
融合分类信息的随机森林特征选择算法及应用
2021-09-07 00:48:20武炜杰张景祥
计算机工程与应用 2021年17期
武炜杰,张景祥
江南大学 理学院,江苏 无锡214122
从海量特征中科学提取关键特征,达到降维、提升模型性能的效果是机器学习与模式识别的关键问题[1]。特征选择是从原始特征集中选出若干具有代表性的特征子集,且在该特征子集上所构建的分类或回归模型达到与特征选择前近似甚至更好的预测精度。特征选择不仅可以提高应用算法的空间和时间效率,避免“维数灾难”[2],还可以在一定程度上避免算法的过拟合问题。
根据特征评价策略,特征选择方法大致分为两种:过滤式(Filter)和封装式(Wrapper)[3-4]。过滤式方法在数据预处理步骤中对特征排序,设定阈值选择最优特征子集,这种方法独立于后续采取的机器学习算法。过滤式方法中经典的排序准则有Pearson相关系数[5]、互信息[6]、Laplacian得分[7]等。Kira等[8]提出的Relief算法依据特征权重对特征排序,但算法只针对于二分类问题的特征选择。Kononenko[9]在Relief算法的基础上进一步提出了Relief-F算法,可以进行多分类问题的特征选择。Peng等[10]提出mRMR(max-Relevance and Min-Redundancy)算法,保留与分类信息具有强相关性的特征,又在一定程度上去除冗余特征。
封装式方法通过与后续的学习算法结合,根据分类器的准确率分别评价每个特征子集,从而选择最优特征子集。Breiman[11]提出通过随机森林置换特征计算其重要性得分,进行特征选择是典型的封装式方法。但当特征规模较大,不可能对每个特征子集进行评价,所以通常向前或向后算法来引入或消除特征。如Gregorutti等[12]通过研究随机森林模型内决策树之间相关性对特征置换的影响,基于随机森林特征置换计算其重要性得分同时,提出了一种递归特征消除算法;姚登举等[13]提出了一种基于随机森林模型的封装式特征选择算法,采用序列后向选择和广义序列后向选择方法选择特征。
随机森林算法通过特征随机置换前后误差分析,计算每个特征重要性得分,分值越高,特征越重要,进一步可以确定特征排序,与过滤式特征选择方法相比,随机森林模型不仅能体现特征间相互作用,还对噪声数据和存在缺失值的数据具有较好的鲁棒性,目前在医学[14-15]、信息学[16]等方面广泛应用。但随着数据特征增加,传统的随机森林算法计算效率大幅降低。
针对这个问题,本文基于特征聚类与特征和分类信息的相关度策略,提出一种随机森林多特征置换(Multi-Feature Permutation by Random Forests,MFPRF)算法。首先,算法对数据特征进行聚类,保持其他特征簇内的特征不变,逐一对同特征簇内的特征同时随机置换,通过置换前后预测误差大小衡量特征簇的重要程度,得到簇间排序。计算簇内特征与分类信息的相关性进一步得到簇内排序。