
《国际中文教师证书》面试信度研究
2021-09-15 02:17李亚男王艾琳王之岭
华文教学与研究 2021年2期
李亚男 王艾琳 王之岭


[关键词] 《国际中文教师证书》面试;多侧面Rasch模型;信度
[摘 要] 面试是一种广泛应用的评价技术,面试的成绩受多方面影响。多侧面Rasch模型(MFRM)可对影响成绩的多个侧面(参数)进行分析,因而适用于面试的信度研究。本文对2019年某次《国际中文教师证书》面试中12位考官给128位考生在5个打分项上的分数进行了MFRM分析,研究发现:考官在面试打分过程中能够有效区分不同水平的考生;考官打分宽严度虽存在显著差异,但对考生打分不会产生决定性影响;考官自身打分一致性总体上处在可接受的范围,但也存在一定程度的趋中现象;考官在不同打分项上给出的分数存在显著差异,在“试讲”这一打分项上打分最严。
0. 引言
面试是一种人员评价技术,其考察方式直观、灵活,具有良好的效度,因而被广泛应用于各类人才选拔。吴志明等(1997)将面试定义为评委通过与考生面对面的交谈,或将后者置于一定情境中进行观察,从而了解、考察考生是否满足条件要求的一种人员评价技术。面试评价的过程是复杂而间接的:首先应试者对测量潜在知识结构或技能的项目或任务做出回答;然后评分者根据评分标准,按照对潜在结构的理解,对应试者的表现做出评价;最后,根据评分者的评分估计考生的能力(丁树良,罗芬,涂东波等,2012)。因而,面试成绩将受到评分者(考官)、试题(打分项)、评分标准等多种因素的影响,对测试信效度提出了更高的要求。
本研究使用多侧面Rasch模型对某次《国际中文教师证书》面试考官的打分数据进行分析,试图探究:考官在面试过程中能否有效区分考生能力?打分宽严度、评分标准、考试时间等因素对考官打出的分数会产生什么影响?这些影响考试信度的各因素之间是否有交互作用?希望通过以上问题的分析结果,为考官培训和考试改进等提供一点建议。
1. 研究背景
1.1《国际中文教师证书》面试
《国际中文教师证书》考试是由教育部中外语言交流合作中心主办的一项标准化考试。考试通过对中文教学基础、中文教学方法、教学组织与课堂管理、中华文化与跨文化交际、职业道德与专业发展等五个方面的考查,评价考生是否具备国际中文教师能力。考试包括笔试和面试两部分,笔试成绩合格者方能报名参加面试。笔试、面试均合格者,可获得证书。
面试着重考查考生综合运用各种方法设计教学方案、组织实施教学过程、完成教学任务以及用外语辅助教学的能力,同时考查考生的沟通交际、心理素质、教姿教态等基本职业素养。面试采用结构化面试和情景模拟相结合的方法,考生经过30分钟的准备后,需在25分钟内,根据试卷内容进行说课、试讲,并回答考官提出的问题。
面试采取考官小组评分的方式,每小组由三名考官组成,分别为主考官、考官和外语考官。所有考官均为具有多年教学经验、副教授以上职称或博士以上学历的高校教师,均参加过考前培训并通过了考核。面试过程中,考官小组按照统一的指导语、时间安排和标准化流程,根据试卷内容对考生进行提问,在“说课”“试讲”“中文问答”“外语水平”和“总体印象”等5个打分项上给考生表现进行打分。
1.2 多侧面Rasch模型
在一项面试中,为提高考试信度,开发者会使用多种方式,如随机匹配考生和考试题目、对考官进行考前培训、对同一考生进行多考官评分、报告成绩取多考官均值等。研究结果表明,经过培训,考官评分的内部一致性①会有所提升,但仍存在显著的宽严度②差异(丁树良,罗芬,涂东波等,2012;Weigle, 1998)。评分过程中,会产生一些考官效应,如趋中效应③、光环效应④及偏差⑤等(范鹏,2017;刘耀中,2009;张洁,2014;Myford & Wolfe,2003;Myford & Wolfe,2004)。因而,要提高面试的信度,就要对这些影响因素进行研究和处理。
