
社交网络内容生产中“标准偶像”现象与机理
2021-09-13 10:59徐翔
华南理工大学学报(社会科学版) 2021年4期
关键词:社交网络
徐翔
摘 要:当前对于社交网络“标准偶像”现象和机理的研究,仍缺乏足够重视、专门实证探讨和理论自觉。明确提出“标准偶像”的理论概念,并进行其机理实证分析。采用潜在语义分析(LSA)对微博用户的文本数据进行挖掘,结合统计检验和路径分析考察标准偶像的作用。社交网络内容生产中,高粉丝数、高流量、高咖位的用户,其个体的内容整体不是趋向丰富性、垂直细分和特立独行的差异化,而是趋向越来越重复、趋似和标准化。微博用户的粉丝数越高,则其趋同于标准用户的程度相应越高,用户粉丝数和内容之间的关系越来越闭合,促进高粉阶层的异质性不断被削磨,同一化标准化程度不断增加,表现出“标准偶像”的现象、效应及其社会文化逻辑。微博中的“标准偶像”及其传播后果,蕴含着从“大众偶像的胜利”到“标准偶像的胜利”、从多样话语崛起到封闭圈层和“社会窄化”的转向。
关键词:社交网络;标准偶像;微博用户;用户相似性;潜在语义分析
中图分类号:G206.3 文献标志码:A 文章编号:1009-055X(2021)04-0109-14
doi:10.19366/j.cnki.1009-055X.2021.04.011
社交网络的内容生产与传播中,“人人都有麦克风”的自主性、多样亚文化和碎片化语境,似乎和个体的同一化乃至标准化并无关系。社交网络用户生成内容(UGC)的各种大咖①、大V②和“流量担当”、人气用户,似乎千差万别,丰富着各种垂直领域和细分领域,形成独树一帜、专门化、多样化的用户。为了便于行文,本文将社交网络具有高影响力、高粉丝数或者高人气关注的用户,称为各种不同程度的“偶像”用户。
从偶像的内涵上,“偶像崇拜是个人对其喜好人物的社会认同和情感依恋”[1]。新媒体语境下,“偶像的发展很大程度上仰仗于粉丝的助力支持”[2],诸多研究也都强调媒体“偶像-粉丝”的紧密对应关系[3-6]。本文基于媒介文化的语境,对于社交网络“偶像用户”的界定如下:在社交网络中,具有足够影响力、“圈粉”量、粉丝规模或追随者的用户。由于偶像用户的粉丝数量或追随者规模的不同,产生了社交网络偶像在程度上的强弱差异。
随之而来的一个基本但又经常面临的问题是:社交网络内容生产中的偶像用户,他们是多样化的,抑或是趋同化的?针对问题,要强调的是一种可称为“标准偶像”的传播趋势和机制:高粉丝数、高流量、高咖位的用户,其个体的内容整体不是趋向丰富性、垂直细分和特立独行的差异化,而是趋向减少个体的独特性,增强同一化和标准化,甚至带来高粉阶层的封闭与窄化。本文将在理论内涵分析的基础上,结合微博用户数据和文本挖掘予以统计检验。
一、研究回顾
现代大众媒介社会,偶像的主要代表是传媒影响下的明星、高人气用户、“大咖”等。中国语境下的大众偶像具有较多的文化意义,榜样、偶像、网络红人的生成“走过了一个政治文化驱动—商业文化驱动—草根文化驱动的历程”[7]。随着网络媒体、自媒体的崛起,涌现出新的大批“网络红人”“草根偶像”和“民星偶像”。这些不同类型、主题、风格的网络媒介偶像,通常不被人们认为具有重复、似同、单一的“标准化”特点。相反,他们往往被惯性地认为具有多样性、丰富性。例如,有学者认为网络后现代性的交往实践所构建的是“不稳定的、多重的和分散的主体”,在网络红人的生产中,个体化的主体的消失正是后现代网络传播主体特征的体现[8]。尤其在网络偶像多元化的“民星”时代和网络红人,有研究者提出,偶像崇拜更为多元和小众[9]。这些观点被接受程度较高,也较为流行,但多数凭借经验或理论判断,因此需要更为实际的检验。社交网络中的偶像用户到底是多样化抑或趋同化,成为本文所拟实证的主要问题之一。
对社交网络中的高流量大咖、高人气用户或意见领袖的实证分析,也多数是在这种“多样性”的框架下进行的,或只是分析在多样之中如何表现出一定程度的聚集趋势的并存,而无法专门聚焦于偶像用户内容特征在深层的趋同性和同化。例如,方付建[10]将网络意见领袖分为专家型、草根型、身份型和技术型四种类型。生奇志等[11]指出,微博意见领袖有明星型、精英型、政务型、专业型、公益型、宗教型等。这些研究对于社交网络或微博意见领袖强调其多样性和内容差异性[12-13],或者强调其个性化和专业化[14]。在此基础上要进一步探讨的是,高影响力用户和意见领袖的类型分化程度,在与其他用户群体的横向比较下,去判定他们是否变得更加多样化,或不那么多样化。这构成本文中重要而基本的问题。
就媒介文化与大众文化而言,法兰克福学派的学者洛文塔尔在其经典研究中,分析和论证了刊物媒体上的偶像人物及其类型的特征与转变,也即他们从企业家、教授、严肅艺术家等生产型的偶像,转向娱乐、体育、休闲等领域的消费型的偶像[15]。这对于偶像的“趋同化”,有着重要意义和启发。同时,以下两方面的现象仍有待继续深入研究。首先,媒介空间中的偶像,在某一时间段,偏向于某种狭窄的类型(无论是生产型还是消费型)和某种狭义上的共通特征,而非同时广泛、均衡地包含这些多种差异的类型。无论是生产偶像还是消费偶像,都可视作狭义的表现,它们服从于一个更大的规律和范畴——可称之为趋于同化的“标准偶像”。或者说,问题的关键不仅仅在于偶像属于何种类型,而是在于它们属于同种类型。“标准偶像”现象表达的是一种“媒体复制时代”的用户再生产及其偶像用户趋同化的社会文化现象。其次,偶像或非偶像,并非只是“是或否”的定性区分,而包含着定量的程度区分。因而需要探讨随着“偶像”程度或层级的变化,偶像的趋同特征又会发生怎样的变化。结合当今强势崛起的社交网络和自媒体,其所包含的问题是“非偶像”或“低程度偶像”与流量明星、圈粉人气偶像的类型分布特征和变化规律。