算法结合过滤式方法,设定相关性阈值在排序后的特征簇内依次选出重要特征,剩余特征则按照先簇间后簇内的规则排序,得到全部特征排序,由分类器在不同特征子集上的分类精度,确定最优特征子集达到降维效果。与文献[11]相比,MFPRF算法优点在于:(1)MFPRF算法将相似特征聚为一类,对若干个相似特征同时随机置换,可避免当特征规模过大时,逐一计算特征重要性得分,算法运行时间更短。(2)MFPRF算法结合过滤式方法引入相关性阈值,在排序后的特征簇内依次选出重要特征,体现出特征的相互作用的同时便于对数据的理解,增强最后分类模型的可解释性。(3)MFPRF算法基于随机森林模型,选择的数据与特征均具有随机性,对噪声数据与缺失数据具有较强的鲁棒性,算法性能稳定。
1 随机森林
随机森林是通过组合(Ensemble)或又称分类器组合(Classifier Combination)的方法,聚集多个模型提高预测精度的经典代表算法之一。RF是装袋算法(Bootstrap aggregating,Bagging)的一个扩展体[17],生成决策树的过程中引入随机特征选择策略,最终根据投票原则确定最终结果。随机森林生成过程如图1所示。
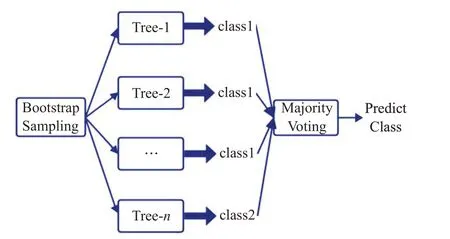
图1 随机森林算法框架Fig.1 Framework of random forests algorithm
本文介绍的RF以构建在Bagging基础上的C4.5决策树[18]为基分类器,在构建过程中基于信息增益率引入随机特征选择。
1.1 传统随机森林特征重要性度量方法
传统随机森林特征重要性度量方法,是对每一个特征随机置换。经由随机森林对特征置换后生成新的袋外数据进行测试,随机森林预测误差率相比原来特征置换前会增大。当特征重要程度越高,随机森林模型预测误差率的变化值会越大。这样通过特征置换前后的袋外数据误差率的变化值对每一个特征进行打分,从而得到特征的重要性得分。
定义1(第i棵决策树的袋外数据(Out-Of-Bag,OOB))假设训练集D,通过Bootstrap方法生成数据集Di构建第i棵决策树。其中未参与第i棵决策树构建的数据D-Di称为第i棵决策树的袋外数据OOBi。
定义2(基于OOB误差分析的特征Xj重要性度量)基于OOB误差分析的特征Xj重要性度量为对所有决策树的OOB的特征Xj随机置换前与置换后的OOB分类误差率的平均变化量。
假设随机森林中决策树数目为Ntree,原始数据集有d个特征,单特征Xj(j=1,2,…,d)的基于OOB误差分析的特征重要性度量按照下述步骤计算:
(1)计算第i棵决策树相应的袋外数据OOBi的袋外错误样本数ErrOOBi。
(2)在保持其他特征不变的同时,对OOBi中的特征Xj进行随机的序列改变得到,重新计算袋外数据的袋外错误样本数
(4)计算所有决策树特征Xj置换前后OOB分类误差率的平均变化量:

其中,VI(Xj)作为特征Xj的重要性得分。