多侧面Rasch模型(Many-Facet Rasch Model,以下简称MFRM),最早由Linacre在1989年提出,是单参数Rasch模型的延伸。单参数Rasch模型处理的测验情境中,只有被试特质参数和项目难度参数。而在面试中,考生在题目上得到某一特定分值的概率,不仅取决于考生自身能力的高低和题目难度的大小,也受到考官对评分标准的理解程度和评分宽严程度等因素的影响。MFRM在单参数Rasch模型基础上,引入了更多可能对考试成绩产生影响的参数(也叫侧面),如考官特质、评分标准等,因而更适用于面试的信度研究。
MFRM在分析某个侧面对考试成绩的影响时,能够剔除其他因素的影响,将此侧面的影响单独剥离出来,从而可以使研究者更好地理解每个侧面对考试成绩是如何产生影响的。在进行MFRM分析时,所有侧面的相关数据都会通过线性逻辑斯蒂克方程轉换到一个量表模型(scaling model)上,因而其估计出来的侧面值(如考生能力值、考官宽严度)是在一个等距量表上的,每个侧面值拥有相同的单位,可以相互比较。另外,MFRM还可以通过偏差/交互分析(Bias/Interaction Analysis)侦测各因素之间可能存在的交互效应,进而探究某个侧面在不同情境下对考试成绩的影响模式,如考官给不同性别的考生打分时的宽严程度变化。这将有助于提高考试的信度,让决策更加公平。
2. 研究方法
2.1 数据来源
MFRM分析要求相互比较的个体之间存在联结(Linacre,2012)。在本研究中,我们以不同评分小组中的同一考官作为联结点,选取同一考官给不同考生的打分数据,以达到比较多位考官、考生的目的。数据来源于2019年的某次面试,通过以共同考官为联结点的方式,抽取了符合MFRM分析要求的12位考官的打分数据,由这12位考官打分的考生共有128位,考官打分数据包括说课分、试讲分、中文问答分、外语水平分和总体印象分共5项。考官按类型分为主考官4人(编号为1A、2A、3A、4A)、考官4人(编号为1B、2B、3B、4B)、外语考官4人(编号为1C、2C、3C、4C),考生编号为1至128号。12位考官平均教龄为21.83年(SD=7.95),其中11位女性,1位男性。128位考生中包括女性115人,男性13人。抽取方案如表1所示,每一组考官都与其他组考官存在一个或以上的相同考官,如通过主考官3A,考官3A、4B、4C、1B、3C等5位考官可以相互比较,考生1-30号与45-58号共44位考生也可以相互比较。另外,一次面试通常会持续两到四天,考生是按事先抽签决定的时间段(批次)参加考试的,考官可以选择参加一天或者多天的面试,每天的面试时间约8小时(上午4小时,下午4小时),考虑到工作时长可能对打分产生些许影响,我们在收集数据时也收集了考官打分数据产生的时间。
2.2 数据处理
要探究面试过程中考官能否有效区分考生能力这一问题,在MFRM分析前我们定义了三个侧面,首先是“考生”侧面,每位考生会得到三位考官在五个打分项上给出的分数,通过这些分数可估计出考生能力值;第二个侧面是“考官”,每位考官在面试过程中会给多位考生打分,通过分析考官打出的所有分数,可得出每位考官自身的打分一致性、考官之间打分一致性、是否存在光环效应、以及不同考官之间的打分宽严差异;第三个侧面是“打分项”,考官会在说课、试讲、中文问答、外语水平和总体印象这五个打分项上给出分数,通过分析每个打分项上所有考官给出的分数,可以得到不同打分项的难易度(考官打分高低)。
将上述三个侧面的数据进行估值和模型建立,用到的计算公式如下:
目前,研究者在MFRM分析时使用较多的统计软件是Facets,本研究使用的是Facets 3.83.2① (Linacre,2020)。
3. 研究结果与讨论
本研究的结果分析和讨论主要从以下三个方面展开:一为总体分析,即三个侧面的总体分布情况,是数据的可视化、总结性表达;二为分侧面分析,分别从考生、考官、打分项三个侧面,进行侧面内的分析和讨论;三为交互分析,分析各个侧面之间的交互关系和不同情境对考官打分宽严度的影响。
数据分析结果包括两个主要部分:个体统计量和层面统计量。个体统计量主要包括度量值(measure)、拟合统计量(fit statistics)和拟合统计量转化而来的标准Z值(Z standard)。层面统计量主要包括分隔系数(Separation)、信度(Reliability)、层度系数(Stara)和卡方检验(chi-square)。除此之外,在考官侧面,还用到了评分者间一致性系数(Inter-rater)进行考官间一致性的分析。
