
基于自编码器的对抗样本生成模型
2021-09-14 00:14陈梦悦
电脑知识与技术 2021年22期
关键词:深度学习
陈梦悦
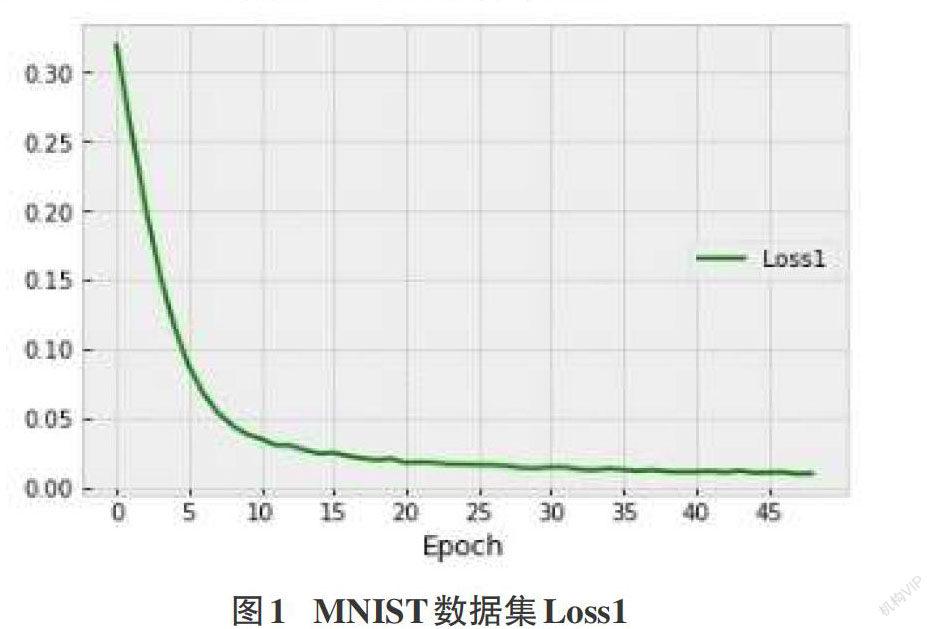
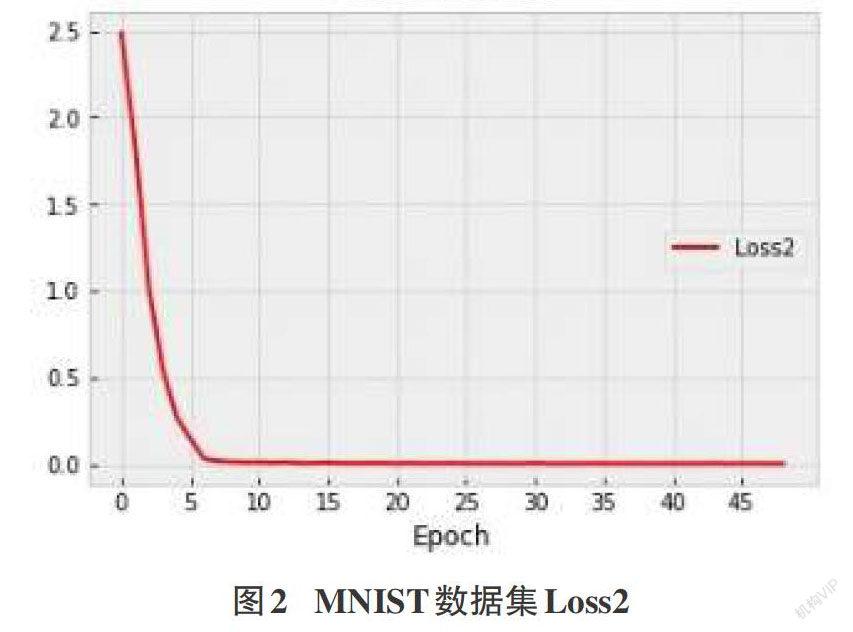
摘要:由于人工智能系统对于数据的依赖以及深度学习算法的不可解释性,导致目前的人工智能系统面临严重的安全风险。其中,对抗样本是目前深度学习面临的主要威胁之一。为了更好地应对对抗样本攻击带来的安全威胁,需要对对抗样本的构造机制有充分的了解。因此,深度学习领域中关于对抗样本的构造方法有了大量的研究。该文提出了一种基于自编码器的对抗样本生成方法,不需要强大的背景知识,降低计算成本,实验结果证实所提出的方法的先进性和可用性。
关键词:深度学习;对抗样本;自编码器
Absrtact:Due to the dependence of artificial intelligence system on data and the unexplainability of deep learning algorithm, the current artificial intelligence system is facing serious security risks. Among them, counter sample is one of the main threats to deep learning. In order to better deal with the security threats brought by counter sample attacks, we need to have a full understanding of the construction mechanism of counter sample. Therefore, in the field of deep learning, there has been a lot of research on the construction method of confrontation samples. This paper proposes a method of generating a countermeasure sample based on selfencoding. It does not require strong background knowledge and reduces computation cost. Experimental results confirm the advanced and usability of the proposed method.