部分研究注意到,内容各异的微博用户和意见领袖之中可能具有主导类型与倾向性。例如,曹洵等[16]的研究显示,微博的意见群体中营销类、娱乐类成为主流。佟力强[17]把新浪微博名人用户主要分为七类,指出文化传媒类、商业财经类、文体明星类占的比例最大。王国华等对于微博意见领袖分布的调研中,人气榜、影响力榜各自的前100名意见领袖中,娱乐明星占比最大且明显超过其他任何类型[18]。总体上,这些分析给我们的重要启示是多样用户内容的背景下,用户高趋同化或相似化是可能的。在此基础上,仍需回应的问题包括:一是同样作为“主流”的用户类型,如偏娱乐型和偏营销型,彼此之间的差异,是否确证用户仍然是多样分化的,而非标准化的?二是同一种主导性的用户类型内部,不同个体在彼此之间仍然是存在差异的,他们属于同一类型并不直接等于这些用户具有同质性,如何兼容差异性和标准化的关系?即使有限度地承认存在着偏倚,也可能只是把“非均衡”分布作为和多样性并存的一种现象;并不等于认可偏倚性是一种朝向标准化和同一化的趋势,也不等于精确分析偏倚程度和用户影响力之间的关联机制。本文所考虑的回应路径,不仅仅是考察用户在“优势”类型、“主导”倾向上的较为粗糙的定类区分,而是将用户之间在内容生产上的差异度或相似度纳入连续性的计算框架,进而考察随着用户“偶像程度”的变化,用户之间相似程度趋大,或趋小,或无显著增减的变化趋势。
高影响力的用户或意见领袖较之低影响力用户具有更强的内容扩散能力、扩散效果,以及使得其他用戶和自己内容相似化的同化作用。例如,Matsumura等[19]提出的影响力扩散模型(Influence Diffusion Model, IDM)描述博主的内容扩散及其对其他用户的影响,反映了意见领袖在内容上向其他用户的扩散力和扩散深度。Borge等[20]对于推特中的政治意见领袖,分析了他们在推特中被追随、转推、提及的扩散能力。王晓光[21]指出博客用户的关注对象常常集中在特定的核心博客上,容易陷入特定主题的交流社区。这些显示着可能存在具有强同化能力的用户,包括意见领袖、“核心博客”等高影响力、高内容扩散能力的用户。
在大众偶像和粉丝用户之间的双向交互关系下,受众对于社交网络的公共领域产生同质化的反作用。由于媒介议程设置及其共鸣效果[22]、溢散效果[23]、网民共性偏好等因素,媒体和舆论的内容存在着趋同倾向。有研究指出新闻内容同质化的现象包含多种原因。例如,大众化的市场定位导致受众定位趋同;市场导向作用下对新闻娱乐性的片面追求等[24]。对于内容生产者的实践能力和传播效果生成而言,需要工具使用能力和标题党能力、热点导向思维、快速借鉴能力、商业变现思维[25]。以爆款、流量和变现为导向的内容生产,难以避免地会导致迎合受众的大众口味、同质化信息的模式化生产。
大众文化中对“标准化”的思考和批判,揭示了文化工业时代中的文化趋同化的深刻逻辑。“标准”与“标准化”包含着局部各要素的趋同性和同一性,伴随着人类发展的各个阶段,其基础内涵涉及测量工具、生产模板的标准化、工业时代零部件标准化、现代工业中标准化的生产流水线等。法兰克福学派的代表人物霍克海默等[26]提出著名的“文化工业”理论概念,指出在规模化的、商业化的文化生产和流通中,文化逐渐地同一化、非个性化。法兰克福学派的另一代表人物马尔库塞[27]提出“单向度的人”,反思着现代社会中主体的重复性和单一化。文化工业批判中,大众传媒和文化的“流水线”生产出了标准化的电影和流行音乐等文化产品,它们看上去是很“个别的样子”,但实际上无个性可言,产生一种“伪个性主义”[28]。这些对于文化工业及其“标准化”主体性[29]的批判,移植到社交媒体环境的内容生产以及微博用户的分析上同样是具有深思意义的。尤其是表层个体性之下所潜藏的深层趋同化,在表层的“碎片化”帖子和“人人时代”[30]的多样草根赋权中,可能忽视深层的同一性。或者说,微博社交网络在内容生产中的各种偶像用户,其用户在内容风格、内容气质、内容“人设”上的多样性与个性化上潜藏着“伪个性化”和趋于同一性的“标准化”的可能,这个问题有待结合社交网络语境进行进一步的探思。
二、问题分析与假设提出
社交网络中的偶像用户,其多样性或趋同性有待实证的检验,而不只是对理论或经验的浅层判断。高影响力用户、偶像用户的多样性需要对偶像进行比较才可显现出其是否趋于多样化抑或减少多样化的动态过程中,需要在多样性的表面背后寻求深层的同一性、在多样性的静态现状之外对于趋同化趋势的慎思。用户在类型分布上的集中或偏倚并不等于标准化和趋同化,一种可行的推测是:如果意见领袖、高影响力或高人气用户存在向少数“用户类型”的集中化和偏倚化,那么意见领袖的这种分布就不应该是静态的,而应该是动态的,是随着用户的影响力扩大而不断加强的过程。高影响力用户具有更强的内容扩散能力和对于其他用户的同化能力。同时,社交网络用户的社会连接,也增强了高影响力、高社会连接用户在内容传播中的圈层扩散与同质化传递。基于此,进一步探讨的问题是:社交网络内容生产中的偶像用户,他们随着偶像程度的提高,是否趋于相似化和标准化,抑或趋于差异化和多样化?
