
基于小样本学习的多因素单粒子翻转截面预测
2021-09-11 01:38于泽芳
上海航天 2021年4期
刘 婷,杨 博,于泽芳
(上海交通大学电子信息与电气工程学院,上海 200240)
0 引言
在航天电子系统中,空间辐射环境带来的单粒子效应评估是系统可靠性的一个重要研究领域[1],其主要形式为器件的单位面积翻转截面σ(单位cm2/bit)与重离子线性能量传输(Linear Energy Transfer,LET)(单位MeV/(mg/cm2))的关系曲线σ-LET,一般通过地面辐照实验数据和经验模型(如Weibull 曲线)进行推算。随着卫星系统功能日趋多样化和复杂化,高性能处理器、现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)和大容量存储器等先进半导体器件被引入航天电子系统组成,用于满足星载任务的算力和存储需求。这些器件大多具有结构复杂、可配置性强等特点,体现在可调的电压、运行频率、缓存机制、容错机制等方面。这些配置参数与来自空间环境的离子总剂量(Total Ionizing Dose,TID)、电磁干扰(Electromagnetic Interference,EMI)等环境因素一起,形成了影响真实环境下单粒子翻转截面特性的多因素集合。然而,在现有常规辐照实验中,受限于实验条件和成本,测试通常很难覆盖这些影响因素集合的可调范围,导致σ-LET 评估结果的不准确[2]。
国内外已有部分研究通过变量控制的方式,分析辐照实验中多因素效应对σ-LET 曲线的影响。BENFICA 等[3]通过协 同实验分 析了TID 和EMI 对FPGA 芯片单粒子翻转(Single Event Upset,SEU)截面的影响,发现电源VDD 上的10%以上EMI噪声和TID 带来的印记效应(Imprint Effect)均可能导致SEU 截面升高。ZHENG 等[4]发现在65 nm DICESRAM 中,TID 也会带来SEU 翻转截面的升高。VARGAS 等[5]提出了面向28 nm 多核处理器MPPA-256 的单粒子事件(Single Event Upset,SEE)测试方法,其中,动态响应测试通过改变CPU 运行模式和缓存使能、使用动态频率/电压、部署不同类型应用等因素,分析单粒子失效截面的变化。姬庆刚等[6]分析了静态随机存取存储器(Static Random-Access Memory,SRAM)器件中γ 射线模拟的TID 剂量对后续重离子SEU 截面的影响,发现在静态和动态场景下TID 越高,对SEU 敏感性影响越大,饱和截面也会明显增大。王利斌等[7]通过脉冲激光粒子注入,发现在双极电压比较器电路中,TID 对单粒子瞬态效应的影响取决于电路的工作状态。由于目前多因素σ-LET实验缺乏统一规范,这些案例的实验条件通常差异较大,对应结果的数据结构化程度差,难以为通用场景下的σ-LET 评估中提供有意义的量化指导。