1.2 随机森林多特征重要性度量方法
由于传统的随机森林特征重要性度量方法是对单个特征进行随机置换,通过置换前后的袋外数据误差分析对该特征的重要程度打分。相较于中、高维数据集,传统方法对低维数据集优势较为明显。由于中、高维数据集的特征数目增大,采用单个特征重要性度量的方式会导致算法运行占据空间大,时间长,效率低。本文在传统方法上进行改进,引入随机森林多特征重要性度量方法。在使用随机森林度量特征重要性前,首先对原始特征进行聚类,将相似性较高的特征聚成一类。对多个相似性较高的特征组成的特征簇采用多特征同时随机置换的方式,度量特征簇的重要性得分。
定义3(基于OOB误差分析的特征簇XJ重要性度量)基于OOB误差分析的特征簇XJ={Xj|j∈J}重要性度量为对所有决策树的OOB的特征簇XJ内所有特征{Xj|j∈J}同时随机置换前后OOB的分类误差率的平均变化量。
假设随机森林中决策树数目为Ntree,原始数据集有d个特征,对原始特征集进行聚类,聚成l类后得到特征簇集合{XJk|k=1,2,…,l}。第k个特征簇XJk基于OOB误差分析的特征簇重要性度量按照下述步骤计算:
(1)计算第i棵决策树相应的袋外数据OOBi的袋外错误样本数ErrOOBi。
(2)在保持其他特征簇内的特征不变的同时,对OOBi中的特征簇XJk内所有特征{Xj|j∈J}同时进行随机的序列改变,重新计算袋外数据的袋外错误样本数
(4)计算所有决策树特征簇置换前后OOB分类误差率的平均变化量:
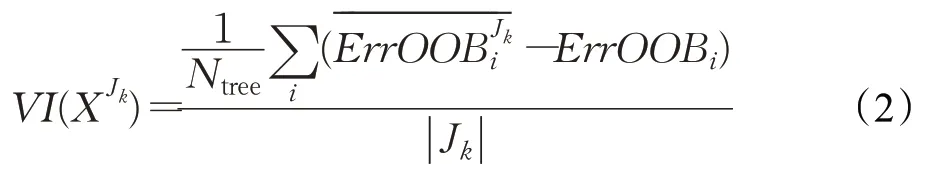
其中,||Jk为第k个特征簇内含有特征的个数,VI(XJk)作为特征XJk的重要性得分。
由于特征簇内的特征越多,该特征簇的重要性得分越高。为防止出现特征簇内实际每个特征重要性得分低,但由于该特征簇内的特征较多,导致得到虚高的特征簇重要性得分,所以得出的特征簇的重要性得分取该特征簇内特征个数的平均值。
2 随机森林多特征置换算法
本文根据引入的随机森林多特征度量方法,提出随机森林多特征置换算法。MFPRF算法对特征进行聚类,由随机森林多特征度量方法确定特征簇间排序,簇内特征按与分类信息的相关性确定簇内排序。MFPRF算法流程图如图2所示。
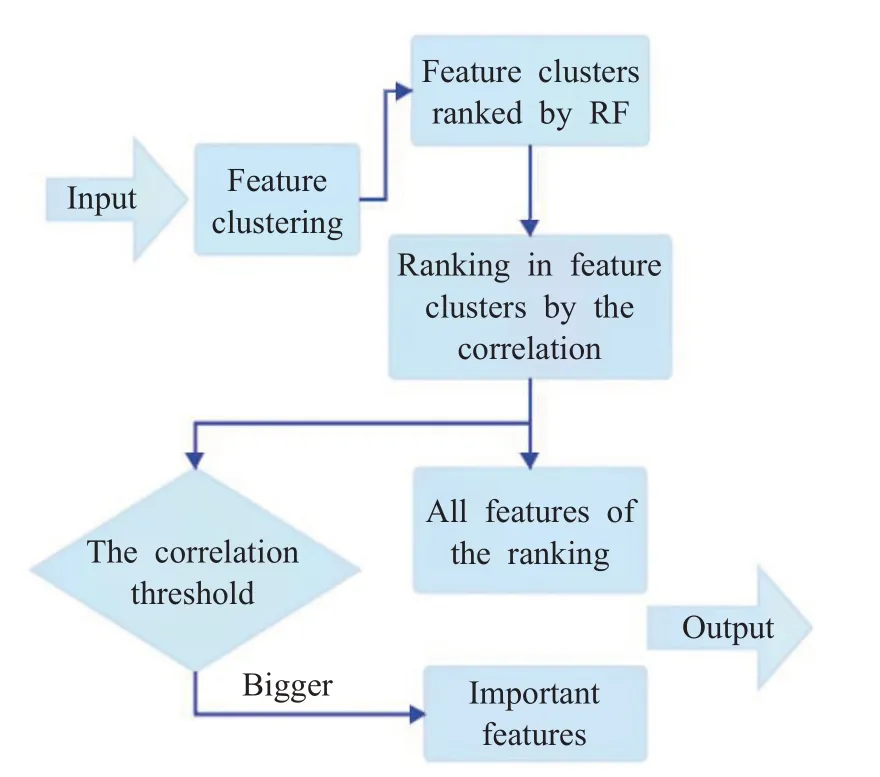
图2 MFPRF算法框架图Fig.2 Framework of MFPRF algorithm
2.1 特征聚类及有效性的衡量
聚类根据相似性原则将数据进行划分,相似性较高的数据划为一簇,相似性较低的数据划为不同簇。为了将相似性较高的特征聚为一簇,本文采用三种经典聚类算法K均值(K-means,KM)聚类、层次聚类(Hierarchical Clustering,HC)和模糊C均值(FuzzyC-means,FCM)聚类算法对特征进行聚类,得到MFPRF-KM(MFPRF based onK-means)、MFPRF-HC(MFPRF based on HC)和MFPRF-FM(MFPRF based on FCM)三种基于随机森林多特征置换的特征选择算法。引入与类间距离和类内离散度相关的DBI(Davies-Bouldin-Index)指标[19-21]来衡量特征聚类的有效性,其中DBI指标内容如下:
