
考虑旅客出行满意度的高铁列车开行方案优化
2021-09-12 04:57樊昊煜黄志鹏
铁道科学与工程学报 2021年8期
樊昊煜,黄志鹏
(1. 兰州交通大学 交通运输学院,甘肃 兰州730070;2. 包头铁道职业技术学院,内蒙古 包头014060)
高速铁路上,同一出行起讫点(OD)之间通常开行多列平行列车[1]供旅客出行选择。面对高密度的列车服务,旅客的出行需求不仅仅是对传统铁路客运的核心产品——“位移”的需求,同时对出行的方便性和舒适性提出了更高要求。在同一线路区段上,高铁列车速度差异性较小,影响旅客出行方便的主要因素是出发时间是否符合旅客的期望;另一方面,不同高铁列车提供的高品质客运服务差异性也较小,影响旅客舒适性的主要因素表现在列车是否拥挤。制定一个符合旅客出行期望的列车开行方案既能满足旅客对出行时间的偏好,又能引导旅客合理选择出行时间,避免出行拥堵。因此,考虑旅客满意度,建立数学模型并运用计算机仿真技术编制的列车开行方案具有重要的工程实践价值。列车开行方案问题是轨道交通运营优化的一个核心问题,也是国际交通和运筹学界广泛关注的热点问题,国内外学者在列车开行方案和客流分配领域做了大量的研究工作。在早期列车开行方案的研究中,国内外学者认为旅客只是为了完成“位移”需求。因此,通常根据日平均旅客出行数据和一定的规则设计列车开行线路,这类方法称为预分配方法[2]。这类研究是站在运输企业的角度,在满足基本运输需求的约束下优化运输方案,使运输成本最小化[3−5]。随着出行条件的改善,旅客对服务质量的需求逐渐提高,最显著的变化就是对出行时间的要求。学者们开始关注旅客服务质量和列车开行方案的关系问题[6−11]。随着高铁的大力建设,高铁列车开行方案问题引起了学术界的关注。因为高铁客流的出行需求特征较普通客流有很大的差异,一些学者试图建立双层规划模型对该问题进行数学描述,并取得了一定的成果[12−15]。本文综合考虑旅客出行时间的方便性和列车的拥挤程度,定义并量化旅客的出行满意度。优化决策不同发车时段内各停站类型列车(服务的OD 客流不同)的开行数量和流量分配方案,使得铁路运输企业的运输成本最小,同时旅客的满意度最大且均衡,充分体现铁路运输服务的公平性。
1 问题描述
1.1 高铁车站和列车类型
在一条高铁线路上,有m个车站,从始发站1开始,按照车站的邻接顺序依次标记车站2,3,…,m。令S为车站集合,S={1,2,…,m},s表示该高铁线路上的任一车站,s∈S。在这条高铁线路上,列车运行速度相同,列车按照停站方案来划分类型,即每一类列车对应一种停站序列。令H为列车类型集合,用h标记任一类列车,h∈H。
1.2 旅客满意度
1.2.1 出发时段方便度的量化
相同类型旅客对不同时段出发的偏好性具有明显的差异性,本文通过数据调查的方法,对郑州东-西安北高铁线路上的工作日(2019/11/4−8,2019/11/11−15)客流的期望出发时段进行调查。获得各个出行时段的平均出行需求。并以出行量最大的时段作为出行方便度标准,令其取值为1;其他时段按照该时段出行人数与方便度最高时段出行人数的比值获得各个时段t∈T的方便度系数Ct,0 ≤Ct≤1。
1.2.2 旅客舒适度的量化
在出发时段t∈T,高铁的服务能力为Nt,当该时段的客流量qt逐渐增大时,旅客的出行舒适度会因为进站、取票、候车等环节的排队时间及乘车环境因素而逐渐下降。通过对831份有效问卷中旅客对出行人数与服务能力比值的敏感度进行数据拟合,该数据变化趋近于自然指数函数。本文将最大舒适度设置为1,当qt/Nt增大时,舒适度逐渐下降,直到趋近于0。
1.2.3 满意度函数
通过以上分析,构建了满意度函数,如式(1)所示。
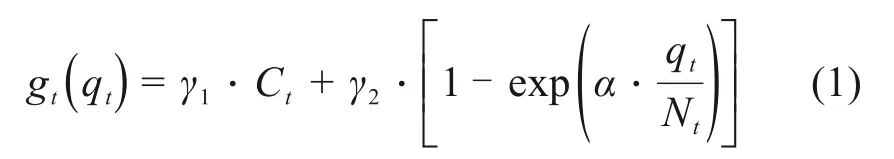
其中,α为调节系数;Ct为与流量无关的时段方便度;γ1和γ2分别为出发时段方便性和舒适性的权重系数,γ1+γ2= 1。
1.3 优化方案
如前所述,本文综合考虑高铁运营企业的运营效益和旅客的出行满意度,优化列车开行方案。在高铁出行旅客数量和列车票价确定的条件下,铁路运营企业的收入是相同的,而不同停站方案的列车,其开行成本是不同的。因此上层规划的目标可以简化为运输成本最小。下层为用户平衡(User Equilibrium,UE)配流模型,根据UE 模型目标为最小化的特点,故设置旅客的不满意度最小且相等,等价于满意度最大且相等。上下层的关联关系如图1所示。

