
面向阀门内漏声发射检测的支持向量机分类建模
2021-09-09 06:40吴文凯徐科军叶国阳
计量学报 2021年8期
吴文凯,徐科军,叶国阳
(合肥工业大学 电气与自动化工程学院,安徽 合肥 230009)
1 引言
阀门在当代电力、石油化工等行业应用广泛,其密封性的好坏,对工业生产系统的安全和高效运行影响巨大。阀门泄漏往往是重大工业生产事故的隐患,同时也会造成生产资源的浪费和自然环境的污染[1]。为了防止阀门泄漏造成的安全事故,学者们将声发射技术引入阀门内漏的在线检测,这种无损检测技术能够为阀门的维护提供前瞻性的预测和分析[2,3]。声发射技术探测到的信号能量来自被测对象本身,因此,对于阀门内部泄漏问题具有良好的适用性[4]。为了实现声发射技术的在线检测,必须构建阀门内漏检测的数学模型,即确立声发射信号特征量与泄漏量之间的关系[5]。
目前,对阀门泄漏声发射信号进行处理主要分为两类方法。一类是回归建模的方法,即建立阀门泄漏声发射信号特征量与泄漏量之间准确的定量数学模型,即根据分析得到的声发射信号特征量定量计算泄漏量。例如:Kaewwaewno W 等建立了基于声发射源几何分布关系的阀门液体泄漏速率预测模型,在其研究过程中推导出信号均方根(RMS)和泄漏率Q之间的关系,为阀门泄漏故障特征库的建立及阀门泄漏率定量诊断奠定了理论基础[6];Ye G Y等研究了泄漏率为0~1 000 mL/min,压力为0.35,0.50,0.80 MPa时,阀门泄漏声发射信号的标准差与阀门泄漏率之间的关系,采用最小二乘线性拟合方法建立数学模型,建模的最佳拟合度为0.980 8[7]。虽然根据回归建模方法可以得到阀门泄漏量的经验公式;但是,由于被测对象、测试手段和实验条件等多方面因素的影响,经验公式计算的泄漏量与实际泄漏量之间的误差较大。另一类是分类建模的方法,即对阀门泄漏按照泄漏量大小划分等级,建立阀门泄漏声发射信号特征量与泄漏等级之间准确的分类数学模型。例如:李振林等针对天然气的球阀泄漏问题,提出了核主成分分析和支持向量机分类器的泄漏识别方法,该方法得到的分类模型预测准确率可达96.5%[8];Zhu S B等采用因子分析与kmedoids聚类方法,对球阀的气体泄漏量进行分类,分析结果的准确度为96.28%[9]。
