,而且难以长时间对用户的轨迹进行记录。随着移动互联网技术的飞速发展和各种设备中全球定位系统(Global Positioning System,GPS)的广泛使用,诸如Foursquare(https://foursquare.com)和Gowalla(http://blog.gowalla.com)这样基于位置的社交网络变得无处不在。用户通过这些设备,留下他们的足迹并分享他们的心情或经验,使得拥有相同兴趣点的用户轨迹中的签到点相互交汇,例如美术馆、食堂、购物中心、音乐厅等。
文献[6]通过对100 万用户的研究,发现用户的移动行为具有明显的稳定性,93%的用户移动模式是可以被预测的,与早期文献[7]中对45 000 个匿名用户的运动模式进行研究的结论大致相同。结论也表明不同的个体可预测性的差别并不是很大,这种高可预测性是由于人们的运动具有高度的规律性。到目前为止,人们做了大量的研究来将这种可预测性转化为实际的移动行为预测模型。早期预测移动行为的方法大多数是基于模式的,这种基于模式的预测方法[8-9]首先从用户的轨迹中发现预定义的移动机制,如周期模式、序列模式等,然后根据提取到的这些模式来预测下一个位置。这些关于人类移动行为的研究大多是提取人类移动行为中的统计特征,而忽略了社会关系中的因素对人类移动模式的影响。事实上,用户偏好、社交关系等因素对人类移动的预测至关重要。最近的发展转向基于模型的方法[10-12]来进行轨迹预测,利用序列统计模型如:马尔可夫链(Markov Chain,MC)、循环神经网络(Recurrent Neural Network,RNN)来捕捉人类运动的转移规律,并从给定的训练语料库中学习模型参数。
最近深度学习如卷积神经网络(Convolutional Neural Network,CNN)、长短时记忆网络(Long Short-Term Memory Network,LSTM)、注意力机制(Attention Mechanism)等在许多领域逐渐崭露头角(如图像处理、行人识别等领域[13]),并取得了比较突出的贡献,为用户轨迹预测提供了新的解决思路。Liu 等[14]在2016 年提出的ST-RNN(Spatial Temporal Recurrent Neural Network)模型利用时空上下文信息来分析用户行为,使用并扩展了RNN。ST-RNN 可以用不同时间间隔的时间-转移矩阵和不同地理距离的距离-转移矩阵对每一层的局部时空上下文进行建模。Feng 等[15]没有从传统的用户角度对POI 进行探索,而是考虑了一个新的研究问题,即预测在给定的未来时间内访问给定的POI的用户。该方法通过结合地理因素的影响,建模用户偏好和POI 序列转换,来预测给定POI的潜在访问者。Feng 等[16]在2018 年设计了一种多模式嵌入循环神经网络,通过联合嵌入控制人类活动性的多种因素来捕获复杂的轨迹序列的状态转换,同时还提出了两种注意力机制模型,捕获轨迹的多层次周期性。该模型有效地利用了周期性来增强循环神经网络的移动模式预测。但上述模型都存在样本量不足、足迹点稀疏等问题,没有充分挖掘历史轨迹的隐含信息,且无法高效地表示和利用整个历史轨迹。