对此,可提出“标准偶像”的问题,其最为核心的内涵:社交网络中,用户的偶像程度和用户的标准化程度这两者之间存在着何种的相关关系?
关于用户“标准偶像”现象和问题中,关键概念的界定与内涵如下。一是偶像用户。参见前文。二是用户的偶像程度。作为偶像用户的强弱程度,结合关于偶像用户的内涵分析,主要选择粉丝规模作为偶像程度的衡量指标。三是用户的标准化指的是用户在内容整体特征上趋于重复、同化和封闭的现象和趋势,而非趋于多样化、丰富性和差异性。反过来说,对社交网络的流量用户、意见领袖、大咖偶像的趋同化的研究是匮乏和不足的,甚至缺乏专门的理论和理论自觉。四是用户相似程度的衡量。不是对用户的零散帖子之间的相似度进行衡量,而是把用户所有帖子还原、组装到该用户的整体内容特征,“以帖察人”,从而测量任意两个用户的相似程度。从每个用户的整体内容中,剥离下来的帖子“碎片”可能是差别化、非“标准”化的,但是把这些碎片组回整体,则可能显现出碎片背后的统一性。
“标准偶像”的作用是用户们围绕“标准偶像”发展和自我“养成”,这也是用户逐渐被同一化和标准化的过程。越是高粉丝数的用户,就越有可能成为“标准用户”,也可能使得媒介场域中的其他人继续被养成和同化为“标准用户”。本文以典型的社交网络媒体之一新浪微博为媒介对象,引申出假设H1、假设H2、假设H3这三个具体化的观点和假设。
(一)用户粉丝数和“趋同于顶部高粉丝数用户的程度”之间的关系
一个媒介场中的“标准用户”和“标准偶像”究竟长成什么样,并非只是“生产型”“消费型”可以简单描画的,本文也不是针对标准偶像的内容轮廓进行用户画像。但是有一点可以确定,既然越是高粉丝数的用户,其内容就越是接近于或约等于“标准偶像”,而同时这些高粉丝数的用户依然存在着各自的内容特点,那么就有理由认为:不同的高粉丝数用户,从各自不同的面接近某种“标准偶像”,并且高人气用户比低人气用户、偶像比非偶像要更接近这种“标的”和“标准用户”。在我们没有描画最终的标准模板具体长成什么样的情况下,可以通过离它最近的一批人,来近似地得到标准偶像的趋同特征。越是高粉丝数的用户,越是偶像群体,越是使得其他用户和本群体发生相似。所以,一方面,如果高粉丝用户比低粉丝用户更趋近“标准偶像”,那么前者就需要表现出比后者更趋近于微博最高人气的那批用户;另一方面,如果高粉丝用户越来越趋近“标准偶像”,那么他们就应该在增加和最高粉丝数的那批用户的相似度的同时,也越来越减少和低粉丝用户的相似度,也即离“标准偶像”的相反端的负极越来越远和趋异。后文的实证部分,我们用前者减后者的差值来综合地反映某个用户“趋顶离底”、趋近于“偶像模板群”的程度。
由此,提出假设H1:越是高粉丝数的微博用户,他和微博中粉丝数最高的n个偶像用户,具有越大的相似度;兩者具有线性正相关。
(二) 用户粉丝数和“与同粉丝数层级用户的相似度”之间的关系
如果用户特征类型是在不同的圈粉层级随机分布的,那么和某个用户相似的其他n个用户,就有可能散落在微博中各个不同的粉丝数层级;由此得到的结论就会是每个用户的这些相似用户的平均粉丝数,不存在显著差异。但是,结合假设H1,如果越高粉丝数的用户,就越是重复、类同的用户,那么可以得到:第一,中、低粉丝数用户的n个内容最相似用户(代称Glow),其粉丝数的分布会比高粉用户的相对分散,从而其Glow的粉丝数平均值相对会分布得更缺乏规律性,会更接近全体用户粉丝数的平均值(只是接近,而不是等于)。第二,对于高粉丝数用户,其内容最相似用户会由于“标准偶像”的效应而更接近于自己的粉丝数,从而高粉丝数用户的n个最相似用户(代称Ghigh)的粉丝数平均值会比Glow的更高,更为超出平均值而正向地靠近、相关于高粉用户自身的粉丝数。第三,越是高粉丝数用户,由于“标准偶像”作用,他的n个内容相似用户接近于自己的粉丝数的可能性越高。
由标准偶像进行的更为合理的阐释是:对于任意一个用户Ux,与Ux具有最高内容相似度的n个用户Gx,尽管依然存在着粉丝数分布不够确定的问题,但是若Ux的粉丝数越低,则Gx的平均粉丝数Fg就越接近于总体用户粉丝数的平均水平;而若Ux的粉丝数Fx越高,则Gx的平均粉丝数Fg就越接近Ux的粉丝数,也就是Fg相应地越高。从而,会表现出Fx和Fg的正相关性。总体来看,越接近高程度“模板”和“标准偶像”的用户,他的n个最为相似用户(n≥1)的平均粉丝规模越大,虽然我们不否认相反情况的存在,但后者不是规律,也不会具有统计显著性。