(1)类内平均离散度:

其中,Zi是Ci类的类中心,||Ci表示Ci类样本数。
(2)用两个类中心的距离表示类间距离:

(3)DBI计算:

在DBI指标中,DBk的值越小,聚类的效果越好,由此可以确定对特征聚类的最佳类数。
2.2 特征排序机制与重要特征的选择
通过随机森林得到特征簇间排序,再按簇内特征与分类信息之间的相关性大小进一步得到簇内排序。簇内特征与分类信息为两个非退化的随机变量,其相关性使用皮尔逊相关性系数ρxy衡量(见式(6)),相关系数ρxy的绝对值大小表示特征x、y相关程度的高低,ρxy绝对值越大,表示相关程度越高。

逐一计算全部特征与分类信息的相关性,设定相关性阈值δ作为标准选择重要特征。本文参考文献[22],选取δ=EX+C×std(X),其中EX与std(X)分别为数据集所有特征与分类信息相关性的均值与标准差。通过相关性阈值δ,依次从排序后的特征簇内选取与分类信息相关性大于δ的特征作为重要特征。剩余特征按照先簇间、后簇内顺序依次排列在重要特征之后,得到最终的特征序列。
2.3 MFPRF算法
算法1MFPRF算法
输入:训练集D∈Rn×d,随机森林RForest。
输出:重要特征数目s(s≤d);特征序列{S}。
步骤1取特征集F←D,对特征集F聚类并计算其DBI指标,取最优聚类数生成的特征簇集合得到
步骤2通过随机森林RForest对特征簇排序,即{Lk'}←RForest({Lk}),其中k'为k的置换。
步骤3取分类信息ClassInform←D,计算簇内特征与分类信息的相关性CorrD,确定其相关性阈值δ=mean(CorrD)+C×std(CorrD),重复下述步骤:
(1)依据簇内特征与分类信息的相关性对簇内特征排序得到L'k'←corr(Lk',ClassInform)。
(2)挑选重要特征fk←select({L'k'},δ)。
步骤4(s,U)←Number{fk|k=1,2,…,g},U为重要特征序列;{S}←{U}+rank(F-{U})。
3 实验结果与分析
本文实验在8个真实数据集上进行,其中两个数据集结肠癌数据集Colon[23]与白血病数据集Leukemia[24]为生物数据集,其余数据集均为UCI数据集[25]。为了方便本文实验中描述数据集特征数目的大小,本文根据不同数据集特征数目所在范围将数据集划分为低维、中维或高维数据集。数据集详细描述可见表1,其中d为特征数目。
3.1 实验设计