针对上述问题,本文使用深度学习中的一种新的自监督学习方法对轨迹预测进行建模。首先使用数据增强丰富样本,提高模型的泛化能力。其次,结合轨迹的时序特点,将轨迹划分为历史轨迹和当前轨迹,并使用RNN 对当前轨迹进行编码,针对轨迹具有时间依赖性的特点,学习当前轨迹数据中潜在的特征信息;使用CNN 学习用户的历史轨迹移动模式,该方法可以有效地捕获个人的长期运动模式,比常用的RNN的效率有所提升;同时使用了注意机制学习对历史轨迹的关注度,可以利用最近轨迹的潜在表示来匹配用户过去最相似的移动方式。然后使用概率对比损失,捕获对预测未来样本最有用的信息,并采用负采样(Negative Sampling,NS)的方法,每次随机选择一部分的负样本来更新模型对应的权重,使模型更容易训练。本文模型在Foursquare 和Gowalla 这两个现实生活中具有代表性的数据集上进行了实验,在纽约测试集上的评估结果表明,SeNext 在Top@1 的预测准确率比最新的VANext模型[17]高出10%以上,且优于其他轨迹预测模型。
1 相关工作
通过分析以往轨迹预测的模型,可以将轨迹预测的手段分为两类:一种是基于模式的方法,另一种是基于模型的方法。
1.1 基于模式的方法
基于模式的方法[8,18]首先从轨迹中发现常用的序列移动模式,然后根据这些常用的模式来预测用户的移动行为。矩阵分解(Matrix Factorization,MF)[19]可以看作是一种探究轨迹移动模式的方法,它在推荐系统中经常出现,其基本思想是将用户-项目矩阵分解为代表用户和项目特征的两个潜在矩阵。Cheng 等[8]通过将位置概率建模为多中心高斯模型,将MF 与地理影响融合在一起。Rendle等[20]将马尔可夫(Markov)模型与矩阵分解相结合,提出了分解个性化马尔可夫链(Factorizing Personalized Markov Chains,FPMC)模型来进行项目推荐。Cheng 等[21]基于FPMC 提出了一种称为FPMC-LR(FPMC with Localized Region constraint)的矩阵分解方法,在考虑局部区域约束的情况下捕获马尔可夫链的序列转换。这些方法中的预定义移动模式比较固定且片面,与基于模式的方法相比,本文模型不仅可以对所有用户轨迹的转移规律进行建模,还可以基于个人历史轨迹对个人偏好进行建模。
1.2 基于模型的方法
基于模型的方法主要是马尔可夫模型[22]及其变体,它们根据历史轨迹在多个地点之间建立状态转移矩阵来对未来移动的可能性进行建模。为了捕获位置转移之间未观察到的特征,Mathew 等[11]根据轨迹对位置进行聚类,然后为每个用户训练隐马尔可夫模型。考虑到用户组群之间移动模式的相似性,Zhang 等[12]提出了组级移动性建模方法GMove 来共享重要的运动规律。尽管基于模型的轨迹预测取得了不错的结果,但仍难以挖掘出复杂轨迹序列的移动特征。与现有基于Markov 的模型不同,本文模型通过对历史轨迹和当前轨迹的划分,能更好地提取不同时间轨迹更鲜明的特征,可以对既有时间依赖性又有高度顺序性的轨迹建模;同时使用对比学习,通过负采样的方式对比锚与正样本、锚与负样本之间的相似度,获取互信息。
1.3 数据增强
