
基于网格搜索改进随机森林的顾客满意度预测
2021-09-10 01:26:38张蓓蓓
北京信息科技大学学报(自然科学版) 2021年4期
张蓓蓓,胡 敏
(北京信息科技大学 信息管理学院,北京 100192)
0 引言
伴随着激烈的市场竞争,服务业逐步发展为顾客主导型行业,顾客满意度对服务业市场的影响日益提升。通常,顾客满意度来自消费者的亲身经历且具有实时性,可以帮助商家更及时、准确地了解消费者需求并改进产品;同时为潜在消费者购买产品或服务提供值得信赖的参考,是影响电子口碑传播的主要因素。
随着机器学习的发展,国内外大量学者开始采用机器学习方法进行顾客满意度的预测,目前随机森林算法在顾客满意度预测方面应用较广泛。如Baswardono等[1]通过对航空公司客户满意度分类,证明了随机森林算法比C4.5算法预测的精度更高。Bihar等[2]运用随机森林分类器将评论分为低质量和高质量,再用梯度增强回归器进行评分预测。杨东红等[3]发现评论回复在预测模型中影响最大,认为在较常用的机器学习算法中,随机森林和决策树算法预测的准确率较为理想。程平等[4]利用随机森林算法构造服务质量满意度预测模型,并实证该模型预测的拟合优度明显高于多元线性回归模型。
随机森林的预测性能良好,在顾客满意度预测领域已得到广泛应用。但大部分研究都忽略了参数选择对模型的重要性,通常根据经验选择参数。本文利用网格搜索(grid search)对随机森林算法进行优化调参,通过对随机森林中的决策树数量k和候选分裂特征属性数m等参数做优化选择,并结合具体案例进行分析,旨在提高预测顾客满意度评分的准确性和高效性。
1 模型建立
1.1 随机森林算法
随机森林(random forest)算法是一种基于决策树的集成学习算法,其本质就是由多个弱模型决策树输出为强模型的过程,可用于特征选择、回归问题和分类问题。由于随机森林算法抽取样本的随机性和选择特征属性的随机性,误差值会有一定的波动。为了减小其不确定性对参数选择和预测结果造成的影响,本文采用网格搜索算法优化随机森林,以取到超参数的最优值。
1.2 随机森林与其他模型的对比实验
为了验证在顾客满意度预测方面随机森林模型比其他模型更有优势,本文进行了对比实验。实验中使用线性回归模型及其正则化方法与随机森林模型作比较。为了准确地衡量预测评分与实际评分之间的误差,本文定义函数来计算各模型的均方根误差(RMSE),以便能更容易地评估各模型的预测效果[5]。均方根误差作为综合分析误差的指标之一,数值越小表明误差越小,此时模型的效果最好。均方根误差的计算表达式为
(1)


表1 各模型的预测评价指标
从表1可以看出,在本实验中,无超参数配置的随机森林回归模型预测的均方根误差最低,说明随机森林模型比其他模型更适合做顾客满意度预测。此研究结果比耿娟等[7]利用随机森林模型预测电影评分的准确率高很多;魏勤等[8]对现货市场数据构建的随机森林模型预测市场出清价格,并用交叉验证和网格搜索确定模型最优参数,其预测效果明显优于本研究模型。
1.3 模型参数率定方法
模型的参数选择在很大程度上影响模型的应用效果。为了减小取样随机性造成的训练偏差影响,在机器学习和统计分析等领域常采用K-fold交叉验证法来评价模型的泛化性能,将数据集随机地平均划分为K个互斥子集后,进行K轮的模型训练和评估,每一轮取1份作测试集,其余K-1份作训练集,训练模型并评估模型的准确性[9],根据K次迭代所得的均方根误差的平均值估计期望泛化误差,最终选择最小的平均均方根误差或最高准确率所对应的最佳优化参数,提高模型的稳定性及泛化性。
网格搜索法是一种穷举搜索的参数优化算法[10],该方法通用性较强且简单高效。其本质就是将参数空间划分成若干网格,通过遍历网格交叉点处所有的参数组合来优化需要训练的模型,同时计算其对应模型的均方根误差或准确率。只有遍历网格平面的所有节点,才能得到使准确率最高或均方根误差最小的参数组合,也就是模型的最优参数组合[11]。本文为了使随机森林更迅速地找到模型的最优解,将K-fold交叉验证和网格搜索法相结合对随机森林算法作改进,以模型的平均均方根误差最小作为优选参数的目标,极大地规避了不确定性对训练结果的影响,有利于防止模型的欠拟合或过拟合,保证所得的解是全网格范围内的最佳参数组合,从而避免用传统经验法选取参数可能造成的重大误差[12]。
本文针对随机森林算法中较重要的两个参数:决策树的数量k和候选分裂特征属性数m,用网格搜索算法进行调节优化。基于网格搜索的随机森林优化算法具体步骤如图1所示。