由此,提出假设H2:越是高粉丝数的用户,与该用户整体内容相似程度最高的n个用户的平均粉丝数越大;两者具有线性正相关。
(三) 用户粉丝数和“与自己内容最为相似用户的平均粉丝规模”之间的关系
低粉丝数用户虽然也会有和粉丝数同层级用户的内容相似度,但是这个相似度比较低;而高粉丝数用户和粉丝数同层级用户的相似度较高;并且这种内容相似度和该用户的粉丝数成正相关。以往对于这个问题容易产生误解:认为低粉丝数的“大众”“群氓”可能是芸芸众生般的高相似化;而相反,高粉丝数的内容精英和意见领袖,由于其标杆性、引领性或面向垂直领域、细分受众的专门性,才可能是更为差异化的。但是,根据标准偶像的假设就意味着:越是低粉丝用户,由于非标准化的异质性较多,所以相互之间相似度较低;越是高粉丝用户就越是消磨自己的异质性和“个性”,呈现文化批判理论中的“伪个性化”。而标准化的程度越多,异质性和独特化的个性内容被消磨越多,也就越相似。
由此,提出假设H3:越是高粉丝数的用户,他和处于同一粉丝数阶层的n个用户的内容相似度越高;两者具有线性正相关。
(四)假设H1、假设H2、假设H3的内在关系
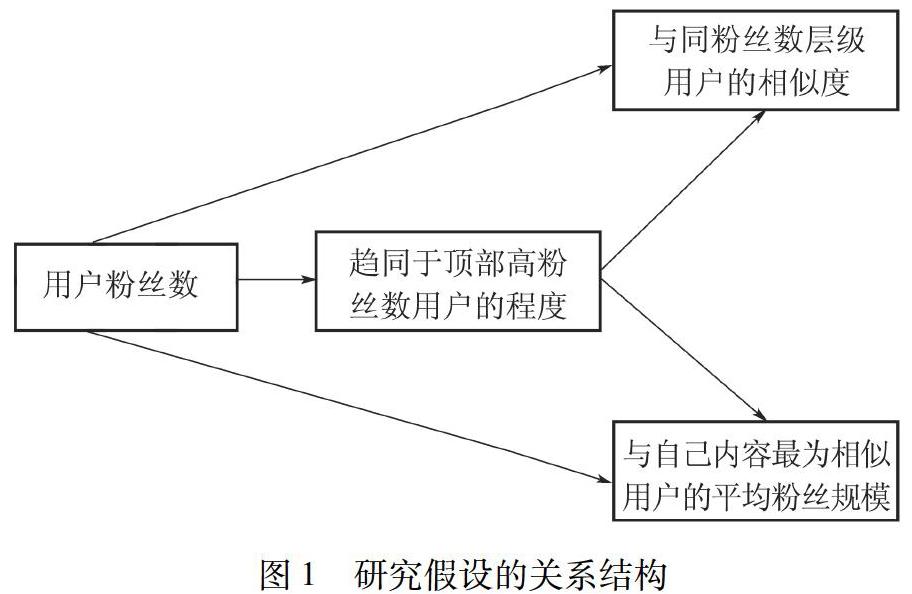
假设H1、假设H2、假设H3分别由用户粉丝数及其与标准偶像之间的关系得出。其中,用户粉丝数和“趋同于顶部高粉丝数用户的程度”之间的正向关系,对应于假设H1。用户在趋同于顶部高粉丝数用户的程度越来越高的同时,其与同粉丝数层级用户的相似度(对应于假设H2)、与自己内容最为相似用户的平均粉丝规模(对应于假设H3)也越来越高。三个假设的关系结构如图1所示。
三、研究方案与研究设计
(一)样本选取和数据预处理
样本选取自新浪微博,这是中国具有代表性的社交媒体和自媒体平台,活跃用户数量超4亿个,用户分布于社会、经济、文化、娱乐、体育、科学等广泛的领域。抓取新浪微博87739个用户的历史所发帖子,每人按发布时间顺序抓取最多4500条,初始获取帖子样本131770017条。全部用户只选取时间段2017年1月1日到2018年12月31日的两年间的帖子,以统一横向比较的口径。为了稳健和较为充分地反映个体的内容特征,对于这两年间的帖子,每个用户一律随机选取1500条;不足1500条的用户不纳入考察范围。最后得到有效样本用户12478个。
用户的偶像程度指标的选取方面,结合偶像用户的内涵,选择具有很高认可度和代表性的粉丝数反映用户作为高人气偶像用户的程度。虽然微博偶像有很多种来源和方式,但是在当今注重“圈粉”“流量明星”“饭圈”的时代,粉丝数的多少可以作为反映用户作为各种类型的偶像用户的程度,如娱乐圈的高粉明星、企业界大V或文化科普的高流量大咖等。张玉晨等[31]把粉丝规模作为区分大V与中V的唯一依据。实际操作中,采取对数转换后的形式,式(1)中x为用户粉丝数的原始数值。
(二)基于潜在语义分析的用户内容特征提取及其向量表达
把单个样本用户的各条帖子,无顺序地拼接为一个长文本,然后通过向量空间模型(VSM)得到每个用户的词频矩阵。词频矩阵的获取过程采取sklearn模块,关键部分的参数如下:最低词频数(min_df)=50,最大文档频率(max_df)=0.3,n元词范围(ngram_range)=(1,1),也即只采用一元词。得到的词频矩阵有128082个不同的词,将各词的频数转换为该词在该用户所有词总数中占的比例(也即L1的规范化),最终形成12478行×128082列的矩阵X。
对于潜在语义分析模型转换得到的词频矩阵,采取潜在语义分析(latent semantic analysis, LSA)进行降维和内容特征提取[32]。其中,对于用户-词项的矩阵X,进行奇异值分解。潜在语义分析对X进行阶段奇异值分解,保留前k个最大的奇异值,通过降维后的k个潜在语义主题以表示原有的全部信息。经过潜在语义分析降维,把矩阵X降到12478行×500列,保留信息的解释比(explained_variance_ratio_)为0.903,从而充分保留了原用户的内容特征。此外,如图2所示,横轴为潜在语义分析保留的特征维数,纵轴为该维数对应的解释比;当维数在500维时,解释比处于一个“肘拐点”,其后尽管也可再增加维数,但对于表示用户特征的解释比增长已大幅放缓。
(三)用户的内容相似度计算
本文对于用户相似度的计算,如无特别的说明,则一律指用户在内容整体特征上的相似度。
