
基于Rasch模型的力概念量表质量分析
2021-09-16 08:16胡象岭
物理教师 2021年8期
潘 澎 胡象岭
(曲阜师范大学物理学系,山东 曲阜 273165)
1 引言
力概念量表(Force Concept Inventory,简称FCI)是由美国学者David Hestenes等人以力学诊断测验(Mechanics Diagnostic Test,MDT)为基础开发的运用于教学和研究的测试工具,用于评估学生对牛顿力学最基本概念的理解,包括29个测题,内容涉及运动学、牛顿第一定律、牛顿第二定律、牛顿第三定律、力的叠加原理、力的种类6个方面,发表于1992年.[1]经Ibrahim Halloun等人修订的版本,包括30个多项选择题,1995年发布.[2]FCI是广为人知且应用广泛的力学概念测验,已成为物理教育研究领域的重要诊断工具.[3]
在我国物理教育研究领域,有研究者使用FCI对我国学生进行测评,被试涉及初中生、高中生、大学生.2000年曲亮生等运用1992年版FCI对我国中学和大学不同层次的学生进行了小范围测试,并与美国的测试结果进行了对比.[4]2004年王春风等采用FCI对165 名高一学生进行了测试,运用集中度分析法定量分析学生选项的集中程度,揭示学生在学习力和运动这部分内容时的认知模式和错误认识.[5]2011年李正福等以FCI 问卷为工具对90名刚学习完高一力学内容的藏族高一学生进行测试,以了解学生掌握力学知识的情况.[6]2011年张轶炳等以宁夏大学和美国俄亥俄州立大学的理工科学生(各180名)为样本,以FCI测试成绩为依据,比较了中美大学生的测试成绩,并对中美大学生力学概念理解的差异进行了分析.[7]2018年吴维宁等在传统教学与互动参与式教学的对比实验中将FCI作为前后测的测评工具以检验概念转变的效果.[8]还有研究者以FCI为工具考察教师对力学概念的理解情况.在曲亮生等人的研究中,考察了44名初中教师、37名高中教师在FCI测试上的表现.[4]2007年李光蕊等以FCI为工具,以166名初中和高中物理教师为被试,考察了我国中学物理教师对力学相关概念的掌握情况.[9]
测评工具的质量检验是教育测评的一个重要环节,然而,在我国物理教育研究中,中文版FCI虽然常被作为评估学生牛顿力学知识理解情况的测试工具,却鲜见其信度与效度等测量学指标的检验报告,至今只见到吴维宁采用Rasch分析方法对其进行的评估.[10]吴维宁的研究以820名学生(其中大学一年级学生253名,高一学生267名,初二学生200名)为被试,运用怀特图(Wright Map)、气泡图(Bubble Chart)等初步分析了学生能力分布与试题难度分布的适切度、测试数据的拟合度,研究结果显示,总的看来,FCI的适切性与拟合度指标较好,但也存在有待改进的问题.
本研究以中学生为被试基于Rasch模型对中文版FCI 的测量学特征进行较为全面的检验,以评估中文版FCI的质量,为今后进一步修订和完善该测试工具提供测量学依据.本研究所使用的中文版FCI,是以美国AAPT官方网站建议的中文简体版(即北京师范大学郭晨跃翻译的1995版FCI)为基础修订而成,修订的内容为题目的表述,修订的原则是题目的表述既要符合英文原版的命题意图又要符合我国物理题目的表述习惯.[2]
2 研究方法
2.1 被试
本研究的被试是已经完成初中力学知识学习的9年级学生和已完成高中阶段力学知识学习的高二年级学生.在曲阜市城区各选一所初中和一所高中,在两个学校各随机选取两个班进行测试.共发放测试卷172份,收回172份,剔除无效答卷后,得到有效答卷149份.有效被试中,男生73人,女生76人.有效初中生被试71人,男生35人,女生36人.有效高中生被试78人,男生38人,女生40人.
2.2 研究工具
Rasch模型最早是由丹麦数学家Georg Rasch提出的用来测量潜在特质的概率模型.[11]根据测量的数据类型,可以把Rasch 模型分为二分模型、部分给分模型和等级量表模型;根据维度的多少,可分为单维模型和多维模型;根据参数估计数目不同,可分为两面模型和多面模型.