3.1 总体分析
总体分析主要说明本研究定义的三个侧面在统一量表上的分布情况。如图1所示,第一列的“Measr”代表的是MFRM分析的度量值(measure),单位是“logits”,它是三个侧面的共同标准,每个侧面中的个体(如考生127号、考官3B)都在这个统一量尺上有确定的值。考生侧面的度量值代表考生的能力值,考官侧面的度量值代表考官的打分宽严度,打分项侧面的度量值代表打分项得分的难易度,也就是考官在这一打分项上给出分数的高低。每个侧面在MFRM分析中是有方向性的,可以正向发挥作用(用 “+”号表示),也可以反向发挥作用(用“-”号表示)。在教育领域中,通常的惯例是“能力为正向,其他方面为反向”(Linacre,2012)。据此,本研究中的考生侧面是正向的,考官和打分项这两个侧面是反向的。
考生能力值由大到小自上而下排列,位于最上方的127号考生能力值最高,位于最下方的84号考生能力值最低,考生的能力基本呈正态分布。考官打分宽严度由严至宽自上而下排列,考官3B位于最上方,说明他在评分过程中最为严厉,给考生的打分最低;考官1A和1C位于最下方,说明他们在评分过程中最为宽松,给考生打分最高。打分项根据考官给出的分数由低至高排列,“试讲”位于最上方,说明这一打分项最难,考官打分最严格,给出的分数最低;“总体印象”位于最下方,说明这一打分项最容易,考官打分最宽松,给出的分数最高。
3.2 分侧面分析
分侧面分析主要说明本研究定义的每一个侧面的内部情况,主要包括侧面内个体的度量值、个体的拟合统计量、每个侧面的层面统计量。在考官侧面,还包括评分者间一致性系数。分侧面将用到以下几个指标进行分析。
拟合统计量用于分析各侧面中的每个个体与模型之间的拟合程度。MFRM使用均方拟合统计量(Chi-square fit statistics)和标准Z值(ZStd)来表示数据和模型的拟合程度。拟合统计量包括加权均方拟合统计量(Infit Mnsq)和未加权均方拟合统计量(Outfit Mnsq),因后者更易受到个别值的影响,一般以前者作为判断个体是否拟合模型的依据(张洁,2014)。一般认为,0.5-1.5是Infit Mnsq的可接受范围。而对于高風险测试,应采取更严格的控制(Linacre,2012;孙晓敏、张厚粲,2006)。因此,本研究选用0.8-1.2的严格范围(Linacre,2012),Infit Mnsq大于1.2为不拟合,小于0.8为过度拟合。ZStd是由Infit Mnsq转化而来的符合正态分布的标准值。Linacre(2012)指出,|ZStd|≥2.6可作为数据与模型不拟合及过度拟合高度显著的指标。
层面统计量主要包括分隔系数(Separation)、信度(Reliability)、层度系数(Stara)和卡方检验(chi-square),用于分析该侧面中个体之间的差异大小。分隔系数(Separation)标志着测量分数整体的有效性,如果来自考生的真实变异与来自测量误差的变异相等,则分隔系数等于1(孙晓敏、薛刚,2008)。一般认为,分隔系数大于2,意味着个体间有明显差异(Myford & Wolfe,2004; Linacre,2012),数值越大,说明有越大的把握认为该层面个体之间存在显著的差异。信度(Reliability)说明了在总观测变异中真实变异所占的比例(孙晓敏、张厚粲,2006)。信度值的取值范围在0到1之间,越接近于0,说明该侧面个体之间差异越小;越接近于1,说明该侧面个体之间差异越大。通过分隔系数可以把侧面内的个体分成几层,用层度值(Strata)表示,其计算方法为Strata=(4*Separation+1)/3(Myford &Wolfe, 2000)。卡方检验(chi-square)用于统计样本的实际观测值与理论推断值之间的偏离程度,数值越大,说明有越大的把握认为该层面个体之间存在显著的差异。