分类建模方法避免了回归方法精确定量建模的困难,而只是判断被测泄漏量是否在某个已划分的泄漏范围内,这与实际检漏过程中只需要判断阀门是否超过允许泄漏标准的要求是契合的。但是,目前分类的建模方法主要应用于阀门气体介质泄漏的检测,还没有应用于阀门液体介质泄漏的检测[10]。考虑到液体阀门在工业现场也被广泛使用,且液体与气体这两种介质的性质有所不同。所以,本文提出应用支持向量机方法对阀门液体泄漏信号进行泄漏等级的分类建模研究。为建立阀门内漏时声发射信号特征量与阀门内漏不同等级之间的支持向量机分类模型,在重庆川仪自动化有限公司提供的液压阀门检漏平台上进行阀门泄漏声发射信号采集实验,对信号进行预处理,提取信号特征量,再进行支持向量机分类建模,数据处理结果表明支持向量机分类建模方法对阀门液体泄漏检测是有效的。
2 阀门内漏声发射检测机理
声发射是物体或材料损伤时迅速释放能量而产生应力波的一种物理现象,而声发射信号则是声发射现象发生时信号被传感器捕捉并经系统处理后以另一种形式出现的电信号[1]。声发射是正在扩展的材料缺陷(裂纹)的指示器,只有当物体的缺陷扩展成永久损伤之后才会产生声发射[11]。当阀门密封面出现磨损或者裂痕时,泄漏的流体通过有破损的密封面便会产生声发射信号。液体在阀门泄漏的过程中,激发的声发射信号是连续型声发射信号,该信号携带着液体泄漏的信息,经过液体介质、阀门内壁和耦合剂的传播之后被声发射传感器采集。
通过大量实验研究阀门泄漏声发射信号,分析得出声发射信号具有如下特点:1)阀门泄漏时所产生声发射信号频率成分复杂,信号能量主要集中在超声频带。并且,泄漏声发射信号频带会受到许多其他因素的影响,如进口压力大小、阀门类型、泄漏大小、阀体内介质类型等。2)阀门泄漏所产生声发射信号波形都具有一个陡峭的尖峰,超声频带信号能量最多,信号集中的具体频带由阀门类型及流体介质决定。3)阀门泄漏声发射信号是一种随机信号,波形十分复杂。传播路径、传输介质和环境噪声等因素都会对声发射信号造成影响[4,12~17]。
3 阀门内漏声发射信号采集实验
阀门内漏声发射信号采集实验的实验平台由2部分组成,其中,液压阀门试验台由重庆川仪调节阀有限公司提供,声发射信号采集与处理系统由本文搭建。实验装置框图如图1所示,阀门泄漏检测实验平台现场如图2所示。