根据二分Rasch模型原理, 特定的被试对特定的项目作出特定反应的概率可以用被试能力与该项目难度的一个函数来表示.被试回答某一题目正确与否取决于被试能力和题目难度之间的比较.Rasch 模型具有被试与题目共用标尺、线性数据、参数分离等特点,从而确保了客观测量的实现.[12]
Rasch分析方法已成为教育测评工具质量分析的重要手段.[13]本研究采用二分Rasch模型评估中文版FCI的质量.
本研究利用Winsteps3.72.0软件进行Rasch分析.测试结果采用二级计分方式,回答正确计为1,回答错误计为0.将测试数据转化为符合软件运行要求的txt格式的记事本文件,编制程序文件,运行Winsteps3.72.0进行数据处理.输出结果包括整体质量检验结果、怀特图、数据与模型拟合统计、气泡图等.
3 研究结果
3.1 整体质量检验
对149名被试30个项目数据进行整体质量检验,结果如表1所示.

表1 整体质量检验结果
从表1看出,学生能力平均值为0.23,与项目难度相差不大(Rasch模型中通常将项目难度平均水平设为0),表明测验整体上能较好地匹配学生的能力水平.
Outfit MNSQ(OMNSQ)和Infit MNSQ(IMNSQ)是Rasch分析程序报告的两个拟合统计量,前者是未加权均方拟合统计量,后者是加权均方拟合统计量,ZSTD统计量表示拟合统计量的显著性.MNSQ的期望值为1,取值范围为(0,∞),一般认为其值在0.5-1.5 之间表示数据与模型拟合程度可接受;理想拟合情况下ZSTD 值为0,当其值介于-2-2 时,认为拟合较好.从表1可见,被试和题目的拟合度指标均接近理想值,拟合程度好.
一般认为分离度指数超过2较好,本研究中的被试、项目分离度(Separation)分别为2.83、3.45,表明测验能较好地区分被试的能力.
信度(Reliability)的理想值为1,大于0.7 表明测验信度较高,0.6~0.7 表明信度良好.本研究中的被试信度为0.89,试卷信度为0.92,信度较高.
3.2 题目难度与被试能力分布的匹配检验
Rasch模型通过对数转换,将被试能力与试题难度转换成等距的Logit放在同一标尺上进行标定,形成项目——被试图(即怀特图),它可以直观地表征被试与项目之间的匹配情况.
怀特图如图1所示.中间竖线表示Logit 刻度尺,标尺上的M表示平均水平(Mean),S表示距离均值一个标准误(One Standard Error),T表示距离均值两个标准误(Two Standard Error).最左端数字是用于对比被试能力水平和题目难度的Logit 量尺值,自下而上Logit 值增大,表示被试能力水平升高、题目难度增加.标尺左边表示被试能力水平分布,一个“X”代表一个被试.标尺右边是试题的难度分布情况,编号代表了不同的题目.被试之间的距离代表了被试之间的能力差异,试题之间的距离代表了试题之间的难度差异.在怀特图中,理想的分布情况应该是:不同难度的题目均有能力水平与之对应的被试,且在被试分布相对密集之处对应的题目数量相对较多.

图1 怀特图
由图1可见,被试能力水平的平均值M略高于题目难度均值M,但比较接近,说明测试的整体难度适当.这与前述整体质量检验的结果是一致的.被试能力水平分布范围大约为6.5个Logit,分布形态大致为双峰分布.
题目难度分布范围大约为5个Logit,难度最大的题目是第23题,最小的是第1题,除第1、23题外,其他题目均分布在距均值两个标准误之内,题目的难度分布形态较为合理.但个别题目间难度差异较大(如第1题与第16题之间).
从分布的对应情况看,题目难度分布与被试能力分布的形态差异较大,高水平被试没有与之相对应的题目,题目的难度分布没有覆盖所有水平的学生.