在训练模型时,研究人员经常会遇到数据不足的情况。一些任务只有几百条数据,这样的数据训练出来的模型泛化性往往不好。深度学习在训练一个模型时,其优化目标是降低代价函数,使模型的损失最低。此时需要以正确的方式调整模型参数,而参数的数量与样本量成正比,所以模型通常需要大量的数据。目前最先进的神经网络都需要成千上万的数据(如SimCLR(Simple framework for Contrastive Learning of visual Representations)模型[23]),而获取数据是一件耗时且困难的事,需要采取一些方式达到降低代价的目的。
数据增强是指在没有真正实质性增加数据的基础上,让有限的样本产生更多具有相同数据分布的样本。数据增强需要保证变换前后的数据和初始样本的主要特征和数据分布一致,确保模型能够学习到数据中的模式。目前,数据增强在图像学习领域被广泛使用,通过对图片进行翻转、缩放比例、扭曲、移位和添加高斯噪声等,或者改变同一个场景下的不同投影方式(如光线、角度、距离和焦距等)来增加样本量,提高模型的泛化能力。同时数据增强起正则化作用并避免过拟合,可以降低模型网络结构过于复杂的风险。训练样本的丰富,会增加数据噪声,能提升模型的鲁棒性。本文模型利用现有的数据进行数据增强,来获取更好的实际效果。
1.4 自监督学习
深度学习中的监督学习需要足够多的标记数据,某些领域尽管数据很多,但大部分都是未标记的数据。自监督学习主要从大规模的无标注数据中挖掘自身的监督信息,通过这种构造的有效监督信息对模型进行训练,可以学习到价值的表示。自监督学习的方法主要可以分为三类:基于上下文(Context Based)、基于时序(Temporal Based)和基于对比(Contrastive Based)的方法。基于上下文的方法是根据数据本身的上下文信息来构造任务,比如在自然语言处理领域中的word2vec[24]就是利用语句的顺序来预测不同位置的词语。基于时序的自监督学习主要是利用时序的约束关系来学习,如视频中相邻帧的特征都比较相似,而间距较远的视频帧不太相似。另一种自监督学习是以对比学习(Contrastive Learning,CL)为基础,这种方法通过对比样本的相似或不相似程度进行编码来学习数据的表示,通过构建正样本和负样本,然后度量正负样本的距离来实现自监督学习,进而使得更容易解决下游的任务。
对比自监督学习作为一种比较突出的处理无标签或少量标签的方法,在图像学习领域得到了广泛的应用并取得了巨大的成功。SimCLR 简化了对比自监督学习算法,不需要专门的架构或者存储库,并证明了数据增强之后的样本在定义有效的预测任务中起着至关重要的作用。CPC(Contrastive Predictive Coding)[25]使用自监督里面的对比学习,通过对比正负样本的互信息量,在潜在空间中预测未来可能发生的步骤。鉴于自监督学习在这些模型上的成功,本文提出了基于对比自监督学习的轨迹预测方法。本文模型将自监督学习用在轨迹预测上,使用正负采样的方法让复杂的模型更易于训练。
2 问题定义
在预测人类移动轨迹的模式中,主要目的是学习下一个POI 的预测。兴趣点可以是一个GPS 点、一个区域的中心或者是一个用户可以访问的地址,该地址在适当的坐标系中有唯一的标识。本文定义c=为POI 的一个三元组表示,其中id、lo、la分别表示兴趣点的ID、经度和纬度。用户u的轨迹可以表示为一个有序序列Tu=,其中:是用户u在时间ti访问的第i个兴趣点。通常省略去用户表示的上标,简写为。一条轨迹T是连续且有序的POI 序列,将每条轨迹划分为在时间间隔[t1,tn]内的m段子轨迹,则T=T1,T2,…,Tm。