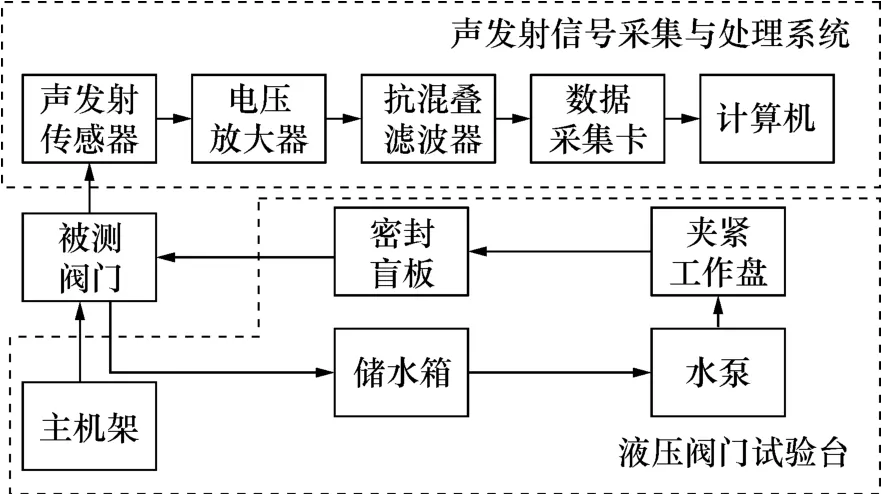
图1 实验装置框图Fig.1 Block diagram of experimental device

图2 阀门泄漏检测实验平台Fig.2 Valve Leak Detection Platform
液压阀门检漏平台通过液压系统推动夹紧工作盘固定阀门,并通过增压水泵和水循环系统来给阀门提供恒定的前端压力,调节增压水泵功率控制阀门的前端压力。声发射信号采集与处理系统由声发射传感器、电压放大器、抗混叠滤波器、数据采集、线性电源和笔记本电脑组成。声发射传感器为美国物理声学公司的R15a压电式传感器,其工作频率范围为50~400 kHz,能够有效地检测阀门泄漏信号。电压放大器对声发射传感器的输出信号具有放大作用,放大倍数为40 dB,能够提高整个系统中的信噪比。数据采集卡选用的是NI公司开发的高性能数据采集卡,采样频率为1.25 MHz。声发射传感器的固定方式为磁夹固定。声发射信号采集系统的工作过程为:传感器捕捉信号后传输至电压放大器,进行阻抗变换和放大,然后通过截止频率为600 kHz抗混叠滤波器后,由数据采集卡以1.25 MHz的频率进行采样,转换成数字信号。最后,采用Matlab程序对数字信号进行分析。
在重庆川仪调节阀有限公司的工业生产现场,选择型号为HTS、公称直径为50 mm、流量系数为17的单座阀(简称阀门HTS50)进行实验。在泄漏实验中,为了使实验能够反映实际工况下的阀门泄漏现象,一般可以选择以下方法进行模拟:1)选择生产中出现的阀门次品进行实验;2)对泄漏检测合格的阀门产品进行人为损坏来模拟实际泄漏;3)通过调节阀门来控制阀门的开度以模拟实际泄漏。由于生产技术的提高,鲜有不合格的阀门出现,对合格阀门进行破坏实验成本高,所以,本实验采用调节手轮的方法来进行泄漏实验。
将阀门HTS50安装在液压阀门试验平台上,利用磁夹将声发射传感器固定在阀体平面处。在阀体与传感器之间涂抹耦合剂以减少信号能量损失。传感器安装如图3所示。

图3 传感器安装图Fig.3 Sensor installation diagram
