
结合LDA和用户特征的协同过滤算法
2021-09-16 02:28梁静,葛宇
计算机工程与设计 2021年9期
梁 静,葛 宇
(1.成都工业学院 计算机工程学院,四川 成都 611730;2.四川师范大学 计算机科学学院,四川 成都 610066)
0 引 言
基于用户的协同过滤算法能根据用户最近邻居(文中简称最近邻)的兴趣偏好,向其推荐满足需求的商品、信息和服务,近年来已被广泛应用于电子商务和社交网络中[1]。但是,传统基于用户的协同过滤算法对数据稀疏问题和用户冷启动问题的处理能力较差,导致用户间相似性度量的准确度降低,从而影响推荐质量[1,2]。为此,不少学者进行了相关研究。例如,针对数据稀疏问题,文献[3]利用基于项目的协同过滤结果填充评分矩阵空值,降低数据稀疏度后结合ALS矩阵分解算法进行预测,提高推荐质量。文献[4]基于项目评分数据和项目类别数据构建用户-项目-类别的三维张量,通过填补缺失数据建立用户类别偏好矩阵和评分偏好矩阵,进行联合推荐。文献[5]在传统算法中加入用户和项目的标签信息,嵌入LDA主题模型计算用户和项目的余弦相似性,提高相似性计算的准确度。文献[6]构造时间柱模型,根据用户评分及时刻生成时间加权相似度进行预测评分,并对项目类型进行LDA聚类预测评分,最终通过调节因子确定两种评分的权重生成结果,提高了推荐质量。针对新用户冷启动难题,文献[7]从评分、兴趣、置信度3个方面计算用户评分相似性,结合用户属性相似性进行联合预测推荐,并实现冷启动到非冷启动状态用户相似性计算的平滑过渡。文献[8]在文献[7]的平滑过渡方案上,基于用户特征的动态变化进行分类,设计了结合用户特征和评分数据的相似度计算方案,提高推荐的准确率。文献[9]设计了适应于计算个性化用户相似性的距离度量公式,并对用户属性评分量化,将其引入相似性计算公式中,既提高了推荐精度,也满足了用户的个性化需求。
不同于以上思路,本文为提高用户相似性计算准确度,提出一种结合LDA和用户特征的协同过滤算法。具体地,针对数据稀疏问题,利用基于吉布斯采样的LDA主题模型,设计用户对项目主题评分的相似性评价方案,并从理论角度论证该方案能有效降低数据稀疏性;针对用户冷启动问题,结合用户特征设计相应的编码,用海明距离计算用户间相似度,作为冷启动用户寻找最近邻的依据。在MovieLens数据集上的实验结果表明,本文算法能有效预测用户评分,提高推荐质量,在应对数据稀疏性问题和冷启动用户时也有较好的表现。
1 传统基于用户的协同过滤算法
传统基于用户的协同过滤根据邻居用户的偏好向目标用户进行推荐[1],首先根据已知的用户-项目评分矩阵,依据文献[9]采用皮尔逊系数法由式(1)[9]评估用户间的相似程度,然后根据相似性高低选取目标用户的最近邻Num(u),找出与目标用户偏好一致的邻居用户,最后根据式(2)预测目标用户对项目的评分
(1)
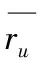
(2)
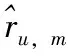
2 结合LDA主题模型和用户特征的协同过滤算法
文献[1]指出,传统基于用户的协同过滤算法,用户相似性评价会受到用户-项目评分数据稀疏性问题和用户冷启动问题的影响,而用户间相似性评价的准确程度又直接影响了算法最终推荐质量。为此,本文在传统基于用户的协同过滤算法基础上,以提高用户相似性评价准确性为出发点,对数据稀疏问题和用户冷启动问题的处理方案进行研究,具体思路为:
在传统基于用户的协同过滤算法基础上,通过借助吉布斯采样的LDA主题模型和矩阵运算,挖掘项目类型的隐含主题,生成项目-主题隶属概率矩阵,构造用户-主题评分数据,设计用户相似性评价方案,并用概率方法分析方案对数据稀疏问题处理的有效性。同时,在改进相似性的基础上分析用户特征,设计基于海明距离编码的冷启动用户相似性评价方案,用于提高冷启动用户的推荐质量。
2.1 基于LDA主题模型的用户相似性评价
LDA主题模型是一种文档主题生成模型,常用于挖掘大规模文档集中潜藏的主题信息,利用隐藏主题优化文档分类。如:文献[10]针对TF-IDF模型,运用LDA模型挖掘出文本的潜在主题,以提高文档聚类纯度。本文受此思路启发,借助LDA主题模型从项目类型关系中挖掘项目对应的潜在主题,将项目按主题进行聚类、构造项目-主题关系矩阵,以便更科学地反映数据规律。
2.1.1 基本吉布斯采样的LDA主题模型
Blei提出的隐含狄利克雷分布(latent Dirichlet allocation,LDA)是一种经典的主题模型,常被用来推测文档的隐含主题分布[10],其对应的概率模型如图1所示。