针对上述问题,本文基于现有多因素辐照实验数据,提出了数据驱动的多因素σ-LET 建模方法。首先,根据现有多因素σ-LET 实验结果构建了非结构化小样本数据集,作为多因素σ-LET 预测的数据基础;其次,针对自建数据集中的样本规模和特征维度有限问题,设计了卷积神经网络特征提取、小样本学习匹配网络特征融合和集成学习极端梯度提升(eXtreme Gradient Boosting,XGBoost)回归的级连网络结构,利用非结构化小样本数据集以端到端的方式训练级连网络,实现任意给定因素条件下的σ-LET 曲线预测,为多因素影响下的通用系统单粒子效应评估提供了一种新方法。
1 多因素σ-LET 曲线预测的问题描述
根据美国国家航空航天局(NASA)及其合作厂商相关实验室的辐照实验数据[8-17],本研究收集了9种CPU 和3 种FPGA 共计128 组多因素单粒子辐照实验数据,涉及的因素包括LET、辐照总剂量TID、电磁干扰EMI 频率、数据位宽、工艺尺寸、存储容量、时钟频率等,单个样本的因素数量从7 维到18维不等,取值包括布尔值、字符串、整数和浮点数等多种类型,样本之间的特征重合程度较低。为了最大限度保留因素特征信息,本研究采用以下方式对原始的半结构化特征数据进行结构化预处理。
1)空间映射。将所有字符串型特征映射为独热码,对于缺失较多的非共有特征,扩充对应的布尔型属性标志特征维度,以此最大限度地保留属性信息。
2)均值填充。对于仅有较少样本缺失的特征,将同类型样本器件该属性的均值填入空缺的位置。
结构化预处理后的小样本数据集的特征维度扩充至31 维,其定义见表1。对应的结构化特征空间A=(X1,X2,…,Xn) ∈R32×182,每个样本Xi由1×31的特征向量xi和对应的单粒子翻转截面值标量yi组成。因此,本研究的问题可以描述为在小样本特征空间A上构建xi到yi的连续映射f:xi→yi。

表1 辐照实验小样本数据集中的结构化因素特征定义Tab.1 Definitions of structured factor features in the few-shot dataset of radiation experiments
2 基于小样本学习的多因素翻转截面预测模型
根据小样本数据集样本类别少和规模小等特点,本文提出的预测模型结构如图1 所示,分为特征提取网络、特征融合网络和回归网络3 个部分。
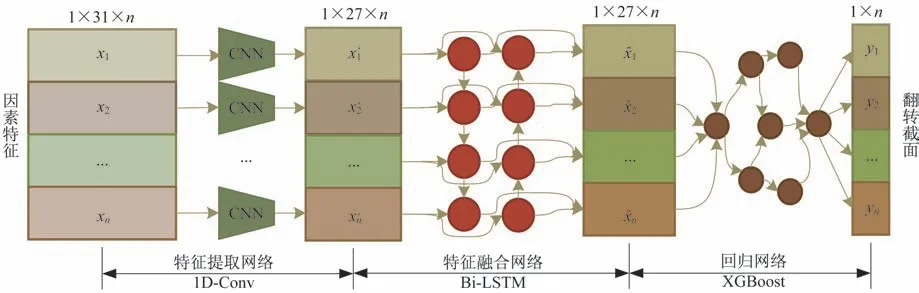
图1 多因素翻转截面预测模型结构Fig.1 Structure of the multi-factor cross section prediction model
特征提取网络用于学习单个样本不同特征之间的关联性,使用了3 层一维卷积层1D-Conv 和1层非线性激活层(ReLU)组成的卷积神经网络(Convolutional Neural Networks,CNN),所有卷积层均使用1×3 大小的卷积核。每个1×31 的输入样本xi的经过特征提取网络映射后转化为1×27 的向量,输入后续特征融合网络。
特征融合网络用于学习来自不同样本特征之间的关联性,使用了小样本学习(Few-Shot Learning)中的匹配网络(Matching Network)[18]作为主干结构。匹配网络是属于单样本学习(One-Shot Learning),视每个样本为一个独立类别,将单粒子翻转截面值yi看作输入向量的类别“标签”。通过一次训练多个任务,完成对输入样本的编码。匹配网络由基于递归神经网络的双向长短时记忆网络Bi-LSTM[19]构成,使用完全上下文嵌入(Fully-Conditional Embedding)机制生成不同样本特征之间的注意力,将输入的序列映射为等长的序列。