每个用户根据其内容,提取500维的向量之后,采用余弦相似度,进行用户之间的相似度计算。任意两个用户Um和Un之间的余弦相似度计算方法为:把两个用户Um、Un的内容分别转换得到两个向量A、B,则A、B的余弦相似度即两个向量A、B之间夹角θ的余弦cos(θ),该值范围在[-1,1],cos(θ)值越大表明这两个用户之间内容越相似。
在式(2)的基础上进行扩展,从1对1的用户相似度,扩展到n对n的两组用户(每组中用户数量n≥1)之间的相似度。也即任意一组用户G1(包含n1个用户)和另一组用户G2(包含n2个用户)的内容相似度,表示为:
式(3)在式(2)的基础上,采用“类平均法”(或称“簇平均法”,average group linkage)衡量两组对象间的平均距离、平均相似度。其中G1或G2都可以有且仅有一个用户,这种情况下也即:式(2)中所计算的个体与个体之间的两两相似度R(Ux1,Ux2),成为本公式中n1和n2分别为1时的特例。
式(3)变形后的形式是计算任一层组用户(G1,其中用户个数n1≥2)内部的彼此平均相似度。该式在本文中,用于对各用户层级内部平均相似度的计算。这和式(3)的唯一差别之处就是不计算用户和他自身的内容相似度。具体形式为:
四、实证检验与分析
对最终的12478个用户样本进行分析。其中,根据式(1)得到每个用户的粉丝数xi,并把这12478个值依次组成用户粉丝数序列(代称list_0)=[x1,x2,x3,…,x12478]。假设H1、假设H2、假设H3的检验中所涉及的变量F1、F2、F3,其用户顺序皆与用户粉丝数序列中的一致。
(一)假设H1的转换及检验
采用“趋顶去底”的差值,作为反映用户趋向模板偶像的综合程度,也即:相似于顶部最高粉丝数的用户群的程度-相似于底部最低粉丝数的用户群的程度(该变量简称F1)。这个差值越大,即该用户“趋中心-离边缘”的程度越高。如果某个用户为Gx,粉丝数最高的n个用户为集合Gn_max,粉丝数最低的n个用户为集合Gn_min。根据式(3),用户“趋顶离底”的差值为:H(Gx,Gn_max)-H(Gx,Gn_min)
N分别从[1,201,401,601,…,6401]等差数列依次取值的情况下,用户粉丝数和用户趋顶离底程度之间,皮尔逊相关系数和斯皮尔曼相关系数全部为显著的正相关,p值全部<0.001;皮尔逊相关系数绝大多数都在0.4以上,如图3所示。
当参照群体规模N取值较小时,如只取N=1个,则由于顶部、底部的参照人数过少,他们对“顶部”标准偶像的用户特征反映的综合程度较低,从而增大了相关系数的不稳定性。但即使如此,假设H1依然是显著的,皮尔逊相关系数(N=12478)依然大于0.25。而当N取值稍大,对“标准偶像”反映得更为全面,例如当N为201时,假设H2的皮尔逊相关系数增加到了0.36,斯皮尔曼相关系数增加到了0.39。此后无论N如何取值,相关系数一直维持稳定。
因此,假设H1得到检验。用户的粉丝数越高,其趋向于粉丝数最高的顶部偶像模板的程度越深。
(二)假设H2的转换及检验
对于任一用户Gx, 从全体用户中逐个计算每个用户和Gx的余弦相似度,根据式(2),从中选出余弦相似度最高的n个用户作为Gsim。其中,如果Gsim包含Gx,则预先剔除掉该元素。Gx与Gsim的平均相似度,采用式(3)计算,为H(Gx,Gsim)。
对相关系数的分析显示,在N分别取1,2,3,…,500时,由于N的取值都不大,所有在这些条件下,用户粉丝数和“该用户最为相似的n个用户的平均粉丝数”(该变量简称F2)之间,相关系数的p值全部小于0.001,也即线性正相关是全部成立的。皮尔逊相关系数大多数在0.5以上;其中当N小于32时,则多数在0.65以上,如图4所示。
如图5所示,随着相似用户数量n的增大,即使最终增加到约为全体用户的情况下,相关系数依然显著。但是超过一定的阈值后,为600左右时,则相关系数出现了下跌的拐点。其中,皮尔逊相关系数在N为601时尚有0.49,之后则逐渐下跌速度较快;斯皮尔曼相关系数也有类似情况,如图5所示。
总体而言,假设H2得到了检验。并且结果显示,当最相似用户个数n控制在一定的阈值范围内,则相似度可以保持在足够高位,所以正相关更为紧密和稳定。
(三)假设H3的转换及检验
对于任一用户Gx,首先从全体用户中选出和Gx在粉丝数上最为接近,且不包括Gx自身的n个用户作为Gnear。Gx与Gnear的平均相似度,采用式(3)计算,为:H(Gx,Gnear)。逐个用户计算H(Gx,Gnear)后,记为变量F3。考察用户粉丝数序列和其顺序对应的变量F3之间,其皮尔逊相关系数和斯皮尔曼相关系数是否显著。