图1 优化方案示意图Fig.1 Schematic diagram of optimization plan
上层规划确定的发车时段和列车类型会影响旅客的满意度。下层规划会按照满意度均衡的配流规则,将OD 客流需求加载至上层规划确定的列车开行方案上。当流量发生变化后,又会影响上层规划的决策,上层随之会做出调整。这样上层规划的列车开行方案和下层规划的配流结果循环反复的调整,直至达到预先设定的可接受停止条件为止。
2 模型和算法
2.1 模型构建
2.1.1 符号说明
为上层决策变量,表示第t时段第h类列车的开行数量,列;qt为下层决策变量,表示第t时段,从始发站出发的客流量,人;qs为从始发站到s站的客流量,人;为始发站到车站s的客流被分配到第k个出行时段的客流量,人;Ft为t时段,始发站的发车能力,列;θh为第h类列车可以为始发站提供坐席的比例,%;与该类列车沿途停站的预留坐席有关;Y为列车的定员数,人;Rh为第h类列车的单位开行成本,列/万元;Ks为始发站到s站间,旅客可出行时段的集合;为0-1 参数,当第h类列车的停站序列包含车站s时,取值为1,否则为0;为0-1 参数,当k=t时,取值为1,否则为0。
2.1.2 上层规划

其中:式(2)为目标函数,表示所有列车的开行成本;式(3)为发车能力约束;式(4)为各时段服务能力约束,即发车时段内列车的服务能力要大于客流分配量;式(5)为沿途各到达站的服务能力约束,即列车分配给沿途各上车站的能力要大于客流分配量;式(6)表示到达s站的客流占比,当比值越大时,在t时段列车xth需要为s站分配的座位数量相应增加,当前时段旅客的出行人数多了,进一步体现旅客在当前时段的出行意愿。
2.1.3 下层规划
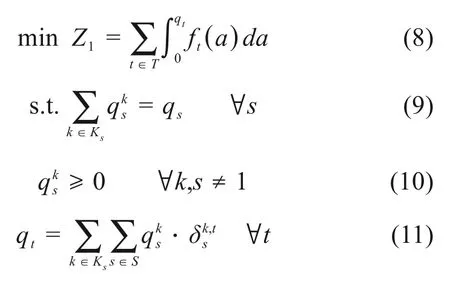
其中:式(8)为目标函数,在本文中的物理意义为当需求qt在时段t出行时,该时段出行旅客的不满意度,其与式(1)的满意度函数满足关系式ft(qt)=1-gt(qt);式(9)满足客流守恒,即客流需求被分配到了不同的时段上;式(10)表示始发站到车站s的第k个可行时段流量为正值;式(11)表示任意时段t的流量由不同OD的客流叠加构成。
2.2 算法设计
论文所建模型是一个双层规划问题,它被公认为是极难求解的优化问题之一。本文基于遗传算法中的编码/解码规则,设计了符合模型特点的启发式算法对上层规划进行求解。同时,运用Frank-Wolfe方法求解下层规划。算法流程如下。
Step 1:初始化
按照染色体编码规则和约束条件,随机生成规模为popsize的初始可行解种群;置上层规划最优目标Z2*= 0;置最优开行方案集Ω*为零向量;迭代次数i= 0。
Step 2:遗传操作
对初始种群进行选择、交叉和变异操作,搜寻当前种群中适应度最高的可行解(开行方案)Ω(i),并更新最优开行方案集Ω*= Ω(i);迭代次数i=i+ 1。
Step 3:判断和检查
运用参数判断当前方案中第t时段开行的第h类列车的停站序列与各到达站s的匹配关系,生成集合Ks;检查,当Ks≠∅,∀s时,转Step 4,否则转Step 2。
Step 4:用户平衡配流
对于当前开行方案Ω(i),用Frank-Wolfe方法求解下层规划,得到符合Wardrop 的UE准则的。
Step 5:运输能力检查
按照式(3)检查各时段始发站能够提供的客票数与平衡配流结果的匹配关系,如果满足转Step 6;不满足转Step 2。
Step 6:将当前开行方案Ω(i)和时段配流结果代入上层目标函数,计算目标函数Z2;如果,则令
Step 7:终止检验
如果迭代次数i大于迭代上限Ge,输出最优解Ω*,否则,转Step 2。
3 算例
3.1 参数设置
本文以郑西高铁走廊为例,为了方便表示,将西安北站编号为1,按照上行方向依次编号,如图2所示。