根据传统随机森林特征重要性度量方法得到最终特征排序的算法记为FSRF(Feature Selection by Random Forests)算法。MFPRF算法是在传统随机森林特征重要性度量方法上提出的。本文验证了FSRF算法的有效性,通过与FSRF、mRMR与Laplacian三种算法对比验证提出的基于随机森林多特征置换的特征选择算法MFPRF-KM、MFPRF-HC和MFPRF-FM的性能。实验方式如下:
(1)在低、中维数据集上通过将FSRF算法与ReliefF、MI两种特征选择方法在SVM分类器实验结果对比,验证基于传统随机森林特征重要性度量方法的FSRF算法的有效性。
(2)在低、中维数据集上通过将MFPRF算法与FSRF、mRMR与Laplacian三种算法在SVM分类器上实验结果对比,验证MFPRF算法的有效性与优越性。
(3)在低、中维数据集上通过将MFPRF算法与FSRF算法的运行时间对比,验证MFPRF算法更具有高效性。
MFPRF算法中的随机森林决策树数目Ntree=200,生成每棵决策树的样本数ψ=0.63×N(其中N为训练数据集的样本数)。为了得到较为稳定的结果,FSRF算法运行20次,取20次均值为特征的重要性得分。MFPRFKM算法采用欧式距离度量特征相似性,MFPRF-HC算法采用余弦相似性度量特征相似性。对比算法ReliefF参数选取抽样次数m=80,k=8。
实验对数据集进行预处理:删除数据集内缺失数据;为避免特征之间不同量纲对实验结果的影响,采用最大最小化方法标准化数据。采用SVM和KNN(K=1)两种分类器检验选取的重要特征集效果,并在排序后的特征序列中选取最优特征子集。SVM分类器使用林智仁等开发的SVM工具箱Libsvm,其中,核函数采用线性核函数,参数取值详见表1。以10次5折交叉验证实验结果的平均值比较各算法的性能,评价准则采用分类准确率ACC、AUC(或MAUC)与F-measure,其中MAUC是AUC对多类问题的推广。实验代码使用MATLAB 2014a实现;实验环境为Win7 64 bit操作系统,4 GB内存,Intel®Core™i7-3520M CPU@2.90 GHz。

表1 实验数据集描述及在SVM分类器参数Table 1 Descriptions of datasets used in experiments and parameters in SVM
3.2 实验结果
3.2.1 FSRF算法实验结果对比
图3为FSRF算法与ReliefF算法、MI算法在低、中维数据集上选择不同特征子集基于SVM分类器的平均ACC指标值。从图3实验结果可以得到如下结论:
(1)在6个数据集上,FSRF算法与ReliefF算法、MI算法相比,在选择较少特征时,就能取得最高(图3(a)、(b)、(c)、(e))或较高的分类准确率(图3(d)、(f))。这说明相较于ReliefF算法与MI算法,FSRF算法在较少特征时就可以选择到对分类模型最重要的特征。
(2)在6个数据集上FSRF算法在取到部分特征时可以达到峰值(如图3(a)、(b)、(c))或局部峰值(图3(d)、(e)、(f))。这说明FSRF算法在这6个数据集上特征选择是有效的,可以在较少特征上取得近似或更好的结果。
