
基于双流卷积的实时跌倒行为检测
2021-09-16 02:29金彦亮
计算机工程与设计 2021年9期
金彦亮,陈 刚
(上海大学 通信与信息工程学院,上海 200444)
0 引 言
针对老龄化加剧伴随而来的独居老人跌倒问题,本文对基于双流卷积的实时跌倒检测展开研究。
目前针对跌倒检测的研究主要有两个方向:基于三维传感数据的方法与基于视觉的方法。基于三维传感数据的方法即采用陀螺仪等传感器获取人体运动的三维加速度和角速度值[2]来检测跌倒事件,近几年也出现了利用智能手机配备的传感器来实时获取人体运动的加速度和角速度信息的解决方案[3]。但是这些传感器和手机需要定期更换电池或充电,受限于设备的电量与寿命,还存在老人在家中并不会随身携带手机的情况。相比之下基于视觉的方法主要利用计算机视觉来检测画面中的人是否跌倒,这种方法不需要佩戴相关传感器,方便、体验好。
基于视觉的跌倒检测关键在于从视频帧中提取有意义的特征来进行检测,例如人体姿态、倾斜角度等。Stone等[4]提出了一种使用Kinect深度相机和两阶段跌倒检测系统来检测老人跌倒的方法,第一阶段除了提取人体速度、加速度等特征外,在单个深度图像帧中还计算一个人在地面的投影面积,这个特征可以很好区别跌倒和躺下动作,然后在第二阶段使用决策树来计算跌倒的置信度。J.Donahue等[5]提出将CNN与LSTM相结合对空间维度特征与时间维度特征进行学习和理解的方法。而LSTM复杂度高,相比双流卷积方法计算会更耗时,不适合实时的跌倒检测。此外,利用光流图作为时间流输入虽能很好地描述运动特征,但光流图的计算也比较耗时,对实时性影响较大。
本文构建双流卷积神经网络,选用预训练的轻量级模型MobileNetV2,输入人物轮廓的RGB单帧提取空间维特征,输入连续的多帧MHI提取时间维特征,将两个流输出的特征按一定方式进行融合获得时空特征来进行跌倒行为识别。实验结果表明,基于人物轮廓RGB-MHI的双流卷积神经网络对于跌倒检测具有良好的可靠性和实时性。
1 跌倒检测模型设计
双流卷积神经网络是通过模仿人眼观察事物的机制,将视频分为空间流与时间流两条支路[6]。空间流的每一帧代表着视频中所描绘的物体和场景信息等,而时间流是指帧与帧之间的运动信息,因此,该神经网络由分别处理时间维度与空间维度信息的两个神经网络所构成。
1.1 空间流卷积神经网络
空间流采用MobileNetV2[7]模型,相比其它预训练模型,MobileNetV2更加轻量级,在减少网络大量计算量的同时能够保持良好的性能,适合将实时跌倒检测模型放入嵌入式平台上。MobileNetV2是由MobileNetV1升级来的,MobileNetV2更加高效,首先它依然使用MobileNetV1中的深度可分离卷积(depthwise separable convolution),深度可分离卷积的目的在于对参数量的节省,控制参数的数量,从而提高网络运行速度,区别在于MobileNetV2又引入了残差结构和瓶颈层。MobileNetV2的残差结构借鉴于ResNet,在ResNet的残差结构基础上又做了些改进,引入了倒残差块,ResNet的残差块是对图像先将降维、卷积,再升维,而倒残差块是对图像先升维、深度可分离卷积,再降维,所以倒残差块的作用就是将输入的数据变换到高维度后再经过深度可分离卷积提取特征,从而提升网络的表达能力。加入瓶颈层这种新的结构被称作为线性瓶颈,即在深度可分离卷积之前添加了一个1×1卷积用于改变输入数据的维度,保证卷积过程是在高维空间提取特征,然后为了不破坏特征,去掉了第二个1×1卷积后的激活函数,使用线性激活函数以保持卷积提取到的特征。MobileNetV2 网络结构的具体参数见表1,其中Conv2d代表标准卷积,Inverted Residual代表由倒残差块组成的卷积层,Avgpool代表平均池化,通道扩张系数代表倒残差块中通道升维的倍数。该网络共包含19层,中间各层用于提取特征,最后一层用于分类。