回归网络使用了基于Boosting 集成学习的XGBoost(eXtreme Gradient Boosting)回归算法[20],将特征融合网络输出的序列映射为连续标量yi。与传统线性回归模型相比,XGBoost 将多个决策树弱分器集成为强学习器,在小规模训练集上具有更好的泛化能力。
整个流程使用端到端联合训练方式,训练算法和模型收敛过程分别如图2(a)和图2(b)所示。其中,训练集和测试集采用全数据集混合下的5折(5-fold)随机划分,下游XGBoost 回归器输出的损失(Loss)将回传到所有上游网络,通过优化器Adam 进行参数更新,此过程称为一个训练回合(Epoch)。图2(b)显 示,级连网络 在10 个epoch左右达到收敛状态,即损失稳定在一个较低的水平不再继续降低。上述模型的搭建、训练和测试在PyTorch 框架下完成,由于采用了针对小样本数据集的轻量化结构设计,级连网络在3.2 GHz的Intel(R)Core(TM)i7-8700 CPU 上完成一 次训练和测试推理的时间在3 min 以内,具有良好的实时性表现。

图2 级连网络的端到端训练过程Fig.2 End-to-end training procedure for cascaded networks
3 测试结果分析
3.1 消融测试
为了验证预测模型各阶段的有效性,修改特征融合网络和回归网络配置下进行消融测试,预测结果的均方根误差(Root Mean Square Error,RMSE)对比见表2。可以发现,在小样本数据集场景下,特征融合网络对精度影响最大,XGBoost 性能优于经典多元线性回归器。

表2 结构消融测试结果Tab.2 Results of structure ablation tests
为了测试模型的泛化性,采用不同数据集随机划分方式,对模型的跨器件/跨类别性能进行多次测试,划分方式对应的数据规模和公共属性维度见表3。其中,跨器件表示使用训练集/测试集的数据来自同类型的不同器件样例,如使用FPGA 的器件A 训练和器件B 测试。跨类别表示训练和测试使用不同类型样本,如使用FPGA 训练和CPU 测试。有效特征维度表示随机抽取的样本中值不完全一致的特征数量。
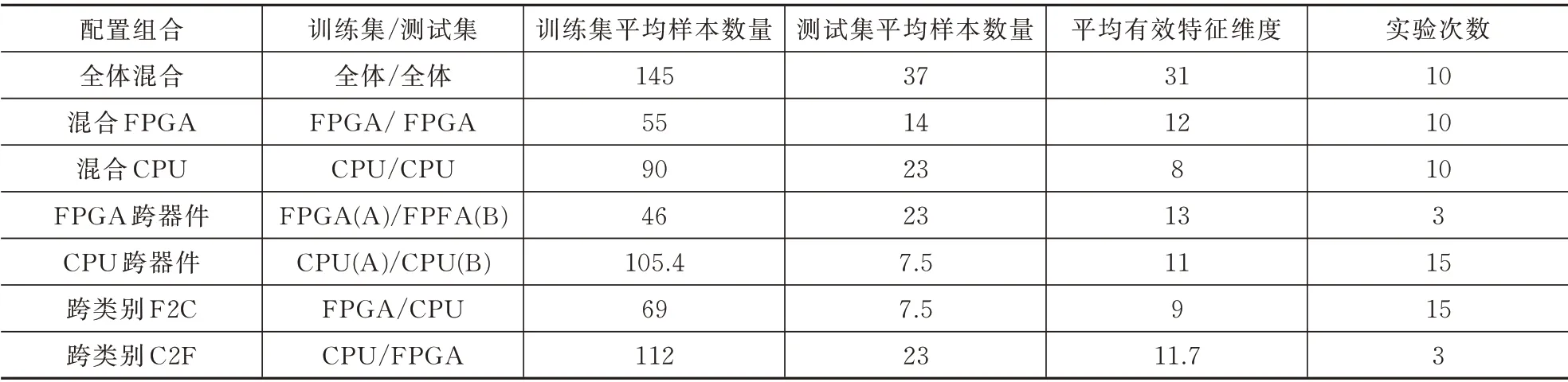
表3 域适应性测试配置Tab.3 Configurations of domain adaption tests
上述多轮实验的RMSE 的分布如图3 所示,可以发现小样本SEU 翻转截面预测网络的泛化性受样本公共特征维度的影响较大,具体体现在如下几个方面。

图3 不同训练/测试集划分的域适应性能对比Fig.3 Comparison of domain adaption performance of different training/test sets
1)在混合场景下,训练和测试场景数据分布相对接近,网络可以学习到更多样的特征,从而可以获得稳定准确的预测结果。