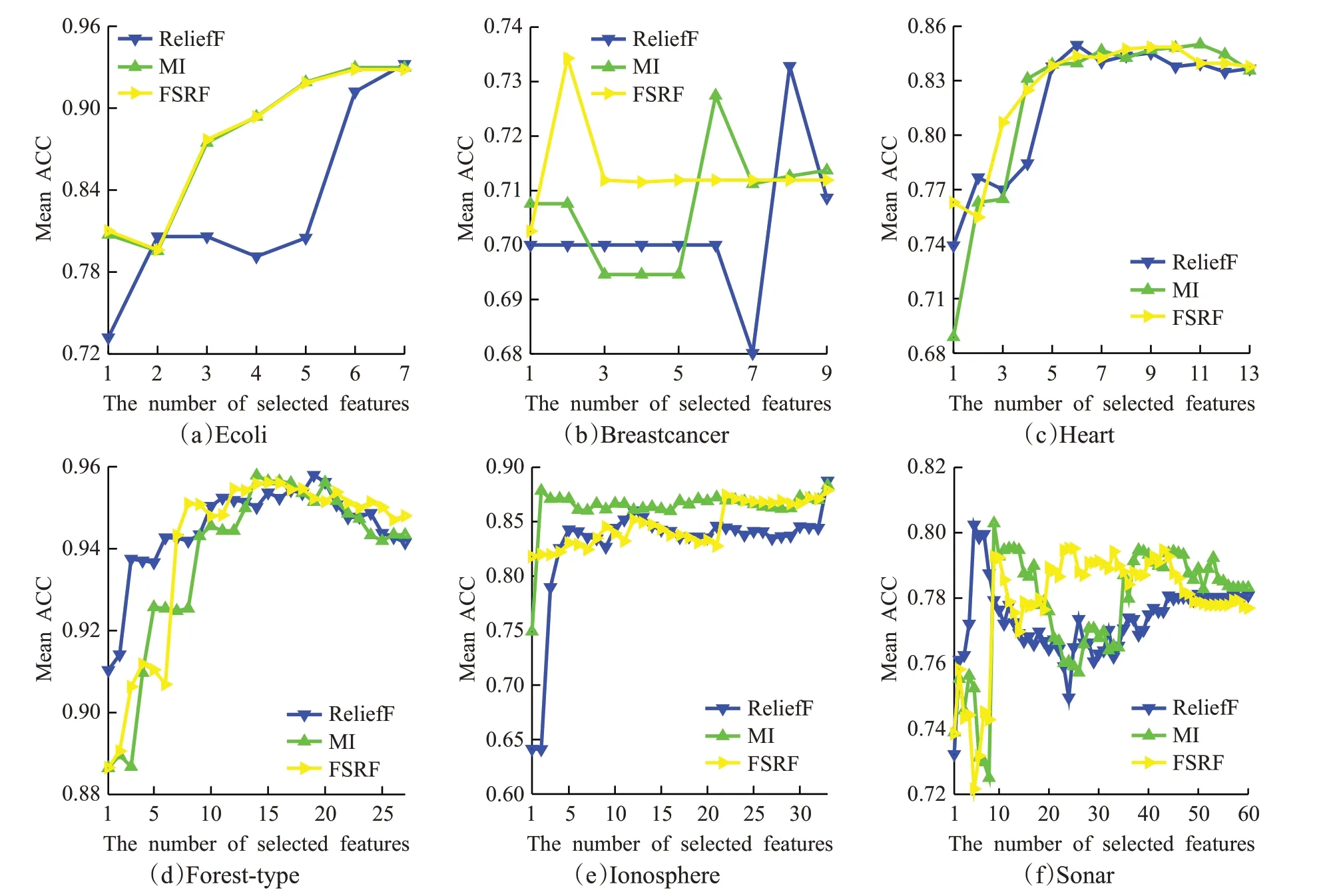
图3 FSRF与对比算法在数据集上的ACC指标值Fig.3 ACC of FSRF and its contrast algorithms on datasets
3.2.2 MFPRF算法实验结果对比
将随机森林多特征置换的特征选择算法MFPRF算法与FSRF、MI、Laplacian三种算法基于SVM分类器的实验结果对比,分别在低、中维共6个数据集上测试。
图4为MFPRF算法与对比算法在低维数据集上选择不同特征子集基于SVM分类器实验结果的平均指标值。由于低维数据集的特征数目较少,从优化特征序列考虑对分类效果的影响,图4所示实验结果显示,图4(a)中MFPRF-FM算法选择的特征序列在分类中取到最高分类准确率,其分类性能略优于其他算法,MFPRF-HC算法在选择较少特征时,可达到较高的分类准确率,并且其AUC指标明显优于其他算法;图4(b)中,基于MFPRF的三种算法在首特征上的分类性能优于其他算法,其中MFPRF-FM、MFPRF-KM算法优化后的特征序列分类平均准确率与F-measure指标优于其他算法;图4(c)基于MFPRF的三种算法的分类性能优于Laplacian算法,其中MFPRF-KM算法选择的特征序列AUC指标明显高于其他算法。
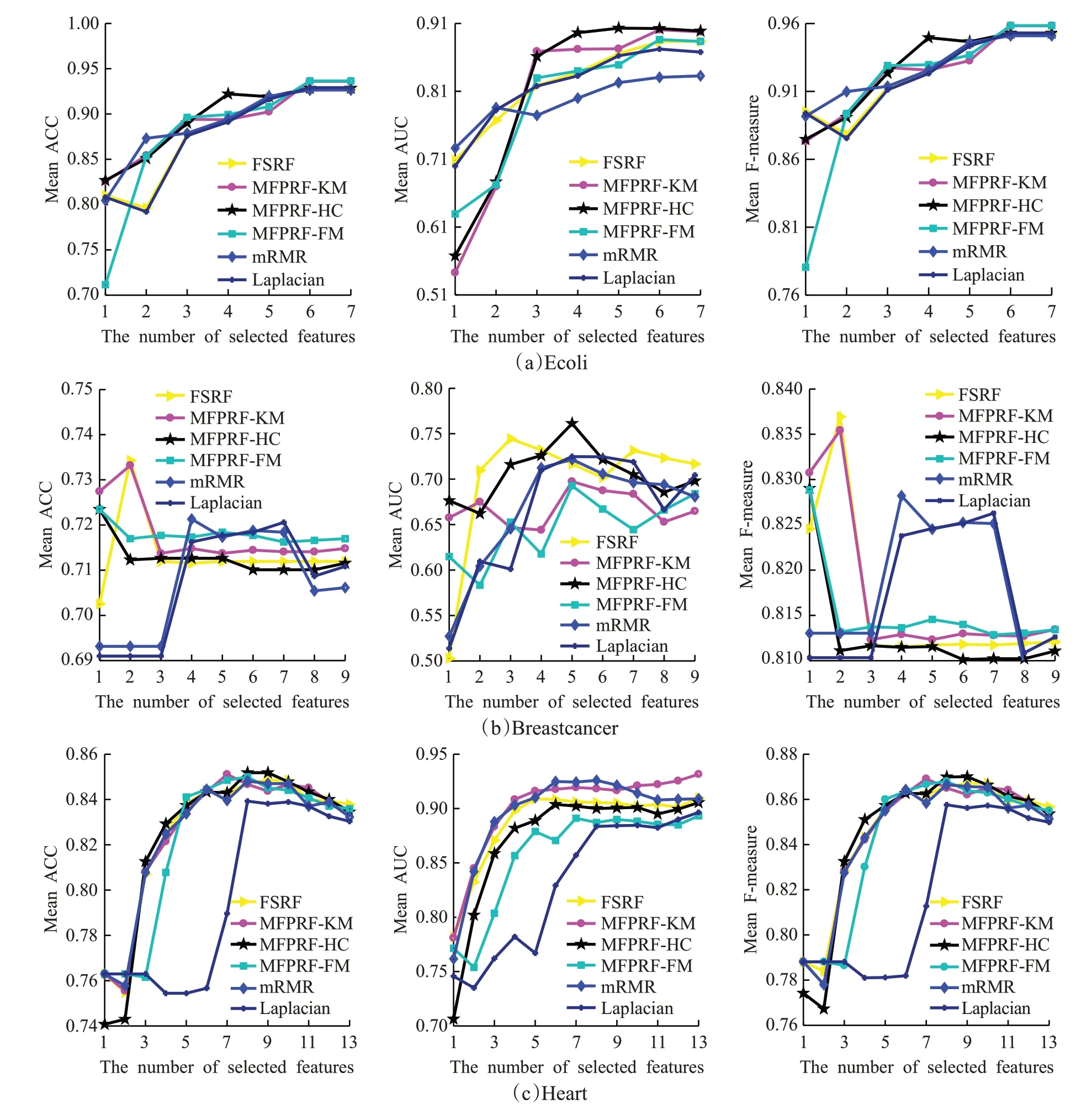
图4 MFPRF与对比算法在低维数据集上的指标值Fig.4 Index of MFPRF and its contrast algorithms on low dimensional datasets
图5为MFPRF算法与对比算法在中维数据集上选择不同特征子集基于SVM分类器实验结果的平均指标值。图5所示实验结果显示,图5(a)中,基于MFPRF的三种算法在首特征上均达到较高的分类准确率,在选择最优特征子集上,MFPRF-FM算法分类性能略优与其他算法;图5(b)中基于MFPRF的三种算法在分类准确率与F-measure指标上与mRMR算法相当,明显优于FSRF与Laplacian算法,在AUC指标上优于其他对比算法;图5(c)中基于MFPRF的三种算法的分类性能略优于FSRF算法或与其相当,明显优于Laplacian算法。
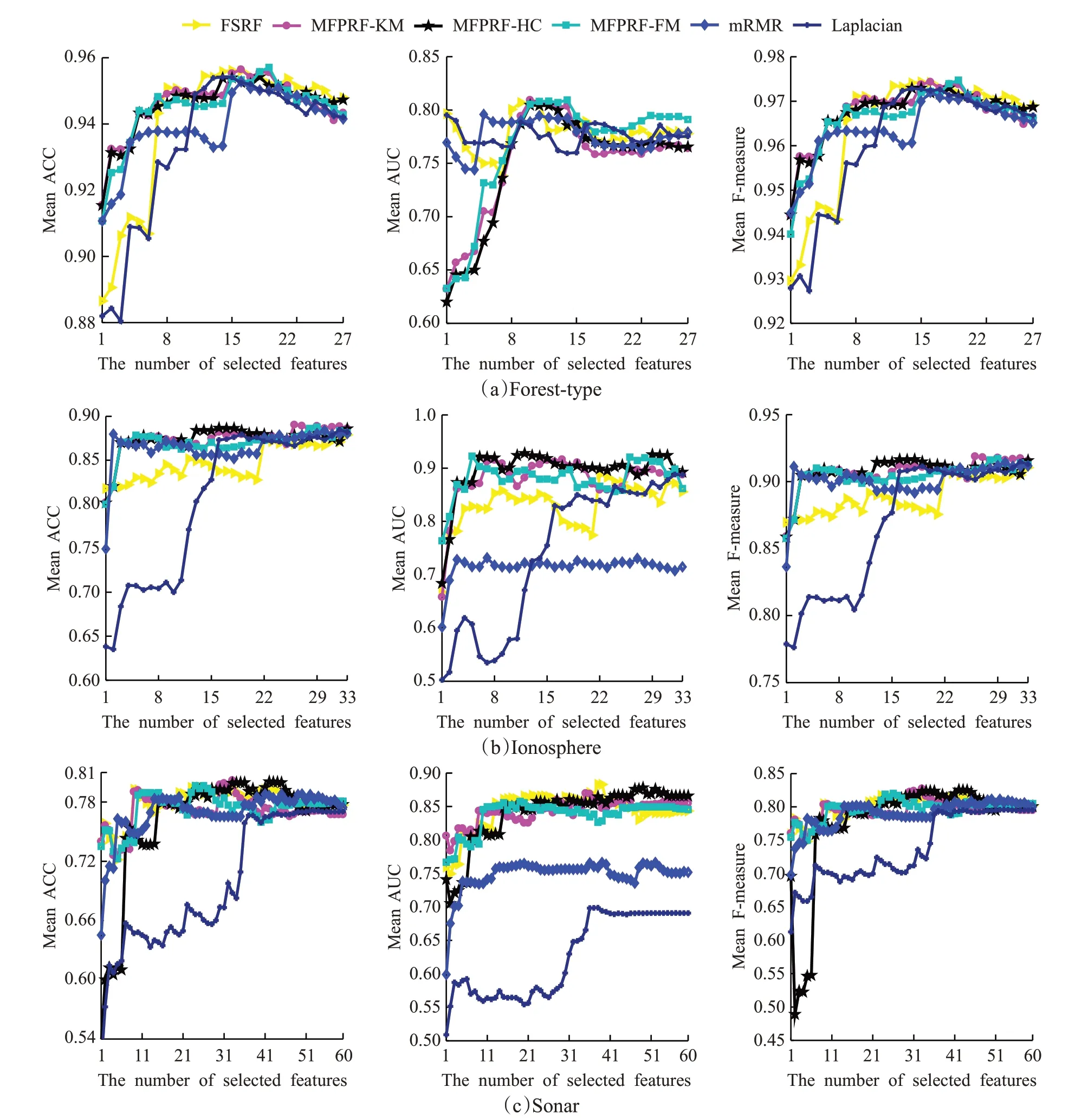
图5 MFPRF与对比算法在中维数据集上的指标值Fig.5 Index of MFPRF and its contrast algorithms on medium dimensional datasets
由图6结果所示,在6个数据集上,FSRF算法所用时间明显多于MFPRF算法,并且随着数据集特征数的增加,FSRF算法与MFPRF算法所用时间差值呈上升趋势。从图6得到数据集特征数目越多,MFPRF算法比FSRF算法更高效。