评分者间一致性系数(Inter-rater)包括Exact Agreement Expected %(以下简称Expected %)和Exact Agreement Observed %(以下简称Observed %),其中Expected %是MFRM估算出的、在每个考官都独立打分的情况下,考官组之间的一致性评分占所有评分的比例; Observed %则是考官组在实际打分过程中所出现的一致性评分在所有评分中所占的比例。如果Observed %与Expected %数值相近,则说明在打分过程中考官是独立打分的。如果Observed %数值高于Expected %数值,则说明考官在打分过程中有意与其他考官达成一致(Linacre,2012)。
3.2.1 考生侧面
考生侧面代表的是考生的能力水平,在MFRM分析中是正向的。如表2所示,样本中能力值最高的考生为127号,其度量值为1.20 logits,84号考生能力值最低,度量值为-1.44 logits,考生的能力跨度为2.64 logits。考生侧面的分隔系数为4.48,信度值为0.95,卡方值为2435.4,接受各考生能力度量值在统计上全部相同这一假设的概率p<0.001。这说明考分的差异具有显著意义,且该差异绝大部分可由考生的被考查能力得到解释。从考官打分角度说,就是考官能够区分考生的能力水平。考生侧面的层度值为6.30,说明考生能力水平最少可分为6级。
从考生个体的角度来看,|ZStd|≥2.6的考生有23位,其中12人的Infit MnSq高于1.2,表现为不拟合,11人的Infit MnSq低于0.8,表现为过度拟合。不拟合的原因一方面可能跟不同考官对同一考生的评分不一致程度高有关,另一方面可能是由于不同打分项测查的是作为一名合格的国际中文教师在不同方面的能力,而考生在不同方面的能力水平并不一致。过度拟合则说明考官给考生的评定过于一致,可能有考官间一致性过强或评分趋中的问题。后面我们还将分别对考生和考官、考生和打分项进行偏差/交互分析,寻找考生数据不拟合的原因。
3.2.2 考官侧面
面试的主观性使得多个考官之间的评分一致性成为面试理论和实践中长期关注的一个重要问题。经典测量理论中的评分者信度只能提供多个考官之间的一致性信息,而MFRM则可以对考官个体的宽严程度、自身评分一致性、与其他考官的一致性、与各因素之间的交互/偏差等多个角度进行分析。以下将从考官的打分宽严度、自身一致性和考官间一致性进行分析。
考官侧面代表的是考官打分情况,在MFRM分析中是反向的。从表3的考官度量值可以看出考官打分宽严度,考官3B打分最严,其度量值为0.17 logits, 考官1A打分最松,其度量值为-0.20 logits。考官侧面的分隔系数为3.45,信度为0.92,卡方值为125.9,接受考官的评分宽严程度在统计上全部相同这一假设的概率p<0.001。这说明考官打分的宽严度有显著的差异。考官的宽严跨度为0.37 logits,考生能力跨度(2.64 logits)是考官宽严跨度的7.14倍。通常认为,考生能力跨度在考官宽严跨度4倍以上时,考官在宽严度上的差异总体上不会对考生的成绩产生决定性的影响(何莲珍,张洁,2008;张新玲,曾用强,2009)。所以,虽然此次考官打分宽严度有显著差异,但不会对考生成绩造成太大影响。
考官打分的自身一致性可依据Infit MnSq值进行分析,这里的“一致性”并不是指不同考官之间需要达成相互一致,而是指某一位考官是否能够对所有考生保持稳定的打分宽严程度。如表3所示,从考官个体角度来看,|ZStd|≥2.6的考官有4位,其中2A、3B两位考官的Infit MnSq高于1.2,表现为不拟合,说明他们在打分过程中自身稳定性较差;3A、4B两位考官的Infit MnSq低于0.8,表现为过度拟合,说明他们在打分过程中给出的分数差异太小,存在一定的趋中性,也许是采用了“安全策略”,在打分过程中仅仅使用了少数几个等级分数对不同表现的考生进行评分。
除了考官自身一致性,我们又根据三人考官小组对同一批考生的打分情况分析了考官间评分的一致性,结果如表4所示。
