
基于注意力机制的DDoS攻击检测方法
2021-09-16 01:51:42王庆生陈永乐郭旭敏
计算机工程与设计 2021年9期
贾 婧,王庆生+,陈永乐,郭旭敏
(1.太原理工大学 信息与计算机学院,山西 晋中 030600;2.山西青年职业学院 计算机信息与工程系,山西 太原 030000)
0 引 言
攻击者利用傀儡机使用分布式、协作式计算机资源以网络带宽和系统资源为主要攻击目标,发送大量良性流量导致目标用户无法访问服务[1-3]。由于DDoS攻击具有易实施、易布控、难以防范追踪以及攻击流量多样性、混合性、不确定性等特点,因此以区分合法流量和攻击流量为目标的攻击检测成为DDoS主要防御机制之一。其中基于统计学习,机器学习等浅层学习方法很难捕捉DDoS攻击的演化本质,导致DDoS攻击检测准确率不高。同时,基于深度学习方法通过前后向序列信息去考虑特征的时空相关性,一定程度上提高了检测准确率[6]。但是对于长期序列而言,深度学习中编码向量所能存储的信息以及其相互关系受限于序列间的距离,导致某种程度造成序列间重要特征丢失。
因此,本文提出基于注意力机制的双向LSTM模型应用到DDoS攻击检测之中。首先,根据DDoS攻击领域知识提取出网络攻击流量最相关元组特征,即多种大流量攻击类型所具备的明显流量特征,将其与数据预处理后的数据集进行向量拼接。随后,提出于BiLSTM中加入注意力机制模块,为对序列进行全面分析和局部探索,BiLSTM网络使用所有从未来和过去的时间步长所获得的信息,学习嵌入在原始输入流量中的复杂流级特征表示,同时注意力模型有助于聚焦表示DDoS攻击的隐含信息,将有限注意力资源聚焦于高价值信息,用于提高准确率,降低误报率。
1 研究现状
DDoS攻击的数量、频率、复杂程度和影响都在急剧增长,攻击方式变得尤为难以缓解,区分正常流量和DDoS攻击流量特别困难。
关于统计方法在DDoS攻击检测方面的应用,Bhuyan MH等[4]根据Hartley熵、Shannon熵、Renyi熵、广义熵这些度量来描述网络流量数据的特征进而检测低速率DDoS攻击;Hoque N等[5]提取出3个特征,即源IP的熵、源的变化IP和数据包速率,计算对网络流量的每个样本使用FFSc的相似度值用于攻击检测。然而统计方法需要根据专业知识进行特征向量提取,所以人为因素的不确定性导致准确率有所影响;同时机器学习在此领域中已经取得了不错的效果,Singh.K等[7]提出一种基于随机森林分类模型的DDoS检测方法,将数据流信息熵作为分类标准,对3种常见的DDoS攻击方式进行特征分析,但由于传统机器学习的局限性,无法从攻击流量的长期序列中获取深层次特征,很难对低速率DDoS进行检测,准确率低。近年来,深度学习在各个领域中卓有成效,在DDoS攻击检测中,利用一系列连续的网络数据包获取攻击流量和合法流量之间的区别。Saied等[8]提出一种使用人工神经网络检测已知和未知的DDoS攻击的检测方法,选择人工神经网络(ANN)基于分离DDoS的特定特征,来检测DDoS攻击行为;Yuan X等[9]设计了一个递归的深度神经网络(RNN),从网络流量序列中学习模式,并跟踪网络攻击活动。
基于注意力机制的神经网络最近成为了图像再识别、语音识别和语言翻译等研究领域中的一个热点[10-12],其本质包含两个部分:其一,基于实现任务目标,需着重于输入目标的哪个部分;其二,针对使用全局注意力机制计算出注意力值,从已关注部分模块快速筛选有用信息。在DDoS攻击检测领域,注意力机制思想还未得到应用。本文借鉴其主要思想提出基于注意力机制的双向LSTM进行DDoS攻击检测方法。
2 基于注意力机制的DDoS攻击检测
本文提出一种基于注意力机制的DDoS攻击检测方法,该方法包含领域知识、数据预处理、基于注意力机制的BiLSTM这3个模块,系统总体结构如图1所示。首先,将根据领域知识所提取的特征向量与数据预处理后的数据流矩阵进行向量拼接,然后经过BiLSTM模型和注意力模型学习表示,最终通过分类器完成DDoS攻击数据流检测工作。