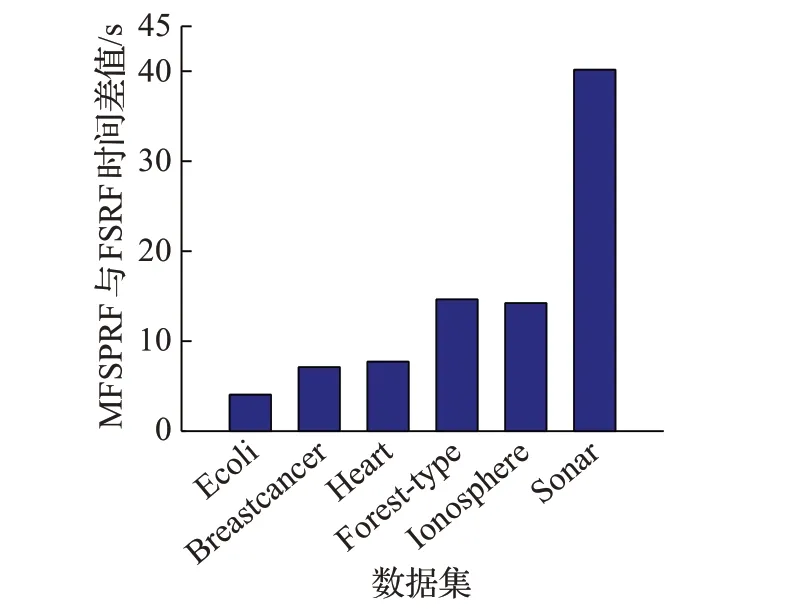
图6 FSRF与MFPRF算法在低、中维数据集的时间差值Fig.6 Difference of time of FSRF and MFPRF algorithms on low or medium dimensional datasets
3.3 MFPRF算法重要特征与最优特征子集选择结果
为了进一步验证MFPRF算法的性能,表2、3分别给出了三种MFPRF算法在低、中维数据集上F/B/I(全部特征/最优特征子集/重要特征集)基于SVM与KNN不同分类器的分类准确率平均指标值F_ACC/B_ACC/I_ACC,ACC表示无特征排序时的分类准确率。MFPRF算法参数C的取值与每个数据集的特征与分类信息之间的相关系数有关,C的大小可以控制MFPRF算法选择重要特征的数目,其具体取值时可以根据平均分类准确率与需要特征数目来进行调整,本文选取的参数C在表2、3中列出。
从表2数据看出:MFPRF算法在6个数据集上的重要特征分类准确率与无特征排序时相比,在Breastcancer数据集上最高高出1.95%,在Ecoli数据集上下降最多,但选取的重要特征数目为2,约占全部特征的29%,大大减少了选择特征的数目,并且分类准确率均在85%以上;MFPRF算法在6个数据集上的最优特征子集分类精度与无特征排序时相比,在Heart数据集上最高高出2.38%,在Ionosphere数据集上下降了0.29%,但选取的最优特征子集数目仅约为全部特征数目的15%,有效实现降维的目的。
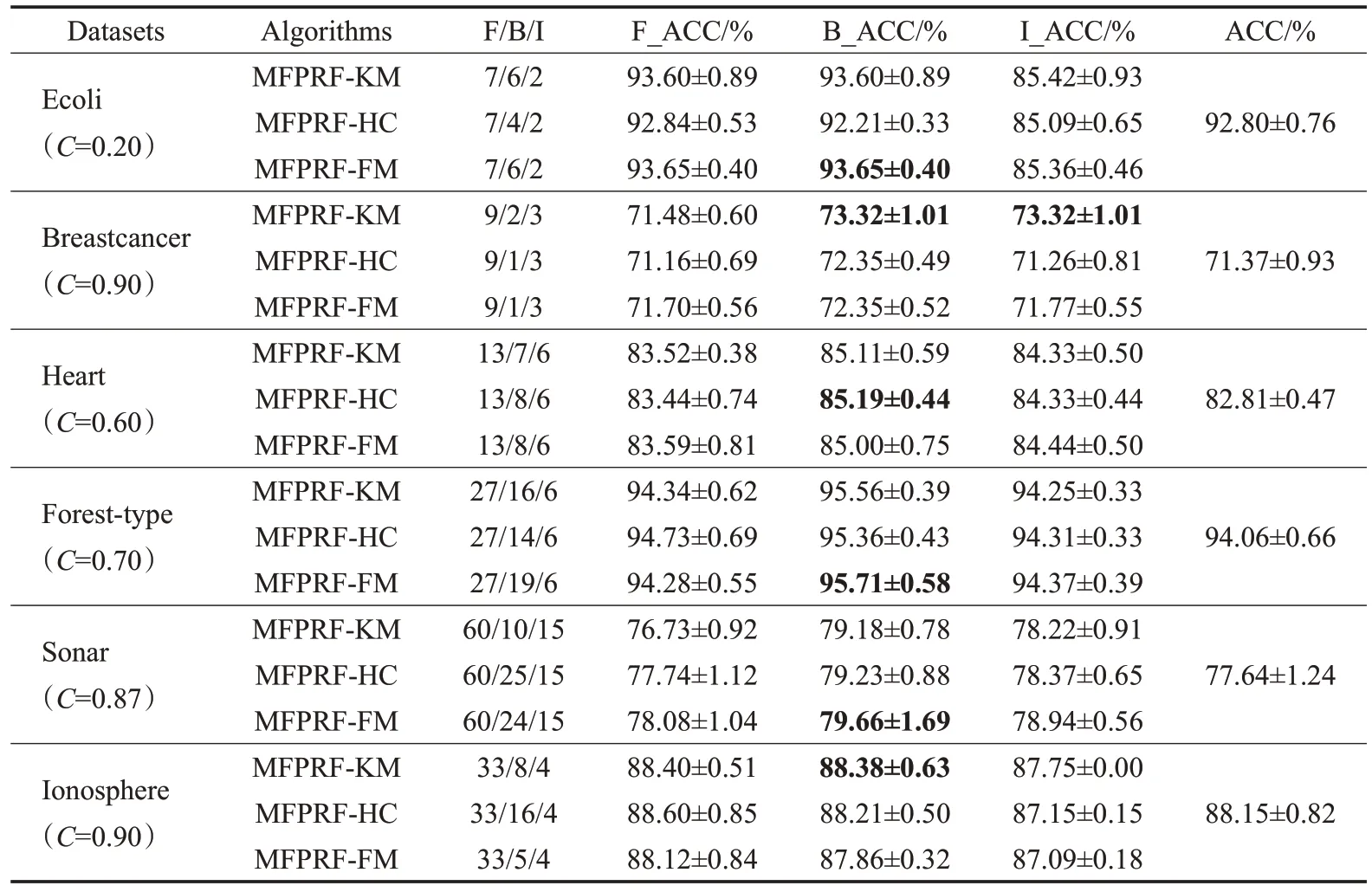
表2 MFPRF算法在数据集上F/B/I的SVM分类器ACC指标值Table 2 ACC of SVM classifier of MFPRF algorithms for F/B/I on datasets
从表3数据得出:MFPRF算法在6个数据集上的重要特征分类精度与无特征排序时相比,在Breastcancer数据集上最高高出4.36%,在Ecoli数据集上下降最多,但选取的重要特征数目约占全部特征的29%,且分类准确率均在80%;MFPRF算法在6个数据集上的最优特征子集分类准确率与无特征排序时相比,在Breastcancer数据集上最高高出8.26%,在Sonar数据集上下降了0.77%,但选取的重要特征数约为全部特征的78%,减少了选择特征的数目。
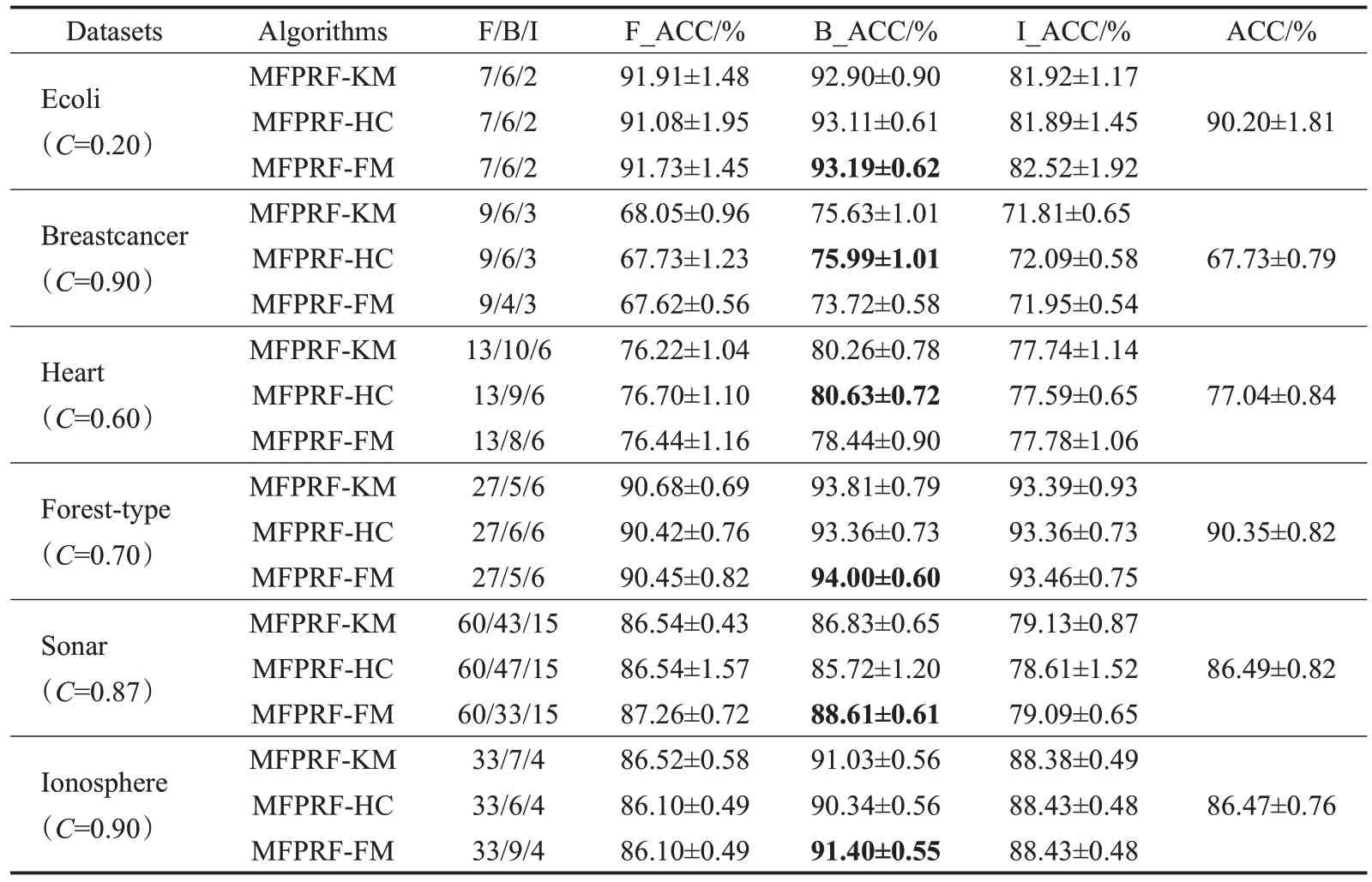
表3 MFPRF算法在数据集上F/B/I的KNN分类器ACC指标值Table 3 ACC of KNN classifier of MFPRF algorithms for F/B/I on datasets