调节手轮使阀门处于密封状态,开启增压水泵使阀门正常工作,转动调压扳手给予阀门适当的压力,保持该压力,然后转动手轮使阀门开始泄漏,采集声发射信号,同时测量泄漏量。调节手轮逐渐减小开度,并采集声发射信号和测量泄漏量。重复以上过程直至阀门关死不再泄漏,然后调节阀门前端压力,继续下一轮实验。
实验过程中使阀门HTS50分别在0.60,0.65,0.70,0.75 MPa的压力下进行泄漏实验。液体泄漏范围在0~575 mL/min以内。测量泄漏量的方法是使用量筒测量泄漏液体的体积,使用手机进行计时,然后计算泄漏量。为了提高数据采集的准确性,数据采集卡设置采集时长为2 s,每次采集2 500 000点数据。
4 实验数据预处理及特征提取
4.1 实验数据预处理
由于声发射传感器采集的阀门内漏声发射信号具有随机信号的特点,还含有电机噪声和其它环境噪声,因此,除了在硬件上要对信号进行放大和抗混叠低通滤波之外,还要对转换成的数字信号进行预处理,从而确定信号的特征频带。
对采集到的声发射信号进行频谱分析,如图4所示。当泄漏量为零时,信号在0~30 kHz的频带内具有较高的幅值,随着泄漏量的增加,该频段内的信号幅值无明显变化,因此确定噪声频带主要是在0~30 kHz内。而在频带40~320 kHz内,信号的幅值随着泄漏量的增加逐渐抬升,因此确定信号的特征频带为40~320 kHz。因此,在预处理时,选择通带频率为40~320 kHz的巴特沃斯滤波器对信号进行滤波,从而为信号的特征提取做准备。滤波前后的时域信号如图5所示。
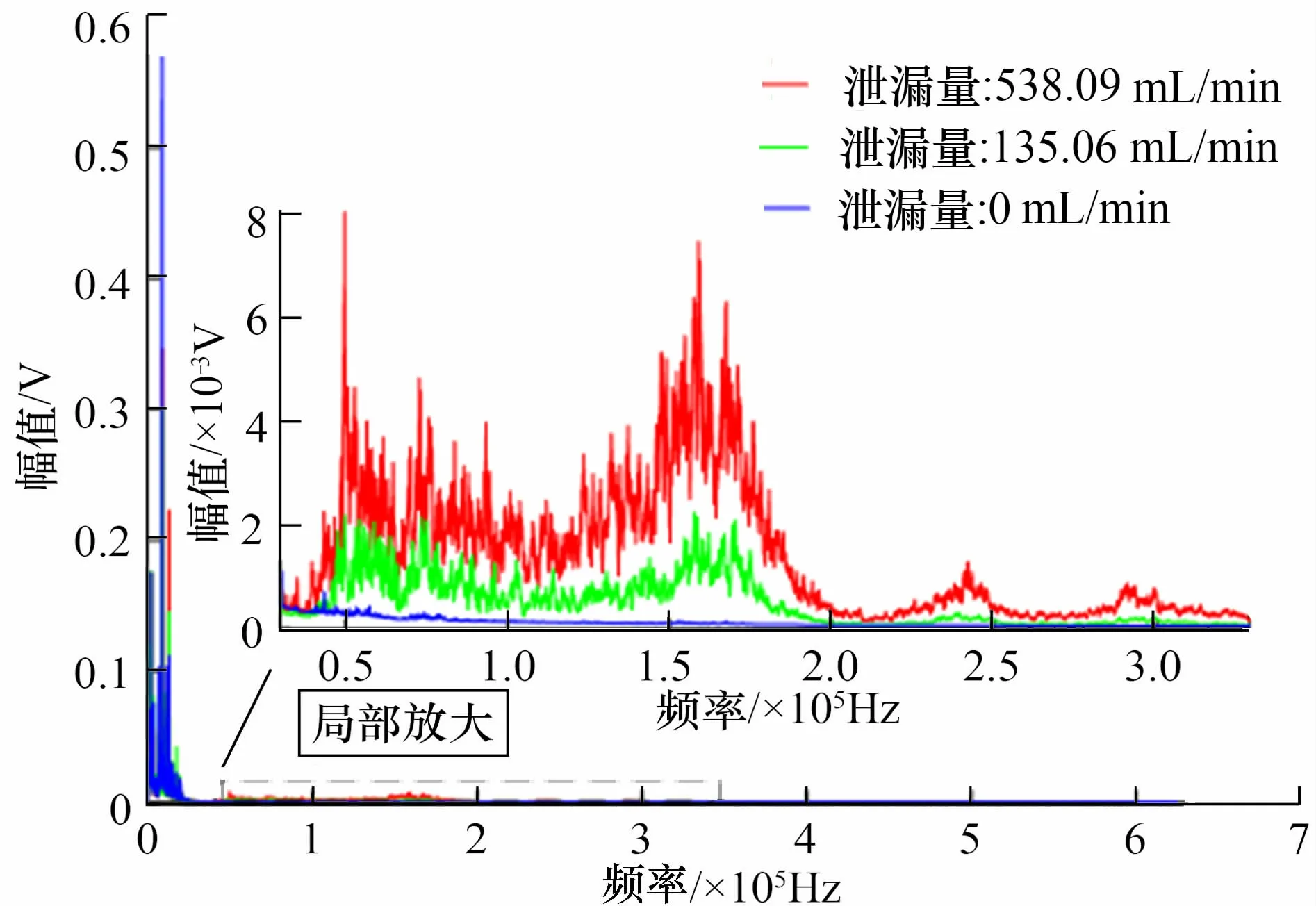
图4 阀门泄漏声发射信号频谱图Fig.4 Acoustic emission signal spectrum of valve leakage
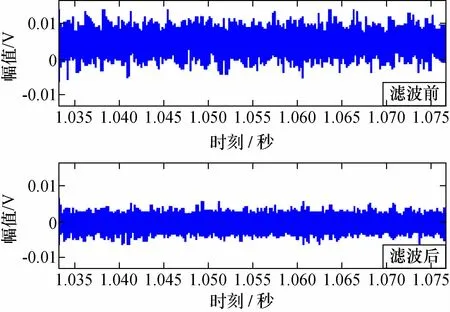
图5 阀门泄漏声发射信号滤波前后图Fig.5 Pre-filter and back-filter charts of acoustic emission signal for valve leakage
4.2 声发射信号特征提取