图1 LDA概率图模型
图1中M为文档总数,K为主题编号总数,Nm为第m篇文档中包含的词汇总数。zm,n(m∈[1,M],n∈[1,Nm])是文档m第n个词汇所属的主题编号,wm,n是文档m中的第n个词汇在词典中的序号。θm、φk分别表示第m篇文档下的主题分布和第k个主题下的词汇分布。α和β为先验参数。在给定文档集合下,wm,n是可观察的已知量,α和β是根据经验所得先验参数。按图1所示概率模型,可通过变分贝叶斯推断、吉布斯采样和最大似然估计[11]等方式估计出θm和φk值。本文采用吉布斯采样法估计LDA主题模型的θm主题分布,流程如图2所示。

图2 LDA吉布斯采样算法流程
图2对应的流程描述为:
(1)指定参数K(主题数)、α、β,和输入数据wm,n。

(3)利用吉布斯公式p(zi|z-i,d,w)对每个词汇进行采样,求出它对应的主题编号,并更新zm,n状态。
(4)重复(3),直到吉布斯采样收敛或达到迭代次数。
(5)输出每篇文档的主题分布θm。
2.1.2 挖掘项目-主题关系数据
针对项目数据(如本文实验中MovieLens 100K数据集的u.item和u.genre信息),将项目的类型看作词汇,每个项目看作文档,依据2.1.1节中的LDA主题模型挖掘项目隐含主题。设项目总数为M,将第m个项目记为itm(m∈[1,M]),如itm=(Action,Adventure,Thriller),表示项目m对应的类型有Action,Adventure和Thriller。所有项目的类型集合IT={it1,it2,…itM}。
采用图2流程,计算项目主题分布。输入项目类型集合IT,超参数α、β和主题数K。经过吉布斯采样算法,G次迭代(为保证算法收敛,G不宜过小)后输出本文所需的项目主题分布Iθ(如图3所示)。图3中,行列分别代表项目和主题,如第1行第1列数值为0.025 64,表示第1个项目在第1个主题的概率。

图3 项目主题分布Iθ
2.1.3 构造用户-主题评分数据
为了处理用户-项目评分矩阵RUM中的稀疏问题(即:用户没有对项目评分,造成矩阵中对应项为空),本文结合2.1.2节中得出的项目主题分布Iθ,把RUM转换为用户-主题评分矩阵RUK。以下给出转换方案,随后从概率角度进行分析,以说明本方案的有效性。
(1)用户-项目评分矩阵到用户-主题评分矩阵的转换方案。
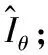
(3)

(4)

(5)
(2)从概率角度分析转换前后数据的稀疏性。
稀疏性和数据(矩阵)中存在空值(0值)成正比,为了说明以上方案所使用的用户-主题评分矩阵RUK稀疏性小于传统方法所使用的用户-项目评分矩阵RUM,下文从概率角度进行论证。
RUM和RUK中各个元素不为空值的事件是等可能事件(即项目或主题被对应用户作过评分事件),设DM对应矩阵RUM中一个元素值不为空的随机事件,其概率p(DM)记为λ1,λ1∈(0,1);DK对应矩阵RUK中一个元素值不为空的随机事件,其概率p(DK)记为λ2,λ2∈(0,1)。RUM(U×M)中所有元素值不为空的概率用p(RUM)表示;RUK(U×K)中所有元素值不为空的概率用p(RUK)表示。则矩阵RUM出现空值的概率
(6)
同理,矩阵RUK出现空值的概率为
(7)