表4为考官组(分组情况见表1)内的三位考官之间的评分一致性系数,第三列为Expected %,即MFRM估计的独立打分时的一致性打分占比,第四列为Observed %实际打分中的一致性打分占比,第五列为前两列差值。从中可以看出2、3、5、7组的Observed %值均比Expected %值高百分之十几,这与考官在面试中并不是完全被要求独立打分的情况相吻合。根据打分要求,考官在打分过程中可以对考生的表现进行一定程度的讨论,因而Observed %值往往会高于Expected %值。同时,如表3所示,这几组的考官也大都表现出了稳定的自身一致性。第4组和第6组考官的Observed %均与Expected %数值相近,说明这两组的考官在打分中偏向于独立打分,但也有可能是与2A、3B两位考官打分过程中自身稳定性较差有關。第1组考官的Observed %值远大于其Expected %值,差值达到了40.3%,远远大于其他组,这可能与3A、4B两位考官打分过程中存在一定的趋中性有关。第4组和第6组体现出来的打分独立性和自身稳定性之间的因果关系,有待进一步讨论,可能是由于考官们未按照要求进行一定程度的讨论导致考官评分稳定性较差,也可能是评分不稳定的考官无法与评分稳定的考官达成一致,因而使评分者一致性系数呈现出独立打分的状态。第1组考官打分也是如此,可能是考官间的过度讨论使得组内考官均给出了趋中性的打分,也可能是由于三位考官各自打分的趋中性使得组内评分者一致性系数过高。未来可针对此问题进行进一步研究。
3.2.3 打分项侧面
打分项侧面代表的是各打分项的难易度情况,也就是考官在不同打分项上的打分高低情况,在MFRM分析中是反向的。根据表5所示,在排除了不同考官宽严程度差异、考生能力差异的影响后,考官打分最严格的是“试讲”这一项,度量值为0.26 logits,最宽松的是“总体印象”这一项,度量值为-0.14 logits。打分项侧面的总体跨度为0.40 logits,分隔系数为5.70,信度为0.97,卡方值为308.5,接受各打分项的难度在统计上全部相同这一假设的概率为p<0.001,说明考官在“说课”“试讲”“中文问答”“外语水平”“总体印象”这五个打分项上的宽严程度有明显差异,“试讲”最严格,其次是“外语水平”“说课”和“中文问答”,考官对“总体印象”这一项的打分偏慷慨。
打分项侧面的Infit MnSq值代表了某打分项的考官打分一致程度,从表5可以看出,“说课”和“总体印象”的|Zstd|≥2.6,Infit MnSq低于0.8,表现为显著的过度拟合,说明考官在对这两项打分时存在过度一致的情况,这可能与“说课”的程式化和“总体印象”比较容易趋中性给分有关。“中文问答”的|Zstd|≥2.6,Infit MnSq高于1.2,数据呈现显著的不拟合,说明考官在这一打分项存在较大分歧,这可能是考官对“中文问答”的评分细则的理解和尺度把握不同有关,也可能是由于考官对这一部分参考答案的理解和侧重有所不同所致。“试讲”“ 外语水平”这两项则拟合较好,说明考官在这两个打分项上总体来讲能恰当地把考生水平区分开。
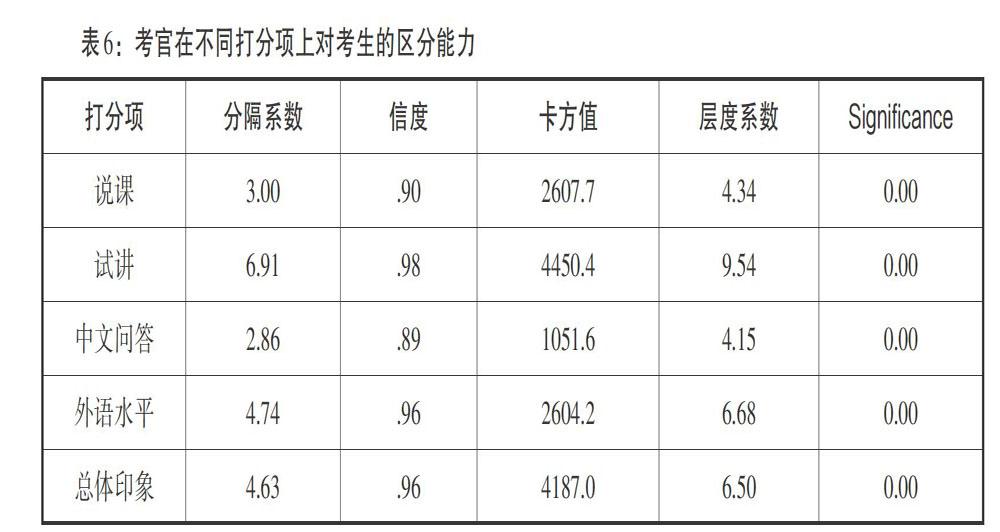
为进一步探究考官在每个打分项的打分质量,我们又分别计算了考生在这五个打分项上的分隔系数和信度,以考察考官在不同打分项上对考生的区分能力如何。如表6所示,在各打分项上接受考生能力度量值在统计上全部相同这一假设的概率p均小于0.001,也就是说,每个打分项上考生的差异均具有显著意义,且该差异绝大部分可由考生的被考察能力得到解释,这就说明考官在所有打分项上均能有效地区分考生能力。考官在“试讲”这一项上至少能将考生能力水平分为9层,区分能力最强;在“外语水平”和“总体印象”这两项上均可以将考生能力水平分出6个以上的层次,区分能力较强;在“说课”和“中文问答”这两项上将考生能力水平都是仅分为4个层次,区分能力相对较弱。“说课”的区分能力较弱可能与前文提到的“说课”具有较强的程式化有关,“中文问答”的区分能力较弱的原因,我们将在后面的偏差分析中进一步讨论。