为了更多地挖掘阀门泄漏声发射信号所携带的泄漏信息,本文计算了标准差Sstd、均方根Rrms和方差Vvar3个特征量来表征声发射信号的波动特性;计算了平均值Mmean和熵Eentr2个特征量来表征声发射信号所包含的能量;计算了峰度Kkurt和峭度Sskew2个特征量来表征声发射信号的冲击特性。从3个不同角度对信号进行特征提取,为支持向量机算法提供必要的分类建模依据[17]。特征量计算公式如表1所示。以信号特征量标准差Sstd计算过程为例进行说明:
1)将滤波后的数据分段,分为1 250段,每段2 000点。
2)根据式(1)计算每段数据的标准差,得到1 250个标准差,如图6所示。
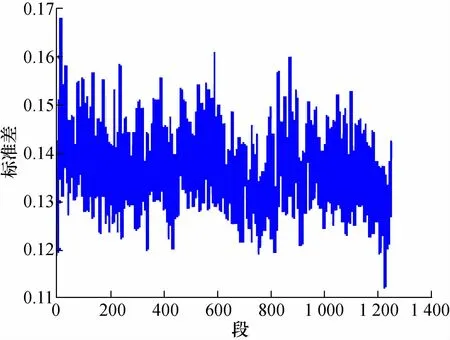
图6 每段数据的标准差Fig.6 Standard deviation for each segment of data
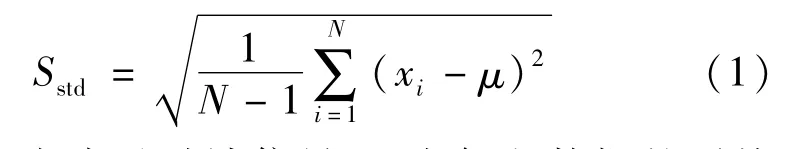
式中:xi为滤波后时域信号;μ为每段数据的平均值;N为每段数据包含的点数。
3)对计算得到的1 250个标准差进行从小到大的排序,排序之后如图7所示。为了进一步减少统计变异性和随机噪声的干扰,选取排序后的前20个标准差的均值作为特征量标准差最终的取值。
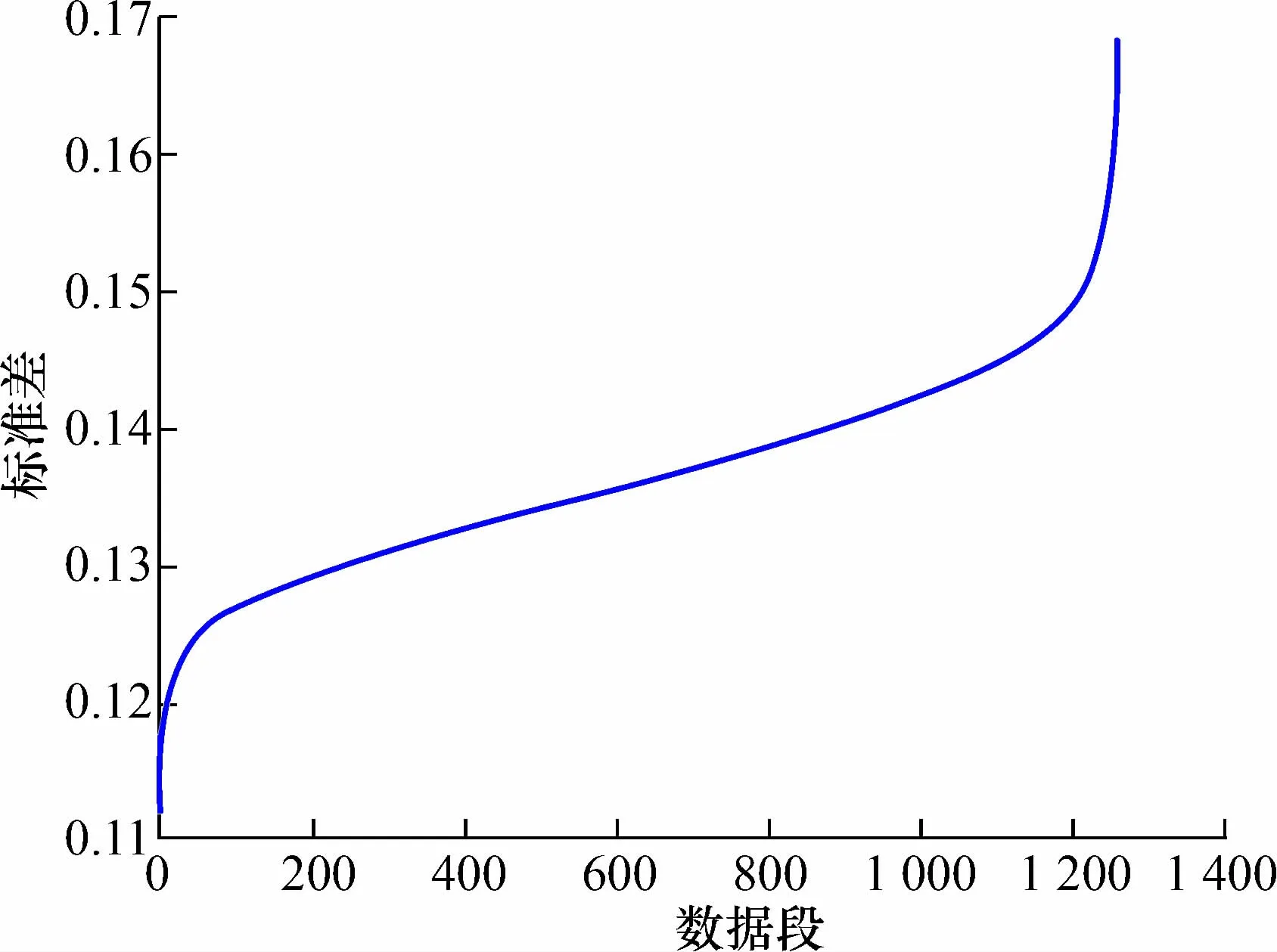
图7 排序后的标准差Fig.7 standard deviation after sorting
4)以此类推,分别计算其余6个特征量,特征量计算公式如表1所示。

表1 特征量计算公式Tab.1 Characteristic quantity formula
5 支持向量机建模
支持向量机(support vector machine,SVM)是以统计学理论作为支撑,以结构风险最小化原则为优化策略,寻求使经验风险和置信范围之和最小的学习机器。将最优分类超平面的构造计算转化为二次优化问题,解决了容易在神经网络中出现的局部极值问题[18]。因此,选择SVM方法对阀门液体泄漏数据进行处理。
支持向量机方法适用于阀门液体泄漏实验数据小样本和非线性的特点,并且训练得到的分类模型泛化能力强,能满足实际工程中在线检漏的需要。
5.1 支持向量机原理
线性二分类问题是支持向量机算法的研究起点。存在两类线性可分的样本点,如图8所示。