本文将轨迹划分为历史轨迹和当前轨迹,用Th=T1,T2,…,Tm表示用户完整的历史轨迹,Tc=Tm+1=表示用户的当前子轨迹,其中当前轨迹的长度通常小于历史轨迹的长度。
人类轨迹预测问题通常被定义为:给定一个用户ui、其对应的历史轨迹Th=T1,T2,…,Tm以及当前轨迹Tc=,训练一个模型M去预测用户ui的下一个兴趣点,形式化表示为
3 轨迹预测模型
本文模型主要包括轨迹数据增强模块、因果POI 嵌入模块、当前轨迹学习模块、历史轨迹学习模块和分类器模块。首先对初始划分好的轨迹数据进行数据增强处理;其次使用因果嵌入方法把当前轨迹和历史轨迹中的POI都嵌入到低维表示中;然后用变体RNN 对当前轨迹Tc进行编码,用共享权重矩阵和CNN 对历史轨迹Th进行编码;结合注意力机制搜索历史轨迹Th,寻求与当前轨迹Tc最相似的移动轨迹;接着将当前轨迹的最后一个隐藏状态和历史轨迹的注意力集中到一个特征表示中,并预测下一个POI;最后通过自监督学习中的对比学习方式,使得样本和正样本之间的距离远远大于样本和负样本之间的距离,然后构造一个Softmax 分类器,以正确分类正样本和负样本,进而可以更好地训练模型。本文的轨迹预测模型框架如图1所示。

图1 基于自监督学习的轨迹预测模型框架Fig.1 Framework of trajectory prediction model based on self-supervised learning
3.1 轨迹数据增强
在深入研究本文模型的实现方法之前,首先介绍轨迹数据处理方法。由于用户的轨迹序列长度通常有所不同,一些用户可能去过很多地点,而另一些用户只是去了少量的地点。不同用户在不同时间段内的轨迹序列长度也不同,本文的目标应该是无论序列长度如何,都能准确地预测出下一个兴趣点。在此,本文提出了一种增强轨迹数据的方法。
文献[26]首先提出对轨迹序列进行预处理,本文分别为每个用户的每条轨迹进行数据增强。将初始输入的轨迹序列与数据增强之后的轨迹序列一起作为新的训练序列。给定一条轨迹Si=l1,l2,…,ln,表示用户i在给定时间段内的一条子轨迹序列。数据增强之后的轨迹序列表示形式为“l1,l2”“l1,l2,l3”……“l1,l2,l3,…,ln”,然后将增强之后的轨迹数据送入模型进行训练。将该方法用于所有的轨迹数据,图2 是该方法的图形示例,li表示一个签入点,p表示要预测的下一个POI。

图2 数据增强示意图Fig.2 Schematic diagram of data augmentation
3.2 因果POI嵌入层
为了更好地呈现不同POI 之间的语义关系,本文模型采用因果嵌入的方法,将POI 从当前轨迹和历史轨迹嵌入到一个低维表示中。受word2vec 的启发,之前的工作使用CBOW(Continuous Bag of Word)或Skip-Gram 模型将POI与上下文信息一起进行嵌入。然而,对于预测下一个POI的问题,更感兴趣的是嵌入轨迹的后续部分,而不是兴趣点的上下文。这是因为当前的POI是由它之前的足迹而不是它之后的足迹决定的,这与高阶马尔可夫过程的思想非常相似。也就是说,当嵌入POI时,不会将未来的位置泄露到过去。