图2 郑西高铁走廊示意图Fig.2 Schematic diagram of Zheng-Xi high-speed railway corridor
始发站西安北站到沿途9个停靠站的近期、中期和远期预测客流数据,如表1所示。本文分别对不同客流需求强度下始发站西安北站出发前往沿途各站的客流需求为基础,进行列车开行方案和客流分配优化。

表1 始发站1到各停靠站的客流需求Table 1 Demands of passenger flow from original station 1 to each stop 人
根据列车停站方案设定列车类型(h)的备选集,表2 所示为本算例的6 种停站方案的列车。其中“1”表示在对应的车站停车,“0”表示在对应的车站不停车。始发站列车的坐席比例θh(%)根据西安北站的客票分配比例设定,列车开行成本Rh根据列车运营数据设定(单位:万元)。
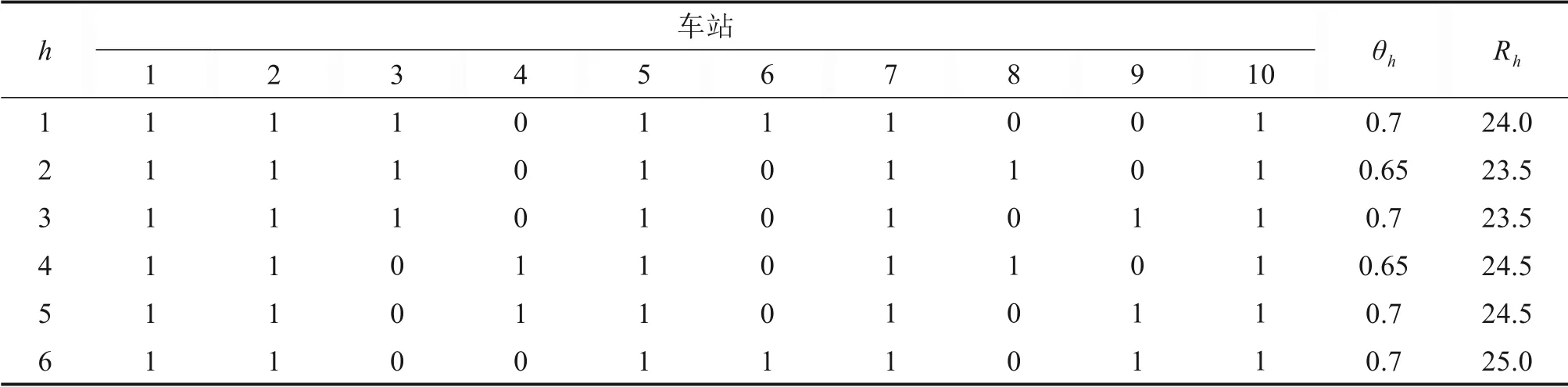
表2 列车备选集和参数Table 2 Alternative train set and parameter
将西安北站的列车运营时间按照每2 h 为1 个时段将全天运营时间(7:00−23:00)划分为8 个时段,并对西安北站客流的期望出发时段调查数据进行统计,按照1.2.1 提出的方法,可以得到8 个时段t的方便度Ct,如表3所示。