图8 最优超平面示意图Fig.8 Optimal Hyperplane Diagram
假设样本点集合为{(xi,yi),i=1,2,…,l},其中l为样本数,一类样本点yi=-1,另一类的样本点yi=1,需要寻找到一个最优超平面。

式中:w为权值向量;x为输入向量;b为偏置项。使式(2)到2类样本的间隔最大,其中且两类样本点满足:

式(4)可以转化为Langrange问题:

式中:αi>0为Langrange系数,i=1,2,…,l。

式中xr和xs为2个类别中任意一对支持向量。计算得出最优超平面的函数表达式为
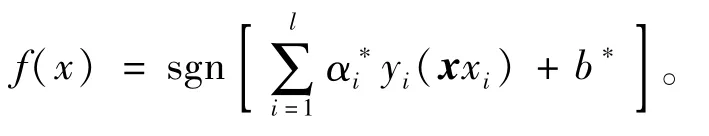
为了避免模型对于SVM模型的过拟合,需要引入松弛变量ξ,允许少数样本被错分,以此提高模型的预测准确率。
在实际问题中,非线性样本的分类建模需要利用核函数K(xi,xj)=Φ(xi)Φ(xj)减少计算量。利用核函数方法得到的最优分类函数为:
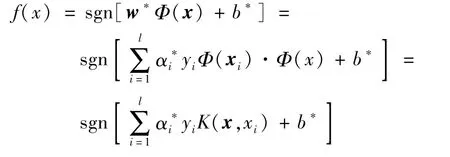
支持向量机算法中常用的核函数是线性核函数、多项式核函数、Sigmoid核函数和RBF核函数,本文采用RBF核函数进行训练建模。
5.2 支持向量机分类建模过程
1)计算特征量。计算得到每个泄漏量下声发射信号的7个特征量,组成支持向量机的特征数据矩阵x,即

式中:Sstd(i)、Rrms(i)、Vvar(i)、Mmean(i)、Eentr(i)、Kkurt(i)、Sskew(i)分别为xi的7个特征量的值。
2)添加标签。根据GB/T 4213—9调节阀泄漏标准,计算得到本文所研究阀门的四级泄漏量Q。在实际工业生产中,以四级泄漏量Q为标准来判断阀门是否需要维修,因此,为每个泄漏量下阀门泄漏小声发射信号划分的泄漏等级是:小泄漏范围为0~Q;中等泄漏范围为Q~2Q;大泄漏范围为2Q~3Q;特大泄漏范围为大于3Q。样本添加标签的规则如表2所示。确定标签之后,可以得到样本标签矩阵Y=[y1,y2,…,yi,…]T,其中yi为xi的标签值。

表2 样本标签添加规则Tab.2 Sample Label Addition Rules