可以通过因果嵌入层来实现,具体来说,给定先前的足迹点lτ-ω:lτ-1,通过预测历史轨迹Th和当前轨迹Tc中的当前位置lτ来获得签到点的向量表示,其中:ω表示滑动窗口的大小;|ζ| 表示数据集中签到点的数量;d表示矩阵的维度。然后最大化签到点lτ被访问的概率p(lτ|C(lτ)),由Softmax函数定义:

其中:l′表示被访问过的lτ签到点集合;l″∈ζ,每次表示ζ中的一个点,该点在式(1)中计算后再分别累加。为了加速模型计算,保证模型训练的效果,每次优化参数只关注代价函数涉及的词向量。本文采用了负采样技术来避免对所有签到点l″进行枚举,以提高模型处理的效率。
3.3 当前轨迹和历史轨迹模块
该模块使用门循环单元(Gate Recurrent Unit,GRU)来提取用户当前轨迹的签到模式。值得注意的是,用户的当前轨迹往往小于历史轨迹的长度,即|Tc|≪|Th|。因此选择RNN捕获当前轨迹数据的表示,由于GRU 具有参数少且易收敛等特性,所以选择GRU作为神经网络单元,其更新过程:
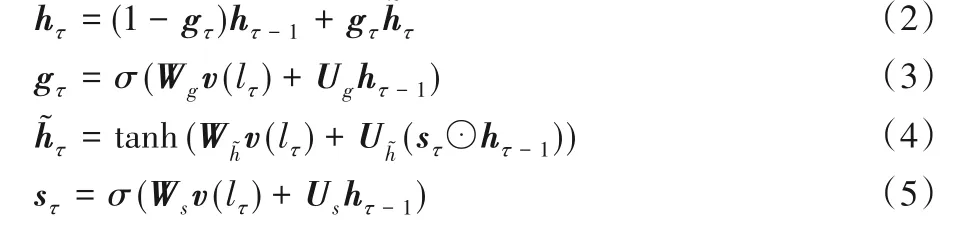
其中:gτ是在τ时刻的更新门,控制着当前的候选状态中有多少是来源于上一时刻的候选状态;候选状态的计算和传统的RNN单元很相似;sτ是重置门,决定了怎么将新的输入信息与之前的信息相结合;σ为Sigmoid 激活函数,将数据转换为区间[0,1]内的值,用来充当门控信号;⊙为哈达玛积;W*和U*均为参数矩阵。
接下来对历史轨迹Th进行处理。在对历史轨迹的处理中,先使用权重共享层多层感知机(Multi-Layer Preceptron,MLP)将每个POI 的嵌入向量合并到隐藏状态;再利用非线性神经网络进行1×D卷积来挖掘隐藏状态,获得的卷积状态作为下一个注意力层的输入;然后使用注意力机制来学习历史轨迹中卷积状态的权值。

其中:z是从当前轨迹最后一个隐藏状态中采样的潜在变量;q为利用MLP 从z中获取的向量;uti是q和ot间的相似度;ot为卷积层所获得的卷积状态;αi为通过Softmax 函数得到重要性权重。
然后通过对POI 加权求和得到了历史轨迹的表示。为了预测Tc的下一个POI,需要将当前轨迹的最后隐藏状态hn+k-1和注意力历史轨迹连接起来以获得Φ,如下所示:

将Φ输入Softmax 函数,计算数据集中每个POI 的概率p(l)。在训练时,将最小化预测下一个POI的经验风险。
3.4 自监督学习
当前的机器学习训练方法大都依赖于手工标注信息,这样会导致样本需求量大、模型脆弱等不良影响。本文使用自监督学习的方法对模型进行训练,通过学习编码器k,使得:
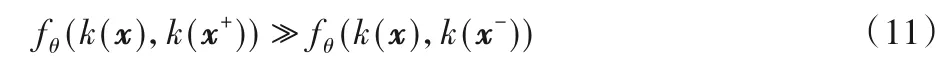
其中:x通常被称为锚数据,x+是与x相似或者相同的数据点,称为正样本;x-指的是与x不同的数据,称为负样本。fθ是一个由θ参数化的相似度衡量函数,用来衡量特征之间的相似性(如一个词和它上下文的编码表示之间的点积[27],图像与图像的局部区域的编码表示之间的点积[28])。在对比自监督学习中,通过对比正负样本来学习表示,其目标就是让式(11)中左边的部分尽可能大于右边的部分,即让正样本x+与锚数据的相关程度尽可能最大化。