图1 基于网格搜索的随机森林优化算法流程
1)将数据集划分为训练集、测试集,对训练集进行K折划分,即平均分为K份;
2)确定决策树数量k和候选分裂特征属性数m的范围,以k和m为坐标系建立二维网格,网格的交叉节点就是对应的k和m参数组合[13];
3)选取训练集中的任意K-1份数据;
4)选取网格搜索交叉点的1组参数,从K-1份数据中有放回地抽取样本总数的样本数据作为1棵决策树的样本;
5)预测剩余1份数据,计算所有树在剩余1份训练样本上的平均均方根误差;
6)重复步骤4)、5),直到遍历完K-1份训练样本的预测效果;
7)遍历网格交叉点处所有的参数组合构建对应的决策树,形成随机森林,重复步骤3)~6),选择出最优的超参数组合;
8)根据最优参数组合,将测试集所有样本重复建立随机森林模型;
9)将测试集数据输入到每棵树,得出改进后模型的预测效果。
通过训练好的模型对商家的顾客满意度进行预测,确定使平均均方根误差最小或准确率最高的参数组合,提高了预测模型的优化性能。
2 实验与分析
2.1 数据来源与预处理
本文所研究的数据来源于Kaggle平台的Zomato数据集,该数据集提供了截止到2019年3月Zomato网站中各餐厅的基本信息及营销情况。Zomato消费者数量及用餐评论量巨大,是预测顾客满意度理想的网络在线评论源,具有普适性。
为了提高预测过程的高效性和结果的准确性,先进行数据预处理。本数据集中的特征属性共43个,由相关系数矩阵图分析得出影响顾客满意度的6个主要因素,分别为:餐厅能否线上点餐、能否餐桌点餐、截至上述日期餐厅的评分总数、双人餐的价格水平、用餐类型、餐厅位置,使用上述6个重要变量训练预测模型,因变量为顾客满意度。因变量与6个自变量之间存在的相关性如表2所示。

表2 顾客满意度与主要变量的相关性
本研究使用管道模型进行特征选择、数据转换、空数据处理,并将数据集拆分成训练集与测试集,其中训练集占比为0.8。使用StandardScaler对预处理后的数据进行标准化和归一化处理,用One-Hot 编码对数据特征化处理,以提高预测结果的准确性。
2.2 预测结果与分析
本文采用五折交叉验证的网格搜索方法对随机森林模型进行适当的超参数调整,发现优化模型比无超参数配置的随机森林预测的均方根误差还要低0.001 9,预测准确率得到了改善。网格搜索优化随机森林模型各参数取值如表3所示。

表3 网格搜索优化随机森林模型的参数取值
由于新餐厅无初始评分,对用户没有参考价值,因此需要利用构造好的模型对原数据集中评分列为“NEW”的餐厅进行预测,结果的前5行如表4所示。
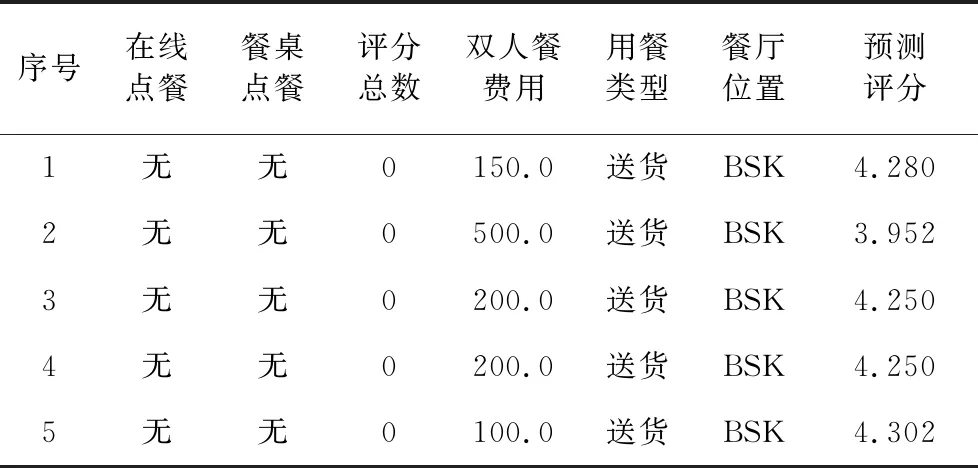
表4 新餐厅顾客满意度评分预测
最后利用优化后的预测模型,对输入特征的重要性进行排序,重要性排前5的顾客满意度特征如表5所示。

表5 顾客满意度特征重要度排序
由该排序可知,在最后做预测的特征中重要性排在最高的为平台商家当前的口碑评价,其次为双人餐的价格水平,而商家能否提供线上点餐或餐桌点餐的重要程度相当,其他的特征则与预测顾客满意度评分的相关性较小。因此,商家的口碑评价和双人餐的价格水平是顾客满意度的重要影响因素,一方面,新商家可做免费试吃活动或定期发放优惠券与限时折扣,提高商家的口碑评价;另一方面,消费者也可主要根据商家口碑及价格水平快速选择自己喜欢的餐厅。
3 结束语
为了快速响应以顾客为主导的市场变化,研究顾客满意度预测具有非常重要的意义。本研究通过使用网格搜索算法对随机森林的决策树数量和候选分裂特征属性数进行优化调参,改进随机森林的不足,能够有效预测餐厅的客观满意度评分。该模型可应用在顾客满意度预测的实例中,也可推广应用于其他服务类企业的满意度预测。在本研究使用的实例中,商家的口碑评价和双人餐的价格水平是影响顾客满意度的主要因素,因此,餐饮行业在提升顾客满意度时应予以着重考虑。
下一步的工作可将网格搜索改进随机森林模型与其他机器学习模型进行融合,进一步提高模型的预测精度。还可将顾客满意度预测模型进一步应用于其他类型的电商评分网站,验证模型的普适性和稳定性。
猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21 00:44:56
中学生数理化·七年级数学人教版(2022年10期)2022-11-11 03:18:56
中国石油石化(2021年9期)2021-07-17 09:24:16
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:40
北京航空航天大学学报(2017年6期)2017-11-23 05:57:36
自动化学报(2017年2期)2017-04-04 05:14:28
浙江大学学报(工学版)(2016年10期)2016-06-05 09:20:56
中学生数理化·七年级数学人教版(2016年2期)2016-05-30 21:20:57
山东青年(2016年1期)2016-02-28 14:25:27
中国洗涤用品工业(2015年6期)2015-02-28 19:02:35