图1 总体结构
2.1 领域知识
领域知识[13]是某个研究领域中相互关联、相互约束的概念集合,当我们处理控制、优化和其它问题时,我们需要利用领域知识来正确地设计、初始化和修改问题解决程序的参数。DDoS攻击的本质是攻击者可以使用大量的“傀儡”机器短时间生成大量攻击流量使系统或网站崩溃。当攻击发生时源IP地址端和目的IP地址端数据包数量差异大以及网络流量中数据包的大小变化率、不同端口间增长率及时间间隔均异常增长。为了及时精确检测DDoS攻击,本文基于DDoS攻击领域知识,提取出最相关的特征子集,即四元组流量特征。领域知识特征组见表1。

表1 领域知识特征向量组
(1)不同端口增长速率:当发生大流量攻击例如Smurf、ICMP、UDP攻击时,通常攻击者所发起的瞬时高峰流量通过随机生成端口进行端口扫描攻击,端口变化速率有异常激增情况。
(2)单位时间内数据包数量:由于DDoS大流量攻击有瞬时、突发等特点,单位时间内所产生的数据包急剧增加。
(3)数据包大小变化率:攻击者通过僵尸网络产生大量无用数据包,其内容及字节长度一致性较高,相较于正常数据包往往大小不一。因此数据包大小变化率极低。
(4)流持续时间:当发生TCP攻击时,攻击方利用3次握手协议缺陷导致受害者端资源被半连接队列充满,持续时间较正常连接变长。
2.2 基于注意力机制的BiLSTM结构
2.2.1 注意力机制
注意力机制在深度学习中被广泛应用研究,其在语音识别、机器翻译等序列数据方面取得较好的效果,其本质是通过将足够的注意力来突出对结果有重要贡献的局部信息,而忽视不相关的信息。本文将对LSTM结构中的注意力机制进行过程说明:
LSTM结构中,编码器读取向量的输入序列,x=(x1,x2,…,xTx)为向量c,公式如下
st=f(xt,st-1,ct)
(1)
c=q(s1,…,sTx)
(2)
其中,st为隐藏层状态,c为取决于LSTM隐藏状态的输出向量。在注意力模型中,上下文向量ct与编码器映射输入句子的注释序列(h1,h2,…,hTx)密切相关,整个输入序列的信息包含在注释ht中,这些信息主要集中在围绕输入序列第t个单词的部分,所有注释的加权和构成上下文向量ct,公式如下
(3)
式中:每个注释hj的权重αtj计算公式如下
(4)
etj=a(st-1,hj)
(5)
其中,函数a(st-1,hj)是用于描述j位置附近的输入与t位置处的输出之间的匹配能力,权重通过使用LSTM隐藏状态st-1和输入语句的第j个单词的注释hj来计算。神经网络中的注意力机制旨在通过评估权重αtj选择输入中的重要输入序列(x1,x2,…,xTx),使得神经网络有能力专注于序列子集的输入,即它总是选择重要的输入。注意力机制模型如图2所示。

图2 注意力机制模型
2.2.2 基于注意力机制的双向LSTM结构
长短期记忆网络(LSTM)是RNN的最常见形式之一,旨在避免RNN等长期依赖问题,并且适合全局化处理和预测时序数据,但传统LSTM的明显缺点是它们仅利用先前的(单方面)信息对输出进行价值评估。在DDoS攻击检测过程中,不仅需要关注相邻数据流,还需要关注长距离流,以确定当前数据流是合法流量还是攻击流量。双向LSTM网络通过前后向时间步长获得信息,同时注意机制接受注释以提取对攻击检测很重要的数据包所包含的细微特征,同时聚合并判断这些信息对结果的贡献度,形成注意力分布向量。基于注意力机制的BiLSTM结构如图3所示。