为解决此问题,首先引入互信息(Mutual Information,MI)来描述两个变量之间的相关程度。假设存在一个随机变量X,和另外一个随机变量Y,那么它们的互信息是:

其中:H(X)是X的信息熵;H(X|Y)是已知Y的前提下,使X的不确定性减少的信息量,即X的信息熵。
互信息实际上是相对熵的特殊情形,它度量两个对象之间的相关性,在信息论中可以看成是一个随机变量中包含关于另一个随机变量的信息量,如果信息量为0,则表示两个随机变量相互独立。使用互信息理论进行POI预测是基于如下假设:当签到点在某个特定类别出现频率高,但在其他类别出现频率比较低时,该签到点与该类的互信息比较大,也就是说正样本之间的互信息较大,负样本之间的互信息小。
一般地,互信息I(X,Y)可以通过计算联合概率分布p(x,y)与边缘概率分布p(x)、p(y)乘积之间的相对熵(KL散度(Kullback-Leibler divergence,KLD))来确定变量之间的差异程度:
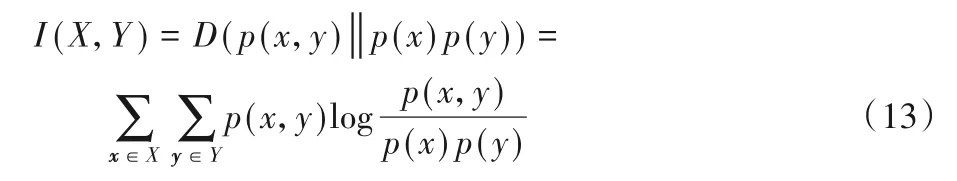
KL 散度越小,说明两个变量之间接近彼此独立,相互提供信息就很少,也就是互信息很小。最大化KL 散度,互信息MI 就越大,同时相似度衡量函数fθ也越大。在实际的应用中,增大MI 很难实现,受到文献[25]的启发,本文模型减小MI 的下界,即优化噪声对比估计(Noise Contrastive Estimation,InfoNCE)损失函数:
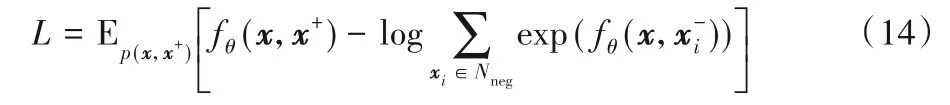
在本模型中,每次负采样包含一个正样本x+和Nneg个负样本x-,在对数据进行词向量训练时也用到了负采样技术,这种对比方法已被广泛应用于一系列基于自监督学习的语言、图像和视觉识别任务中[23,25,29]。
由于InfoNCE 与交叉熵有关,几乎包含随机变量的所有可能值,并且它们是均匀分布的,所以最小化InfoNCE 等同于最小化标准交叉熵损失:
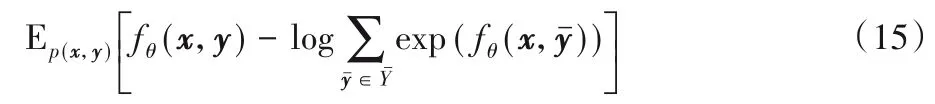
其中:y是指正样本;是负样本。同时,由这个方程可知InfoNCE 与最大化fθ(x,y)有关,基于上述方程,可以通过利用特定的X和Y来最大化原始数据不同变量之间的互信息。通过对比正负样本与原始数据之间的相似程度,最大化正样本对的互信息,提高了预测下一个POI的准确性。
InfoNCE 损失可以同时优化嵌入层和当前和历史轨迹模型。同时式(14)是一个分类交叉熵,用来区分数据中的正负样本。实际操作中可以通过Softmax 分类器来区分正负样本。本文模型SeNext的算法流程如下所示。

4 实验与结果分析
4.1 数据集
本文模型在Foursquare 和Gowalla 这两个数据集的四个城市上进行实验,比较SeNext与几个经典模型的性能。
本文对Foursquare 和Gowalla 两个数据集进行实验,从Foursquare 中选择了纽约和新加坡两个城市,从Gowalla 中选择了加利福尼亚州和休斯敦这两个区域的数据。对于每个数据集,删除了少于5 个用户访问的POI。对于每个用户,本文将所有签到的位置连接起来形成一条轨迹。随后,将每条轨迹划分为子轨迹,设置每条轨迹的时间间隔为6 h。此外,本文筛选并剔除少于5 个子轨迹的用户。对于所有数据集,选择每个用户前80%的子轨迹作为训练集,并选择其余的20%作为测试数据。表1总结了预处理后的数据集统计信息。