2)在跨器件场景下,训练和测试数据分布差异变大,预测误差开始上升。由于CPU 的器件种类(8 种)多于FPGA(3 种),体现出了更强的分布差异,导致CPU跨器件预测的精度和鲁棒性明显差于FPGA。
3)在跨类别场景下,训练和测试数据分布差异进一步变大,整体精度和鲁棒性远低于混合和同器件场景。同时,由于FPGA 的种类和样本数量均少于CPU,导致使用FPGA 数据预训练的模型在CPU 测试集上出现了大范围的精度波动。
从网络结构和域适应消融结果可知,最佳级连结构配置为1D-CNN 特征提取网络、匹配网络和XGBoost 的组合,最佳训练/测试配置为全体样本混合,后续章节的测试均基于此最佳配置。
3.2 因素重要性分析
级连结构中的回归网络XGBoost 作为基于梯度提升的集成决策树算法,除了完成回归预测,还能为输入特征提供重要性度量。本研究选择了分裂总增益(Total Gain)作为因素重要性的度量指标,其含义为使用某特征的分裂带来总信息增益值,使用全数据集混合训练获得的因素重要性分布如图4 所示。可以发现,除了LET、TID 剂量值(TID_krad)等环境因素,重要性排名靠前的影响因素还包括电压(Voltage)、测试部件(Device Under Test,DUT)、芯片类型(Type)、工艺尺寸(Feature_Size_Um)、运行频率(Freq_MHz)等实验配置因素。因素重要性度量可以帮助系统测试人员在有限开销下制定更有效的测试方案,还能够为卫星电子系统架构设计人员提供早期容错设计指导。

图4 通过XGBoost 中分裂总增益度量的因素重要性Fig.4 Factor importance measured via thetotal gain in XGBoost
基于上述因素重要性结论,进一步测试了关键设计性因素改变对全局σ-LET 曲线的影响,如图5所示。其中,默认(Default)为基线设置,LET 取值范围为0~15 MeV/(mg·cm-2)。可以发现,同等条件下的FPGA 饱和截面要远高于CPU,这说明FPGA 的抗辐照性弱于同等配置下的CPU,这和CPU微架构中存在的复杂屏蔽效应相关。同时,DUT 从全局变为D-cache 造成σ-LET 曲线的整体下移,工作电压的升高使得σ-LET 曲线前段下移,工艺尺寸降低时观测到了饱和截面的整体提升,这些趋势与辐照实验经验基本相符。值得指出的是,工作频率提高时观测到了σ-LET 曲线的降低,这与实际经验不符,可能是极端输入和多类型器件样本联合学习导致的偏差。
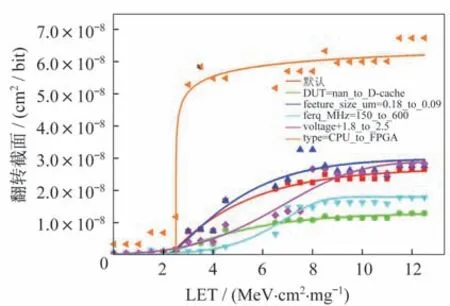
图5 关键因素对全局σ-LET 曲线的影响Fig.5 Effects of the key factors on the overall σ-LET curve
3.3 多因素σ-LET 曲线和系统失效率预测案例分析
为了验证小样本翻转截面预测的有效性,本研究以国产PowerPC750 架构处理器芯片SM750 为例,推导了给定因素配置下的系统组件σ-LET 值和系统失效率。其中,组件粒度的翻转截面值利用系统失效率(System Failure Rate,SER)(单位cm2·dev-1)进行度量,其上边界可以通过独立事件联合概率进行估算:

式中:Pc为SM750中组件c的硬件仿真故障注入失效率;σc(LET)为多因素预测模型计算的组件c在LET={1.73,4.06,8.19,12.90,18.50}MeV/(mg·cm-2)时的翻转截面(单位cm2/bit);Mc为组件c中的存储位数量;C为所有仿真故障注入组件c的集合。
对比国外PowerPC750 全芯片辐照结果[21],系统SER 预测的饱和截面边界和真实辐照实验处于同一量级(10-3)。
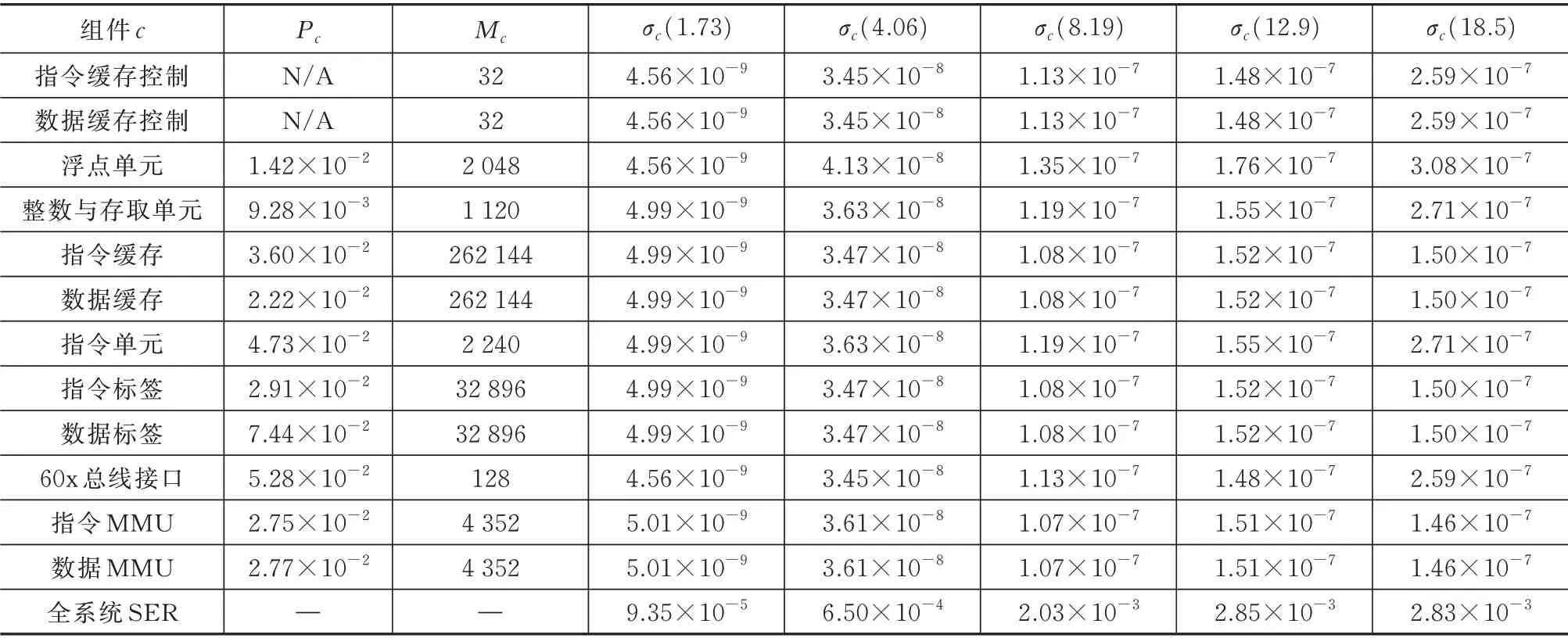
表4 SM750 处理器中组件单粒子翻转截面和全系统失效率的预测结果Tab.4 Prediction results of the component SEU cross sections and full system SER in SM750 processor
为进一步验证上述联合推导系统失效率边界的有效性,选择了LET=37.6 MeV/(mg·cm-2)时部件翻转截面σc(LET)Pc Mc预测结果与同等条件重离子辐照实验结果进行对比,完整结果如图6 所示。在部件方面,本研究使用的“多因素预测模型+硬件故障注入仿真”联合推导方法在寄存器文件(如浮点单元、整数单元等)、指令单元、缓存标签和MMU 等部件上的预测结果与重离子辐照实验比较接近,指令和数据缓存的预测高于辐照实验结果,控制逻辑类组件低于辐照实验结果。同时,利用部件结果推导的全系统SER 与辐照实验结果处于同一量级但略微偏高(约6.76 倍),这主要是有本研究采用了基于最差情况的上界估算策略,另外未知的实验配置也可能导致评估的偏差,如基准软件、系统运行模式、故障注入策略等。
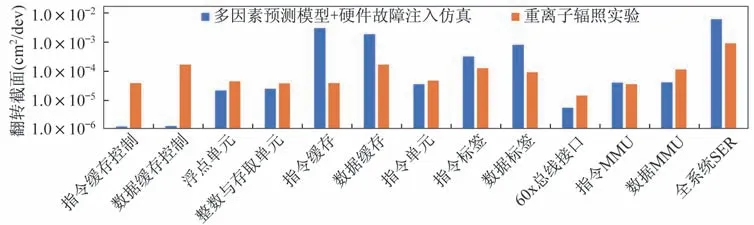
图6 联合推导与重离子辐照实验的翻转截面结果对比Fig.6 Comparison of the cross section results of joint derivation prediction and heavy ion irradiation experiment
4 结束语
本文研究了基于小样本学习的数据驱动方法在多因素单粒子翻转截面预测中的应用。通过构建特征提取、特征融合和集成学习回归组成的端到端级连预测模型,在小规模自建数据集上获得了具有良好泛化性的预测表现,对各因素的重要性和影响效果进行了量化评价。以国产处理器芯片SM750 为案例,结合硬件仿真故障注入和重离子辐照实验结果,证明了通过多因素单粒子翻转截面预测模型推导组件和系统失效率的有效性。由于本文所使用的自建数据集的参考文献数据来源均为国外器件,缺少国内器件样本,各类因素覆盖范围有限,个别场景预测结果存在不可忽略的偏差。因此,后续研究将继续扩充数据集,并与更多的目标器件的实际辐照实验对比结果。
猜你喜欢
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
考试与评价·高一版(2020年2期)2020-10-29
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
西南学林(2011年0期)2011-11-12
电子世界(2004年4期)2004-07-26