Key words: deep learning; adversarial examples; autoencoder
1背景知识
日益增多的社会信息交流系统和软件中,几乎连接着人们的方方面面,改变着人们的学习,工作方式以及日常生活,在丰富精神文化生活的同时,也带来了风险。网络与信息安全问题是世界各国信息时代所面临的主要难题,作为信息保护的主要环节,这个风险和问题需要一直被重视。人们的生活成本需求在信息化、科技化、人性化、智能化驱动下,精准定位智能需求,多元扩展智能来源,弹性发挥智能能效,个性化定制智能服务等多机制入手,把握信息时代之魂,关注信息时代之需,聚焦信息时代之变,引领信息时代之风。以及新理论新技术和经济社会发展的强烈需求的共同推动下,人工智能科学持续创新,逐步走向工业世界。虽然深度学习[1]技术有着广泛的应用前景,但是对于现阶段的研究水平而言,以深度学习为基础的人工智能应用面临严重的安全风险。2018年3月26日,由全球最大的网络预约汽车服务公司Uber研发的L4自动驾驶汽车在亚利桑那州的公共道路上撞上行人,这是世界上首次自动驾驶造成的死亡。今年5月,Uber事故的初步报告显示,Uber的自动操作软件无法准确识别受害者何时过马路。目前深度学习在隐私保护和安全领域面临诸多问题,其中最为突出的安全问题是对抗样本[2],上述两个案例背后的始作俑者正是对抗样本。对抗样本[3-5]是目前深度学习面临的主要威胁之一, 对抗样本是指通过对原始样本进行一些细微的扰动来使得目标模型以高置信度给出一个截然不同的预测结果。为了更好地应对对抗样本攻擊带来的安全威胁,针对当前对抗样本构造方法存在的缺陷,本文提出了一种基于自编码器的对抗样本生成方法,主要贡献包括:本文是通过在原始样本经过降维之后,对其低维的特征表示进行扰动,从而构造对抗样本。通过大量的实验,我们证明了该构造方法的有效性。
2自编码器
自编码器是深度学习中比较著名的无监督学习方法,最早的概念来自Rumelhart等人在《Nature》上发表的论文。后来,Burlard等人做出了详细的阐述。自编码器的输入层和输出层分别代表神经网络的输入层和输出层,隐层承担编码器和解码器的工作,编码过程是从高纬度输入层到低纬度隐层的转换。另一方面,解码过程是从低维层到高阶输出层的转换过程。转换过程通过比较输入和输出之间的差异来定义损失函数。在转换过程中,不需要标记数据。整个过程就是求解损失函数最小化的过程。这也是编码器名称的来源。自编码器是一种人工神经网络,通过无监督学习有效地显示输入数据。自动编码器是一种数据压缩算法,数据压缩和解压功能与数据、丢失相关,并从样本中自动学习。如果提到大多数自动编码器,压缩和解压缩功能是通过神经网络实现的。自编码器是一种自监督算法,不是无监督算法。自监督学习是监督学习的一个例子,标签生成自输入数据。为了获得一个自监督模型,需要一个可靠的目标和损失函数。设定重新配置输入的目标可能不是正确的选择。基本上,模型需要在像素级重新配置。输入不是机器学习的兴趣,而是学习高级抽象特征。在实践中,如果主任务是分类定位等任务,则这些任务的最佳特征基本上是重构输入的最差特征。这种输入数据的有效表示称为编码,它比输入数据的维数更小,允许使用自编码器降维。更重要的是,自编码器可以作为一个强大的特征检测器用于深度神经网络的先验训练。此外,自编码器可以随机生成与训练数据相似的数据,这称为生成模型。一般来说,常见的自编码器包括编码和解码两个阶段。编码器和解码器的结构一般来说是对称的。
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
考试周刊(2016年64期)2016-09-22