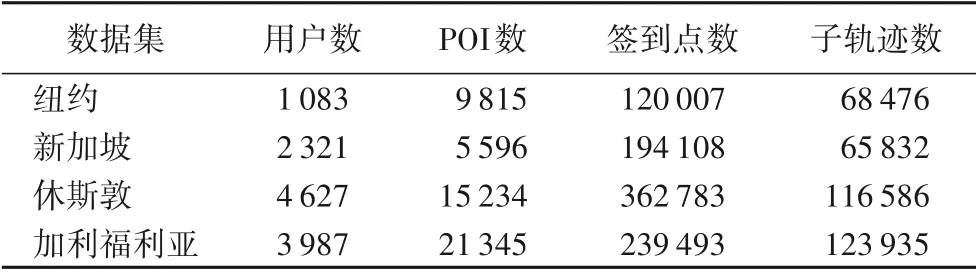
表1 数据集统计信息Tab.1 Statistical information of datasets
4.2 实验设置
表2 描述了实现基于对比自监督学习的轨迹预测模型的特定设置和超参数。对于嵌入层,单词嵌入模型CBOW 的目的是给定上下文来预测输入词语。与之相反,Skip-Gram 是基于输入词语预测上下文。不同于分层Softmax(Hierarchical Softmax,HS)中每个训练样本更新所有权重,负采样(NS)每次只更新一部分权重。本文使用负采样来确保计算效率和可扩展性。实验环境是在Linux 的TensorFlow 框架上,并使用GTX1080 GPU加速计算。

表2 实验参数设置Tab.2 Setting of experimental parameters
4.3 基准模型比较
为了验证本文提出模型的有效性,本文模型与几种经典模型以及有关下一个POI预测的最新模型进行了比较,包括:
1)Markov chain[10]:马尔可夫链是使用估计的转移概率预测POI的经典方法之一。
2)ST-RNN[14]:是一种结合了时空上下文,并在RNN 框架内预测用户的下一次访问的深度学习模型。
3)POI2vec[15]:是一种结合基于word2vec技术的地理影响来预测下一个POI的嵌入表示学习方法。
4)DeepMove[16]:是学习人类移动性的第一个基于历史注意力的方法,包括一个带有RNN 的序列编码模块,用于从最近轨迹和历史轨迹中学习移动模式。
5)VANext[17]:它采用变分注意力机制对最近的轨迹进行编码,挖掘用户轨迹的历史移动行为模式。
4.4 总体性能比较
表3 和表4 给出了四个数据集的Top@k性能比较。可以看到,就预测精度而言,所提出的基于对比自监督学习的轨迹预测模型在所有方法中均表现出最佳的性能。
表3展示了模型在Top@1上的性能比较,从表3中可以发现,在纽约数据集和新加坡数据集上,SeNext在Top@1上的准确率分别比VANext提高了11.10%和12.93%。在性能方面,基于深度神经网络的模型(ST-RNN、POI2vec、DeepMove)的预测精度高于传统基于特征的嵌入方法和基于马尔可夫链的方法。此外,DeepMove 通常比大部分基准模型表现更好,因为它能够利用历史轨迹,而其他基准模型只能在训练期间学习当前轨迹中的序列模式。尽管所有这些方法都使用了RNN来获取长期的POI 依赖,但由于RNN 存在固有的梯度消失问题,即使是LSTM 和GRU 也不能很好地处理非常长的历史轨迹。这一结果符合了RNN 应用于自然语言处理的局限性。因此,DeepMove 的主要优势在于它对历史轨迹的重要性区分,这也证实了注意机制在处理序列数据方面的优越性。

表3 不同模型在Top@1上的准确率比较 单位:%Tab.3 Accuracy comparison of different models on Top@1 unit:%
另一方面,SeNext 优于DeepMove,主要是因为引入的轨迹预测模型不仅能更有效地捕捉短期的人类移动模式,而且数据增强能增提升模型的泛化能力,同时使用对比自监督学习方法中的负采样使模型更易于训练。