表1 MobileNetV2网络参数
因此本文选择MobileNetV2作为空间流的基础网络,然后添加全连接层,与后面一小节的时间流模型在相同维度的全连接层Concatenation相连。
空间流的输入为对视频中的连续帧采用帧间差分法提取出的人物轮廓单帧,输入shape为224×224×3,输入提取的人物轮廓RGB相比较输入原始RGB可以消除背景对检测的干扰,在实验与结果分析章节通过实验表明输入人物轮廓RGB比输入原始RGB准确率提高了5.26%。帧间差分法的执行速度较快,实现思路简单,可以满足实时性要求,且在大多数情况下检测结果较好[8]。帧间差分法的算法流程介绍如下:将fn和fn-1分别表示为视频中的第n帧和第n-1帧,fn(x,y)和fn-1(x,y)分别表示为第n帧和第n-1 帧在(x,y)像素点的灰度值,然后将其对应像素点的灰度值做差后取绝对值,于是得出差分图像Dn
Dn(x,y)=|fn(x,y)-fn-1(x,y)|
(1)

(2)

帧间差分法的核心在于THRESHOLD阈值的设置,THRESHOLD值的选择会对检测结果造成直接影响,如果THRESHOLD的值设置较大,当运动目标的RGB值与背景的RGB值接近时,会导致运动目标部分区域的缺失,相反的,如果THRESHOLD的值设置较小,检测的结果就会混合一些背景区域。在本文中THRESHOLD的值取为32,最终目标轮廓检测结果如图1所示。

图1 人物轮廓检测
由于数据集的视频是固定镜头的,所以从图1可以看出当镜头固定时帧间差分法的检测结果是良好的,而跌倒检测一般用于镜头固定的监控设备,所以使用帧间差分法能够基本满足需求。
1.2 时间流卷积神经网络
时间流设计的CNN网络包含卷积操作、批标准化操作(Batch Normalization)、采样操作、“压平”操作(Flatten)、全连接网络和Sigmoid网络,将输入帧的特征抽象化来实现分类任务。其中Batch Normalization层的作用第一为了加快收敛速度,第二为了控制过拟合,能少用或者不用Dropout和正则,第三为了降低网络对初始化权重不敏感,第四可以允许用较大的学习率来实现[9]。
为提高检测速度达到实时性,将模型中滤波器的数量、深度、大小、步长等因素进行了权衡,第1个卷积层卷积核大小为7×7,卷积核个数为64,第2个卷积层大小为5×5,个数为128,第 3、4、5个卷积层大小均为3×3,个数均为256,采样层窗口均为2×2,采样方式都采用最大值下采样;全连接层T-Full1维度为512,T-Full2维度为256,T-Full3维度为128。激活函数采用不饱和非线性函 ReLUs(rectified linear units),该函数已被验证更接近人脑神经突触效果,具有更快的收敛速度[10]。其数学表达式如下
F(y)= max(0,y)
(3)
时间流设计的CNN网络结构如图2所示。

图2 时间流网络结构
时间流的输入为连续3帧的MHI运动历史图,输入shape为224×224×3。MHI是基于视觉的模板方法,根据一定持续时间内同一点的像素值变换,从而以图像亮度的形式来表示目标的运动情况。运动历史图中每一点的灰度值代表了在某段持续时间内该点位像素的最近运动状况,点位像素的灰度值高则表示该点位的运动时刻接近于当前帧。所以可以通过运动历史图来描述人体在摔倒过程中的动作状况。通过式(4)可算出MHI像素的强度值Hτ(x,y,t)
(4)
式中:(x,y)和t为像素点的位置和时刻;τ为设定的持续时间,相当于运动的时间范围;δ为衰退参数。ψ(x,y,t)为更新函数,可由帧间差法来定义
(5)
其中
D(x,y,t)=|I(x,y,t)-I(x,y,t±Δ)|
(6)
式中:I(x,y,t)表示视频序列第t帧中(x,y)像素点的强度值,Δ表示帧间距离,T为设定的阈值,可根据动作和视频场景的不同来设置。
在本文中动作持续时间τ设为1500 ms,阈值T设为32,实现的MHI效果图如下,其中图3一组为从站立到摔倒的连续3张运动历史图,图4为一组跟摔倒动作近似的从站立到坐下的连续3张运动历史图。