MFPRF算法的最优特征子集的分类准确率略优于重要特征,但其所含特征数目明显多于重要特征数。在6个数据集上选择重要特征子集就可以达到较好的结果,若要分类结果达到最好,可以选择最优特征子集。
3.4 MFPRF算法应用在高维生物数据集
上述实验验证了MFPRF算法的有效性与优越性,相较于传统的FSRF算法更具有高效性,在运行时间少于FSRF算法的情况下,选择的重要特征数目远远少于全部特征数目,并可达到较高的分类准确率。将MFPRF应用在Colon与Leukemia两个高维的生物数据集上。图7为三种MFPRF算法分别在Colon数据集与Leukemia数据集上选取的重要特征子集在SVM分类器与KNN分类器上的平均分类准确率。MFPRF算法在Colon数据集上,所取参数C=2.2,在2 000个特征中选取了62个特征;在Leukemia数据集上,所取参数C=2.9,在7 070个特征中选取了84个特征。
从图7的实验结果可以得到如下结论:
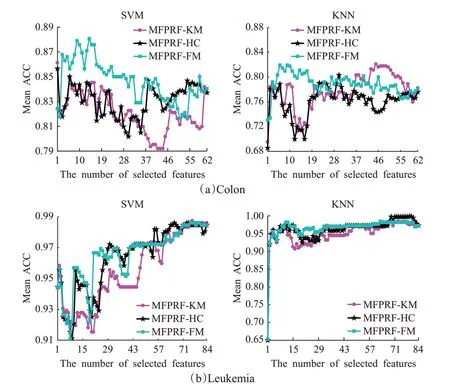
图7 MFPRF算法在数据集上重要特征的ACC指标值Fig.7 ACC of MFPRF algorithms for important feature subset on datasets
(1)在Colon数据集上,三种MFPRF算法中MFPRF-FM算法结果最好,选取重要特征中前20特征子集在SVM分类器与KNN分类器上均可以达到很好的分类效果。MFPRF-FM与MFPRF-HC算法结果略次于MFPRFFM算法,在SVM分类器上的结果略好于KNN分类器,并且分类精度基本在80%以上。
(2)在Leukemia数据集上,三种MFPRF算法在SVM分类器上选择前70左右的重要特征后分类精度达到最高并趋于稳定。在KNN分类器上,三种MFPRF算法在选取的重要特征子集上一直取得较高的分类精度,结果较为稳定。
4 结论与展望
针对高维特征计算消耗巨大问题,本文基于随机森林提出多特征置换的选择算法,包括MFPRF-KM、MFPRF-HC和MFPRF-FCM。实验结果证明了FSRF算法与MFPRF算法在低、中维数据集上的有效性;MFPRF算法在低、中维数据集上取得的重要特征集与最优特征子集的特征数目远远小于总特征数目,且在重要特征集上得到较好的分类效果,MFPRF算法计算效率明显高于FSRF;MFPRF算法在高维生物数据集上,其选取的重要特征在两个分类器上均能达到较好的分类结果。
MFPRF算法属于过滤式方法,比较依赖设定阈值,最优特征子集与分类器检验相互独立。MFPRF算法虽然简单高效,但不利于后续特征优化,影响分类模型的泛化性能。今后的工作重点设计出基于随机森林的多特征封装式算法,进一步提高分类器性能。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
都市丽人(2015年4期)2015-03-20 13:33:22
振动工程学报(2014年4期)2014-03-01 01:15:41