3)选择训练样本。将样本集分为测试样本集和训练样本集,将泄漏量从小到大排序之后均匀挑选其中2/3的样本作为训练样本,剩余1/3样本作为测试样本。由训练样本集的特征矩阵和训练样本集标签矩阵计算得到SVM分类函数模型。将测试集本的特征矩阵输入到上述计算得到SVM模型中即可对测试样本集进行分类。
4)SVM建模。通过数据处理过程,得到SVM建模所需输入的特征矩阵和标签矩阵。SVM建模过程为:输入特征矩阵归一化;利用交叉验证法选取SVM建模的最优C和g参数;对训练样本数据进行建模。得到模型之后,输入测试集特征矩阵,得到预测标签,并计算准确率。
通过测试样本集标签的预测正确率来判断SVM模型的好坏。预测准确率为,其中l1为预测正确的测试样本数,l2为测试集样本数。预测准确率越高,说明SVM模型越准确。
5.3 网格搜索法SVM 参数寻优与建模
SVM建模过程中C、g参数的选择决定了算法速度和模型好坏。其中,C是惩罚系数,即对误差的宽容度。C过大或过小,泛化能力变差。参数g是RBF核函数的参数,用于确定模型训练的快慢。
网格搜索法就是分别给定C参数和g参数的范围,定步长划分参数范围,组成C和g二维参数矩阵,依次利用每对参数进行试验,由预测准确率来确定最优的C和g参数。
分别对阀门HTS50在前端压力为0.6,0.65,0.7,0.75 MPa下的试验数据进行建模,各个压力下的最优参数如表3所示,参数寻优如图9所示。
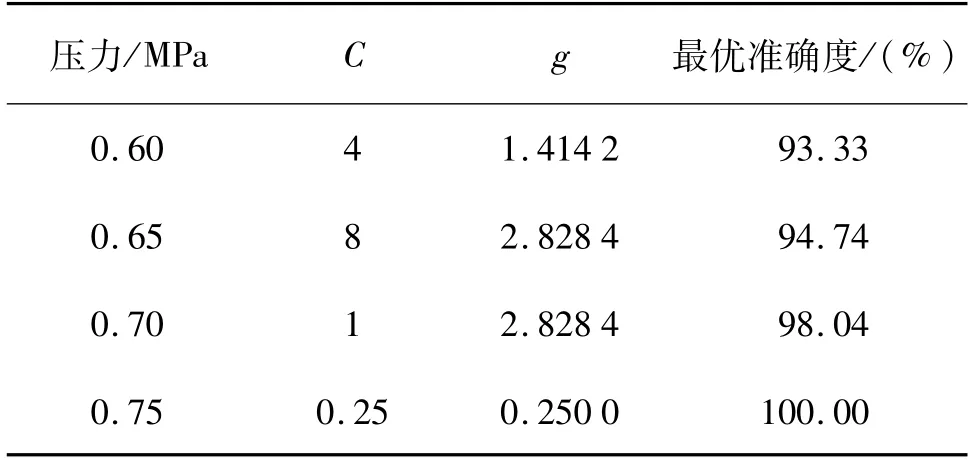
表3 参数寻优结果Tab.3 Parameter optimization results

图9 参数寻优结果Fig.9 results of parameter optimization
图9中最高峰对应的训练模型准确率最高,对应的C和g参数就是最优参数。最优参数如表3所示,利用最优参数建立SVM分类数学模型。
5.4 支持向量机分类结果
在前端压力为0.6,0.65,0.7,0.75 MPa对阀门HTS50进行了实验,预测结果如图10所示。4个压力下SVM模型的预测准确率如表4所示。表4指出SVM模型在压力为0.75 MPa时预测准确度最高为100%,在压力为0.65 MPa时预测准确度最低为93.1%,这说明支持向量机分类建模方法能够在不同压力下对阀门泄漏情况进行识别。由图10可以看到分类出现错误的数据都是处于分类边界上的点,这与支持向量机原理是一致的。在SVM模型训练过程中,为了达到结构风险最小化的效果,少数边界上的点是允许被错分的,这样能强化模型的泛化能力,因此在预测时错误的点都处于边界附近。