3.3 测量数据与Rasch模型的拟合检验
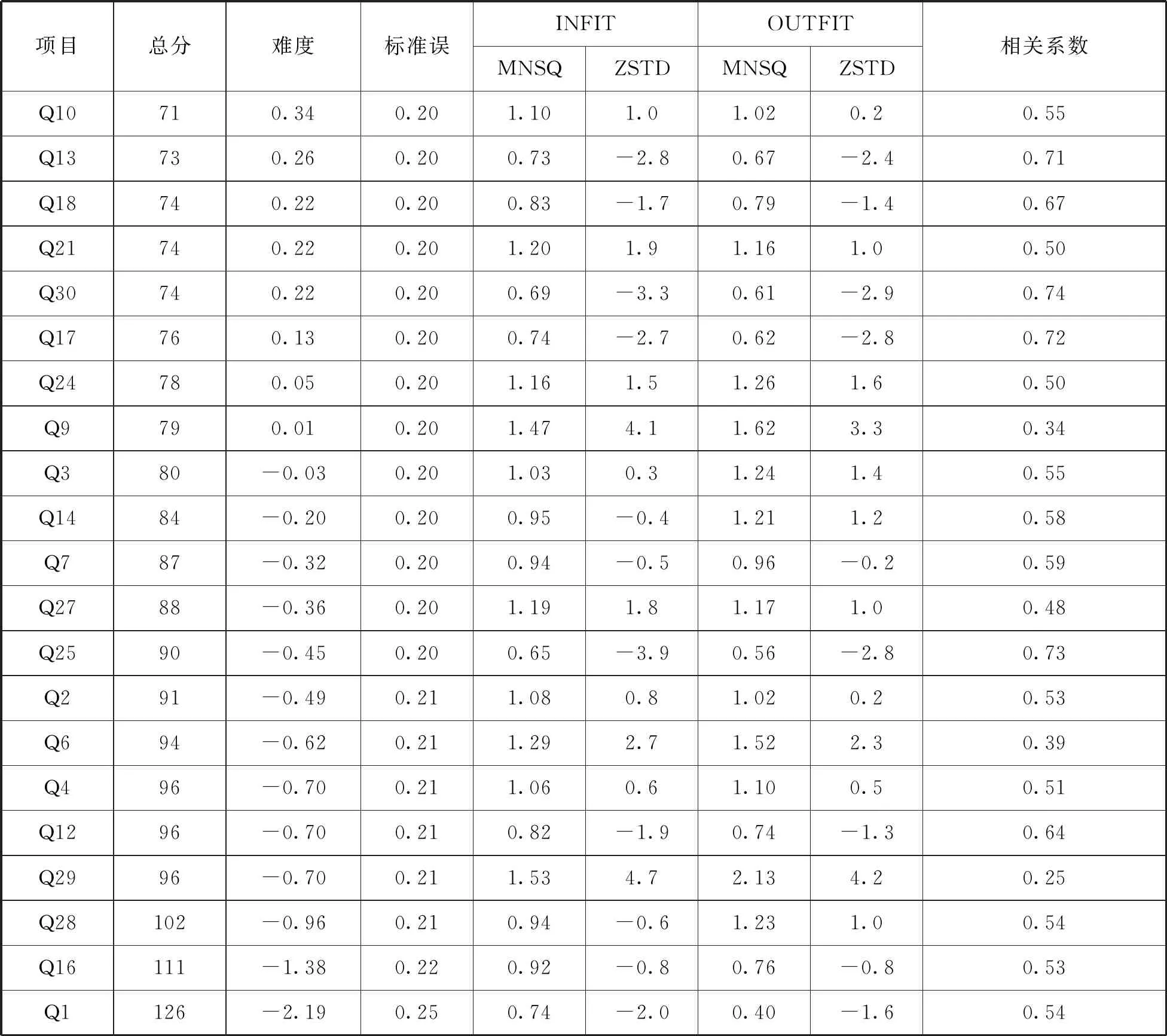
每个题目与Rasch模型的拟合情况如表2所示,包括难度估计值(measure)、标准误(S.E.)、infit和outfit的残差均方拟合指标(MNSQ和ZSTD)以及相关系数(CORR.).Infit MNSQ和outfit MNSQ的范围在0.5-1.5内表示拟合较好,小于0.5为过度拟合,大于1.5为欠拟合.标准误表示测量的误差,标准误越小,说明试题对被试的测量越稳定,题目的信度也就越高.相关系数表示题目与测量目标相关程度,相关系数越大,说明该题目与测量目标越相关.