图3 基于注意力机制的BiLSTM结构
BiLSTM由2个并行运行的LSTM组成:一个按顺时针方向处理数据方向即x1到xt,而另一个设置为逆时针方向即xt到x1。在每个时间步长,BiLSTM的隐藏状态是向前和向后隐藏状态的串联,此设置允许隐藏状态以捕获过去和将来的信息,公式如下
(6)
(7)
(8)
基本的LSTM由一个存储器组成的单元,一个输入激活功能和3个门(输入门it,忘记门ft,输出门ot)。LSTM网络在每个单个时间步生成两个状态:一个单元状态转移到下一个时间步和隐藏状态时间步的输出向量。
ht-1和ct-1是隐藏状态和单元状态上一个时间步t-1,ht和ct分别是隐藏状态和当前时间步t的单元状态,定义如下
ft=σ(Wf·[ht-1,xt]+bf)
(9)
it=σ(Wi·[ht-1,xt]+bi)
(10)
ct=ft∘ct-1+it∘[tanh(Wc·[ht-1,xt]+bc)]
(11)
ot=σ(Wo·[ht-1,xt]+bo)
(12)
ht=ot∘tanh(ct)
(13)
权重(Wf,Wi,Wc和Wo)和偏差(bf,bi,bc和bo)都是可训练的参数。最后时间步长的隐藏状态ht是整个LSTM网络的输出。
在双向LSTM网络中,联合嵌入序列(前向)和对应的反向嵌入序列(后向)分别输入两个LSTM,最终双向LSTM的输出为hn,之后根据公式计算其对应的注意力权重,并对所有的隐藏向量进行加权求和得出其最终编码向量c,然后将所得值传入全连接层特征转换后,传入最后softmax函数的输出层计算输出向量。该模型伪代码如下所示。
算法1:基于注意力机制的BiLSTM算法
输入:数据流样本F={P(1),P(2),…P(i),…,P(N)|1≤i≤N}
输出:样本分类结果S
(1) For P(i)in F:

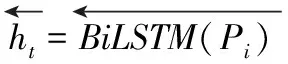

(5) End for

(7)S=softmax(fullyconnect(c))
3 实验与分析
3.1 实验数据集
本文在CAIDA-2007[14]数据集上评估了所提出的框架。此数据集包含2007年8月4日DDoS攻击大约一小时的匿名流量跟踪,包含UDP Flood、TCP Flood、ICMP(Ping)Flood和SYN Flood数据包。数据集中的每个数据包包含源IP地址、目的IP地址、数据包长度、协议和数据包到达时间。数据集包括213 066条网络流量,其中正常流量有94 164条,攻击流量118 902条。将总流量数据集分成60%(127 839)和40%(85 227)进行训练和测试。
3.2 实验细节
3.2.1 数据预处理
根据领域知识,本文使用CICFlowMeter流量提取器[15],对CAIDA-2007训练集提取[Por_inc_rate,Pac_tim_inte,Pac_size_rate,Flow_dur]特征四元组。由于CAIDA-2007数据集属于原始的、未经处理的pcap格式流量集合,该格式无法输入神经网络进行训练,因此本文将原数据以数据流、数据包、数据包字节三级结构转换为神经网络数据输入格式,通过源地址、目的地址、传输层协议、源端口四元组来唯一标记一条数据流,即这两个ip地址间相同协议,相同源端口所进行的会话视为同一条数据流。使用SplitCap工具按上述四元组将每条数据流样本分割为时间顺序不变的数据包M,每个数据包里的字节数为N。即每条数据流表示为N*M矩阵格式。由于N,M有所不同,采用padding补全或切断数据包字节数和数据包个数使得数据流满足模型数据输入格式。数据流格式如图4所示。

图4 数据流格式
将数据流切分后的DDoS数据集和根据领域知识提取的特征四元组进行向量拼接及维度重构,构成(N+4)*M矩阵格式作为神经网络输入格式。由于数据包里有二进制字符串组成,将每个字节转换为取值范围[0,255]的十进制数,将协议类型布尔型转换为二进制数。同时,将数据转换后的十进制数进行取值为[0-1]的归一化处理,经过处理后的数据格式可以提高模型收敛速度。
为了确定最佳数据包数M和字节数N,分别对数据包数N取100,300,500,M取500,1000,1500进行实验。
3.2.2 实验过程
BiLSTM模型设置中,LSTM内部神经元个数为100,全连接层神经元个数为128。为了克服过度拟合的问题,本文使用在模型训练中采用dropout技术,其丢弃率值为0.5;使用Adam优化算法来调整学习率,初始学习率为0.001;训练过程中使用CAIDA-2007数据集进行十折交叉验证,批量大小设置为100,epochs设置为30,其它超参数设定采用默认值。
本文硬件实验环境参数如下:Intel Xeon E5-2678 V3 2.50 GHz 2,NVIDIA Tesla K40c GPU 2,128 gb RAM, 120 gb SSD。所有实验均TensorFlow编写,并使用GPU进行训练、测试。
为了选取最佳的流量矩阵表示格式,选取N=[500,1000,1500],M=[100,300,500]进行排列组合构成9种可能,将其输入已确定参数的Att-Bilstm模型中,最终不同格式数据流分类准确率如图5所示。