表4 中展示了模型在Top@5 上的性能比较,与表3 中在Top@1 上的结果类似,基于对比自监督学习的轨迹预测模型在所有方法中仍表现出最佳的性能。值得注意的是,对比表3和表4的实验结果,可以观察到本文的模型在Top@5上提升的幅度低于Top@1。Top@1 强调的是预测结果取最后概率向量值最大的那一维作为预测结果,Top@5 是预测前五个中只要任意一个出现了目标值即为预测正确,但这五个中也可能是排名靠后的第四个被判断是正确的,这样模型的判断并非可靠。而本文模型是利用正负样本对比学习的方式对模型进行训练,正样本即是正确的POI,负样本是一个训练批次中除这个点之外其他任意的点,通过将正样本与锚数据的相似度最大化,与负样本相拟度的最小化,这使得模型更关注于Top@1而非Top@5。

表4 不同模型在Top@5上的准确率比较 单位:%Tab.4 Accuracy comparison of different models on Top@5 unit:%
4.5 模块性能比较
为了验证本文模型中各个模块的有效性,本文采用不同的方式改变模块来进行实验。具体来说,DeepMove 主要利用RNN 和注意力机制从最近轨迹和历史轨迹中学习移动模式。VANext 在DeepMove 的基础上增加了变分贝叶斯技术,利用变分注意力将最近的移动性编码为潜变量,并使用它来查询用户的历史移动性;而SeNext 进一步将变分注意力替换为以自监督学习的方式来挖掘轨迹中更有价值的表示。将本文基于自监督学习的轨迹预测模型与DeepMove 和VANext 在纽约数据集上进行比较,如图3 所示,其中纵坐标表示的是进行对比的三个模型分别在Top@1、Top@5 和AUC(Area Under Curve)上的结果值。实验结果显示,VANext 的预测效果要优于DeepMove,表明变分注意力机制要比注意力机制更能匹配用户过去最相似的移动方式;而SeNext 优于VANext,说明本文的对比自监督学习方法可以更好地挖掘用户轨迹的潜在移动规律。在后续的工作中,会进一步结合其他上下文POI 属性信息,并改进对比自监督学习中的优化函数来更好地提升预测效果。
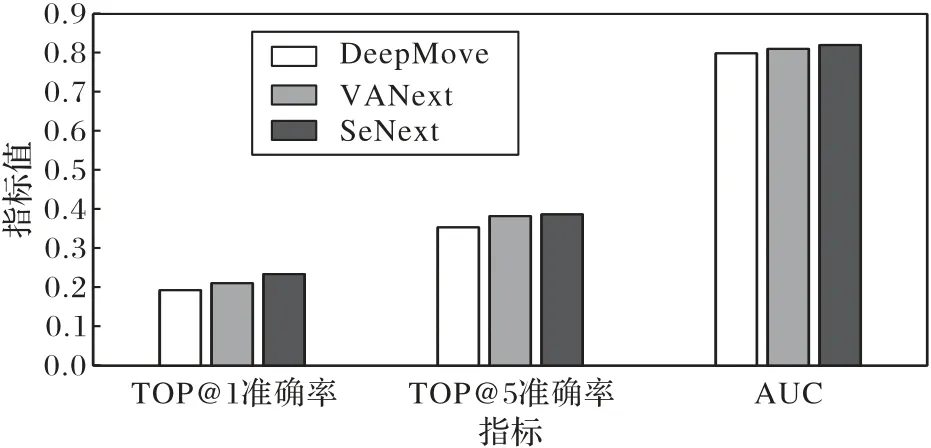
图3 模型性能比较实验结果Fig.3 Experimental results of model performance comparison
5 结语
本文提出了一种新颖的基于对比自监督学习的轨迹预测模型,用于学习并预测下一个POI 的人类移动模式。通过使用数据增强来丰富训练样本,提高了模型的泛化能力。使用RNN 来获取当前轨迹的特征信息,使用CNN 与注意力机制来获取并匹配与当前轨迹最相似的用户历史移动方式,大大提高了现有基于RNN 的方法的效率。通过对比自监督的方式训练模型,更好地捕获轨迹的移动模式和多层次语义。未来进一步的研究工作一部分将集中于结合其他的上下文POI属性(例如博物馆、餐厅),以提高模型的效率;另一种可能的扩展是考虑用户轨迹的交通运行模式(例如步行、公共汽车、出租车)以提高模型综合预测能力。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