图10 实验结果Fig.10 Experimental results
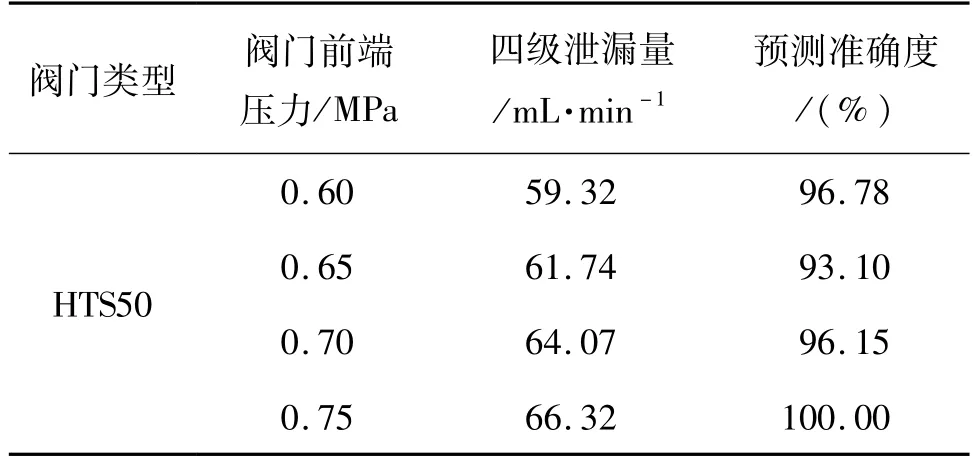
表4 SVM模型的预测准确率Tab.4 Prediction accuracy of SVM model
6 结论
分析了阀门液体泄漏声发射的机理,根据实际工况下阀门泄漏的情况,设计了阀门液体泄漏实验。确定了阀门液体泄漏声发射的信号频带为40~20 kHz。对采集到的声发射信号进行频谱分析,发现在频带40~20 kHz内随着泄漏量的增大,信号的频谱幅值相应增大。
提出将SVM应用于阀门液体泄漏状态分类的具体实现方法:对阀门液体泄漏声发射信号提取多个特征量组成输入特征矩阵,定义了添加阀门泄漏等级标签的规则,对SVM训练参数进行寻优,建立了输入信号特征和泄漏等级标签的分类模型。SVM分类建模方法的数据处理结果表明,阀门泄漏等级的预测准确率均在93%以上。相比于回归方法,SVM分类方法更符合实际工况阀门泄漏在线检测的要求。
液体与气体的性质不同、阀门种类不同以及阀门液体泄漏实验与气体泄漏实验的条件也不同,从而液体的声发射信号与气体的有较大差异,所以,研究阀门液体泄漏声发射信号分类模型是有实际意义的。
猜你喜欢
流程工业(2022年3期)2022-06-23
作文周刊·小学一年级版(2022年24期)2022-06-18
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·八年级物理人教版(2022年4期)2022-04-26
中学生数理化·八年级物理人教版(2021年4期)2021-07-22
煤气与热力(2021年3期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·一年级语数英综合(2017年1期)2017-02-16
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