以下用反证法证明λ1≤λ2。
证:假设λ1>λ2
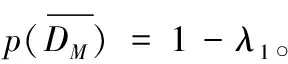
(8)
根据假设λ1>λ2,则有
λ1>1-(1-λ1)Q⟹λ1-1>-(1-λ1)Q⟹
(1-λ1)<(1-λ1)Q
(9)
由指数函数的单调性可知
Q<1
(10)
与已知Q≥1矛盾,假设不成立。因此λ1≤λ2,证明完毕。

2.1.4 结合用户-主题数据计算用户相似性
根据以上结果,用户-主题矩阵RUK中每一行记录了每位用户对各个主题的评分。参考文献[5],使用夹角余弦法计算矩阵RUK中用户间的相似度。设用户u、v对应主题评分数据RUK矩阵中两行(记为向量ru和rv),其相似度uksim(u,v)计算如式(11)所示
(11)
式中:向量ru=[ru,1,ru,2…,ru,K],向量rv=[rv,1,rv,2…,rv,K]。
2.2 基于特征编码的冷启动用户相似性评价
为了应对用户冷启动问题(即:缺少冷启动用户对项目的历史评分数据,导致无法从用户-项目数据中有效评价冷启动用户与其它用户间相似性的问题),本文参考文献[7]、文献[8]中利用特征作用户相似性评价的思路,设计了一种用户特征(如本文实验中MovieLens 100K数据集的u.user、u.occupation信息)编码方案,配合海明距离计算冷启动用户与其他用户间的相似性。
2.2.1 用户特征编码方案
对于冷启动和非冷启动用户,都已知其对应的性别、年龄和职业特征。定义用户特征集合为UA,共U个用户,UA={ua1,ua2,…uaU},其中uau(u∈[1,U])为用户u的特征。如uau=(24,M,Technician),表示该用户年龄24,性别男,职业为技术员。
为配合海明距离计算用户间相似度,本文对3个用户特征使用不同长度的二进制数进行分别编码,以体现出不同特征对用户相似性的影响程度。具体的编码方案为:
(1)性别特征,用1位二进制进行编码,将男女分别编码为0和1。
(2)年龄特征,用7位二进制进行编码。将年龄分为7组:(0-17)、(18-24)、(25-34)、(35-44)、(45-49)、(50-55)和56岁以上。考虑到要区别用户年龄段之间的差异程度,比如年龄50和10,相比50和40的差异程度更大,故本文对年龄特征按分组进行多位置1编码。每一位编码代表一个年龄段,当用户属于某年龄段时,对应编码位和它前面的每位均置1,后面均置0。如24岁编码为“1100000”,47岁编码为“1111100”。
(3)职业特征,用5位二进制进行编码。依据二八定律[12]:任何一组东西,最重要的大约占20%,其余的占80%。本文将职业对应的用户数量降序排列,前20%的职业单独分类,其余职业归为一类。对21个职业统计后,student、other、educator、administrator排在前4,对应前4位编码,其余归为一类对应第5位编码。具体编码时,所属职业的对应位置1,其它位均置0。如educator编码为“00100”,Technician编码为“00001”。
依据以上编码方案,最终构成13位二进制编码。其格式如图4所示。用户特征编码集合对应如图5所示。

图4 13位的用户特征编码格式

图5 用户特征编码集合
2.2.2 结合海明距离计算冷启动用户相似性
在信息学中,海明距离[13]被用于衡量两串代码间的差异,是一种简单高效的距离计算方法,本文基于海明距离设计了冷启动用户相似性计算策略,更准确地为冷启动用户寻找最近邻居。根据以上思路,以下从用户特征编码中计算用户间海明距离,以此评价冷启动用户与其他用户间的相似性。冷启动用户u与非冷启动用户v对应的相似性uasim(u,v),如式(12)所示
(12)
式中:dishamming(u,v)为u、v间的海明距离,即:统计两位用户的编码在进行异或(xor)运算后1的个数,其结果与相似度成反比关系。特别说明的是:为了处理dishamming(u,v)为0的情况,分母中加入了调节项1。
2.3 算法描述
根据前文分析,以下在传统基于用户的协同过滤算法基础上,加入了针对数据稀疏性问题和用户冷启动问题的相应机制,设计了结合LDA主题模型和用户特征的协同过滤算法,算法流程描述如下(其中(1)-(3)、(4)、(5)分别对应文中2.1节和2.2节设计的方案,(6)即对应是否为冷启动用户分别采用不同的方案计算相似度并用于最终预测推荐):
(1)对项目类型集合IT,按照2.1.1节中LDA吉布斯采样算法流程(如图2所示),计算出项目主题分布Iθ。