3.3 偏差/交互分析
在用MFRM进行考试信度研究时,实际考试数据若完全符合假设,则与模型出现不拟合的偏差应该是完全随机的,但在实际面试中各侧面是极可能发生交互作用的,从而导致实际考试分数偏离模型预测的分数。这就有必要通过偏差分析来找到各侧面的偏差所在,相当于进行项目功能差异(differential item functioning, DIF)研究,并通过交互分析来找到各侧面之间的交互关系。本研究分析了考生、考官和打分项三个侧面之间的交互关系,并关注了考官在考生性别、考试时间等两个情境下是否会产生系统性的打分宽严度变化。分析结果如表7所示。
考官和考生之间显著偏差的数量为1,占所有交互总数(384)的0.26%。除考官3C在给119号考生打分时出现了与往常打分宽严略有不同的情况之外,无其他偏差情况。根据McNamara(1996)的观点,显著偏差占比在5%以下,属于可接受的范围。关于测量误差的假设检验p=1.00,说明此次偏差很可能是偶然情况。也就是说,总体上考官能够有效、一致地区分不同能力考生,不存在偏差。
考官和打分项在交互总数为60的情况下,显著偏差为11个,占到了18.3%,大于McNamara提出的5%的范围。关于测量误差的假设检验p<0.001,说明偏差并非偶然产生。在11个显著偏差中,“中文问答”的偏差占到了6个。结合表6的打分项分隔系数和层度系数看,“中文问答”的分隔系数、层度系数均相对较低,说明考官在打分项上的给分确实存在偏差。这可能是由于评分细则的可操作性不足,或考官对参考答案的理解有偏差所致。另外,在分析考官和打分项交互作用时,我们还会综合考官侧面数据来检查考官打分是否存在光环效应。如果考官侧面的Infit MnSq小于1且Outfit MnSq大于1,同时考官与打分项的交互作用显著,则可认为存在光环效应(Myford& Wolfe,2004;Farrokhi & Esfandiari,2011)。虽然这里考官和打分项交互作用显著,但表3所示的考官侧面数据中却没有Infit MnSq小于1且Outfit MnSq大于1的情况,所以还是可以说明考官在打分过程中并不存在光环效应。
考生和打分项在交互总数为640的情况下,显著偏差为108个,占到了16.9%,大于McNamara提出的5%的范围。关于测量误差的假设检验p<0.001,也说明偏差并非偶然产生。显著偏差中,除“总体印象”的偏差数量较少外,其余打分项偏差数量较多,且分布较平均。这说明考生在各打分项所代表的国际中文教师应具备的各方面能力上,水平发展并不均衡,而由于“总体印象”的给分是在综合考量其他4个打分项基础上给出的分数,且考官在打分时可能会存在较大趋中性,因而显著偏差较少。
在考官和考试时间、考官和考生性别之间的偏差/交互分析中,都没有发现显著的差异,即考官的打分宽严度不会随着工作时间长度的变化产生一致的变化趋势,考官在给不同性别的考生打分时也不会产生一致的变化趋势。对考生而言,不论他们在一天中的哪个批次参加面試,也不论他们是男性还是女性,考官都能够一视同仁地根据他们的面试表现进行打分,考生得到了公平的对待。
4. 结论
此次MFRM分析结果表明:在该次面试中,考官能够有效地区分不同水平的考生,考官的打分宽严度存在显著差异,但该差异不会对考生成绩产生决定性的影响;考官打分的自身一致性总体上处在可接受范围,存在一定程度的趋中现象;大部分考官小组内部的三位考官之间打分一致性略高于独立打分时的一致性,与考试打分流程要求相吻合。考官在不同打分项上对考生的区分能力存在差异,在“试讲”这一项上打分最严,对考生水平的区分效果最好,在“总体印象”这一项上打分最慷慨,但也都能够较好地区分考生水平;考官在评分时不存在光环效应,基本做到了性别公平,打分稳定性不受考试时间的影响。
本次研究發现可为考官培训和考生能力培养了提供了一些参考意见。部分考官的打分一致性不高,在面试评分标准、细则以及试题参考答案的理解和把握上存在一定程度的偏差,不能在打分过程中有效区分考生能力水平。为改善这一状况,一方面需要对考官有针对性地加强考前培训和考后反馈,另一方面需要考试开发者对评分标准和试题参考答案等进行一定的调整和优化。根据考生和打分项的偏差分析结果显示,考生在国际中文教师能力的各个方面上发展并不均衡,可有针对性地加强提高相应能力的培养,尽量做到全面发展。