图5 不同格式数据流分类准确率
从图中可以看出,当M=500,N=1000时,模型性能表现最好,准确率最高。随着数据流需划分数据包个数M的减少,准确率同比下降9.1%~27.9%,因为对于DDoS攻击检测数据流的时序要求,每条数据流样本处理时保留多的数据包个数有助于训练序列数据间时序特征;由于DDoS攻击中产生大量内容、字节大致相同的攻击流,而数据包所包含的类别表征信息集中于前几个数据字节数,而数据包具体内容信息集中于后几个字节数,因此字节数设定为1000可以获得较高准确率。通过以上实验分析,N=500,M=1000是最佳数据流矩阵格式。
数据流切分设置阶段,以每条数据流[500,1000]的矩阵格式划分,同时将预处理后的DDoS数据格式和根据领域知识提取的四元组特征进行向量拼接及维度重构,构成[500,1004]矩阵的数据输入格式。
3.3 评价标准
本实验采用准确性,召回率和F量度作为评价标准。其中TP代表真阳性数,FP代表假阳性数,FN代表假阴性数。精度由以下定义确定:所有元素中正确分类为肯定的元素归类所占比例,而召回率则定义为正确分类为正数的元素所占的比例
3.4 结果与分析
3.4.1 深度学习检测结果
为了更直观展示本文方法Att-BiLSTM的性能,与诸如RNN(循环神经网络)、LSTM(长短期记忆网络)、BiLSTM(双向长短期记忆网络)和Att-BiRNN进行对比实验。不同深度学习结果见表2。
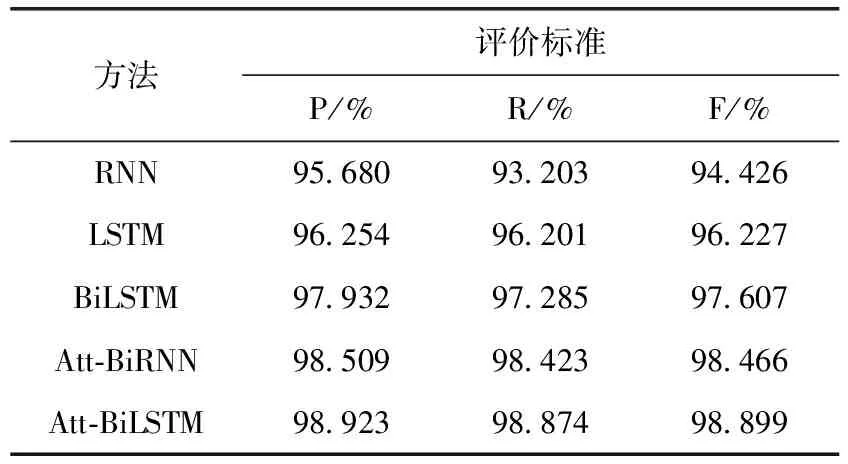
表2 不同深度学习效果对比
实验结果可以看出,Att-BiLSTM模型在处理DDoS攻击检测分类时有很好的效果。与RNN、LSTM模型相比,BiLSTM模型中的记忆单元不仅有效记录数据流中的数据信息,而且加强模型对时序序列数据的双向学习能力,从而模型达到相对较好的结果。与BiLSTM、Att-BRNN模型相比,本文模型F度量增加了0.4%~1.2%,表明Att-BiLSTM既避免了BiRNN对远端序列的长期依赖问题,同时注意力机制的加入将数据包对分类结果所产生的不同的贡献度生成注意力权重,模型的效果进一步提升。
同时,结果表明加入根据领域知识所提取的四元组特征向量与未加入相比,模型的准确率提升0.5%,因此根据领域知识提取明显流量特征对最终分类效果有积极影响。
3.4.2 现有方法对比实验
本文的DDoS攻击检测结果与基于统计学习,机器学习以及其它深度学习进行检测方法的结果对比见表3。
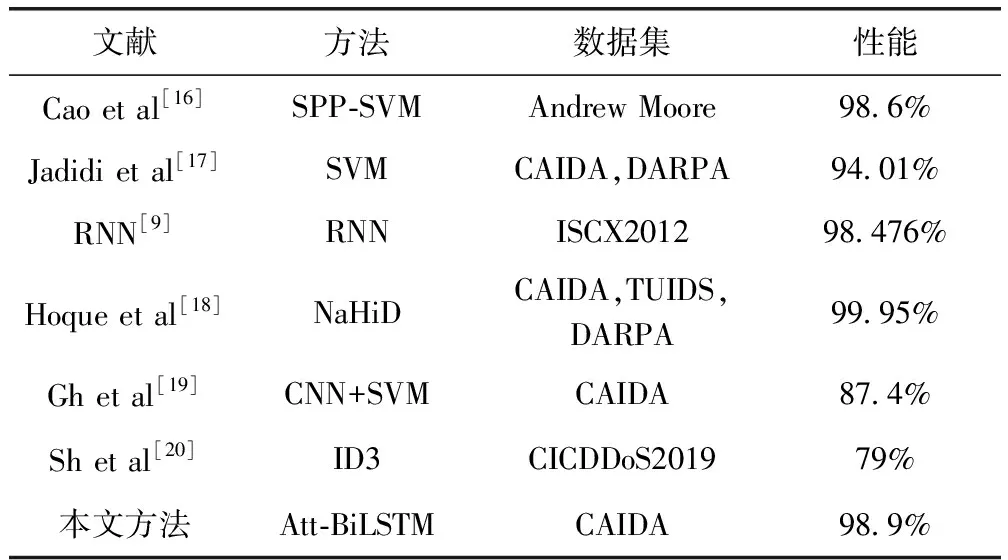
表3 现有方法效果对比
从表中可以得到,本文基于注意力机制的BiLSTM模型准确率可达98.9%。同时本文选择的对比方法文献[16]、文献[17]、文献[21]均需要人工设计流量特征,并且在模型训练之前完成流量特征的提取和选择,之后通过浅层学习实施模型的训练和测试,但该方法无法充分挖掘数据流的前后序列。文献[19]使用静态和动态阈值方法来分别执行已知DDoS攻击与未知DDoS攻击检测,检测准确率高达99.95%,但是阈值的确定需要递增地更新正常流量的统计信息,同时还需专业的研究知识来自定义初始阈值,这样会使得预处理任务变得更加复杂,比本文提出的框架增加了更多训练时间和计算成本。本章提出深度学习加入注意力机制模块,根据BilSTM得出数据包对应权重向量,然后通过权衡时序序列的前后关系得出对最终结果有重要影响的向量表示。实验结果表明,加入注意力机制比使用传统浅层机器学习,神经网络取得更好的分类效果。
3.4.3 数据集对比实验
为了验证本文所提出模型的泛化能力,基于DARPA[17]、ISCX[9]、TU-DDoS[21]、CAIDA这4个常用DDoS公开数据集进行实验,数据集对比实验结果如图6所示。