图3 从站立到摔倒动作运动历史

图4 从站立到坐下动作运动历史
从图3和图4中可以发现,由于摔倒的加速度更快,所以在相同的持续时间内,从站立到摔倒的运动历史图比从站立到坐下幅度更大,且越远离当前时刻,像素的灰度值越低,所以运动历史图可以很好地描述帧之间的运动信息。
1.3 模型融合
由图1可以看出,双流卷积神经网络有两个支路,分别用来提取时间特征和空间特征,最后是把两个网络的输出按一定方式关联到一起。对于跌倒动作,空间特征描述了人体在跌倒过程中某一刻的姿态以及人体宽高比、倾斜角度等,而时间特征描述了跌倒动作前后时刻的人体趋势变化。在文献[11]中,作者采用的是分别训练时间流和空间流网络,最后将两个网络的Softmax层的输出做了加权融合,时间流权值取2/3,空间流权值取1/3。即
(7)
R表示双流网络的输出结果,R1表示空间流的Softmax输出,R2表示时间流的Softmax输出。
本文对以上融合方式做了一定改进,没有选择在两个网络的激活层输出进行融合,而是在两个网络的全连接层将两个网络的同shape张量Concatenation相连后再添加新的网络层,并通过多组实验分别比较了在不同维全连接层Concatenation融合的准确率以及在相同维全连接层采用其它融合方式比如平均融合和Maximum融合的准确率比较,从而以找到最优结果,两个网络Concatenation融合后的输出结果为
R=Fcat(R1,R2)
(8)
R表示融合后的输出结果,R1表示空间流的全连接层输出,R2表示时间流的全连接层输出,Fcat为Concatenation相连操作。因为全连接层具有更高层次的抽象和更友好的语义信息,从而可以通过神经网络的训练来学习和定义两个模型之间的对应关系。Concatenation相连后再添加新的网络层,最后连接Sigmoid层完成二分类。
2 实验与结果分析
2.1 数据预处理
本文选取公开的摔倒数据集Le2i作为实验数据集,该数据集包含Home、Office、Coffee room、Lecture Room这4种场景的视频,视频fps为25,分辨率为320×240,并且包含一个txt文件标注了每个视频开始出现摔倒和摔倒行为结束的帧的序号。
首先对每个视频提取出人物轮廓RGB图和运动历史图,然后将所有的图片大小统一为224×224后分别存储到对应目录下。由于摔倒行为数据偏少,所以对摔倒数据做了简单的增强处理,对每张摔倒的RGB图和MHI图进行水平翻转,使数据集扩大了两倍,然后将摔倒的数据标签记为1,非摔倒数据的标签记为0。另外由于视频有些画面没有人物出现或人物静止,会导致运动历史图为纯黑色,为减少过多的这类图片特征的干扰,对纯黑色的MHI图进行了随机剔除。最后将摔倒行为和非摔倒行为的数据分别选取70%作为训练集,20%作为测试集,10%作为验证集。
2.2 模型训练
本文实验环境选择keras深度学习框架,使用随机梯度下降法,初始学习率设定为0.01,动量参数(momentum)为0.95,学习率衰减值(decay)为0.001,批次大小(batch size)设置为24。训练集的准确率如图5所示,loss损失值如图6所示。可以看出训练70个epoch后模型基本收敛,准确率在训练集上接近100%,损失值接近于0。