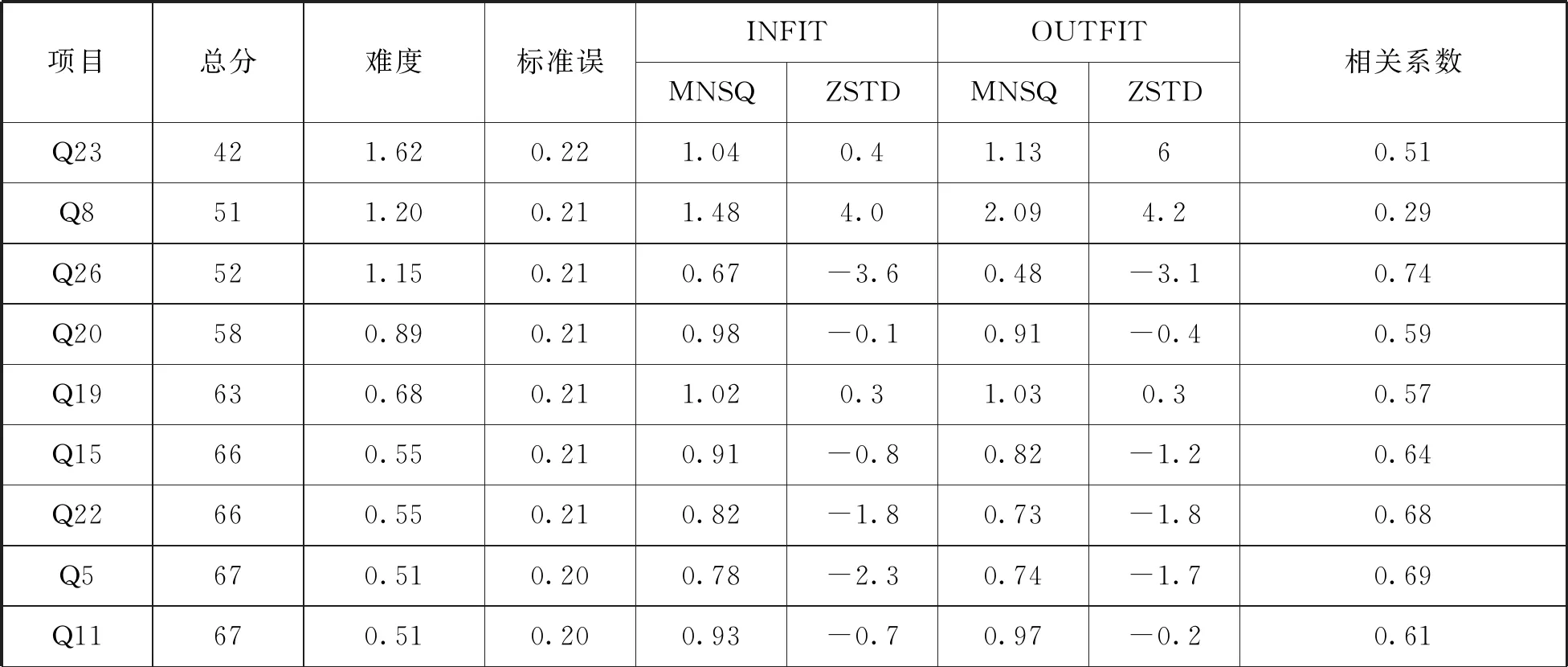
表2 每个题目的测量数据与Rasch模型的拟合情况
续表
表2中按题目难度排序,从上到下试题难度依次降低,第1题难度最小,第23题难度最大.