圖6的结果中,分别考察N的取值范围从1,101,201,…,到3001(等差为100个)的情况。相关系数全部显著(p值全部<0.001),而且在阈值范围内有高度的正相关性。其中,皮尔逊相关系数在同层级用户个数N取值为100时,已达到0.57的相关程度。此后,当N在2001的范围之内时,皮尔逊正相关系数一直维持在0.55以上的较高位。直到N取值过大时(本文中为N超过2100的范围),由于Gnear的范围过大导致它和Gx在“同粉丝数”方面太多松散、差异太大,才减少了正相关系数。但即使如此,也依然维持在0.2以上的水平,说明这种“同粉丝数”带来的用户相似度的影响作用存在。
统计检验的结果显示,假设H3是成立的。并且当N取值不要过宽泛,并在一定的阈值范围内,则这种用户的相似和同化封闭就更为稳定、更有规律性和可预测性。
五、微博“标准偶像”作用的统一性及其结构
假设H1、假设H2、假设H3涉及的三种不同路向,有着内在的有机联系和共同的“标准偶像”化驱动作用力,因而是同步和一致的,而不是相互独立或相互对立的。统计检验也支持这种较强的同步性。假设H1、假设H2、假设H3分别涉及用户粉丝数和三个变量(F1、F2、F3)各自的相关性,因此对这四个变量,通过克朗巴赫系数(Cronbachs Alpha)来考察它们内部的一致性和同步性。
变量一:用户“趋顶离底”的程度(F1),选取粉丝数的顶部用户、底部用户各500个。变量二:用户的n个内容最相似用户的平均粉丝数(F2),选取N为30。变量三:用户与n个粉丝数最接近用户的内容相似度(F3),选取N为500。上述所选择的参数,都具有相关系数的稳定性与较佳的性能。变量四:采取经式(1)转换后的用户粉丝数序列结果。
对每个指标,全部采用blom公式并转为正态分布值,然后计算克朗巴赫系数。标准化的克朗巴赫系数为0.769,显现出四个变量内部较为理想的一致性。其中,删除任何一个指标,都会造成剩下的三个指标间的克朗巴赫系数的下降。计算结果见表1。
在上述四个变量之间的内在一致性的基础上,继续通过“路径分析”,考察其内在的作用关系和结构。路径分析的工具采用AMOS 21.0。由于这四个变量已进行了正态化的转换,因此直接读入AMOS进行分析,采取常用的最大似然法(maximum likelihood)计算。
路径分析的结构与图1相同。
(1)用户粉丝数分别对“趋同于顶部高粉丝数用户的程度”“与同粉丝数层级用户的相似度”“与自己内容最为相似用户的平均粉丝规模”这三个变量,都具有正向作用。
(2)用户“趋同于顶部高粉丝数用户的程度”,分别对“与同粉丝数层级用户的相似度”“与自己内容最为相似用户的平均粉丝规模”这两个变量都具有正向作用。它是塑造“标准偶像”使其他用户朝向标准模板发生标准化的关键“钥匙”。因此,把它作为路径分析中的关键枢纽加以检验。
(3)“与同粉丝数层级用户的相似度”“与自己内容最为相似用户的平均粉丝规模”这两个变量存在着共通性。它们指:越是高粉丝数用户,和相近粉丝数用户的内容相似度越高;越是高粉丝数用户,和具有相似内容用户的粉丝数相近度越高。一正一反,互为补充,因此,不是在这两者间建立单向的路径,而是在他们的残差项e1、e2、e3之间建立起双向的关联。
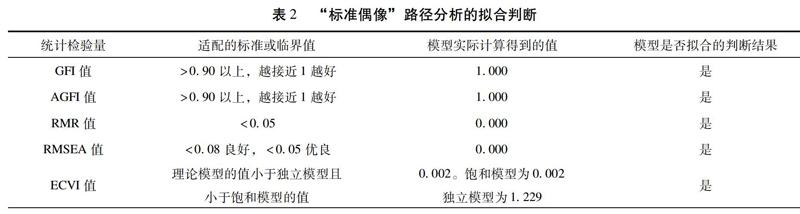
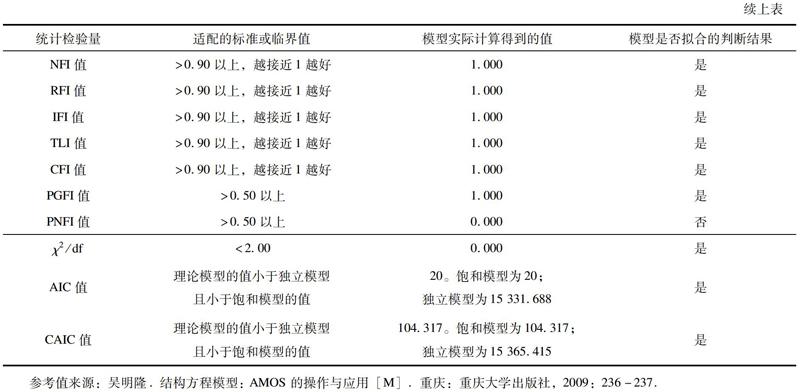
据此建立“标准偶像”的路径分析及其标准化的回归系数,如图7所示。其中回归系数全部显著,因素之间的作用在此模型下是成立的;并且这种结构作用下,整体的关系模型具有高拟合优度。
选择多种评价标准,对本模型的拟合优度进行考察。包括近似误差均方根(RMSEA)、均方根残差(RMR)、卡方与自由度比值(χ2/df)等重要指标在内的大部分拟合指标的匹配程度优良。“标准偶像”路径分析的拟合判断如表2所示。
整体而言,本模型具有高拟合度。路径分析的结果虽然不排斥其他更优的整体关系模型,但从变量的关系路径的检验角度支持了假设H1、假设H2、假设H3的结果,显现了用户随着粉丝数越来越高而趋于“标准偶像”化的过程中所发生的现象和效应。
六、由个体到宏观:微博“标准偶像”作用的社会现象