表3 列车备选集和参数各时段的出行方便度Table 3 Travel convenience of each period
最大服务能力Nt= 12 000,∀t;列车定员Y=1220,调节系数α= 0.5。种群规模popsize= 200,交叉概率Pc= 0.95,变异概率Pm= 0.05,最大停滞迭代次数为10,最大迭代次数为100代。
3.2 计算结果
3.2.1 下层规划的计算结果和分析
通过matlab2014a 软件编程,对该算例进行求解,下层规划的客运需求平衡分配结果如表4 所示,各时段的出行阻抗(不满意度)如表5 所示。通过表4 和表5 的数据不难发现,旅客出行需求规模为40 000人/d时,平衡配流后,各时段旅客出行阻抗为0.284 0,即满意度为0.716 0;当旅客出行需求规模为60 000人/d时,平衡配流后,各时段旅客出行阻抗为0.341 3,即满意度为0.658 7;当旅客出行需求规模为80 000人/d时,平衡配流后,各时段旅客出行阻抗为0.393 3,即满意度为0.606 7。

表4 各时段的出行方便度各时段的客流量分配结果Table 4 Passenger flow distribution in each period

表5 各时段的出行阻抗(不满意度)Table 5 Travel impedance in each period(unsatisfaction degree)
通过以上数据可以看出,当不改变车站服务能力的情况下,流量不断增大时,旅客满意度会逐渐降低。当客流规模增加到为80 000人/d时,将车站服务能力Nt由12 000 调整为15 000,再次计算,流量分配及时段阻抗结果如表6所示,阻抗为0.351 8,满意度为0.648 2。因此,流量不断增大时,可以通过提高车站服务能力来降低出行阻抗,从而提高旅客满意度。

表6 提高车站服务能力后各时段客流量分配结果及出行阻抗Table 6 Passenger flow distribution and travel impedance after enhancing the service capacity of the station
在表4 中,不难发现,当客流规模为40 000人/d时,流量分配结果显示,第8时段的流量为0。检查表5 中客流量为40 000 人/d 的数据,可以发现,第8 时段的阻抗为0.325 0,明显大于其他时段。根据平衡配流理论,当一条路径的阻抗明显大于其他路径时,将不会有流量加载,即没有旅客会选择在这个时段出行。
以远期80 000人/d的客流规模为例,各时段客流分配结果如图3 所示,其中第2 和第8 时段为客流高峰期。这与各时段的方便度系数的趋势线相符合,具有明显的波峰与波谷,且2个高峰出现在早晚高峰时段。

图3 各时段的客流量分配结果与方便度Fig.3 Passenger flow distribution and travel convenient degree in each period
3.2.2上层开行方案优化结果和分析
通过下层规划的流量分配结果和上层规划开行方案的反复迭代,最终经过100 代的进化筛选,得到8 个时段内6 种列车的开行数量(列车开行方案),如图4~6所示。

图4 客流量为40 000人/d时列车开行方案Fig.4 Train operation plan with daily passenger demands of 40 000 people

图5 客流量为60 000人/d时列车开行方案Fig.5 Train operation plan with daily passenger demands of 60 000 people

图6 客流量为80 000人/d时列车开行方案Fig.6 Train operation plan with daily passenger demands of 80 000 people
通过计算数据可知,各类列车均有开行,能够服务沿途所有车站的旅客乘降。但是各类列车的分布不均匀,这与不同OD 客流量大小有关。当客流量为40 000 人/d 时,共开行列车49 列,其中第3 类列车开行数量最多,达到18 列,占全部列车的36.7%;当客流量为60 000 人/d 时,共开行列车70 列,其中第2 类列车开行数量最多,达到18列,占全部列车的25.7%;当客流规模为80 000人/d时,共开行列车87列,其中第4类列车开行数量最多,达到19列,占全部列车的21.8%。
4 结论
1) 旅客的满意度是动态的,当旅客选择期望出行时段出发时,如果客流量较大,由于拥挤带来的阻抗也随之增大,这时旅客的满意度反而会下降。
2)日客流量规模较小时,客流按照UE 规则分配后,其出行阻抗较小,即出行满意度较大。随着日客流量规模增大后,旅客的出行满意度随之下降,由表6的计算数据不难发现,可通过提高车站的发车能力来提高旅客出行满意度。
3) 本文构建的双层规划模型能够描述旅客出行决策和高铁列车开行方案优化的动态博弈过程。但是,本文只研究了一条高铁走廊列车开行方案的优化问题,并未涉及带有换乘站的高铁网络列车开行方案,这也是论文的后续研究方向。
猜你喜欢
环球时报(2022-12-12)2022-12-12
现代电子技术(2021年15期)2021-08-06
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
数学大王·中高年级(2019年5期)2019-06-09
中国生殖健康(2019年8期)2019-01-07
综艺报(2018年17期)2018-09-14
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