[参考文献]
丁树良,罗 芬,涂冬波 2012 项目反应理论新进展专题研究[M]. 北京:北京师范大学出版社.
范 鹏 2017 大规模考试网上评卷中趋中评分的成因探析[J]. 中国轻工教育(5).
何莲珍,张 洁 2008 多层面Rasch模型下大学英语四,六级考试口语考试(CET-SET)信度研究[J]. 现代外语31(4).
孔子学院总部/国家汉办 2016 国际中文教师证书考试大纲[M]. 北京:人民教育出版社.
刘耀中 2009 人员选拔面试中的晕轮效应[J]. 心理科学32(6).
孙晓敏,薛 刚 2008 多面Rasch模型在结构化面试中的应用[J].心理学报(9).
孙晓敏,张厚粲 2006 国家公务员结构化面试中评委偏差的IRT分析[J].心理学报38(4).
吴志明,张厚粲,杨立谦 1997 结构化面试中的评分一致性问题初探[J].应用心理学(02).
曾秀芹,孟庆茂 1999 项目功能差异及其检测方法[J]. 心理科学进展17(002).
张 洁 2014 语言测试研究中的多层面Rasch模型——原理简介和研究综述[J]. 外语测试与教学000(3).
张新玲,曾用强 2009 读写结合写作测试任务在大型考试中的构念效度验证[J]. 解放军外国语学院学报32(001).
Farrokhi, F. & R. Esfandiari 2011 A many-facet Rasch Model to detect halo effect in three types of raters [J]. Theory and Practice in Language Studies 1(11).
Linacre, J. M. 2012 Many-Facet Rasch Measurement: Facets Tutorial [EB/OL] https://www.winsteps.com/tutorials.htm
McNamara, T. F. 1996 Measuring Second Language Performance[M]. London: Longman.
Myford, C. M. & E. W. Wolfe 2000 Monitoring Sources of Variability within the Test of Spoken English Assessment System [R] (TOEFL Research Report NO. 65) Princeton, NJ: Educational Testing Service.
——— 2003 Detecting and measuring rater effects using many-facet Rasch measurement: Part I. [J]. Journal of Applied Measurement 4(4).
——— 2004 Detecting and measuring rater effects using many-facet Rasch measurement: Part II [J]. Journal of applied measurement 5(2).
Weigle, S. C. 1998 Using FACETS to model rater training effects[J]. Language Testing 15(2).
猜你喜欢
青春岁月(2016年20期)2016-12-21
考试周刊(2016年76期)2016-10-09
考试周刊(2016年76期)2016-10-09
考试周刊(2016年60期)2016-08-23
科技视界(2016年7期)2016-04-01
科技视界(2015年25期)2015-09-01
意林(2009年23期)2009-05-14