假设H1、假设H2、假设H3是对用户的个体分析,而这些个体现象则蕴含着微博偶像用户标准化的社会现象和具有宏观性的演变态势。
把本文的12478个用户按照粉丝数进行从低到高的“等人数”分层(设每层人数都为m),并采用式(4)计算每层内m个用户的层内平均相似度。则检验结果鲜明地显示:用户层级越高,层内部的彼此平均相似度越高,两者符合显著的线性正相关。我们分别在2人、3人、4人……500人的不同的分层规模下,进行了相关系数的检验,结果见图8;其中无论按照何种分层规模,其皮尔逊相关系数与斯皮尔曼相关系数的p值全部小于0.001,因此p值变化未在图8中标出。在各种分层规模下,正相关系数多数在0.8乃至0.9以上。以皮尔逊相关系数为例,分层规模仅为2人时,相关系数为0.29;而当分层规模增长到20人时,相关系数迅速增长到0.81;此后保持在0.8以上的高相关系数。
随着微博用户“社会层级”或“咖位”的提高,层级内用户的平均群聚系数(average clustering coefficient)[33]变得越来越大。平均群聚系数是在社会网络分析(SNA)中用于衡量某个群内离散、分裂程度的指标,在本文中,用于度量层内的用户倾向于围绕某种共同中心而相似、趋同的紧密程度。先结合式(2)的计算形成层内所有用户两两之间的n×n的余弦相似度矩阵,然后对各层的余弦相似度矩阵采用networkx中的average_clustering()函数,计算该层用户的平均群聚系数。把用户按照粉丝数从低到高地等频“分箱化”为若干层级,我们分别在3、4、5、……100人的不同的分层规模下进行了相关系数的检验,结果显示见图9:无论做何种规模的分层,每层内各用户粉丝数平均值形成该层“质心”,则层质心和层平均群聚系数之间,相关系数均为显著的正相关。
为了更为直观地显示上述“偶像层级”的层内用户相似程度越来越高的趋势,将12478个样本按照粉丝数的高低,等人数地切分为100层、200层、300层,如图10所示。
七、结 语
本文明确提出“标准偶像”的理论概念,以其来描述社交网络用户所存在的结构化的趋同现象与态势,并结合新浪微博的用户数据进行了实证分析。这种“标准偶像”的现象在强调社交网络用户多样性與偶像用户分化的背景下,得到的重视不足,一些较为流行的理论观点也往往与之相悖。由于“标准偶像”以及假设H1、假设H2、假设H3,用户随着粉丝数的增大而越来越加强重复化、似同化、标准化;尤其是在假设H3的情境下,粉丝数相同的一群用户间,他们的相似程度随着粉丝数的增大而增大。当我们用社会分层的角度来审视微博空间,则越是高粉丝数的阶层,其内部越来越增强同质性、封闭性,减少层组内的个体异质性。尽管我们经常强调网络社会的“壁垒”形成“巴尔干化”[34]摘 要:巴尔干化指网络社会由于各种社会壁垒形成人群之间的分化、差异与隔离。但意外的是,网络本身越来越朝向“标准偶像”“标准用户”发生趋同,整体化地陷入“巴尔干化”而非一个个“巴尔干化”之后的“孤岛”,而这种“社会窄化”是以往重视不足的方面。“标准偶像”的传播现象和效应,意味着微博中偶像阶层的封闭性和“社会茧房”,而非用户的多样性抑或偶像用户在各自的垂直领域、分化范围的异质性。
在“标准偶像”的作用下,微博用户形成“标准化中心-异质化边缘”的总体格局:越是高粉丝数的用户内容就越相似,形成社会中的标准化、模板化、去个性化的“主流”和“中心”区域;而越是低粉丝数的用户越是处于边缘化,相互之间越分散、内容相似度越低;原本可能被认为“无个性”、芸芸众生的大众用户,反而是远离标准化的主流中心的、更为保留内容独特性的个体。
微观个体的“标准偶像”效应,与宏观的社会文化现象之间建立起了稳定的桥梁,使得仍然带有一部分波动的个体标准化效应在中观和宏观的社会层级的角度,表现出接近于1的线性正相关。这意味着这种分层的用户同化和用户标准化,其趋势表现得高度稳定。图10非常鲜明而直观地展现了微博中随偶像层级提升,近乎直线性的高度规律的“社会窄化”变化趋势。高程度的“大咖”、流量明星、高人气用户相互之间,比之低程度“大咖”用户相互之间,其内容相似度更高、更为趋同化。尽管这不意味着高的“阶层”内部一定已经达到了很强烈的、铁板一块的似同化程度,但是意味着这种似同程度的正向增长方向和趋势。微博“偶像”用户阶层越来越增强着趋同性与社会窄化,而非增强开放性与异质性。
参考文献:
[1]王平,刘电芝.青少年偶像崇拜的心理探源[J].苏州大学学报(哲学社会科学版),2010,31(5):179-181.