图5 准确率

图6 损失值
2.3 结果对比与分析
结果对比采用3个指标对模型的性能进行评估,分别为召回率(R)、精确率(P)、准确率(acc),分别定义如下
(9)
(10)
(11)
其中,TP表示将摔倒预测为摔倒的数量,FN表示将摔倒预测为非摔倒的数量,FP表示将非摔倒预测为摔倒的数量,TN表示将非摔倒预测为非摔倒的数量。
将测试集数据输入到训练得到的摔倒检测模型中,首先对MobileNetV2模型输入人物轮廓RGB和输入原始RGB的准确率比较,见表2。
从表2可以看出MobileNetV2输入人物轮廓RGB比输入原始RGB准确率提高了5.26%,且输入原始RGB的召回率比输入人物轮廓RGB低了15.96%,即存在很多摔倒了但未检测到的情况,这对于独居老人的跌倒检测问题是非常严重的,所以提取人物轮廓可以有效消除背景对跌倒检测的干扰,提高检测准确率。

表2 模型性能对比/%
然后对输入人物轮廓RGB的单流MobileNetV2模型、输入MHI的单流CNN模型以及采用相同数据集的文献[11]模型与本文双流卷积模型进行比较,其中文献[11]采用的是双流卷积模型,该模型将RGB帧输入3D-CNN,并提取光流图输入至VGGNet-16,融合方式是在两个网络的Softmax层输出做了加权融合,时间流权值取2/3,空间流权值取1/3,性能指标的对比见表3(文献[11]未给出精确率和召回率)。
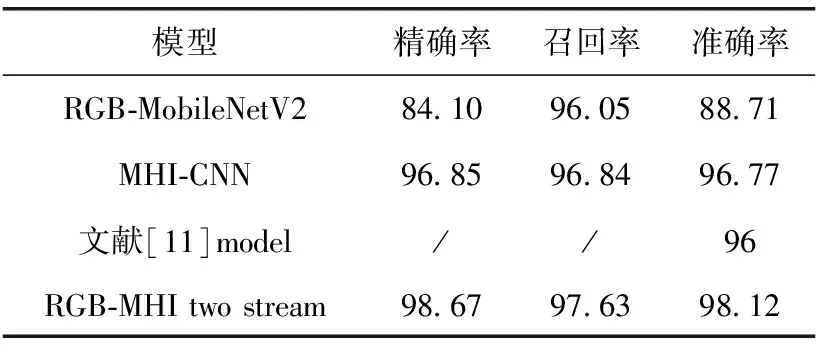
表3 模型性能对比/%
从表3可以看出本文的双流卷积模型在测试集上的准确率为98.12%,比文献[11]的准确率提高了2.2%,且精确率和召回率指标都比单流的模型要高,比空间流提高了9.41%,比时间流提高了1.35%。综上可以得出,双流卷积神经网络比单流的卷积神经网络对于跌倒行为检测准确率更高,且本文设计的双流卷积神经网络相比文献[11]的模型在跌倒行为检测中更具可靠性和有效性。
接下来本文对不同的融合位置和融合方式做了多组实验对比。首先是在不同维度的全连接层Concatenation融合时空特征与在Softmax层平均融合和加权融合的模型指标进行对比,见表4。
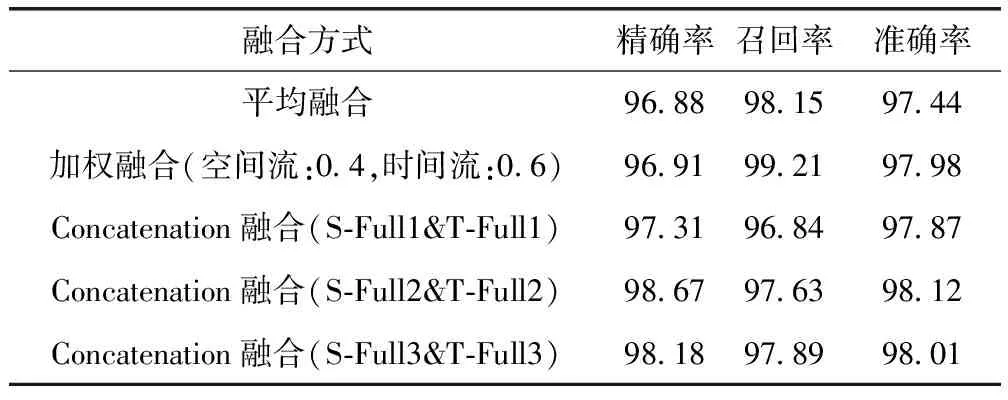
表4 融合方式对比/%
从表4可看出在空间流的Full2层和时间流的Full2层即在两个网络的256维全连接层进行Concatenation融合的准确率最高,为98.12%,其中与表4的第一、第二组实验对比可看出,两个网络在256维全连接层Concatenation融合比在Softmax层平均融合和加权融合的准确率分别高0.68%和0.14%,同时,从上表还可以看出采用平均融合和加权融合方式的召回率指标非常高,但精确率偏低,这是由于这些模型很容易产生误判,将数据集中躺下、坐下动作误判为摔倒。因此,将Softmax层的输出进行融合与在256维全连接层进行Concatenation融合相比,在256维全连接层融合能提取到对跌倒行为更深层次的信息。与表4的第三、第五组实验对比可看出两个网络在256维全连接层Concatenation融合比在512维全连接层和128维全连接层Concatenation融合效果要稍好。
针对两个网络的256维全连接层特征具有更好的表达信息,本文又比较了在256维全连接层分别采取平均融合和Maximum融合的准确率比较,见表5。