(3)按2.1.4节中式(11),利用夹角余弦法计算出用户相似度uksim。
(4)对用户特征集合UA按2.2.1节进行特征编码。
(5)根据2.2.2节中式(12)计算出冷启动用户与非冷启动用户相似度uasim。

(7)输出用户预测评分数据。
3 实 验
3.1 数据集与评价指标
本文实验采用MovieLens 100K数据集[14],抽取数据训练集和测试集比例4∶1,实验环境为Intel Core i5处理器、8 GB内存,Windows10(64 bit)操作系统。
参考文献[4]、参考文献[15],实验使用平均绝对误差MAE[4](mean absolute error,MAE)和准确率Precision[15]对算法进行评价,分别如式(13)、式(14)
(13)
(14)
式中:TopN为算法向用户所推荐的项目数,Hits为算法产生的正确推荐数,Precision值越高,表示推荐质量越高。
3.2 实验结果及分析
参考文献[6],本文将算法中LDA主题数设置为15,为验证本文算法(以下记为:UILCF)的有效性,实验先讨论UILCF在不同数据稀疏度、不同冷启动用户数量情况下的表现,然后将UILCF与4种具有代表性的算法进行性能对比,具体实验如下:
(1)不同数据稀疏度下算法性能对比
本文算法是在传统基于用户的协同过滤算法基础上加入了应对数据稀疏性的机制,为评估其有效性,实验将UILCF与传统协同过滤算法(以下简记为UCF)进行对比。实验随机删除测试集中部分评价数据,模拟不同的稀疏度(矩阵RUM中空值或0值的比例)环境,结果如图6和表1所示。从图6结果可以看出,随着数据稀疏度的增长,两种算法的MAE值都在增加,但UILCF的MAE值始终低于UCF。从变化率的角度看,UILCF也优于UCF,尤其在稀疏度值0.96以后,UILCF的优势更加明显。另外表1对比结果表明,在不同稀疏度下UILCF均具有更好的推荐准确率。这正是因为UILCF在计算用户相似性时结合了LDA模型,让算法在数据稀疏度不断增大时仍然具有较好的预测效果。

图6 UCF与UILCF在不同稀疏度下的对比
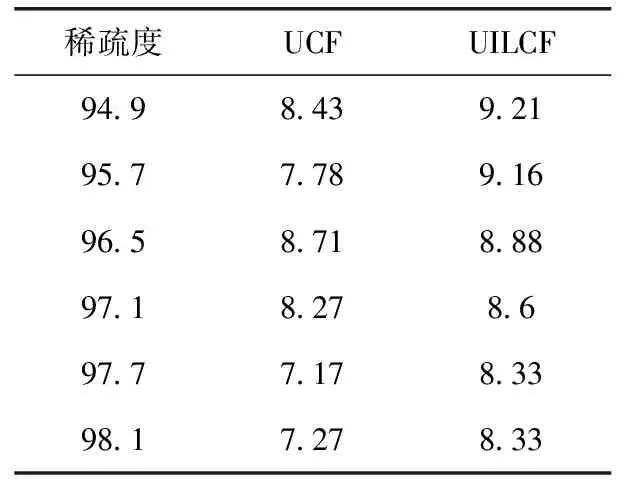
表1 UCF与UILCF在不同稀疏度下的准确率对比/%(TopN=2)
(2)不同冷启动用户数量下算法性能对比
UILCF在UCF的基础上增加了冷启动用户处理机制,以下实验从测试集中随机选择用户,删除其评分数据,模拟不同数量冷启动用户的情况,结果如图7和表2所示。在冷启动用户数量为10-60时,图7中UILCF的MAE值始终低于UCF。表2中UILCF的Precision值始终高于UCF,表明UILCF具有更高的推荐质量。以上结果说明,本文算法利用了用户特征信息寻找邻居用户进行相似推荐,取得了更好的效果。

