
社交网络推荐系统
2016-12-15 20:51张翠莲
电脑知识与技术 2016年27期
张翠莲

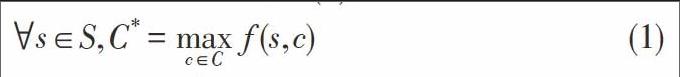

摘要:社交网络之“热”让人们对它的研究也越来越深入,推荐系统是现今社交网络的重要组成部分,通过网站推荐操作也能够更好地提高商业效益,因此也成为人们研究社交网络的重点。而推荐系统作为一种应用程序,程序的完成都需要有推荐算法作支撑。该文详细介绍各类有关的推荐算法,其主要目的是为了能够对社交网络推荐系统的推荐机制有更加深入的认识,并能够掌握和应用其中的一些推荐算法。
论文从对社交网络的介绍开始,通过详细对各个算法阐述,能够对社交网络的推荐机制有更好的理解。
关键词:社交网络;推荐算法;数据挖掘
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)27-0250-03
1 社交网络现状
网络作为21世纪人们互动的平台,给予人类另外一个包含大量资源的世界。人们可以方便快捷地获取所要的资源。 早期的社交网络,主要是指web1.0的社区,主要是由论坛,聊天室等形式组成,这一时期的社交网络系统单一,规模也不大。出现web2.0社区之后,逐渐出现了社交网站,社交网站拥有web2.0的特点,并且希望能够为用户提供一种类似真是社会交流的网络服务平台。
社交网络如今已经拥有着成千上百万个用户,并且占据着一些用户生活的不小的一部分。 在美国Facebook被很多民众使用,在日本,Mixi被人们熟知,在中国,新浪微博,腾讯qq, 微信等几乎被所有网民知晓。
社交网络使得网络与人的关系更加紧密,但同时也产生了大量的数据,这些数据的产生不仅给互联网公司造成了烦恼,更使得用户面对海量的数据信息不知作何选择。现今的社交网络,通过分析用户的行为为用户选择他们所感兴趣的资源,从而有效地保持网站用户量并且获得更多的用户,能够促进产品的开发以及企业更好的运营,让公司更好的发展。因此我们需要一种或多种有效的推荐算法来更好地更为准确地达到这种效果。
2 社交网络推荐系统概念
2.1 社交网络
SNS是social network service的缩写,翻译为社会性网络服务,是为了帮助人们建立一种全球化社会化的网络服务,SNS网站就是运用这一社会性网络服务的社交网站。社交网络即social network就是由这类网站建立起来的网络。
2003年,在线社交网络首次被提出,但是2006年才开始出现SNS比较完整的定义。
社交网络的核心在于用户之间的联系,其理论主要源于“六度分隔理论”。
该理论阐述,任何两个陌生人之间可以通过六个人就可以有所联系,通过这一理论,任何人的社交网络圈子都会继续扩张,形成一个关联全部人员的“社会化网络”。
2.2 推荐系统
推荐系统最初的研究是在其他领域中,例如认知科学,信息检索等。由于互联网以及电子商务的快速发展,推荐系统逐渐成为互联网领域中的重要研究对象。
推荐系统是利用一些可行的推荐方法向用户推荐候选对象的一种系统。用户可以主动向推荐系统提供他们的偏好或者请求,或者通过推荐系统来发现用户的隐式需求,由推荐系统来采集用户的偏好,然后将推荐信息给用户使用。推荐系统的模型图如图1所示:
推荐系统形式定义为:设S是所有要研究的用户对象集合,C是所有能够被推荐给该用户的那些对象的集合。C中的特定对象c相对于用户s的推荐度大小我们用函数f()表示,其中f:S*C→R,R是一定范围中的非负数,那么我们的推荐问题就是寻找能够使得R最大的对象,如式(1):
推荐系统中偏好获取的方式有如下两点:
显式获取:
通过网络中的问卷调查等相关反馈,让用户选取自己的喜好对象,从调研中发现用户的偏好行为。然而这一获取方式并非十分有效,因为大多数用户会由于各种原因而不会积极参与到调研之中,从而使得数据的准确性收到干扰。显示获取中主要要求用户对各种对象进行评分或评论,最好能够提出自己的建议。
隐式获取:
隐式获取不需要用户的主动参与,通过用户以往的行为来判断用户将来可能的操作,这一获取方式能够更好地得出结果,一般来说,隐式获取主要研究用户的浏览记录或者反复性的行为操作等。本研究中将用到的获取用户偏好的方法就是隐式获取的方式。
3 推荐系统算法
推荐系统算法,即通过分析已有对象的行为或者属性,利用一些数学上的算法来得出更可能满足该对象需求或者与该对象更加相似的对象。 此类算法很多,不同的算法分析多种多样,得到的结果也不尽相同,以下简单介绍一些相关的算法。
3.1 协同过滤算法
协同过滤算法被人们研究的比较深入,此算法也经常被应用到推荐系统中,协同过滤算法通过分析用户兴趣,在用户中找到与目标用户有相似兴趣的用户,通过这些用户对某一信息的相似评价来达到对这一信息的预测。此类算法可以细分为以下几种:
3.1.1 基于用户相似算法(user similarity)
基于用户相似算法的目的是为了通过对很多其他用户的喜好进行搜集评价来对某些用户自动进行预测。尤其是通过对那些与目标用户相似性程度高的用户进行喜好搜集。
用表示用户u对某一属性a的评分,并且让表示用户u属性的集合,那么对于用户u给属性a的平均评分为:
根据协同过滤,预测用户u对属性a的评分r为:
其中表示最相似于用户u的用户集合,表示用户u和用户v之间的相似度,是一个正态因子。如果只知道一些个体用户的属性集合,这时候我们不是明确的评估,而是主要预测将来最可能被用户偏好的属性集合。这样一来,上式可由式(4)替代:
其中表示用户u的属性a的推荐分数,是用户属性的二分网络的一个邻接矩阵的一元(如果用户v搜集了属性a,=1,否则=0)。
上述式子中,只有与用户u最相似的用户才会被考虑在内。为了保证,邻居选择策略经常被应用在:1) 相关阈值,它基于选择所有用户v,他们的相似度suv超过一个给定的阈值;2) 矩阵中最大化数目的邻居包括选择k个最相似于用户u的用户,这里k是算法的一个参数。这种选择最接近用户的计算通常会导致更好的结果。
3.1.2 基于项相似算法(item similarity)
这里我们暂且把项理解为属性,我们用属性-属性相似度替代用户-用户相似度,最简单的方式就是用平均加权的方式估算未知的排序优先权:
其中T是被用户u评估的属性的集合。
这个算法的一个优点就是其属性之间的相似度相比于用户之间更加趋与静态化,这样就允许它们之间的值可以在线下的时候也能够用于计算。
3.1.3 slope-one算法
slope-one 算法最简单的表达式为,其中b是一个常量,x是变量表示评分。它除去属性的平均评分,然后比较一个属性(item)比另外一个属性的相似度多多少。例如,考虑一种情况,当用户i给属性 a评分为1,给属性b分数为1.5,而用户j给属性a 2分。slope-one算法就预测用户j将对属性b评分分为2+(1.5-1)=2.5。
slope-one算法既考虑其他用户对同一属性的评价相关信息,也考虑了此用户对其他属性的评价。特殊情况下,只有已经评价了那些与目标用户相同的属性的用户以及目标用户已经进行了评估的属性是我们包含在我们要预测所要用到的过程中的。用W(a,b)表示那些已经对属性a和b进行评估的用户集合,属性b与a之间的平均偏差表示为:
给定一个一直的评级r,slope-one预测u在属性b上的评估为,一个合理的整体预测就是他们的平均值:
其中S是已经被u评价过的并且和属性b同时被评价的属性的集合。要注意预测时候,不管此时有多少用户同时评价过a和b,要保证不同的属性a都有相同的加权。考虑到的可信度依赖于|W(a,b)|,我们可以引进一个加权过得slope-one算法:
另外一个对基础slope-one算法的改进的方法是通过一个给定用户将所有属性的集合分割为偏好属性和非偏好属性两个集合。从这些偏好属性和非偏好属性中,两个分开的预测相结合而派生出一个最终的预测。用和分别表示用户的偏好属性和非偏好属性,我们先认为这两个集合中都有属性a,b。那么偏好属性与非偏好属性之间的偏差为:
那么基于属性a的评分而对属性b上的预测是或是,具体选择取决于目标用户是否偏好属性a,那么我们就有二维slope-one算法:
公式中的加权的选择与上一slope-one类似。
以上论述也表明了,slope-one算法可以超越线性回归的方式(比如评估表达式为f(x)=ax+b)并且计算所有变量的一半。这种简单的接近预测同样也减少了我们的存储空间以及我们运算的复杂度。slope-one算法已经成为一种其他算法改进的借鉴,能够更好地提高预测准确度。
3.2 聚类
聚类算法通过一定的评分方式将用户聚类,然后对每个类进行进一步分析计算。通过相似度进行聚类的算法最为常见。聚类算法的用途很广泛,比如商业上,可以利用不同的聚类方法将消费者划分为不同的消费群体,从而更加能够了解到消费者的行为模式,帮助商家更好地盈利。
3.3 基于内容的推荐
这类算法主要用于信息检索方面,通过用户已有的搜索记录来预知用户即将可能浏览的页面。基于内容的推荐,主要注重文本的相似度,比如网络中大部分搜索引擎就是根据这一算法搜索到页面。
基于内容的推荐算法,简单来讲就是通过用户a对某一物品s1的评价u(a,s1)来估计该用户对于某一与s1相似的物品s2的评价u(a,s2)。例如,在网站推荐中,我们目的是要推荐某一网站给用户a,那么基于内容的推荐算法就试图在该用户对以往网站评价高的网站中分析出它们的相同之处(比如某些类似的应用,网站页面设计等)。那些和该用户偏好相同的网站将被推荐给该用户。
更加形式化说明该算法,假定cons(a)表示物品a的一系列特征,这些特征可以用来确定该物品是否能够得到推荐。前面已经讲到,基于内容的推荐算法经常运用在信息检索也就是文本查询方面。设词在文档中的权重为,这一权重可以有多种定义方法。
信息检索里,一个比较常用的用来确定词语权重的指标为TF-IDF。TF-IDF定义为:设n是可以被推荐的文档的总和,词在文档中出现的次数为。则有在文档中的词频为:
其中是所有关键词出现在中的最大值。
同时有在该文档中的倒文档频率定义为:
在文档中的TF-IDF的权重为:
文档内容为:
用liked(c)表示包含用户偏好的集合。可以定义它为向量,每一个表示对用户c的重要程度。
在基于内容的推荐算法中,定义效用函数u(c,s)为:
3.4 其他推荐算法
当然还有其他各种类型的推荐算法,或者各种算法相组合而得到的算法。这些推荐算法的研究,让我们对推荐系统更为深入地了解。不同的研究论题,可能只有以上一种或者几种算法才合适,在我们进行研究的时候要尤其注意算法的选择。
4 结束语
经过近几年互联网的发展积累,社交网络逐渐成为互联网的主要应用之一。社交网络的各个功能也在逐渐完善化,细分化,社交网络也逐渐成为新闻传播的重要方式,让人们在其中进行即时的互动,通过调查发现,越来越多的用户倾向于从社交网站中掌握新闻动态。
推荐系统作为社交网络的重要组成部分,至今为止,对它的研究还没有特别深入,还有很多可以挖掘的地方,比如推荐算法的选择与改进,研究时候对于数据集合的选取与分析等等。从阅读过的多篇文献中发现,推荐算法已经有不少人在研究而且得到有效的运用,这便给我们研究社交网络推荐系统的推荐算法提供了很好的理论基础。相信今后会有更多有关社交网络推荐系统的新发现,我们拭目以待。
参考文献:
[1] 丁华俊. SNS发展探析[J]. 中国证券期货, 2011(4): 170-171.
[2] 蒋翀, 费洪晓. 个性化推荐系统中的混合用户偏好获取[J]. 计算机系统应用, 2010, 19(10): 203-206.
[3] 吴俊杰, 刘耀军, 赵月爱. 基于用户行为的网站推荐系统模型[J]. 山西电子技术, 2011(6): 66-67.
[4] 郑佳佳. 社交网络中基于图排序的好友推荐机制研究与实现[D]. 杭州: 浙江大学, 2011.
[5] 林大瀛. 基于分组聚类的SVM训练算法[D]. 广东: 华南理工大学, 2003.
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