由表2可见,题目标准误均在0.2左右.Infit MNSQ在0.65-1.53范围内,除了第29题的Infit MNSQ为1.53略大于1.5外,其他各题的Infit MNSQ都在0.5-1.5的范围内.Outfit MNSQ在0.4-2.13范围内,除了第1、26题的Outfit MNSQ分别为0.40、0.46小于0.5,第6、9、8、29题的Outfit MNSQ分别为1.52、1.62、2.09、2.13大于1.5外,其他各题的Outfit MNSQ都在0.5-1.5范围内.相关系数在0.25-0.74范围内,与测量目标都是正向相关的,第29、8题分别为0.25、0.29,其他各题都大于0.3.
根据Rasch 拟合统计量使用时应遵循“均方统计量先于ZSTD统计量,未加权均方拟合统计量先于加权均方拟合统计量,不够拟合先于过分拟合”的原则,[14]结合相关系数的大小来判断,总的看来,拟合指标最差的是第29题,其次是第8题,再次是第9、6题.
气泡图可以直观地显示题目与模型的拟合程度和题目的测量误差,如图2所示.图中每一个气泡代表一个题目,气泡的大小代表标准误的大小,气泡越小则标准误越小,测量结果越准确.图中横坐标为未加权均方拟合统计量(Outfit MNSQ),左边表示欠拟合,右边表示过度拟合;纵坐标为题目难度的测量值(Measure),从下往上题目难度越来越大.
由图2可见,第1题难度最小,第23题难度最大.各个气泡的大小差异不大,表示各个题目的标准误相差不大.大部分题目拟合度在可接受范围内,但第8、29题的位置与其他题目明显分离,Outfit MNSQ值较大,即拟合较差.有部分气泡重合在一起,说明这些题目的难度和拟合指标接近.气泡图所展现的结论与表3相互印证.
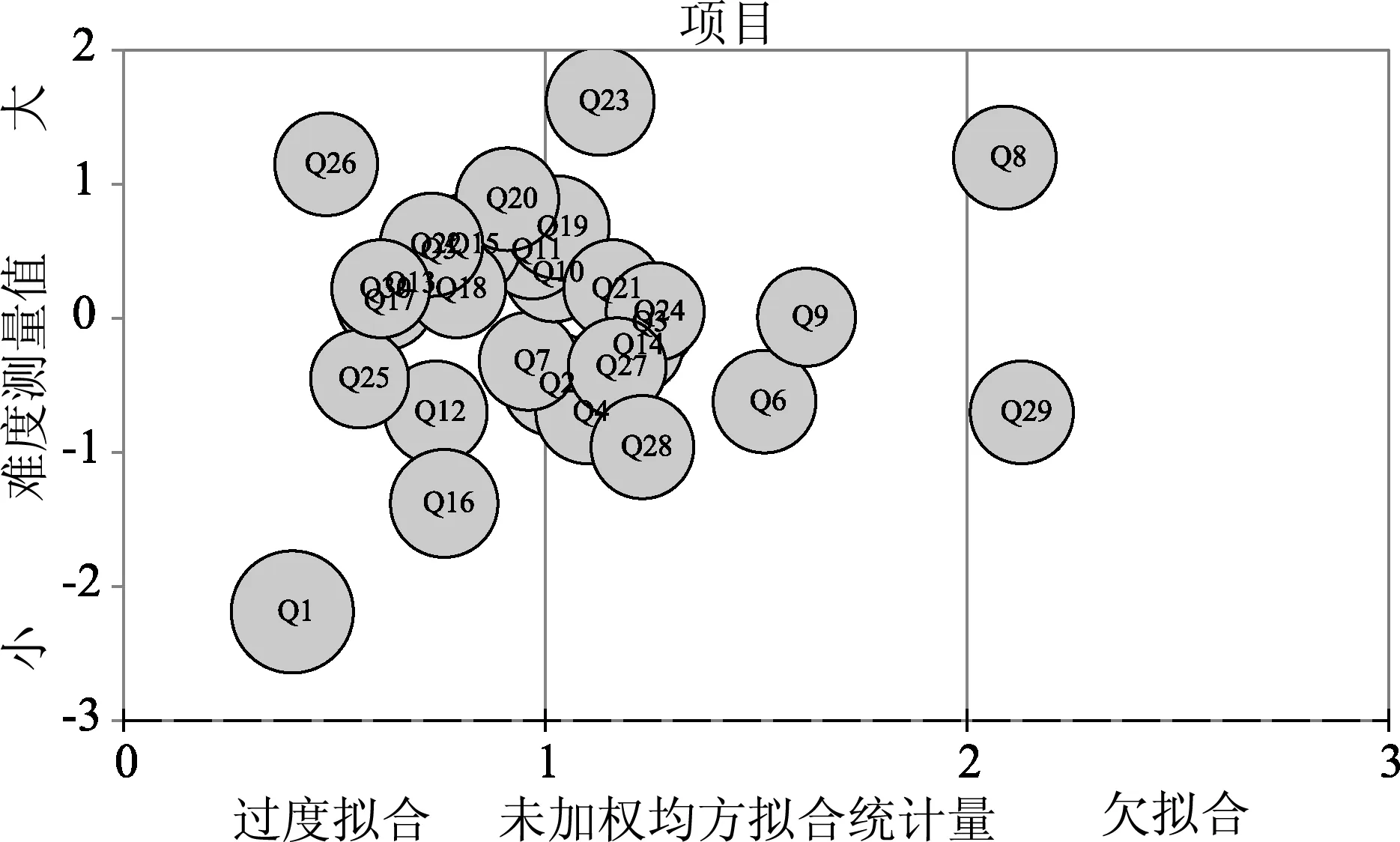
图2 气泡图
4 讨论
本研究的主要目的是检验中文版FCI的测量学特征,从研究的结果看,中文版FCI的测量学特征大部分比较理想,个别不理想.
从整体质量来看,对于中学生被试而言,测试的整体难度适当,拟合度较高,分离度、信度均较好.这就是说,总体看来FCI的质量是理想的.这一结果,在我国的研究报告中还没有见到.