图7 UCF与UILCF在不同冷启动用户下的对比

表2 UCF与UILCF在不同冷启动用户下的准确率对比/%(TopN=2)
(3)与文献报道的算法性能对比
实验选择4种具有代表性的算法进行对比:传统基于用户的协同过滤算法(以下记为:UCF)、传统基于项目的协同过滤算法(以下记为:ICF)、嵌入LDA主题模型的协同过滤推荐算法(以下记为:ULRCF)[5]、基于用户属性和评分的协同过滤算法(以下记为:UARCF)[7],实验结果如图8和表3所示,其中表3给出了推荐数目TopN在不同取值下的准确率对比。图8中,UCF、ICF、ULRCF对应数据来自文献[6],UARCF对应数据来自文献[7]。表3中UCF、UARCF对应数据来自文献[8]。

图8 不同算法下的MAE值变化
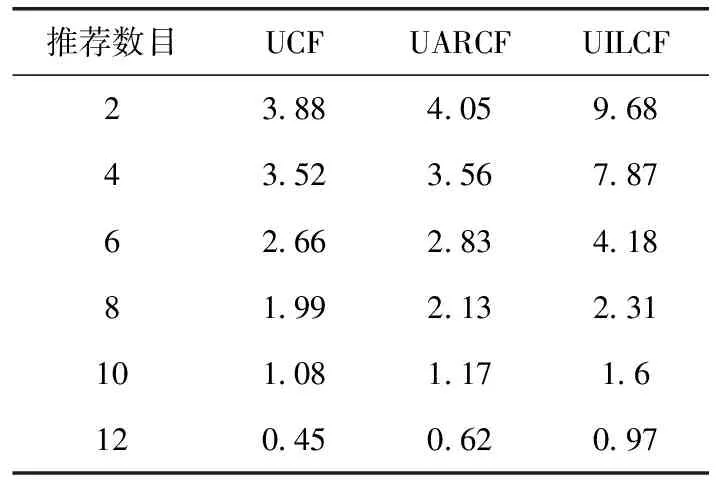
表3 不同算法的准确率对比/%
表3结果说明,各算法随推荐数目的增多,Precision值呈下降趋势。但UILCF在不同的推荐数目下,Precision值均优于文献中的另两种算法,尤其在推荐数目较小时,UILCF的推荐准确率很高。从图8不难看出,相比于UCF、UARCF、ULRCF和ICF,在最近邻数量小于35时UILCF对应的MAE值更低,说明本文算法因为采取了针对数据稀疏问题和用户冷启动问题的对应策略,所以性能优于上述4种算法。需要说明的是,在最近邻数量大于38时,UILCF的MAE值变化趋于平缓,且高于ULRCF,说明本文算法在最近邻个数增大时效果不及ULRCF。但是结合实际考虑,算法在最近邻个数较少时得到的推荐准确性更具有应用价值,由此说明,本文算法在最近邻个数较少时相比4种算法推荐质量更高,更具有实用价值。
4 结束语
本文提出了结合LDA主题模型和用户特征的协同过滤算法。在传统基于用户的协同过滤算法基础上,利用LDA主题模型挖掘项目的隐含主题,和已有数据一起计算用户-主题评分,从而将用户相似度评价依据从稀疏度较高的用户-项目评分矩阵,转变成了稀疏度较低的用户-主题评分矩阵,有效缓解了数据稀疏性问题对用户相似度的影响。另外,本文还提出了基于用户的特征编码方案,并根据海明距离建立冷启动用户和其它用户的特征相似性评价方法,以提高冷启动用户对应用户相似度计算的准确性。实验结果表明,本文算法在最近邻数量较少的情况下能提高算法的推荐质量,具有较好的实用性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
重庆大学学报(2022年6期)2022-06-23
客联(2021年2期)2021-09-10
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
河北画报(2020年8期)2020-10-27
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
浙江大学学报(工学版)(2016年2期)2016-06-05