图6 数据集对比实验结果
实验结果表明,该方法在公开的流量数据集上取得了良好效果,DARPA、CAIDA、TU-DdoS这3个数据集准确率最高可达98.5%以上,ISCX数据集的检测率略低,达96.5%。基于总体评价指标方面,总体精度可达98.3%,由以上折线图分析可知,本文提出的基于注意力机制的双向LSTM的DDoS攻击流量分类方法取得了良好的分类效果,验证了该方法的有效性。
4 结束语
本文提出了一种基于注意力机制的双向LSTM的DDoS攻击检测方法。该模型使用双向LSTM考虑双向框架对所有攻击流量的时间相关性分析并使用注意机制以便自适应地注意那些具有对检测结果判断的重大影响,有效利用了Att-BiLSTM优秀的时序特征学习能力。其次,本文引入DDoS攻击领域知识,通过对多种攻击类别分析提取出特征元组,在CAIDA-2007数据集上的实验结果表明,该元组使得模型检测准确率提高0.5%。另外通过与其它现有研究方法进行对比,基于注意力机制的BiLSTM在取得较高的精度和检测率的同时,保持了较低的误警率,比其它公开的攻击检测方法具有更好的综合检测效果,验证了本文提出的方法在特征学习和降低误警率等两方面的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
汽车维修与保养(2020年11期)2020-06-09 05:42:22
网络安全和信息化(2018年4期)2018-11-09 12:01:54
电脑与电信(2018年12期)2018-03-23 02:37:36
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国卫生(2014年7期)2014-11-10 02:32:54
中国新通信(2014年11期)2014-09-11 19:27:52
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