从题目难度与被试能力分布的匹配情况来看,题目难度分布范围大约为5个Logit,难度分布形态较为合理,但个别题目间(如第1题与第16题之间)难度差异较大.题目难度分布与被试能力分布的形态差异较大,高水平被试没有与之相对应的题目,题目的难度分布没有覆盖所有水平的学生.出现这一情况,可能与本研究的样本有关,本研究的样本包括初中生和高中生,怀特图显示被试能力水平分布范围大约为6.5个Logit,分布形态大致为双峰分布.在吴维宁的研究中曾发现初中被试能力均值低于试题难度均值1.5个Logit,高中被试能力均值比试题难度均值高2个Logit.[10]这提示我们,FCI对我国初中生和高中生的适切性有待在更大样本中进一步检验.
从每个题目的测量数据与Rasch模型的拟合情况来看,大部分题目拟合较好,但第29、8、9、6题等题目的拟合度较差.这与吴维宁[10]的研究结果不尽一致,他的研究结果显示除第15题外其他题目的拟合指标都在理想范围内.这提示我们,有必要在今后的研究中进一步考察每个题目的质量.
本研究是基于Rasch测量理论采用Winsteps软件对中文版FCI的质量进行的初步考察,对该测试的测量学指标的考察并不十分全面,如测试的内容效度、结构效度、预测效度等还有待进一步检验.尽管如此,本研究的结果仍是有益的,为我们提供了FCI部分测量学指标比较理想的证据,但也提醒我们,FCI未必是一个很完善的测量工具,个别测题有待完善,测量学指标有待进一步检验.
客观地说,中文版FCI的信度、效度等测量学指标并没有在我国得到充分的检验,它却被不少物理教育研究者作为测量工具,这是我国物理教育研究中值得深思的一个现象.
猜你喜欢
数学年刊A辑(中文版)(2022年3期)2023-01-05
数学年刊A辑(中文版)(2022年1期)2022-08-20
数学年刊A辑(中文版)(2021年3期)2021-11-05
世界科学技术-中医药现代化(2021年7期)2021-11-04
新潮电子(2021年7期)2021-08-14
建材发展导向(2021年13期)2021-07-28
数学年刊A辑(中文版)(2021年1期)2021-06-09
儿童故事画报·发现号趣味百科(2019年9期)2019-02-02
统计与决策(2018年14期)2018-08-22
听力学及言语疾病杂志(2015年5期)2015-12-24