表5 256维全连接层融合方式对比/%
由表5可看出在256维全连接层采用Concatenation融合比采用平均融合和Maximum融合的方式准确率都要高。
同时本文对输入MHI和文献[11]采用的输入光流图的实时性进行了对比。采用上述相同的网络结构,空间流输入不变,时间流输入由连续3帧MHI图改为连续3帧光流,GPU为GTX960,如图7所示。

图7 连续3帧的MHI和连续3帧的光流
得出连续10次的检测速度,使用fps进行衡量。由表6可看出使用MHI运动历史图的平均fps达到33.5 Hz,比光流图要高13 Hz。由于我国采用PAL制式,而PAL制式的帧速率为25 fps[12],所以基于此网络结构时间流输入MHI运动历史图能满足实时性要求,而输入光流图没有达到。

表6 MHI、光流图检测速度fps对比/Hz
3 结束语
本文构建了一种基于双流卷积神经网络的实时跌倒检测模型,该模型的空间流输入为提取人物轮廓的RGB单帧,相比输入原始RGB,提取人物轮廓能减少背景造成的干扰,采用MobileNetV2模型处理,时间流输入为连续3帧的MHI运动历史图,采用搭建的CNN模型,改进了融合方式,在特定维度的全连接层将两个网络的同shape张量Concatenation融合后再添加到新的网络层,相比直接在Softmax层融合,全连接层具有更高层次的抽象和更友好的语义信息,最后在公开的摔倒数据集上进行了测试。实验结果表明,采用人物轮廓RGB-MHI的双流卷积神经网络在非摔倒和摔倒的区分检测中准确率为98.12%,比人物轮廓RGB的MobileNetV2模型提高了9.41%,比MHI的CNN模型提高了1.35%,模型优于其它采用相同数据集的文献;在256维全连接层Concatenation融合时空特征与在其它维全连接层Concatenation融合相比,准确率最高,比在分类层进行平均融和和加权融合识别率分别提高了0.68和0.14个百分点;基于此网络结构通过比较fps,输入MHI比输入光流图具有更好的实时性,验证了本文的双流卷积模型具有良好的可靠性和实时性。
猜你喜欢
中小学校长(2022年7期)2022-08-19
北京航空航天大学学报(2021年9期)2021-11-02
冶金设备(2020年2期)2020-12-28
装备制造技术(2020年1期)2020-12-25
高原山地气象研究(2020年3期)2020-07-16
制造技术与机床(2019年11期)2019-12-04
中小学校长(2019年10期)2019-11-07
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国交通信息化(2017年4期)2017-06-06