[2]郑石,张绍刚.颠覆与创造:新媒体环境下我国的偶像生产与粉丝文化[J].新闻界,2019(6):54-59.
[3]宋雷雨.虚拟偶像粉丝参与式文化的特征与意义[J].现代传播(中国传媒大学学报),2019,41(12):26-29.
[4]赵丽瑾,侯倩.跨媒体叙事与参与式文化生产:融合文化语境下偶像明星的制造機制[J].现代传播(中国传媒大学学报),2018,40(12):99-104.
[5]罗坤瑾.新媒介使用中的偶像崇拜研究——以人气组合TFBOYS崇拜群体为研究样本的考察[J].西南民族大学学报(人文社科版),2020,41(2):188-192.
[6]邢彦辉,樊雪琛.数字时代的偶像崇拜:品牌虚拟形象与受众关系视角[J].当代传播,2020(5):78-81.
[7]徐鹰,岳晓东.中国大陆青少年偶像崇拜变迁与思考[J].青海社会科学,2009,(1):5-8.
[8]余霞.网络红人:后现代主义文化视野下的“草根偶像”[J].华中师范大学学报(人文社会科学版),2010(4):105-110.
[9]陈赛金.青少年偶像崇拜文化的变迁与引导[J].思想理论教育,2020(9):97-102.
[10]方付建. 论网络意见领袖的发展走向及其引导策略[J]. 湖北行政学院学报, 2013(1):31-35.
[11]生奇志,高森宇.中国微博意见领袖:特征、类型与发展趋势[J].东北大学学报(社会科学版),2013,15(4):381-385.
[12]刘果.微博意见领袖的角色分析与引导策略[J].武汉大学学报(人文科学版),2014,67(2):115-118.
[13]曹洵,张志安.基于媒介权力结构的微博意见领袖影响力研究[J].新闻界,2016(9):43-49.
[14]王平.中国网络意见领袖的发展历程[M].北京:人民日报出版社,2017:73-76
[15]利奥·洛文塔尔.文学、通俗文化和社会[M].甘锋,译.北京:中国人民大学出版社,2011:147-179.
[16]曹洵,张志安.社交媒体意见群体的特征、变化和影响力研究[J].新闻界,2017(7):24-30.
[17]佟力强.中国微博发展报告(2012)[M].北京:人民出版社,2013:27-28
[18]王国华,张勇波,王雅蕾,等.微博意见领袖的类型特征与内容指向研究[J].电子政务,2014(8):69-75.
[19]MATSUMURA N, OHSAWA Y, ISHIZUKA M. Influence diffusion model in text based communication[J]. Transactions of the Japanese society for artificial intelligence, 2002,17(3):259-267.
[20]BORGE B R, MARC E D V. Opinion leadership in parliamentary twitter networks:a matter of layers of interaction? [J]. Journal of information technology & politics, 2017, 14(3):1-14.
[21]王晓光.博客社区内的非正式交流:基于网络链接的实证分析[J].情报学报,2009(2):248-256.
[22]NOELLENEUMANN E, MATHES R. “The event as event”and “the event as news”:the significance of “consonance” for media effects research[J]. European journal of communication, 1987, 2(4):391-414.
[23]MATHES R, PFETSCH B. The role of the alternative press in the agenda-building process:spill-over effects and media opinion leadership[J]. European journal of communication, 1991, 6(1):33-62.
[24]朱秀清.新闻同质化分析[J].现代传播,2005(6):116-117.
[25]翟秀凤.创意劳动抑或算法规训?——探析智能化传播对网络内容生产者的影响[J].新闻记者,2019(10):4-11.
[26]马克斯·霍克海默,西奥多·阿道尔诺.启蒙辩证法——哲学断片[M].渠敬东,曹卫东,译.上海:上海人民出版社.2006:107-152.
[27]赫伯特·马尔库塞.单向度的人[M].刘继,译. 上海:上海人民出版社.2008.
[28]曾一果.批判理论、文化工业与媒体发展——从法兰克福学派到今日批判理论[J].新闻与传播研究, 2016(1):26-40.
[29]阿尔都塞.哲学与政治:阿尔都塞读本[M].陈越,编译.长春:吉林人民出版社,2003:320-375.
[30]克莱·舍基.人人时代:无组织的组织力量[M].胡泳,沈满琳,译.杭州:浙江人民出版社,2015:77-110.
[31]张玉晨, 翟姗姗, 许鑫,等. 微博“中V”用户的传播特征及其引导力研究——以罗一笑事件为例[J]. 图书情报工作, 2018, 62(11):79-87.
[32]DUMAIS S T. Latent semantic analysis[J]. Annual review of information science and technology, 2004, 38(1):188-230.
[33]SARAMAKI J, KIVELA M, ONNELA J P, et al. Generalizations of the clustering coefficient to weighted complex networks[J]. Physical review E, 2007, 75(2):027105.
[34]VAN ALSTYNE M, BRYNJOLFSSON E. Could the internet balkanize science? [J]. Science, 1996,274(5292):1479-1480.
猜你喜欢
现代情报(2016年11期)2016-12-21
科技视界(2016年26期)2016-12-17
电脑知识与技术(2016年27期)2016-12-15
博览群书·教育(2016年9期)2016-12-12
声屏世界(2016年10期)2016-12-10
电脑知识与技术(2016年24期)2016-11-14
企业导报(2016年20期)2016-11-05
戏剧之家(2016年19期)2016-10-31
新闻前哨(2016年10期)2016-10-31
